1. Introduction
Object detection in optical remote sensing images is widely applied into many key fields such as environmental monitoring, geological hazard detection, precision agriculture, etc. [
1]. With the rapid development of remote sensing technology, the number of remote sensing images has been growing dramatically and the quality of images has been improved rapidly. In the meanwhile, the task of object detection is increasingly complicated, which may face a large amount of object categories and complex target scenes. The conventional analytical methods are hard to meet growing diversified needs. In this case, the introduction of Convolutional Neural Networks (CNN) [
2], the performance of which has been widely proved on general object detection [
3,
4], attracts growing attention from remote sensing field. In general, these detectors can be divided into two main categories: the two-stage detection and the one-stage detection framework.
The two-stage detection method consists of two steps: the pre-processing step for region proposal and the classifying step. At the first step, region proposals that contain potential objects instead of background are generated from one image through an algorithm by using Selective Search (SS) [
5]. The second step includes determination for the label and regression for the bounding box. Category-specific classifiers will be used to determine the labels of those region proposals. In addition, the bounding box will be corrected more precisely through box regression.
The two-stage detection and their extensions like Region-CNN (R-CNN) [
6], Fast R-CNN [
7], Faster R-CNN [
8], and Feature Pyramid Networks (FPN) [
9] make great progress on general object detection. However, two-stage detection has inherent defects: since numerous region proposals are required, training and testing are getting slow.
The one-stage detectors, such as You Only Look Once (YOLO) [
10], Single Shot MultiBox Detector (SSD) [
11], and Retina-Net [
12], straightforwardly predict label confidences and locations of all possible objects on the feature maps from one image. After removing the region box, one-stage detection gains great improvement in detection speed but gets relatively poor detection accuracy on detecting multi-scale and multi-class targets. To address this issue, enhancing the capability of feature representations is effective to improve the performance of one-stage detector. SSD predicts objects from multiple layers with multi-scale features. This strategy neglects semantic information of features from shallow layers and does not solve the problem of poor performance for detecting small objects yet. FPN introduces a top-down structure to fusion features from different layers and brings about more semantic information of features. However, fusing features layer by layer is not effective enough to represent context information. Based on SSD, Receptive Field Block Net (RFBNet) [
13] introduces receptive field Block (RFB) ahead of prediction module. RFB simulates the mechanism between the human population Receptive Field (pRF) size and eccentricity in the human visual system, which effectively produces multi-scale receptive fields. However, branches of RFB structures are independent, which results in the loss of correlation of features.
Compared with natural scenes, object detection in remote sensing images suffers from fundamental challenges like changeable-scale objects, small objects in dense-target scenes.
Figure 1 illustrates the instance size distribution of typical remote sensing dataset DOTA [
14] and natural dataset VOC [
15]. It is clear that the DOTA dataset is dominated by instances under 100 pixels while the instances in VOC dataset are widely distributed between 0 to 500 pixels. In addition, there are both some extremely small and huge objects in remote sensing scenes. For example, a bridge can be as small as 15 pixels and as large as 1200 pixels, which is 80 times larger than the smaller one. The enormous differences among instances make the detection task more challenging because models must be flexible enough to handle extremely tiny and giant objects.
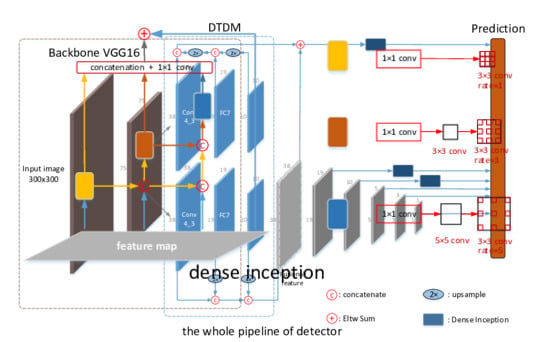
To handle these problems above, this paper attempts to enhance the ability of feature representation by proposing two novel structures: Dual Top-Down Module (DTDM) and Dense-connected Inception (Dense Inception) module. DTDM is merged into top layers of the backbone network, with limited extra computation under control, and replaces the top layers of the backbone network with two top-down modules branches. For one branch, the features from the last several layers are integrated from upper layers to lower layers and delivered directly to the prediction module. For the other, the top layers of the backbone network are combined to generate the fusion feature and replace the top layer. By combining different level features—low-level local detailed features and high-level global semantic features—the ability of feature representation is significantly enhanced and the performance on small objects is improved. Inspired by the dense structure of DenseNet [
16], this paper proposes Dense Inception with dense-connected branches of different atrous layers, to combine features from branches with stronger correlation and more effective field, yielding more efficient integrated features. Dense Inception further enhances the ability of feature representation of each feature map, which is useful for detecting changeable-scale objects.
Our detection framework effectively improves the model’s ability of feature representation. With adding newly proposed structures, our detector achieves state-of-the-art performance among published articles on the public DOTA dataset. In this paper, our contributions can be briefly summarized as follows:
We propose a novel top-down module, DTDM, to combine multi-scale features from fusion layers of multiple layers. The multi-scale features from different layers can be effectively merged to detect multi-scale objects in complicated scenes.
We introduce a Dense Inception module to extract features more efficiently. The new structure can generate features that cover larger and denser receptive field size, as well as effectively integrating contextual information.
The rest of paper is organized as follows:
Section 2 introduces proposed modules in detail. We compare DTDM modules with several relative modules. In
Section 3, we conduct our experiment and list compared experiments. In addition, some experiment details are shown for further comprehension. The result of all experiments as well as their analysis are presented in
Section 4. In
Section 5 and
Section 6, we draw the conclusions from our work and make the plan for further work.
2. Methods
In this section, we describe the architecture of DTDM module and Dense Inception. Furthermore, we also compare proposed modules with relative structures. Finally, the whole pipeline structure of the model is presented in detail.
2.1. DTDM
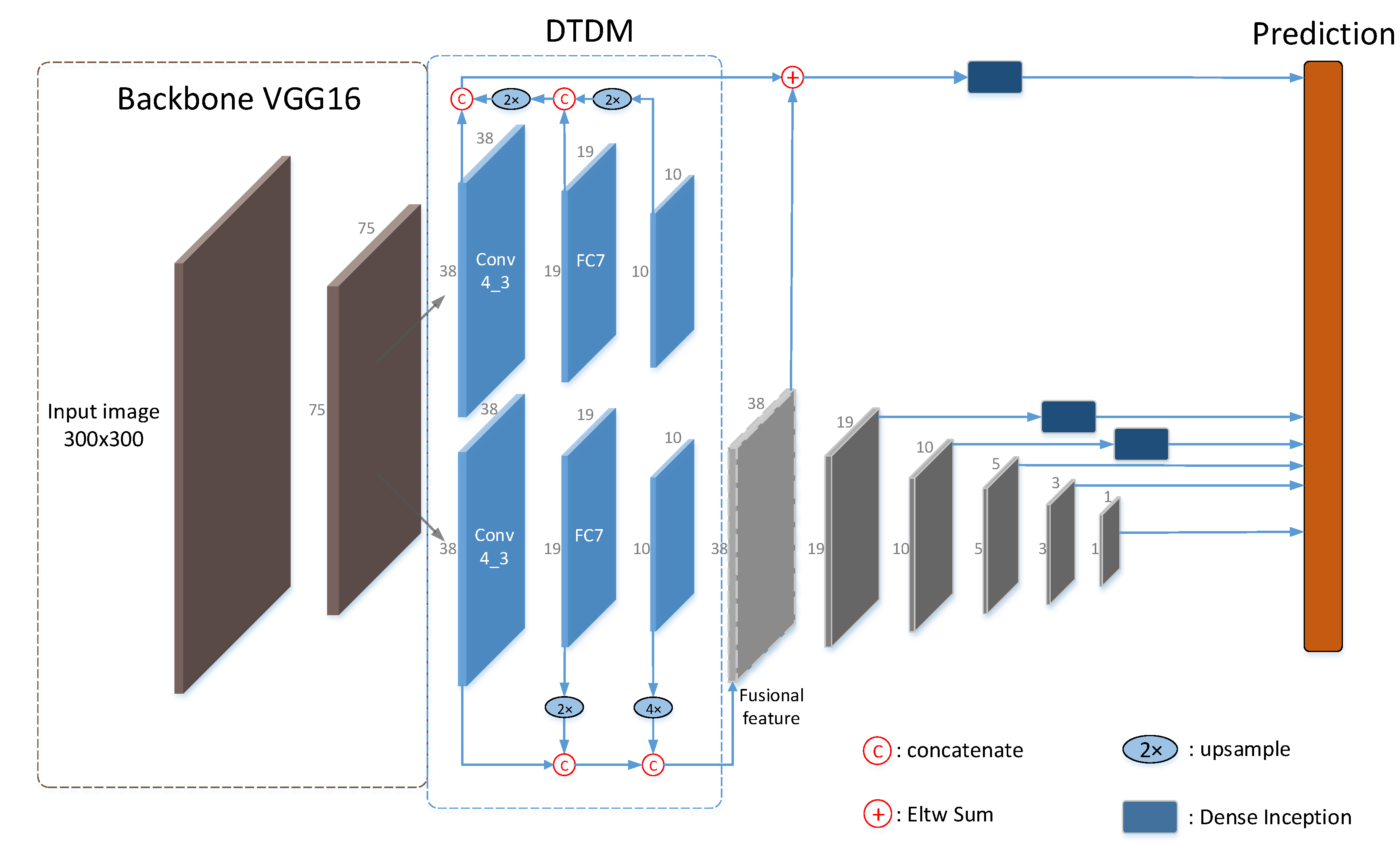
CNN module consists of a series of convolution layers with filters, Pooling, Fully Connected layers (FC) and Softmax function. The backbone network of detectors is based on CNN modules, in which many convolution layers cascade and generate various feature maps with size descending. The features from high layers have large receptive fields and strong semantics, with great robustness to variations like illumination but at the cost of geometric details. In contrast, the features from lower layers have small receptive fields and rich geometric details, but possess much less semantic information. Classic detectors based on deep CNN like R-CNN, Fast R-CNN, Faster R-CNN and YOLO, merely make use of the top layer of CNN modules for feature representation. However, a single feature map is not enough to extract the various features with multi-scale and multi-level feature information.
To handle this contradiction, there are some explorations on multi-level object detection: detecting at multiple CNN layers or detecting with combined features of multiple CNN layers. The former, like FPN in
Figure 2a, combines predictions from multiple feature layers to handle multi-scale objects. The latter, like Top-Down Module (TDM) [
17] in
Figure 2b, is generally implemented by skip connections: skip selected layers and feed the output of lower layers as the input to upper layers. It proves that both explorations have made progress to a large extent. In order to achieve the best combination of feature information, it is natural to implement both strategies. Since the two methods above separately work at different stages of detection: detecting at multiple CNN layers was applied in prediction or detecting with combined features in extracting semantic information. This paper proposed DTDM to detect with combined features and merged the structure into the backbone network Visual Geometry Group Net (VGG16) [
18].
As is presented in
Figure 2c, the input was fed into two branches: for one branch, feature maps of decreasing sizes from different layers were upsampled to the same size and concatenated together. For the other branch, it integrated a top-down network with lateral connections. High level semantic features were transmitted back by the top-down network and combined with the bottom-up features from intermediate layers. Then, the outputs of both branches were further processed via element-wise summation for prediction.
2.2. Dense Inception
At the beginning of deep learning, CNN was used to extract feature from one image. Although CNN made a breakthrough on the performance of object detection, it still needs to be enhanced. In order to improve the image representation performance, very deep convolutional network have been proved efficient. However, the deepening of convolutional network brought about serious side effects: the high computational cost and huge amount of parameters.
One alternative is increasing the depth and width of the network with limited extra computational cost. Considering this motivation, the inception architecture [
19] achieved great performance at relatively low computational cost.
Figure 3 shows three typical multi-branch convolution layers. Inception architecture attempted to extract multi-scale feature information by launching multi-branch convolution layers with different convolution kernels. In the multi-branch CNN architecture of inception, all kernels were sampled at the same center. To further enhance the representation ability of CNN, the atrous convolution was first introduced [
20] to apply multi-scale kernels, which is equivalent to convolving the input with up-sampled filters for a large receptive field. In many scenes like aerial image, there were various objects in multiple sizes. To deal with this situation, the feature maps must cover multi-scale receptive fields. Thus, RFBNet made use of multi-scale dilated convolution layers to adapt to multi-scale kernels of CNN, which covers multi-scale receptive fields and makes it significantly useful for extracting multi-level information. Furthermore, the introduction of residual connection can accelerate the training of inception network significantly [
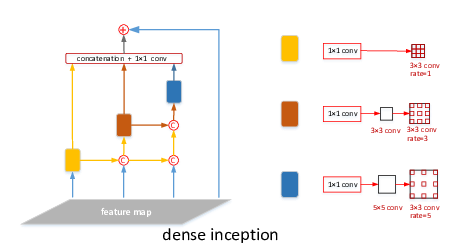
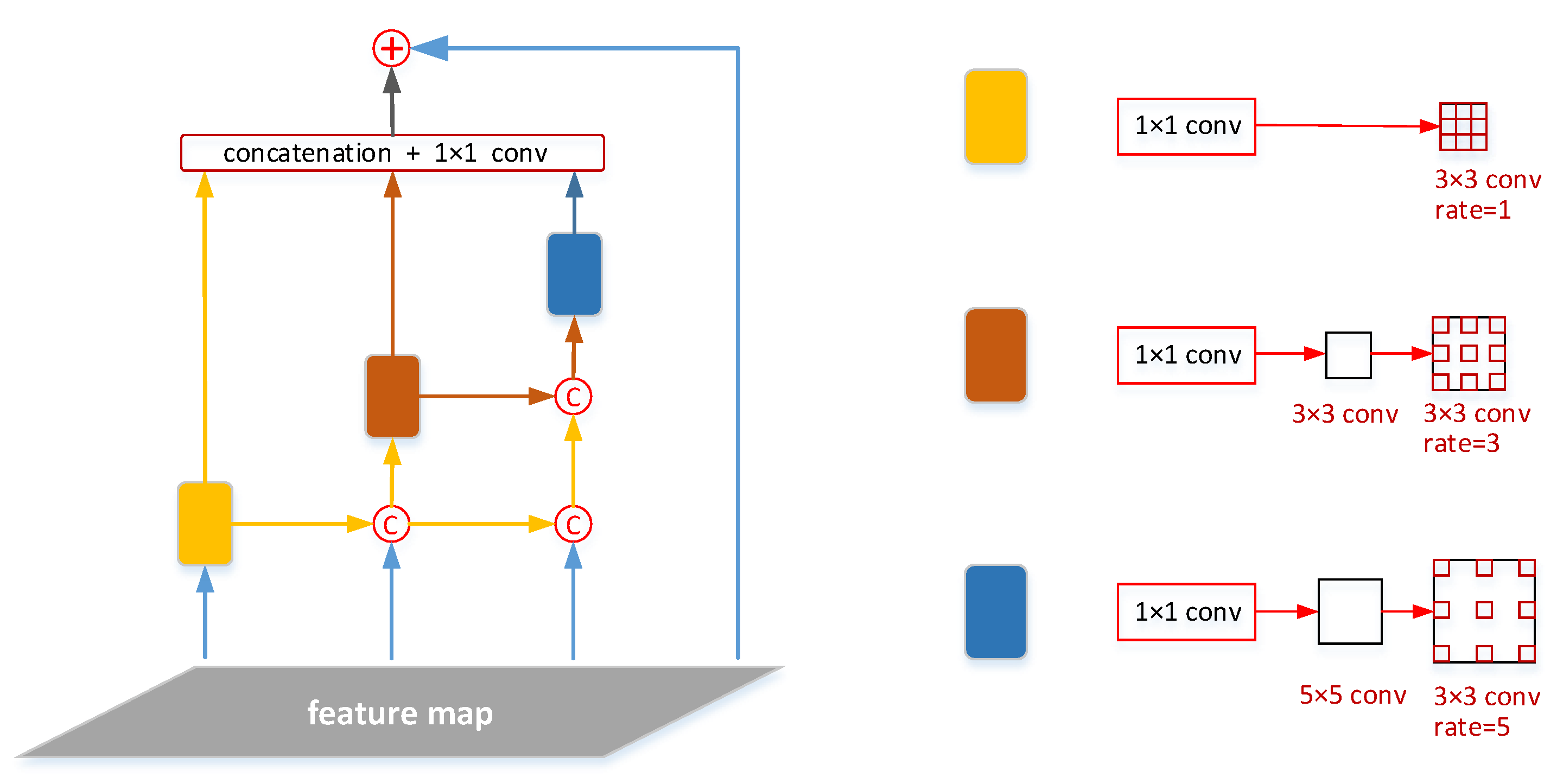
21]. However, each branch in RFBNet is independent of one another, resulting in the lack of correlation of semantic information from extracted features. To rethink the structure of RFBNet, there is another alternative to integrate multi-branch information ahead of delivery together to the prediction module. Inspired by the dense structure in densenet in semantic segmentation, this paper proposes a novel structure, called Dense Inception, in which the output of small-kernel CNN branch is concatenated to the input to the other bigger-kernel ones. In addition, there is a lateral connection from the original feature map to the output of the module. The combined features were further processed and delivered to the prediction module. The new module not only increased the receptive field of features but also made features of each branch more relational, which is greatly useful for detecting multi-scale objects.
Figure 4 presents the structure of Dense Inception in detail.
There are two strategies on Dense Inception: cascading and parallel modes. The cascading mode defines the cross-layer dense-connected structure. The lower atrous layers are connected to upper atrous layer, which can generate large receptive fields. As for parallel mode, multiple atrous layers accept the same input. It means that the output is indeed a sampling of the input with different scales of receptive fields. The module not only inherits the advantage of aspp by using multiple atrous-convolved feature representation, but also makes better use of inner relationship of multiple layers.
In the inception module, the branches were organized in parallel. Multiple atrous layers were fed with the same inputs and the inputs were indeed sampled with various scales of receptive fields. As for single branch, there exists one theoretical issue called ‘gridding’ [
22]. During atrous convolutional operation, much feature information will be lost: for a feature map in dilated convolutional operation with kernel size
k and dilation rate
r, only
out of
in the region were used for the computation. When
r became large, the information sampled by atrous convolution would be weakly correlated, which would cause severe loss of local information. The cascading atrous layers with increasing dilation rate can solve the problem. The progressive concatenation of atrous layers made the top atrous layers accept more complete information from the input.
In Dense Inception, the atrous layers are organized both in cascading and parallel modes. Since the atrous layer of larger dilation rate accepts the output of the other atrous layers of smaller dilation rate, it can efficiently produce larger receptive fields. The final output of Dense Inception is a feature map derived from multi-scale and multi-rate atrous convolutions. The details are presented as follows:
Firstly, in order to decrease and regularize the channel numbers of the input, we placed a convolution layer between each branch and the original feature map, respectively. For one branch, the head was followed by different convolution layers of increasing kernel sizes. After the multi-size kernel convolution layer, we put the corresponding atrous convolution layer whose rate is identical with the kernel size of previous layer. Finally, we adopted the shortcut design from inception from Resnet and the original feature was fed for concatenation with outputs from each branch.
2.3. Structure of Detector
Considering the demand of both precision and speed, we chose lightweight network VGG16 as our backbone network. VGG16 is a classic lightweight network which is adopted by lots of state-of-the-art detectors, especially by those high-speed ones. However, lightweight detector is popular for its “light” but relatively weak ability of detecting multi-scale and multi-class targets. As is shown in
Figure 5, we removed the last FC layer of VGG16 to decrease the parameters of original network as well. Layer conv1, conv2, conv3 of VGG16 were reserved and later layers were replaced by DTDM. In consideration of the resolution and feature representation of layers, we chose conv4_3 as a base feature map. Therefore, the conv4_3, conv7 and conv7_2 were combined via concatenation, and then the fusion feature map replaced original conv4_3 with the network once again. The corresponding feature size was
,
and
, respectively. In particular, the Dense Inception was placed after the fusion feature map from DTDM, con4_3 and conv7 to extract more effective features for prediction. In addition, the later layers were set the same as that in RFBNet.
3. Experiment Settings
3.1. Dataset
Remote sensing datasets differ from general datasets and possess their own characteristics. Multi-scale targets have a wide range: the size of objects varies from meters to hundreds of meters. Extremely uneven distribution of targets: the detected image may contain hundreds of objects or nothing valid.
Compared with other public optical remote image datasets, including UCAS-AOD [
23], NWPU VHR-10 [
24] and VEDAI [
25], DOTA covers the most categories and the largest quantity scale. The other datasets have a lack of category or number of instances in Earth Vision, making themselves far from achieving simulation of the complicated realistic aerial scene. We conduct our experiment on the aerial images DOTA dataset. It contains 2806 aerial images and the size of images ranges from
pixels to
pixels. In detail, the dataset consists of 188,282 instances over 15 categories, including plane, ship, storage tank (ST), baseball diamond (BD), tennis court (TC), ground track field (GTF), harbor, bridge, large vehicle (LV), small vehicle (SV), helicopter (HC), roundabout (RA), swimming pool (SP), soccer ball field (SBF) and basketball court (BC).
The DOTA dataset has been divided into three subsets: training, validation and testing subsets, in which only the labels of training and validation subsets are public. Thus, we train and evaluate our detectors in the training and validation subset, respectively, and then submit our testing results on testing subsets to the public official website for comparing our detection performance with other published ones. In particular, it is difficult to directly train the network on the raw images with huge size. Therefore, the raw images in training and validation subsets are cropped at the size of with the stride of 600.
3.2. Baseline
Considering the giant size of remote sensing images and some particular usage scenarios with real-time demand of detection, we preferentially choose a one-stage state-of-the-art detector with high detection speed. Therefore, we choose RFBNet as our baseline for its excellent balance between detection accuracy and computation. RFBNet is one of the best one-stage detectors which achieves the state-of-the-art performance among very deep detectors while keeping the real-time speed.
3.3. Evaluation Metric
For evaluation metrics, we adopt the same mean Average Precision (mAP) calculation as for PASCAL VOC. The most commonly used metric for evaluating the performance of detection algorithms is Average Precision (AP), derived from precision and recall. For a given annotated image, the output form a detector denotes
indexed by
i, where
b,
l, and
p separately represents predicted box location, label and confidence of target
i. A predicted instance regarded as TP (True Positive) must meet the following conditions: the predicted label
l is the same as the ground true label
; the iou (Intersection Over Union) between predicted bounding box b and the ground truth one
exceeds the preset threshold (commonly defined as 0.5):
Here,
and
respectively denotes the intersection and union of the predicted and ground truth BBs. The other ones that do not meet above two conditions are regarded as False Positive (FP). In addition, if there are no more than one FP for one
, the
b with max
p will still be regarded as TP while the other ones will be regarded as FPs. For one special category, all relative TPs and FPs are counted from the whole testing images. Based on the TP and FP, the precision
and recall
are defined as follows:
where FN and
respectively denote the number of false negatives and the confidence threshold. The precision
and recall
can be determined as a function of the confidence threshold
. By computing the average value of Precision over Recall with different Recall value ranging from 0 to 1, the AP can be obtained. Finally, the mean AP (mAP) of all categories is defined as the final detection indicator.
3.4. Experiment Details
In our experiment, our training strategies mostly follow the RFBNet, including hard negative mining, data augmentation, some hyperparameters like default box scale and ratios. For better initialization for parameters, our model is trained from a pre-trained VGG model. In addition, all our training experiments are implemented on a Nvidia Tesla P100 GPU (Santa Clara, CA, USA) with batch size 16 for 240 k iterations. In particular, when compared with other published models, our detectors are evaluated on Nvidia 2080Ti GPU.
When testing our detector on a testing subset of the DOTA dataset, we directly set each raw image as our input. A sliding window of
scans the input image with a stride of
to generate a set of image patches. Then, the detector detects objects on each patch and outputs detecting results. The outputs are merged to make up the final results of raw whole image. The Non-maximum suppression (NMS) with IoU threshold is set as a 0.3 to filter overlapped boxes. In particular, we implement our detector based on the Pytorch framework and will open the code at
https://github.com/pioneer2018/dtdm-di. For fair comparison, we preserve the most of original RFBNet.
5. Discussion
The above experiment results show that, compared with other published methods, our detector achieves higher mAP than other one-stage detectors and outperforms other two-stage detectors both in detection accuracy as well as speed on the DOTA dataset. From the perspective of both detection accuracy and speed, our detector achieves state-of-the-art detection performance. With the integration of DTDM and Dense Inception, we further enhance the baseline network, excellent one-stage detector RFBNet, by 2.66% mAP with a little loss in detection speed. In particular, DTDM enhances the ability of the feature representation of the backbone network to a large extent, which mainly improves the performance of detecting small and changeable-scale objects. In addition, Dense Inception further improves the detection accuracy by effectively increasing the receptive field, which is beneficial for detecting objects in complicated remote scenes. Compared to the work of Azimi et al. [
28] and Yan et al. [
29], which get the best detection performance among published methods, our method achieves even better detection accuracy and speed.
In the meantime, our detector performs relatively poorly in categories like bridge, GTF (ground track field), ST (storage tank) and RA (roundabout). We think there are two factors mainly resulting in this issue. On the one hand,
Table 4 presents an extremely uneven number of the distribution of categories. There are numerous vehicles (SV, LV), but far less objects like GTF (ground track field), SBF (soccer ball field) and HC (helicopter). The sample lack of those categories makes it hard to fully train the model for detecting them. On the other hand, it is difficult to detect multi-scale objects that cover quite a wide range in size. Remote sensing images contain many special categories, which possess lots of large-scale objects, and these objects are easily cut to several slices when testing on cropped
images. Incomplete objects bring extra difficulty to our detection model.
In addition, there are some misclassifications that cause some performance loss of detection. In
Figure 8, the confusion matrix obtained by our model presents classification details among 15 categories and backgrounds. The misclassifications are located between some categories, such as GTF (ground track field) and SBF (soccer ball field), HC (helicopter) and plane, especially between objects and bg (background). The improvement of classification performance will be considered in the future.
In future study, we will change our loss function in response to an unbalanced distribution of samples and misclassifications among categories. The adaptive weight of each category will be added to the loss function to adapt to particular categories with a lack of samples. The strategy to learn semantic similarity directly from deep features [
30] may be useful to decrease misclassifications. In addition, we will try to introduce an image pyramid into data preprocessing before training to better detect multi-scale objects. In addition, it has been proved that adding extra prior information to the model is the key to help improve the achievement of some tasks [
31,
32]. We will attempt to redesign our model to utilize other related prior information to enhance the detection.
6. Conclusions
In this paper, we propose a powerful one-stage object detector. In order to improve the performance while maintaining the high detection speed, we choose the lightweight network VGG16 as our backbone network. However, the performance of a lightweight network on feature representation remains to be enhanced and it is hard to adapt to the characteristics of remote sensing images. In order to improve the performance of detectors in remote sensing images, especially on detecting a small and changeable-scale, we choose to handle the problem by multi-layer feature fusion. In the meantime, a deeper network means better capability of feature representation. Furthermore, we introduce Dense Inception to deepen and widen the network with little computation cost. From all of the experiment results, both methods contribute a lot to the improvement of detecting performance. On the one hand, DTDM integrates multiple features from multiple layers via two branches. Each branch plays a different role in the fusion of features and the experiment shows that the impact of two branches are complementary for improving detection accuracy. On the other hand, Dense Inception adopts atrous convolution with an increasing atrous rate. The structure of dense connection yields a larger receptive field and avoids much loss of information, which brings an improvement in detecting multi-scale and changeable-shape categories. For further work, we plan to apply our model to other lightweight backbone networks like MobileNet-SSD to achieve more real-time detection speed.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}