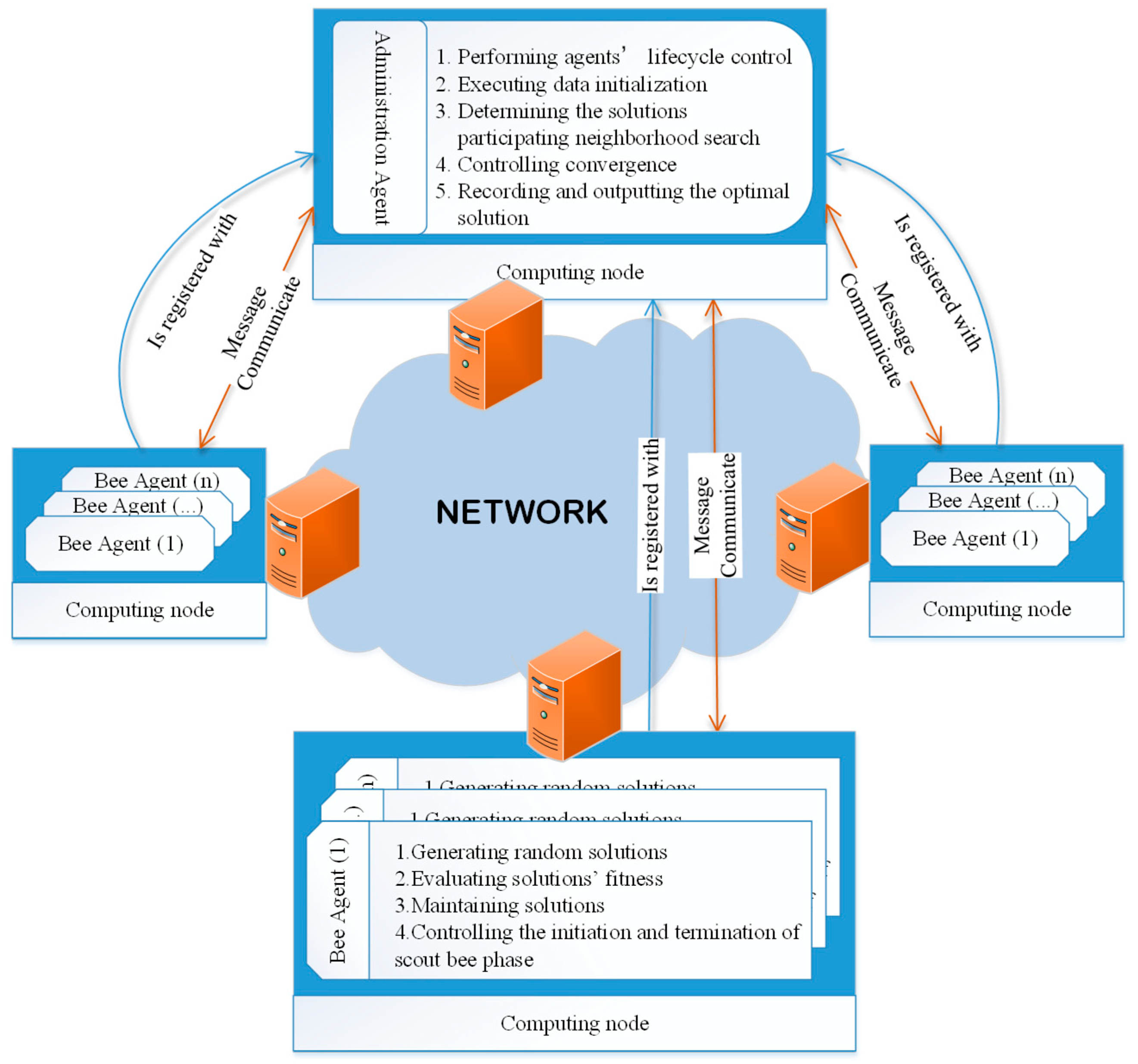
3.2. Agents’ Communication Design
In this paper, a message-passing mechanism is adopted for the smooth implementation of the algorithm. All agents communicate with each other through the network by messages. According to the standard of agent communication language (ACL), each message contains at least five fields: the sender, the receivers, contents, language, and a communicative act [
24].
For example, in ABC’s employed bee phase, the administrator agent will pass a neighborhood solution to each bee agent before executing the neighborhood search. Therefore, the sender of the message is the administrator agent, and the receiver is a bee agent. The message content contains the neighborhood solution, which is coded in the language of Java by serialization in our design. Under these circumstances, the sender (the administrator agent) wants the receiver (a bee agent) to perform an action (begin its neighborhood search); thus, the communicative act should be set as REQUEST. However, in certain other situations, the sender only wants the receiver to be aware of a fact, such as a bee agent notifying the administrator agent while completing a scout bee behavior; thus, the communicative act should be set as INFORM.
3.3. Agents’ Behavior Design
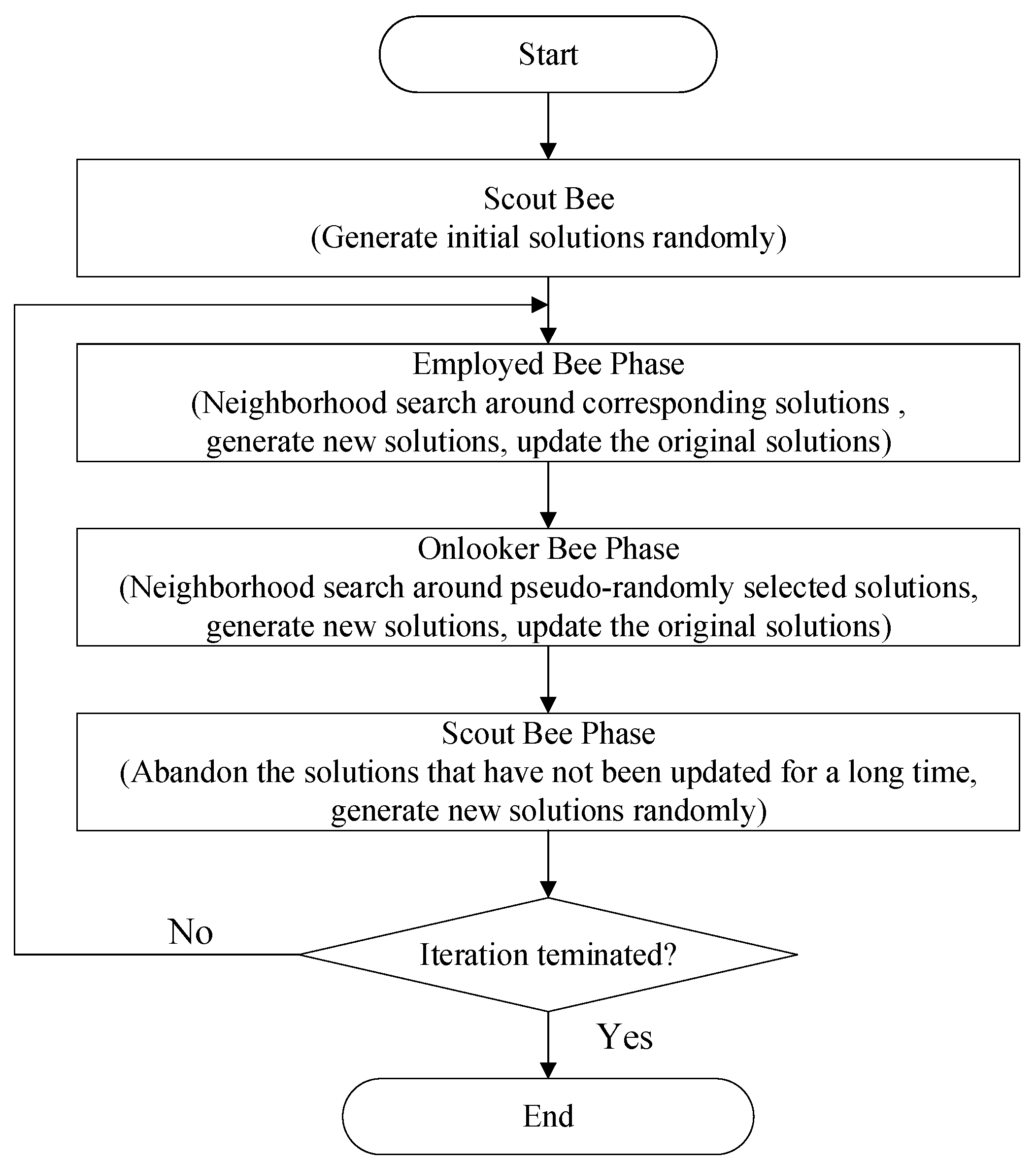
The agents’ behavior in an MA framework is tightly coupled with the procedure of the ABC algorithm. There are five phases in ABC: the initial phase, the employed bee phase, the onlooker bee phase, the scout bee phase, and the convergence judgment phase (
Figure 3).
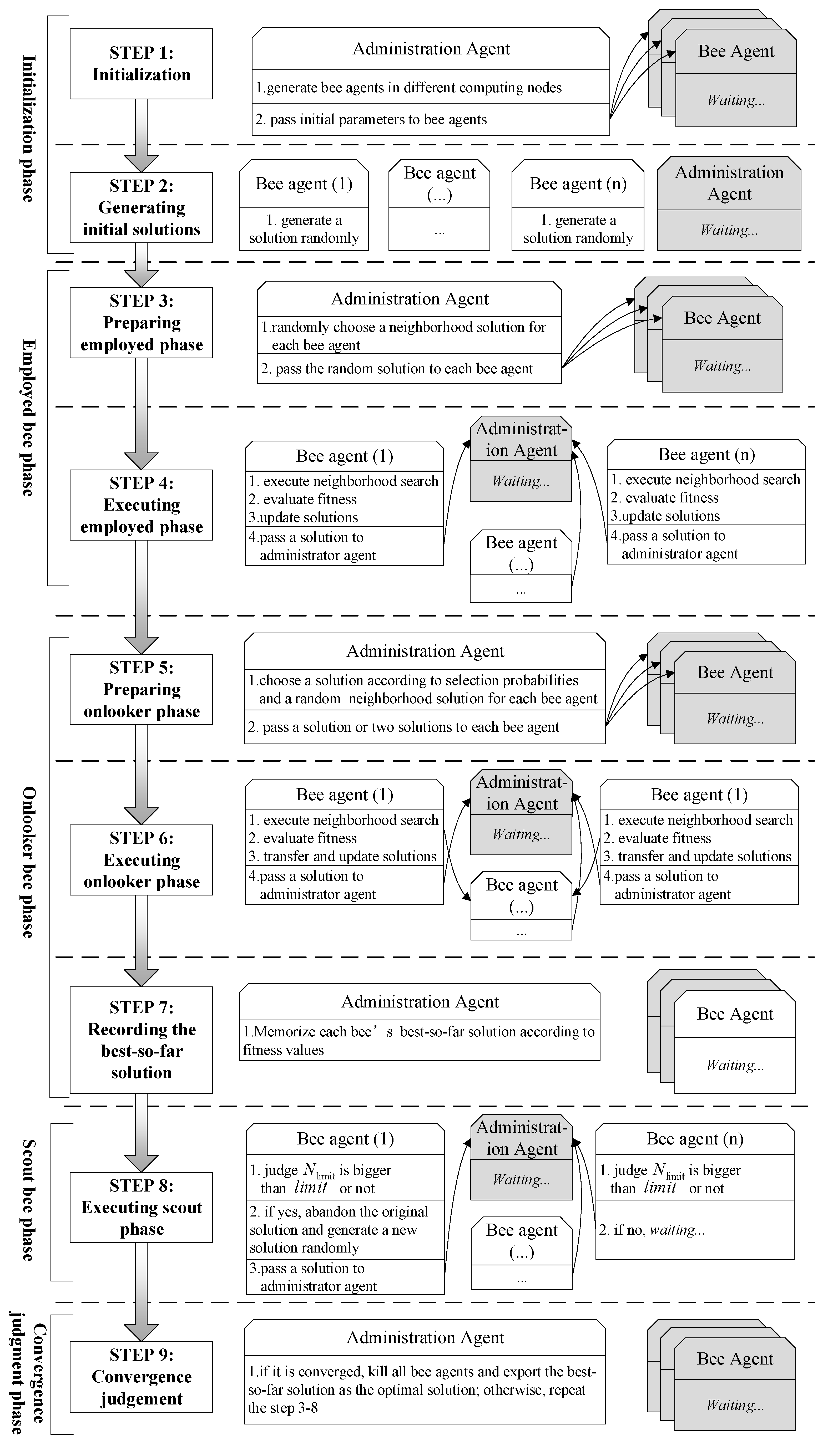
(1) Initialization phase
First, we launch an administration agent and set initial parameters, including MA-related data, such as the number of bee agents, the network address list of computing nodes that can participate in the parallel computation, and RS-optimization-related initial data, such as the number of clustering centers in the problem of hyperspectral image clustering.
Then, the administration agent will generate multiple bee agents in different computing nodes according to the parameters of the network address list and pass the RS-optimization-related initial parameters to each bee agent.
After receiving the initial parameters, each bee agent will generate a random solution.
(2) Employed bee phase
First, the administration agent will pass to each bee agent a random neighborhood solution through the network. Then, the
bee agent maintaining solution
with fitness
will receive the solution
as a neighborhood solution, where
is the dimension and
. The
bee agent then executes a neighborhood search to generate a new candidate solution
according to Equation (2)
where
is a random dimension index selected from the set
and
is a random number within
. For a minimal optimization problem, when a new solution
is generated, its fitness
will be calculated via Equation (3) after its objective function value
is obtained. Then, a greedy selection will be used to improve the fitness of the
bee agent’s solution. If
is better than the original solution’s fitness
, the solution will be replaced by the new one; otherwise, the parameter
. Later, the updated solution will be passed to the administrator agent through the network.
It should be noted that the objective function calculation is a problem-focused process. How the solution’s objective function value is calculated is irrelevant in the MA framework, since only its function value is needed to evaluate the fitness. However, the objective function calculation could be loosely coupled with the MA-based approach by providing each agent with the calculation interface.
(3) Onlooker bee phase
Once the administrator agent receives all bee agents’ fitness, a random selection probability for each bee agent will be calculated according to Equation (4).
where
is the selection probability of the
bee agent,
is the fitness value, and
is the bee agent number. The probability gives a solution with better fitness a greater chance of being selected by an onlooker bee than the solutions with worse fitness.
Then, the administrator agent will pass to each bee agent two solutions, and , where is obtained by roulette wheel selection according to the selection probabilities and is selected randomly. Later, each bee agent will execute a neighborhood search according to Equation (2) and calculate the new generated solution’s fitness via Equation (3). If the new solution’s fitness is worse than solution , then ; otherwise, the new generated solution will be transferred to the bee agent to replace the original solution. Finally, all bee agents’ solution will be transferred to the administrator agent to help it update each bee’s best-so-far solution.
To further improve the parallel computation of the entire framework, the employed and onlooker bee phases could be carried out simultaneously.
(4) Scout bee phase
After the onlooker bee phase, each bee agent will judge whether its parameter exceeds the value of a predefined number . If the parameter exceeds the value, the original solution is abandoned, and a new solution will be generated randomly.
(5) Convergence judgment phase
If the iteration meets the convergence condition, the administrator agent will kill all bee agents and export the best-so-far solution in its memory as the optimal solution. Otherwise, the employed bee, onlooker bee, and scout bee operations will be executed repeatedly.
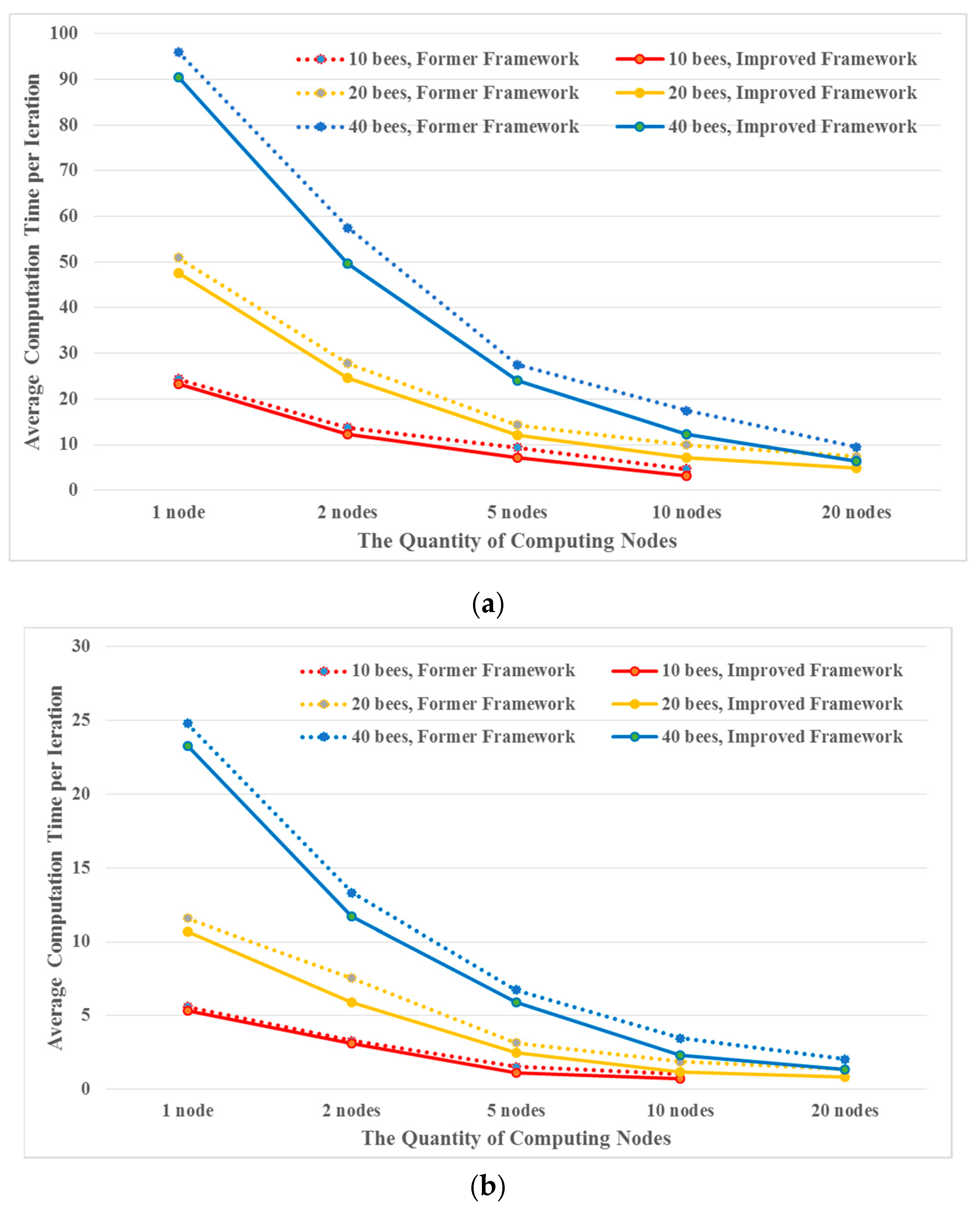
3.5. Comparison
In the MA-based ABC proposed in [
17], a food source agent is only responsible for a solution’s maintenance and a bee agent is only responsible for the neighborhood search (shown in
Figure 4a). Because a bee agent does not store a solution, whenever it executes a neighborhood search in the employed and onlooker bee phases, it has to solicit two solutions from two different food source agents through the network (shown as step 1 in
Figure 4a). Subsequently, the new generated solution should also be passed to its corresponding food source agent to update solutions (shown as step 3 in
Figure 4a). The frequent communications in the MA-based ABC reduce the computational performance.
In the improved MA-based ABC framework proposed in this paper, each agent exhibits both behaviors (solution maintenance and neighborhood search), and its neighborhood search can be directly executed on its maintenance solution, which means that only one neighbor solution has to be passed to an agent in all of the employed phases (shown in
Figure 4b) and parts of the onlooker bee phases (if one of the two randomly selected solutions for a bee happens to be maintained by the bee). Thus, the frequency of transferring solutions among agents will be effectively reduced, which is helpful for improving the efficiency of parallel computation.
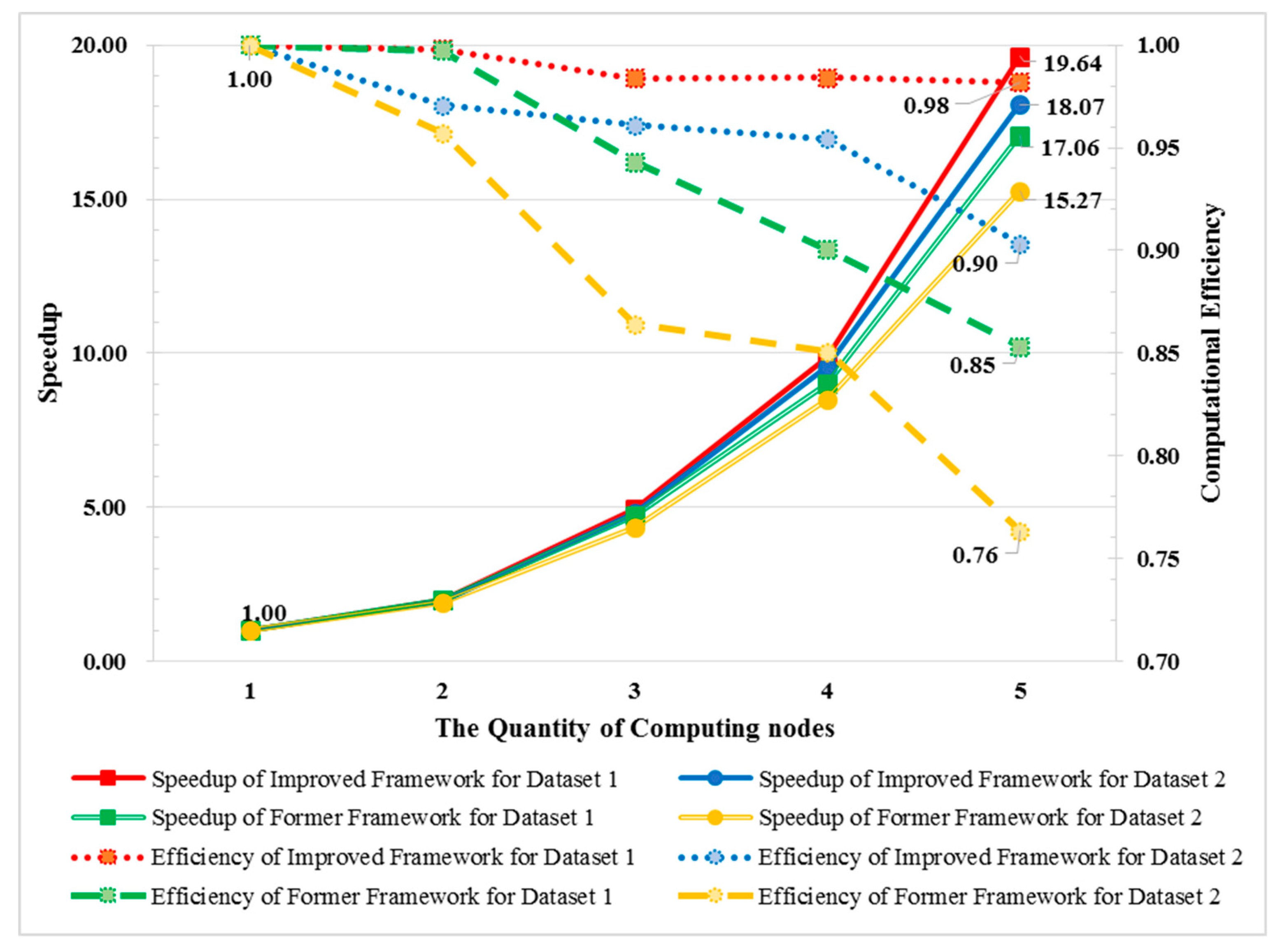
To quantitatively analyze the improvement, the number of transferred solutions among agents in one iteration can be listed as shown in
Table 2, which indicates that the improved framework proposed in this paper will spend less time on communication than the former framework [
17] does, thus achieving higher efficiency.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}