A High-Accuracy Indoor-Positioning Method with Automated RGB-D Image Database Construction

Abstract
1. Introduction
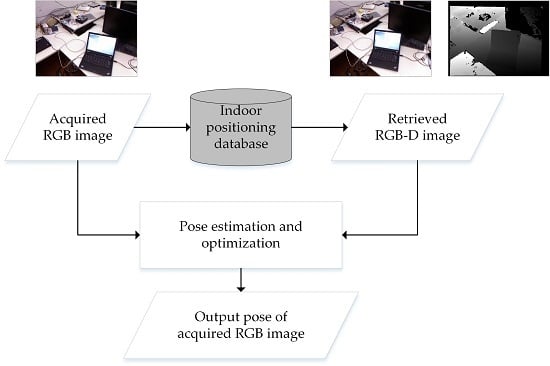
2. Methodology
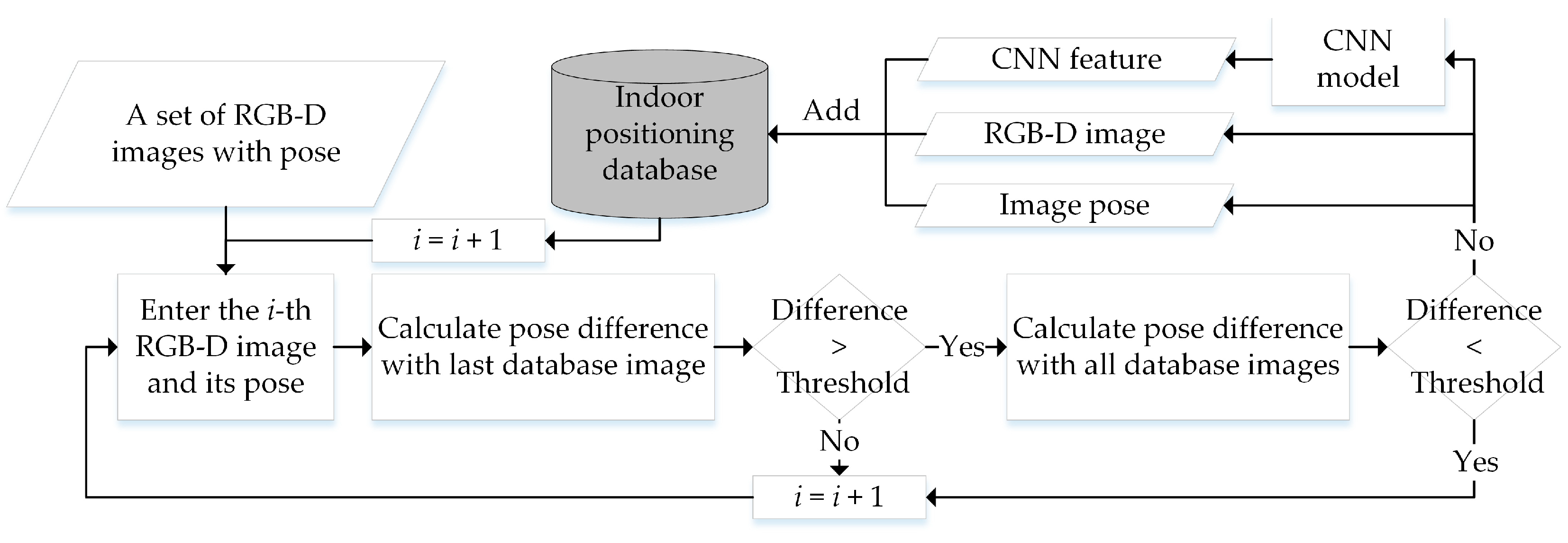
2.1. RGB-D Indoor-Positioning Database Construction
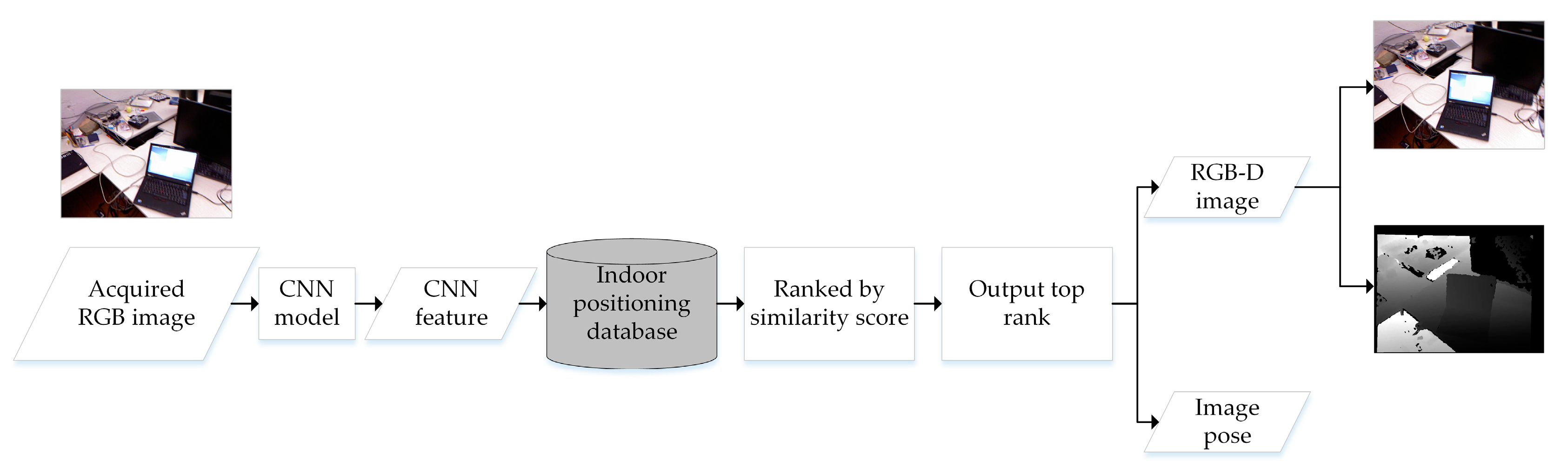
2.2. Image Retrieval Based on Convolutional Neural Network (CNN) Feature Vector
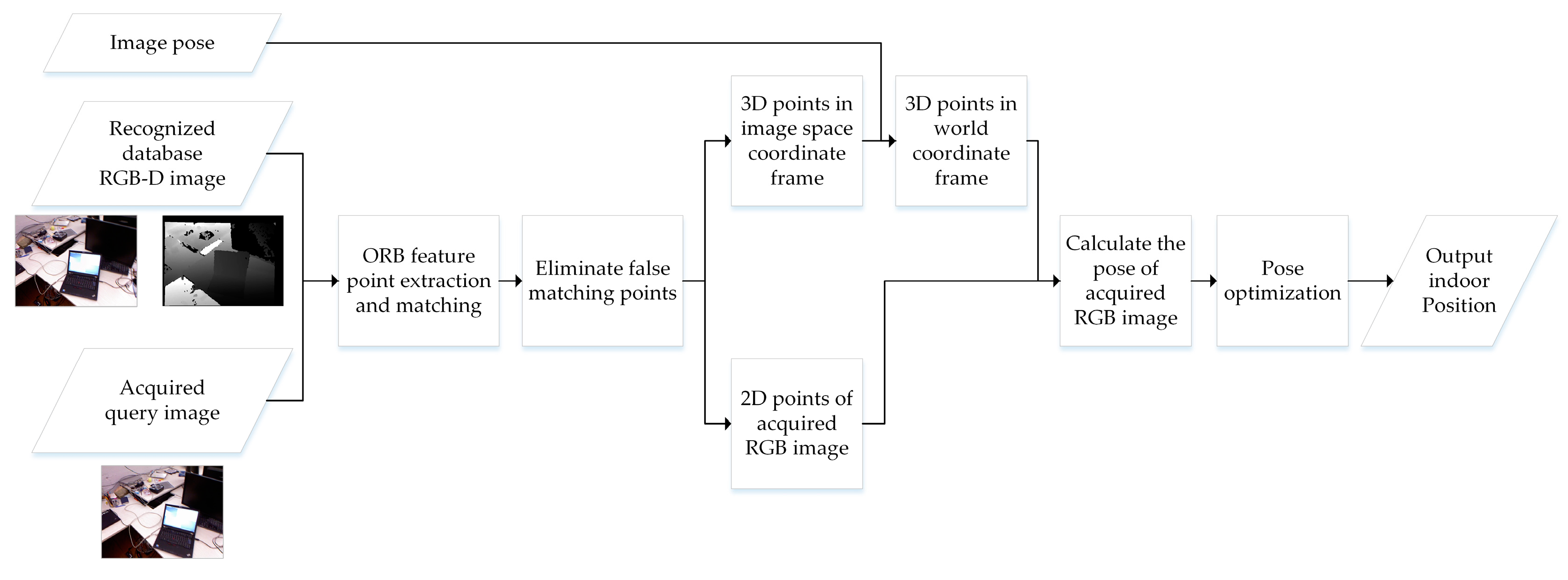
2.3. Position and Attitude Estimation
3. Experimental Results
3.1. Test Data and Computer Configuration
3.2. Results of RGB-D Database Construction
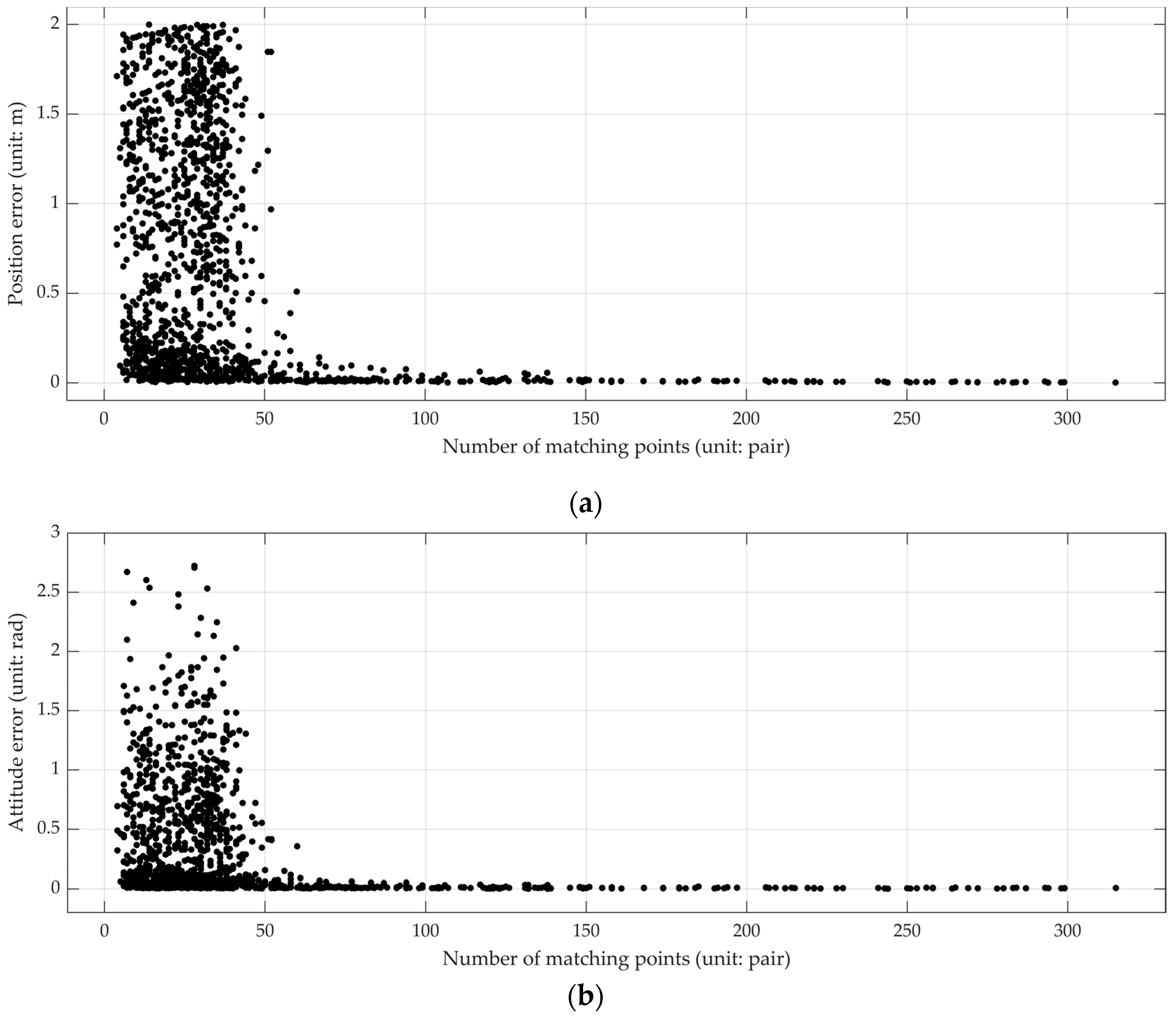
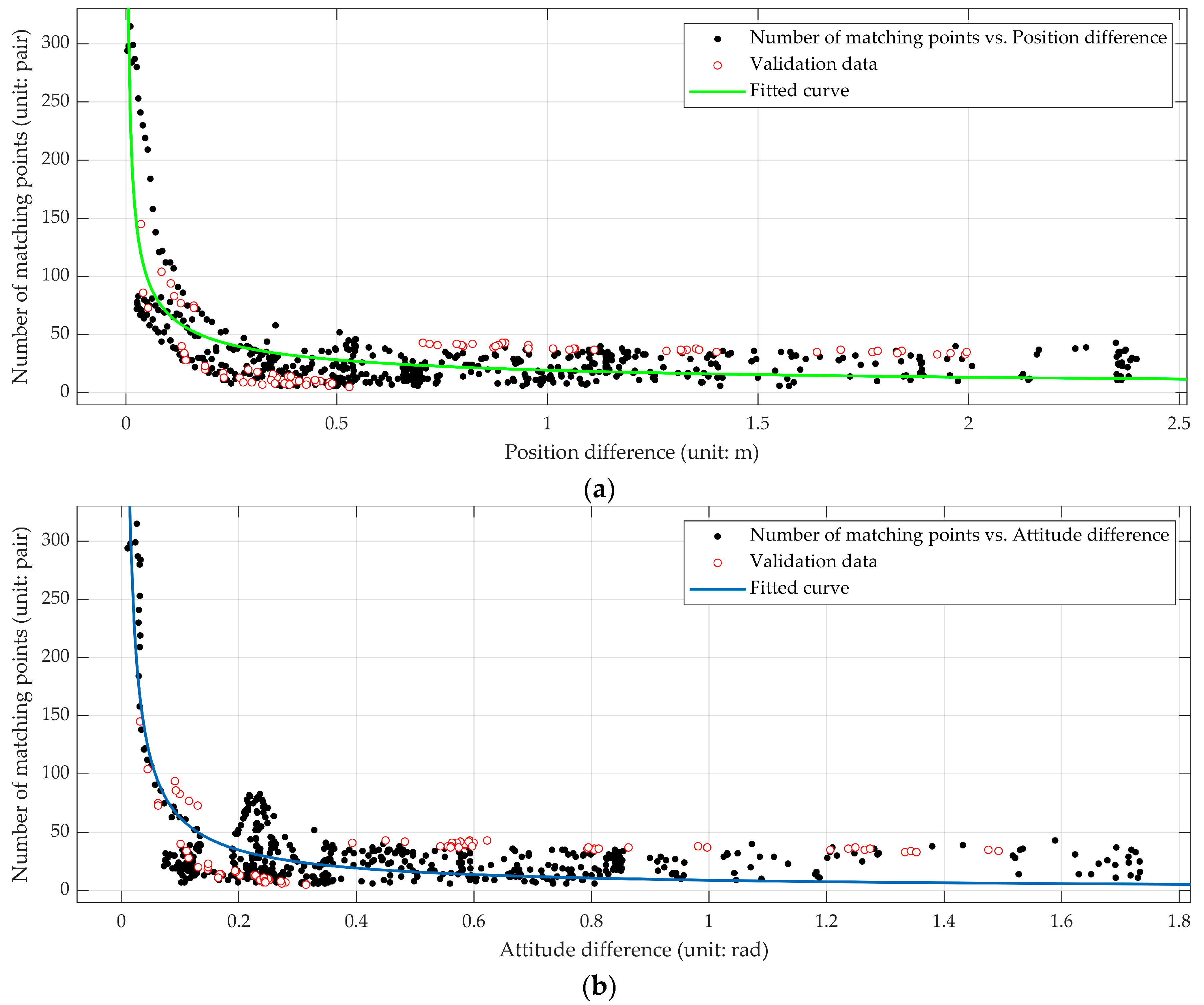
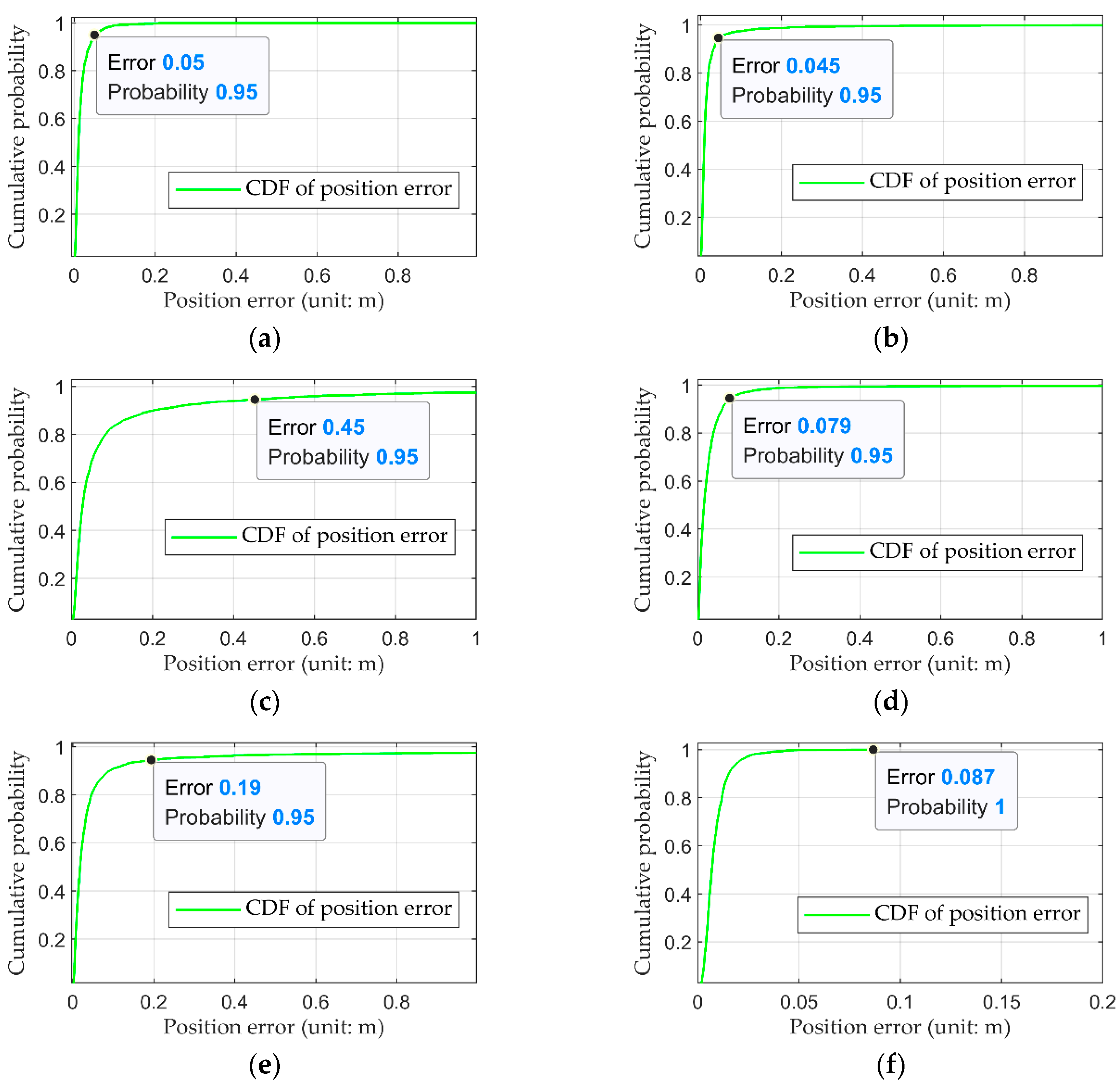
3.3. Quantitative Analysis of Positioning Accuracy
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| RGB-D | red, green, blue and depth |
| GNSS | Global Navigation Satellite System |
| SIFT | scale-invariant feature transform |
| PCA | principal component analysis |
| SAD | sum of absolute difference |
| DoFs | degrees of freedom |
| SLAM | simultaneous localization and mapping |
| CNN | convolutional neural networks |
| TUM | Technical University of Munich |
| RMSE | root mean square errors |
| NetVLAD | vector of locally aggregated descriptors |
| RANSAC | random sample consensus |
| EPnP | efficient perspective-n-point method |
| CDF | cumulative distribution function |
References
- Jiang, B.; Yao, X. Location-based services and GIS in perspective. Comput. Environ. Urban Syst. 2006, 30, 712–725. [Google Scholar] [CrossRef]
- Weiser, M. The computer for the 21st century. IEEE Pervasive Comput. 1999, 3, 3–11. [Google Scholar] [CrossRef]
- Davidson, P.; Piché, R. A survey of selected indoor positioning methods for smartphones. IEEE Commun. Surv. Tutor. 2017, 19, 1347–1370. [Google Scholar] [CrossRef]
- Atia, M.M.; Noureldin, A.; Korenberg, M.J. Dynamic Online-Calibrated Radio Maps for Indoor Positioning in Wireless Local Area Networks. IEEE Trans. Mob. Comput. 2013, 12, 1774–1787. [Google Scholar] [CrossRef]
- Du, Y.; Yang, D.; Xiu, C. A Novel Method for Constructing a WIFI Positioning System with Efficient Manpower. Sensors 2015, 15, 8358–8381. [Google Scholar] [CrossRef]
- Moghtadaiee, V.; Dempster, A.G.; Lim, S. Indoor localization using FM radio signals: A fingerprinting approach. In Proceedings of the 2011 International Conference on Indoor Positioning & Indoor Navigation (IPIN), Guimarães, Portugal, 21–23 September 2011; pp. 1–7. [Google Scholar]
- Bahl, P.; Padmanabhan, V.N. In RADAR: An in-building RF-based user location and tracking system. IEEE Infocom 2000, 2, 775–784. [Google Scholar]
- Youssef, M.; Agrawala, A. The Horus WLAN location determination system. In Proceedings of the 3rd International Conference on Mobile Systems, Application, and Services (MobiSys 2005), Seattle, WA, USA, 6–8 June 2005; pp. 205–218. [Google Scholar]
- Cantón Paterna, V.; Calveras Augé, A.; Paradells Aspas, J.; Pérez Bullones, M.A. A Bluetooth Low Energy Indoor Positioning System with Channel Diversity, Weighted Trilateration and Kalman Filtering. Sensors 2017, 17, 2927. [Google Scholar] [CrossRef]
- Chen, L.; Pei, L.; Kuusniemi, H.; Chen, Y.; Kröger, T.; Chen, R. Bayesian Fusion for Indoor Positioning Using Bluetooth Fingerprints. Wirel. Pers. Commun. 2013, 70, 1735–1745. [Google Scholar] [CrossRef]
- Huang, X.; Guo, S.; Wu, Y.; Yang, Y. A fine-grained indoor fingerprinting localization based on magnetic field strength and channel state information. Pervasive Mob. Comput. 2017, 41, 150–165. [Google Scholar] [CrossRef]
- Kim, H.-S.; Seo, W.; Baek, K.-R. Indoor Positioning System Using Magnetic Field Map Navigation and an Encoder System. Sensors 2017, 17, 651. [Google Scholar] [CrossRef]
- Gronat, P.; Obozinski, G.; Sivic, J.; Pajdla, T. Learning and Calibrating Per-Location Classifiers for Visual Place Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 907–914. [Google Scholar]
- Vaca-Castano, G.; Zamir, A.R.; Shah, M. City scale geo-spatial trajectory estimation of a moving camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1186–1193. [Google Scholar]
- Arandjelović, R.; Zisserman, A. Three things everyone should know to improve pbject retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2911–2918. [Google Scholar]
- Zamir, A.R.; Shah, M. Accurate Image Localization Based on Google Maps Street View. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 255–268. [Google Scholar]
- Zamir, A.R.; Shah, M. Image Geo-Localization Based on MultipleNearest Neighbor Feature Matching UsingGeneralized Graphs. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1546–1558. [Google Scholar] [CrossRef] [PubMed]
- Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural Codes for Image Retrieval. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 584–599. [Google Scholar]
- Azzi, C.; Asmar, D.; Fakih, A.; Zelek, J. Filtering 3D keypoints using GIST for accurate image-based positioning. In Proceedings of the 27th British Machine Vision Conference, York, UK, 19–22 September 2016; pp. 1–12. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Hervé, J.; Douze, M.; Schmid, C. Product Quantization for Nearest Neighbor Search. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 117–128. [Google Scholar]
- Nistér, D.; Stewénius, H. Scalable Recognition with a Vocabulary Tree. In Proceedings of the Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2161–2168. [Google Scholar]
- Kim, H.J.; Dunn, E.; Frahm, J.M. Predicting Good Features for Image Geo-Localization Using Per-Bundle VLAD. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1170–1178. [Google Scholar]
- Torii, A.; Arandjelovic, R.; Sivic, J.; Okutomi, M.; Pajdla, T. 24/7 place recognition by view synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1808–1817. [Google Scholar]
- Milford, M.J.; Lowry, S.; Shirazi, S.; Pepperell, E.; Shen, C.; Lin, G.; Liu, F.; Cadena, C.; Reid, I. Sequence searching with deep-learnt depth for condition-and viewpoint-invariant route-based place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 18–25. [Google Scholar]
- Poglitsch, C.; Arth, C.; Schmalstieg, D.; Ventura, J. A Particle Filter Approach to Outdoor Localization Using Image-Based Rendering. In Proceedings of the IEEE International Symposium on Mixed & Augmented Reality, Fukuoka, Japan, 29 September–3 October 2015; pp. 132–135. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern RecognitionWorkshops, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar]
- Yandex, A.B.; Lempitsky, V. Aggregating Local Deep Convolutional Features for Image Retrieval. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1269–1277. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Younes, G.; Asmar, D.; Shammas, E.; Zelek, J. Keyframe-based monocular SLAM: Design, survey, and future directions. Robot. Auton. Syst. 2017, 98, 67–88. [Google Scholar] [CrossRef]
- Campbell, D.; Petersson, L.; Kneip, L.; Li, H. Globally-optimal inlier set maximisation for simultaneous camera pose and feature correspondence. In Proceedings of the IEEE Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1–10. [Google Scholar]
- Liu, L.; Li, H.; Dai, Y. Efficient Global 2D-3D Matching for Camera Localization in a Large-Scale 3D Map. In Proceedings of the IEEE Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2391–2400. [Google Scholar]
- Yousif, K.; Taguchi, Y.; Ramalingam, S. MonoRGBD-SLAM: Simultaneous localization and mapping using both monocular and RGBD cameras. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4495–4502. [Google Scholar]
- Turan, M.; Almalioglu, Y.; Araujo, H.; Konukoglu, E.; Sitti, M. A non-rigid map fusion-based rgb-depth slam method for endoscopic capsule robots. Int. J. Intell. Robot. Appl. 2017, 1, 399. [Google Scholar] [CrossRef]
- Sattler, T.; Torii, A.; Sivic, J.; Pollefeys, M.; Taira, H.; Okutomi, M.; Pajdla, T. Are Large-Scale 3D Models Really Necessary for Accurate Visual Localization? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6175–6184. [Google Scholar]
- Degol, J.; Bretl, T.; Hoiem, D. ChromaTag: A Colored Marker and Fast Detection Algorithm. In Proceedings of the IEEE Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1481–1490. [Google Scholar]
- Muñoz-Salinas, R.; Marín-Jimenez, M.J.; Yeguas-Bolivar, E.; Medina-Carnicer, R. Mapping and Localization from Planar Markers. Pattern Recognit. 2017, 73, 158–171. [Google Scholar] [CrossRef]
- Schweighofer, G.; Pinz, A. Robust pose estimation from a planar target. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 28, 2024–2030. [Google Scholar] [CrossRef]
- Valentin, J.; Niebner, M.; Shotton, J.; Fitzgibbon, A.; Izadi, S.; Torr, P. Exploiting uncertainty in regression forests for accurate camera relocalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4400–4408. [Google Scholar]
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. CNN-SLAM: Real-Time Dense Monocular SLAM with Learned Depth Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6565–6574. [Google Scholar]
- Shotton, J.; Glocker, B.; Zach, C.; Izadi, S.; Criminisi, A.; Fitzgibbon, A. Scene Coordinate Regression Forests for Camera Relocalization in RGB-D Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2930–2937. [Google Scholar]
- Kendall, A.; Cipolla, R. Geometric loss functions for camera pose regression with deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6555–6564. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-Time Seamless Single Shot 6D Object Pose Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 292–301. [Google Scholar]
- Piasco, N.; Sidibé, D.; Demonceaux, C.; Gouet-Brunet, V. A survey on Visual-Based Localization: On the benefit of heterogeneous data. Pattern Recognit. 2018, 74, 90–109. [Google Scholar] [CrossRef]
- Ummenhofer, B.; Zhou, H.; Uhrig, J.; Mayer, N.; Ilg, E.; Dosovitskiy, A.; Brox, T. DeMoN: Depth and motion network for learning monocular stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5622–5631. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5667–5675. [Google Scholar]
- Zhan, H.; Garg, R.; Weerasekera, C.S.; Li, K.; Agarwal, H.; Reid, I. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 340–349. [Google Scholar]
- Gao, X.; Zhang, T. Unsupervised learning to detect loops using deep neural networks for visual SLAM system. Auton. Robot. 2017, 41, 1–18. [Google Scholar] [CrossRef]
- Wu, J.; Ma, L.; Hu, X. Delving deeper into convolutional neural networks for camera relocalization. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 5644–5651. [Google Scholar]
- Chen, Y.; Chen, R.; Liu, M.; Xiao, A.; Wu, D.; Zhao, S. Indoor Visual Positioning Aided by CNN-Based Image Retrieval: Training-Free, 3D Modeling-Free. Sensors 2018, 18, 2692. [Google Scholar] [CrossRef] [PubMed]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. Netvlad: CNN architecture for weakly supervised place recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1437–1451. [Google Scholar] [CrossRef] [PubMed]
- Richard, H.; Andrew, Z. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2003; pp. 241–253. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. Acm 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An accurate O(n) solution to the PnP problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. G2o: A general framework for graph optimization. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fitted Curves | RMSE of Fit | RMSE of Validation |
|---|---|---|
| Figure 3a | 23.73 | 21.88 |
| Figure 3b | 23.96 | 24.08 |
| Six Sequences of TUM RGB-D Dataset | The Number of Test RGB-D Images |
|---|---|
| freiburg1_plant | 1126 |
| freiburg1_room | 1352 |
| freiburg2_360_hemisphere | 2244 |
| freiburg2_flowerbouquet | 2851 |
| freiburg2_pioneer_slam3 | 2238 |
| freiburg3_long_office_household | 2488 |
| Six Sequences of TUM RGB-D Dataset | Images in the Reference Method | Images in the Proposed Method | ||
|---|---|---|---|---|
| Database | Query | Database | Query | |
| freiburg1_plant | 115 | 456 | 158 | 968 |
| freiburg1_room | 91 | 454 | 193 | 1159 |
| freiburg2_360_hemisphere | 273 | 1092 | 253 | 1991 |
| freiburg2_flowerbouquet | 149 | 1188 | 104 | 2747 |
| freiburg2_pioneer_slam3 | 128 | 1017 | 173 | 2065 |
| freiburg3_long_office_household | 130 | 1034 | 152 | 2336 |
| Six Sequences of TUM RGB-D Dataset | Pose Error of the Reference Method | Pose Error of the Proposed Method | ||
|---|---|---|---|---|
| Mean | Median | Mean | Median | |
| freiburg1_plant | 0.38 m 3.37° | 0.12 m 0.01° | 0.02 m 0.61° | 0.01 m 0.44° |
| freiburg1_room | 0.43 m 4.82° | 0.17 m 0.54° | 0.02 m 1.14° | 0.01 m 0.50° |
| freiburg2_360_hemisphere | 0.38 m 6.55° | 0.05 m 0.16° | 0.22 m 2.77° | 0.03 m 0.36° |
| freiburg2_flowerbouquet | 0.15 m 5.32° | 0.07 m 0.12° | 0.04 m 1.57° | 0.02 m 0.51° |
| freiburg2_pioneer_slam3 | 0.34 m 8.80° | 0.13 m 0.13° | 0.18 m 4.10° | 0.02 m 0.43° |
| freiburg3_long_office_household | 0.36 m 3.00° | 0.15 m 0.21° | 0.01 m 0.37° | 0.01 m 0.31° |
| Six Sequences of TUM RGB-D Dataset | 90% Accuracy of the Reference Method | 90% Accuracy of the Proposed Method |
|---|---|---|
| freiburg1_plant | 0.45 m 1.95° | 0.04 m 1.09° |
| freiburg1_room | 0.71 m 4.04° | 0.03 m 1.29° |
| freiburg2_360_hemisphere | 0.38 m 1.08° | 0.21 m 1.94° |
| freiburg2_flowerbouquet | 0.26 m 2.54° | 0.06 m 2.76° |
| freiburg2_pioneer_slam3 | 0.66 m 1.54° | 0.10 m 2.75° |
| freiburg3_long_office_household | 0.41 m 2.05° | 0.02 m 0.65° |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Wan, W.; Di, K.; Chen, R.; Feng, X. A High-Accuracy Indoor-Positioning Method with Automated RGB-D Image Database Construction. Remote Sens. 2019, 11, 2572. https://doi.org/10.3390/rs11212572
Wang R, Wan W, Di K, Chen R, Feng X. A High-Accuracy Indoor-Positioning Method with Automated RGB-D Image Database Construction. Remote Sensing. 2019; 11(21):2572. https://doi.org/10.3390/rs11212572
Chicago/Turabian StyleWang, Runzhi, Wenhui Wan, Kaichang Di, Ruilin Chen, and Xiaoxue Feng. 2019. "A High-Accuracy Indoor-Positioning Method with Automated RGB-D Image Database Construction" Remote Sensing 11, no. 21: 2572. https://doi.org/10.3390/rs11212572
APA StyleWang, R., Wan, W., Di, K., Chen, R., & Feng, X. (2019). A High-Accuracy Indoor-Positioning Method with Automated RGB-D Image Database Construction. Remote Sensing, 11(21), 2572. https://doi.org/10.3390/rs11212572