1. Introduction
It is a fundamental problem in Earth Vision to achieve accurate and robust object detection in aerial images, which is very challenging due to four issues:
arbitrary orientations: unlike natural images in which objects are generally oriented upward, objects in aerial images often appear with arbitrary orientations since aerial images are typically taken with a bird’s-eye view [
1,
2].
densely packed objects: it is hard to separate small crowded objects like vehicles in parking lots [
3].
huge scale variations: scale changes of objects in aerial images captured with various platforms and sensors are usually huge [
2,
4].
cluttered background: the background in aerial images is cluttered and normally contains a large number of uninteresting objects [
5].
To tackle these issues, we need a robust object detection method for aerial images which is resilient to the aforementioned appearance variations.
With the development of deep learning technology, modern generic object detection methods based on a horizontal bounding box (HBB) have achieved great success in natural scenes. They can be organized into two main categories: two-stage and single-stage detectors. Two-stage detectors are firstly introduced by a Region-based Convolutional Neural Network (R-CNN) [
6]. R-CNN generates object proposals by Selective Search [
7], then classifies and refines the proposal regions by a Convolutional Neural Network (CNN). To eliminate the duplicated computation in the R-CNN, Fast R-CNN [
8] extracts the feature of the whole image once, then generates region features through Region of Interest (RoI) Pooling. Faster R-CNN [
9] introduces a Region Proposal Network (RPN) to generate the region proposals efficiently. Some researchers further extend the work of Faster R-CNN for better performance, like Region-based Fully Convolutional Network (R-FCN) [
10], Deformable R-FCN [
11], Light Head R-CNN [
12], Scale Normalization for Image Pyramids (SNIP) [
13], SNIP with Efficient Resampling (SNIPER) [
14], etc. Unlike two-stage detectors, single-stage detectors directly estimate class probabilities and bounding box offsets with a single CNN like You Only Look Once (YOLO) [
15,
16,
17], Single Shot Multibox Detector (SSD) [
18] and RetinaNet [
19]. Compared with two-stage detectors, one-stage detectors are much simpler and more efficient, because there is no need to produce region proposals.
Similarly, object detection methods based on HBB are widely used for object detection in aerial images. Han et al. [
20] propose R-P-Faster R-CNN for detecting small objects in aerial images. Xu et al. [
21] use Deformable Convolutional Network (DCN) [
11] to address geometric modeling in aerial image object detection and propose a Ratio Constrained Non Maximum Suppression (arcNMS) to reduce the increase of false region proposals. Guo et al. [
22] propose a multi-scale CNN and multi-scale object proposal network for geospatial object detection in high resolution satellite images. Li et al. [
23] propose a hierarchical selective filtering network (HSF-Net) to detect ships with various scales efficiently. Pang et al. [
24] design a Tiny-Net backbone and a global attention block to detect tiny objects in large-scale aerial images. Dong et al. [
25] propose the Sig-NMS to replace traditional NMS for improving the detection accuracy of small objects. These methods greatly promote the development of object detection in the remote sensing field.
However, the HBBs are not suitable for describing objects in aerial images since the objects in aerial images are often of arbitrary orientations. To deal with this challenge, instead of using HBB, some datasets [
2,
26,
27,
28,
29] use oriented bounding boxes (OBBs) to annotate objects in aerial images. OBBs can not only compactly enclose oriented objects, but also retain the orientation information which is very useful for further processing. Many works [
1,
2,
30,
31,
32] handle this problem as a regression task and directly regress oriented bounding boxes. We call them regression-based methods. For instance, DRBox [
33] redesigns the SSD [
18] to regress oriented bounding boxes by multi-angle prior oriented bounding boxes. Xia et al. [
2] propose the FR-O which regresses the offsets of OBBs relative to HBBs. ICN [
30] joints image cascade and feature pyramid network to extract features for regressing the offsets of OBBs relative to HBBs. Ma et al. [
34] design a Rotation Region Proposal Network (RRPN) to generate prior proposals with the object orientation information, and then regress the offsets of OBBs relative to oriented proposals. R-DFPN [
35] adopts RRPN and puts forward the Dense Feature Pyramid Network to solve the narrow width problems of ships. Ding et al. [
1] design a rotated RoI learner to transform horizontal RoIs to oriented RoIs by a supervised method. All these regression-based methods can be summarized as the problem of regression for the offsets of OBBs relative to HBBs or OBBs, and they rely on the accurate representation of OBB.
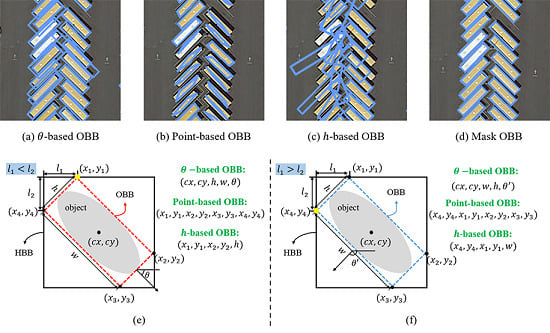
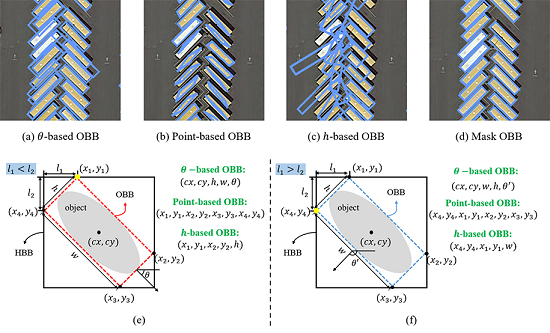
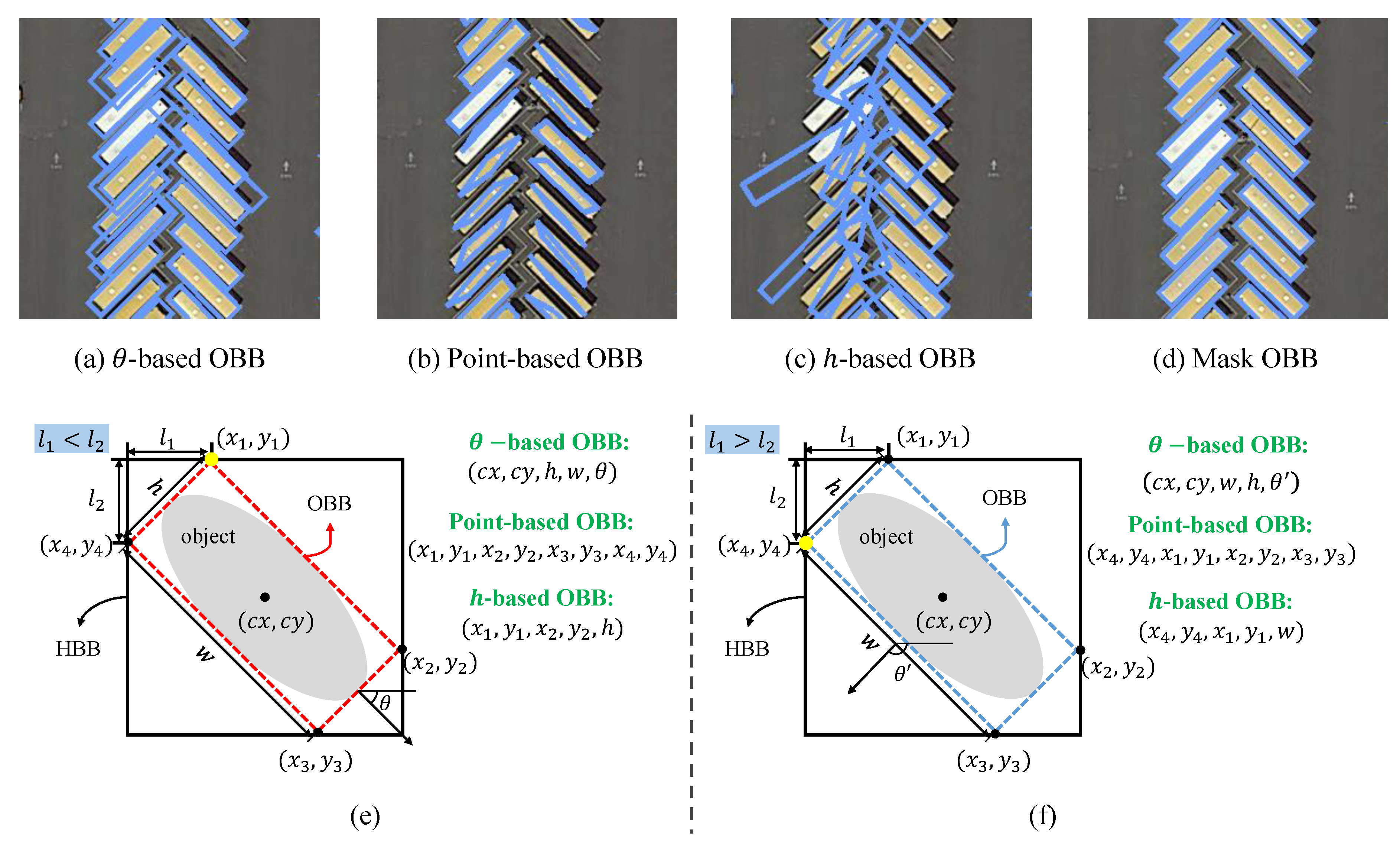
Nevertheless, regression-based methods encounter the problem of ambiguity in the regression target. For example, OBB represented as
(point-based OBB) has 4 different representation ways if we just change the order of vertexes. In order to get the uniqueness of OBB representation, some tricks, such as defining the first vertex by a certain rule [
2], are used to leverage the ambiguity problem. The ambiguity is still unsolved, because two similar region features may have obvious different OBB representations. For instance,
Figure 1e,f show the ambiguity problem of regression-based OBB intuitively. When the angle of OBB is near
or
, the ambiguity of adjacent points is the most serious. Specifically, by the definition in [
2], OBB in
Figure 1e can be represented as
(point-based OBB), but in
Figure 1f which is very similar with
Figure 1e, the OBB needs to be represented as
(point-based OBB). Although OBBs (
-based OBBs, point-based OBBs, and
h-based OBBs) in
Figure 1e,f are completely different, but they have similar feature map. Due to the ambiguity, the training is hard to converge, and the mAP of the HBB task is often much higher than OBB task even with the same backbone network. In this paper, we give an experimental analysis of different regression-based methods.
Figure 1a–c are the visualization results of different regression-based OBB representations, and we can see that the detection results are terrible when the angles of objects are near
or
.
In order to eliminate the ambiguity, we represent an object region as a binary segmentation map and treat the problem of detecting an oriented object as pixel-level classification for each proposal in this paper. Then, the oriented bounding boxes are generated from the predicted masks by post-processing, and we call this kind of OBB representation a mask-oriented bounding box representation (Mask OBB). By using Mask OBB, the convergence is faster and the gap of mAP between HBB task and OBB task is greatly reduced while compared with regression-based methods. As shown in
Figure 1d, detection results of Mask OBB are better than regression-based OBB representation methods. Despite its relevance, segmentation-based oriented object detection methods in remote sensing have been poorly exploited when compared with regression-based methods. There are just some segmentation-based methods in the field of oriented text detection. For instance, Ref [
36] presents Fused Text Segmentation Networks to detect and segment the text instance simultaneously. Ref [
37] finishes the detection and recognition task on mask branch by predicting word segmentation maps. These segmentation-based methods are restricted to single-category (text) object detection while there are many different categories to discern for aerial images, such as the dataset DOTA [
2]. Our proposed segmentation-based method Mask OBB can handle multi-category-oriented object detection in aerial images. It is based on an instance segmentation framework Mask R-CNN [
38] which is proposed by adding a mask branch on Faster R-CNN to obtain pixel-level segmentation predictions. To the best of our knowledge, this work is the first multi-category segmentation-based oriented object detection method in the remote sensing field.
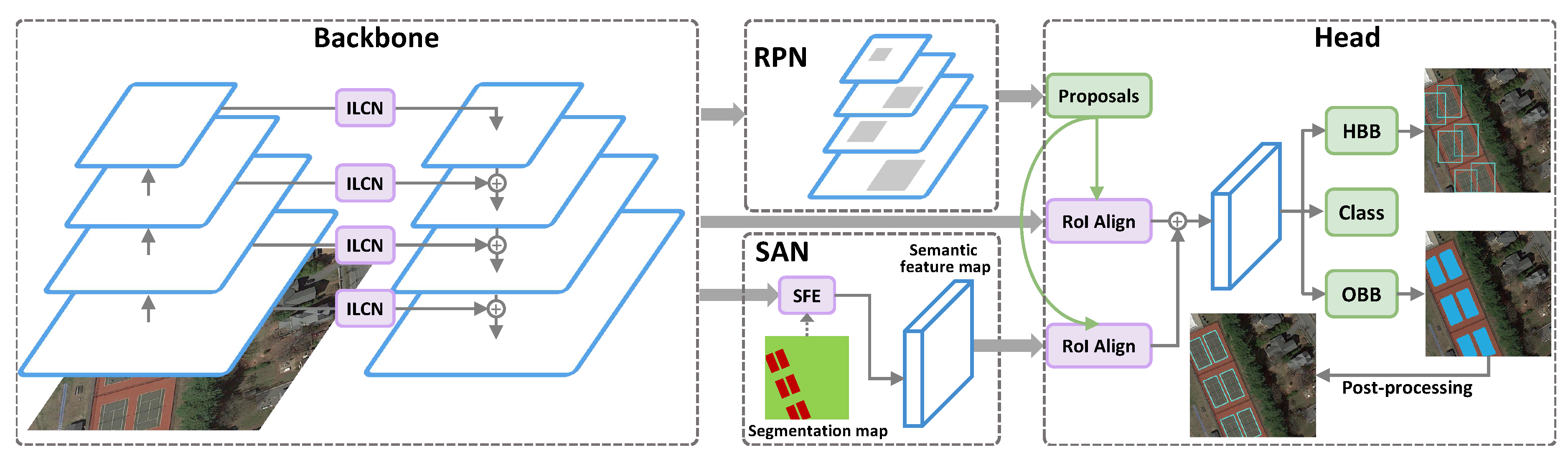
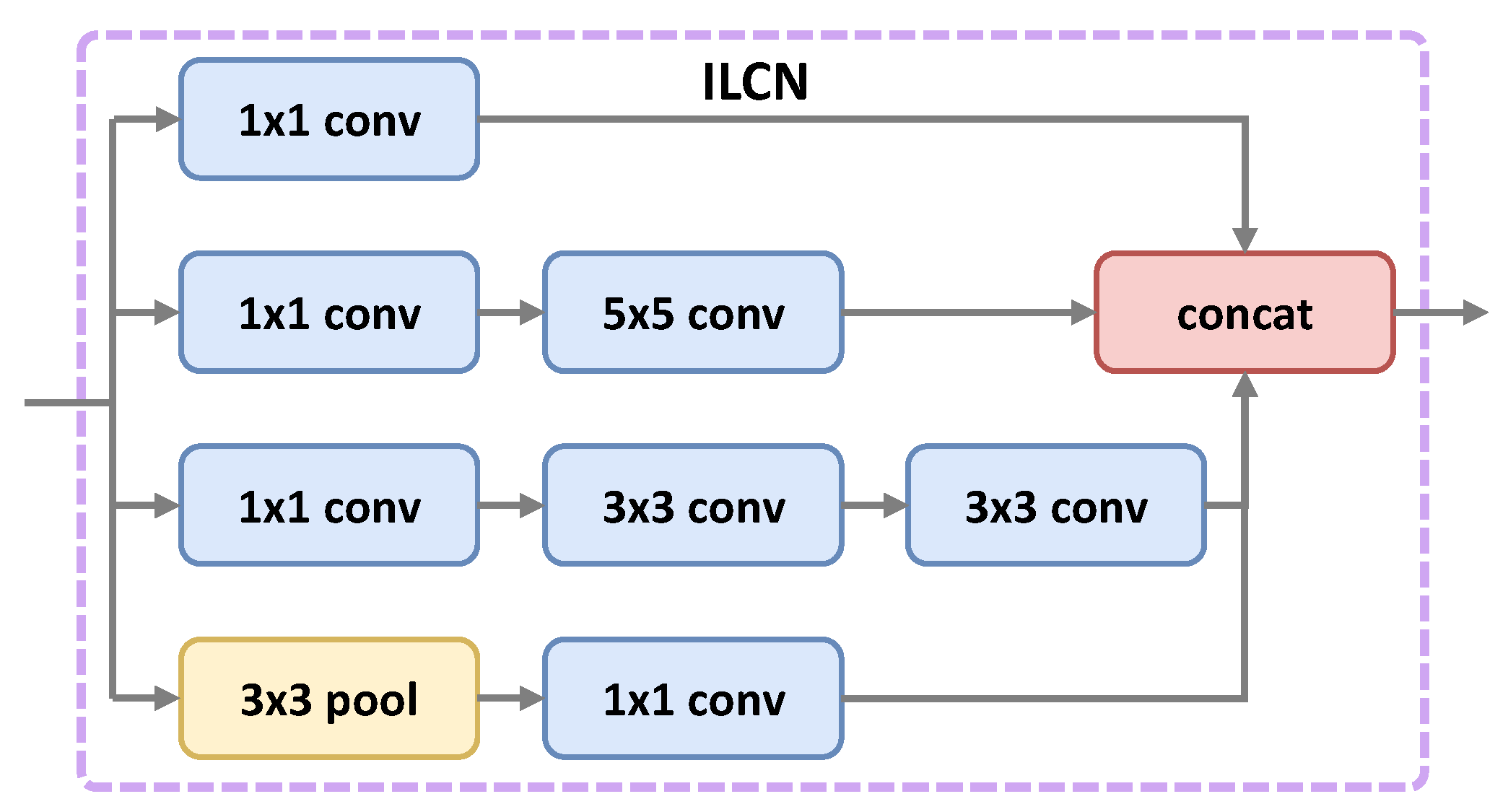
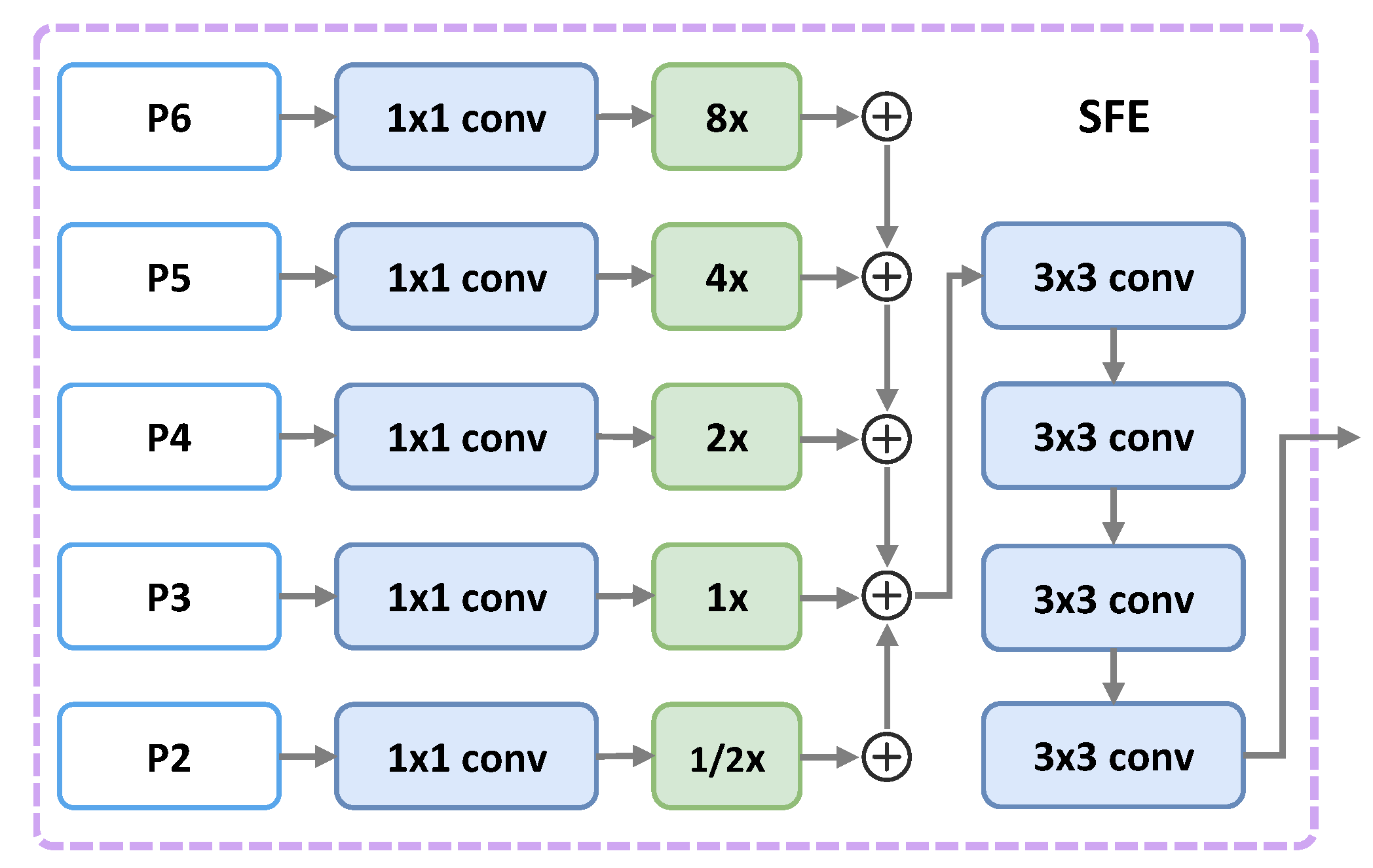
Besides the arbitrary orientation problem, huge scale changes of objects in aerial images is also a challenging problem. Some works [
30,
32,
35] use a Feature Pyramid Network (FPN) [
39] to handle the scale problem by fusing low-level and high-level features. In this paper, we design an Inception Lateral Connection Network (ILCN) to further enhance the FPN for solving the scale change problem. Unlike the original FPN, we use the inception structure [
40,
41,
42,
43] instead of one
convolutional layer as the lateral connection. In the ILCN, besides the original
convolutional layer, three additional layers with different receptive fields are added. We call this enhanced FPN an Inception Lateral Connection Feature Pyramid Network (ILC-FPN). Experimental results show ILC-FPN can handle large-scale variations in aerial images efficiently.
In addition, in aerial images, the background is cluttered and normally contains a large number of uninteresting objects. For distinguishing interesting objects from cluttered background, attention mechanism which is proven to be promising in many vision applications, such as image classification [
44,
45,
46] and general object detection [
47,
48] is used in some aerial image object detection works [
49,
50,
51]. Specifically, inspired by [
45,
49,
52] proposes a Feature Attention FPN (FA-FPN) which contains channel-wise attention and pixel-wise attention to effectively capture the foreground information and restrain the background in aerial images. CAD-Net [
50] designs a spatial-and-scale-aware attention module to guide the network to focus on more informative regions and features as well as more appropriate feature scales in aerial images. Chen et al. [
51] proposes a multi-scale spatial and channel-wise attention (MSCA) mechanism to make the network pay more attention to object in aerial images as human vision. Unlike the aforementioned attention modules which are unsupervised, we use the semantic segmentation map converted from oriented bounding boxes as the target of semantic segmentation network and design a Semantic Attention Network (SAN) to learn semantic features for predicting HBBs and OBBs efficiently.
Overall, our complete model can achieve and mAP on OBB task and HBB task of DOTA dataset, respectively. At the same time, it achieves mAP on OBB task of HRSC2016 dataset. The main contributions of this paper can be summarized as follows:
We address the influence of ambiguity of regression-based OBB representation methods for oriented bounding box detection, and propose a mask-oriented bounding box representation (Mask OBB). As far as we know, we are the first to treat the multi-category oriented object detection in aerial images as a problem of pixel-level classification. Extensive experiments demonstrate its state-of-the-art performance on both DOTA and HRSC2016 datasets.
We propose an Inception Lateral Connection Feature Pyramid Network (ILC-FPN), which can provide better features to handle huge scale changes of objects in aerial images.
We design a Semantic Attention Network (SAN) to distinguish interesting objects from cluttered background by providing semantic features when predicting HBBs and OBBs.
The rest of the paper is organized as follows:
Section 2 presents the proposed method, including Mask OBB, ILC-FPN, SAN, and overall network architecture. Then we give the experimental results in
Section 3. Finally, we discuss the model settings in
Section 4 and draw the conclusions in
Section 5.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}