A Point-Wise LiDAR and Image Multimodal Fusion Network (PMNet) for Aerial Point Cloud 3D Semantic Segmentation


Abstract

1. Introduction
2. Related Works
2.1. Image and Digital Elevation Data Fusion for 2D Segmentation Approaches
2.2. 3D Point Cloud Segmentation Approaches
- We design an end-to-end deep neural network architecture for LiDAR point cloud and 2D image point-wise feature fusion, which is suitable for directly consuming unordered point cloud.
- To the best of our knowledge, this is the first approach to use multimodal fusion network for aerial point cloud 3D segmentation which well respects the permutation invariance of point cloud.
- PMNet has an advantage over 2D based models that it can incorporate multi-view 3D scanned data if available.
- The study also evaluated the robustness of multimodality fusion by using fusion layer feature activation maps.
- Study introduced a dataset collected from Osaka, Japan region for urban 3D/2D segmentation with detailed class labels.
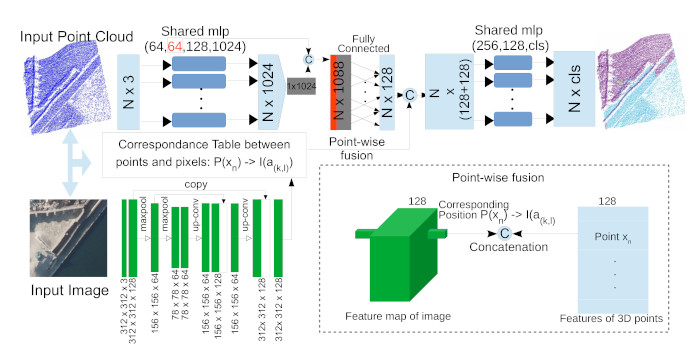
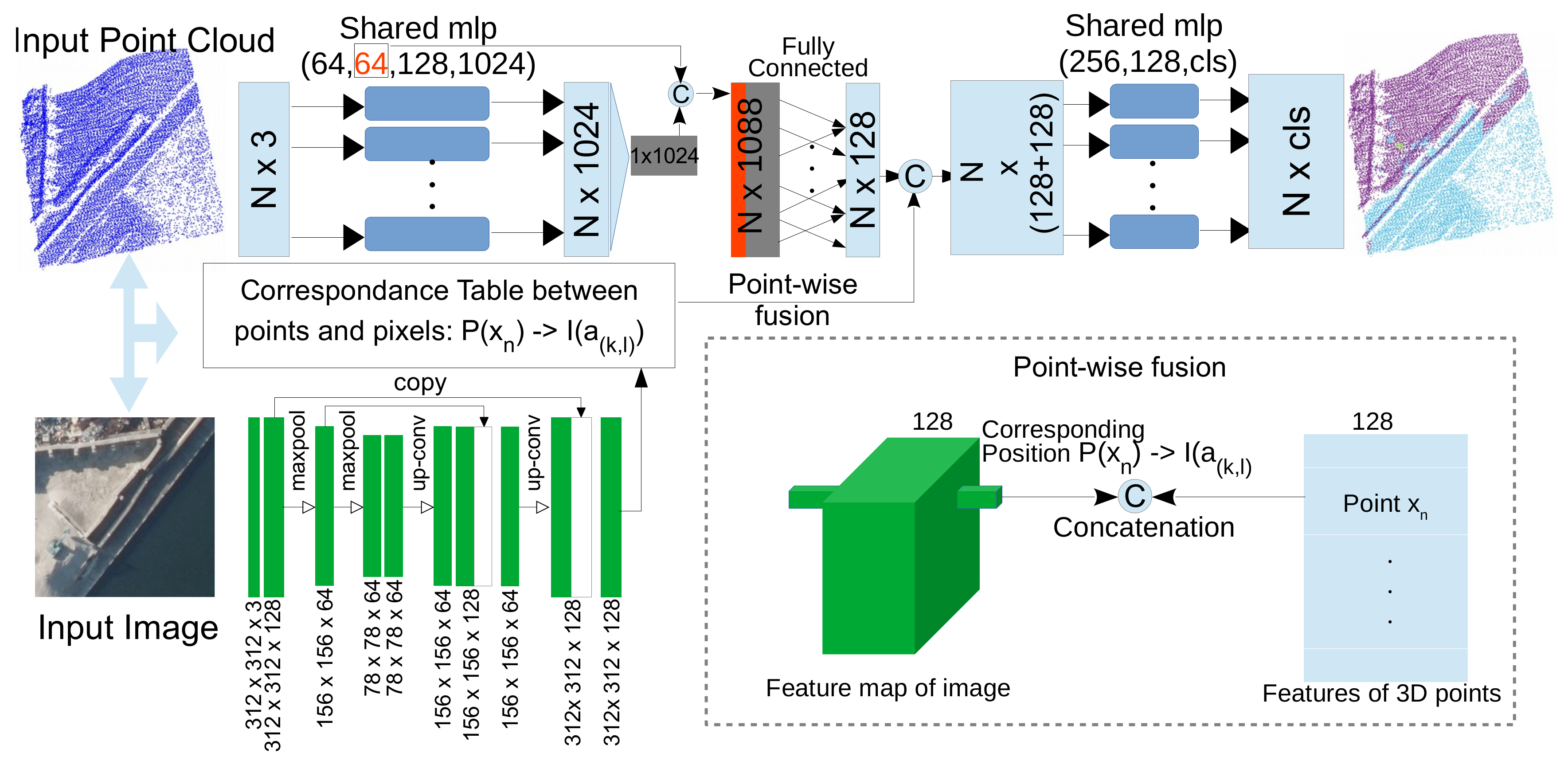
3. Methodology and Conceptual Framework
3.1. Pointnet Part of PMNet
3.2. CNN Encoder-Decoder Part of PMNet
3.3. Concept of the Point-Wise Feature Fusion Strategy of PMNet
4. Datasets
4.1. University of Houston Campus, USA Dataset
4.2. Osaka, Japan Dataset
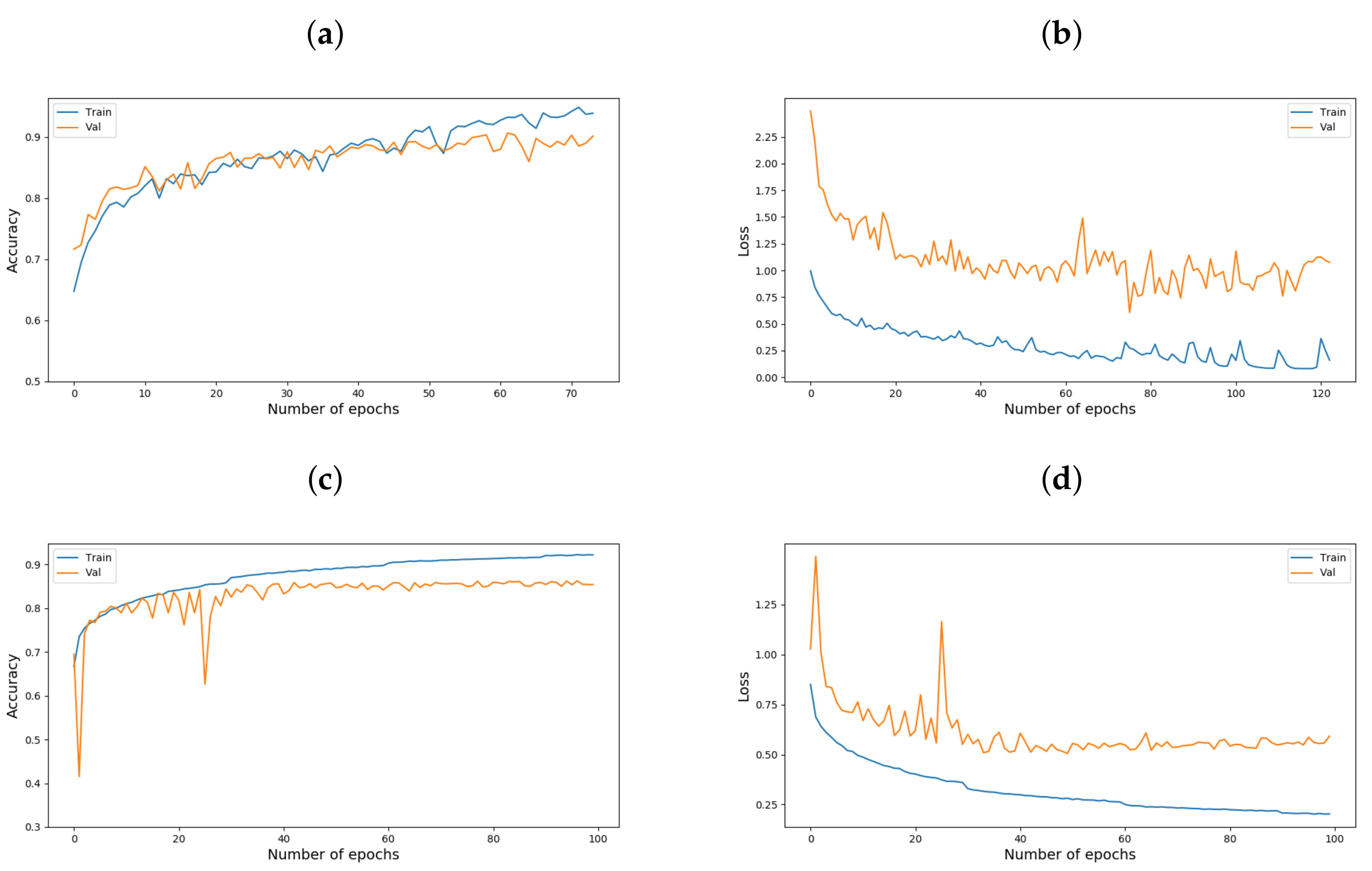
4.3. Training Set Up
5. Results and Discussion
5.1. 3D Segmentation Accuracy Assessment
5.1.1. Quantitative Analysis
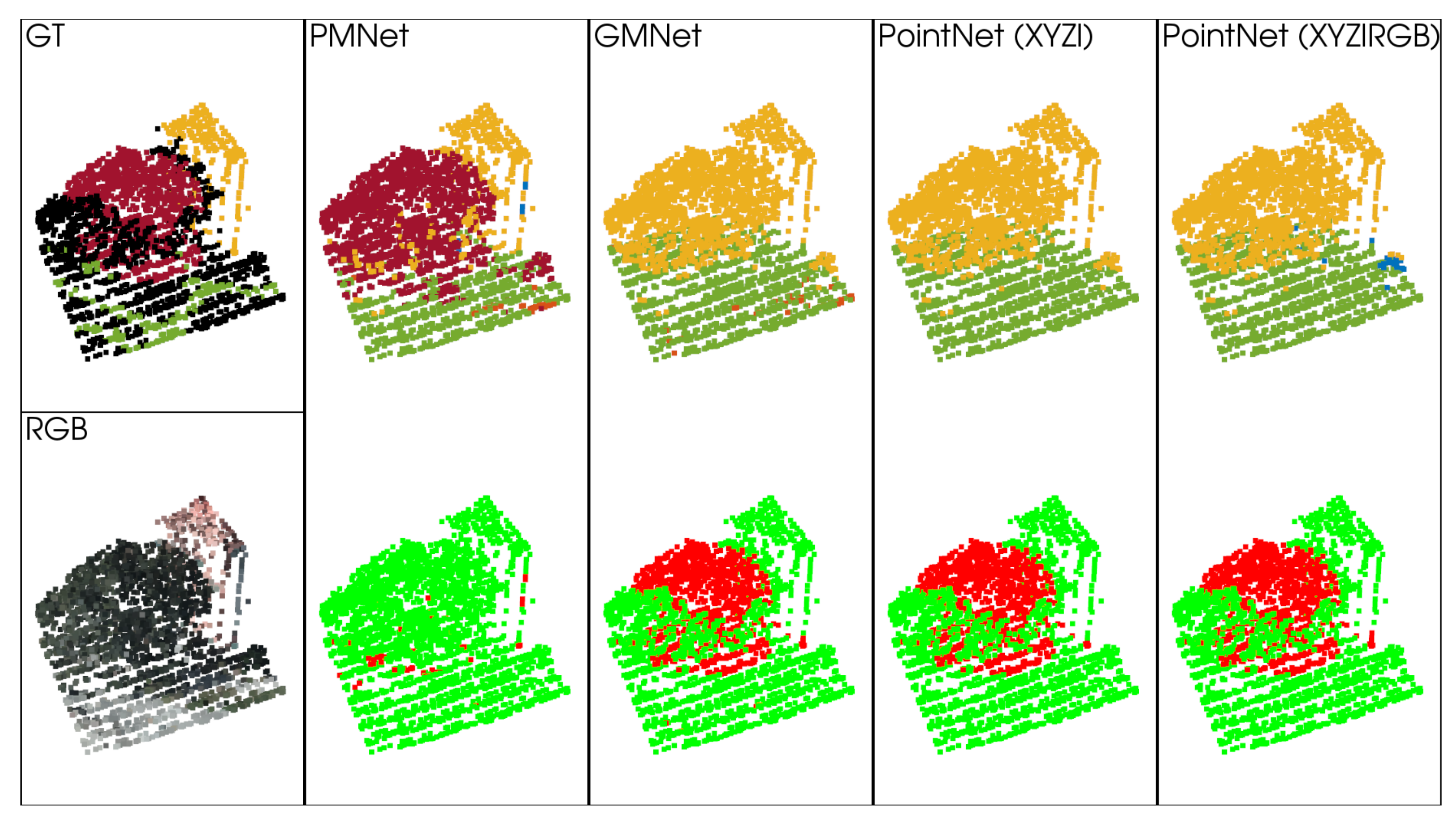
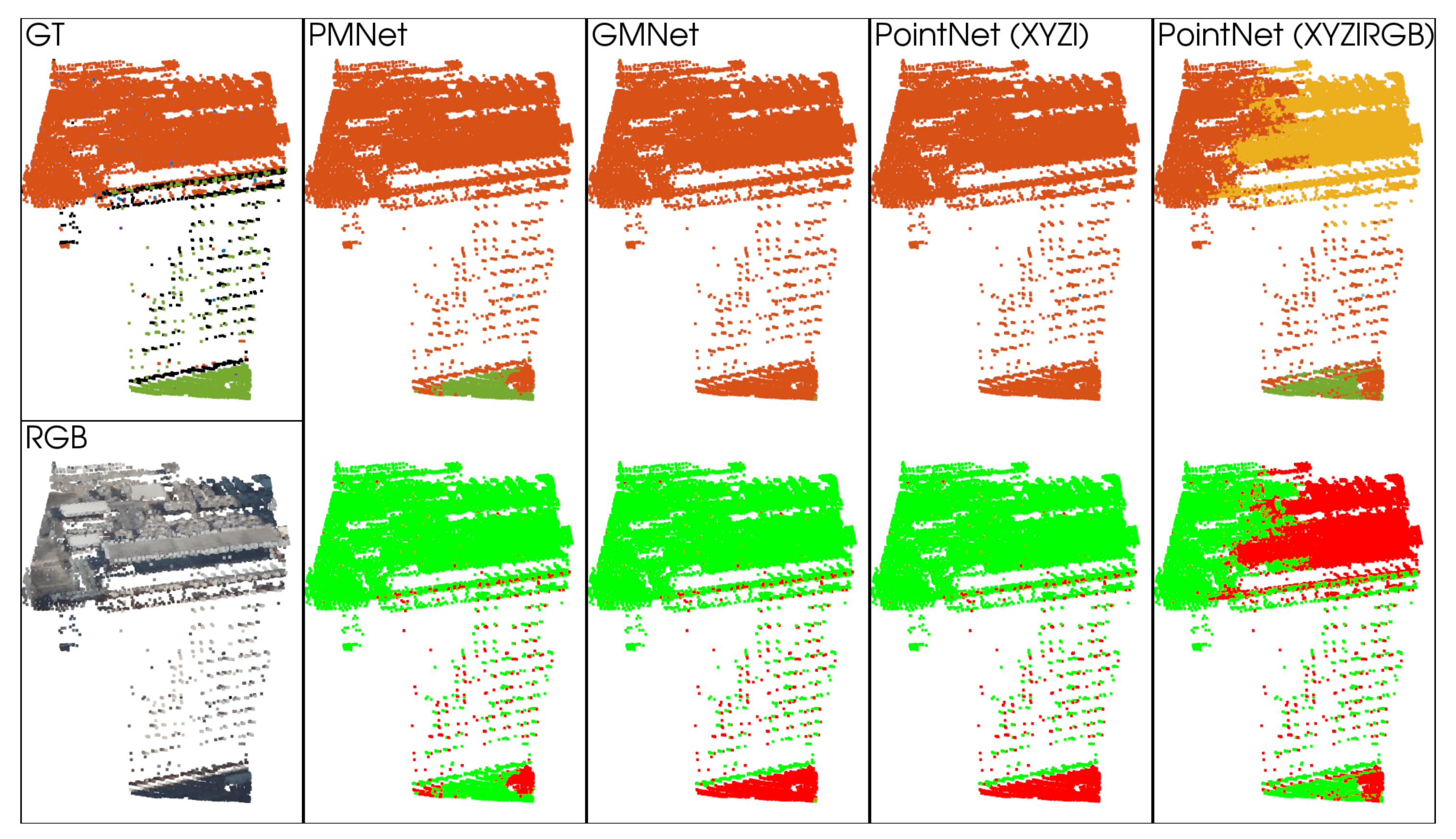
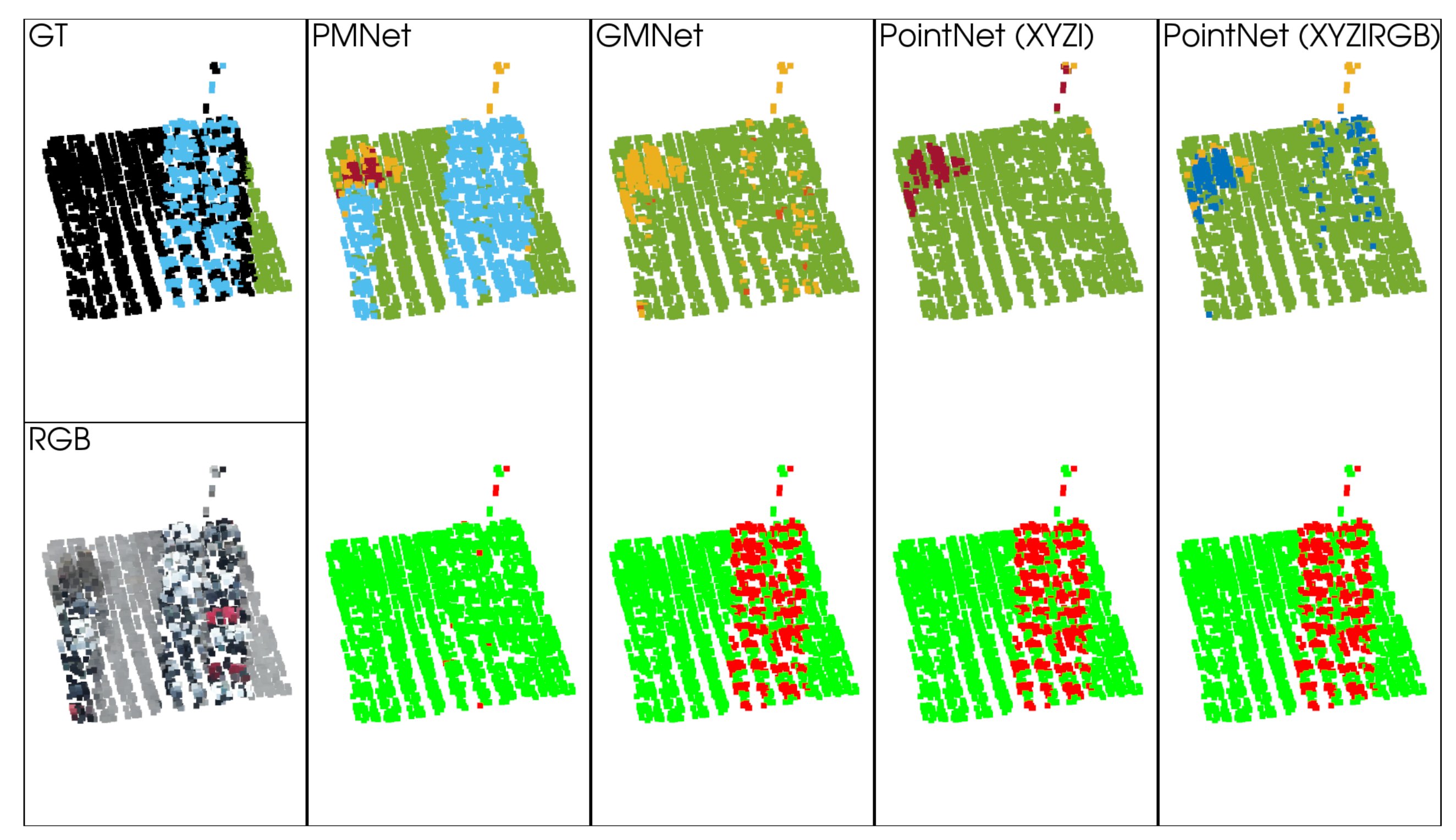
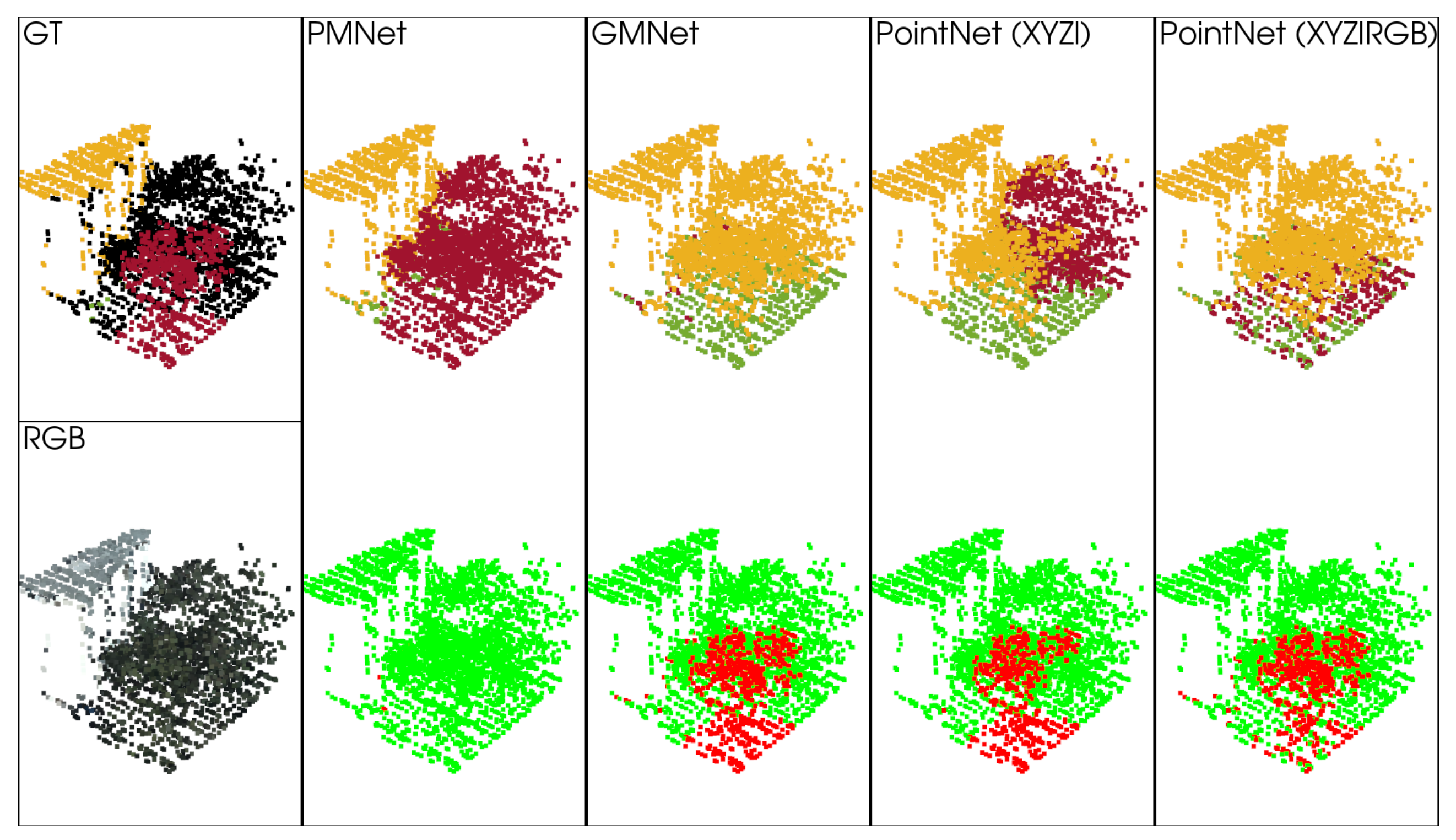
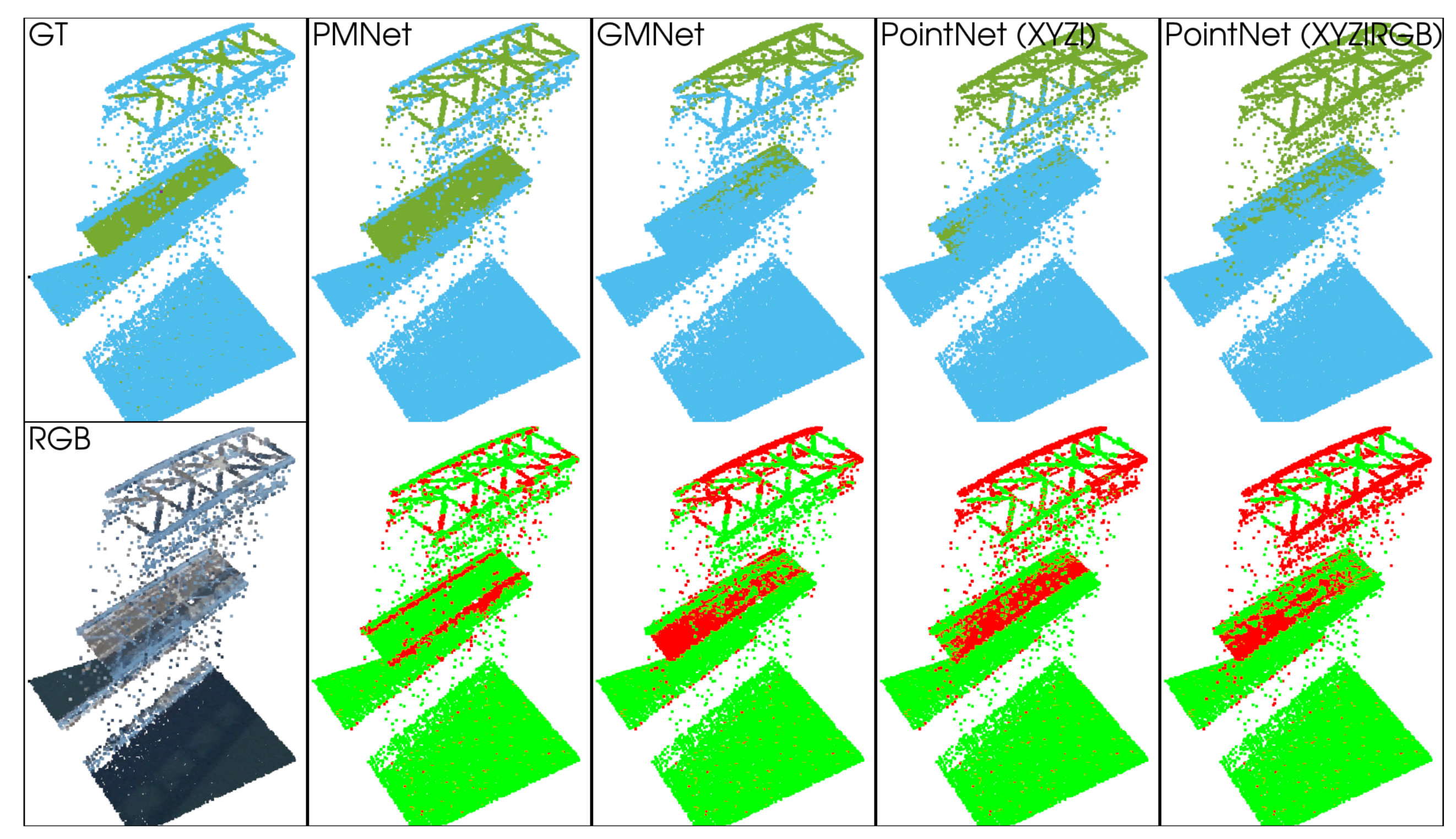
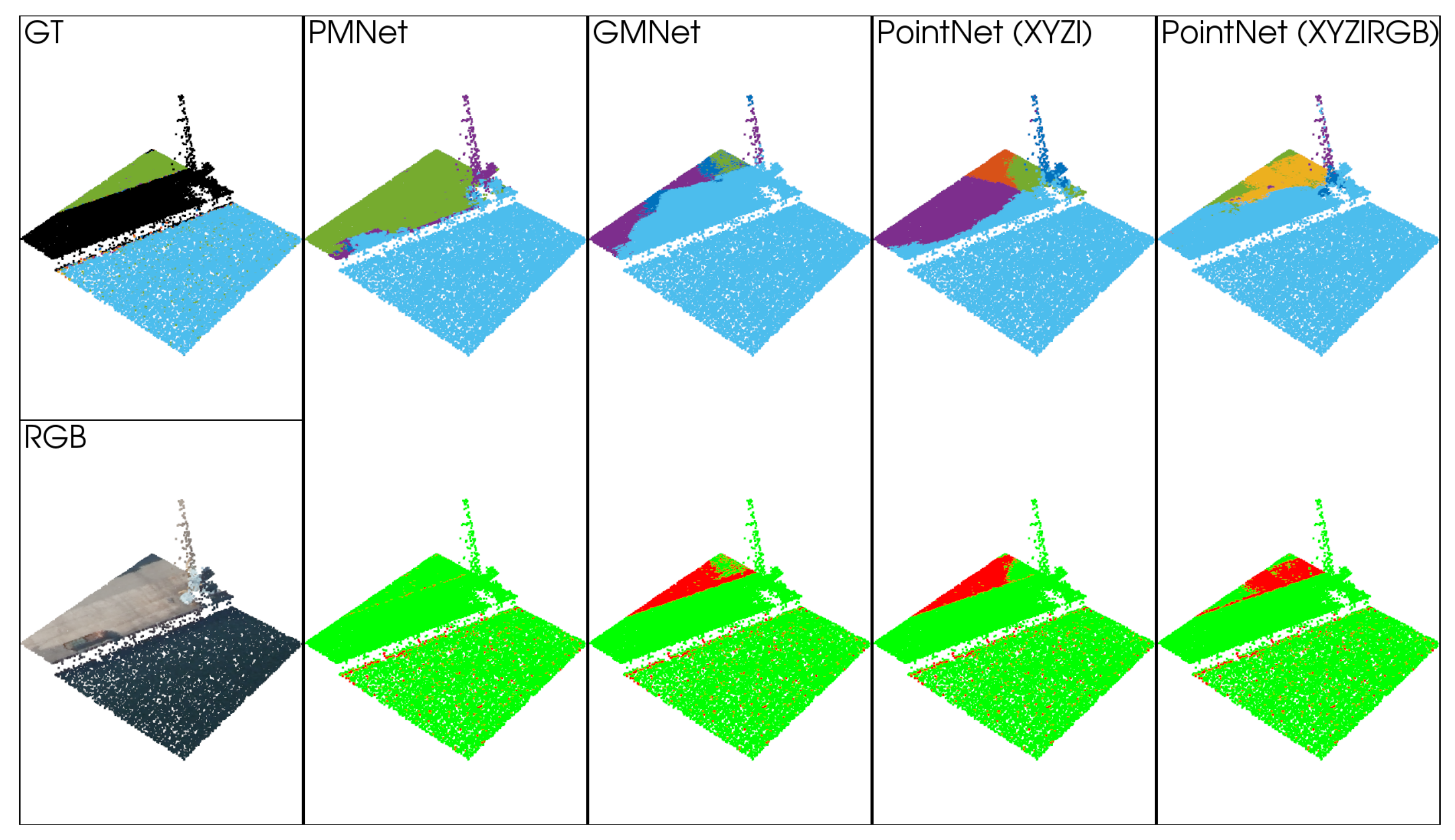
5.1.2. Qualitative Analysis
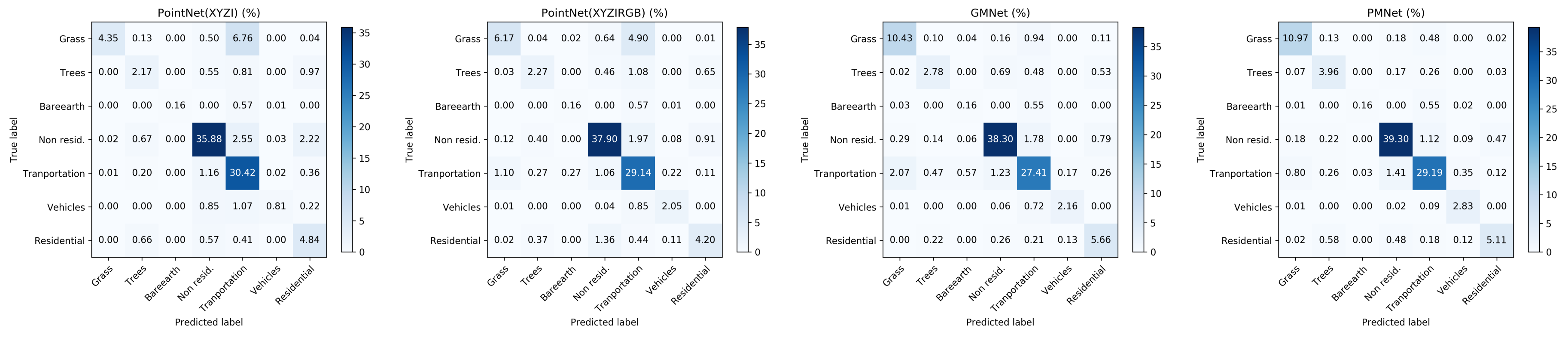
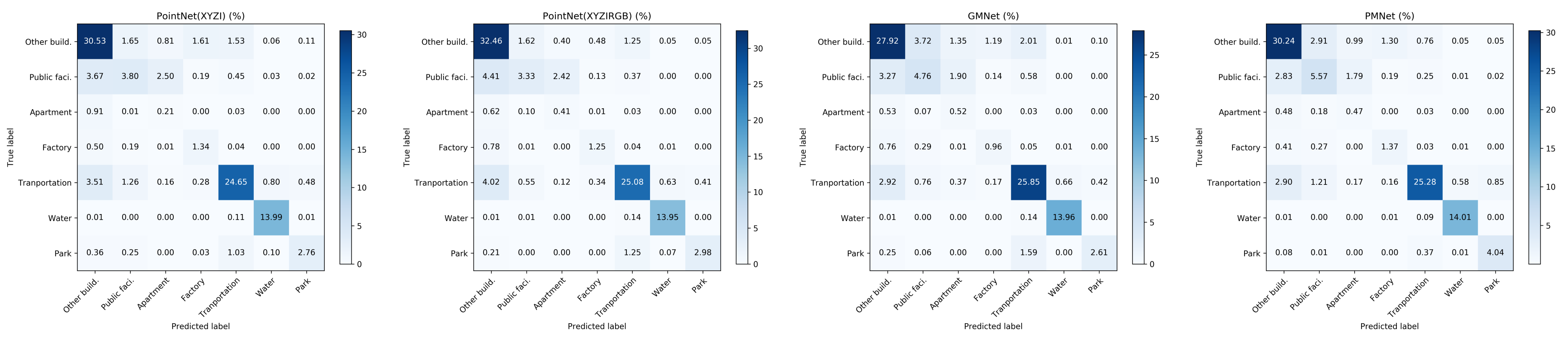
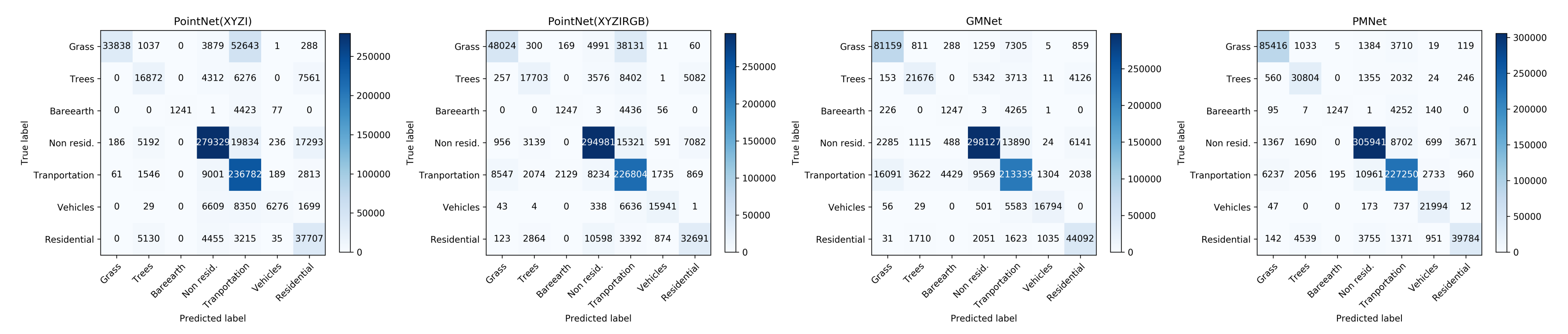
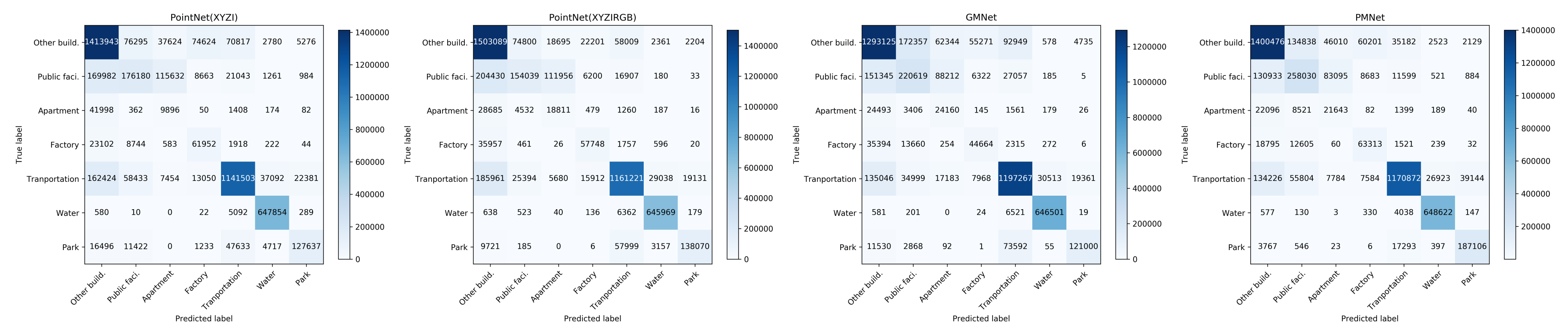
5.2. Detailed Spatial (Per-Point) Comparison Using Confusion Matrix
5.3. Improved Performance by Over-Sampling the Minor Classes and Medium Classes
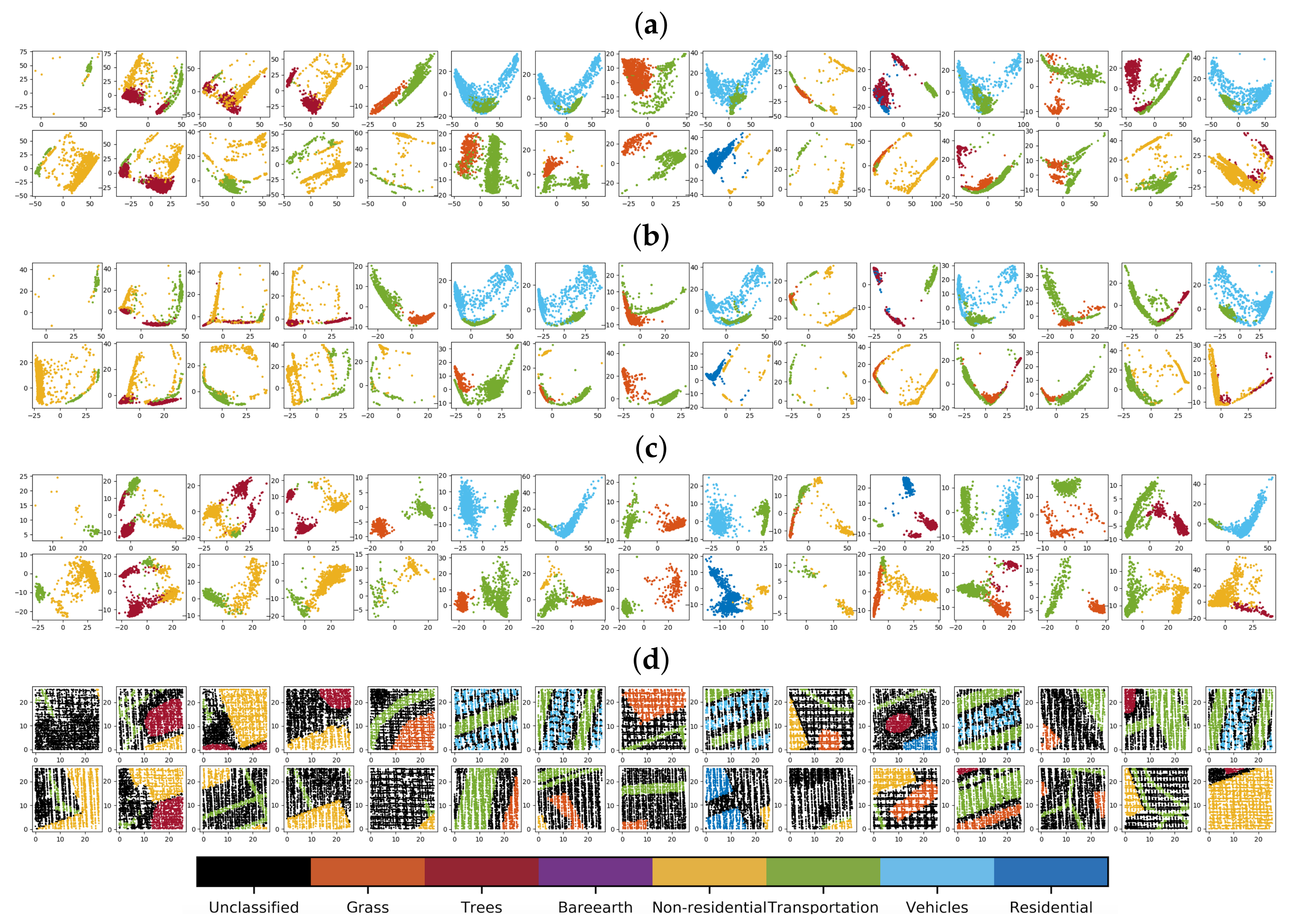
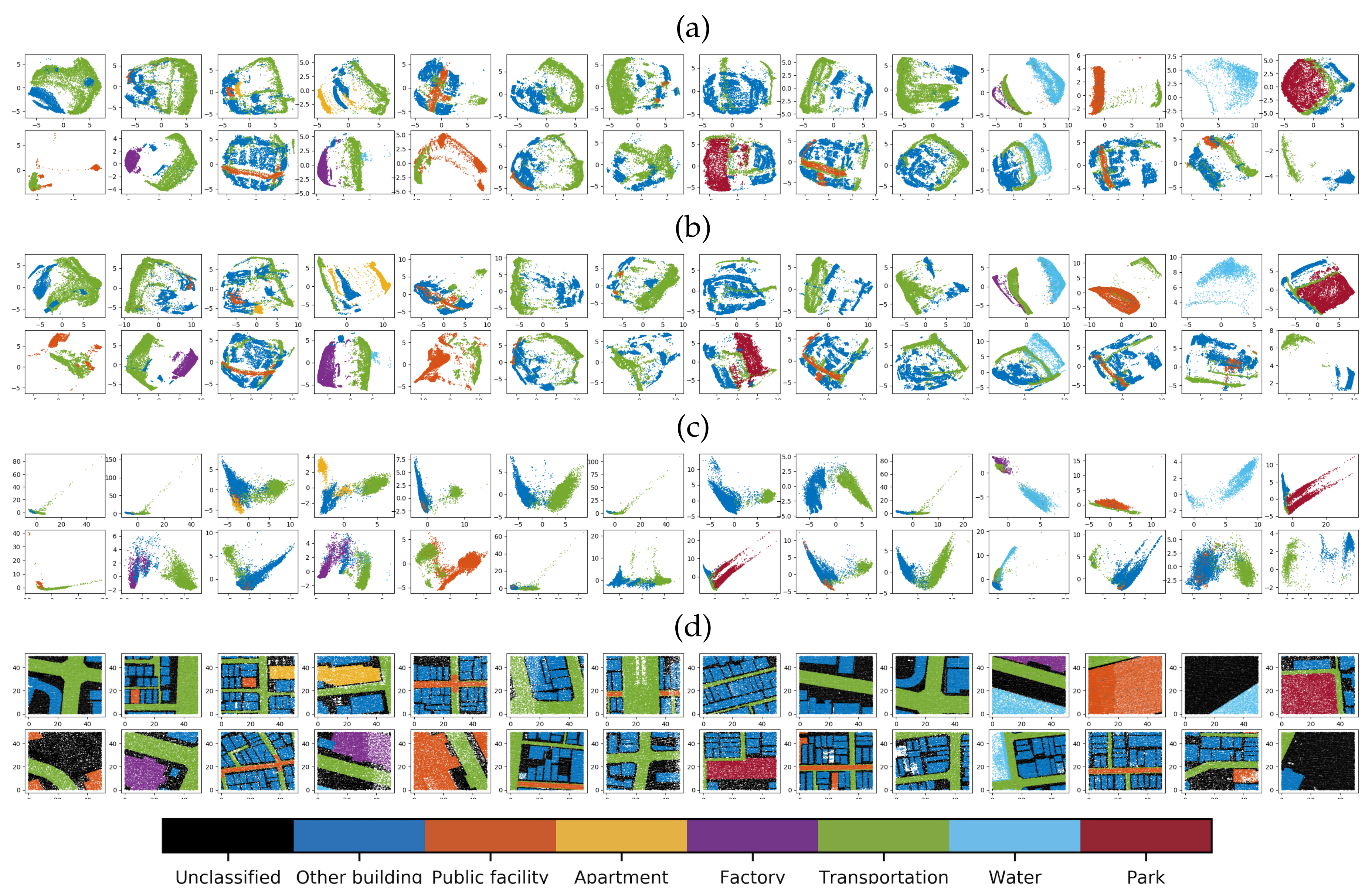
5.4. Evaluate Point-Wise Fusion Strategy Using Feature Activation Maps
5.5. Model Complexity Evaluation Using Computational Parameters and Memory Requirement
5.6. Discussions
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PMNet | Point-wise Multimodal Fusion Network |
| GMNet | Global Multi-modal Fusion Network |
| PCA | Principle Component Analysis |
| LiDAR | Light Detection and Ranging |
| UHC | University of Houston Campus |
| VHR | Very high-resolution |
| MLP | Multi-layer perceptron |
| CNN | Convolutional Neural Network |
| ReLU | Rectified Linear Unit |
Appendix A







References
- Gao, H.; Zhang, H.; Hu, D.; Tian, R.; Guo, D. Multi-scale features of urban planning spatial data. In Proceedings of the 18th International Conference On Geoinformatics, Beijing, China, 18–20 June 2010; pp. 1–7. [Google Scholar]
- Gao, Z.; Kii, M.; Nonomura, A.; Nakamura, K. Urban expansion using remote-sensing data and a monocentric urban model. Comput. Environ. Urban Syst. 2019, 77, 101152. [Google Scholar] [CrossRef]
- Hamaguchi, R.; Hikosaka, S. Building detection from satellite imagery using ensemble of size-specific detectors. In Proceedings of the IEEE/cvf Conference On Computer Vision And Pattern Recognition Workshops (cvprw), Salt Lake City, UT, USA, 18–22 June 2018; pp. 223–2234. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference On Medical Image Computing And Computer-assisted Intervention, Munich, Germany, 1–6 October 2015; pp. 234–241. [Google Scholar]
- Islam, M.; Rochan, M.; Naha, S.; Bruce, N.; Wang, Y. Gated feedback refinement network for coarse-to-fine dense semantic image labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3751–3759. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference On Computer Vision, Tampa, FL, USA, 5–8 December 2017; pp. 2961–2969. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Cruz, C.; Hmida, H.; Boochs, F.; Nicolle, C. From Unstructured 3D Point Clouds to Structured Knowledge-A Semantics Approach. In Semantics-Advances In Theories and Mathematical Models; Afzal, M.T., Ed.; IntechOpen: London, UK, 2012; Chapter 9. [Google Scholar]
- Wu, Y.; Qin, H.; Liu, T.; Liu, H.; Wei, Z. A 3D Object Detection Based on Multi-Modality Sensors of USV. Appl. Sci. 2019, 9, 535. [Google Scholar] [CrossRef]
- Arief, H.G.; Tveite, H.; Indahl, U. Land cover segmentation of airborne LiDAR data using stochastic atrous network. Remote Sens. 2018, 10, 973. [Google Scholar] [CrossRef]
- Lodha, S.; Kreps, E.; Helmbold, D.; Fitzpatrick, D. Aerial LiDAR data classification using support vector machines (SVM). In Proceedings of the Third International Symposium On 3d Data Processing, Visualization, And Transmission (3dpvt’06), Chapel Hill, NC, USA, 14–16 June 2006; pp. 567–574. [Google Scholar]
- Pan, X.; Gao, L.; Marinoni, A.; Zhang, B.; Yang, F.; Gamba, P. Semantic labeling of high resolution aerial imagery and LiDAR data with fine segmentation network. Remote Sens. 2018, 10, 743. [Google Scholar] [CrossRef]
- Zhang, W.; Huang, H.; Schmitz, M.; Sun, X.; Wang, H.; Mayer, H. Effective fusion of multi-modal remote sensing data in a fully convolutional network for semantic labeling. Remote Sens. 2018, 10, 52. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Salberg, A.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Audebert, N.; Lesaux, B.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. In Asian Conference On Computer Vision; Springer: Cham, Switzerland, 2016; pp. 180–196. [Google Scholar]
- Ashraf, I.; Hur, S.; Park, Y. An investigation of interpolation techniques to generate 2D intensity image from LIDAR data. IEEE Access 2017, 5, 8250–8260. [Google Scholar] [CrossRef]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3d point clouds. In Proceedings of the 2017 International Conference On 3d Vision (3dv), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Boulch, A.; Lesaux, B.; Audebert, N. Unstructured Point Cloud Semantic Labeling Using Deep Segmentation Networks. 3DOR 2017, 7. [Google Scholar] [CrossRef]
- Griffiths, D.; Boehm, J. A Review on deep learning techniques for 3D sensed data classification. Remote Sens. 2019, 11, 1499. [Google Scholar] [CrossRef]
- Qi, C.; Su, H.; Mo, K.; Guibas, L. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.; Yi, L.; Su, H.; Guibas, L. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances In Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3d object detector for point cloud. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–29 October 2019; pp. 1951–1960. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–29 October 2019; pp. 9297–9307. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. In Proceedings of the Advances In Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 820–830. [Google Scholar]
- Riegler, G.; Osmanulusoy, A.; Geiger, A. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolul, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
- Zhou, Q.; Neumann, U. Modeling residential urban areas from dense aerial LiDAR point clouds. In Proceedings of the International Conference On Computational Visual Media, Beijing, China, 8–10 November 2012; pp. 91–98. [Google Scholar]
- Huang, X.; Zhang, L.; Gong, W. Information fusion of aerial images and LIDAR data in urban areas: Vector-stacking, re-classification and post-processing approaches. Int. J. Remote Sens. 2011, 32, 69–84. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Lesaux, B.; Yokoya, N.; Hansch, R.; Brown, M.; Hager, G. 2019 Data Fusion Contest [Technical Committees]. IEEE Geosci. Remote Sens. Mag. 2019, 7, 103–105. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L.; Cerra, D.; Pato, M.; Carmona, E.; Prasad, S.; Yokoya, N.; Hansch, R.; Lesaux, B. Advanced Multi-Sensor Optical Remote Sensing for Urban Land Use and Land Cover Classification: Outcome of the 2018 IEEE GRSS Data Fusion Contest. Ieee J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1709–1724. [Google Scholar] [CrossRef]
- Debes, C.; Merentitis, A.; Heremans, R.; Hahn, J.; Frangiadakis, N.; Vankasteren, T.; Liao, W.; Bellens, R.; Pižurica, A.; Gautama, S. Hyperspectral and LiDAR data fusion: Outcome of the 2013 GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2405–2418. [Google Scholar] [CrossRef]
- 2018 IEEE GRSS Data Fusion Contest. Available online: http://www.grss-ieee.org/community/technical-committees/data-fusion (accessed on 2 August 2019).
- Lowphansirikul, C.; Kim, K.; Vinayaraj, P.; Tuarob, S. 3D Semantic Segmentation of Large-Scale Point-Clouds in Urban Areas Using Deep Learning. In Proceedings of the 11th International Conference on Knowledge and Smart Technology (kst), Phuket, Thailand, 23–26 January 2019; pp. 238–243. [Google Scholar]
- Xiu, H.; Vinayaraj, P.; Kim, K.; Nakamura, R.; Yan, W. 3D Semantic Segmentation for High-resolution Aerial Survey Derived Point Clouds Using Deep Learning (Demonstration). In Proceedings of the 26th Acm Sigspatial International Conference On Advances In Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 588–591. [Google Scholar]
- Giri, C.; Zhu, Z.; Reed, B. A comparative analysis of the Global Land Cover 2000 and MODIS land cover data sets. Remote Sens. Environ. 2005, 94, 123–132. [Google Scholar] [CrossRef]
- Kang, J.; Sui, L.; Yang, X.; Wang, Z.; Huang, C.; Wang, J. Spatial Pattern Consistency among Different Remote-Sensing Land Cover Datasets: A Case Study in Northern Laos. ISPRS Int. J. Geo-Inf. 2019, 8, 201. [Google Scholar] [CrossRef]
- Dai, A.; Chang, A.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Abdou, M.; Elkhateeb, M.; Sobh, I.; El-sallab, A. Weighted Self-Incremental Transfer Learning for 3D-Semantic Segmentation. Available online: https://pdfs.semanticscholar.org/41b2/c5ad11a3f55d72def07d44cb32a44701ecd1.pdf (accessed on 1 November 2019).
- Li, J.; Du, Q.; Li, Y.; Li, W. Hyperspectral image classification with imbalanced data based on orthogonal complement subspace projection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3838–3851. [Google Scholar] [CrossRef]
- Bogner, C.; Seo, B.; Rohner, D.; Reineking, B. Classification of rare land cover types: Distinguishing annual and perennial crops in an agricultural catchment in South Korea. PLoS ONE 2018, 13, e0190476. [Google Scholar] [CrossRef] [PubMed]
- Sze, V.; Chen, Y.; Yang, T.; Emer, J. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Canziani, A.; Paszke, A.; Culurciello, E. An analysis of deep neural network models for practical applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Alom, M.; Taha, T.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.; Hasan, M.; Vanessen, B.; Awwal, A.; Asari, V. A state-of-the-art survey on deep learning theory and architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- AIST Artificial Intelligence Cloud (AAIC). Available online: https://www.airc.aist.go.jp/en/info_details/computer-resources.html (accessed on 10 September 2018).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Grass | Trees | Bare | Non | Tran. | Vehicle | Residential | Avg | OA |
|---|---|---|---|---|---|---|---|---|---|
| Earth | Residential | Network | CA | ||||||
| PointNet (XYZI) | 0.52 | 0.50 | 0.21 | 0.91 | 0.90 | 0.69 | 0.64 | 0.62 | 0.63 |
| PointNet | 0.62 | 0.55 | 0.30 | 0.92 | 0.86 | 0.90 | 0.59 | 0.68 | 0.82 |
| (XYZIRGB) | |||||||||
| GMNet | 0.83 | 0.75 | 0.21 | 0.88 | 0.91 | 0.72 | 0.41 | 0.67 | 0.84 |
| PMNet | 0.85 | 0.82 | 0.30 | 0.92 | 0.92 | 0.84 | 0.77 | 0.77 | 0.89 |
| Method | Other | Public | Apartment | Factory | Tran. | Water | Park | Avg | OA |
|---|---|---|---|---|---|---|---|---|---|
| Building | Facility | Network | CA | ||||||
| PointNet (XYZI) | 0.85 | 0.18 | 0.23 | 0.58 | 0.81 | 0.98 | 0.82 | 0.64 | 0.77 |
| PointNet | 0.89 | 0.31 | 0.34 | 0.59 | 0.80 | 0.98 | 0.66 | 0.65 | 0.79 |
| (XYZIRGB) | |||||||||
| GMNet | 0.77 | 0.44 | 0.44 | 0.46 | 0.83 | 0.98 | 0.57 | 0.65 | 0.77 |
| PMNet | 0.86 | 0.41 | 0.22 | 0.59 | 0.84 | 0.99 | 0.84 | 0.68 | 0.81 |
| Method | UHC Dataset | Osaka Dataset | |||||||
|---|---|---|---|---|---|---|---|---|---|
| MIoU | Precision | Recall | F-Score | MIoU | Precision | Recall | F-Score | ||
| PointNet | 0.45 | 0.80 | 0.55 | 0.59 | 0.49 | 0.62 | 0.63 | 0.61 | |
| (XYZI) | |||||||||
| PointNet | 0.52 | 0.72 | 0.62 | 0.66 | 0.52 | 0.67 | 0.65 | 0.65 | |
| (XYZIRGB) | |||||||||
| GMNet | 0.61 | 0.74 | 0.72 | 0.73 | 0.50 | 0.63 | 0.64 | 0.62 | |
| PMNet | 0.71 | 0.87 | 0.80 | 0.80 | 0.57 | 0.66 | 0.73 | 0.68 |
| Method | Grass | Trees | Bare | Non | Tran. | Vehicles | Residential | Avg | OA |
|---|---|---|---|---|---|---|---|---|---|
| Earth | Residential | Network | CA | ||||||
| PMNet | 0.85 | 0.82 | 0.30 | 0.92 | 0.92 | 0.84 | 0.77 | 0.77 | 0.89 |
| Samples (%) | 8.10% | 6.9% | 0.9% | 43.4% | 30.33% | 2.51 % | 7.68% | ||
| PMNet (Ovr.) | 0.89 | 0.85 | 0.32 | 0.94 | 0.90 | 0.90 | 0.78 | 0.80 | 0.91 |
| Samples (%) | 8.69% | 6.47% | 1.43 % | 43.71% | 29.90% | 2.76% | 7.01% |
| Method | Other | Public | Apartment | Factory | Tran. | Water | Park | Avg | OA |
|---|---|---|---|---|---|---|---|---|---|
| Building | Facility | Network | CA | ||||||
| PMNet | 0.86 | 0.41 | 0.22 | 0.59 | 0.84 | 0.99 | 0.84 | 0.68 | 0.81 |
| Samples (%) | 40.17% | 5.23% | 3.04% | 7.77% | 31.66% | 9.46% | 2.64% | ||
| PMNet (ovr.) | 0.83 | 0.52 | 0.40 | 0.65 | 0.81 | 0.99 | 0.89 | 0.73 | 0.81 |
| Samples (%) | 35.06% | 5.8% | 3.05 % | 8.64% | 28.41% | 14.89% | 4.14% |
| Models | Total Number of Weights and Biases | Memory Usage (Kilobytes) |
|---|---|---|
| PointNet (XYZI) | 8,88,392 | 3553 |
| PointNet | 8,88,585 | 3554 |
| GMNet | 99,90,090 | 39,960 |
| PMNet | 8,00,201 | 3200 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poliyapram, V.; Wang, W.; Nakamura, R. A Point-Wise LiDAR and Image Multimodal Fusion Network (PMNet) for Aerial Point Cloud 3D Semantic Segmentation. Remote Sens. 2019, 11, 2961. https://doi.org/10.3390/rs11242961
Poliyapram V, Wang W, Nakamura R. A Point-Wise LiDAR and Image Multimodal Fusion Network (PMNet) for Aerial Point Cloud 3D Semantic Segmentation. Remote Sensing. 2019; 11(24):2961. https://doi.org/10.3390/rs11242961
Chicago/Turabian StylePoliyapram, Vinayaraj, Weimin Wang, and Ryosuke Nakamura. 2019. "A Point-Wise LiDAR and Image Multimodal Fusion Network (PMNet) for Aerial Point Cloud 3D Semantic Segmentation" Remote Sensing 11, no. 24: 2961. https://doi.org/10.3390/rs11242961
APA StylePoliyapram, V., Wang, W., & Nakamura, R. (2019). A Point-Wise LiDAR and Image Multimodal Fusion Network (PMNet) for Aerial Point Cloud 3D Semantic Segmentation. Remote Sensing, 11(24), 2961. https://doi.org/10.3390/rs11242961