1. Introduction
With the development of Unmanned Aircraft Vehicle (UAV), low-altitude remote sensing is playing an increasingly important role in land cover monitoring [
1,
2,
3], heritage site protection [
4], and vegetation observation [
5,
6,
7]. For these applications, aerial imagery-based 3D reconstruction of large-scale scenes is highly desired. For instance, Mancini et al. [
1] used 3D reconstruction from UAV images to get accurate topographic information for coastal geomorphology, which could be used to perform a reliable simulation of coastal erosion and flooding phenomena.
Structure from Motion (SfM) is a 3D reconstruction method used to recover the 3D structure of stationary scenes from a set of projective measurements, via motion estimation of the cameras corresponding to images. In essence, SfM involves the three main stages of: (1) extraction of features in images (i.e., points of interest) and matching these features between images; (2) camera motion estimation (i.e., camera poses including the rotation matrix and translation vector); and (3) recovery of the 3D structure using the estimated motion and features. Among the 3D reconstruction methods, SfM is a basic 3D reconstruction approach that is able to recover sparse 3D information and camera motion parameters from images, which is the basis for generating successively-dense point clouds and high-resolution Digital Surface Models (DSMs). Therefore, SfM is the primary task for the research and application of 3D reconstruction using aerial images.
However, the application of SfM technology to large-scale 3D reconstruction is a very challenging task because of the efficiency problem. For SfM, large-scale means that there is a larger range of scenes to be reconstructed. Obviously, in order to reconstruct the large-scale scene structure, more aerial images and greater image resolution are required, which brings a computational challenge for each step of the SfM pipeline, such as feature matching. For example, given a dataset with n images, this will result in possible image pairs, hence leading to O() complexity for feature matching. On the other hand, the number of features detected from large resolution images is generally very high. Consequently, the computational cost of feature matching is adequately huge, which constrains the efficiency of reconstruction.
Strategies for SfM can be divided into two main classes: incremental [
8,
9] and global [
10,
11,
12]. Incremental SfM pipelines start from a minimum reconstruction based on two views and then incrementally add new views to a merged model. During the adding image process, periodic Bundle Adjustment (BA) [
13] is required to optimize the 3D points of the scene structure and camera poses. The essence of BA is an optimization process, the purpose of which is to minimize the re-projection error. Re-projection error is obtained by comparing the pixel coordinates (i.e., the observed feature positions) with the 2D positions projected by 3D points according to the camera pose of the projected image. Incremental methods are generally slow. This is mainly because of the exhaustive feature matching in a large number of image pairs. In addition, periodic global BA is time consuming. As for global pipelines, most are solved in two steps. The first step estimates the global rotation of each view, and the second step estimates the camera translations and the scene structure. Although global SfM avoids periodic global BA, it still encounters the computational bottleneck brought by feature matching in a large number of image pairs. In other words, both strategies aim at entire image sets, thus causing a serious efficiency problem for large-scale SfM.
To tackle the efficiency problem for large-scale SfM, researchers have proposed some solutions. Some researchers have focused on the BA optimization problem for large-scale SfM. For large-scale SfM, there is a huge number of reconstructed 3D points and camera parameters. Therefore, the global BA optimization of all 3D points and camera parameters is a slow process. Steedly et al. [
14] proposed a spectral partitioning approach for large-scale optimization problems, specifically structure from motion. The idea is to decompose the optimization problem into smaller, more tractable components. The subproblems can be selected using the Hessian of the reprojection error and its eigenvectors. Ni et al. [
15] presented an out-of-core bundle adjustment algorithm, in which the original problem is decoupled into several submaps that have their own local coordinate systems and can be optimized in parallel. However, this method only focuses on the last step of reconstruction, and the solution to the efficiency problem is limited. Obviously, the decomposition of the SfM problem from the beginning of the reconstruction pipeline can maximize the efficiency of reconstruction. Some researchers exploited a simplified graph of iconic images. Frahm et al. [
16] first obtained a set of canonical views by clustering the gist features and then established a skeleton and extended it using registration. Shah et al. [
17] proposed a multistage approach for SfM that involves first reconstructing a coarse global model using a match-graph of a few features and enriching it later by simultaneously localizing additional images and triangulating additional points. These methods merge multiple sub-models by finding the common 3D points across the models. However, 3D point matches obtained by 2–3D correspondences and 2D feature matching are contaminated by outliers, especially in repetitive structure scenes. Thus, care must be taken to identify common 3D points. Some researchers [
18,
19,
20,
21] have organized a hierarchical tree and merged partial reconstructions along the tree. However, the merging processes still rely on 3D point matches to estimate similarity transformations. Some researchers have proposed novel merging methods that do not depend on 3D matches. Bhowmick et al. [
22] estimated the similarity transformation between two models by leveraging the pairwise epipolar geometry of the link images. Sweeney et al. [
23] introduced a distributed camera model, which represents partial reconstructions as distributed cameras, and incrementally merges distributed cameras by solving a generalized absolute pose and scale problem. However, these methods that incrementally merge partial reconstructions may suffer from drifting errors.
To address all of these problems, in this paper, we propose a novel method for fast, large-scale SfM. The contributions of this work are as follows:
First, we present a clustering-aligning framework to perform fast 3D reconstruction. Clustering refers to the clustering of images to obtain the associated image subsets. This specific image organization lays a foundation for the subsequent partial reconstruction alignment.
Second, in the process of aligning partial reconstructions, we present a robust initial similarity transformation estimation method based on joint camera poses of common images across image subsets without 3D point matches.
Third, we present a similarity transformation-based BA hybrid optimization method to make the merged scene structure seamless. In the process of similarity transformation optimization, we introduce closed-loop constraints.
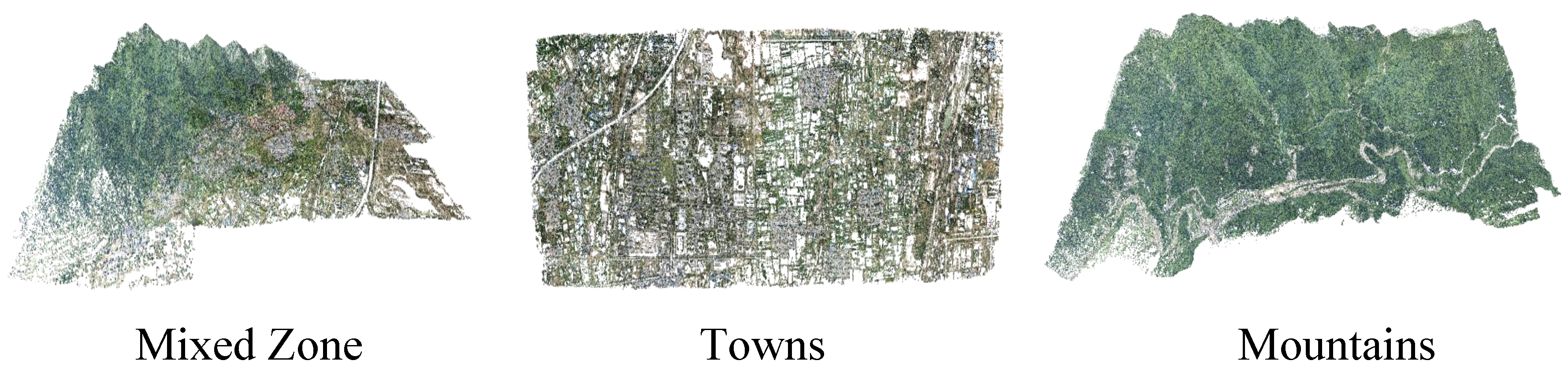
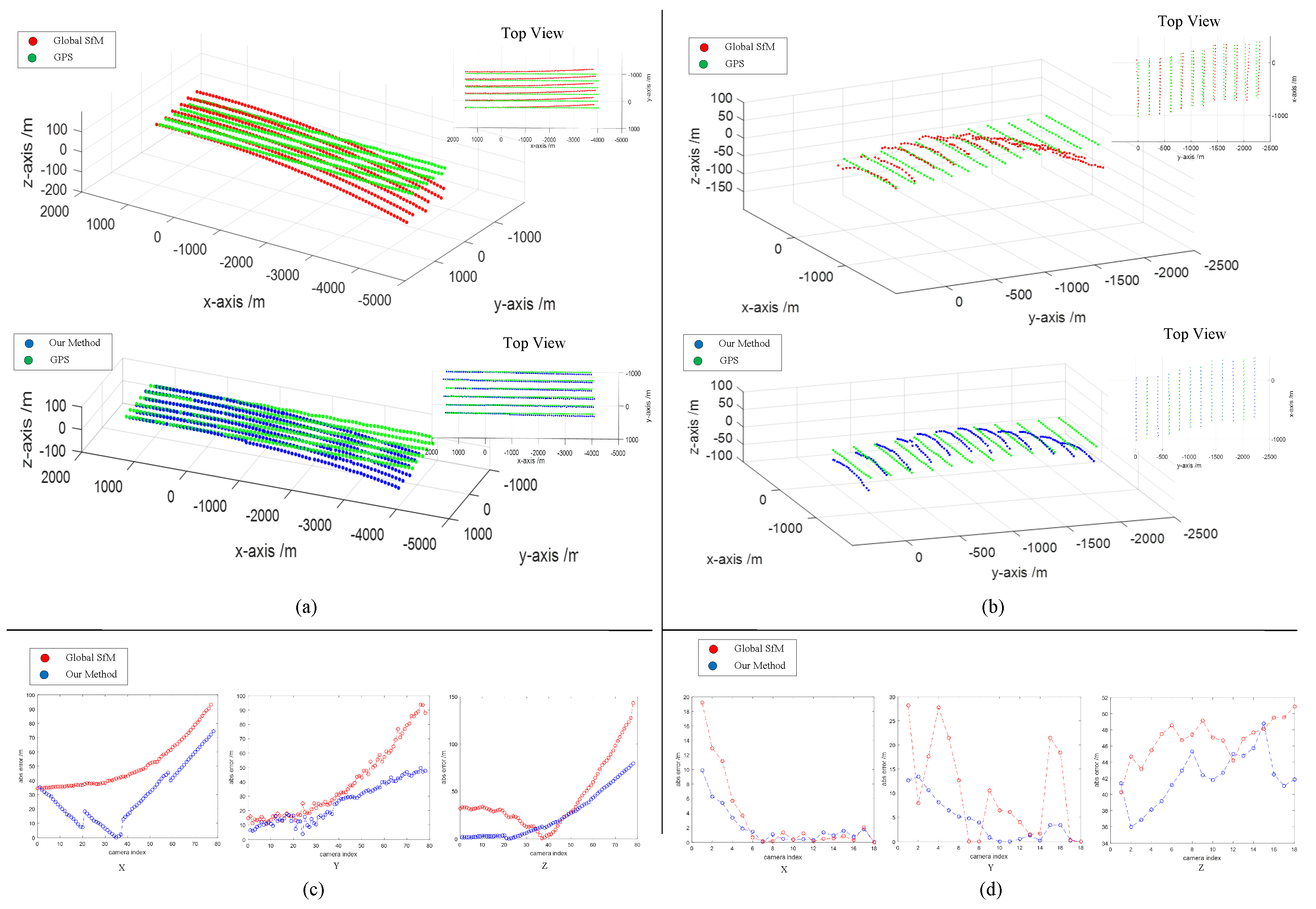
Finally, to evaluate the proposed method, we construct a large-scale aerial image dataset named the Qinling dataset, which is captured over Qinling mountain, covering 57 square kilometers. The experiments demonstrate that our method can rapidly and accurately reconstruct a large-scale dataset.
The remainder of the paper is organized as follows. We describe the proposed method in
Section 2.
Section 3 describes the experimental results. In
Section 4, we discuss the proposed method. Finally, we conclude the paper in
Section 5.
2. Method
This section elaborates our proposed approach for fast, large-scale 3D reconstruction based on the hierarchical clustering-aligning framework. The flowchart of the proposed method is illustrated in
Figure 1.
The framework contains two main parts: image clustering and aligning of partial reconstructions.
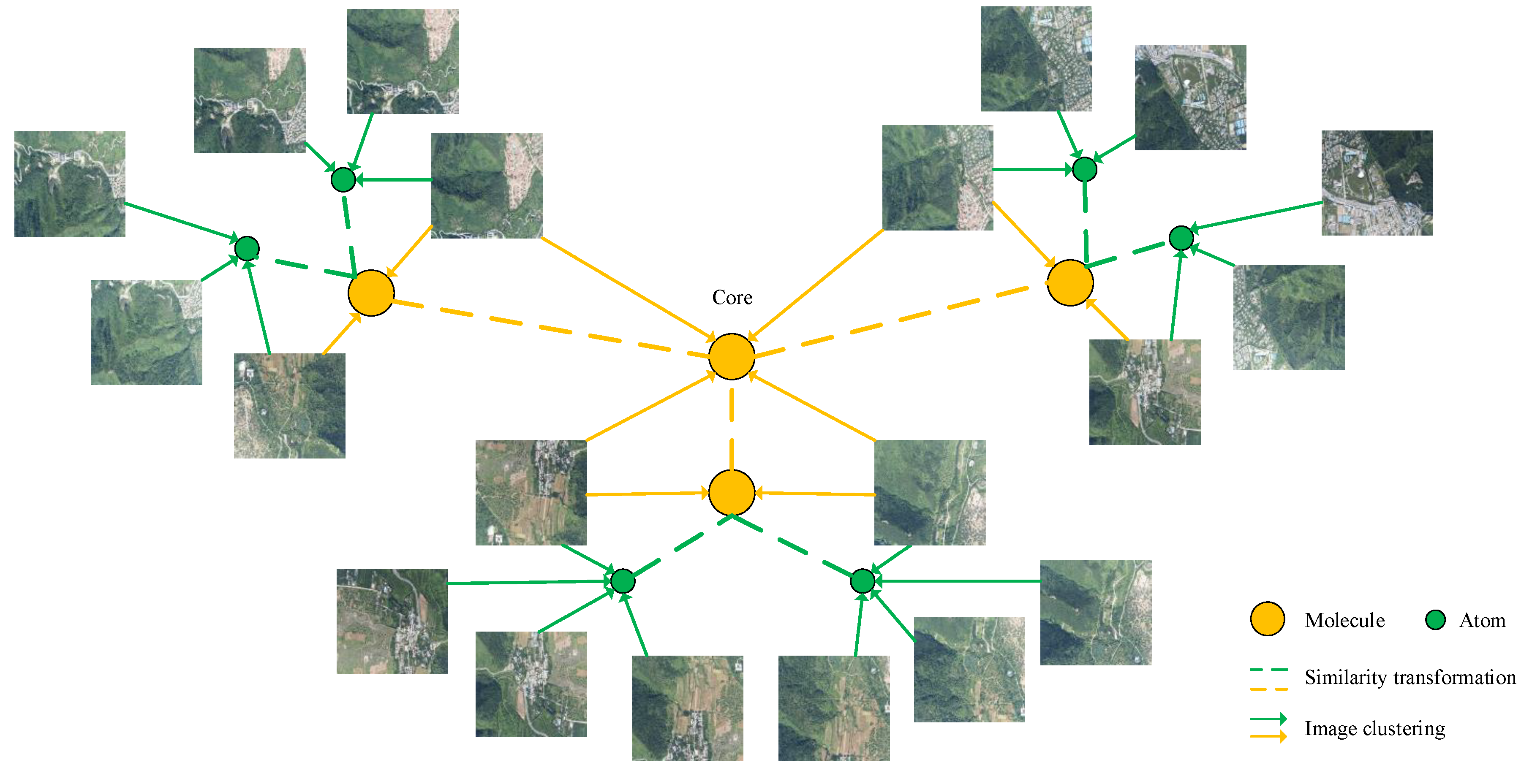
Through image clustering, we obtain the two kinds of associated image subsets. In order to visualize the relationship of the two kinds of image subsets, we use the concept of the hierarchical atomic model, a term used in the chemical field. To distinguish the two kinds of image subsets, we use the concepts of atom and molecule to represent a subset of clustered images, respectively. The hierarchical atomic model is illustrated in
Figure 2. The generation of a molecule is related to some adjacent atoms. In fact, the molecule represents an image subset that overlaps with each given image subset represented by atoms. It should be pointed out that the hierarchical atomic model is just a new name for image subset. For large-scale image datasets, the atomic model has two layers, which means the model has multiple molecules and corresponding atoms. For slightly smaller datasets, the atomic model has just one layer, which means the model has just one molecule and corresponding atoms. For large-scale image datasets, multiple groups of adjacent atoms generate multiple molecules. Among these molecules, we determine a core molecule, which overlaps with each other molecule. In this way, we have built a two-layer atomic model in which each atom is associated with the core molecule. This image clustering pattern provides a prerequisite for the follow-up work. For convenience, in the remainder of this paper, we use the atoms and molecules to represent the concept of the image subset. Next, independent partial 3D reconstruction is performed on each atom and molecule. According to the overlapping relationship between each pair of atoms and its corresponding molecules and each pair of molecules, we compute the similarity transformation via joint camera poses of common images across atoms and molecules. Finally, we implement a similarity transformation-based BA hybrid optimization. During optimization, closed-loop constraints between atoms and molecules are applied to correlate pairwise partial reconstructions. With hybrid optimization, we can get the complete seamless scene structure.
2.1. Image Clustering
In this subsection, we perform an image clustering task. The purpose of image clustering is to decompose large-scale SfM into small problems. This has two significant advantages in terms of efficiency. First of all, due to the small number of images in the image subset, the time consumption in the process of feature matching and BA will be significantly reduced, and second, partial reconstruction on the image subset can be performed in parallel.
In addition, the specific image organization pattern caused by image clustering lays the foundation for the subsequent alignment work.
2.1.1. Vocabulary Tree-Based Atom Generation
In the process of the generation of atoms, we use the vocabulary tree [
24] to cluster images. The vocabulary tree used in this paper is a standard vocabulary tree with K-branch and L-depth. In the experiment, we use a pre-computed and publicly-available tree [
25].
After vocabulary tree establishment, we firstly decide some source images, which are the origins of image clustering. In order to make image clustering more uniform according to the UAV flight path, the source images can be determined from those with long space intervals. Each source image is assigned to an atom. We then iteratively assign similar images to each atom according to the similarity measurement. Considering efficiency, in the image clustering phase, we resize all images to a fixed small resolution; in our experiment, that is 640 × 480. We treat the source images as database images and the remaining images as query images. For each image, Oriented FAST and Rotated BRIEF (ORB) [
26] features are detected and converted to weight vectors. Concretely, we define a query vector
q for query images and a database vector
d for database images according to the assigned weights as:
where
and
are the number of descriptor vectors of the query and database image, respectively, with a path through the cluster center node
i,
is the Inverse Document Frequency (IDF) weight, which is denoted as:
where
N is the number of images in the training database and
is the number of images in the training database containing node
i. For each database image, we compute a relevance score with all query images in turn based on the normalized difference between the query and database vector:
N query images with the highest scores are determined by sorting, which means these query images are most similar to the database image. Therefore, we assign these selected query images to the subset with the same label as the database images. Then, we regard these selected query images as new database images and compute the relevance score to search for similar images. We iteratively perform the above process until most images are assigned. Through image clustering, the number of images in each image subset is generally limited to 35–65. The purpose of this is to avoid having too many images in each image subset, which could affect the efficiency of reconstruction, and to avoid fragmented partial reconstruction on each image subset due to having too few images.
2.1.2. Path Searching-Based Molecule Generation
In the process of the generation of molecules, we use graph searching to cluster images. During the image clustering of the atom sets, we detect ORB features from all the resized images. On this basis, we can construct a scene graph. We apply exhaustive feature matching using Fast Approximate Nearest Neighbor (FLANN) [
27] to accelerate matching. Then, geometry is verified by computing the geometrical constraint, which can map a sufficient number of features between a pair of images. Based on the pairwise image relations, we can construct the scene graph with the images as nodes and the matching relations of two images as edges.
A molecule is generated by searching for the path in the scene graph between the source images of atoms. During each search for the shortest path, the images on the path are assigned to the molecule. Here, we use the Dijkstra algorithm to search for the shortest path. The significance of searching for the shortest path is that it avoids having an excessive number of images in the molecule. Since the Dijkstra algorithm is applied to the weighted graph, in order to find the shortest path, the edge weight should be set to 1. After counting the paths between any pair of source images, the duplicate images are removed. For the large-scale image dataset, the atomic model has two layers. Concretely, there are multiple molecules in the atomic model. According to the distribution of the source image of each atom in space, we first divide the atoms into multiple groups, and each group of atoms will produce a molecule. According to the distribution of molecules in space, we determine a core molecule. It is necessary not only to count the paths in the scene graph between atoms, but also to count the paths between the source images of the core molecule and each other molecule. We assign all the images involved in these paths to the core molecule. In this way, we have built a two-layer atomic model in which all atoms can be associated with the core molecule.
2.2. Aligning of Partial Reconstruction
After the image clustering task, we make an independent partial 3D reconstruction on each image subset, including the atoms and molecules. In this work, the partial 3D reconstruction is conducted by global SfM [
12], including the process from feature detection to the final global BA. To speed up the process, each partial reconstruction could be processed in parallel. It should be pointed out that the images used in partial 3D reconstruction are original images without resizing. The output of partial 3D reconstruction is a sub-model that contains 3D point clouds of the scene structures and camera extrinsic parameters corresponding to images.
In this subsection, we introduce our method to align all partial 3D reconstructions seamlessly. Our method contains two steps: (1) similarity transformation initial estimation and (2) similarity transformation-based BA hybrid optimization.
2.2.1. Similarity Transformation Initial Estimation
To align a pair of partial reconstructions, a similarity transformation should be computed. Mostly, a similarity transformation between the coordinate systems of the partial reconstructions is computed by means of 3D point matches. However, due to the mismatching on features, the found 3D points do not correspond. In addition, some 3D points may be outliers in the reconstruction process. Therefore, 3D point matching-based similarity transformations are unreliable unless rigorous identification is performed.
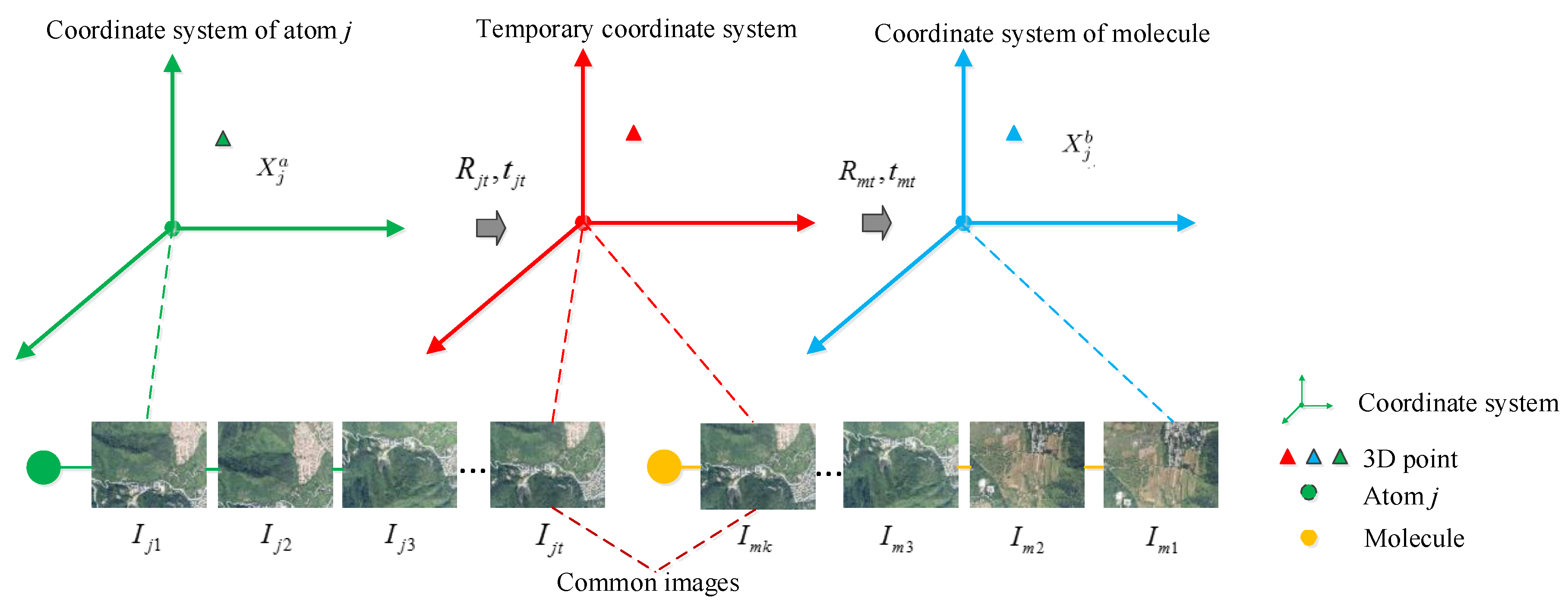
In this paper, we propose a concise method to perform a similarity transformation without 3D point matches, as illustrated in
Figure 3. Taking a group of atoms and the corresponding molecule as an example, here, we suppose there are
L atoms in total. The
atom shares some common images with the molecule, which are denoted as
. Firstly, the scale between the partial reconstructions on an atom and molecule pair should be unified. For each image, we can get its camera center in the frame of the
atom or molecule. Since the camera model that we used is the basic pinhole model, according to the principle of multiple view geometry [
28], supposing an image is
, its camera center is defined as:
where
and
are the transpose of the rotation matrix and the translation vector of image
in the frame of the
atom, respectively. Thus, for any two common images
and
, the distance of the corresponding camera centers in the frame of the
atom could be computed as:
and similarly, we can get the distance
of the corresponding camera centers for
and
in the frame of the molecule, which can be represented by:
where
and
are computed with Equation (
5) using the rotation matrix and translation vector of images
and
in the frame of the molecule, respectively. By combining Equation (
6) and Equation (
7), the scale between the partial reconstructions on a pair of atom and molecule can be computed as:
After finishing the scale estimation on all pairs of common images between the atom and molecule, the scale is averaged.
Then, we adopt a direct way to get the rotation matrix and translation vector of the similarity transformation by means of the corresponding camera poses of common images shared by atoms and molecules. In other words, we use common images to build a bridge to unify the two coordinate systems. For simplicity, we refer to a common image as a reference view. Without any loss of generality, in practice, we usually select the first common image
as the reference view. First, any 3D point
of the
atom should be firstly transformed into the temporary frame of the reference view by means of the rotation matrix
and translation vector
of common image
in the frame of an atom. Then, applying the rotation matrix inverse
and translation vector
of
in the frame of molecule, we get
in the frame of molecule, which is represented as:
which, when written in matrix form, is:
where
represents the transformation as:
where
and
are respectively represented as:
2.2.2. Similarity Transformation Hybrid Optimization
In this part, we elaborate on our optimization strategy. The goal of optimization is to get optimal similarity transformations to make all scene structures of multiple partial reconstructions merge seamlessly. In the initial registration process, we only calculate the similarity transformation based on the camera poses of common images. Therefore, we try to use more 3D points in the optimization process to get a more accurate similarity transformation. In addition, even though we use the 3D points, we still do not need the 3D point matches when optimizing.
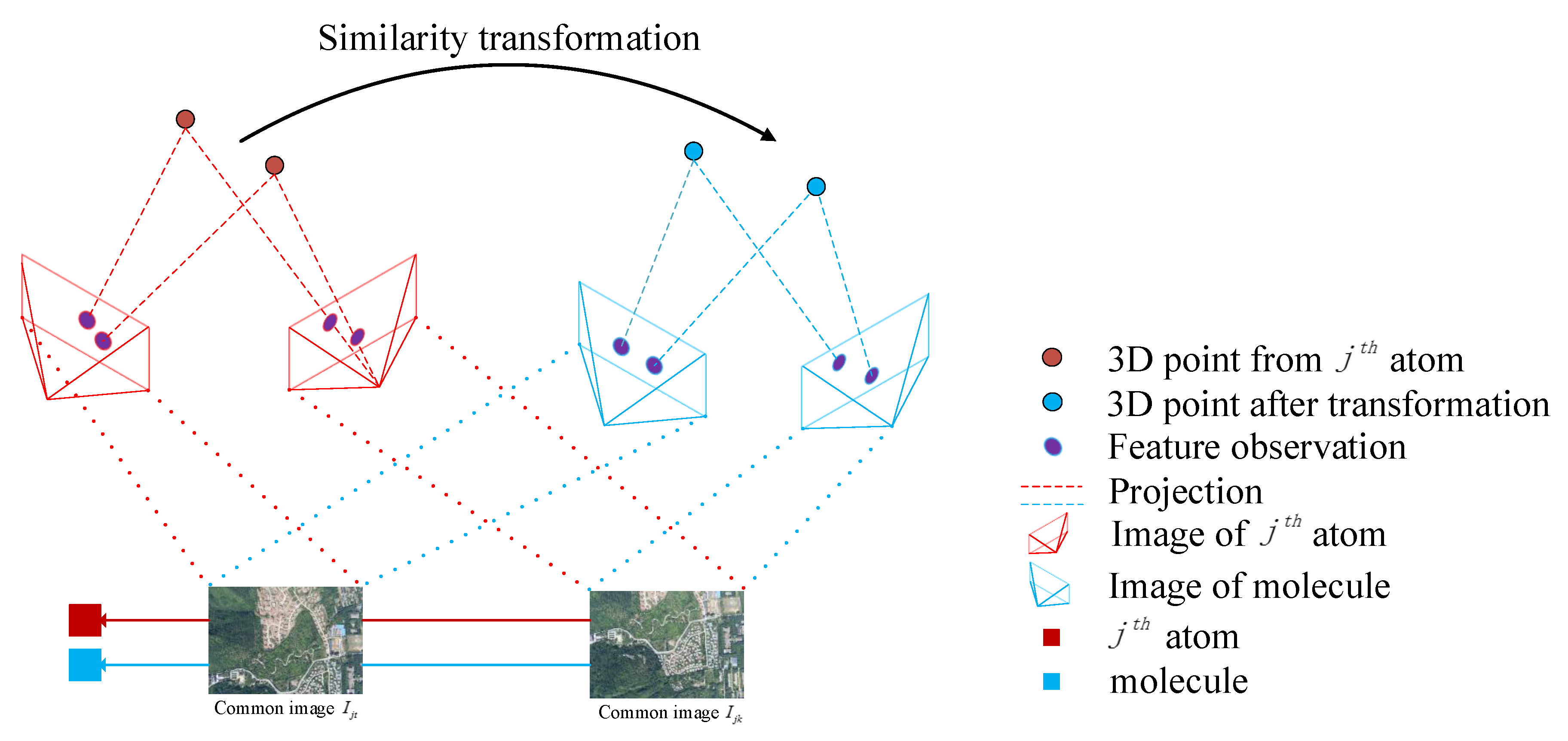
We propose a optimization strategy that is evolved from BA. We firstly introduce a local optimization, which exists between a pair of partial reconstructions, as shown in
Figure 4. Without loss of generality, we still use the
atom and its corresponding molecule as an example. The process of local optimization contains the following steps. In the first step, we get the 3D points reconstructed by common images
of the
atom. From these 3D points, we select some 3D points as data to be optimized, which are observed by at least two common images. By similarity transformation, we can transform these 3D points into the frame of the molecule. In the second step, we perform a BA optimization process in the frame of the molecule. In other words, the transformed 3D points from atom can project into the image planes via the camera poses of common images of the molecule. As the similarity transformation changes, the positions of these transformed 3D points change, and the 2D projected positions change, as well. Therefore, the optimal transformation will minimize the re-projection error. Here, we take advantage of the fact that the features detected from common images of the molecule and atom are consistent. Because the 2D feature observations are the same, the minimum re-projection error means that these transformed 3D points from atoms can replace the original 3D points of the molecule well. Thus, our optimization strategy can be summarized as a BA procedure with similarity transformation, which can be represented as:
where
j is the number of atoms,
i is the number of the common 3D points of the
atom and
P is the camera pose of common image
in the frame of the molecule.
is a common 3D point of the
atom. In the process of optimization,
P is fixed, and
is marginalized for efficiency. Through optimization, we can get the optimal similarity transformation between a pair of partial reconstructions.
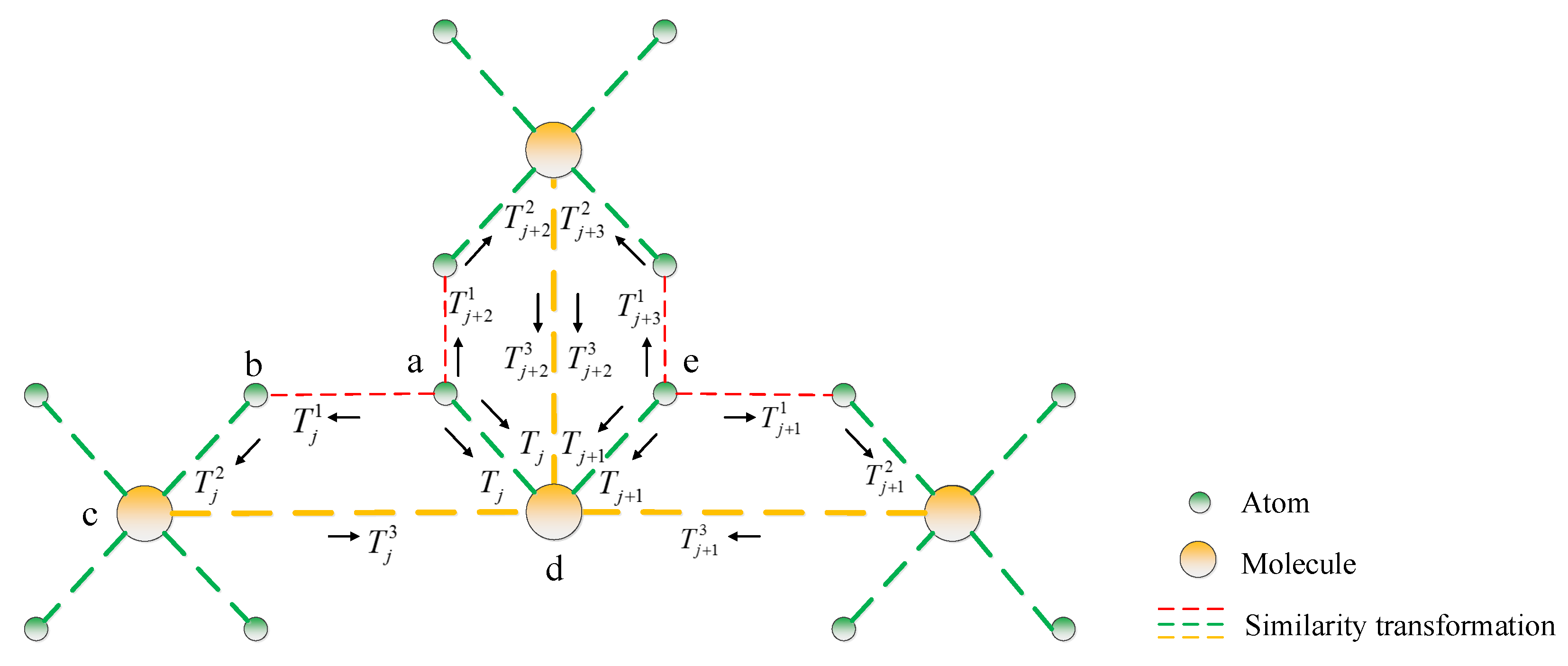
The above optimization process exists in the fusion of a pair of partial reconstructions, including between a pair of molecules and between a pair of an atom and its corresponding molecule. Based on the above local optimization, we propose a loop global optimization strategy. We introduce a closed-loop constraint to incorporate multiple similarity transformations into an optimization process. As we can see from
Figure 5, atoms
a and
b and molecules
c and
d form a closed-loop through similarity transformations between each pair of them.
Thus, the transformation between atom
a and molecule
d can be replaced by a continuous transformation of atom
a to atom
b, atom
b to molecule
c, and molecule
c to molecule
d. Therefore, the similarity transformation between atom
a and molecule
d can be optimized by:
where
,
,
represents the similarity transformation between atom
a to atom
b, atom
b to molecule
c, and molecule
c to molecule
d, respectively. Such an optimized process only occurs on adjacent atoms of different atom groups. In order to construct such a closed loop, it is necessary to copy some of the images on the boundary between the adjacent atoms when constructing the atomic model. By combining Equation (
14) and Equation (
15), we propose a hybrid optimization strategy that can be represented as:
where
represents the index of all pairs of partial reconstructions and
represents the index of closed loops. To solve all of the optimizations defined in Equations (
14)–(
16), we use the standard Levenberg–Marquardt algorithm [
29] implemented in g2o [
30] as the solver.
5. Conclusions
In this paper, we proposed a hierarchical clustering-aligning framework for fast large-scale 3D reconstruction using aerial images. The framework contains two parts, the image clustering and the aligning of the partial reconstructions. The significance of the image clustering is to decompose the large-scale SfM into a smaller problem and to lay the foundation for the follow-up aligning work. Through image clustering, the overlapping relationship between image subsets is established. Using the overlapping relationship, we initially estimate similarity transformations based on the joint camera poses of common images instead of using 3D matching. Then, we introduce the closed-loop constraint and propose a similarity transformation-based BA hybrid optimization method to optimize the similarity transformations. The advantage of the proposed method is that it can quickly reconstruct scene structures for a large-scale aerial image dataset without compromising the accuracy. Experimental results on large-scale aerial datasets show the advantages of our method in terms of efficiency and accuracy.
In the current work, we used the classic global SfM [
12] to make a partial 3D reconstruction on each image subset. In general, global SfM is vulnerable to the challenge of feature mismatching, so global SfM [
12] takes a strict filtering of mismatches. When applied to a challenging dataset, once the filtering standard is reached, it will filter some images from the reconstruction set, which contributes to the stability of the reconstruction but introduces the problem that, if the common images between atoms and molecules are all filtered out, our algorithm process will terminate, because our method relies on the partial reconstruction results, including the camera poses and 3D points corresponding to the common images. In future work, a better partial reconstruction method will be adopted. The requirements for the partial reconstruction method are not only precision and efficiency, but also the completeness of the reconstruction. After all, a good partial reconstruction result guarantees the implementation of our method. In addition, in our optimization approach, we used the closed-loop constraint. In fact, there are other constraints that can be used in the atomic model. In future work, we hope to exploit the constraints fully in the atomic model to make the hybrid optimization algorithm more robust.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}