1. Introduction
Synthetic aperture radar (SAR) operates in all weathers and during day and night, and SAR imagery is widely used for ship detection in marine monitoring, such as for transportation safety and fishing law enforcement [
1,
2,
3,
4]. With the launch of SAR satellites, such as China’s Gaofen-3 in August of 2016, Japan’s Advanced Land Observing Satellite 2 (ALOS-2) in May of 2014, and Sentinel-1 of the European Space Agency in April of 2014, numerous SAR images are available to dynamically monitor the ocean. Traditional ship detection approaches are mainly constant false alarm rates (CFAR) based on the statistical distributions of the sea clutter [
5,
6,
7,
8] and the extracted features based [
9,
10,
11,
12]. These two methods are highly dependent on the distributions or features predefined by humans [
3,
9,
13,
14], degrading the performance of ship detection for a new SAR imagery [
9,
14]. Therefore, they may be less robust.
Being able to automatically learn representation [
15,
16], object detectors in deep learning have achieved top performance with regards to detection accuracy and speed, such as Faster regions with convolutional neural networks (R-CNN) [
17], single shot multibox detector (SSD) [
18], You Only Look Once (YOLO) [
19,
20], and RetinaNet [
21]. These detectors can be divided into one-stage detectors and two-stage detectors [
21]. Two-stage detectors are usually slower than one-stage detectors because of the generation of the candidate object location using an external module and because of the higher detection accuracy due to the consideration of the hard examples [
21]. Here, the hard examples are the examples poorly predicted by the model. Recently, Reference [
21] embraces the advantages of one-stage detectors and introduces the focal loss to help these models to have not only a fast speed but also a high detection accuracy, such as RetinaNet and YOLO-V3 [
19]. Therefore, object detectors in deep learning, such as Faster RCNN and SSD, have been adapted to address ship detection in SAR images [
1,
2,
3,
22]. Kang et al. [
2] used the faster RCNN method to obtain the initial ship detection results and then applied (constant false alarm rate) CFAR to obtain the final results. Li et al. [
22] proposed the use of feature fusion, transfer learning, hard negative mining, and other implementation details to improve the performance of Faster R-CNN. Wang et al. [
3] combined transfer learning with a single shot multibox detector for the detection of ships, with the consideration of both detection accuracy and speed. Kang et al. [
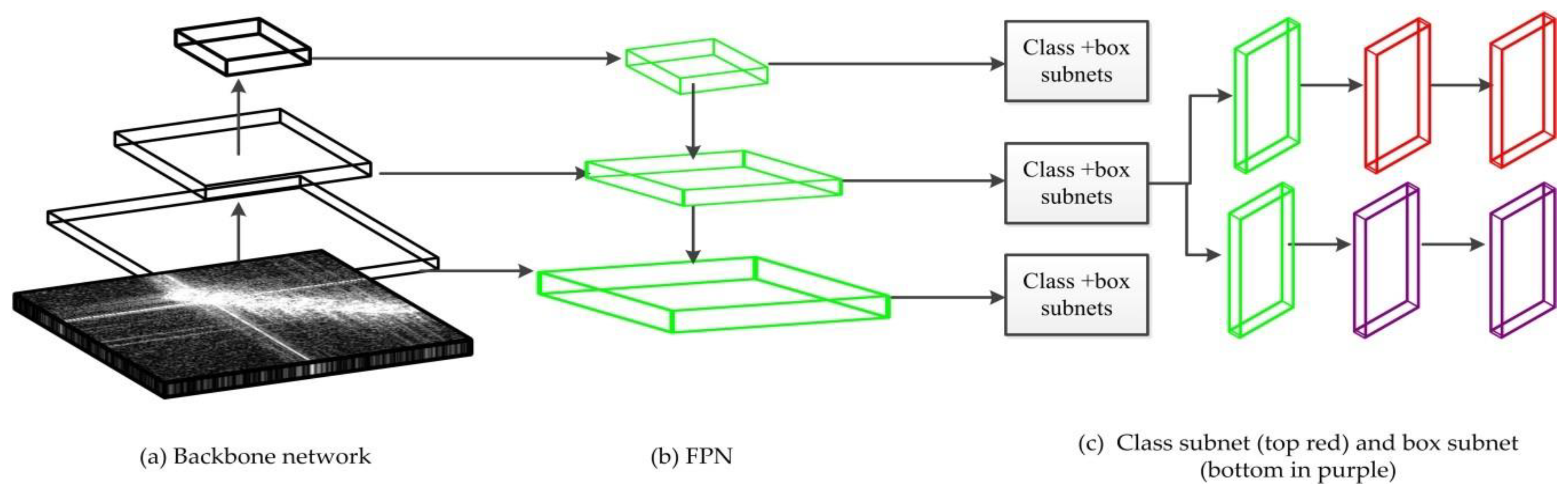
1] proposed a region-based convolutional neural network with contextual information and multilayer features for ship detection and combined the low-level high-resolution features and high-level semantic features to improve the detection accuracy and to remove some errors based on contextual information. The methods are mainly modified from Faster RCNN and SSD, which do not explore the state-of-the-art RetinaNet. There are two main building blocks in RetinaNet: feature pyramid networks (FPN) [
23] and focal loss. The former is used to extract multi-scale features for both ship classification and location. The latter is used to address the class imbalance and to increase the importance of the hard examples.
Targets on SAR imagery are sensitive to pose and configuration [
8,
24]. For ships, their shapes are multi-scale. The first reason is that, due to the influence of various resolutions, the shapes of the same ship are multi-scale, and the second is that vessels with various shapes display differently in the same resolution SAR imagery. Therefore, it is necessary to consider the variance of ship scales. Currently, there are several studies to deal with this [
1,
2,
3,
4,
9,
22,
25]. Except in Reference [
4], the datasets in the papers of Reference [
9,
22,
25] are limited, or some only provide samples for a single-resolution SAR image ship detection [
1,
2,
3]. The China Gaofen-3 satellite, successfully launched in August 2016, could provide data support for long-term scientific research. Therefore, 86 scenes of Chinese Gaofen-3 Imagery at four resolutions, i.e., 3 m, 5 m, 8 m, and 10 m, are studied experimentally in this paper.
One important reason restricting the adaption of object detectors in deep learning to ship detection is the scarce dataset. To relieve this predicament, 9974 SAR ship chips with 256 pixels in both range and azimuth are constructed. They are used to evaluate our methods. They can be used to boost the application of computer vision techniques, especially object detectors in deep learning to ship detection in SAR images, and can also facilitate the emergence of more advanced object detectors with the consideration of SAR characteristics, such as the speckle noise.
Based on the above analysis, RetinaNet is adapted to address ship detection in this paper. To better evaluate our proposed method, two Gaofen-3 images and one CosMo-SkyMed image are used to test the robustness. The main contributions in this paper are as follows:
A large volume of the ship chips in multi-resolution SAR images is constructed with the aim to exploit the benefits of object detectors in deep learning. We believe this dataset will boost the application of computer vision techniques to SAR application.
A state-of-the-art performance object detector, i.e., RetinaNet, is applied to the ship detection in multi-resolution Gaofen-3 SAR imagery. It achieves more than a 96% mean average precision (mAP) and ranks first compared with the other three models.
The organization of this paper is as follows.
Section 2 relates to the background of RetinaNet and the proposed method.
Section 3 reports on the experiments, including the dataset and experimental analysis.
Section 4 and
Section 5 come to a discussion and conclusion.
4. Discussion
As shown earlier, RetinaNet achieves the best mAP (more than 96%) in multi-resolution SAR imagery. This high performance is due to the two core building blocks, i.e., FPN to extract the multi-scale semantic feature and focal loss to deal with the class imbalance and unfair contribution of hard/easy examples to the loss.
There are many factors that influence the performance of ship detection, such as image resolution, incidence angle, polarimetry, wind speed, sea state, ship size, and ship orientation. In Reference [
4], an empirical model was employed to validate the ship size, incidence angle, wind speed, and sea state on the ship detectability. In this paper, we only explore the image resolution. The other factors have an impact on the scattering characteristics of the targets, thus affecting the detection results of ships. Next, we will continue to analyze the impact of other factors on ship detectability.
In addition, we find that preprocessing can also have a certain impact on the detection results. SAR images are converted to 8 bytes with a linear 2% stretch, which may cause a reduction in the ship detection performance. A better way to get chips is also being explored, and this dataset is planned to be released on our website [
34]. One can also evaluate this based on our dataset.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}