The Influence of Region of Interest Heterogeneity on Classification Accuracy in Wetland Systems

 , , , , and
, , , , and
Abstract
:
1. Introduction
2. Materials and Methods
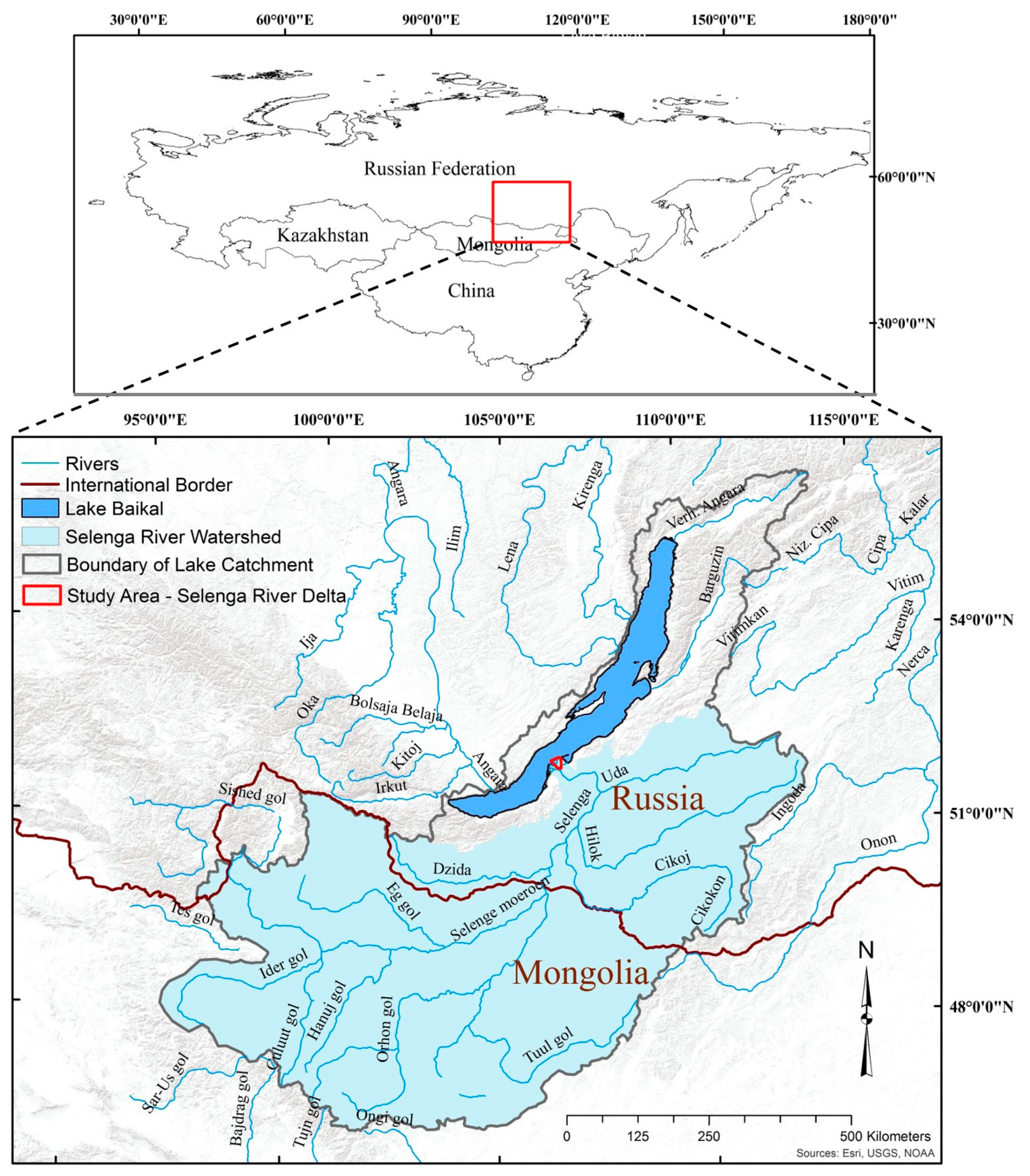
2.1. Study Area
2.2. Remote Sensing Data Acquisitions and Pre-Processing
2.3. Field Data Collection and Processing
2.4. Mixed-ROI Image Classification
2.4.1. Multinomial Logistic Model
2.4.2. Generalized Linear Model
2.4.3. Support Vector Machine
2.4.4. Random Forest
2.5. Accuracy Assessment
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Robertson, L.; King, D.; Davies, C. Object-based image analysis of optical and radar variables for wetland evaluation. Int. J. Remote Sens. 2015, 36, 5811–5841. [Google Scholar] [CrossRef]
- Wu, Q. GIS and remote sensing applications in wetland mapping and monitoring. In Comprehensive Geographic Information Systems; Elsevier: Oxford, UK, 2018; pp. 140–157. [Google Scholar] [CrossRef]
- Burnett, C.; Blaschke, T. A multi-scale segmentation/object relationship modelling methodology for landscape analysis. Ecol. Model. 2003, 168, 233–249. [Google Scholar] [CrossRef]
- Costa, H.; Foody, G.M.; Boyd, D.S. Using mixed objects in the training of object-based image classifications. Remote Sens. Environ. 2017, 190, 188–197. [Google Scholar] [CrossRef]
- Du, P.; Xia, J.; Zhang, W.; Tan, K.; Liu, Y.; Liu, S. Multiple classifier system for remote sensing image classification: A review. Sensors 2012, 12, 4764–4792. [Google Scholar] [CrossRef] [PubMed]
- Woodcock, C.E.; Strahler, A.H. The factor of scale in remote sensing. Remote Sens. Environ. 1987, 21, 311–332. [Google Scholar] [CrossRef]
- Foody, G.M. Relating the land-cover composition of mixed pixels to artificial neural network classification output. Photogramm. Eng. Remote Sens. 1996, 62, 491–499. [Google Scholar]
- Foody, G.M. Fully fuzzy supervised classification of land cover from remotely sensed imagery with an artificial neural network. Neural Comput. Appl. 1997, 5, 238–247. [Google Scholar] [CrossRef]
- Dalponte, M.; Bruzzone, L.; Vescovo, L.; Gianelle, D. The role of spectral resolution and classifier complexity in the analysis of hyperspectral images of forest areas. Remote Sens. Environ. 2009, 113, 2345–2355. [Google Scholar] [CrossRef]
- Foody, G.M.; Arora, M.K. Incorporating mixed pixels in the training, allocation and testing stages of supervised classifications. Pattern Recognit. Lett. 1996, 17, 1389–1398. [Google Scholar] [CrossRef]
- Foody, G.M.; McCulloch, M.; Yates, W. Classification of remotely sensed data by an artificial neural network: Issues related to training data characteristics. Photogramm. Eng. Remote Sens. 1995, 61, 391–401. [Google Scholar]
- Brown, M.; Gunn, S.R.; Lewis, H.G. Support vector machines for optimal classification and spectral unmixing. Ecol. Model. 1999, 120, 167–179. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. The use of small training sets containing mixed pixels for accurate hard image classification: Training on mixed spectral responses for classification by a SVM. Remote Sens. Environ. 2006, 103, 179–189. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training set size requirements for the classification of a specific class. Remote Sens. Environ. 2006, 104. [Google Scholar] [CrossRef]
- Ozesmi, S.L.; Bauer, M.E. Satellite remote sensing of wetlands. Wetlands Ecol. Manag. 2002, 10, 381–402. [Google Scholar] [CrossRef]
- Berhane, T.; Lane, C.; Wu, Q.; Autrey, B.; Anenkhonov, O.; Chepinoga, V.; Liu, H. Decision-tree, rule-based, and random forest classification of high-resolution multispectral imagery for wetland mapping and inventory. Remote Sens. 2018, 10, 580. [Google Scholar] [CrossRef] [PubMed]
- Lane, C.R.; Anenkhonov, O.; Liu, H.; Autrey, B.C.; Chepinoga, V. Classification and inventory of freshwater wetlands and aquatic habitats in the Selenga River Delta of Lake Baikal, Russia, using high-resolution satellite imagery. Wetlands Ecol. Manag. 2015, 23, 195–214. [Google Scholar] [CrossRef]
- Murray-Hudson, M.; Wolski, P.; Cassidy, L.; Brown, M.T.; Thito, K.; Kashe, K.; Mosimanyana, E. Remote Sensing-derived hydroperiod as a predictor of floodplain vegetation composition. Wetlands Ecol. Manag. 2015, 23, 603–616. [Google Scholar] [CrossRef]
- Dronova, I. Object-based image analysis in wetland research: A review. Remote Sens. 2015, 7, 6380–6413. [Google Scholar] [CrossRef]
- White, L.; Brisco, B.; Dabboor, M.; Schmitt, A.; Pratt, A. A collection of SAR methodologies for monitoring wetlands. Remote Sens. 2015, 7, 7615–7645. [Google Scholar] [CrossRef]
- Wohlfart, C.; Winkler, K.; Wendleder, A.; Roth, A. TerraSAR-X and wetlands: A review. Remote Sens. 2018, 10, 916–939. [Google Scholar] [CrossRef]
- Guo, M.; Li, J.; Sheng, C.; Xu, J.; Wu, L. A Review of wetland remote sensing. Remote Sens. 2017, 17, 777. [Google Scholar] [CrossRef] [PubMed]
- Amancio, D.R.; Comin, C.H.; Casanova, D.; Travieso, G.; Bruno, O.M.; Rodrigues, F.A.; da Fontoura Costa, L. A systematic comparison of supervised classifiers. PLoS ONE 2014, 9, e94137. [Google Scholar] [CrossRef] [PubMed]
- Lane, C.; Liu, H.; Autrey, B.; Anenkhonov, O.; Chepinoga, V.; Wu, Q. Improved wetland classification using eight-band high resolution satellite imagery and a hybrid approach. Remote Sens. 2014, 6, 12187–12216. [Google Scholar] [CrossRef]
- Chebykin, E.; Sorokovikova, L.; Vtomberg, I.; Rasskazov, S.; Khodzher, T.; Grachev, M. Current state of the Selenga River waters in the Russian territory concerning major components and trace elements. Chem. Sustain. Dev. 2012, 20, 561–580. [Google Scholar]
- Plyusnin, A.M.; Kislitsina, L.B.; Zhambalova, D.I.; Peryazeva, E.G.; Udodov, Y.N. Development of the chemical characteristics of ground water at the delta of the Selenga River. Geochem. Int. 2008, 46, 288–295. [Google Scholar] [CrossRef]
- Balkhanov, V.K.; Bashkuev, Y.V. Fractal dimension of the channel network structure of Selenga River Delta. Water Resour. 2004, 31, 148–151. [Google Scholar] [CrossRef]
- Chalov, S.; Jarsjo, J.; Kasimov, N.; Romanchenko, A.; Pietron, J.; Thorslund, J.; Promakhova, E. Spatio-temporal variation of sediment transport in the Selenga River Basin, Mongolia and Russia. Environ. Earth Sci. 2015, 73, 663–680. [Google Scholar] [CrossRef]
- Lychagin, M.; Chalov, S.; Kasimov, N.; Shinkareva, G.; Jarsjö, J.; Thorslund, J. Surface water pathways and fluxes of metals under changing environmental conditions and human interventions in the Selenga River system. Environ. Earth Sci. 2016, 76. [Google Scholar] [CrossRef]
- Törnqvist, R.; Jarsjö, J.; Pietroń, J.; Bring, A.; Rogberg, P.; Asokan, S.M.; Destouni, G. Evolution of the hydro-climate system in the Lake Baikal basin. J. Hydrol. 2014, 519, 1953–1962. [Google Scholar] [CrossRef]
- Tulochonov, A.K.; Plusnin, A.M. (Eds.) The Selenga River Delta—Natural Biofilter and Indicator of the Condition of Lake Baikal; Publishing House of the Siberian Branch of the Russian Academy of Sciences: Novosibirsk, Russia, 2008; ISBN 978-5-7692-0669-6. (In Russian) [Google Scholar]
- Ivanov, O. Clarification of the actual portion of Lake Baikal’s water in the world freshwater supply. Bull. Utiliz. Prot. Nat. Resour. Russia 2009, 3, 14–15. [Google Scholar]
- Berezhnykh, T.V.; Marchenko, O.Y.; Abasov, N.V.; Mordvinov, V.I. Changes in the summertime atmospheric circulation over East Asia and formation of long-lasting low-water periods within the Selenga river basin. Geogr. Nat. Resour. 2012, 33, 223–229. [Google Scholar] [CrossRef]
- Chalov, S.; Thorslund, J.; Kasimov, N.; Aybullatov, D.; Ilyicheva, E.; Karthe, D.; Kositsky, A.; Lychagin, M.; Nittrouer, J.; Pavlov, M.; et al. The Selenga River delta: A geochemical barrier protecting Lake Baikal waters. Reg. Environ. Chang. 2016, 17, 2039–2053. [Google Scholar] [CrossRef]
- Khazheeva, Z.I.; Tulokhonov, A.K.; Yao, R.; Hu, W. Seasonal and spatial distribution of heavy metals in the Selenga River Delta. J. Geogr. Sci. 2008, 18, 319–327. [Google Scholar] [CrossRef]
- Ubugunov, L.; Borisova, N.; Anenkhonov, O.; Baldanova, D.; Bazova, N.; Ubugunov, V. Probable biological and ecological consequences of hydropower plant constructing on the Selenga River and its tributaries in Mongolia. Bull. Irkutsk State Univ. Ser Biol. Ecol. 2015, 12, 58–72. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Time series analysis. In Modern Applied Statistics with S; Springer: New York, NY, USA, 2002; pp. 387–418. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization paths for generalized linear models via coordinate descent. J. Stat. Softw. 2010, 33. [Google Scholar] [CrossRef]
- Czarnecki, W.; Jastrzebski, S.; Data, M.; Sieradzki, I.; Bruno-Kaminski, M.; Jurek, K.; Kowenzowski, P.; Pletty, M.; Talik, K.; Zgliczynski, M. gmum.r: GMUM Machine Learning Group Package. 2015. Available online: https://github.com/gmum/gmum.r (accessed on 1 July 2018).
- Wright, M.N.; Ziegler, A. ranger: A fast implementation of random forests for high dimensional data in C++ and R. J. Stat. Softw. 2017, 77. [Google Scholar] [CrossRef]
- Lek, S.; Guégan, J.F. Artificial neural networks as a tool in ecological modelling, an introduction. Ecol. Model. 1999, 120, 65–73. [Google Scholar] [CrossRef]
- Abdel-Rahman, E.M.; Mutanga, O.; Adam, E.; Ismail, R. Detecting Sirex noctilio grey-attacked and lightning-struck pine trees using airborne hyperspectral data, random forest and support vector machines classifiers. ISPRS J. Photogramm. Remote Sens. 2014, 88, 48–59. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. A relative evaluation of multiclass image classification by support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1335–1343. [Google Scholar] [CrossRef]
- Heumann, B.W. An object-based classification of mangroves using a hybrid decision tree—Support vector machine approach. Remote Sens. 2011, 3, 2440–2460. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Berhane, T.; Lane, C.; Wu, Q.; Anenkhonov, O.; Chepinoga, V.; Autrey, B.; Liu, H. Comparing pixel- and object-based approaches in effectively classifying wetland-dominated landscapes. Remote Sens. 2017, 10, 46. [Google Scholar] [CrossRef] [PubMed]
- Corcoran, J.; Knight, J.; Gallant, A. Influence of multi-source and multi-temporal remotely sensed and ancillary data on the accuracy of random forest classification of wetlands in Northern Minnesota. Remote Sens. 2013, 5, 3212–3238. [Google Scholar] [CrossRef]
- Tian, S.; Zhang, X.; Tian, J.; Sun, Q. Random forest classification of wetland landcovers from multi-sensor data in the arid region of Xinjiang, China. Remote Sens. 2016, 8, 954. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Kotsiantis, S. Combining bagging, boosting, rotation forest and random subspace methods. Artif. Intell. Rev. 2010, 35, 223–240. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Foody, G.M. Classification accuracy comparison: Hypothesis tests and the use of confidence intervals in evaluations of difference, equivalence and non-inferiority. Remote Sens. Environ. 2009, 113, 1658–1663. [Google Scholar] [CrossRef]
- Carroll, L. Through the Looking-Glass, and What Alice Found There; MacMillan: London, UK, 1871. [Google Scholar]
- Foody, G.M.; Campbell, N.; Trodd, N.; Wood, T. Derivation and applications of probabilistic measures of class membership from the maximum-likelihood classification. Photogramm. Eng. Remote Sens. 1992, 58, 1335–1341. [Google Scholar]
- Jensen, J.R. Remote Sensing of the Environment: An Earth Resource Perspective; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Dixon, B.; Candade, N. Multispectral landuse classification using neural networks and support vector machines: One or the other, or both? Int. J. Remote Sens. 2008, 29, 1185–1206. [Google Scholar] [CrossRef]
- Adam, E.; Mutanga, O.; Odindi, J.; Abdel-Rahman, E.M. Land-use/cover classification in a heterogeneous coastal landscape using RapidEye imagery: Evaluating the performance of random forest and support vector machines classifiers. Int. J. Remote Sens. 2014, 35, 3440–3458. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Sesnie, S.E.; Finegan, B.; Gessler, P.E.; Thessler, S.; Ramos Bendana, Z.; Smith, A.M.S. The multispectral separability of Costa Rican rainforest types with support vector machines and Random Forest decision trees. Int. J. Remote Sens. 2010, 31, 2885–2909. [Google Scholar] [CrossRef]
- Ma, L.; Fu, T.; Li, M. Active learning for object-based image classification using predefined training objects. Int. J. Remote Sens. 2018, 39, 2746–2765. [Google Scholar] [CrossRef]
- Creed, I.F.; Lane, C.R.; Serran, J.N.; Alexander, L.C.; Basu, N.B.; Calhoun, A.J.K.; Christensen, J.R.; Cohen, M.J.; Craft, C.; D’Amico, E.; et al. Enhancing protection for vulnerable waters. Nat. Geosci. 2017, 10, 809–815. [Google Scholar] [CrossRef] [PubMed]
- Giosan, L.; Syvitski, J.; Constantinescu, S.; Day, J. Climate change: Protect the world’s deltas. Nature 2014, 516, 31–33. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | Deep water with sand bottom | 12 | Dense floating vascular (Nymphoides) |
| 2 | Shallow water with sediment | 13 | Very dense floating vascular (Nymphoides) |
| 3 | Shallow water with mud bottom | 14 | Persistent emergent (Phragmites) |
| 4 | Very shallow water with sand bottom | 15 | Persistent emergent (Bare Soil/Carex) |
| 5 | Shallow water with sand bottom | 16 | Persistent emergent (Equisetum) |
| 6 | Submerged aquatic vascular (Lemna) | 17 | Persistent emergent (Thatch) |
| 7 | Submerged aquatic vascular (Sparganium) | 18 | Persistent emergent (Carex) |
| 8 | Submerged aquatic vascular (Ceratophyllum) | 19 | Persistent emergent (Calamagrostis) |
| 9 | Submerged floating vascular (Nymphoides) | 20 | Persistent emergent (Scolochloa) |
| 10 | Very sparse floating vascular (Nymphoides) | 21 | Persistent terrestrial (Amoria) |
| 11 | Sparse floating vascular (Nymphoides) | 22 | Shrub/scrub (Salix) |
| ROI-ID | Area (m2) | % Areal Increase | # of Pure-ROIs | % of Pure-ROIs | # of Mixed-ROIs | % of Mixed-ROIs |
|---|---|---|---|---|---|---|
| D12 | 113 | 0 | 213 | 93.4 | 15 | 6.6 |
| D14 | 154 | 36 | 211 | 92.5 | 17 | 7.5 |
| D15 | 177 | 56 | 126 | 55.3 | 102 | 44.7 |
| D16 | 201 | 78 | 67 | 29.4 | 161 | 70.6 |
| D17 | 227 | 101 | 48 | 21.1 | 180 | 78.9 |
| D18 | 254 | 125 | 39 | 17.1 | 189 | 82.9 |
| D20 | 314 | 178 | 31 | 13.6 | 197 | 86.4 |
| D24 | 452 | 300 | 21 | 9.2 | 207 | 90.8 |
| D28 | 616 | 444 | 13 | 5.7 | 215 | 94.3 |
| D32 | 804 | 611 | 9 | 3.9 | 219 | 96.1 |
| D52 | 2124 | 1778 | 1 | 0.4 | 227 | 99.6 |
| ROI-ID | MLM | GLM | SVM | RF | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OA | CI | OA | CI | OA | CI | OA | CI | |||||
| D12 | 48.4 | 47.2 | 49.6 | 77.3 | 76.1 | 78.4 | 86.5 | 85.6 | 87.4 | 87.8 | 87.0 | 88.6 |
| D14 | 49.6 | 48.3 | 50.8 | 78.7 | 77.7 | 79.7 | 87.3 | 86.3 | 88.3 | 87.1 | 86.2 | 87.9 |
| D15 | 55.6 | 54.2 | 57.0 | 77.7 | 76.6 | 78.8 | 86.4 | 85.4 | 87.4 | 87.2 | 86.3 | 88.2 |
| D16 | 56.8 | 55.6 | 58.0 | 75.7 | 74.4 | 77.0 | 83.5 | 82.4 | 84.7 | 85.6 | 84.8 | 86.5 |
| D17 | 60.5 | 59.2 | 61.8 | 77.0 | 75.8 | 78.1 | 84.4 | 83.3 | 85.5 | 86.2 | 85.4 | 87.0 |
| D18 | 60.6 | 59.3 | 61.9 | 75.0 | 73.8 | 76.1 | 82.6 | 81.6 | 83.6 | 85.9 | 85.1 | 86.8 |
| D20 | 62.7 | 61.4 | 63.9 | 74.7 | 73.6 | 75.8 | 81.2 | 80.0 | 82.4 | 84.9 | 84.0 | 85.8 |
| D24 | 63.7 | 62.5 | 65.0 | 72.3 | 71.2 | 73.3 | 78.0 | 76.9 | 79.2 | 84.0 | 83.1 | 84.9 |
| D28 | 62.2 | 60.9 | 63.6 | 70.3 | 69.2 | 71.4 | 77.1 | 76.0 | 78.2 | 81.7 | 80.6 | 82.8 |
| D32 | 62.1 | 60.8 | 63.3 | 68.9 | 67.7 | 70.1 | 73.1 | 71.9 | 74.2 | 79.4 | 78.3 | 80.4 |
| D52 | 58.5 | 57.3 | 59.6 | 62.2 | 61.1 | 63.3 | 60.2 | 58.9 | 61.4 | 71.5 | 70.4 | 72.7 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berhane, T.M.; Costa, H.; Lane, C.R.; Anenkhonov, O.A.; Chepinoga, V.V.; Autrey, B.C. The Influence of Region of Interest Heterogeneity on Classification Accuracy in Wetland Systems. Remote Sens. 2019, 11, 551. https://doi.org/10.3390/rs11050551
Berhane TM, Costa H, Lane CR, Anenkhonov OA, Chepinoga VV, Autrey BC. The Influence of Region of Interest Heterogeneity on Classification Accuracy in Wetland Systems. Remote Sensing. 2019; 11(5):551. https://doi.org/10.3390/rs11050551
Chicago/Turabian StyleBerhane, Tedros M., Hugo Costa, Charles R. Lane, Oleg A. Anenkhonov, Victor V. Chepinoga, and Bradley C. Autrey. 2019. "The Influence of Region of Interest Heterogeneity on Classification Accuracy in Wetland Systems" Remote Sensing 11, no. 5: 551. https://doi.org/10.3390/rs11050551