A New CNN-Bayesian Model for Extracting Improved Winter Wheat Spatial Distribution from GF-2 imagery

 ,
,
Abstract
:
1. Introduction
2. Study Area and Data
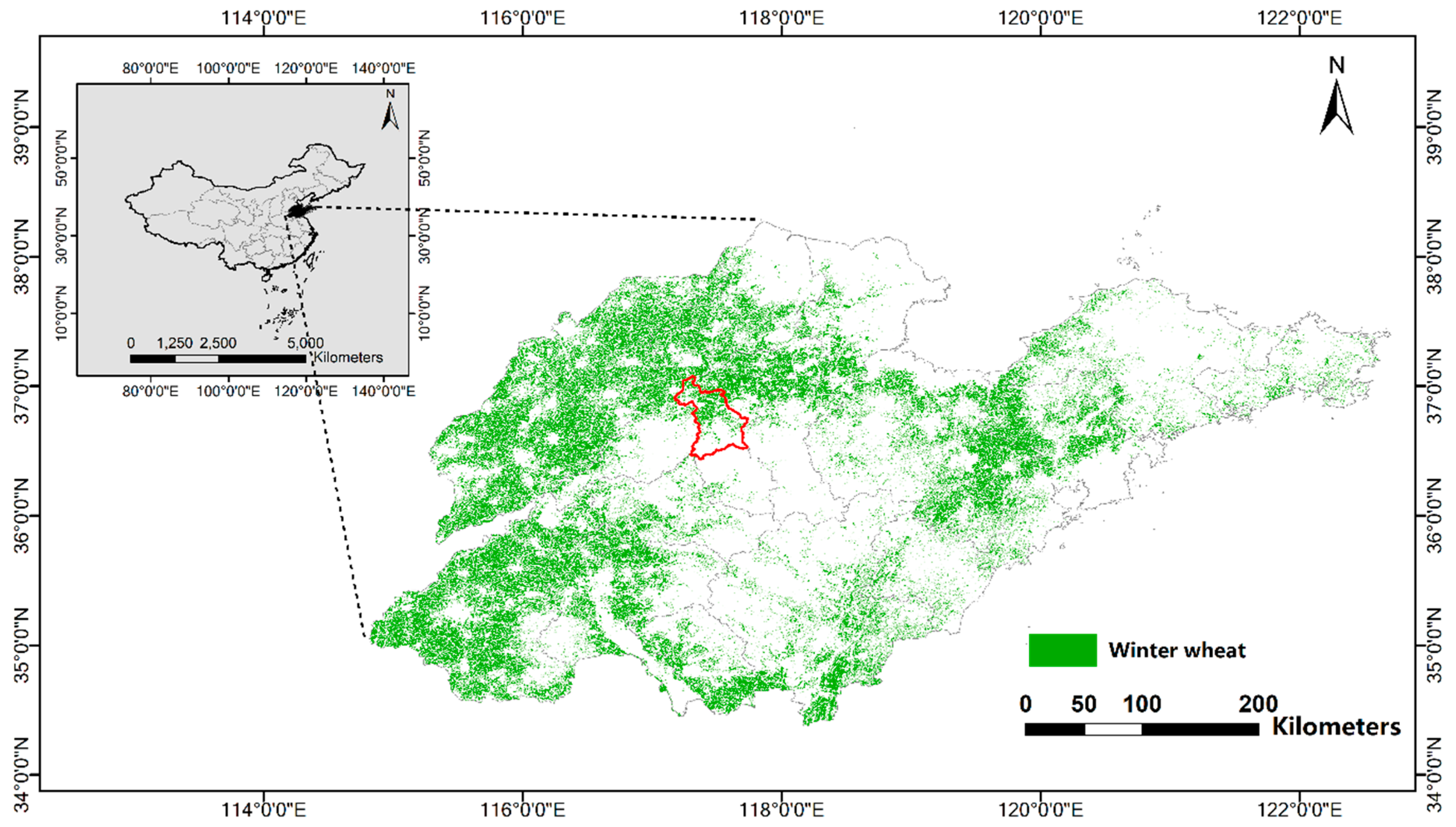
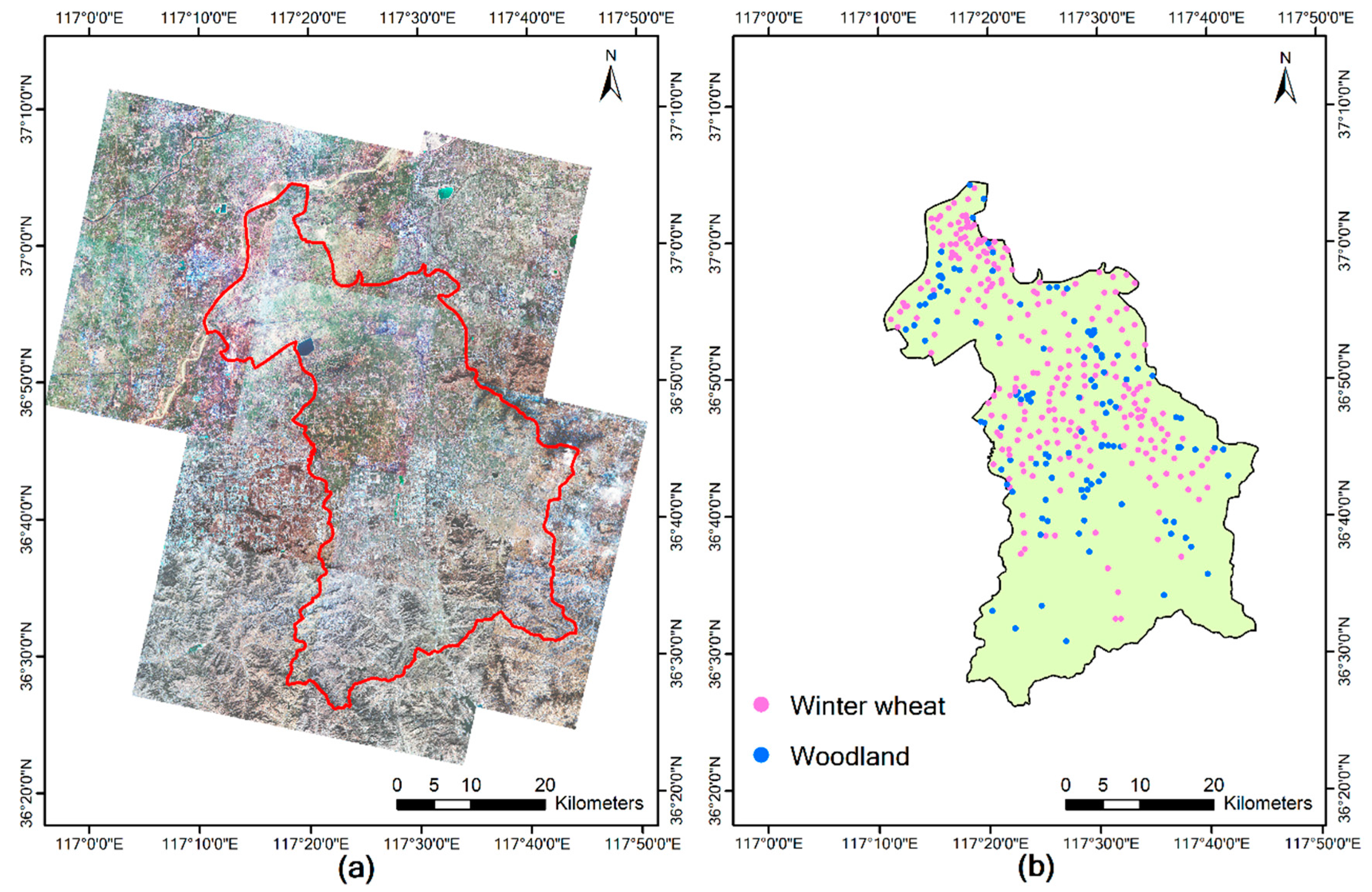
2.1. Study Area
2.2. Data Sources
2.2.1. Remote Sensing Imagery
2.2.2. Ground Investigation Data
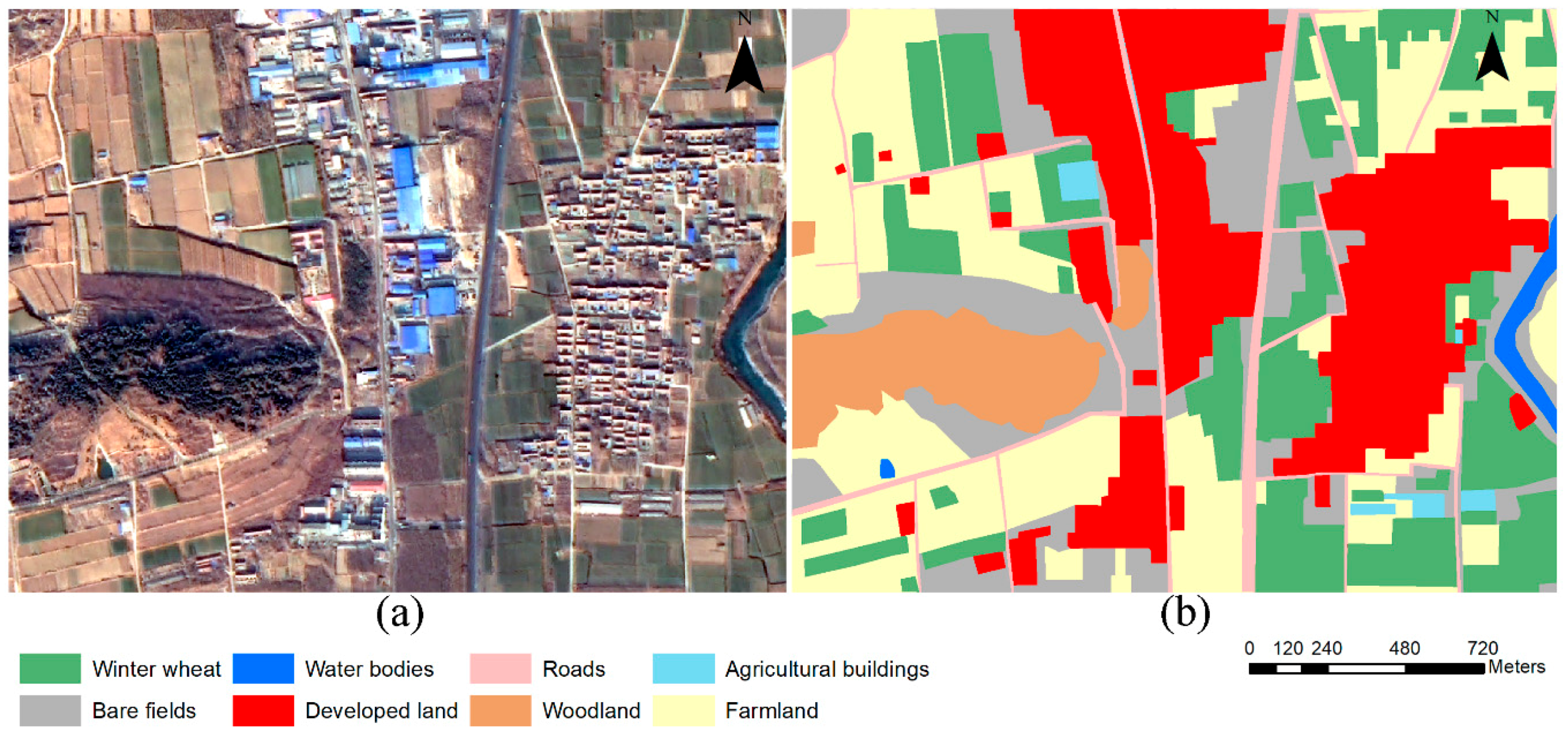
2.3. Image-Label Datasets
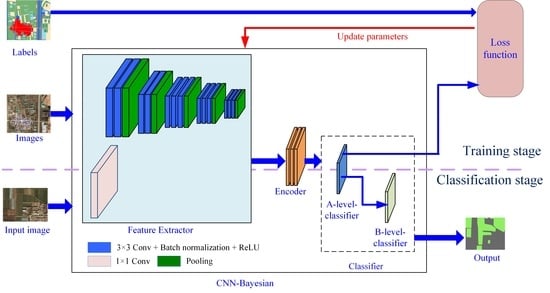
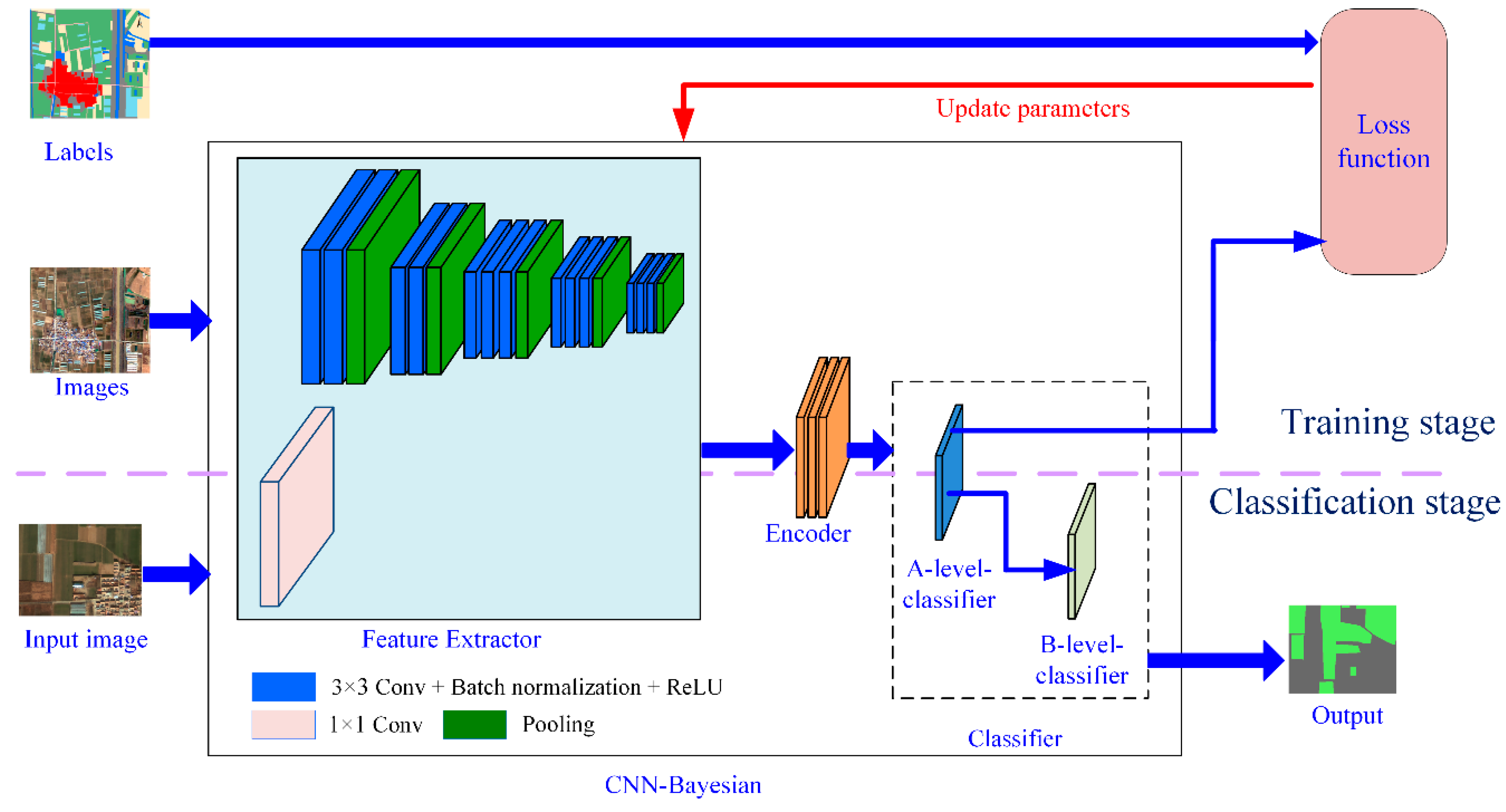
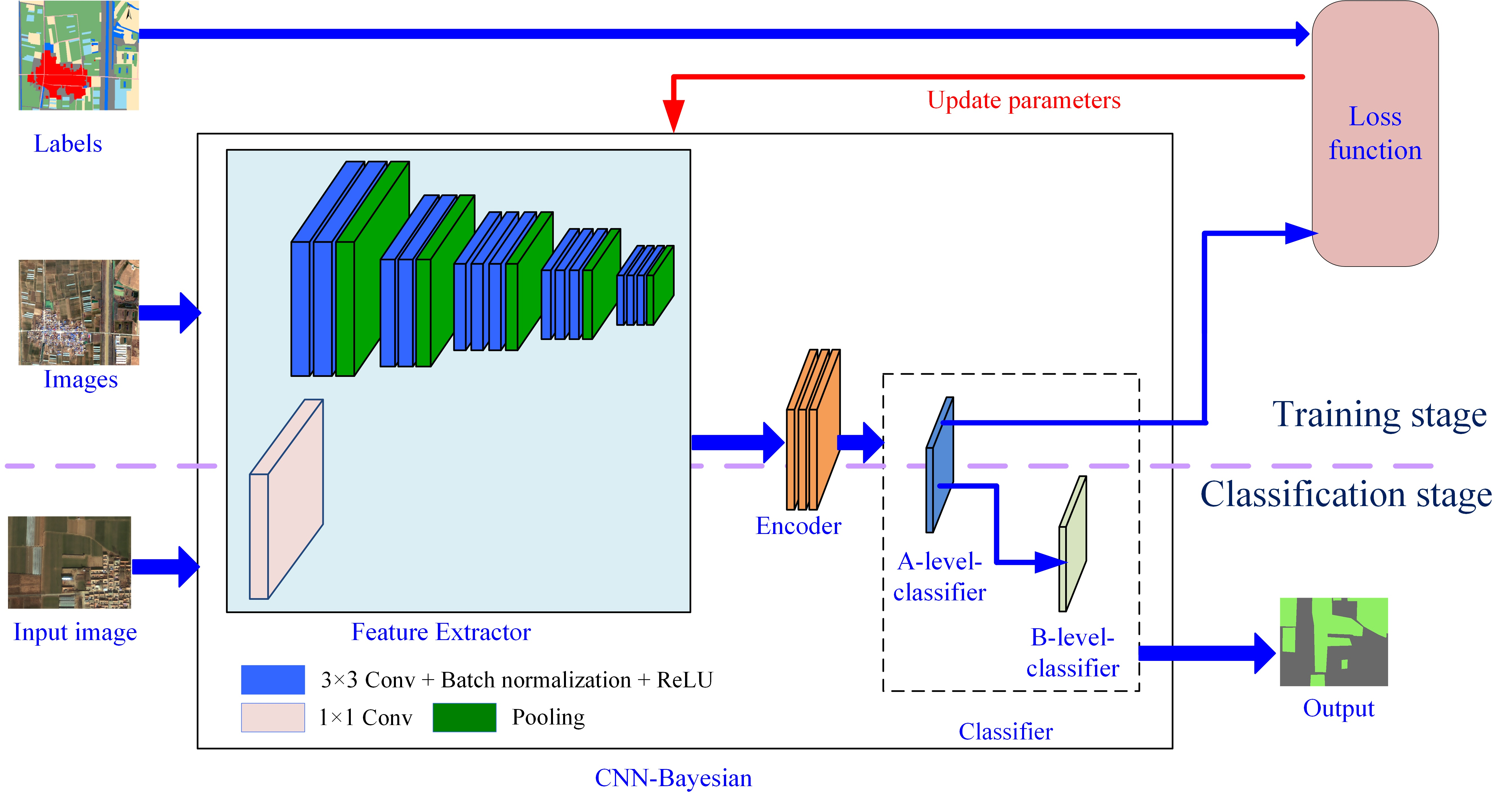
3. Proposed CNN-Bayesian Model
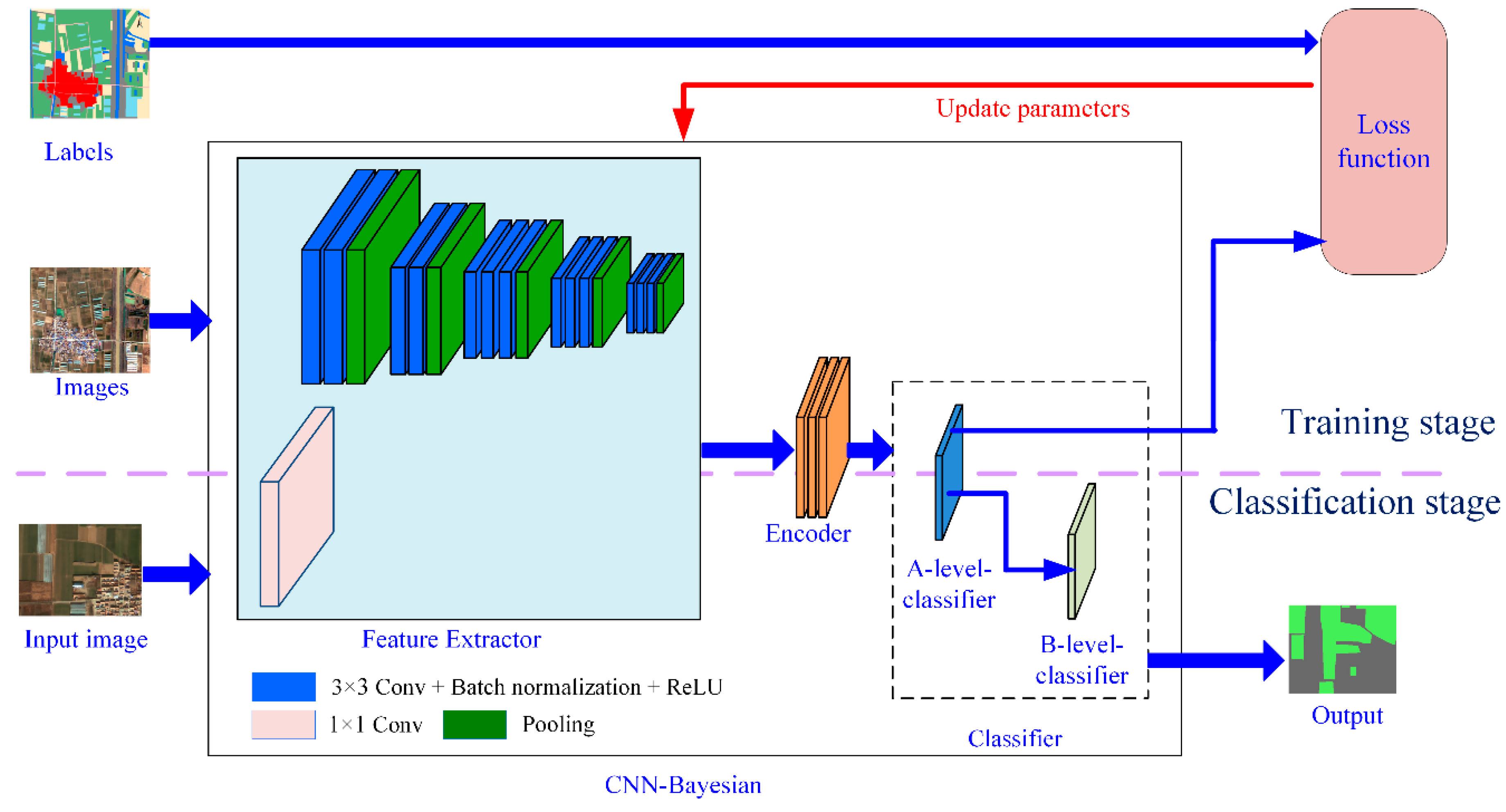
3.1. Model Architecture
3.1.1. Feature Extractor
3.1.2. Encoder
3.1.3. Classifier
3.2. Training Model
- Image-label pairs are input into the CNN-Bayesian model as a training sample dataset, and parameters are initialized.
- Forward propagation is performed on the sample images.
- The loss is calculated and back-propagated to the CNN-Bayesian model.
- The network parameters are updated using the stochastic gradient descent [45] with momentum.
3.3. Work Flow
4. Experimental Results
4.1. Experimental Setups
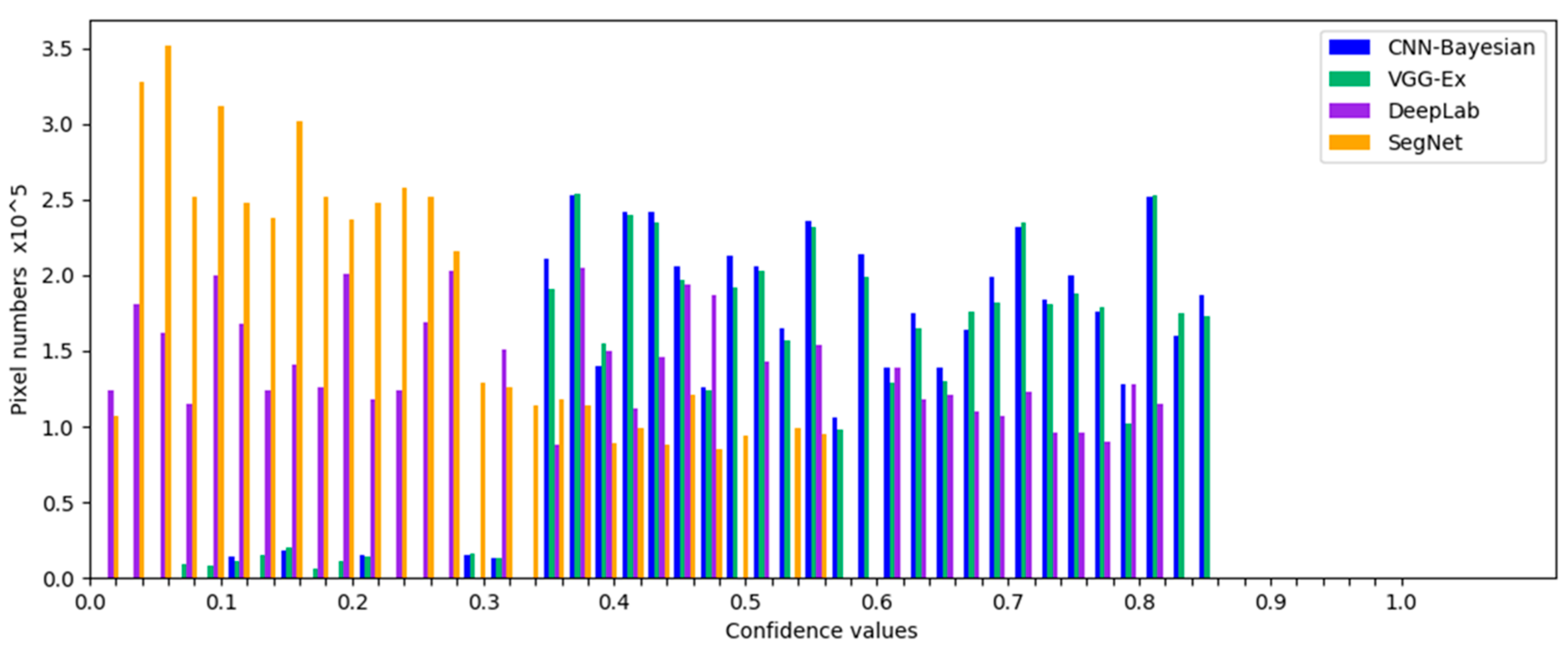
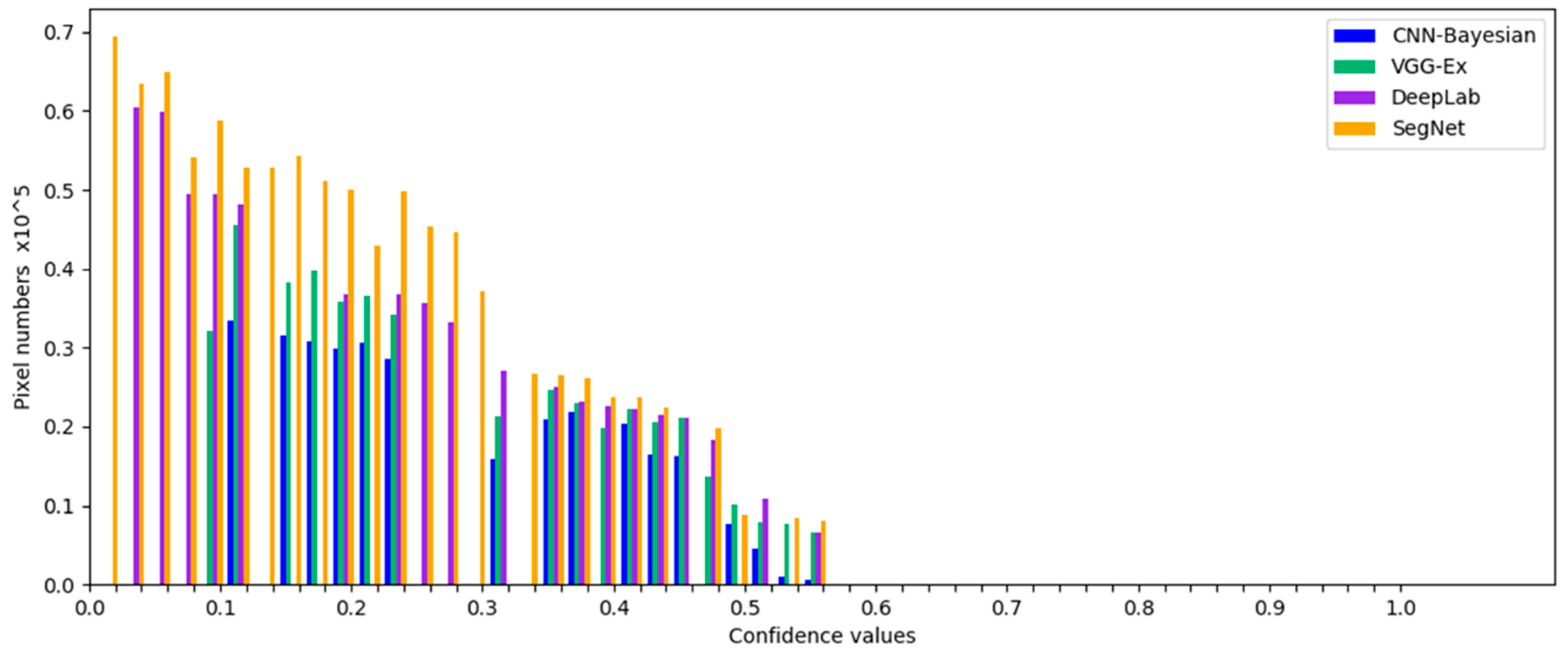
4.2. Results and Evaluation
5. Discussions
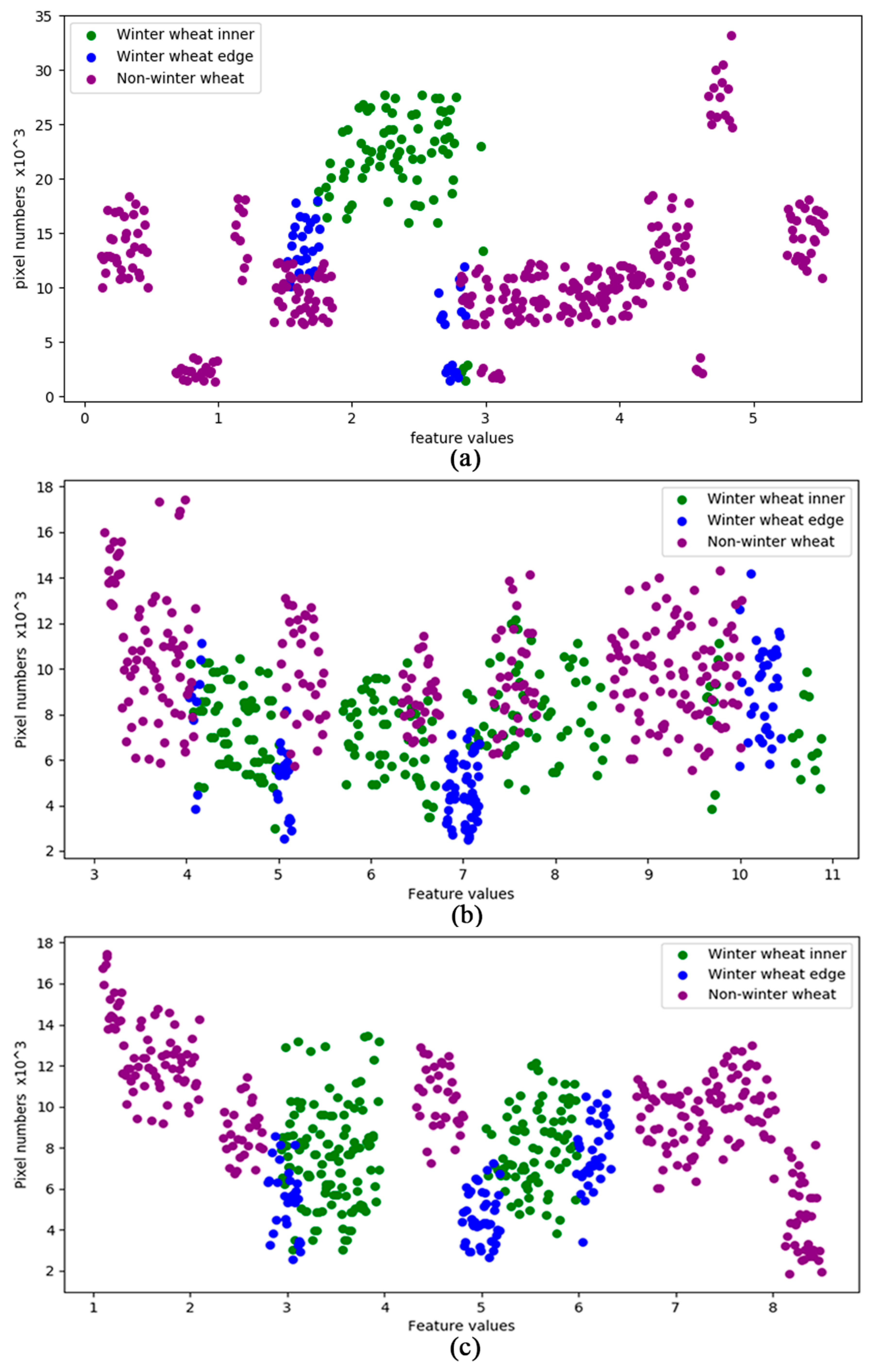
5.1. The Effectiveness of Feature Extractor
5.2. The Effectiveness of Classifier
5.3. Comparison to Other Similar Works
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Websit of Food and Agriculture Organization of the United Nations. Available online: http://www.fao.org/faostat/zh/#data/QC (accessed on 8 August 2018).
- Announcement of the National Statistics Bureau on Grain Output in 2017. Available online: http://www.gov.cn/xinwen/2017-12/08/content_5245284.htm (accessed on 8 December 2017).
- Zhang, J.; Feng, L.; Yao, F. Improved maize cultivated area estimation over a large scale combining MODIS–EVI time series data and crop phenological information. ISPRS J. Photogramm. Remote Sens. 2014, 94, 102–113. [Google Scholar] [CrossRef]
- Chen, X.-Y.; Lin, Y.; Zhang, M.; Yu, L.; Li, H.-C.; Bai, Y.-Q. Assessment of the cropland classifications in four global land cover datasets: A case study of Shaanxi Province, China. J. Integnit. Agric. 2017, 16, 298–311. [Google Scholar] [CrossRef]
- Ma, L.; Gu, X.; Xu, X.; Huang, W.; Jia, J.J. Remote sensing measurement of corn planting area based on field-data. Trans. Chin. Soc. Agric. Eng. 2009, 25, 147–151. (In Chinese) [Google Scholar] [CrossRef]
- McCullough, I.M.; Loftin, C.S.; Sader, S.A. High-frequency remote monitoring of large lakes with MODIS 500 m imagery. Remote Sens. Environ. 2012, 124, 234–241. [Google Scholar] [CrossRef]
- Hao, H.E.; Zhu, X.F.; Pan, Y.Z.; Zhu, W.Q.; Zhang, J.S.; Jia, B. Study on scale issues in measurement of winter wheat plant area by remote sensing. J. Remote Sens. 2008, 12, 168–175. (In Chinese) [Google Scholar]
- Wang, L.; Jia, L.; Yao, B.; Ji, F.; Yang, F. Area change monitoring of winter wheat based on relationship analysis of GF-1 NDVI among different years. Trans. Chin. Soc. Agric. Eng. 2018, 34, 184–191. (In Chinese) [Google Scholar] [CrossRef]
- Wang, D.; Fang, S.; Yang, Z.; Wang, L.; Tang, W.; Li, Y.; Tong, C. A regional mapping method for oilseed rape based on HSV transformation and spectral features. ISPRS Int. J. Geo-Informat. 2018, 7, 224. [Google Scholar] [CrossRef]
- Georgi, C.; Spengler, D.; Itzerott, S.; Kleinschmit, B. Automatic delineation algorithm for site-specific management zones based on satellite remote sensingdata. Precis. Agric. 2018, 19, 684–707. [Google Scholar] [CrossRef]
- Wang, L.; Guo, Y.; He, J.; Wang, L.; Zhang, X.; Liu, T. Classification method by fusion of decision tree and SVM based on Sentinel-2A image. Trans. Chin. Soc. Agric. Mach. 2018, 49, 146–153. (In Chinese) [Google Scholar] [CrossRef]
- Qian, X.; Li, J.; Cheng, G.; Yao, X.; Zhao, S.; Chen, Y.; Jiang, L. Evaluation of the effect of feature extraction strategy on the performance of high-resolution remote sensing image scene classification. J. Remote Sens. 2018, 22, 758–776. (In Chinese) [Google Scholar] [CrossRef]
- Wang, L.; Xu, S.; Li, Q.; Xue, H.; Wu, J. Extraction of winter wheat planted area in Jiangsu province using decision tree and mixed-pixel methods. Trans. Chin. Soc. Agric. Eng. 2016, 32, 182–187. (In Chinese) [Google Scholar] [CrossRef]
- Guo, Y.S.; Liu, Q.S.; Liu, G.H.; Huang, C. Extraction of main crops in Yellow River Delta based on MODIS NDVI time series. J. Nat. Res. 2017, 32, 1808–1818. (In Chinese) [Google Scholar] [CrossRef]
- Xu, Q.; Yang, G.; Long, H.; Wang, C.; Li, X.; Huang, D. Crop information identification based on MODIS NDVI time-series data. Trans. Chin. Soc. Agric. Eng. 2014, 30, 134–144. (In Chinese) [Google Scholar] [CrossRef]
- Hao, W.; Mei, X.; Cai, X.; Du, J.; Liu, Q. Crop planting extraction based on multi-temporal remote sensing data in Northeast China. Trans. Chin. Soc. Agric. Eng. 2011, 27, 201–207. (In Chinese) [Google Scholar] [CrossRef]
- Feng, M.; Yang, W.; Zhang, D.; Cao, L.; Wang, H.; Wang, Q. Monitoring planting area and growth situation of irrigation-land and dry-land winter wheat based on TM and MODIS data. Trans. Chin. Soc. Agric. Eng. 2009, 25, 103–109. (In Chinese) [Google Scholar]
- Sha, Z.; Zhang, J.; Yun, B.; Yao, F. Extracting winter wheat area in Huanghuaihai Plain using MODIS-EVI data and phenology difference avoiding threshold. Trans. Chin. Soc. Agric. Eng. 2018, 34, 150–158. (In Chinese) [Google Scholar] [CrossRef]
- Yang, P.; Yang, G. Feature extraction using dual-tree complex wavelet transform and gray level co-occurrence matrix. Neurocomputing 2016, 197, 212–220. [Google Scholar] [CrossRef]
- Reis, S.; Tasdemir, K. Identification of hazelnut fields using spectral and Gabor textural features. ISPRS J. Photogramm. Remote Sens. 2011, 66, 652–661. [Google Scholar] [CrossRef]
- Naseera, M.T.; Asima, S. Detection of cretaceous incised-valley shale for resource play, Miano gas field, SW Pakistan: Spectral decomposition using continuous wavelet transform. J Asian. Earth. Sci. 2017, 147, 358–377. [Google Scholar] [CrossRef]
- Liu, Y.; Bian, L.; Meng, Y.; Wang, H.; Zhang, S.; Yang, Y.; Shao, X.; Wang, Bo. Discrepancy measures for selecting optimal combination of parameter values in object-based image analysis. ISPRS J. Photogramm. Remote Sens. 2012, 68, 144–156. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addin, E.; Feitosa, R.; Meer, F.; Werff, H.; Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2013, 87, 180–191. [Google Scholar] [CrossRef]
- Wu, M.; Yang, L.; Yu, B.; Wang, Y.; Zhao, X.; Zheng, N.; Wang, C. Mapping crops acreages based on remote sensing and sampling investigation by multivariate probability proportional to size. Trans. Chin. Soc. Agric. Eng. 2014, 30, 146–152. (In Chinese) [Google Scholar] [CrossRef]
- You, W.; Zhi, Z.; Wang, F.; Wu, Q.; Guo, L. Area extraction of winter wheat at county scale based on modified multivariate texture and GF-1 satellite images. Trans. Chin. Soc. Agric. Eng. 2016, 32, 131–139. (In Chinese) [Google Scholar] [CrossRef]
- Liu, D.; Han, L.; Han, X. High spatial resolution remote sensing image classification based on deep learning. Acta Opt. Sin. 2016, 36, 0428001. (In Chinese) [Google Scholar] [CrossRef]
- Li, D.; Zhang, L.; Xia, G. Automatic analysis and mining of remote sensing big data. J. Surv. Mapp. 2014, 43, 1211–1216. (In Chinese) [Google Scholar] [CrossRef]
- Mas, J.F.; Flores, J.J. The application of artificial neural networks to the analysis of remotely sensed data. Int. J. Remote Sens. 2007, 29, 617–663. [Google Scholar] [CrossRef] [Green Version]
- Pacifici, F.; Chini, M.; Emery, W.J. A neural network approach using multi-scale textural metrics from very high-resolution panchromatic imagery for urban land-use classification. Remote Sens. Environ. 2009, 113, 1276–1292. [Google Scholar] [CrossRef]
- Liu, C.; Hong, L.; Chen, J.; Chu, S.; Deng, M. Fusion of pixel-based and multi-scale region-based features for the classification of high-resolution remote sensing image. J. Remote Sens. 2015, 5, 228–239. (In Chinese) [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. An SVM ensemble approach combining spectral, structural, and semantic features for the classification of high-resolution remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 257–272. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chang, L.; Deng, X.M.; Zhou, M.Q.; Wu, Z.K.; Yuan, Y.; Yang, S.; Wang, H. Convolutional neural networks in image understanding. Acta Autom. Sin. 2016, 42, 1300–1312. (In Chinese) [Google Scholar] [CrossRef]
- Fischer, W.; Moudgalya, S.S.; Cohn, J.D.; Nguyen, N.T.T.; Kenyon, G.T. Sparse coding of pathology slides compared to transfer learning with deep neural networks. BMC Bioinform. 2018, 19, 489. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 39, 640–651. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv, 2015; arXiv:1505.07293. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. arXiv, 2015; arXiv:1505.04597. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, Atrous convolution, and fully connected CRFs. IEEE Trans. Patt. Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Visin, F.; Romero, A.; Cho, K.; Matteucci, M.; Courville, A. ReSeg: A recurrent neural network-based model for semantic segmentation. arXiv, 2016; arXiv:1511.07053. [Google Scholar]
- Zhang, L.; Wang, L.; Zhang, X.; Shen, P.; Bennamoun, M.; Zhu, G.; Shah, S.A.A.; Song, J. Semantic scene completion with dense CRF from a single depth image. Neurocomputing 2018, 318, 182–195. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Fu, K.; Lu, W.; Diao, W.; Yan, M.; Sun, H.; Zhang, Y.; Sun, X. WSF-NET: Weakly supervised feature-fusion network for binary segmentation in remote sensing image. Remote Sens. 2018, 10, 1970. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv, 2015; arXiv:1508.00092. [Google Scholar]
- Nogueira, K.; Penatti, O.A.B.; Dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef] [Green Version]
- Lin, H.; Shi, Z.; Zou, Z. Maritime semantic labeling of optical remote sensing images with multi-scale fully convolutional network. Remote Sens. 2017, 9, 480. [Google Scholar] [CrossRef]
- Sharma, A.; Liu, X.; Yang, X.; Shi, D. A patch-based convolutional neural network for remote sensing image classification. Neural Netw. 2017, 95, 19–28. [Google Scholar] [CrossRef]
- Gaetano, R.; Ienco, D.; Ose, K.; Cresson, R. A two-branch CNN architecture for land cover classification of PAN and MS imagery. Remote Sens. 2018, 10, 1746. [Google Scholar] [CrossRef]
- Duan, L.; Xiong, X.; Liu, Q.; Yang, W.; Huang, C. Field rice panicle segmentation based on deep full convolutional neural network. Trans. Chin. Soc. Agric. Eng. 2018, 34, 202–209. (In Chinese) [Google Scholar] [CrossRef]
- Jiang, T.; Liu, X.; Wu, L. Method for mapping rice fields in complex landscape areas based on pre-trained convolutional neural network from HJ-1 A/B data. ISPRS Int. J. Geo-Inf. 2018, 7, 418. [Google Scholar] [CrossRef]
- Hasan, M.M.; Chopin1, J.P.; Laga, H.; Miklavcic, S.J. Detection and analysis of wheat spikes using Convolutional Neural Networks. Plant Methods 2018, 14, 100. [Google Scholar] [CrossRef]
- Rzanny, M.; Seeland, M.; Wäldchen, J.; Mäder, P. Acquiring and preprocessing leaf images for automated plant identification: Understanding the tradeoff between effort and information gain. Plant Methods 2017, 13, 97. [Google Scholar] [CrossRef]
- Jiao, J.; Fan, Z.; Liang, Z. Remote sensing estimation of rape planting area based on improved AlexNet model. Comp. Meas. Cont. 2018, 26, 186–189. (In Chinese) [Google Scholar] [CrossRef]
- Huang, H.; Deng, J.; Lan, Y.; Yang, A.; Deng, X.; Zhang, L. A fully convolutional network for weed mapping of unmanned aerial vehicle (UAV) imagery. PLoS ONE 2018, 13, e0196302. [Google Scholar] [CrossRef]
- Huang, H.; Deng, J.; Lan, Y.; Yang, A.; Deng, X.; Wen, S.; Zhang, H.; Zhang, Y. Accurate weed mapping and prescription map generation based on fully convolutional networks using UAV imagery. Sensors 2018, 18, 3299. [Google Scholar] [CrossRef]
- Huang, H.; Lan, Y.; Deng, J.; Yang, A.; Deng, X.; Zhang, L.; Wen, S. A semantic labeling approach for accurate weed mapping of high resolution UAV imagery. Sensors 2018, 18, 2113. [Google Scholar] [CrossRef]
- Ha, J.G.; Moon, H.; Kwak, J.T.; Hassan, S.I.; Dang, M.; Lee, O.N.; Park, H.Y. Deep convolutional neural network for classifying Fusarium wilt of radish from unmanned aerial vehicles. J Appl. Remote Sens. 2017, 11, 042621. [Google Scholar] [CrossRef]
- Long, M.; Ou, Y.; Liu, H.; Fu, Q. Image recognition of Camellia oleifera diseases based on convolutional neural network & transfer learning. Trans. Chin. Soc. Agric. Eng. 2018, 34, 194–201. [Google Scholar] [CrossRef]
- Liu, T.; Feng, Q.; Yang, S. Detecting grape diseases based on convolutional neural network. J. Northeast. Agric. Univ. 2018, 49, 78–83. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.Y.; Yuan, Y. Embedding Structured Contour and Location Prior in Siamesed Fully Convolutional Networks for Road Detection. IEEE Trans. Intell. Transp. 2018, 19, 230–241. [Google Scholar] [CrossRef]
- Ji, S.; Zhang, C.; Xu, A.; Shi, Y.; Duan, Y. 3D convolutional neural networks for crop classification with multi-temporal remote sensing images. Remote Sens. 2018, 10, 75. [Google Scholar] [CrossRef]
- Ndikumana, E.; Ho Tong Minh, D.; Baghdadi, N.; Courault, D.; Hossard, L. Deep recurrent neural network for agricultural classification using multitemporal SAR Sentinel-1 for Camargue, France. Remote Sens. 2018, 10, 1217. [Google Scholar] [CrossRef]
- Namin, S.T.; Esmaeilzadeh, M.; Najafi, M.; Brown, T.B.; Borevitz, J.O. Deep phenotyping: Deep learning for temporal phenotype/genotype classification. Plant Methods 2018, 14, 66. [Google Scholar] [CrossRef]
- Maggiori, E.; Charpiat, G.; Tarabalka, Y.; Alliez, P. Recurrent Neural Networks to Correct Satellite Image Classification Maps. arXiv, 2017; arXiv:1608.03440. [Google Scholar] [CrossRef]
- Peng, X.; Feng, J.S.; Xiao, S.J.; Yau, W.Y.; Zhou, J.T.; Yang, S.F. Structured AutoEncoders for Subspace Clustering. IEEE T Image Process 2018, 27, 5076–5086. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Meng, Z.T.; Li, X.L. Locality Adaptive Discriminant Analysis for Spectral-Spatial Classification of Hyperspectral Images. IEEE Geosci. Remote Sens. 2017, 14, 2077–2081. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, H.; Zhou, J.T.; Peng, X. Multiple Marginal Fisher Analysis. IEEE Trans. Ind. Electron. 2018. [Google Scholar] [CrossRef]
- Jung, M.C.; Park, J.; Kim, S. Spatial Relationships between Urban Structures and Air Pollution in Korea. Sustainability 2019, 11, 476. [Google Scholar] [CrossRef]
- Chen, M.; Sun, Z.; Davis, J.M.; Liu, Y.; Corr, C.A.; Gao, W. Improving the mean and uncertainty of ultraviolet multi-filter rotating shadowband radiometer in situ calibration factors: Utilizing Gaussian process regression with a new method to estimate dynamic input uncertainty. Atmos. Meas. Tech. 2019, 12, 935–953. [Google Scholar] [CrossRef]
- Website of Zhangqiu County People’s Government. Available online: http://www.jnzq.gov.cn/col/col22490/index.html (accessed on 21 October 2018).
- Calibration Parameters for Part of Chinese Satellite Images. Available online: http://www.cresda.com/CN/Downloads/dbcs/index.shtml (accessed on 29 May 2018).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| mini-batch size | 32 |
| learning rate | 0.0001 |
| momentum | 0.9 |
| epochs | 20,000 |
| Layer | Operations | Parameters 1 | Data Dimension of Input | Data Dimension of Output |
|---|---|---|---|---|
| 1 | Convolutional | f = 3 × 3 × 3, s = 1, d = 64 | 748 × 748 × 3 | 746 × 746 × 64 |
| pooling | f = 3 × 3, s = 1 | 746 × 746 × 64 | 744 × 744 × 64 | |
| 2 | Convolutional | f = 3 × 3 × 64, s = 1, d = 64 | 744 × 744 × 64 | 742 × 742 × 64 |
| pooling | f = 3 × 3, s = 1 | 742 × 742 × 64 | 740 × 740 × 64 | |
| 3 | Convolutional | f = 3 × 3 × 64, s = 1, d = 64 | 740 × 740 × 64 | 740 × 740 × 64 |
| pooling | f = 3 × 3, s = 1 | 740 × 740 × 64 | 738 × 738 × 64 | |
| 4 | Convolutional | f = 3 × 3 × 64, s = 1, d = 128 | 738 × 738 × 64 | 736 × 736 × 128 |
| pooling | f = 3 × 3, s = 1 | 736 × 736 × 128 | 734 × 734 × 128 | |
| 5 | Convolutional | f = 3 × 3 × 128, s = 1, d = 128 | 734 × 734 × 128 | 732 × 732 × 128 |
| pooling | f = 3 × 3, s = 1 | 732 × 732 × 128 | 730 × 730 × 128 | |
| 6 | Convolutional | f = 3 × 3 × 128, s = 1, d = 128 | 730 × 730 × 128 | 728 × 728 × 128 |
| pooling | f = 3 × 3, s = 1 | 728 × 728 × 128 | 726 × 726 × 128 | |
| 7 | Convolutional | f = 3 × 3 × 128, s = 1, d = 256 | 726 × 726 × 128 | 724 × 724 × 256 |
| pooling | f = 3 × 3, s = 1 | 724 × 724 × 256 | 722 × 722 × 256 | |
| 8 | Convolutional | f = 3 × 3 × 256, s = 1, d = 256 | 722 × 722 × 256 | 720 × 720 × 256 |
| pooling | f = 3 × 3, s = 1 | 720 × 720 × 256 | 718 × 718 × 256 | |
| 9 | Convolutional | f = 3 × 3 × 256, s = 1, d = 256 | 718 × 718 × 256 | 718 × 718 × 256 |
| pooling | f = 3 × 3, s = 1 | 718 × 718 × 256 | 716 × 716 × 256 | |
| 10 | Convolutional | f = 3 × 3 × 256, s = 1, d = 512 | 716 × 716 × 256 | 714 × 714 × 512 |
| pooling | f = 3 × 3, s = 1 | 714 × 714 × 512 | 712 × 712 × 512 | |
| 11 | Convolutional | f = 3 × 3 × 512, s = 1, d = 512 | 712 × 712 × 512 | 710 × 710 × 512 |
| pooling | f = 3 × 3, s = 1 | 710 × 710 × 512 | 708 × 708 × 512 | |
| 12 | Convolutional | f = 3 × 3 × 512, s = 1, d = 512 | 708 × 708 × 512 | 706 × 706 × 512 |
| pooling | f = 3 × 3, s = 1 | 706 × 706 × 512 | 704 × 704 × 512 | |
| 13 | Convolutional | f = 3 × 3 × 512, s = 1, d = 512 | 704 × 704 × 512 | 702 × 702 × 512 |
| pooling | f = 3 × 3, s = 1 | 702 × 702 × 512 | 700 × 700 × 512 | |
| Output | 700 × 700 × 586 |
| Category | Number of Total Samples (Million) |
|---|---|
| Winter wheat | 1572 |
| Agricultural buildings | 6 |
| Woodland | 568 |
| Developed land | 1199 |
| Roads | 51 |
| Water bodies | 57 |
| Farmland | 1521 |
| Bare fields | 1332 |
| Approach | Predicted | Winter Wheat | Non-Winter Wheat |
|---|---|---|---|
| CNN-Bayesian | Winter wheat | 0.669 | 0.021 |
| Non-winter wheat | 0.033 | 0.277 | |
| VGG-Ex | Winter wheat | 0.631 | 0.059 |
| Non-winter wheat | 0.049 | 0.261 | |
| SegNet | Winter wheat | 0.574 | 0.116 |
| Non-winter wheat | 0.093 | 0.217 | |
| DeepLab | Winter wheat | 0.605 | 0.085 |
| Non-winter wheat | 0.063 | 0.247 |
| Index | CNN-Bayesian | VGG-Ex | SegNet | DeepLab |
|---|---|---|---|---|
| Accuracy | 0.946 | 0.892 | 0.791 | 0.852 |
| Precision | 0.932 | 0.878 | 0.766 | 0.837 |
| Recall | 0.941 | 0.872 | 0.756 | 0.825 |
| Kappa | 0.879 | 0.778 | 0.616 | 0.712 |
| Approach | Predicted | Winter Wheat Inner | Winter Wheat Edge | Non-Winter Wheat |
|---|---|---|---|---|
| CNN-Bayesian | Winter wheat inner | 0.542 | / | 0.001 |
| Winter wheat edge | / | 0.127 | 0.02 | |
| Non-winter wheat | 0.006 | 0.027 | 0.277 | |
| VGG-Ex | Winter wheat inner | 0.539 | / | 0.012 |
| Winter wheat edge | / | 0.092 | 0.047 | |
| Non-winter wheat | 0.008 | 0.041 | 0.261 | |
| SegNet | Winter wheat inner | 0.532 | / | 0.035 |
| Winter wheat edge | / | 0.042 | 0.081 | |
| Non-winter wheat | 0.033 | 0.06 | 0.217 | |
| DeepLab | Winter wheat inner | 0.538 | / | 0.026 |
| Winter wheat edge | / | 0.067 | 0.059 | |
| Non-winter wheat | 0.015 | 0.048 | 0.247 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Han, Y.; Li, F.; Gao, S.; Song, D.; Zhao, H.; Fan, K.; Zhang, Y. A New CNN-Bayesian Model for Extracting Improved Winter Wheat Spatial Distribution from GF-2 imagery. Remote Sens. 2019, 11, 619. https://doi.org/10.3390/rs11060619
Zhang C, Han Y, Li F, Gao S, Song D, Zhao H, Fan K, Zhang Y. A New CNN-Bayesian Model for Extracting Improved Winter Wheat Spatial Distribution from GF-2 imagery. Remote Sensing. 2019; 11(6):619. https://doi.org/10.3390/rs11060619
Chicago/Turabian StyleZhang, Chengming, Yingjuan Han, Feng Li, Shuai Gao, Dejuan Song, Hui Zhao, Keqi Fan, and Ya’nan Zhang. 2019. "A New CNN-Bayesian Model for Extracting Improved Winter Wheat Spatial Distribution from GF-2 imagery" Remote Sensing 11, no. 6: 619. https://doi.org/10.3390/rs11060619
APA StyleZhang, C., Han, Y., Li, F., Gao, S., Song, D., Zhao, H., Fan, K., & Zhang, Y. (2019). A New CNN-Bayesian Model for Extracting Improved Winter Wheat Spatial Distribution from GF-2 imagery. Remote Sensing, 11(6), 619. https://doi.org/10.3390/rs11060619