1. Introduction
Hyperspectral images (HSIs) are obtained by a series of hyperspectral imaging sensors and composed of hundreds of successive spectral bands. Because the wavelength interval between every two neighboring bands is quite small (usually 10 nm), HSIs generally have a very high spectral resolution [
1]. Analysis of HSIs has been widely used in a large variety of fields, including materials analysis, precision agriculture, environmental monitoring and surveillance [
2,
3,
4]. Among the hyperspectral community, the HSIs classification is most vibrant filed of research which is to assign a unique class to each pixel in the image [
5]. However, due to the excessively redundant spectral band information and limited training samples, it also poses a great challenge to the classification of HSIs [
6].
Early attempts for HSIs classification including the radial basis functions (RBFs) and K-nearest neighbor (kNN) methods are all pixel-wise and focus on the spectral signatures of hyperspectral data. But besides the spectral aspect, the spatial dependency which indicates the adjacent pixels likely belong to the same category is another useful information in the hyperspectral data. According to this, in aim to characterize the relationship between the samples, several spatial methods such as sparse representation and graph-based methods were proposed [
7,
8,
9,
10]. However, they used the class label to construct the manifold structure by both labeled and unlabeled data for classification which didn’t incorporate the spectral feature. Consequently, a promising way is to combine the spectral and spatial information for classification that can enhance the performance of classification due to taking full advantage of HSIs contained [
11,
12,
13]. In [
13], to cleanse the label noise the authors proposed a random label propagation algorithm (RLPA) which is guided by the spectral−spatial constraint-based knowledge. The RLPA algorithm constitutes two steps: spectral–spatial probability transform matrix (SSPTM) generation and random label propagation. However, the feature extraction of all the above-mentioned methods is hand-crafted which is not enough for the large intra-class difference or subtle inter-class difference.
Recently, deep learning (DL) has witnessed a great surge of interest that minds the deep feature and extracts the high-level feature of big data automatically in computer vision and big data field. Among the various DL models, the deep convolutional neural network (CNN) has become an efficient and popular tool for image recognition [
14,
15,
16,
17,
18]. For the HSIs classification task, a series of CNN methods have been exploited [
19,
20,
21,
22]. In [
19], a CNN architecture containing five layers was developed to classify hyperspectral images directly in spectral domain. In [
20], a CNN network with a multi-layer perceptron was proposed to encode the pixels’ spectral and spatial information to accomplish the classification task. In [
21], Li et al. proposed a pixel-pair method to increase the training samples and used deep CNN to learn the pixel-pair features which are expected to have more discriminative power. However, these methods require a large amount of data as a training set and the over-fitting occurs easily that greatly decreases the classification accuracy when the labeled hyperspectral data is limited. In order to reduce the probability to over-fitting, a CNN based on diverse regions was proposed [
22]. In this paper, on the one hand, the authors proposed a data enhancement method to obtain more training data. They cropped and filled the pixel patch according to diverse regions, and then flipped the original samples and added tiny Gaussian noise to the obtained training samples. On the other hand, inspired by the [
18], they designed the network structure as a residual network, which has been proved to be effective to prevent the network from over-fitting.
To directly extract the spectral–spatial feature, some methods based on 3D CNN were proposed. Chen et al. [
23] proposed a novel DL framework of 3D CNN to extract the spectral–spatial features effectively. In [
24], Li et al. proposed a lightweight network based on 3D CNN, which required fewer parameters and performed better compared with 2D CNN method. Inspired by this, He et al. [
25] provided a method based on 3D CNN with multi-scale convolution kernel, which could extract multiple sets of features by using convolution kernel with different sizes to enlarge receptive field. In [
26], the authors not only effectively integrated spectral–spatial information through the use of 3D CNN but also employed residual network structure to alleviate the declining-accuracy phenomenon and facilitated the backpropagation of gradients. Inspired by [
26], Wang et al. proposed a fast dense spectral–spatial convolution network for HSIs classification [
27]. They used 3D convolution kernel of different sizes to extract more recognizable features and utilized dense network structure to prevent the proposed framework from over-fitting, which has been reported to be more effective than residual network structure [
28]. In [
29], a novel HSIs classification method was proposed, which combined the adaptive dimensionality reduction and semi-supervised 3D CNN. It can overcome the problem of high dimensionality curse of HSIs and limited training samples.
With the sustaining development of DL technology, some auxiliary technologies have been emerged. It is remarkable that attention mechanism as a representative has played an important role in many fields and interested numerous researchers [
30,
31,
32,
33,
34,
35]. The attention mechanism is based on the fact that humans focus attention selectively on parts of the visual space to acquire information when and where it is needed to. This is of significant interest for analyzing remotely sensed hyperspectral images. In [
36], the author incorporated attention mechanisms to a ResNet to better characterize the spectral–spatial information contained in the data. In [
37], a novel DL framework based on dense connectivity with spectral-wise attention for HSI classification was proposed. In this framework the dense connectivity is employed to prevent the network from over-fitting and a new spectral-wise attention is used to refine the features maps.
Although the DL methods for HSIs classification have achieved excellent results, which are better than the traditional approaches, there are still some problems.
There is a lot of spatial redundancy in the hyperspectral data processing which takes up much memory space. Especially when 3D CNN is adopted to learn the feature, it will include numerous parameters which is disadvantage to the classification performance, compared to the 2D CNN and 1D CNN.
Although the methods of combining DL method and attention mechanism have achieved successes for HSIs classification, to my best knowledge, there is not much research on the spatial attention for HSIs classification which does play an important role for HSIs classification.
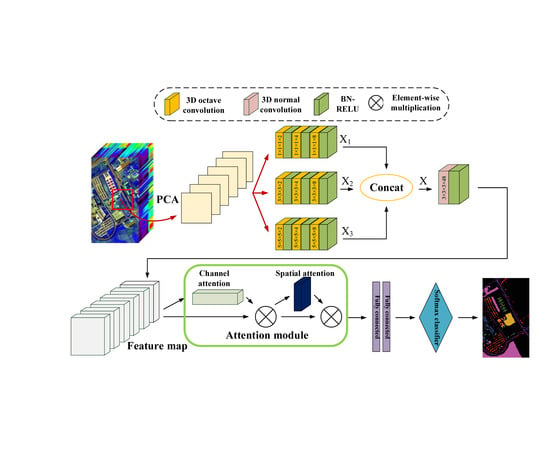
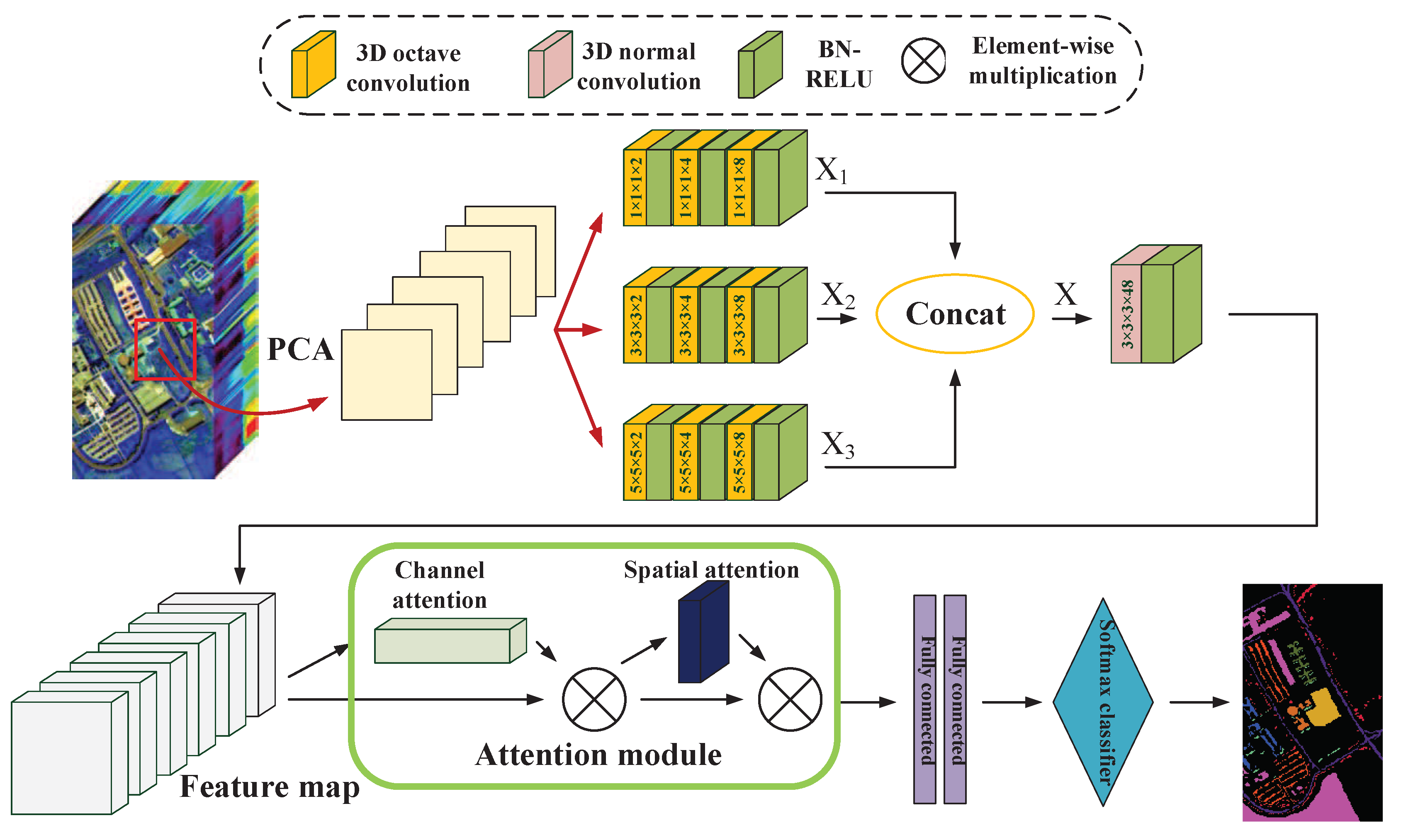
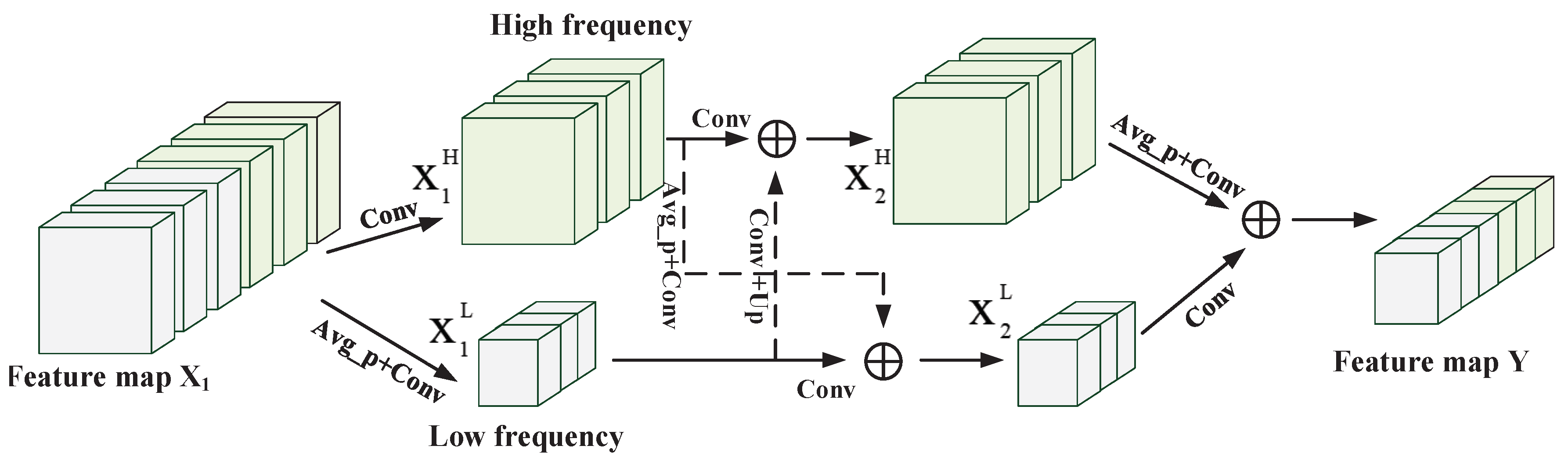
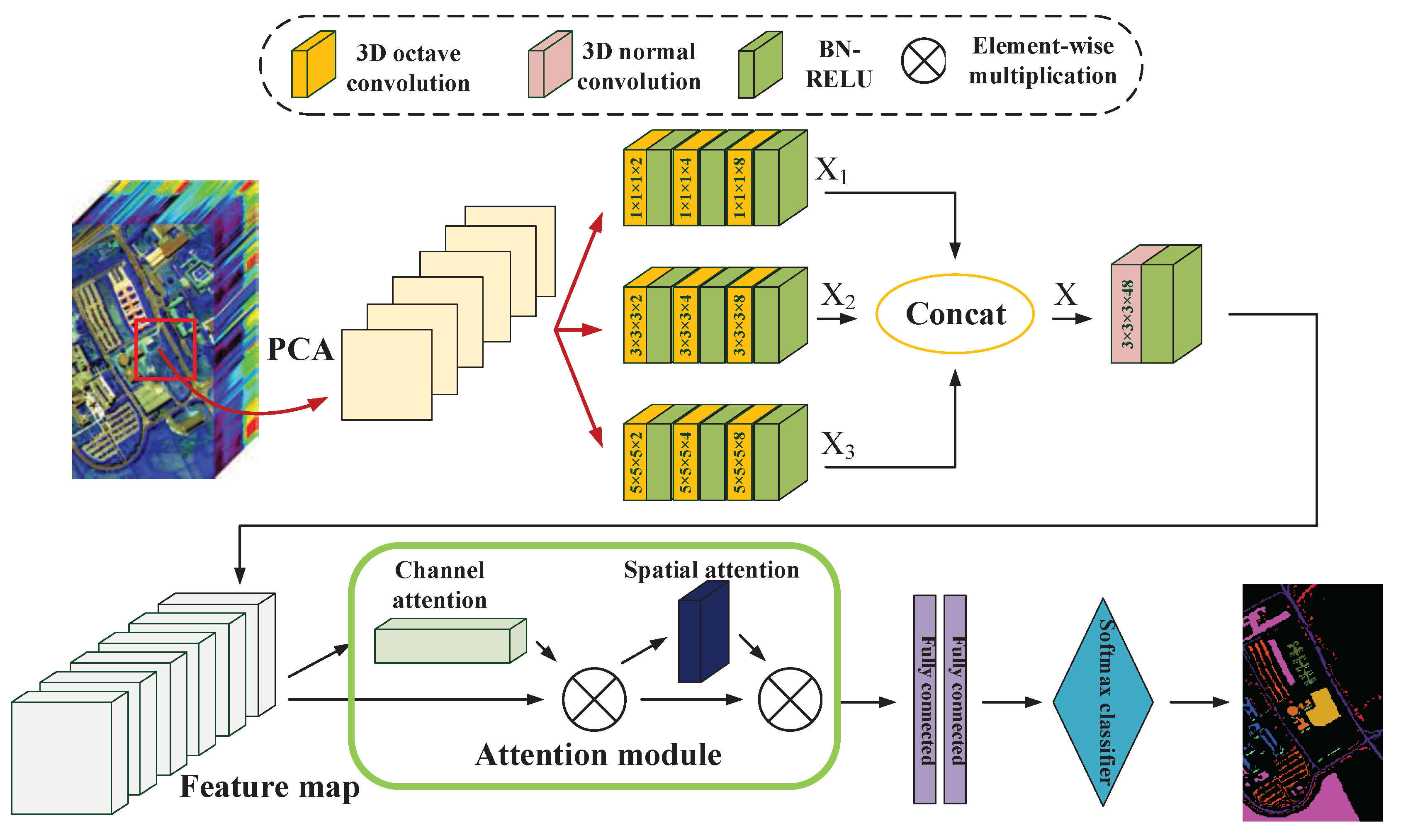
In this paper, we propose a novel multiscale octave 3D CNN with channel and spatial attention (CSA-MSO3DCNN) for hyperspectral image classification. In our method, as 3D CNN can mine information hidden in the hyperspectral data more effectively whereas 1D CNN and 2D CNN can not, 3D CNN serves as the foundation of the entire architecture to directly extract the spectral–spatial features. In order to extract the spectral–spatial features of different scales, we design 3D CNN convolution kernels of different sizes. Due to 3D CNN has a lot of parameters and redundancy, we propose to use octave 3D CNN to replace the standard 3D CNN to decompose the features into high frequency and low frequency and reduce the spatial redundancy. Before feeding into the full connection layer, the channel and spatial attention mechanism modules are added to refine the feature maps. Through a series of optimization design, our method can extract higher and more recognizable features compared with the standard methods based on deep learning, like 2D CNN, 3D CNN, etc. Finally, the contributions of this paper can be summarized as follows:
The proposed network takes full advantages of octave 3D CNN with different kernels to capture diverse features and reduce the spatial redundancy simultaneously. Given the same input and structure, our proposed method works more effectively than the method based on normal 3D CNN.
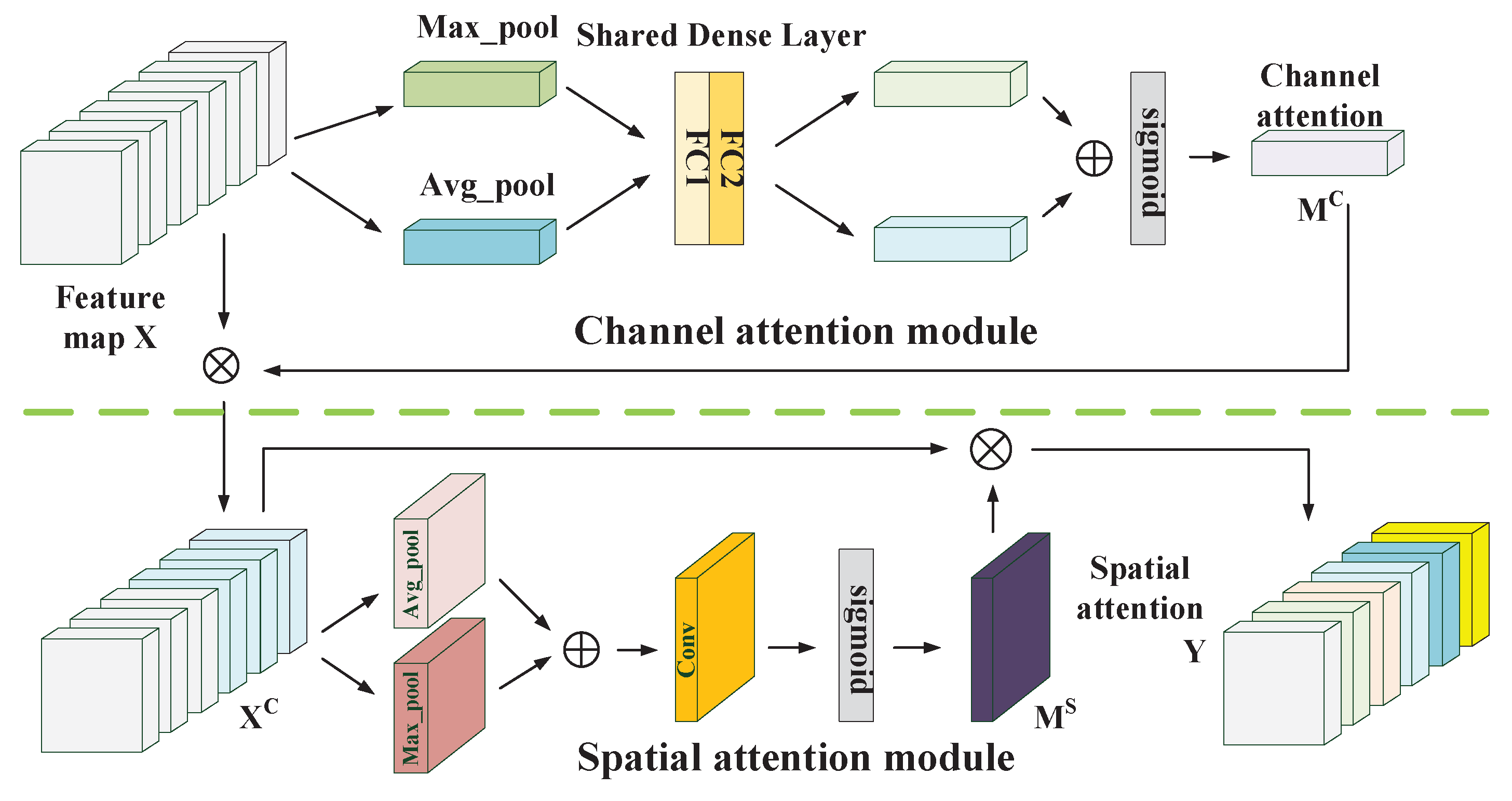
A new attention mechanism with two attention modules is employed to refine the feature maps, which selects the discriminative features from the spectral and spatial views. This boosts the performance of our proposed network which further captures the similarity of adjacent pixels and the correlation of various spectral bands.
The remainder of this paper is organized as follows. In
Section 2, we briefly introduce the CNN and the attention mechanism in DL. The detailed design of CSA-MSO3DCNN method is given in
Section 3. In
Section 4, we present and discuss the experimental results, including ablation experiments. Finally,
Section 5 summarizes this paper.
5. Conclusions
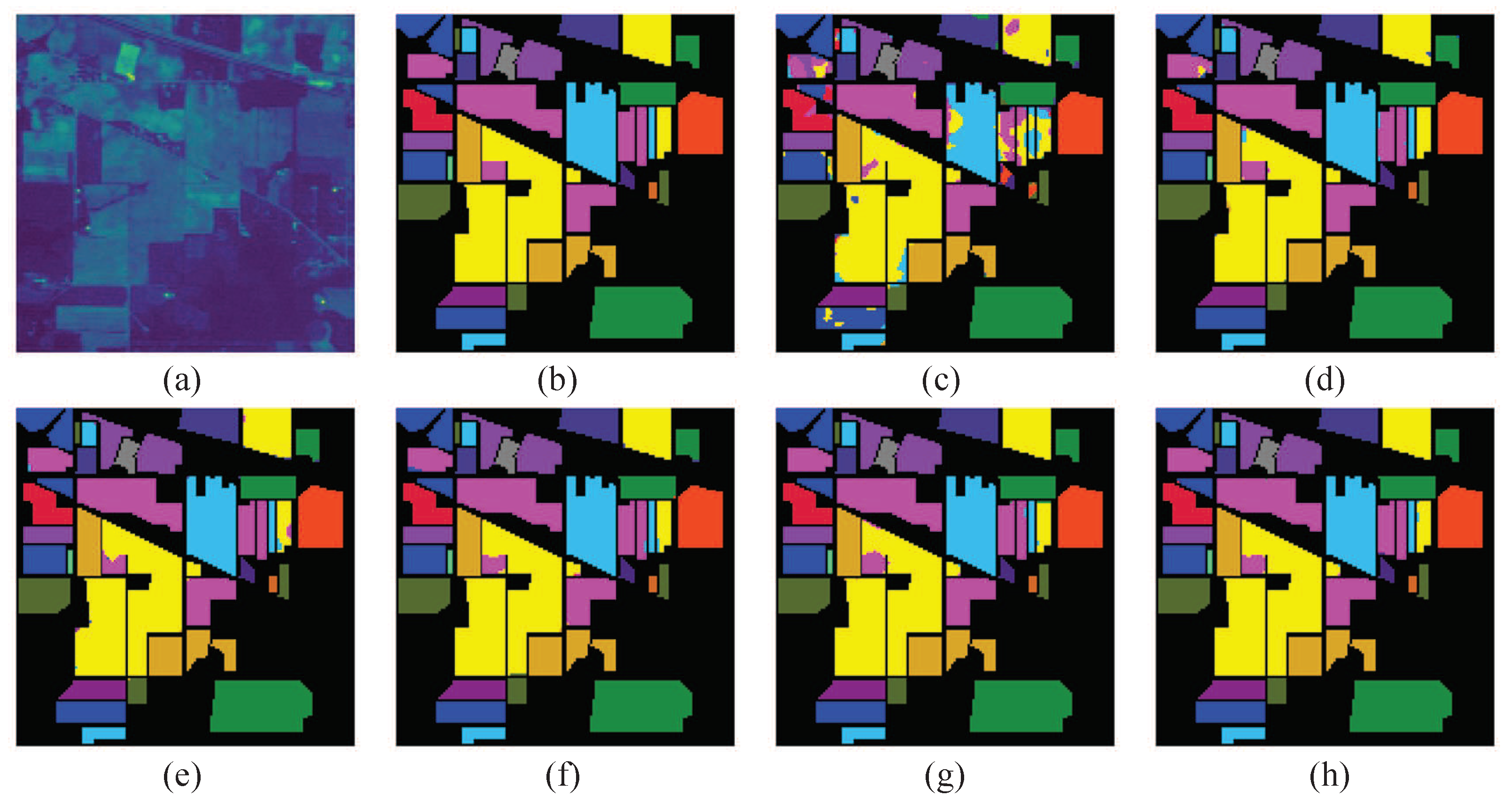
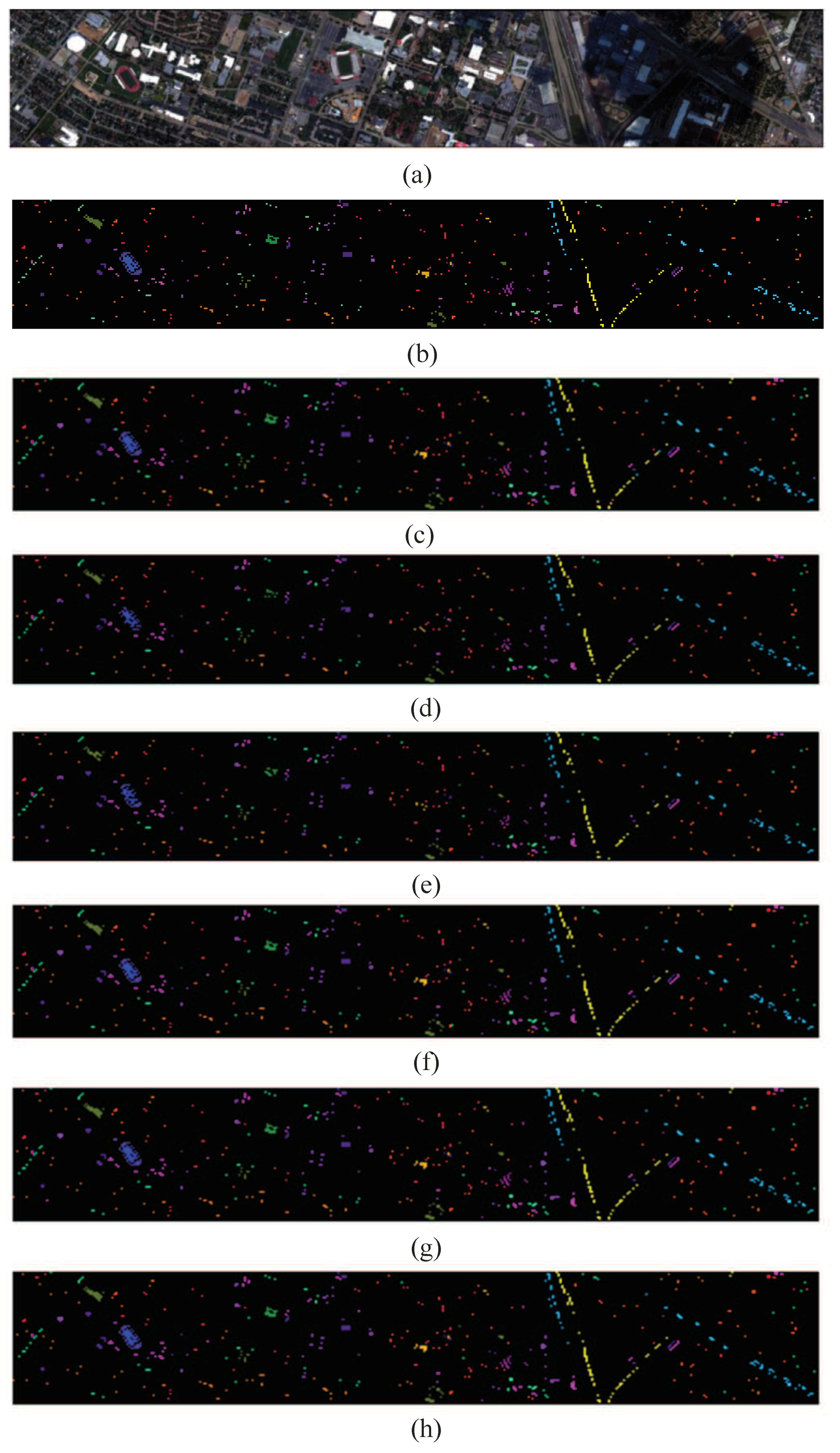
In this paper, we have proposed a new framework based on DL for HSIs classification. Although the method based on DL has achieved good results in HSIs classification, the automatically extracted features are still rough and contain a lot of noise. Therefore, we investigate to reduce the noise of features and select more appropriate features by octave 3D CNN and attention mechanism operations.
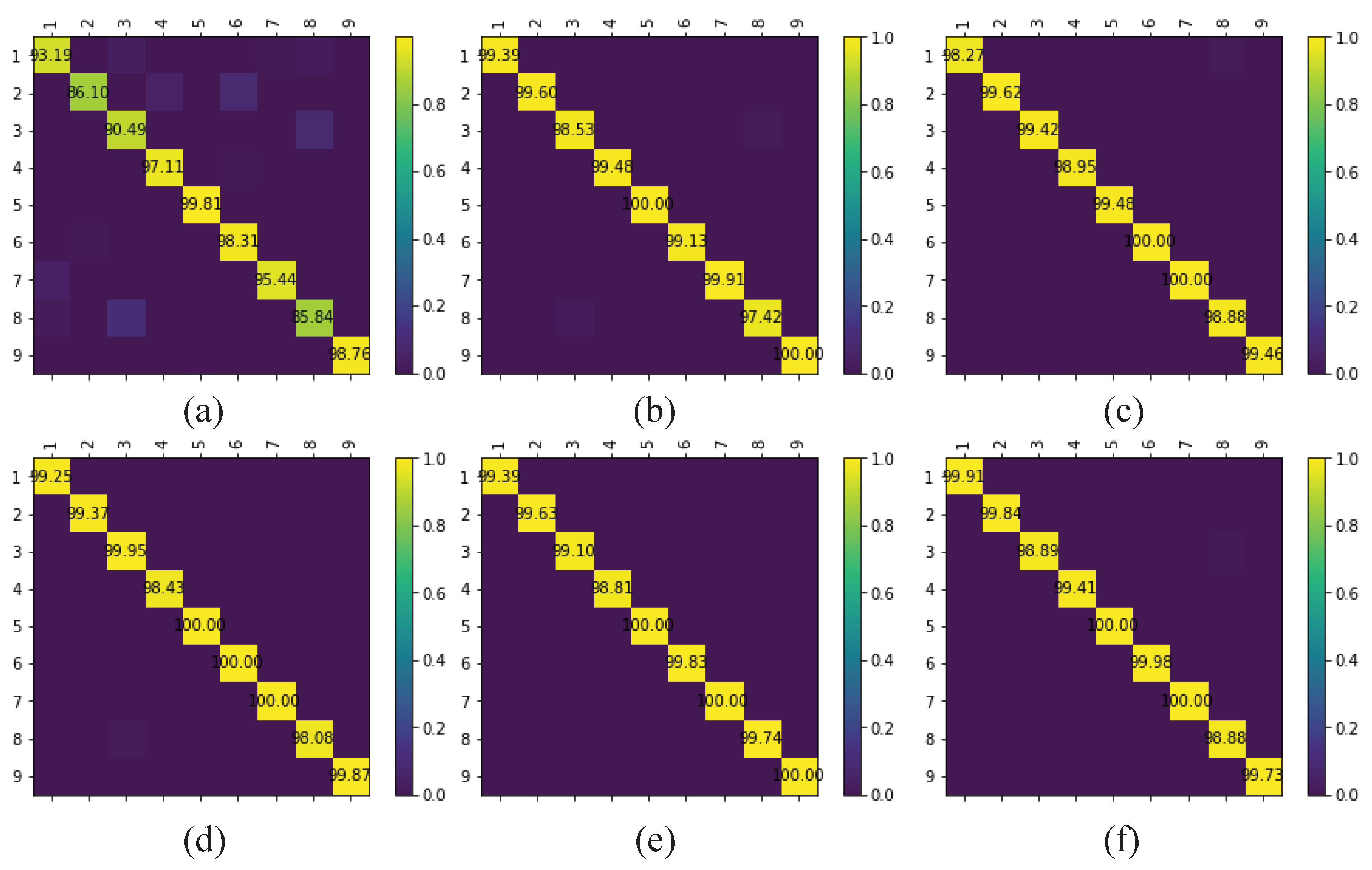
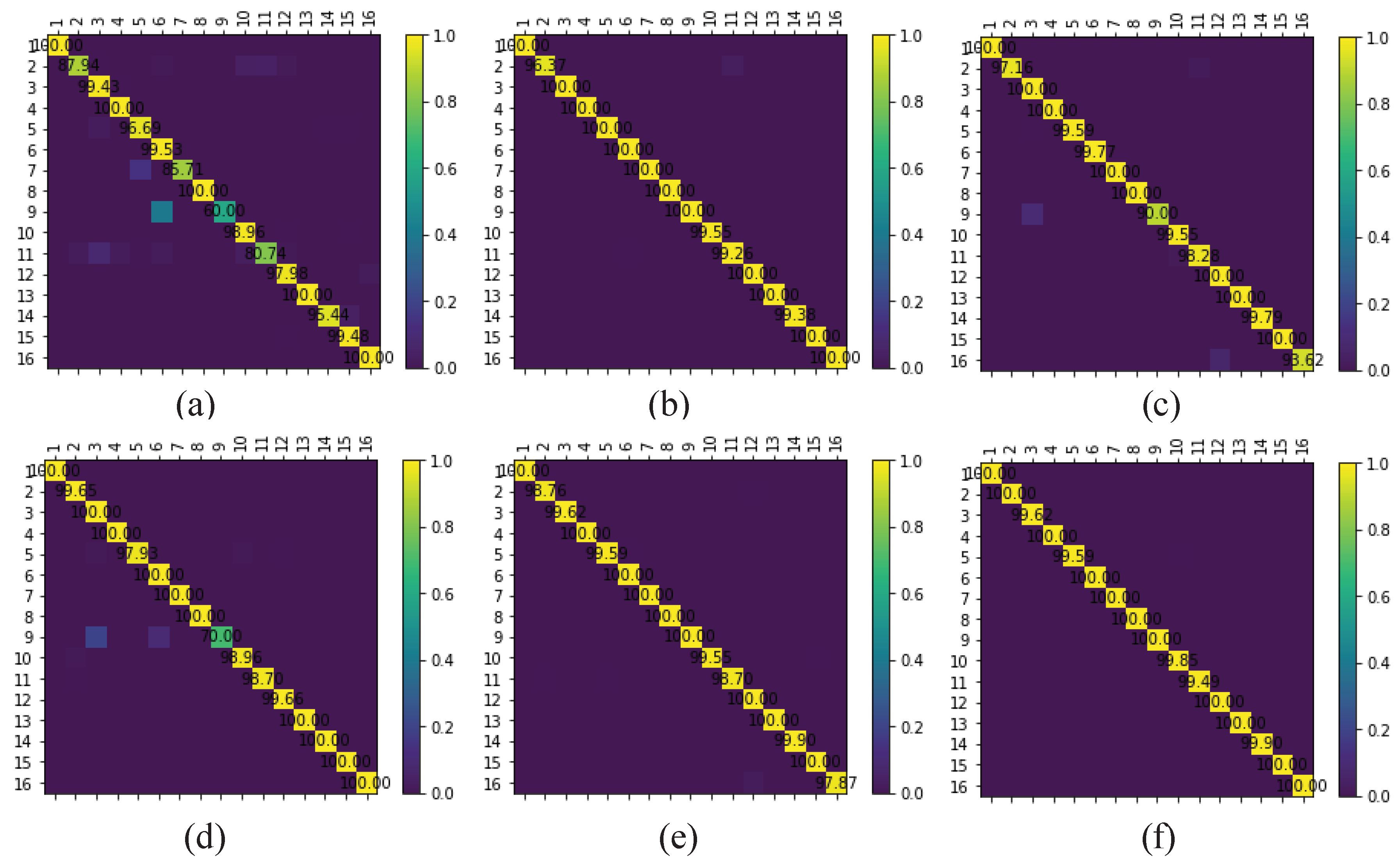
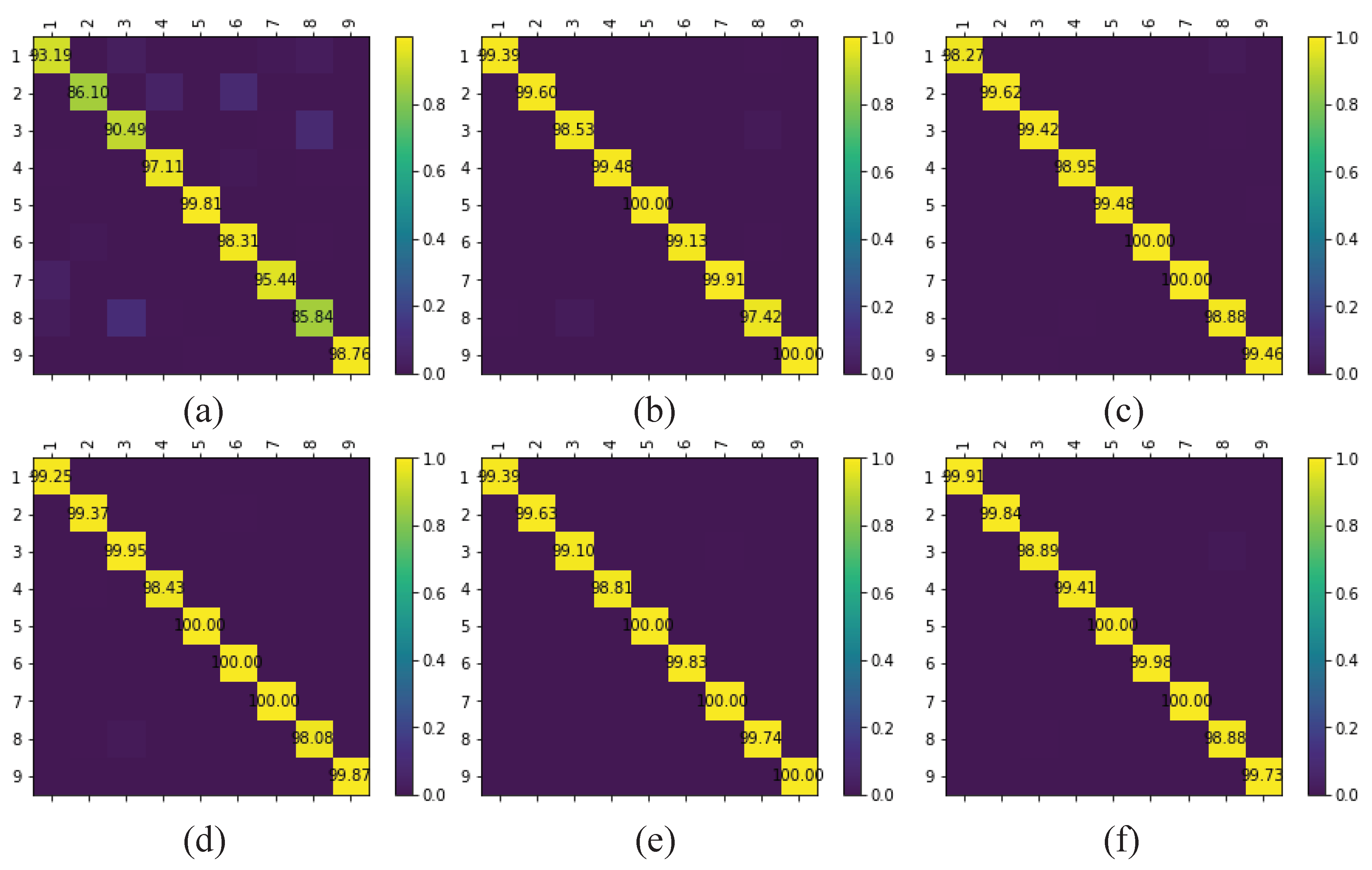
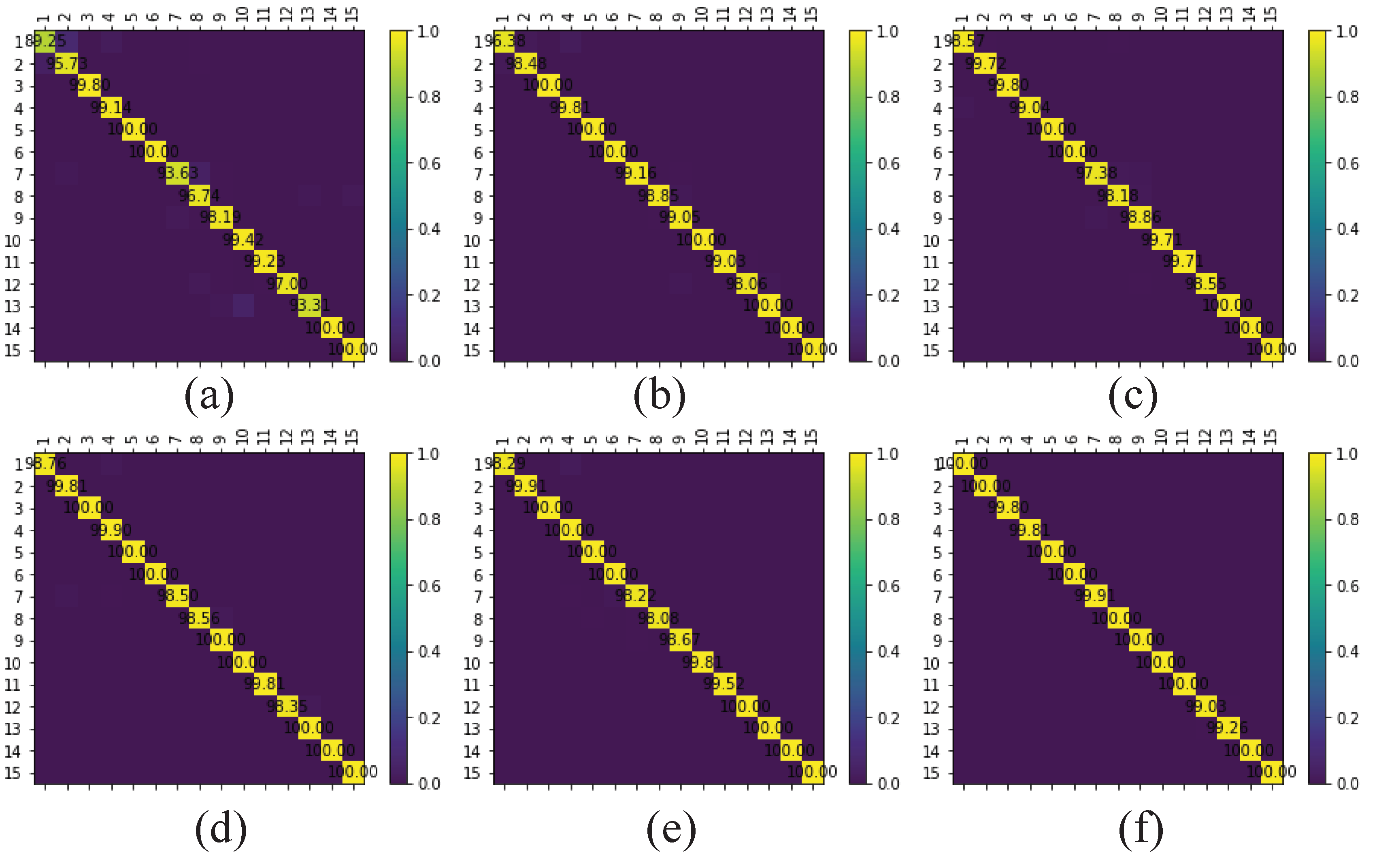
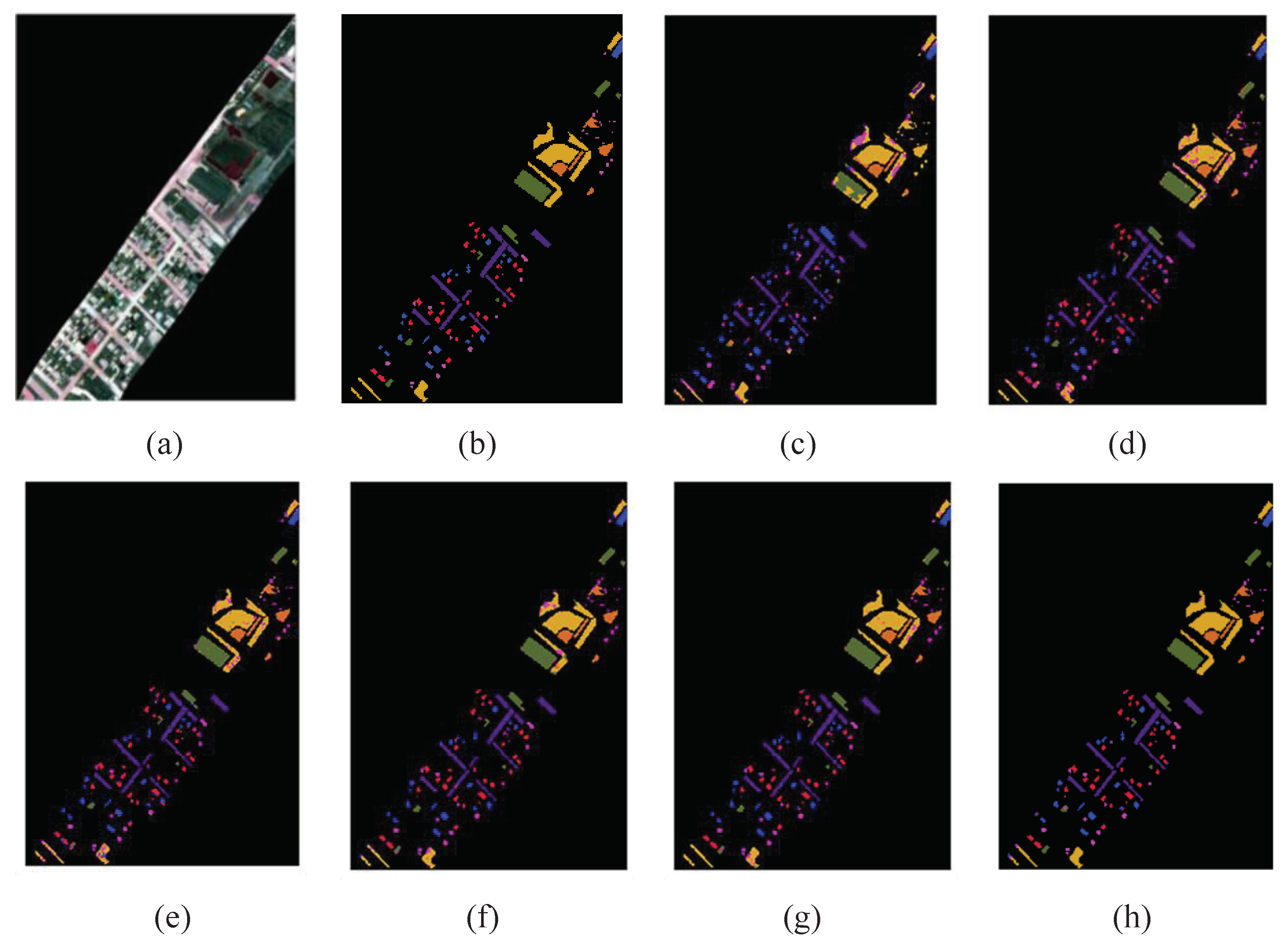
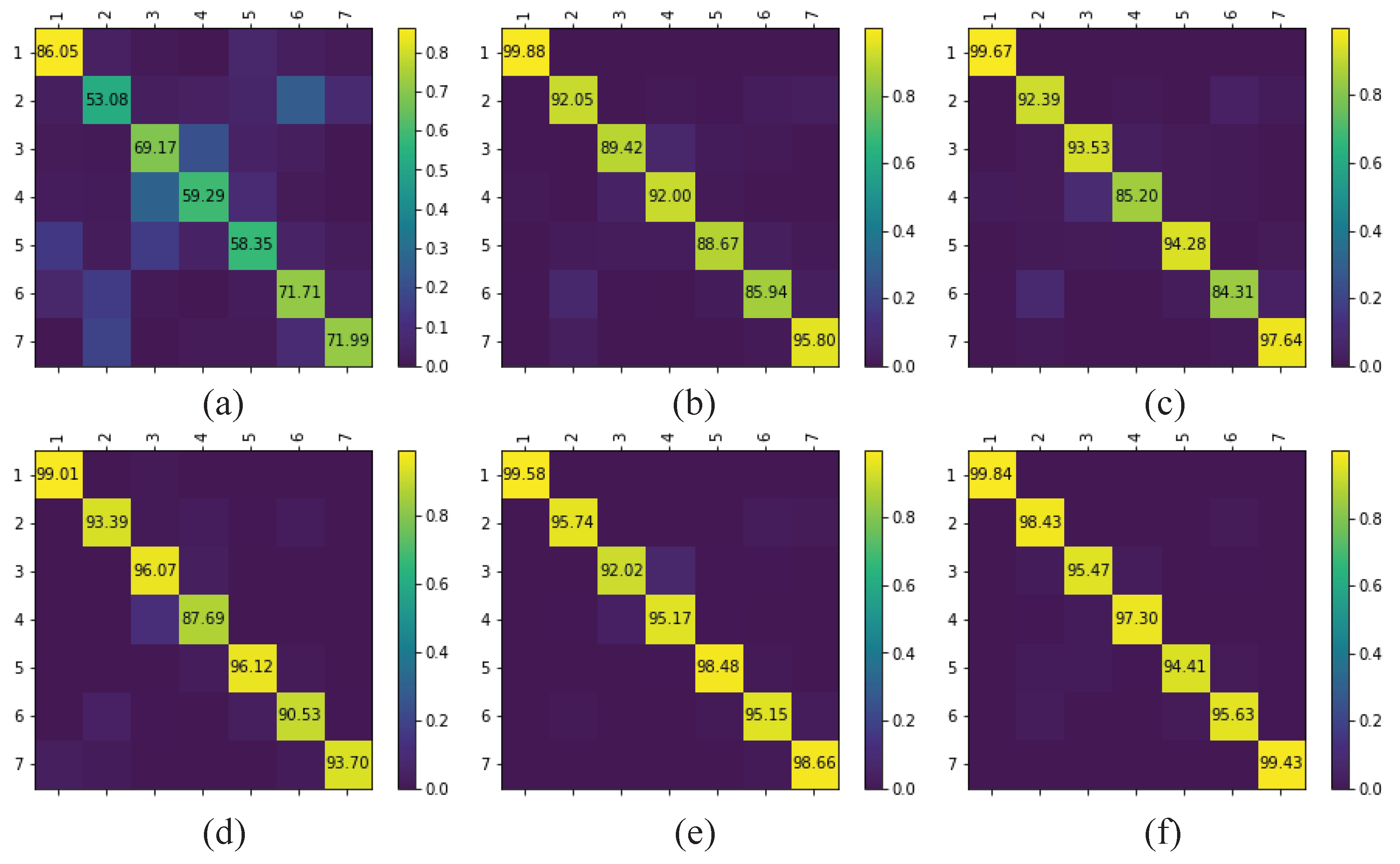
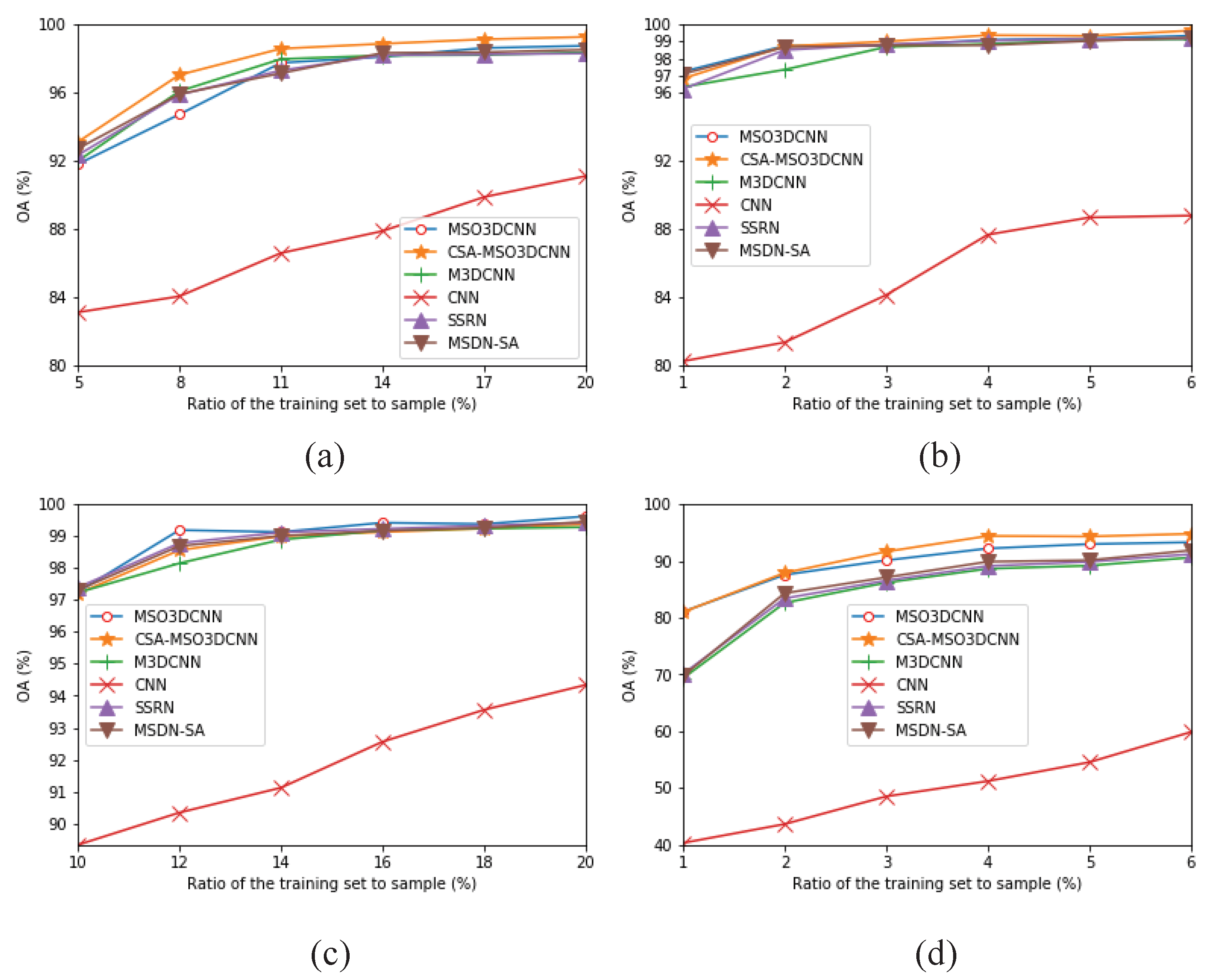
The multi-scale octave 3D convolution is designed to decrease the spatial redundancy and expand the receptive field which are proven to be important for extracting appropriate features. Then, three different group feature maps are cascaded into one. In addition, a channel attention module and a spatial attention module are employed to refine the feature maps, which not only assign different weights to the feature maps along the channel dimension but also along the spatial dimension. The refined feature maps have been demonstrated to be beneficial for improving the classification performance. The results of ablation experiments have shown the efficiency of the attention modules. The experimental results on four public HSIs data sets have demonstrated that the proposed CSA-MSO3DCNN outperforms the state-of-the-art methods. Accordingly, it can be concluded that our method is more suitable for HSIs classification.
Because of the limit labeled HSIs pixel samples and the difficult of labeling the HSIs pixel samples, as future work, we intend to explore the HSI classification methods combined with the data enhancement techniques and semi-supervised HSIs classification in order to overcome the problem of the limit labeled HSIs pixel samples.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}