Random Forest Spatial Interpolation

 , , ,
, , ,
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Methodology
2.1.1. Deterministic Interpolation Methods
2.1.2. Kriging
2.1.3. Random Forest
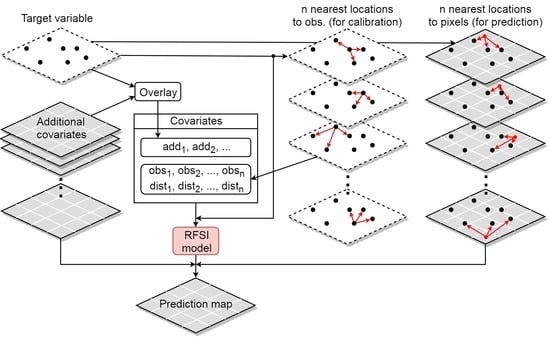
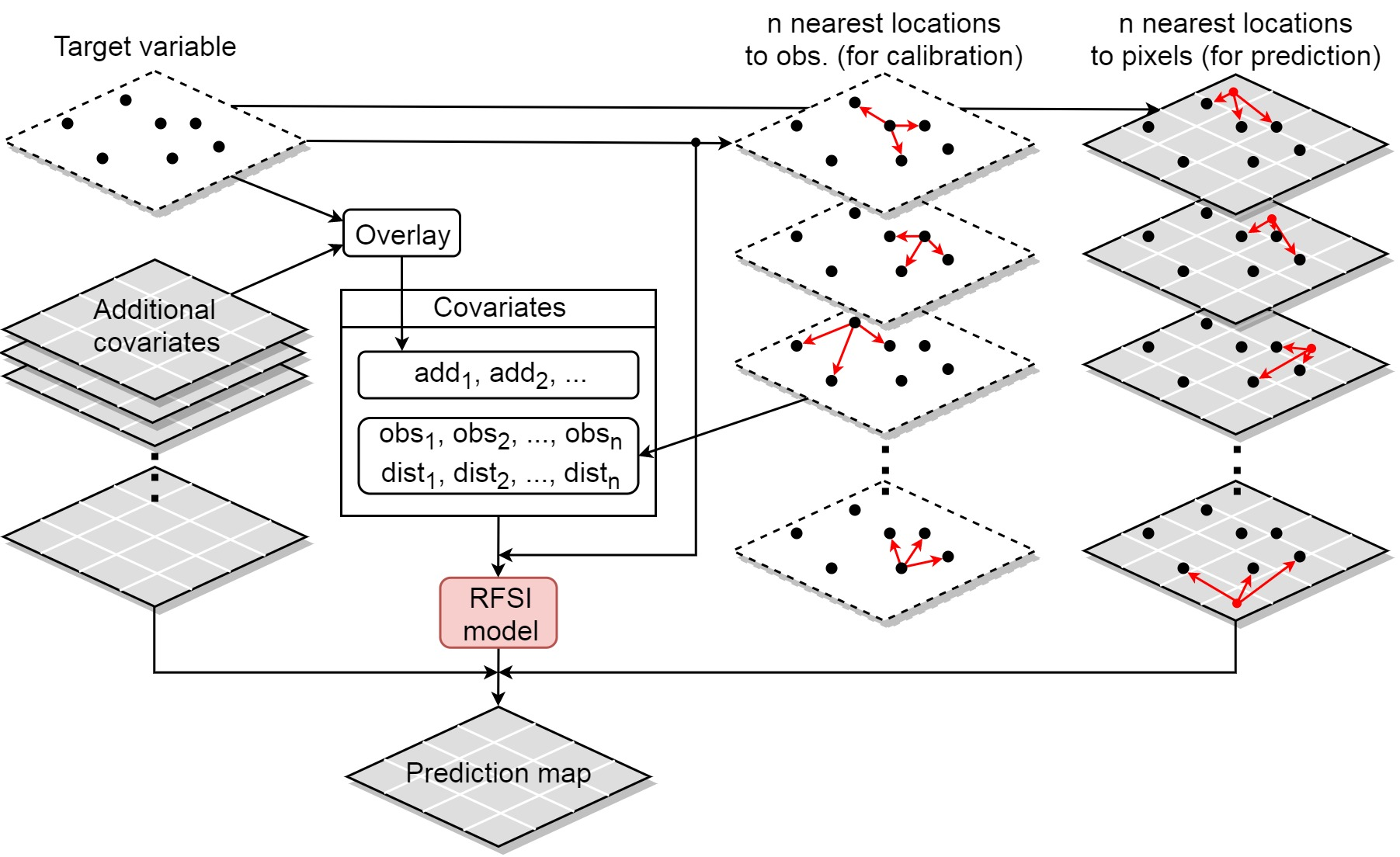
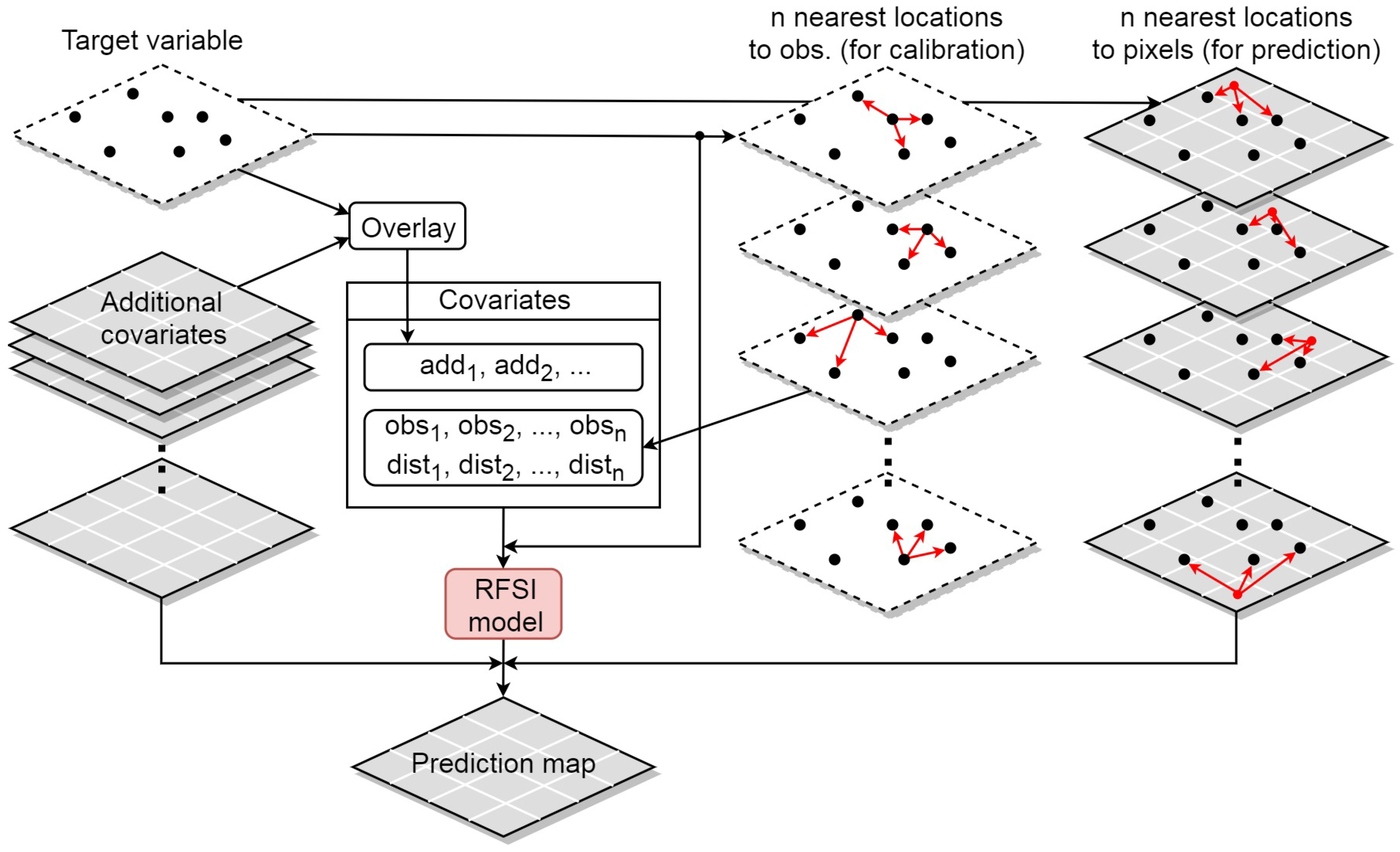
2.1.4. Random Forest Spatial Interpolation
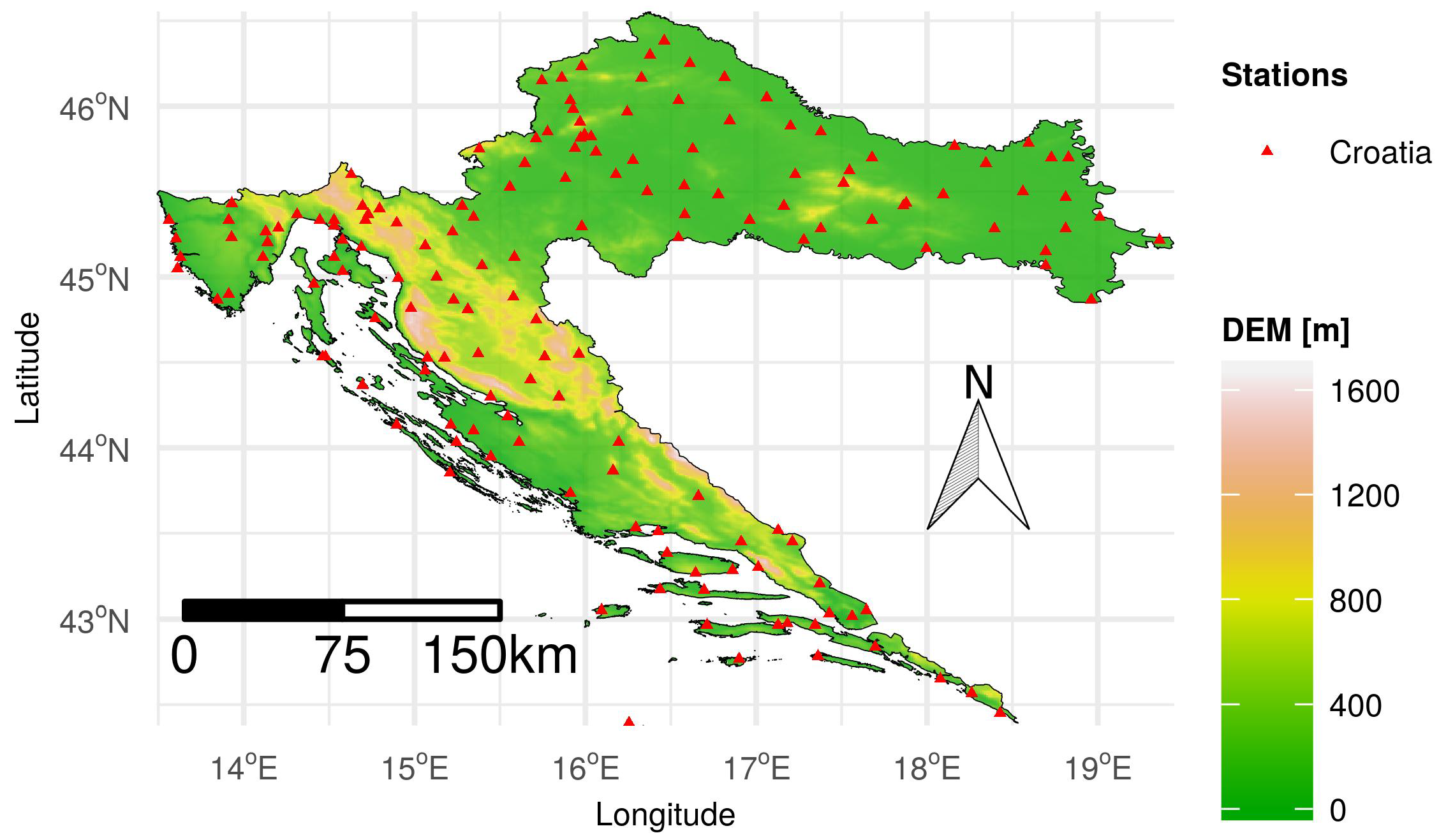
2.2. Datasets and Covariates
2.2.1. Synthetic Dataset
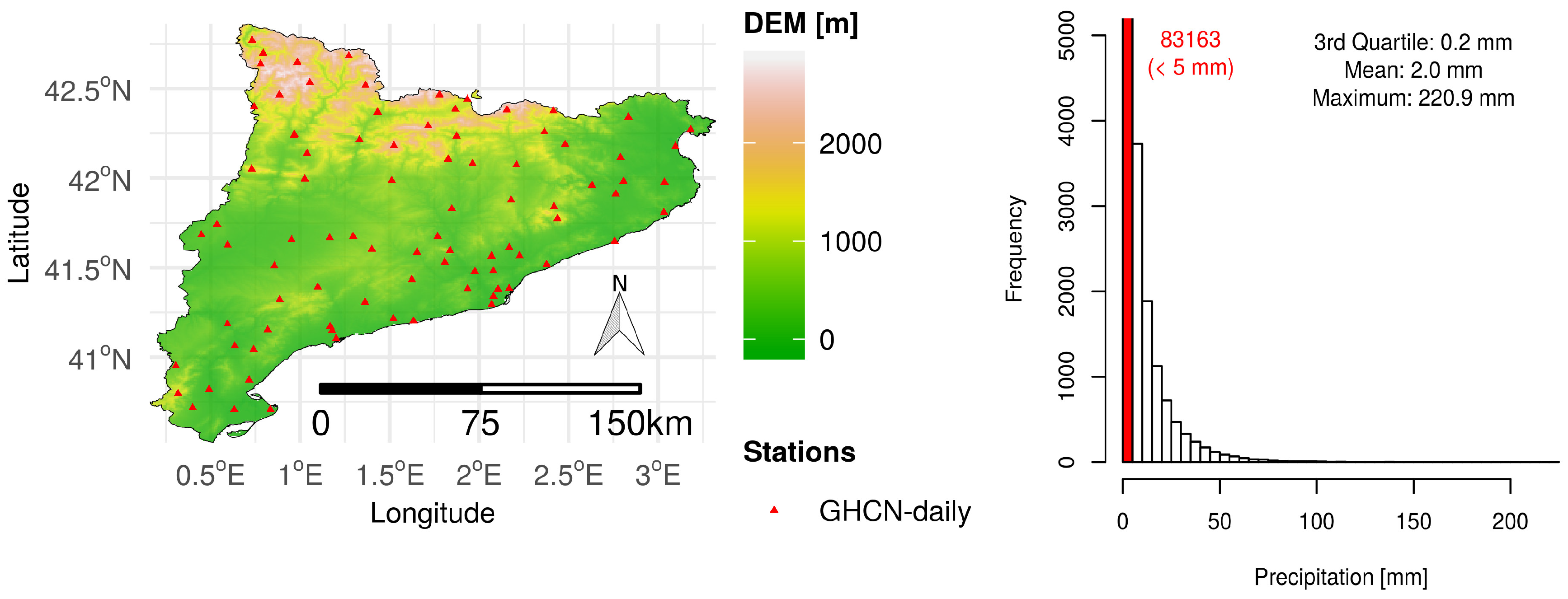
2.2.2. Precipitation Dataset
2.2.3. Temperature Dataset
2.3. Accuracy Assessment
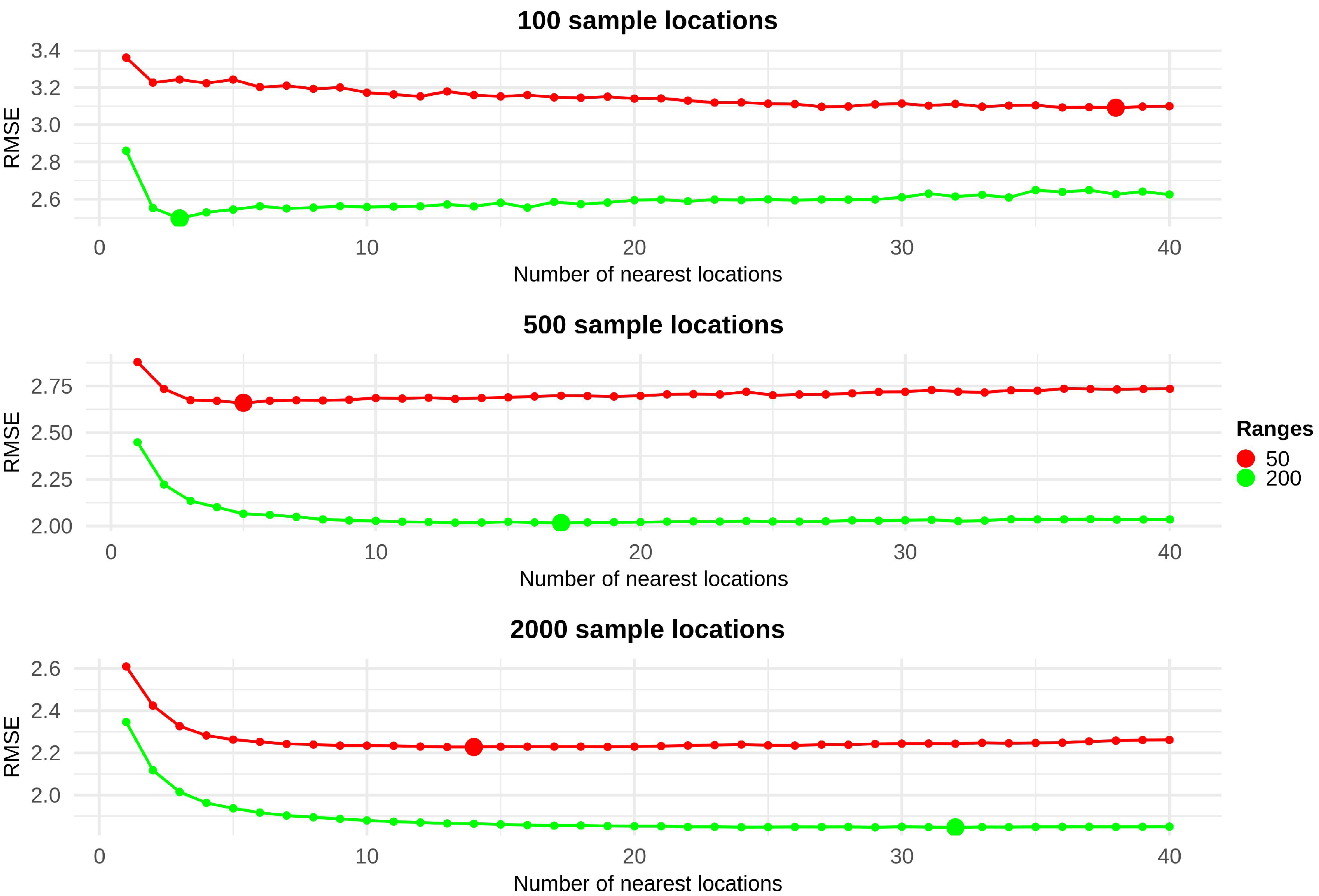
2.3.1. Synthetic Case Study
2.3.2. Real-World Case Studies
3. Results
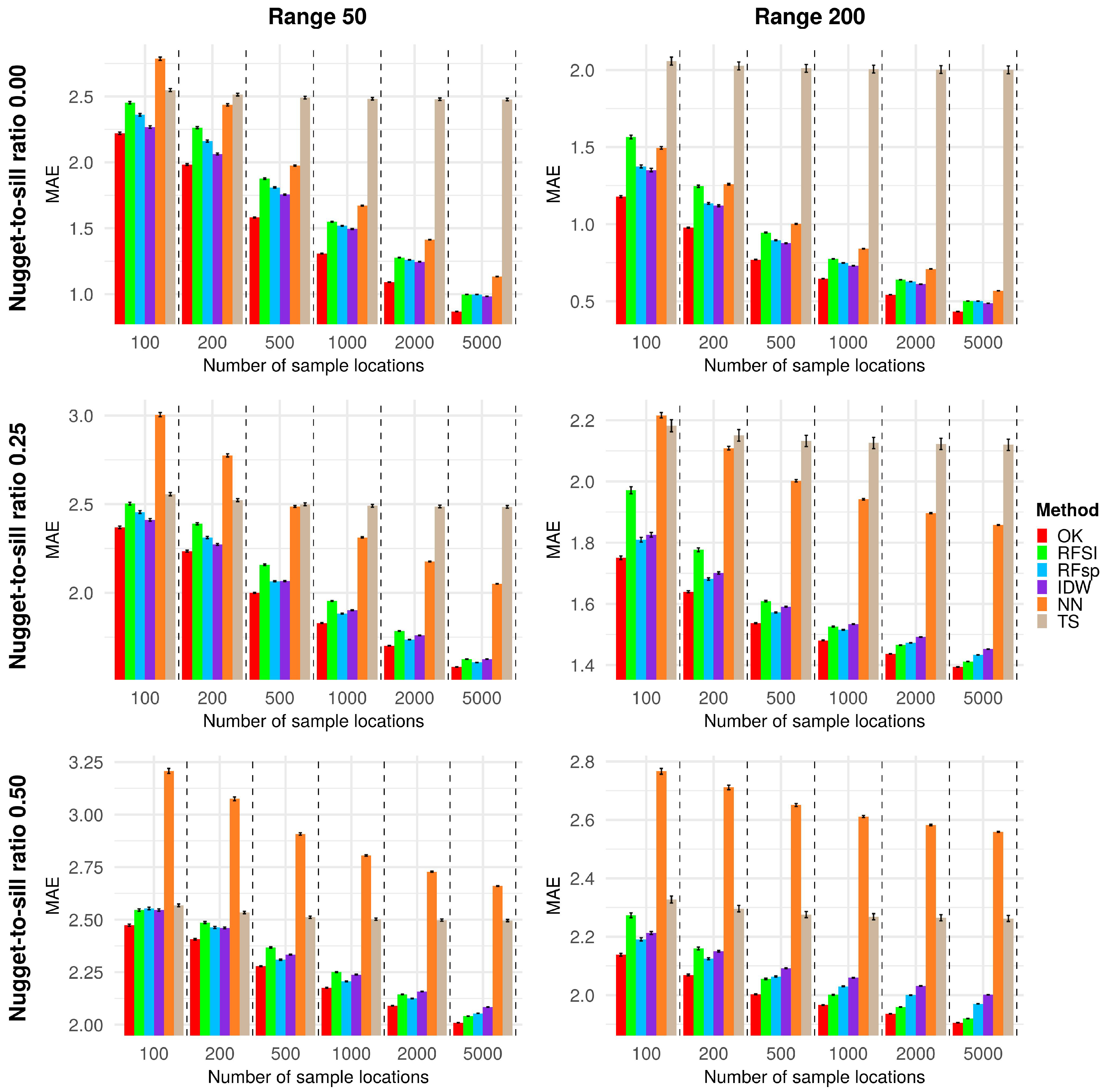
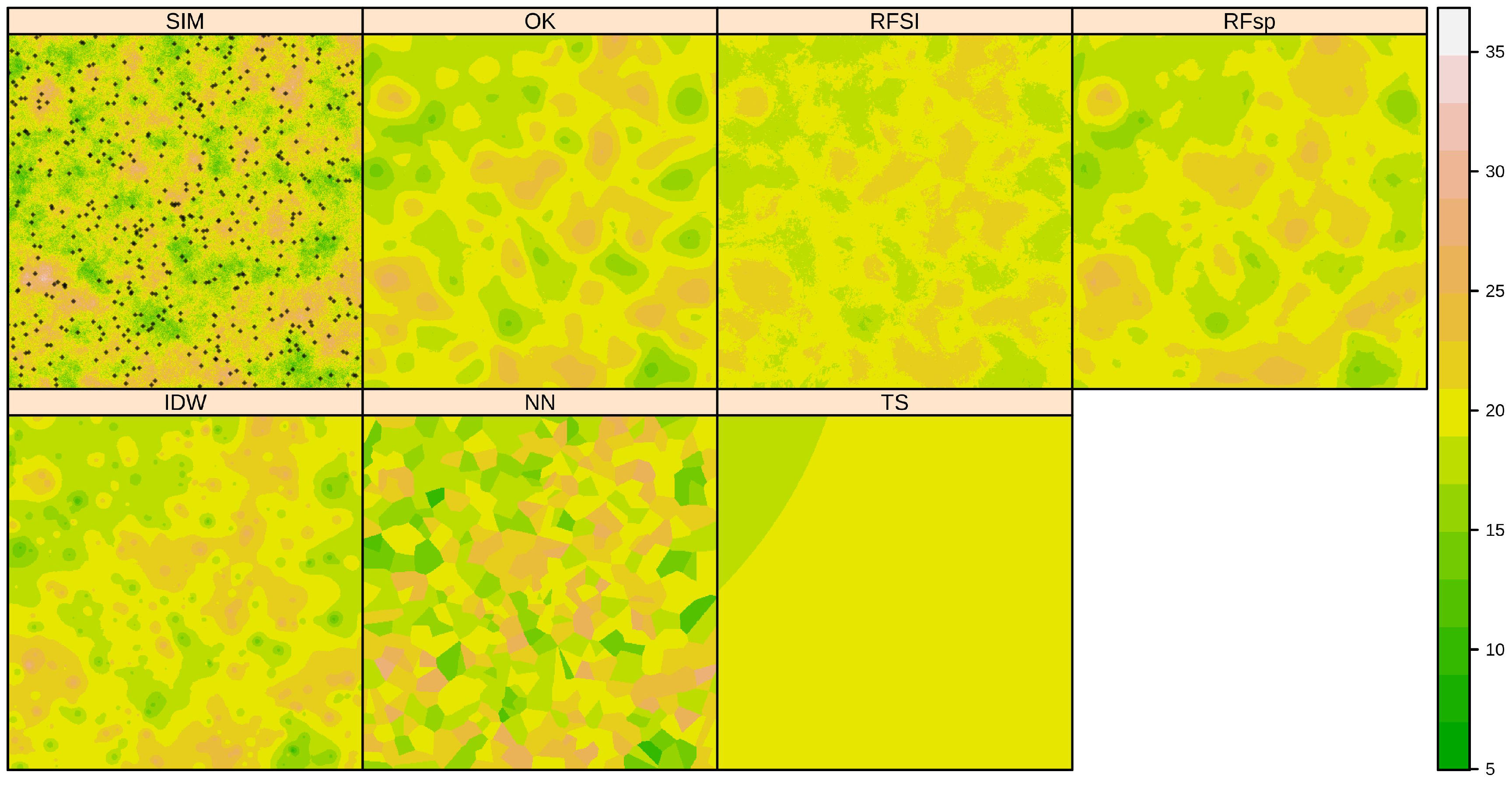
3.1. Synthetic Case Study
3.2. Precipitation Case Study
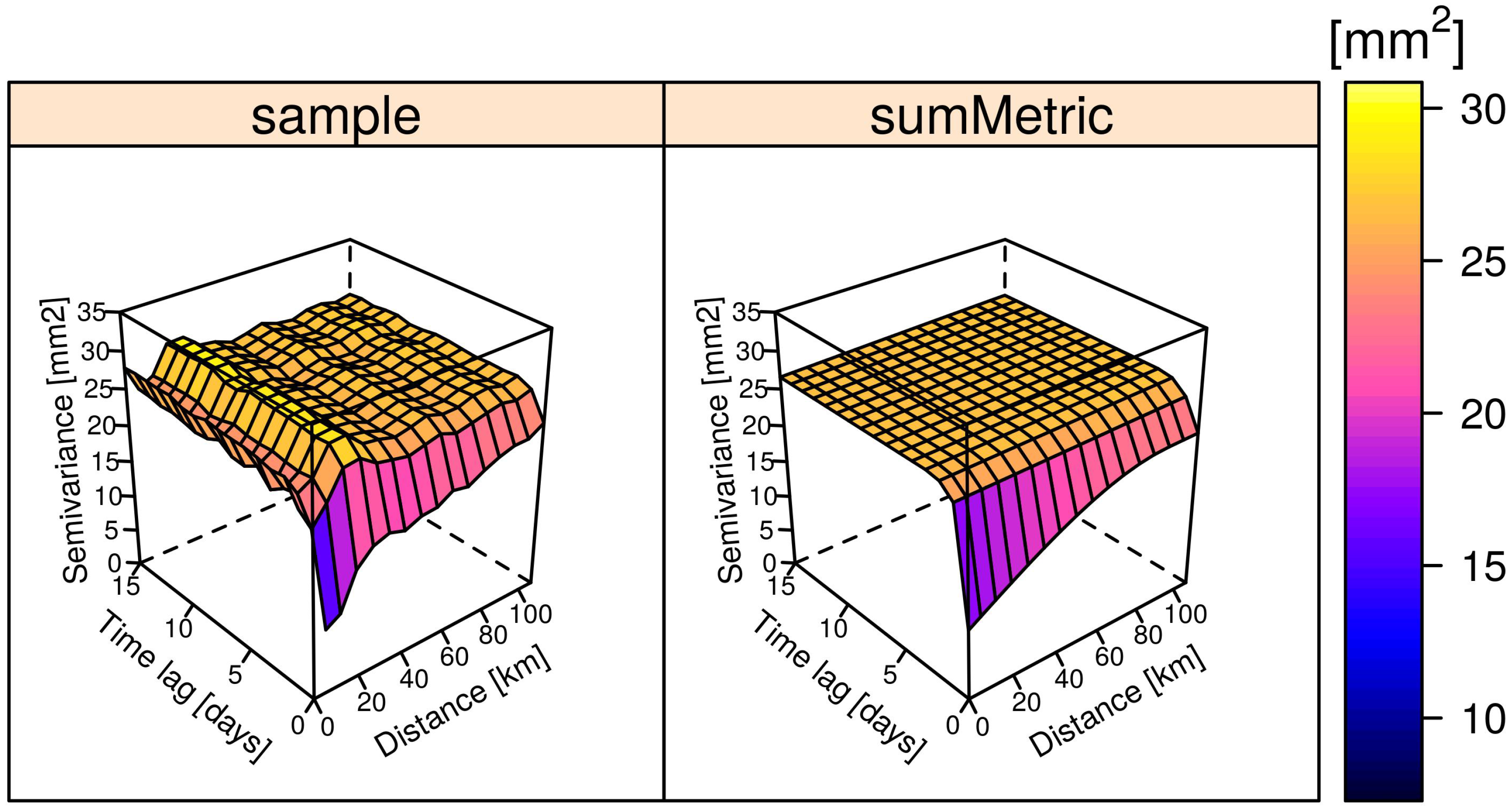
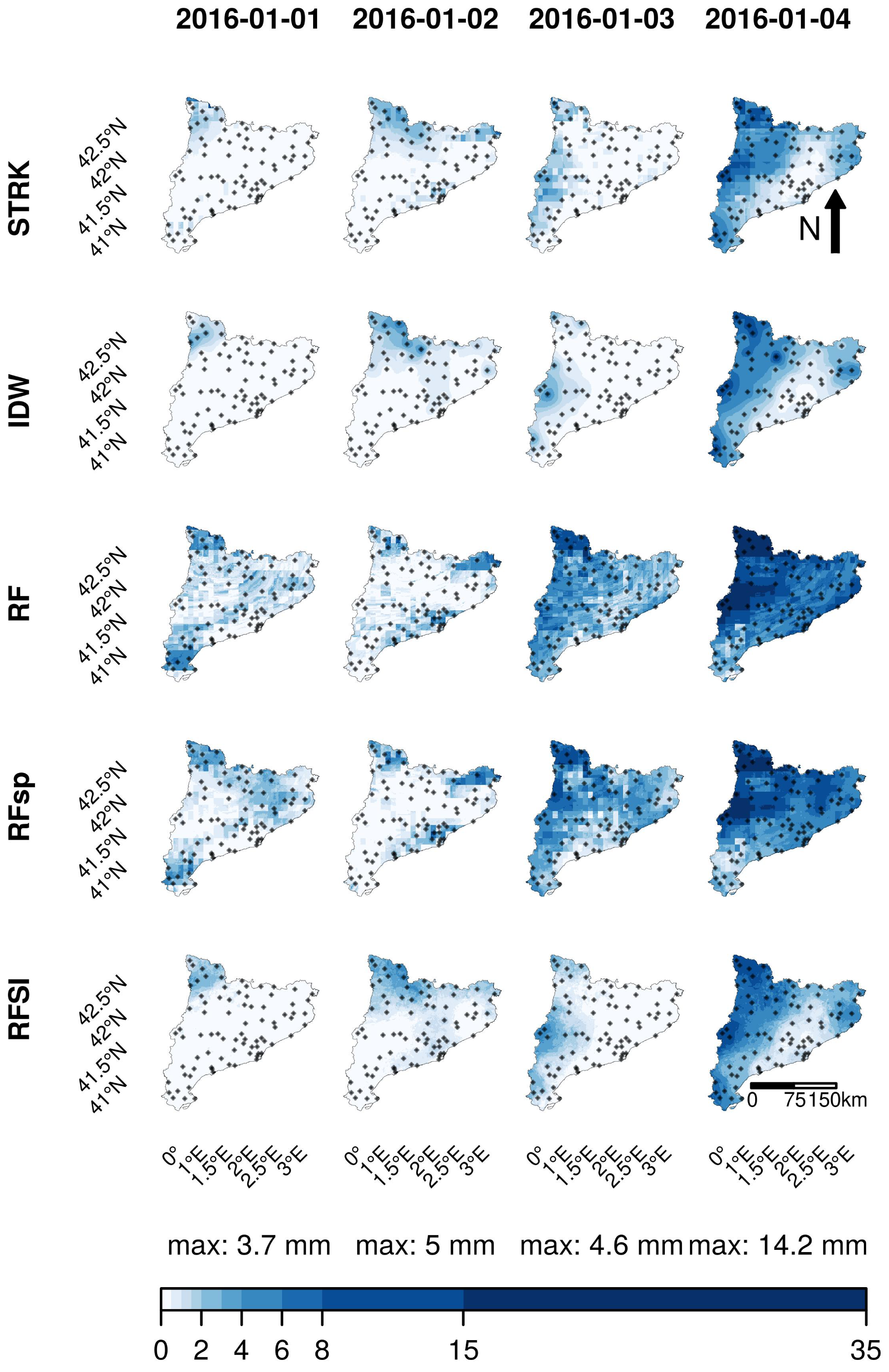
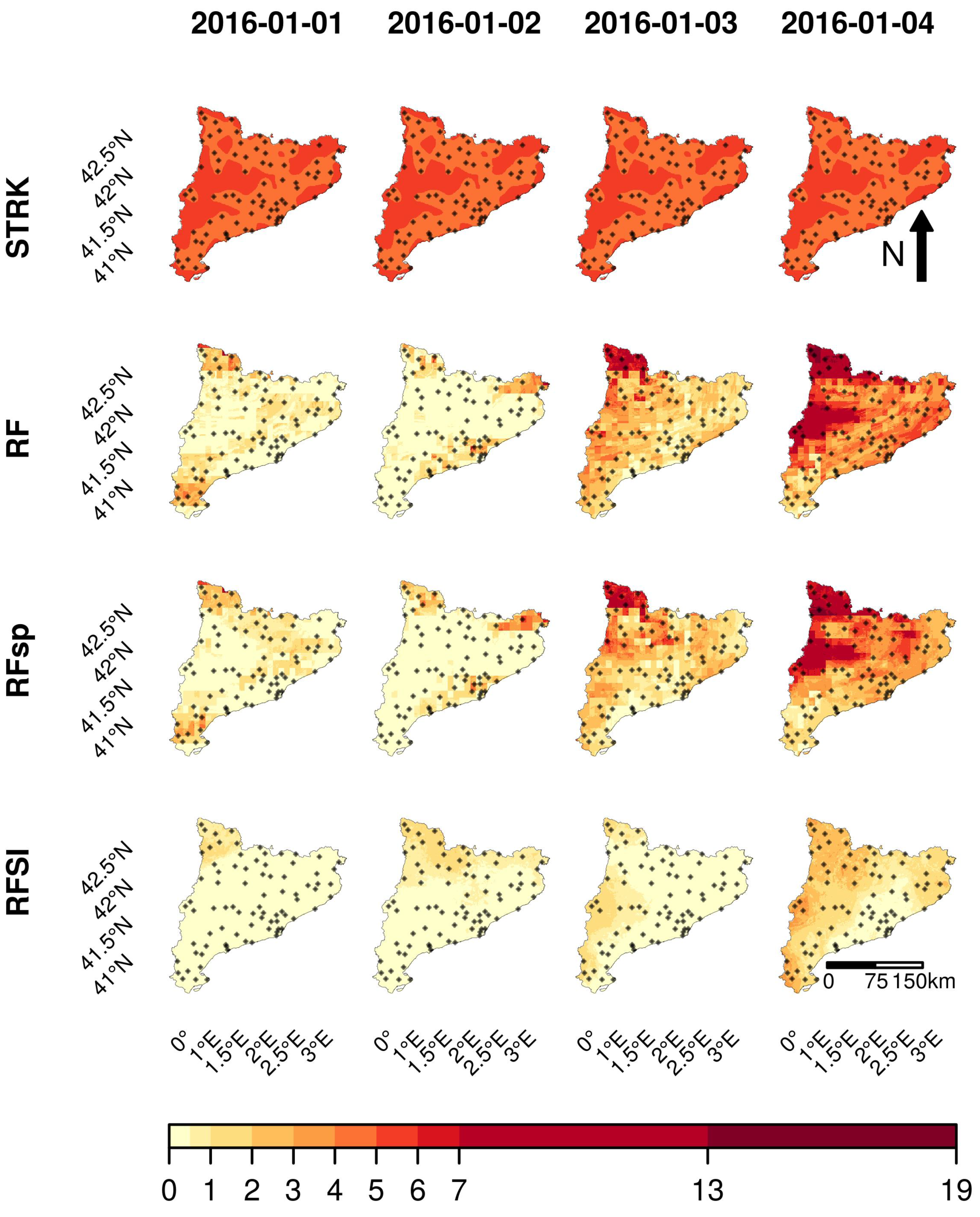
3.2.1. Space–Time Regression Kriging (STRK)
3.2.2. IDW and Random Forest Models
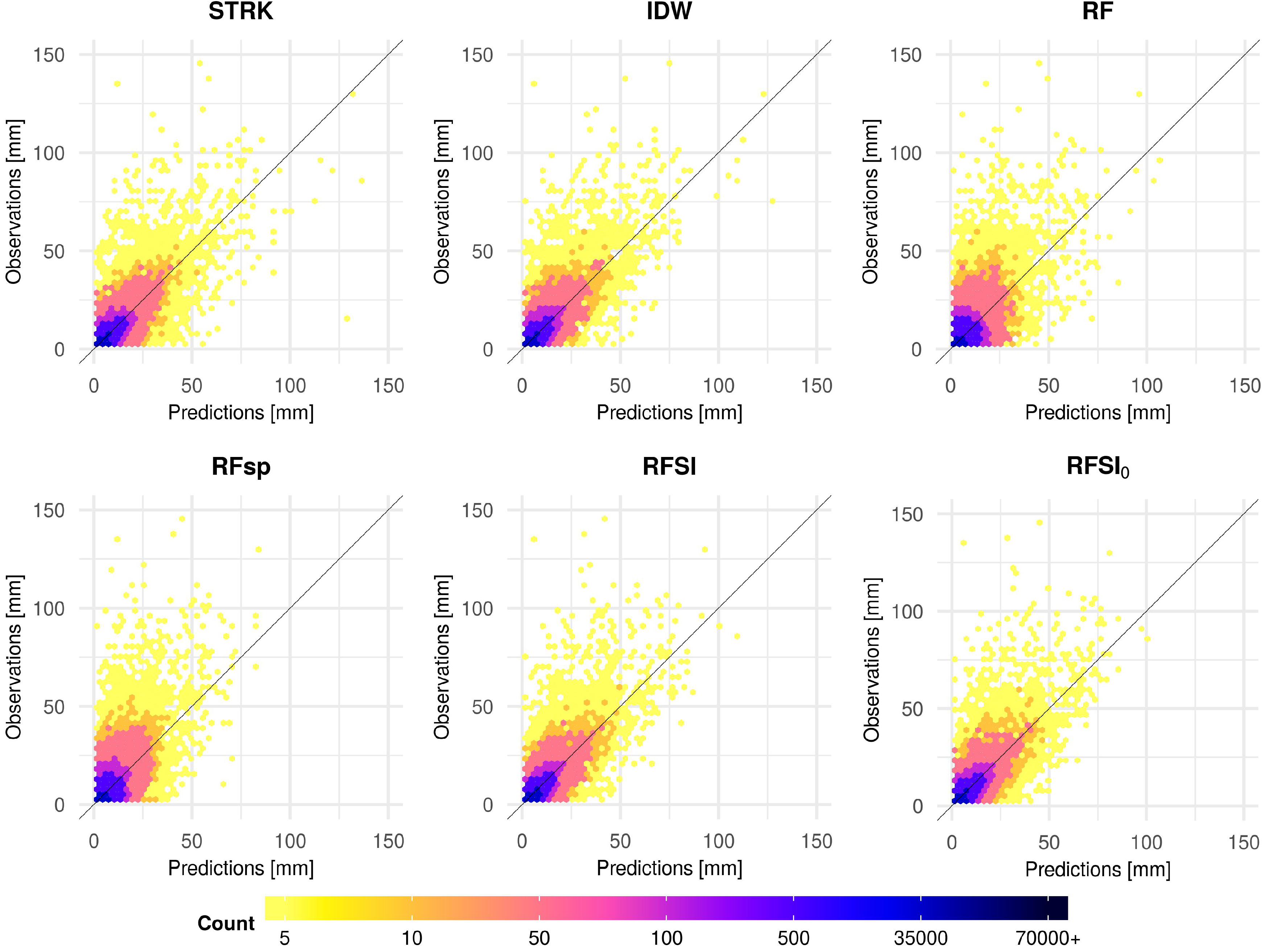
3.2.3. Accuracy Assessment
3.3. Temperature Case Study
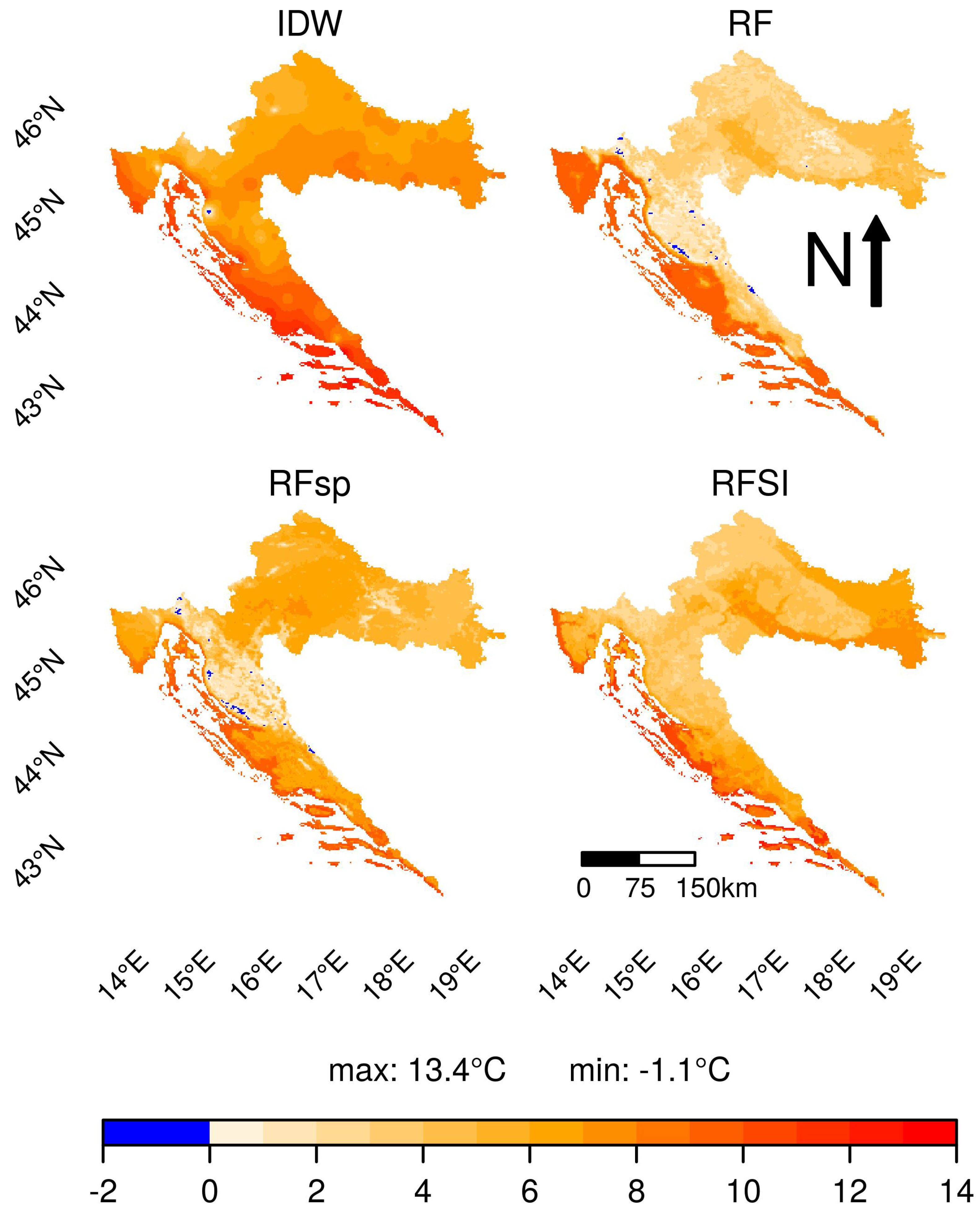
3.3.1. IDW and Random Forest models
3.3.2. Accuracy Assessment
4. Discussion
4.1. RFSI Performance
- RFSI is much closer to the philosophy of spatial interpolation than standard RF and RFsp. RFSI uses observations nearby in a direct way to predict at a location. RFsp uses a much more indirect way to include the spatial context in RF prediction. In fact, RFSI mimics kriging much more than RFsp, with the additional advantage that it is not restricted to a weighted linear combination of neighbouring observations.
- Compared to kriging, RFSI is easier to fit, because there is no need for semivariogram modelling and stringent stationarity assumptions.
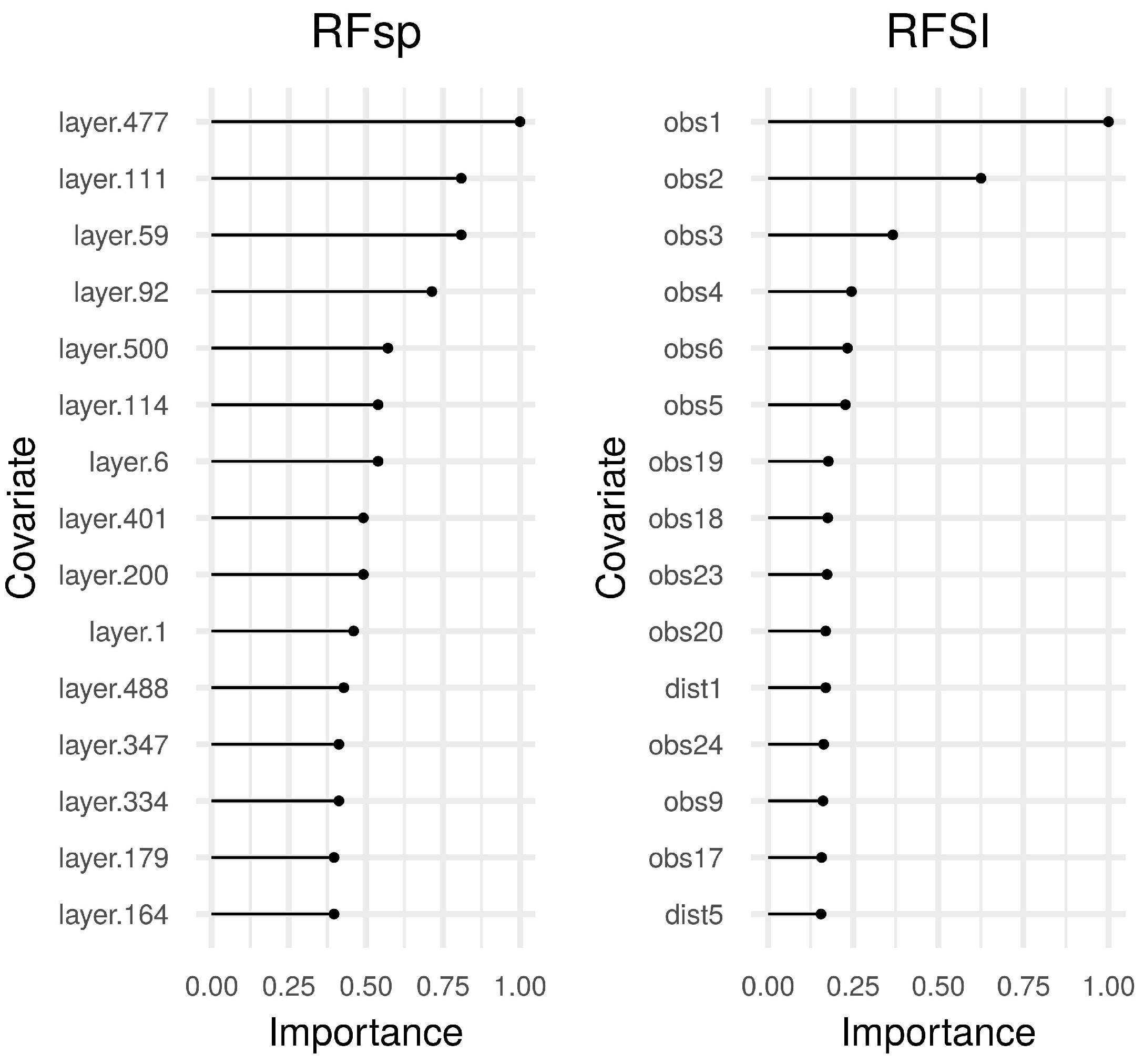
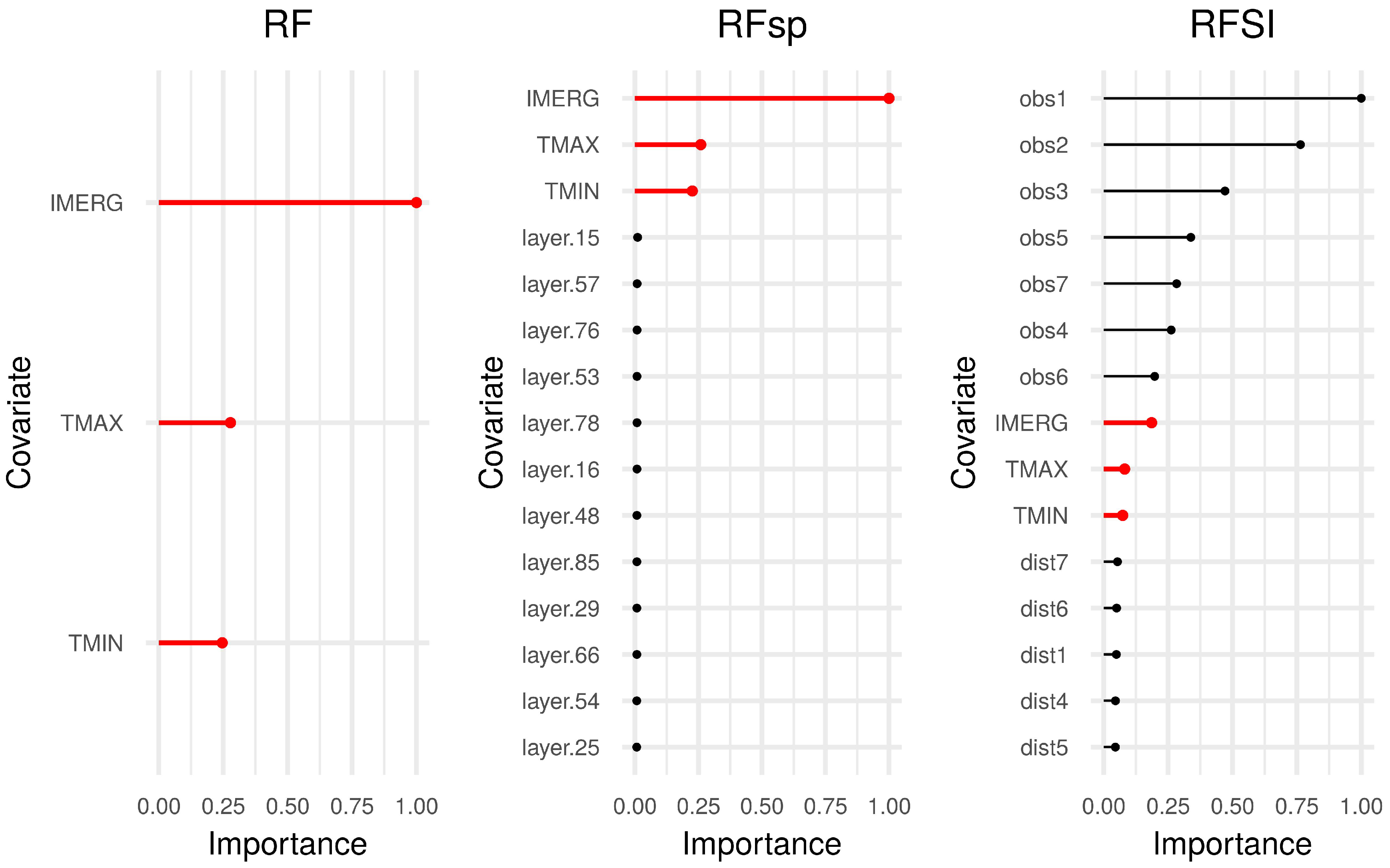
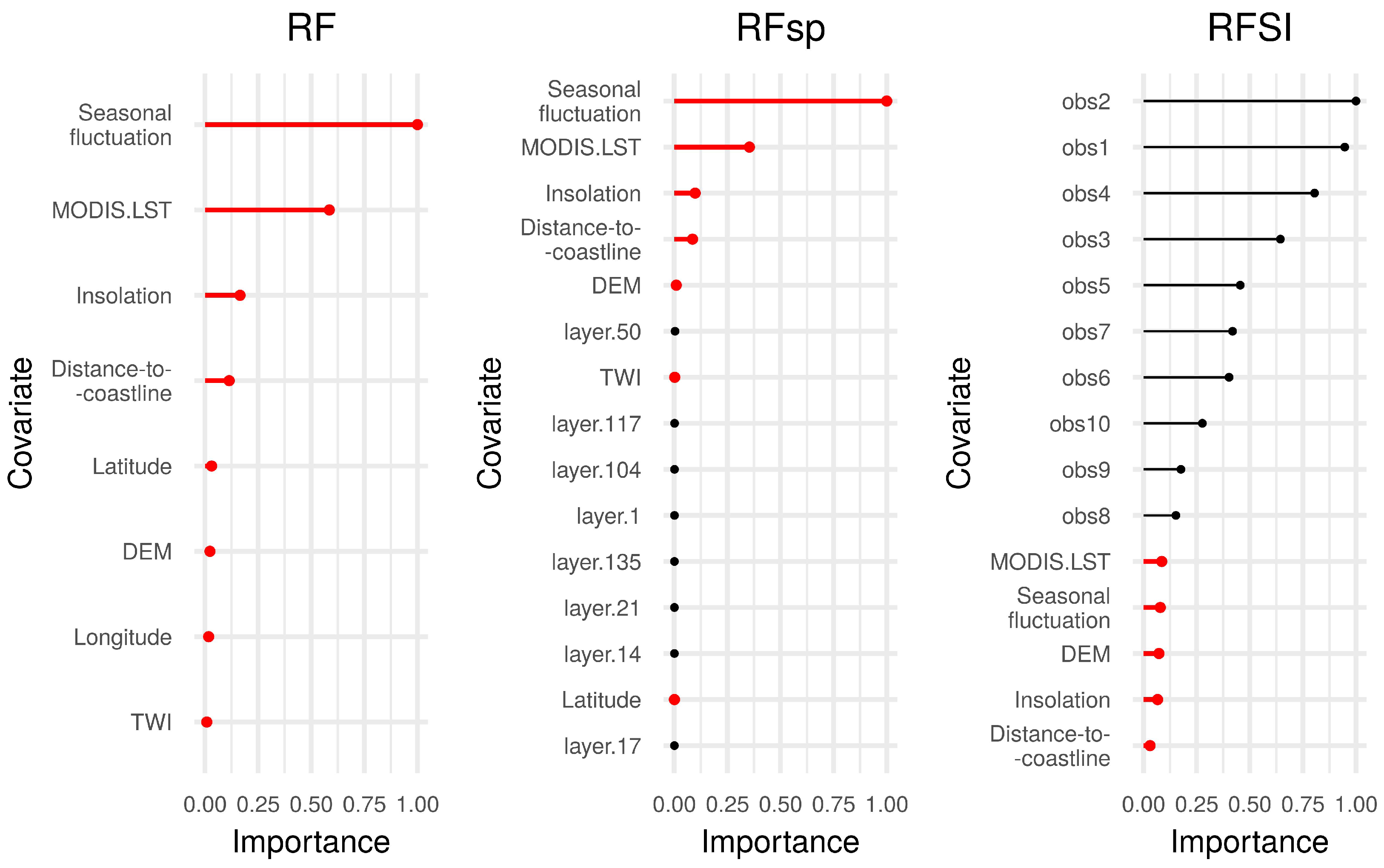
- RFSI provides a model with more interpretative power than RFsp, i.e., the importance of the first, second, third, etc., nearest observations can be assessed and compared with each other (Figure 6) and with the importance of environmental covariates (Figure 10 and Figure 14). RFsp variable importance shows how important buffer distances from observation points are, but this is difficult to interpret, because it is unclear why certain buffer distance layers have high importance and others do not. However, it should be noted that feature importance is difficult to measure objectively in cases where covariates are cross-correlated and their influence may be masked by other covariates.
- RFSI has several orders of magnitude better scaling properties than RFsp. In RFsp the number of spatial covariates equals the number of observations, whereas in RFSI it is optimized and fairly independent of the number of observations.
- Hengl et al. [8] recommended using RFsp for fewer than 1000 locations. For more than 1000 locations RFsp becomes slow because buffer distances cannot be computed quickly (Table 1). The calculation of spatial covariates needed to apply RFSI, (Euclidean) distances and observations to the nearest locations, is not computationally extensive.
- RFsp cannot be spatially cross-validated properly, i.e., with nested LLOCV. Considering that in nested LLOCV entire stations are held out, the buffer distance covariates in the test dataset (consisting of one main fold) and nested folds of the calibration dataset (consisting of the other folds) are not the same. Therefore, RFsp hyperparameters tuned on the nested folds with one set of buffer distance covariates can be a poor choice to make predictions on the test dataset.
4.2. Extensions and Improvements
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| RFSI | Random Forest Spatial Interpolation |
| RFsp | Random Forest for Spatial Predictions framework |
| NN | Nearest Neighbour |
| IDW | Inverse Distance Weighting |
| TS | Trend Surface mapping |
| BLUP | Best Linear Unbiased Predictor |
| ML | Machine Learning |
| RS | Remote Sensing |
| RK | Regression Kriging |
| KED | Kriging with External Drift |
| OK | Ordinary Kriging |
| RF | Random Forest |
| SVM | Support Vector Machines |
| ANN | Artificial Neural Networks |
| NEX-GDM | NASA Earth Exchange Gridded Daily Meteorology |
| GRF | Geographical Random Forest |
| STRK | Space–Time Regression Kriging |
| CART | Classification And Regression Trees |
| OOB | Out-Of-Bag |
| GHCN-daily | daily Global Historical Climatological Network |
| DEM | Digital Elevation Model |
| IMERG | Integrated Multi-satellitE Retrievals for GPM |
| TMAX | Maximum Temperature |
| TMIN | Minimum Temperature |
| MODIS LST | Moderate Resolution Imaging Spectroradiometer Land Surface Temperature |
| CCC | Lin’s Concordance Correlation Coefficient |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Square Error |
| ESS | Error Sum of Squares |
| TSS | Total Sum of Squares |
| LLOCV | Leave-Location Out Cross-Validation |
| QRF | Quantile Regression Forest |
| IQR | Interquartile Range |
| RFSI | RFSI without environmental covariates |
| DOY | Day Of Year |
| CDATE | Cumulative Day from a Date |
References
- Thiessen, A.H. Precipitation averages for large areas. Mon. Weather Rev. 1911, 39, 1082–1089. [Google Scholar] [CrossRef]
- Willmott, C.J.; Rowe, C.M.; Philpot, W.D. Small-Scale Climate Maps: A Sensitivity Analysis of Some Common Assumptions Associated with Grid-Point Interpolation and Contouring. Am. Cartogr. 1985, 12, 5–16. [Google Scholar] [CrossRef]
- Chorley, R.J.; Haggett, P. Trend-Surface Mapping in Geographical Research. Trans. Inst. Br. Geogr. 1965, 37, 47–67. [Google Scholar] [CrossRef]
- Matheron, G. Principles of geostatistics. Econ. Geol. 1963, 58, 1246–1266. [Google Scholar] [CrossRef]
- Goovaerts, P. Geostatistics for Natural Resources Evaluation; Oxford University Press: Oxford, UK, 1997. [Google Scholar] [CrossRef]
- Diggle, P.J.; Ribeiro, P.J. Model-Based Geostatistics; Springer Series in Statistics; Springer: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Webster, R.; Oliver, M.A. Geostatistics for Environmental Scientists; Statistics in Practice; John Wiley & Sons, Ltd.: Chichester, UK, 2007. [Google Scholar] [CrossRef] [Green Version]
- Hengl, T.; Nussbaum, M.; Wright, M.N.; Heuvelink, G.B.M.; Gräler, B. Random forest as a generic framework for predictive modeling of spatial and spatio-temporal variables. PeerJ 2018, 6, e5518. [Google Scholar] [CrossRef] [Green Version]
- Journel, A.G. Nonparametric estimation of spatial distributions. J. Int. Assoc. Math. Geol. 1983, 15, 445–468. [Google Scholar] [CrossRef]
- Carrera-Hernández, J.; Gaskin, S. Spatio temporal analysis of daily precipitation and temperature in the Basin of Mexico. J. Hydrol. 2007, 336, 231–249. [Google Scholar] [CrossRef]
- Castro, L.M.; Gironás, J.; Fernández, B. Spatial estimation of daily precipitation in regions with complex relief and scarce data using terrain orientation. J. Hydrol. 2014, 517, 481–492. [Google Scholar] [CrossRef]
- Gräler, B.; Rehr, M.; Gerharz, L.; Pebesma, E.J. Spatio-Temporal Analysis and Interpolation of PM10 Measurements in Europe for 2009. ETC/ACM Tech. Paper 2012/08 2013, 30p. Available online: https://www.eionet.europa.eu/etcs/etc-atni/products/etc-atni-reports/etcacm_2012_8_spatio-temp_pm10analyses (accessed on 1 February 2020).
- Li, J.; Heap, A.D. Spatial interpolation methods applied in the environmental sciences: A review. Environ. Model. Softw. 2014, 53, 173–189. [Google Scholar] [CrossRef]
- Li, J.; Heap, A.D.; Potter, A.; Daniell, J.J. Application of machine learning methods to spatial interpolation of environmental variables. Environ. Model. Softw. 2011, 26, 1647–1659. [Google Scholar] [CrossRef]
- Appelhans, T.; Mwangomo, E.; Hardy, D.R.; Hemp, A.; Nauss, T. Evaluating machine learning approaches for the interpolation of monthly air temperature at Mt. Kilimanjaro, Tanzania. Spat. Stat. 2015, 14, 91–113. [Google Scholar] [CrossRef] [Green Version]
- Hengl, T.; Heuvelink, G.B.M.; Kempen, B.; Leenaars, J.G.B.; Walsh, M.G.; Shepherd, K.D.; Sila, A.; MacMillan, R.A.; Mendes de Jesus, J.; Tamene, L.; et al. Mapping Soil Properties of Africa at 250 m Resolution: Random Forests Significantly Improve Current Predictions. PLoS ONE 2015, 10, e0125814. [Google Scholar] [CrossRef]
- Kirkwood, C.; Cave, M.; Beamish, D.; Grebby, S.; Ferreira, A. A machine learning approach to geochemical mapping. J. Geochem. Explor. 2016, 167, 49–61. [Google Scholar] [CrossRef] [Green Version]
- Hashimoto, H.; Wang, W.; Melton, F.S.; Moreno, A.L.; Ganguly, S.; Michaelis, A.R.; Nemani, R.R. High-resolution mapping of daily climate variables by aggregating multiple spatial data sets with the random forest algorithm over the conterminous United States. Int. J. Climatol. 2019, 39, 2964–2983. [Google Scholar] [CrossRef]
- Veronesi, F.; Schillaci, C. Comparison between geostatistical and machine learning models as predictors of topsoil organic carbon with a focus on local uncertainty estimation. Ecol. Indic. 2019, 101, 1032–1044. [Google Scholar] [CrossRef]
- Mohsenzadeh Karimi, S.; Kisi, O.; Porrajabali, M.; Rouhani-Nia, F.; Shiri, J. Evaluation of the support vector machine, random forest and geo-statistical methodologies for predicting long-term air temperature. ISH J. Hydraul. Eng. 2018. [Google Scholar] [CrossRef]
- He, X.; Chaney, N.W.; Schleiss, M.; Sheffield, J. Spatial downscaling of precipitation using adaptable random forests. Water Resour. Res. 2016, 52, 8217–8237. [Google Scholar] [CrossRef]
- Čeh, M.; Kilibarda, M.; Lisec, A.; Bajat, B. Estimating the Performance of Random Forest versus Multiple Regression for Predicting Prices of the Apartments. ISPRS Int. J. Geo-Inf. 2018, 7, 168. [Google Scholar] [CrossRef] [Green Version]
- Georganos, S.; Grippa, T.; Niang Gadiaga, A.; Linard, C.; Lennert, M.; Vanhuysse, S.; Mboga, N.; Wolff, E.; Kalogirou, S. Geographical random forests: A spatial extension of the random forest algorithm to address spatial heterogeneity in remote sensing and population modelling. Geocarto Int. 2019. [Google Scholar] [CrossRef] [Green Version]
- Behrens, T.; Schmidt, K.; Viscarra Rossel, R.A.; Gries, P.; Scholten, T.; MacMillan, R.A. Spatial modelling with Euclidean distance fields and machine learning. Eur. J. Soil Sci. 2018, 69, 757–770. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, Q.; Xu, C.Y.; Sun, P.; Hu, P. Reconstruction of high spatial resolution surface air temperature data across China: A new geo-intelligent multisource data-based machine learning technique. Sci. Total Environ. 2019, 665, 300–313. [Google Scholar] [CrossRef] [PubMed]
- Hengl, T.; Heuvelink, G.B.M.; Perčec Tadić, M.; Pebesma, E.J. Spatio-temporal prediction of daily temperatures using time-series of MODIS LST images. Theor. Appl. Climatol. 2012, 107, 265–277. [Google Scholar] [CrossRef] [Green Version]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2012. [Google Scholar]
- Burrough, P.A.; McDonnell, R. Principles of Geographical Information Systems; Oxford University Press: Oxford, UK, 1989. [Google Scholar]
- Webster, R. Is soil variation random? Geoderma 2000, 97, 149–163. [Google Scholar] [CrossRef]
- Chilès, J.P.; Delfiner, P. Geostatistics: Modeling Spatial Uncertainty, 2nd ed.; Wiley Series in Probability and Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2012. [Google Scholar] [CrossRef]
- Ahmed, S.; De Marsily, G. Comparison of geostatistical methods for estimating transmissivity using data on transmissivity and specific capacity. Water Resour. Res. 1987. [Google Scholar] [CrossRef]
- Kilibarda, M.; Hengl, T.; Heuvelink, G.B.M.; Gräler, B.; Pebesma, E.J.; Perčec Tadić, M.; Bajat, B. Spatio-temporal interpolation of daily temperatures for global land areas at 1 km resolution. J. Geophys. Res. Atmos. 2014, 119, 2294–2313. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: Abingdon, UK, 2017. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer Texts in Statistics; Springer: New York, NY, USA, 2013; Volume 103. [Google Scholar] [CrossRef]
- Amit, Y.; Geman, D. Shape Quantization and Recognition with Randomized Trees. Neural Comput. 1997. [Google Scholar] [CrossRef] [Green Version]
- Pebesma, E.J. Multivariable geostatistics in S: The gstat package. Comput. Geosci. 2004, 30, 683–691. [Google Scholar] [CrossRef]
- Bivand, R.S.; Pebesma, E.J.; Gómez-Rubio, V. Applied Spatial Data Analysis with R; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Menne, M.J.; Durre, I.; Vose, R.S.; Gleason, B.E.; Houston, T.G. An Overview of the Global Historical Climatology Network-Daily Database. J. Atmos. Ocean. Technol. 2012, 29, 897–910. [Google Scholar] [CrossRef]
- Huffman, G.J.; Bolvin, D.T.; Nelkin, E.J. Integrated Multi-satellitE Retrievals for GPM (IMERG), Late Run, Version V06A. 2014. Available online: ftp://jsimpson.pps.eosdis.nasa.gov/data/imerg/gis/ (accessed on 31 March 2019).
- Lin, L.I.K. A Concordance Correlation Coefficient to Evaluate Reproducibility. Biometrics 1989, 45, 255–268. [Google Scholar] [CrossRef] [PubMed]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77. [Google Scholar] [CrossRef] [Green Version]
- Elseberg, J.; Magnenat, S.; Siegwart, R.; Andreas, N. Comparison of nearest-neighbor-search strategies and implementations for efficient shape registration. J. Softw. Eng. Robot. 2012, 3, 2–12. [Google Scholar]
- Meyer, H.; Reudenbach, C.; Hengl, T.; Katurji, M.; Nauss, T. Improving performance of spatio-temporal machine learning models using forward feature selection and target-oriented validation. Environ. Model. Softw. 2018, 101, 1–9. [Google Scholar] [CrossRef]
- Pejović, M.; Nikolić, M.; Heuvelink, G.B.M.; Hengl, T.; Kilibarda, M.; Bajat, B. Sparse regression interaction models for spatial prediction of soil properties in 3D. Comput. Geosci. 2018, 118. [Google Scholar] [CrossRef]
- Meinshausen, N. Quantile regression forests. J. Mach. Learn. Res. 2006, 7, 983–999. [Google Scholar]
- Heuvelink, G.B.M.; Pebesma, E.J.; Gräler, B. Space-Time Geostatistics. In Encyclopedia of GIS; Shekhar, S., Xiong, H., Zhou, X., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 1–20. [Google Scholar] [CrossRef]
- Tank, A.K.; Zwiers, F.W.; Zhang, X. Guidelines on Analysis of Extremes in a Changing Climate in Support of Informed Decisions for Adaptation; Technical Report WCDMP-No. 72, WMO-TD No. 1500; World Meteorological Organization: Geneva, Switzerland, 2009. [Google Scholar]
- Zimmerman, D.; Pavlik, C.; Ruggles, A.; Armstrong, M.P. An experimental comparison of ordinary and universal kriging and inverse distance weighting. Math. Geol. 1999, 31, 375–390. [Google Scholar] [CrossRef]
- MacCormack, K.E.; Brodeur, J.J.; Eyles, C.H. Evaluating the impact of data quantity, distribution and algorithm selection on the accuracy of 3D subsurface models using synthetic grid models of varying complexity. J. Geogr. Syst. 2013, 15, 71–88. [Google Scholar] [CrossRef]
- Nevtipilova, V.; Pastwa, J.; Boori, M.S.; Vozenilek, V. Testing Artificial Neural Network (ANN) for Spatial Interpolation. J. Geol. Geosci. 2014, 3, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef] [Green Version]
- Malamos, N.; Koutsoyiannis, D. Bilinear surface smoothing for spatial interpolation with optional incorporation of an explanatory variable. Part 2: Application to synthesized and rainfall data. Hydrol. Sci. J. 2016, 61, 527–540. [Google Scholar] [CrossRef]
- Liao, Y.; Li, D.; Zhang, N. Comparison of interpolation models for estimating heavy metals in soils under various spatial characteristics and sampling methods. Trans. GIS 2018, 22, 409–434. [Google Scholar] [CrossRef]
- Qiao, P.; Li, P.; Cheng, Y.; Wei, W.; Yang, S.; Lei, M.; Chen, T. Comparison of common spatial interpolation methods for analyzing pollutant spatial distributions at contaminated sites. Environ. Geochem. Health 2019, 41, 2709–2730. [Google Scholar] [CrossRef]
- Long, J.; Liu, Y.; Xing, S.; Zhang, L.; Qu, M.; Qiu, L.; Huang, Q.; Zhou, B.; Shen, J. Optimal interpolation methods for farmland soil organic matter in various landforms of a complex topography. Ecol. Indic. 2020, 110, 105926. [Google Scholar] [CrossRef]
- Goovaerts, P. Estimation or simulation of soil properties? An optimization problem with conflicting criteria. Geoderma 2000, 97, 165–186. [Google Scholar] [CrossRef]
- Wadoux, A.M.; Brus, D.J.; Heuvelink, G.B.M. Sampling design optimization for soil mapping with random forest. Geoderma 2019, 355, 113913. [Google Scholar] [CrossRef]
- Davies, M.M.; van der Laan, M.J. Optimal Spatial Prediction Using Ensemble Machine Learning. Int. J. Biostat. 2016, 12, 179–201. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Method | Number of Points | |||||
|---|---|---|---|---|---|---|---|
| 100 | 200 | 500 | 1000 | 2000 | 5000 | ||
| Distance calculation time [s] | RFsp | 24.98 | 47.75 | 114.42 | 263.08 | 477.37 | 3832.88 |
| RFSI | 1.40 | 1.48 | 1.62 | 1.65 | 1.69 | 1.75 | |
| Modelling time [s] | RFsp | 0.06 | 0.27 | 2.35 | 13.50 | 71.73 | 498.21 |
| RFSI | 0.02 | 0.04 | 0.09 | 0.20 | 0.42 | 1.18 | |
| Prediction time [s] | OK | 5.25 | 5.72 | 6.38 | 6.81 | 7.11 | 8.03 |
| RFsp | 5.47 | 9.57 | 22.30 | 46.32 | 70.58 | 312.12 | |
| RFSI | 2.93 | 3.37 | 4.05 | 4.74 | 5.60 | 6.83 | |
| Component | Nugget [mm2] | Sill [mm2] | Range | Function | Anisotropy Ratio |
|---|---|---|---|---|---|
| Spatial | 0.00 | 0.89 | 218.8 km | Spherical | n/a |
| Temporal | 1.63 | 4.15 | 2.6 days | Spherical | n/a |
| Spatio-temporal | 9.51 | 11.30 | 91.7 km | Spherical | 120 km/day |
| Model | Mtry | Min.Node.Size | Sample.Fraction | n | p |
|---|---|---|---|---|---|
| IDW | n/a | n/a | n/a | 13 | 2.2 |
| RF | 2 | 20 | 0.65 | n/a | n/a |
| RFsp | 58 | 4 | 0.29 | n/a | n/a |
| RFSI | 4 | 6 | 0.95 | 7 | n/a |
| Method | R [%] | CCC | MAE [mm] | RMSE [mm] |
|---|---|---|---|---|
| STRK | 67.5 | 0.815 | 1.2 | 3.9 |
| IDW | 69.6 | 0.820 | 1.1 | 3.8 |
| RF | 49.4 | 0.674 | 1.7 | 4.9 |
| RFsp | 53.3 | 0.690 | 1.6 | 4.7 |
| RFSI | 69.5 | 0.820 | 1.1 | 3.8 |
| RFSI | 68.6 | 0.814 | 1.2 | 3.9 |
| Hits | Misses | RMSE [mm] | Overall | |||||
|---|---|---|---|---|---|---|---|---|
| Method | obs. pred. | < 1 mm < 1 mm | ≥ 1 mm ≥ 1 mm | < 1 mm ≥ 1 mm | ≥ 1 mm < 1 mm | < 1 mm | ≥ 1 mm | Accuracy [%] |
| STRK | 68,272 | 15,894 | 6307 | 1847 | 1.2 | 8.6 | 91.2 | |
| IDW | 68,398 | 16,164 | 6181 | 1577 | 1.0 | 8.4 | 91.6 | |
| RF | 63,382 | 14,914 | 11,197 | 2827 | 1.7 | 10.6 | 84.8 | |
| RFsp | 64,235 | 15,273 | 10,344 | 2468 | 1.6 | 10.2 | 86.1 | |
| RFSI | 68,031 | 16,524 | 6548 | 1217 | 1.0 | 8.4 | 91.6 | |
| RFSI | 67,917 | 16,535 | 6662 | 1206 | 1.0 | 8.5 | 91.5 | |
| Model | Mtry | Min.Node.Size | Sample.Fraction | n | p |
|---|---|---|---|---|---|
| IDW | n/a | n/a | n/a | 11 | 1.8 |
| RF | 6 | 3 | 0.85 | n/a | n/a |
| RFsp | 154 | 2 | 0.77 | n/a | n/a |
| RFSI | 5 | 15 | 0.90 | 10 | n/a |
| Method | R [%] | CCC | MAE [mm] | RMSE [mm] |
|---|---|---|---|---|
| STRK | 91.0 | n/a | n/a | 2.4 |
| IDW | 95.0 | 0.974 | 1.2 | 1.8 |
| RF | 95.7 | 0.978 | 1.1 | 1.6 |
| RFsp | 95.5 | 0.976 | 1.1 | 1.6 |
| RFSI | 96.6 | 0.983 | 1.0 | 1.4 |
| RFSI | 94.9 | 0.974 | 1.2 | 1.8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sekulić, A.; Kilibarda, M.; Heuvelink, G.B.M.; Nikolić, M.; Bajat, B. Random Forest Spatial Interpolation. Remote Sens. 2020, 12, 1687. https://doi.org/10.3390/rs12101687
Sekulić A, Kilibarda M, Heuvelink GBM, Nikolić M, Bajat B. Random Forest Spatial Interpolation. Remote Sensing. 2020; 12(10):1687. https://doi.org/10.3390/rs12101687
Chicago/Turabian StyleSekulić, Aleksandar, Milan Kilibarda, Gerard B.M. Heuvelink, Mladen Nikolić, and Branislav Bajat. 2020. "Random Forest Spatial Interpolation" Remote Sensing 12, no. 10: 1687. https://doi.org/10.3390/rs12101687
APA StyleSekulić, A., Kilibarda, M., Heuvelink, G. B. M., Nikolić, M., & Bajat, B. (2020). Random Forest Spatial Interpolation. Remote Sensing, 12(10), 1687. https://doi.org/10.3390/rs12101687