Self-Supervised Representation Learning for Remote Sensing Image Change Detection Based on Temporal Prediction


Abstract
:1. Introduction
- To the best of our knowledge, this is the first work to built a discriminative mapping framework to extract discriminative feature representations for direct comparison and detecting the changes. In the learning process, the temporal signal of data is used as a free supervised signal, so that our framework precludes complex additional works for the need of prior changed and unchanged knowledge, and does not introduce additional calculation cost.
- The proposed framework leverages the characteristic of homogeneous image pairs to learn their general feature representations. As the leaned representations are more consistent and discriminative for comparing the difference, the corruption of the irrelevant variations, such as speckle noises, brightness, and topography impact occurred between two images, has been avoided at a significant margin, which enables our method to be robust for generating the final change map.
2. Related Work
3. Methodology
3.1. Overview of Self-Supervised Mechanism for Learning Useful Representations
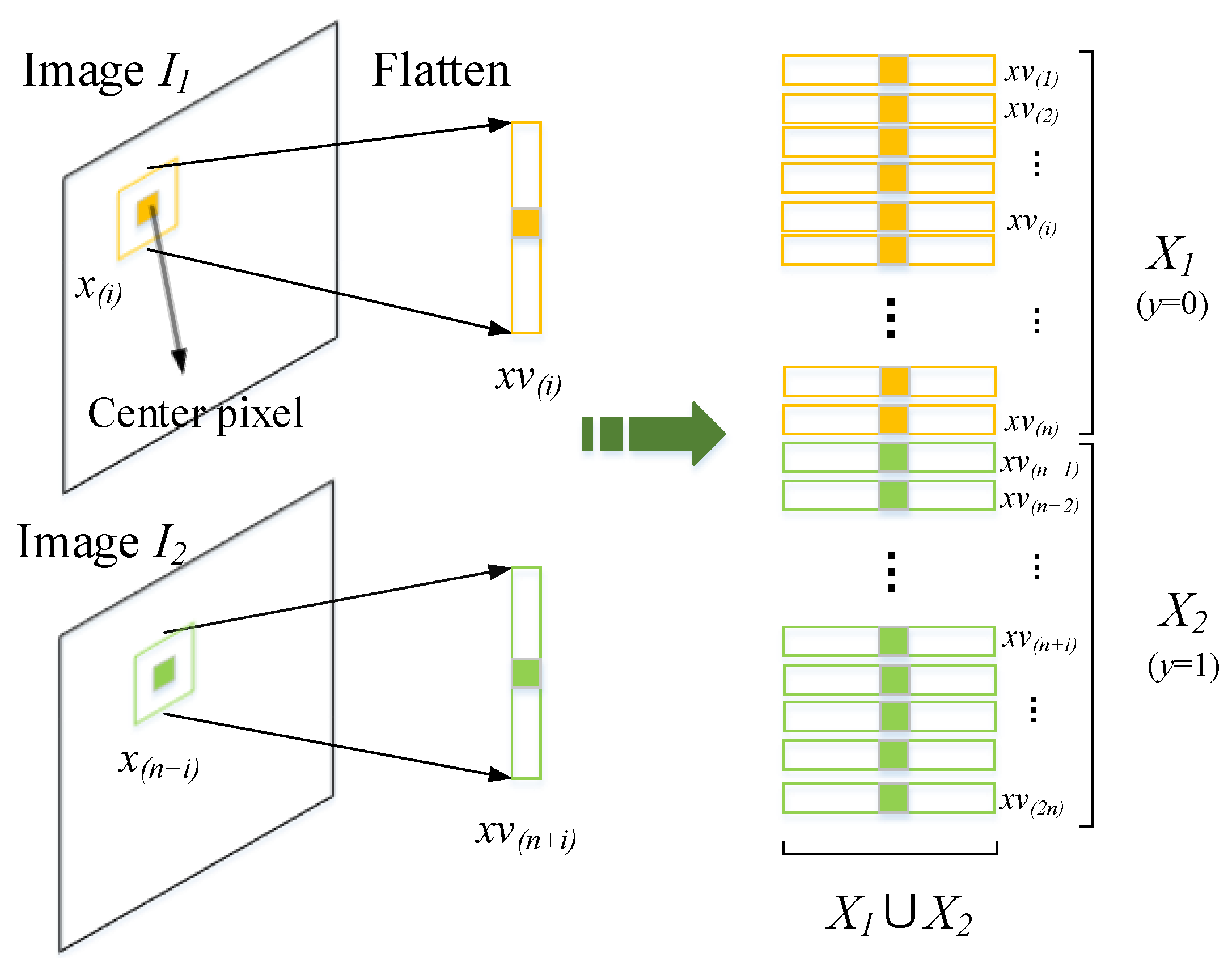
3.2. Architecture of Temporal Prediction
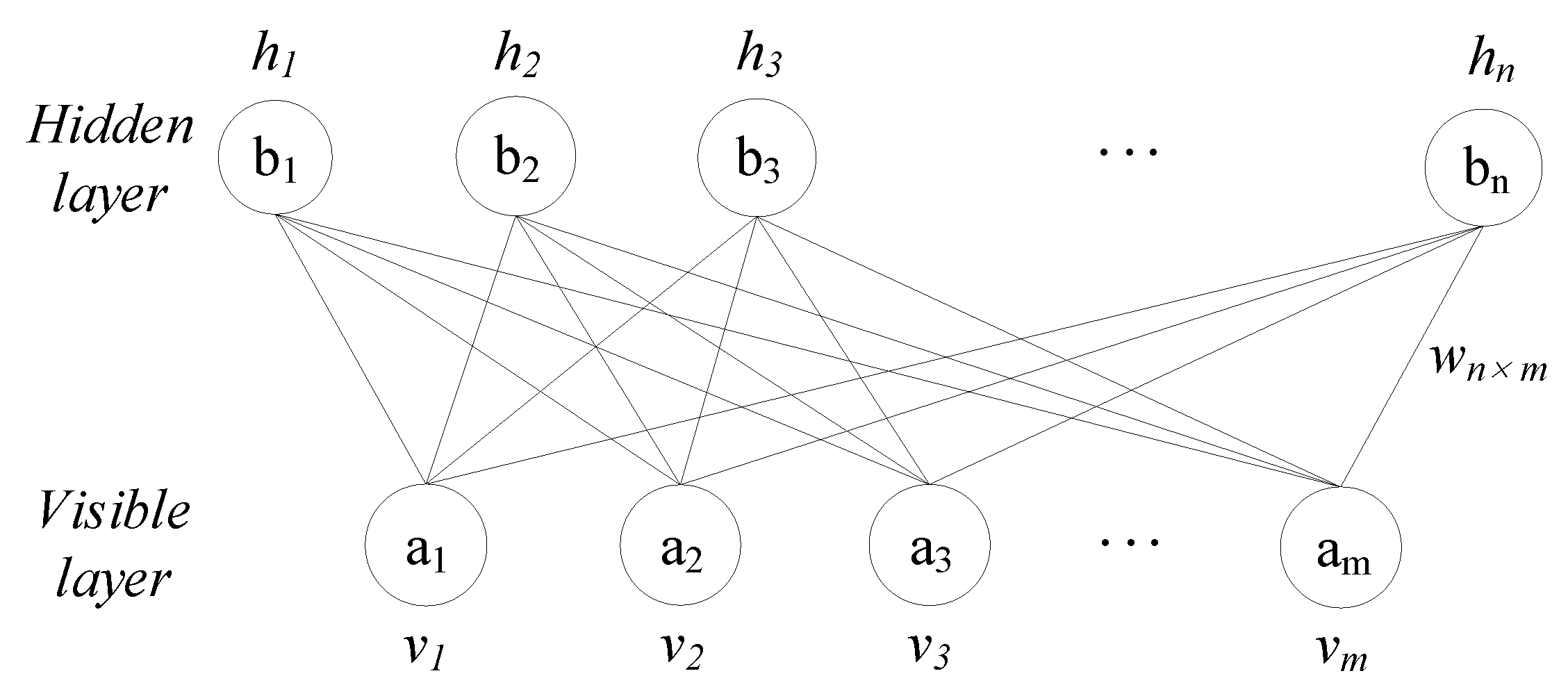
3.3. Establishment of Deep Neural Networks
3.4. Training
| Algorithm 1 Learning Procedure in DADNN |
|
3.5. Result Analysis
3.6. Mapping-Based Binary Segmentation
4. Experimental Study
4.1. Data Description
4.2. Experimental Setup
4.3. Verification of Theoretical Results and Feature Visualization Analysis
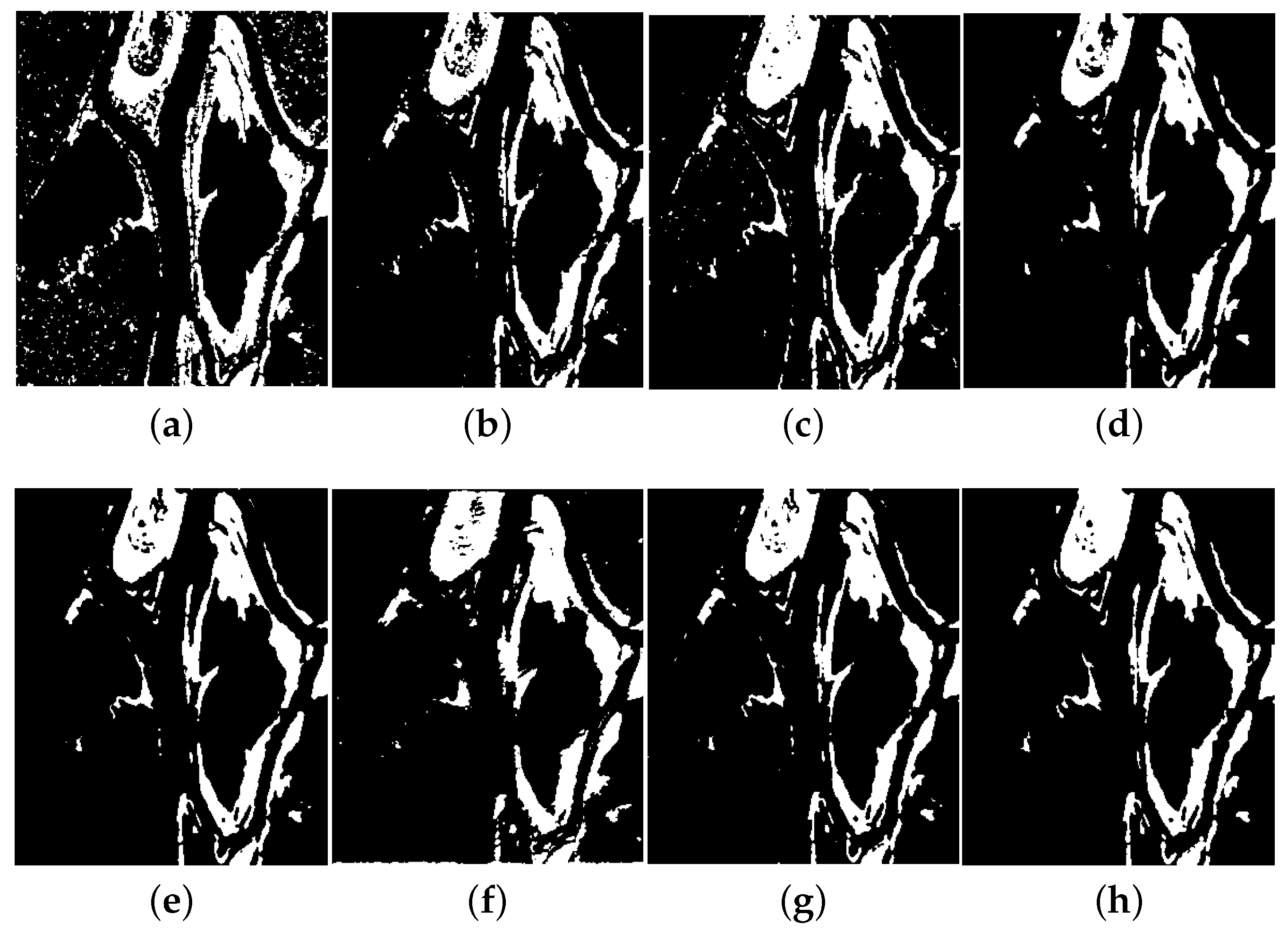
4.4. Performance of Detection Results
4.5. Effect of Noise
4.6. Analysis of Parameters
4.6.1. Effects of Neighborhood Size
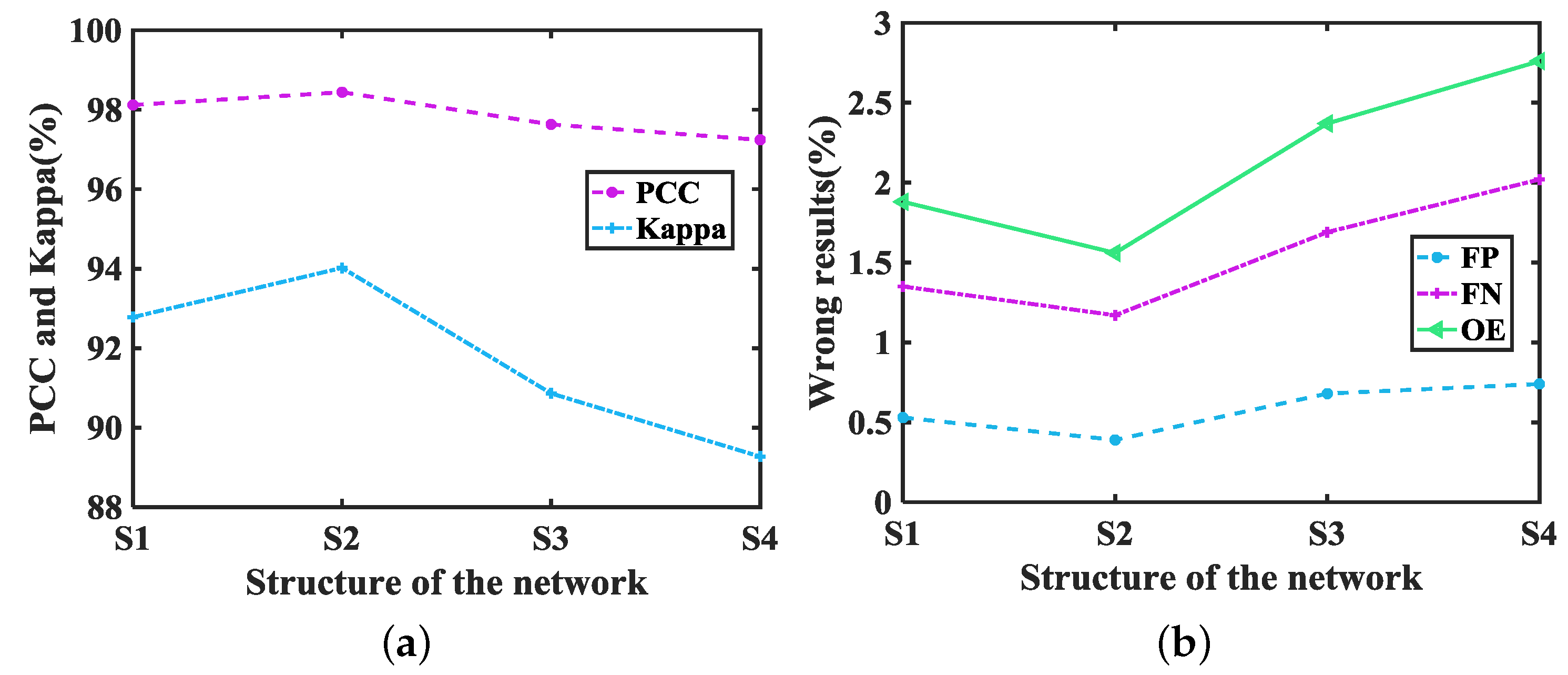
4.6.2. Effects of Network Structure
4.7. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Data Set

Appendix A.2. Result Verification

Appendix A.3. Additional Experiments

Appendix B
Appendix B.4. Data Description


Appendix B.5. Performance of Detection Results




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AUC | FP (%) | FN (%) | OE (%) | PCC (%) | Kappa (%) |
|---|---|---|---|---|---|---|
| CVA | 0.9633 | 0.66 | 2.95 | 3.61 | 96.39 | 84.86 |
| subtraction | 0.9665 | 0.43 | 2.83 | 3.26 | 96.74 | 86.29 |
| log-ratio | 0.8587 | 16.19 | 2.59 | 18.78 | 81.22 | 46.28 |
| wavelet fusion | 0.8951 | 22.18 | 1.38 | 23.56 | 76.44 | 41.12 |
| DNN | - | 0.25 | 3.27 | 3.52 | 96.48 | 84.89 |
| SSCNN | - | 0.26 | 3.07 | 3.33 | 96.67 | 85.79 |
| SCCN | 0.9611 | 0.93 | 2.25 | 3.18 | 96.82 | 87.02 |
| DADNN | 0.9758 | 0.42 | 2.44 | 2.86 | 97.13 | 88.06 |



| Method | AUC | FP (%) | FN (%) | OE (%) | PCC (%) | Kappa (%) |
|---|---|---|---|---|---|---|
| CVA | 0.8101 | 11.60 | 1.08 | 12.68 | 87.32 | 23.87 |
| subtraction | 0.8110 | 11.96 | 1.06 | 13.02 | 86.98 | 23.45 |
| log-ratio | 0.6612 | 36.70 | 1.38 | 38.08 | 61.92 | 4.02 |
| wavelet fusion | 0.6676 | 46.44 | 1.19 | 47.63 | 52.37 | 2.60 |
| DNN | - | 5.35 | 1.62 | 6.97 | 93.03 | 32.53 |
| SSCNN | - | 0.64 | 20.60 | 3.24 | 96.76 | 35.75 |
| SCCN | 0.8381 | 22.27 | 1.05 | 23.32 | 76.68 | 12.25 |
| DADNN | 0.8437 | 3.15 | 2.03 | 5.18 | 94.82 | 34.61 |
References
- Singh, A. Review Article Digital change detection techniques using remotely-sensed data. Int. J. Remote. Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef] [Green Version]
- Saxena, R.; Watson, L.T.; Wynne, R.H.; Brooks, E.B.; Thomas, V.A.; Zhiqiang, Y.; Kennedy, R.E. Towards a polyalgorithm for land use change detection. J. Photogramm. Remote Sens. 2018, 144, 217–234. [Google Scholar] [CrossRef]
- Xing, J.; Sieber, R.; Caelli, T. A scale-invariant change detection method for land use/cover change research. J. Photogramm. Remote Sens. 2018, 141, 252–264. [Google Scholar] [CrossRef]
- Gong, J.; Ma, G.; Zhou, Q. A review of multi-temporal remote sensing data change detection algorithms. Protein Expr. Purif. 2011, 82, 308–316. [Google Scholar]
- Bruzzone, L.; Prieto, D.F. Automatic analysis of the difference image for unsupervised change detection. IEEE Trans. Geosci. Remote Sens. 2000, 38, 1171–1182. [Google Scholar] [CrossRef] [Green Version]
- Huerta, I.; Pedersoli, M.; Gonzalez, J.; Sanfeliu, A. Combining where and what in change detection for unsupervised foreground learning in surveillance. Pattern Recognit. 2015, 48, 709–719. [Google Scholar] [CrossRef] [Green Version]
- Ghanbari, M.; Akbari, V. Generalized minimum-error thresholding for unsupervised change detection from multilook polarimetric SAR data. IEEE Trans. Geosci. Remote. Sens. 2015, 44, 2972–2982. [Google Scholar]
- Zanetti, M.; Bruzzone, L. A Theoretical Framework for Change Detection Based on a Compound Multiclass Statistical Model of the Difference Image. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1129–1143. [Google Scholar] [CrossRef]
- Ferretti, A.; Montiguarnieri, A.; Prati, C.; Rocca, F.; Massonet, D. InSAR Principles–Guidelines for SAR Interferometry Processing and Interpretation. J. Financ. Stab. 2007, 10, 156–162. [Google Scholar]
- Ban, Y.; Yousif, O. Change Detection Techniques: A Review; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Tewkesbury, A.P.; Comber, A.J.; Tate, N.J.; Lamb, A.; Fisher, P.F. A critical synthesis of remotely sensed optical image change detection techniques. Remote Sens. Environ. 2015, 160, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Lunetta, R.S.E.; Christopher, D. Remote Sensing Change Detection: Environmental Monitoring Methods and Applications; CRC Press: Boca Raton, FL, USA, 1998. [Google Scholar]
- Gong, M.; Li, Y.; Jiao, L.; Jia, M.; Su, L. SAR change detection based on intensity and texture changes. J. Photogramm. Remote Sens. 2014, 93, 123–135. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L. A theoretical framework for unsupervised change detection based on change vector analysis in the polar domain. IEEE Trans. Geosci. Remote Sens. 2006, 45, 218–236. [Google Scholar] [CrossRef] [Green Version]
- Celik, T. Unsupervised Change Detection in Satellite Images Using Principal Component Analysis and k-Means Clustering. IEEE GEoscience Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Sezgin, M.; Sankur, B.L. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–166. [Google Scholar]
- Gong, M.; Zhou, Z.; Ma, J. Change detection in synthetic aperture radar images based on image fusion and fuzzy clustering. IEEE Trans. Image Process. 2012, 21, 2141. [Google Scholar] [CrossRef]
- Zhao, W.; Wang, Z.; Gong, M.; Liu, J. Discriminative Feature Learning for Unsupervised Change Detection in Heterogeneous Images Based on a Coupled Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7066–7080. [Google Scholar] [CrossRef]
- Mikolov, T.; Kombrink, S.; Burget, L.; Cernocky, J.; Khudanpur, S. Extensions of recurrent neural network language model. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, 22–27 May 2011; pp. 5528–5531. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Advances on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Song, Y.; Ma, C.; Wu, X.; Gong, L.; Bao, L.; Zuo, W.; Shen, C.; Lau, R.W.; Yang, M.H. Vital: Visual tracking via adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8990–8999. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Souly, N.; Spampinato, C.; Shah, M. Semi supervised semantic segmentation using generative adversarial network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5688–5696. [Google Scholar]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. arXiv 2019, arXiv:1902.06162. [Google Scholar]
- Wang, X.; Gupta, A. Unsupervised Learning of Visual Representations Using Videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Fernando, B.; Bilen, H.; Gavves, E.; Gould, S. Self-supervised video representation learning with odd-one-out networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3636–3645. [Google Scholar]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1422–1430. [Google Scholar]
- Liu, J.; Gong, M.; Qin, K.; Zhang, P. A deep convolutional coupling network for change detection based on heterogeneous optical and radar images. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 545–559. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Lang, F.; Yang, J.; Yan, S.; Qin, F. Superpixel Segmentation of Polarimetric Synthetic Aperture Radar (SAR) Images Based on Generalized Mean Shift. Remote Sens. 2018, 10, 1592. [Google Scholar] [CrossRef] [Green Version]
- Stutz, D.; Hermans, A.; Leibe, B. Superpixels: An Evaluation of the State-of-the-Art. Comput. Vis. Image Underst. 2018, 166, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Ciecholewski, M. River channel segmentation in polarimetric SAR images: Watershed transform combined with average contrast maximisation. Expert Syst. Appl. Int. J. 2017, 82, 196–215. [Google Scholar] [CrossRef]
- Cousty, J.; Bertrand, G.; Najman, L.; Couprie, M. Watershed Cuts: Thinnings, Shortest Path Forests, and Topological Watersheds. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 925–939. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Braga, A.M.; Marques, R.C.P.; Rodrigues, F.A.A.; Medeiros, F.N.S. A Median Regularized Level Set for Hierarchical Segmentation of SAR Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1171–1175. [Google Scholar] [CrossRef]
- Jin, R.; Yin, J.; Zhou, W.; Yang, J. Level Set Segmentation Algorithm for High-Resolution Polarimetric SAR Images Based on a Heterogeneous Clutter Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2017, 10, 4565–4579. [Google Scholar] [CrossRef]
- Gong, M.; Zhao, J.; Liu, J.; Miao, Q.; Jiao, L. Change Detection in Synthetic Aperture Radar Images Based on Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 125–138. [Google Scholar] [CrossRef]
- Gong, M.; Liang, Y.; Shi, J.; Ma, W.; Ma, J. Fuzzy C-means clustering with local information and kernel metric for image segmentation. IEEE Trans. Image Process. 2013, 22, 573–584. [Google Scholar] [CrossRef]
- Li, Y.; Gong, M.; Jiao, L.; Li, L.; Stolkin, R. Change-Detection Map Learning Using Matching Pursuit. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4712–4723. [Google Scholar] [CrossRef]
- Gu, W.; Lv, Z.; Hao, M. Change detection method for remote sensing images based on an improved Markov random field. Multimed. Tools Appl. 2017, 76, 1–16. [Google Scholar] [CrossRef]
- Turgay, C.; Hwee Kuan, L. A robust fuzzy local information C-means clustering algorithm. IEEE Trans. Image Process. 2013, 22, 1258–1261. [Google Scholar]
- Gong, M.; Su, L.; Jia, M.; Chen, W. Fuzzy Clustering With a Modified MRF Energy Function for Change Detection in Synthetic Aperture Radar Images. IEEE Trans. Fuzzy Syst. 2014, 22, 98–109. [Google Scholar] [CrossRef]
- Gong, M.; Jia, M.; Su, L.; Wang, S.; Jiao, L. Detecting changes of the Yellow River Estuary via SAR images based on a local fit-search model and kernel-induced graph cuts. Int. J. Remote Sens. 2014, 35, 4009–4030. [Google Scholar] [CrossRef]
- Liu, J.; Gong, M.; Miao, Q.; Su, L.; Li, H. Change detection in synthetic aperture radar images based on unsupervised artificial immune systems. Appl. Soft Comput. 2015, 34, 151–163. [Google Scholar] [CrossRef]
- Zheng, Y.; Jiao, L.; Liu, H.; Zhang, X.; Hou, B.; Wang, S. Unsupervised saliency-guided SAR image change detection. Pattern Recognit. 2017, 61, 309–326. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2018, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 924–935. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A General End-to-End 2-D CNN Framework for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Gong, M.; Tao, Z.; Zhang, P.; Miao, Q. Superpixel-Based Difference Representation Learning for Change Detection in Multispectral Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2658–2673. [Google Scholar] [CrossRef]
- Dong, H.; Ma, W.; Wu, Y.; Gong, M.; Jiao, L. Local Descriptor Learning for Change Detection in Synthetic Aperture Radar Images via Convolutional Neural Networks. IEEE Access 2019, 7, 15389–15403. [Google Scholar] [CrossRef]
- Gao, F.; Wang, X.; Gao, Y.; Dong, J.; Wang, S. Sea Ice Change Detection in SAR Images Based on Convolutional-Wavelet Neural Networks. IEEE Geosci. Remote. Sens. Lett. 2019, 16, 1240–14244. [Google Scholar] [CrossRef]
- Zhan, T.; Gong, M.; Liu, J.; Zhang, P. Iterative feature mapping network for detecting multiple changes in multi-source remote sensing images. J. Photogramm. Remote Sens. 2018, 146, 38–51. [Google Scholar] [CrossRef]
- Gong, M.; Niu, X.; Zhang, P.; Li, Z. Generative Adversarial Networks for Change Detection in Multispectral Imagery. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 2310–2314. [Google Scholar] [CrossRef]
- Niu, X.; Gong, M.; Zhan, T.; Yang, Y. A Conditional Adversarial Network for Change Detection in Heterogeneous Images. IEEE Geosci. Remote. Sens. Lett. 2019, 16, 45–49. [Google Scholar] [CrossRef]
- Gong, M.; Yang, Y.; Zhan, T.; Niu, X.; Li, S. A generative discriminatory classified network for change detection in multispectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 321–333. [Google Scholar] [CrossRef]
- Hou, B.; Liu, Q.; Wang, H.; Wang, Y. From W-Net to CDGAN: Bitemporal Change Detection via Deep Learning Techniques. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1790–1802. [Google Scholar] [CrossRef] [Green Version]
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 132–149. [Google Scholar]
- Wang, S.; Quan, D.; Liang, X.; Ning, M.; Guo, Y.; Jiao, L. A deep learning framework for remote sensing image registration. J. Photogramm. Remote Sens. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- Jensen, J.R.; Ramsey, E.W.; Mackey, H.E., Jr.; Christensen, E.J.; Sharitz, R.R. Inland wetland change detection using aircraft MSS data. Photogramm. Eng. Remote Sens. 1987, 53, 521–529. [Google Scholar]
- Mubea, K.; Menz, G. Monitoring Land-Use Change in Nakuru (Kenya) Using Multi-Sensor Satellite Data. Adv. Remote Sens. 2012, 1. [Google Scholar] [CrossRef] [Green Version]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504. [Google Scholar] [CrossRef] [Green Version]
- Fischer, A.; Igel, C. An Introduction to Restricted Boltzmann Machines. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 14–36. [Google Scholar]
- Hinton, G.E. A Practical Guide to Training Restricted Boltzmann Machines. Momentum 2012, 9, 599–619. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Brennan, R.L.; Prediger, D.J. Coefficient Kappa: Some Uses, Misuses, and Alternatives. Educ. Psychol. Meas. 1981, 41, 687–699. [Google Scholar] [CrossRef]
- Rosin, P.L.; Ioannidis, E. Evaluation of global image thresholding for change detection. Pattern Recognit. Lett. 2003, 24, 2345–2356. [Google Scholar] [CrossRef] [Green Version]
- Daudt, R.C.; Saux, B.L.; Boulch, A.; Gousseau, Y. Urban Change Detection for Multispectral Earth Observation Using Convolutional Neural Networks. In Proceedings of the International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar]
























| Method | Category | Pros and Cons | Examples |
|---|---|---|---|
| Traditional CD methods | Postclassification comparison | Can avoid radiation normalization from different sensors, but easily suffer from cumulative classification errors | [60,61] |
| postcomparison analysis | The mainstream with excellent performance, but rely heavily on the quality of a DI | [13,16,17,39] | |
| Deep learning CD methods | Semisupervised methods | The current mainstream, be superior to traditional methods, but rely heavily on the quality of pseudo-labels | [38,49,50,52] |
| Unsupervised methods | Introduce many additional manual parameter with complex optimizing process, often perform better on heterogeneous images than on homogeneous ones | [18,19,30] | |
| GAN-Based methods | Aim to improve the detection performance by the adversarial process, but also introduce challenges of GAN itself, e.g., training difficulty | [54,55,56] | |
| Self-Supervised methods | Independent of semantic supervision, easily obtain supervised signal, robust to noise, but rely on the quality of extracted features | The proposed method |
| Method | AUC | FP (%) | FN (%) | OE (%) | PCC (%) | Kappa (%) |
|---|---|---|---|---|---|---|
| subtraction | 0.9868 | 0.38 | 1.42 | 1.80 | 98.20 | 89.23 |
| log-ratio | 0.9874 | 0.27 | 2.18 | 2.45 | 97.55 | 84.75 |
| wavelet fusion | 0.9885 | 0.89 | 0.85 | 1.74 | 98.26 | 90.14 |
| DNN | - | 0.18 | 2.67 | 2.85 | 97.15 | 81.72 |
| SSCNN | - | 0.38 | 1.50 | 1.88 | 98.12 | 88.78 |
| SCCN | 0.9883 | 0.42 | 1.31 | 1.73 | 98.27 | 89.76 |
| DADNN | 0.9961 | 0.69 | 0.74 | 1.43 | 98.57 | 91.86 |
| Method | AUC | FP (%) | FN (%) | OE (%) | PCC (%) | Kappa (%) |
|---|---|---|---|---|---|---|
| subtraction | 0.9103 | 5.68 | 2.40 | 8.08 | 91.92 | 72.00 |
| log-ratio | 0.9576 | 0.58 | 1.86 | 2.44 | 97.56 | 90.52 |
| wavelet fusion | 0.9907 | 1.89 | 0.20 | 2.09 | 97.91 | 92.49 |
| DNN | - | 0.19 | 1.96 | 2.15 | 97.85 | 91.58 |
| SSCNN | - | 0.57 | 1.24 | 1.81 | 98.09 | 93.08 |
| SCCN | 0.9609 | 1.56 | 1.95 | 3.51 | 96.49 | 86.69 |
| DADNN | 0.9945 | 0.39 | 1.17 | 1.56 | 98.44 | 94.02 |
| Method | AUC | FP (%) | FN (%) | OE (%) | PCC (%) | Kappa (%) |
|---|---|---|---|---|---|---|
| subtraction | 0.6570 | 37.18 | 3.78 | 40.96 | 59.04 | 19.60 |
| log-ratio | 0.7639 | 22.03 | 1.72 | 23.75 | 76.25 | 44.25 |
| wavelet fusion | 0.8520 | 17.46 | 2.26 | 19.72 | 80.28 | 49.86 |
| DNN | - | 0.67 | 5.95 | 6.62 | 93.38 | 74.77 |
| SSCNN | - | 0.66 | 4.46 | 5.12 | 94.88 | 81.16 |
| SCCN | 0.9328 | 7.06 | 2.41 | 9.47 | 90.53 | 70.96 |
| DADNN | 0.9621 | 2.21 | 2.23 | 4.44 | 95.56 | 85.01 |
| Method | AUC | FP (%) | FN (%) | OE (%) | PCC (%) | Kappa (%) |
|---|---|---|---|---|---|---|
| subtraction | 0.7527 | 64.09 | 0.13 | 64.22 | 35.78 | 2.32 |
| log-ratio | 0.8245 | 58.77 | 0.13 | 58.90 | 41.10 | 2.98 |
| wavelet fusion | 0.8711 | 54.05 | 0.13 | 54.18 | 45.82 | 3.68 |
| DNN | - | 59.47 | 0.03 | 59.50 | 40.50 | 3.20 |
| SSCNN | - | 58.77 | 0.10 | 58.86 | 41.14 | 3.10 |
| SCCN | 0.8901 | 15.17 | 0.56 | 15.73 | 84.27 | 17.40 |
| DADNN | 0.9522 | 3.17 | 0.48 | 3.65 | 96.35 | 52.89 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, H.; Ma, W.; Wu, Y.; Zhang, J.; Jiao, L. Self-Supervised Representation Learning for Remote Sensing Image Change Detection Based on Temporal Prediction. Remote Sens. 2020, 12, 1868. https://doi.org/10.3390/rs12111868
Dong H, Ma W, Wu Y, Zhang J, Jiao L. Self-Supervised Representation Learning for Remote Sensing Image Change Detection Based on Temporal Prediction. Remote Sensing. 2020; 12(11):1868. https://doi.org/10.3390/rs12111868
Chicago/Turabian StyleDong, Huihui, Wenping Ma, Yue Wu, Jun Zhang, and Licheng Jiao. 2020. "Self-Supervised Representation Learning for Remote Sensing Image Change Detection Based on Temporal Prediction" Remote Sensing 12, no. 11: 1868. https://doi.org/10.3390/rs12111868