A Tile-Based Framework with a Spatial-Aware Feature for Easy Access and Efficient Analysis of Marine Remote Sensing Data


Abstract
:
1. Introduction
2. Foundation and Implementation
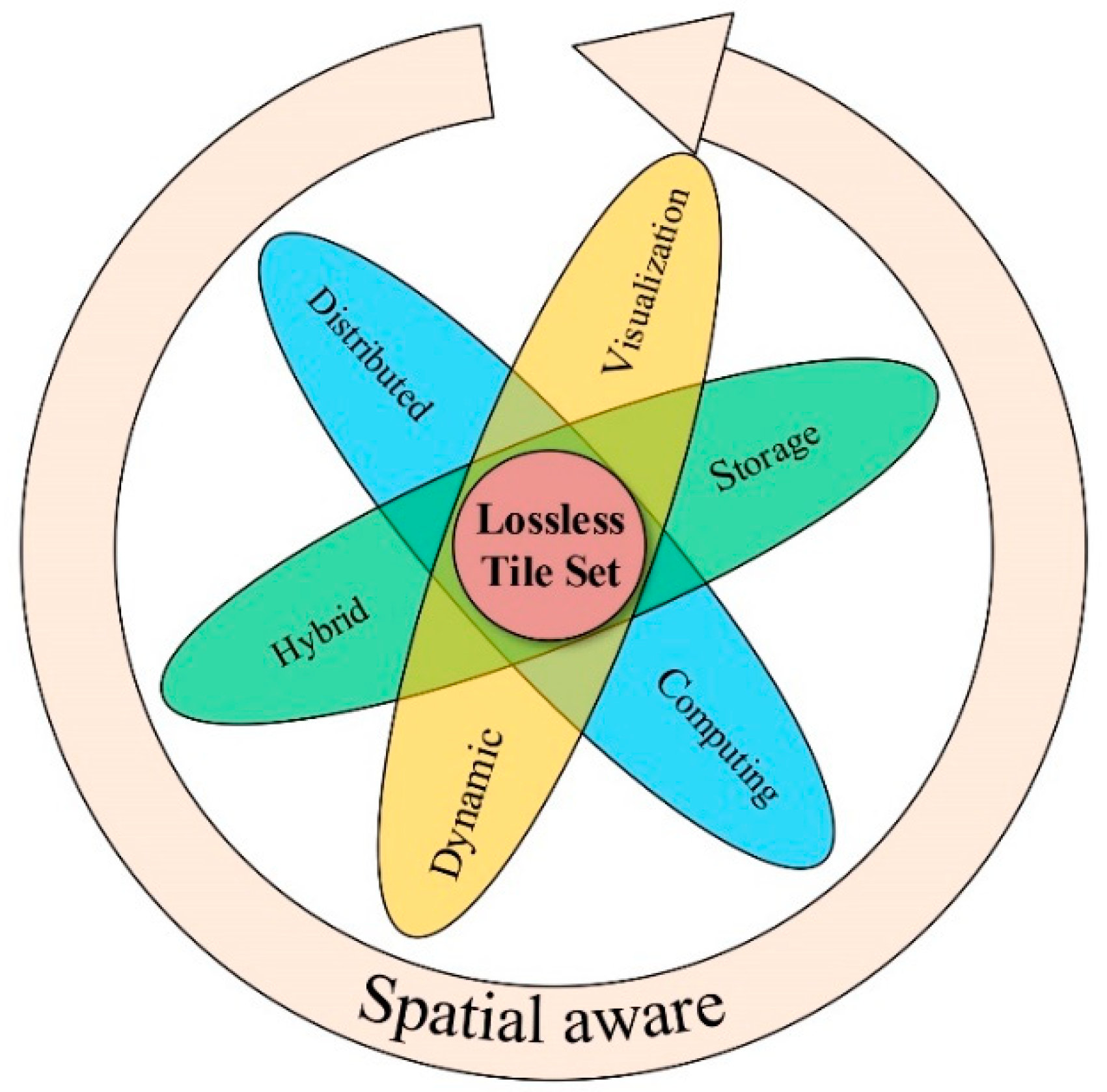
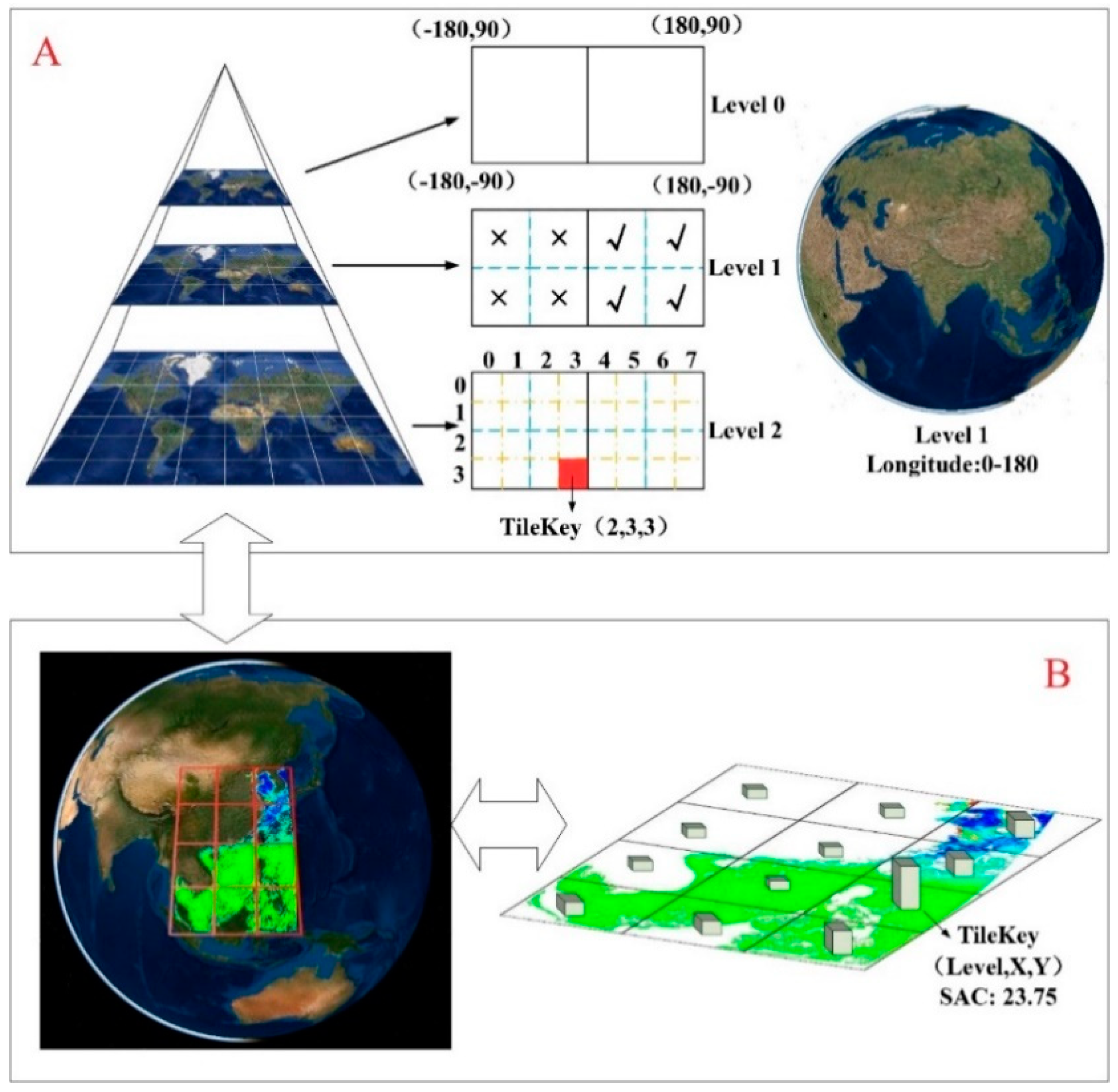
2.1. Lossless Tile Set with Spatial Awareness
2.2. Tile-Based Implementation
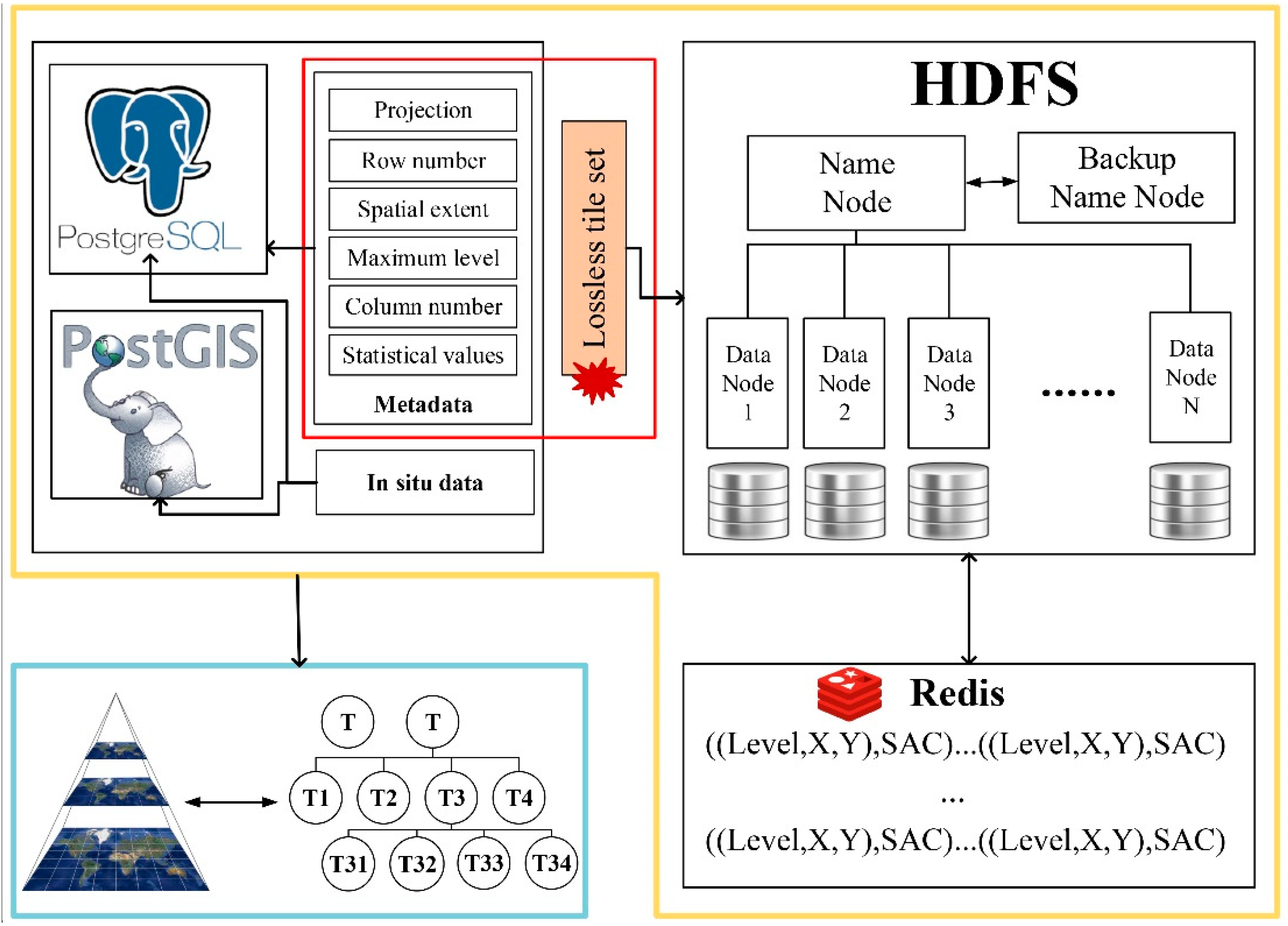
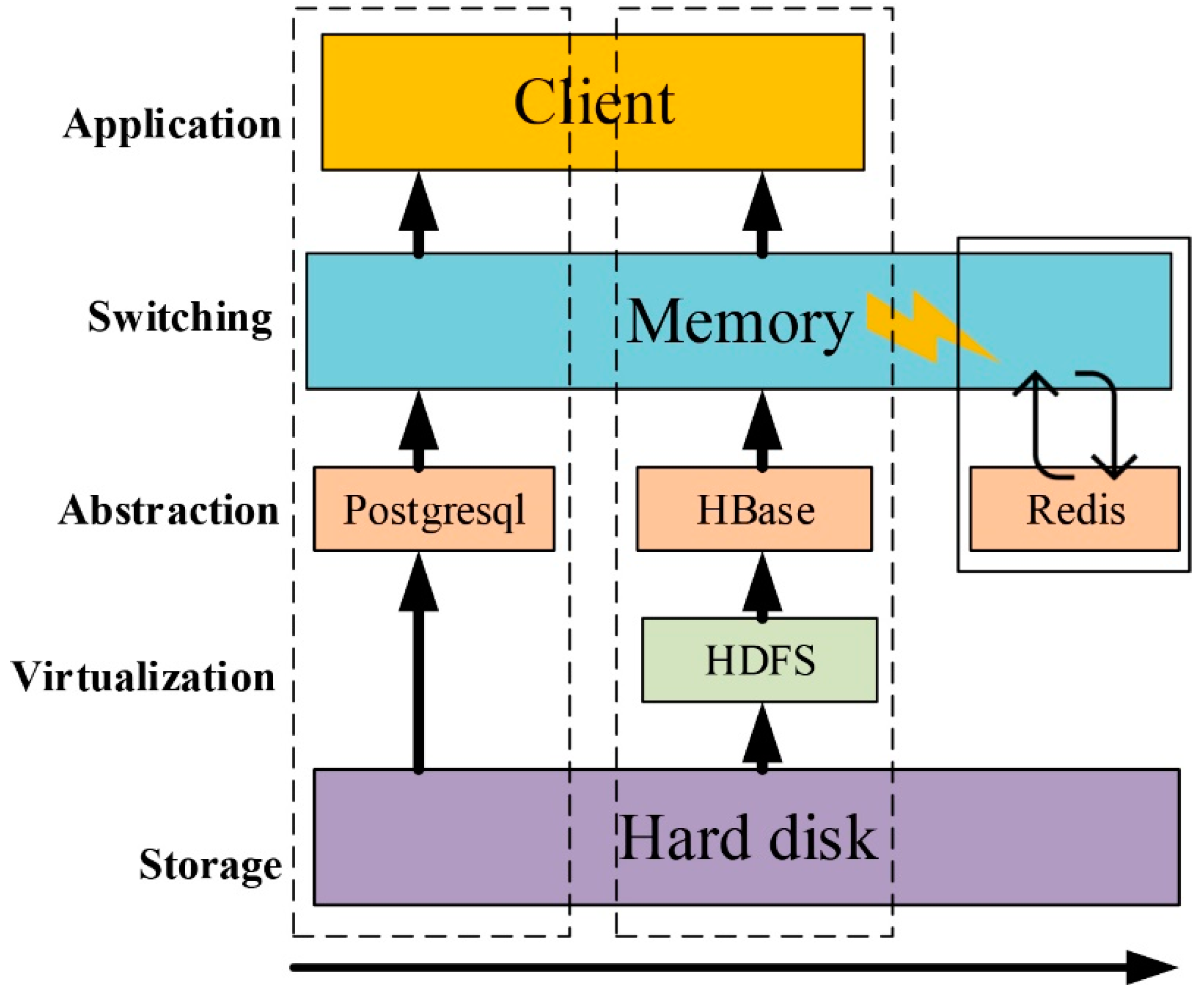
2.2.1. Intelligent Hybrid Database Storage
2.2.2. Dynamic Visualization Using a Virtual Globe
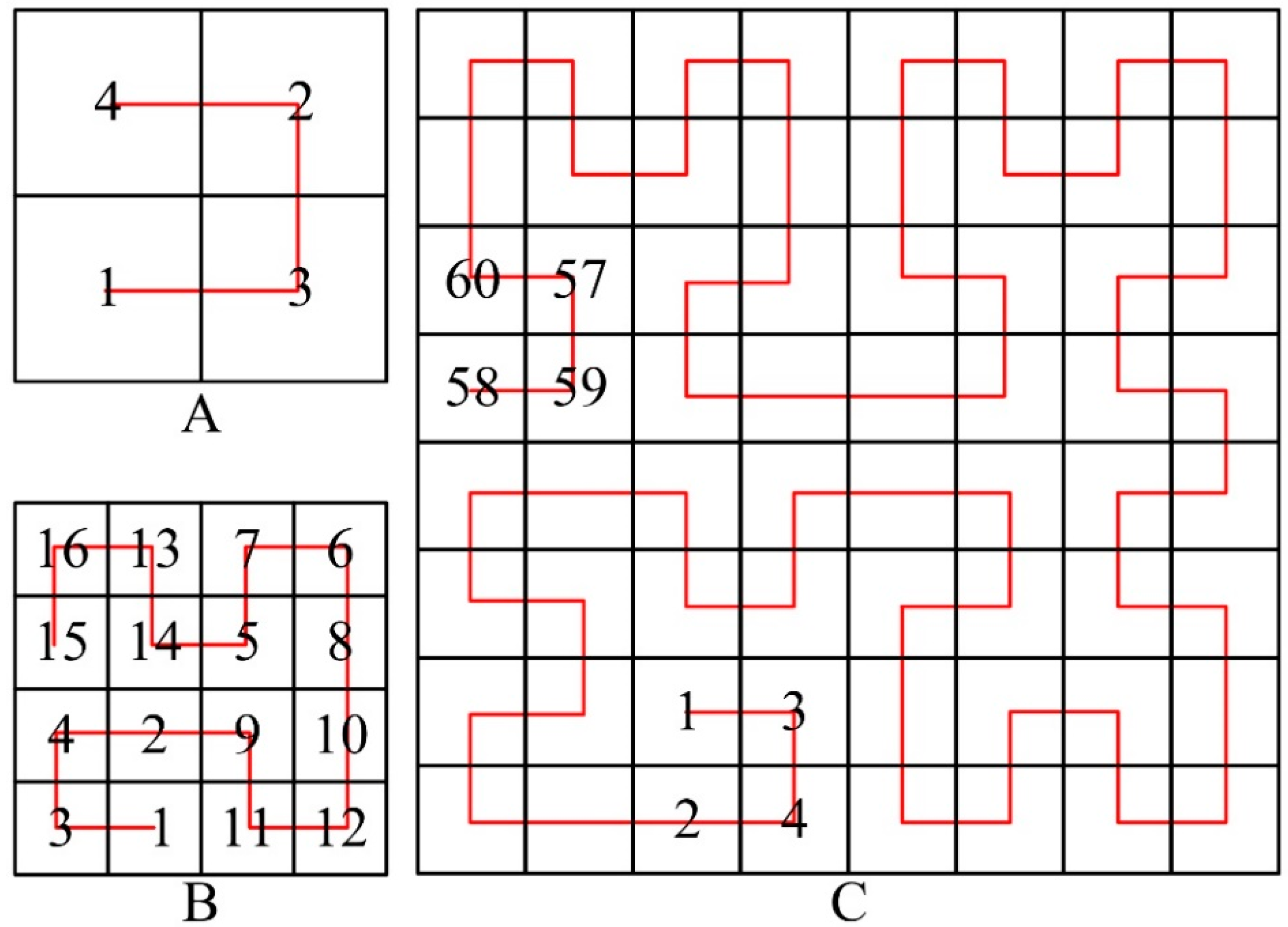
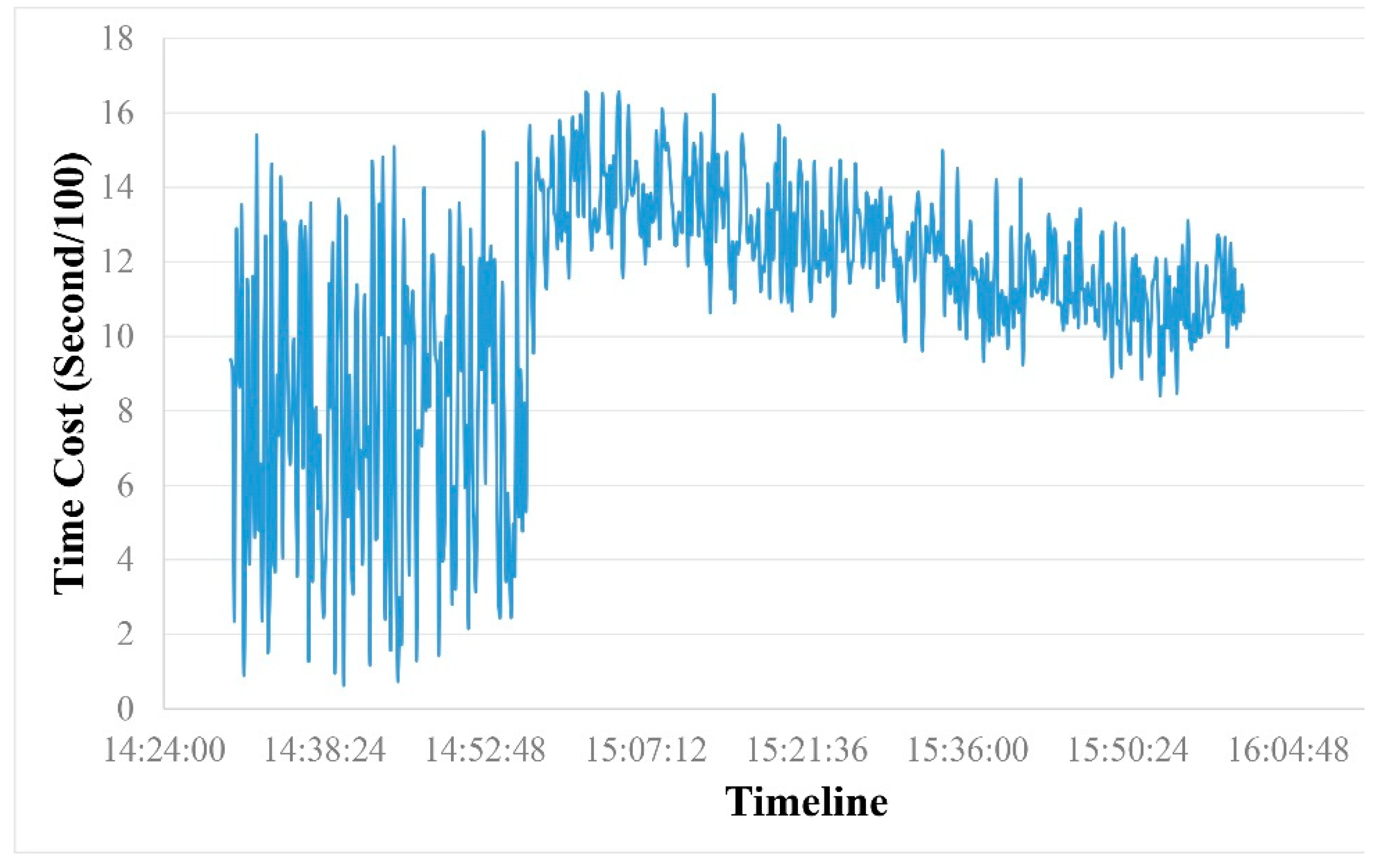
2.2.3. SAC-Driven Hilbert Index for High-Performance Computing
3. Platform Demonstration
3.1. Platform Overview
3.2. Online Data Sets
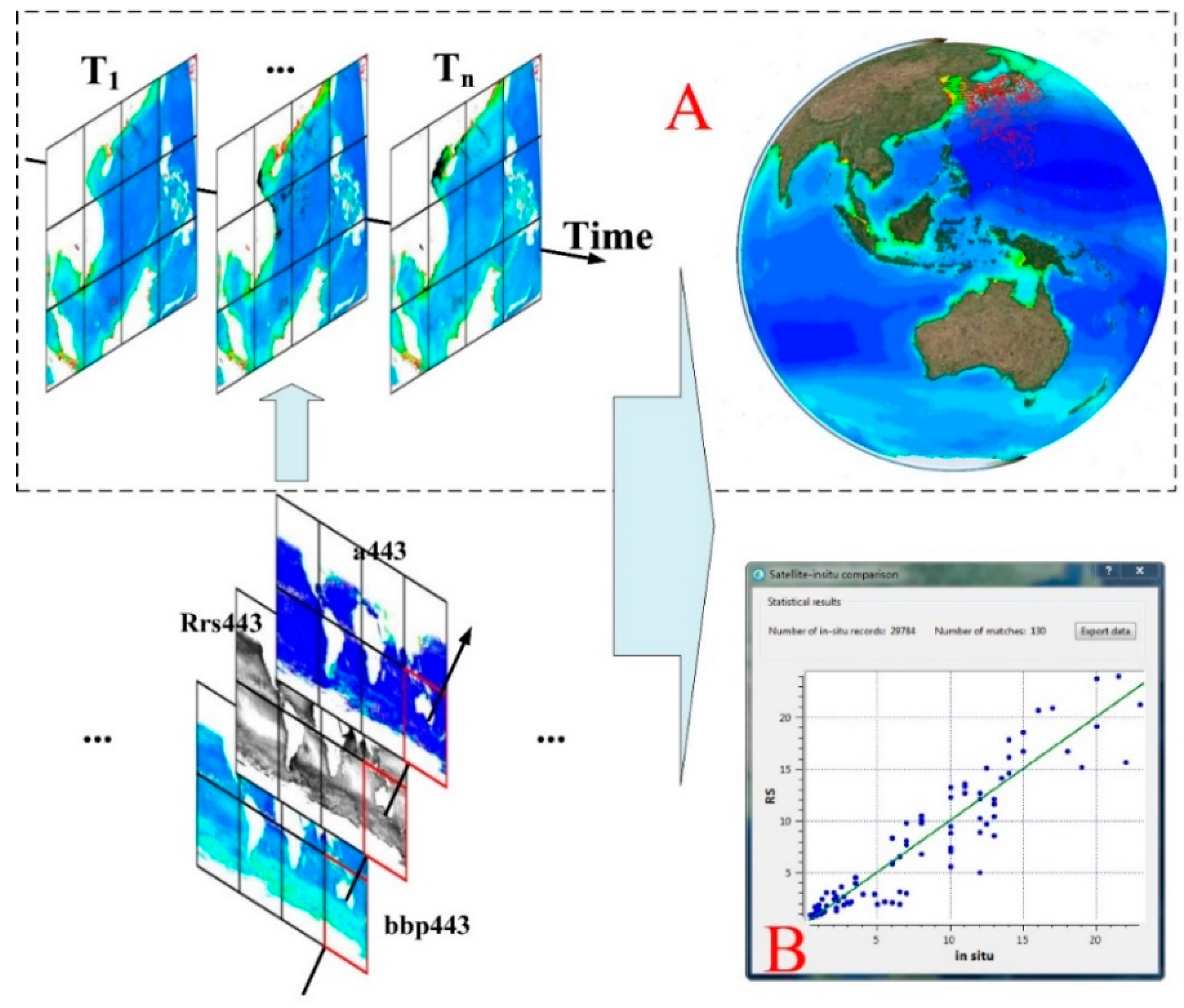
3.3. Case Study: Anomaly Analysis of Multiyear MRS Data
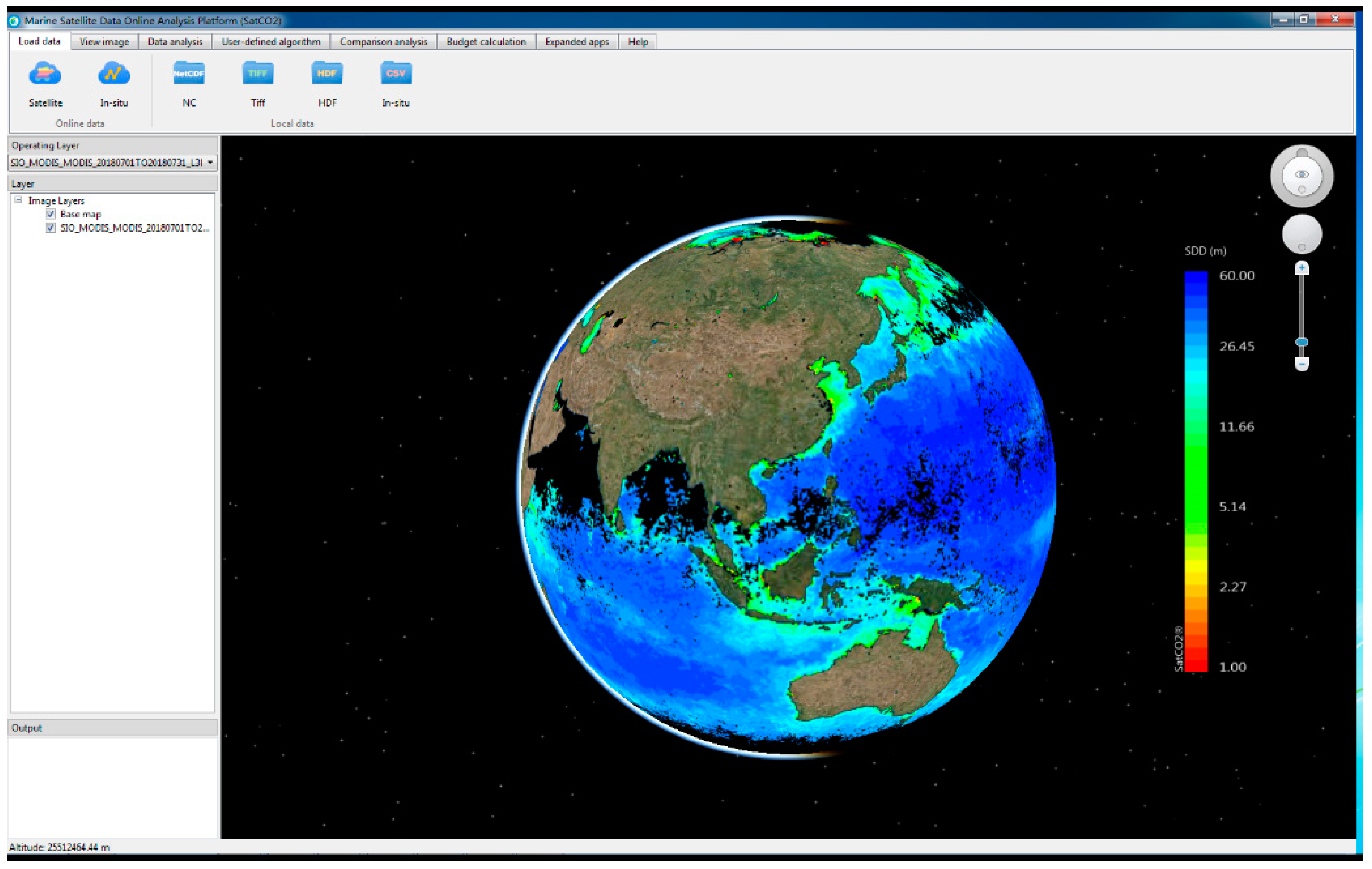
3.4. Calculation Ability: Satellite-Driven Ocean SDD Retrieval
3.5. Application: Training Courses
- In November 2018, a SatCO2 training course was held at the Dragon 4 Cooperation Program in Shenzhen, China;
- In November 2018, the SatCO2-III workshop was held in Hangzhou, China;
- In April 2019, a SatCO2 training course was held at the International Ocean Color Science Meeting in Busan, South Korea;
- In April 2019, a SatCO2 training course was held at the 4th Global Ocean Acidification Observing Network International Workshop in Hangzhou, China;
- In October 2019, an advanced training course on ocean color remote sensing was held in Hangzhou, China. In addition, the participants learned to use SatCO2 for environmental monitoring and scientific research.
4. Challenges and Further Work
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics of the Data Sets | Names of the Data Sets | Parameters | Spatial Range/ Resolution | Temporal Range/ Resolution |
|---|---|---|---|---|
| Special Data Sets of the Seas Surrounding China | GF-4 data sets | Normalized water-leaving radiance (491, 561, 653, 809 nm), suspended particle matter concentration | Single orbit; 50 m | 2017–present; single orbit |
| HY-1B data sets | Normalized water-leaving radiance (412, 443, 490, 520, 565, 670 nm), surface chlorophyll concentration, surface suspended matter concentration, 865 nm aerosol optical thickness, sea water transparency, sea surface temperature, attenuation coefficient, atmosphere visibility, CDOM absorption coefficient (including the detritus absorption) | Single orbit; 1.6 km | 2007–2016; single orbit | |
| China sea CO2 data sets | Surface water salinity, aquatic pCO2 | (100°–130°E, 0°–41°N); 1.6 km | 2003–2018; monthly average | |
| GF-4 data sets | Normalized water-leaving radiance (491, 561, 653, 809 nm), suspended particle matter concentration | Single orbit; 50 m | 2017–present; single orbit | |
| HY-1B data sets | Normalized water-leaving radiance (412, 443, 490, 520, 565, 670 nm), surface chlorophyll concentration, surface suspended matter concentration, 865 nm aerosol optical thickness, sea water transparency, sea surface temperature, attenuation coefficient, atmosphere visibility, CDOM absorption coefficient (including the detritus absorption) | Single orbit; 1.6 km | 2007–2016; single orbit | |
| China sea CO2 data sets | Surface water salinity, aquatic pCO2 | (100°–130°E, 0°–41°N); 1.6 km | 2003–2018; monthly average | |
| GOCI Data Sets | Yangtze River Estuary | Normalized water-leaving radiance (412, 443, 490, 555, 660, 680, 745, 865 nm), surface suspended matter concentration | (119°–126°E, 27°–35°N); 500 m | 2011–present; hourly |
| Bohai Sea | (117°–123°E, 37°–41°N); 500 m | |||
| Western Pacific-Indian Ocean Data Sets | South China Sea | Surface suspended matter concentration, surface chlorophyll concentration, sea water transparency | (98°–127°E, 0°–25°N); 1.8 km | 2010–2015; daily average, 10-day average, monthly average, yearly average |
| Western Pacific Ocean | (121°–160°E, 2°S–46°N); 1.8 km | |||
| Eastern Indian Ocean | (80°–118°E, 10°S–21°N); 1.8 km | |||
| One Belt and One Road region | Surface chlorophyll concentration, sea surface temperature, photosynthetic effective radiation, sea water transparency, primary productivity | (12°W–150°E, 40°S–80°N); 9 km | 2003–2014; monthly average | |
| Disastrous wave product | Count of disastrous waves | (20°–160°W, 60°S–85°N); 9 km | 2006–2016; Climatological monthly mean data | |
| Significant wave height | 2006–2016; daily average | |||
| Global Data Sets | SeaWiFS | 355 nm CDOM absorption coefficient, seawater transparency, non-algal particle absorption coefficient, 660 nm particle attenuation coefficient, 660 nm organic particle attenuation coefficient, and sea surface salinity | Global, 9 km | 1997–2010; daily average, monthly average |
| MODIS/Aqua | 2002–present; daily average, monthly average | |||
| VIIRS | 2012–present; daily average, monthly average | |||
| NASA Public Data Sets [41] | Aquarius | Sea surface salinity | Global, 100 km | 2011–2015; monthly average |
| SeaWiFS | RS reflectance (412, 443, 490, 510, 555, 670 nm), surface chlorophyll concentration, photosynthetic available radiation at sea surface, particulate organic carbon and particulate inorganic carbon | Global, 9 km | 1997–Nov 2010; daily average, monthly average | |
| MODIS/Aqua | RS reflectance (412, 443, 488, 531, 547, 555, 645, 667 nm), surface chlorophyll concentration, photosynthetic available radiation at sea surface, particulate organic carbon and particulate inorganic carbon | Global, 9 km | 2002–present; daily average, monthly average | |
| VIIRS | RS reflectance (410, 443, 486, 551, 671 nm), surface chlorophyll concentration, photosynthetic available radiation at sea surface, surface particulate organic carbon and particulate inorganic carbon | Global, 9 km | 2002–present; daily average, monthly average | |
| Public Data Sets of Other Institutions [42,43] | CCMP from RSS | Sea surface wind | Global, 25 km | 1987–2017; daily average, monthly average |
| SMAP from RSS | Sea surface salinity | 2016–present; monthly average | ||
| Sea level anomaly from CMEMS | Sea level anomaly | Global, 25 km | 1993–present; daily average, monthly average | |
| Geostrophic flow from CMEMS | Geostrophic flow | 1993–2018; daily average, monthly average | ||
| Mixing layer depth from CMEMS | Mixing layer depth | 1998–2015; daily average, monthly average | ||
| SeaWiFS by OSU | Net primary productivity | Global, 9 km | 1997–2010; monthly average | |
| MODIS by OSU | 2002–present; monthly average | |||
| VIIRS by OSU | 2012–present; monthly average | |||
| SMOS from ESA | Sea surface salinity | Global, 100 km | 2009–present; monthly average | |
| CCI from ESA | Multiple-satellite-merged chlorophyll concentration | Global, 4 km | 1997–2016; daily average, monthly average | |
| CarbonTr-acker from NOAA | Atmospheric pCO2 (after correction of the air pressure, water vapor, and spatial interpolation) | Global, 25 km | 2000–2016; daily average, monthly average | |
| Relative Humidity from NOAA | Relative humidity | Global, 100 km | 2000–2016; daily average | |
| AVHRR_OI from NOAA | Sea surface temperature | Global, 25 km | 1981–present; daily average, monthly average | |
| Underway pCO2 from CDIAC | Sea surface pCO2, temperature, salinity | underway | 1992–2015; underway |
References
- Berger, M.; Moreno, J.; Johannessen, J.A.; Levelt, P.F.; Hanssen, R.F. ESA’s sentinel missions in support of Earth system science. Remote Sens. Environ. 2012, 120, 84–90. [Google Scholar] [CrossRef]
- Han, G.; Chen, J.; He, C.; Li, S.; Wu, H.; Liao, A.; Peng, S. A web-based system for supporting global land cover data production. ISPRS J. Photogramm. Remote Sens. 2015, 103, 66–80. [Google Scholar] [CrossRef]
- Boyd, D.S.; Jackson, B.; Wardlaw, J.; Foody, G.M.; Marsh, S.; Bales, K. Slavery from space: Demonstrating the role for satellite remote sensing to inform evidence-based action related to UN SDG number 8. ISPRS J. Photogramm. Remote Sens. 2018, 142, 380–388. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef]
- Peternier, A.; Boncori, J.P.M.; Pasquali, P. Near-real-time focusing of ENVISAT ASAR Stripmap and Sentinel-1 TOPS imagery exploiting OpenCL GPGPU technology. Remote Sens. Environ. 2017, 202, 45–53. [Google Scholar] [CrossRef]
- Liu, Q.; Klucik, R.; Chen, C.; Grant, G.; Gallaher, D.; Lv, Q.; Shang, L. Unsupervised detection of contextual anomaly in remotely sensed data. Remote Sens. Environ. 2017, 202, 75–87. [Google Scholar] [CrossRef]
- Mattmann, C.A. Computing: A vision for data science. Nature 2013, 493, 473–475. [Google Scholar] [CrossRef]
- Wang, L.; Ma, Y.; Yan, J.; Chang, V.; Zomaya, A.Y. pipsCloud: High performance cloud computing for RS big data management and processing. Future Gener. Comput. Syst. 2018, 78, 353–368. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Yu, L.; Gong, P. Google Earth as a virtual globe tool for Earth science applications at the global scale: Progress and perspectives. Int. J. Remote Sens. 2012, 33, 3966–3986. [Google Scholar] [CrossRef]
- Ye, W.; Zhang, F.; Bai, Y.; Du, Z.; Liu, R. A tile service-driven architecture for online climate analysis with an application to estimation of ocean carbon flux. Environ. Model. Softw. 2019, 118, 120–133. [Google Scholar] [CrossRef]
- Fu, G. SeaDAS: The SeaWiFS data analysis system. In Proceedings of the PORSEC’98, Qingdao, China, 28–31 July 1998; pp. 73–79. [Google Scholar]
- Zhang, T.; Li, J.; Liu, Q.; Huang, Q. A cloud-enabled remote visualization tool for time-varying climate data analytics. Environ. Model. Softw. 2016, 75, 513–518. [Google Scholar] [CrossRef]
- Giuliani, G.; Dao, H.; De Bono, A.; Chatenoux, B.; Allenbach, K.; De Laborie, P.; Rodila, D.; Alexandris, N.; Peduzzi, P. Live Monitoring of Earth Surface (LiMES): A framework for monitoring environmental changes from Earth Observations. Remote Sens. Environ. 2017, 202, 222–233. [Google Scholar] [CrossRef]
- Lewis, A.; Oliver, S.; Lymburner, L.; Evans, B.; Wyborn, L.; Mueller, N.; Raevski, G.; Hooke, J.; Woodcock, R.; Sixsmith, J.; et al. The Australian geoscience data cube—Foundations and lessons learned. Remote Sens. Environ. 2017, 202, 276–292. [Google Scholar] [CrossRef]
- Goyal, S.; Srivastava, P.P.; Kumar, A. An overview of hybrid databases. In Proceedings of the 2015 International Conference on Green Computing and Internet of Things (ICGCIoT), Noida, India, 8–10 October 2015. [Google Scholar]
- Villari, M.; Giacobbe, M.; Fazio, M. Enriched ER model to design hybrid database for big data solutions. In Proceedings of the 2016 IEEE Symposium on Computers and Communication (ISCC), Messina, Italy, 27–30 June 2016. [Google Scholar]
- Ogasawara, G.H.; Tso, M.M. Hybrid Data Management System and Method for Managing Large, Varying Datasets. U.S. Patent No. 9,396,290, 19 July 2016. [Google Scholar]
- Vyawahare, H.R.; Karde, P.P.; Thakare, V.M. A Hybrid Database Approach Using Graph and Relational Database. In Proceedings of the 2018 International Conference on Research in Intelligent and Computing in Engineering (RICE), San Salvador, El Salvador, 22–24 August 2018. [Google Scholar]
- Vora, M.N. Hadoop-HBase for large-scale data. In Proceedings of the 2011 International Conference on Computer Science and Network Technology, Harbin, China, 24–26 December 2011; Volume 1. [Google Scholar]
- Fortner, B. HDF: The hierarchical data format. Dr. Dobb’s J. Softw. Tools Prof. Program. 1998, 23, 42. [Google Scholar]
- Shupeng, C.; van Genderen, J. Digital Earth in support of global change research. Int. J. Digit. Earth 2008, 1, 43–65. [Google Scholar]
- Liu, P.; Gong, J.; Yu, M. Visualizing and analyzing dynamic meteorological data with virtual globes: A case study of tropical cyclones. Environ. Model. Softw. 2015, 64, 80–93. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, X.; Li, Z. Multiple-view geospatial comparison using web-based virtual globes. ISPRS J. Photogramm. Remote Sens. 2019, 156, 235–246. [Google Scholar] [CrossRef]
- Hoffer, D. What does Big Data Look Like? Visualization is Key for Humans. Available online: http://www.wired.com/insights/2014/01/big-data-look-like-visualization-k (accessed on 12 February 2020).
- Li, S.; Dragicevic, S.; Castro, F.A.; Sester, M.; Winter, S.; Coltekin, A.; Pettit, C.; Jiang, B.; Haworth, J.; Stein, A.; et al. Geospatial big data handling theory and methods: A review and research challenges. ISPRS J. Photogramm. Remote Sens. 2016, 115, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Integrating geo web services for a user driven exploratory analysis. ISPRS J. Photogramm. Remote Sens. 2016, 114, 294–305.
- Fang, S.; Biddlecome, T.; Tuceryan, M. Image-based transfer function design for data exploration in volume visualization. In Proceedings of the Visualization’98 (Cat. No. 98CB36276), Research Triangle Park, NC, USA, 18–23 October 1998. [Google Scholar]
- Warmerdam, F. The geospatial data abstraction library. In Open Source Approaches in Spatial Data Handling; Springer: Berlin, Heidelberg, 2008; pp. 87–104. [Google Scholar]
- Salloum, S.; Dautov, R.; Chen, X.; Peng, P.X.; Huang, J.Z. Big data analytics on Apache Spark. Int. J. Data Sci. Anal. 2016, 1, 145–164. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Kang, J.; Du, Z.; Zhang, F.; Huang, X.; Liu, R.; Zhang, X. Vector spatial big data storage and optimized query based on the multi-level Hilbert grid index in HBase. Information 2018, 9, 116. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Pan, D.; Bai, Y.; He, X.; Chen, C.T.A.; Hao, Z. Episodic phytoplankton bloom events in the Bay of Bengal triggered by multiple forcings. Deep Sea Res. Part I Oceanogr. Res. Pap. 2013, 73, 17–30. [Google Scholar] [CrossRef]
- Prasad, K.S.; Bernstein, R.L.; Kahru, M.; Michell, B.G. Ocean color algorithms for estimating water clarity (Secchi depth) from SeaWiFS. J. Adv. Mar. Sci. Technol. Soc. 1998, 4, 301–306. [Google Scholar]
- He, X.; Pan, D.; Bai, Y.; Wang, T.; Chen, C.T.A.; Zhu, Q.; Gong, F. Recent changes of global ocean transparency observed by SeaWiFS. Cont. Shelf Res. 2017, 143, 159–166. [Google Scholar] [CrossRef]
- He, X.Q.; Pan, D.L.; Mao, Z.H. Water transparency (Secchi depth) monitoring in the China Sea with the SeaWiFS satellite sensor. In Remote Sensing for Agriculture, Ecosystems and Hydrology VI; International Society for Optics and Photonics: Canary Islands, Spain, 2004; Volume 5568, pp. 112–122. [Google Scholar] [CrossRef]
- Jiao, N.Z.; Zhang, Y.; Zeng, Y.; Gardner, W.D.; Mishonov, A.V.; Richardson, M.J.; Hong, N.; Pan, D.; Yan, X.-H.; Jo, Y.-H.; et al. Ecological anomalies in the East China Sea: Impacts of the Three Gorges Dam? Water Res. 2007, 41, 1287–1293. [Google Scholar] [CrossRef]
- Doron, M.; Babin, M.; Hembise, O.; Mangin, A.; Garnesson, P. Ocean transparency from space: Validation of algorithms estimating Secchi depth using MERIS, MODIS and SeaWiFS data. Remote Sens. Environ. 2011, 115, 2986–3001. [Google Scholar]
- Smart, J.H. Worldwide Ocean Optics Database (WOOD); Johns Hopkins University Applied Physics Lab: Laurel, MD, USA, 2002. [Google Scholar]
- Wang, P.; Wang, J.; Chen, Y.; Ni, G. Rapid processing of RS images based on cloud computing. Future Gener. Comput. Syst. 2013, 29, 1963–1968. [Google Scholar] [CrossRef]
- Berrick, S.W.; Leptoukh, G.; Farley, J.D.; Rui, H. Giovanni: A web service workflow-based data visualization and analysis system. IEEE Trans. Geosci. RS 2008, 47, 106–113. [Google Scholar] [CrossRef]
- NASA Goddard Space Flight Center, Ocean Ecology Laboratory, Ocean Biology Processing Group. Sea-Viewing Wide Field-of-View Sensor (SeaWiFS), Moderate-Resolution Imaging Spectroradiometer on Board Aqua (MODIS/Aqua), Visible Infrared Imaging Radiometer (VIIRS), Ocean Color Data, NASA OB.DAAC. 2018. Available online: https://doi.org/10.5067/ORBVIEW-2/SEAWIFS_OC.2014.0 (accessed on 29 February 2020).
- Research Data Archive at the National Center for Atmospheric Research. Computational and Information Systems Laboratory. Available online: https://doi.org/10.5065/D6M043C6 (accessed on 9 November 2018).
- Takahashi, T.; Sutherland, S.C.; Kozyr, A. Global Ocean Surface Water Partial Pressure of CO2 Database: Measurements Performed During 1957–2015 (Version 2015); ORNL/CDIAC-161, NDP-088(V2015); Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory, U.S. Department of Energy: Oak Ridge, TN, USA, 2016. [CrossRef]





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, W.; Zhang, F.; He, X.; Bai, Y.; Liu, R.; Du, Z. A Tile-Based Framework with a Spatial-Aware Feature for Easy Access and Efficient Analysis of Marine Remote Sensing Data. Remote Sens. 2020, 12, 1932. https://doi.org/10.3390/rs12121932
Ye W, Zhang F, He X, Bai Y, Liu R, Du Z. A Tile-Based Framework with a Spatial-Aware Feature for Easy Access and Efficient Analysis of Marine Remote Sensing Data. Remote Sensing. 2020; 12(12):1932. https://doi.org/10.3390/rs12121932
Chicago/Turabian StyleYe, Weiwen, Feng Zhang, Xianqiang He, Yan Bai, Renyi Liu, and Zhenhong Du. 2020. "A Tile-Based Framework with a Spatial-Aware Feature for Easy Access and Efficient Analysis of Marine Remote Sensing Data" Remote Sensing 12, no. 12: 1932. https://doi.org/10.3390/rs12121932
APA StyleYe, W., Zhang, F., He, X., Bai, Y., Liu, R., & Du, Z. (2020). A Tile-Based Framework with a Spatial-Aware Feature for Easy Access and Efficient Analysis of Marine Remote Sensing Data. Remote Sensing, 12(12), 1932. https://doi.org/10.3390/rs12121932