Refined UNet: UNet-Based Refinement Network for Cloud and Shadow Precise Segmentation



Abstract
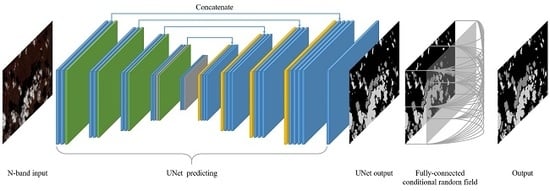
:
1. Introduction
- Refined UNet: We propose an innovative architecture of assembling UNet and Dense CRF to detect clouds and shadows and refine their corresponding boundaries. The proper utilization of the Dense CRF refinement can sharpen the detection of cloud and shadow boundaries.
- Adaptive weights for imbalanced categories: An adaptive weight strategy for imbalanced categories is employed in training, which can dynamically calculate the weights and enhance the label attention of the model for minorities.
- Extension to four-band segmentation: The segmentation efficacy of our Refined UNet was also tested on the Landsat 8 OLI imagery dataset of Blue, Green, Red, and NIR bands; the experimental results illustrate that our method can obtain feasible segmentation results as well.
2. Related Work
2.1. Cloud and Shadow Segmentation
2.2. State-of-the-Art Neural Semantic Segmentation
3. Methodology
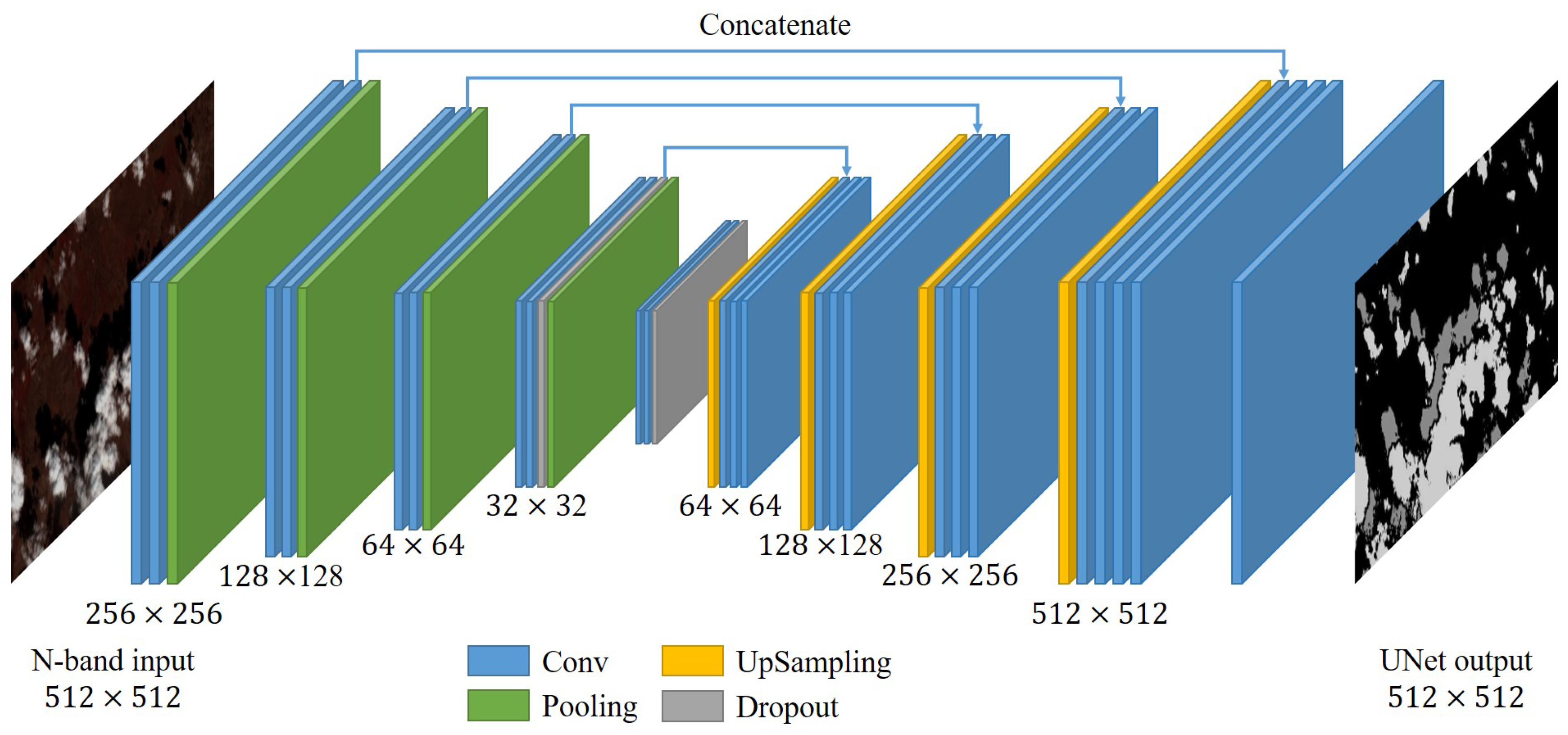
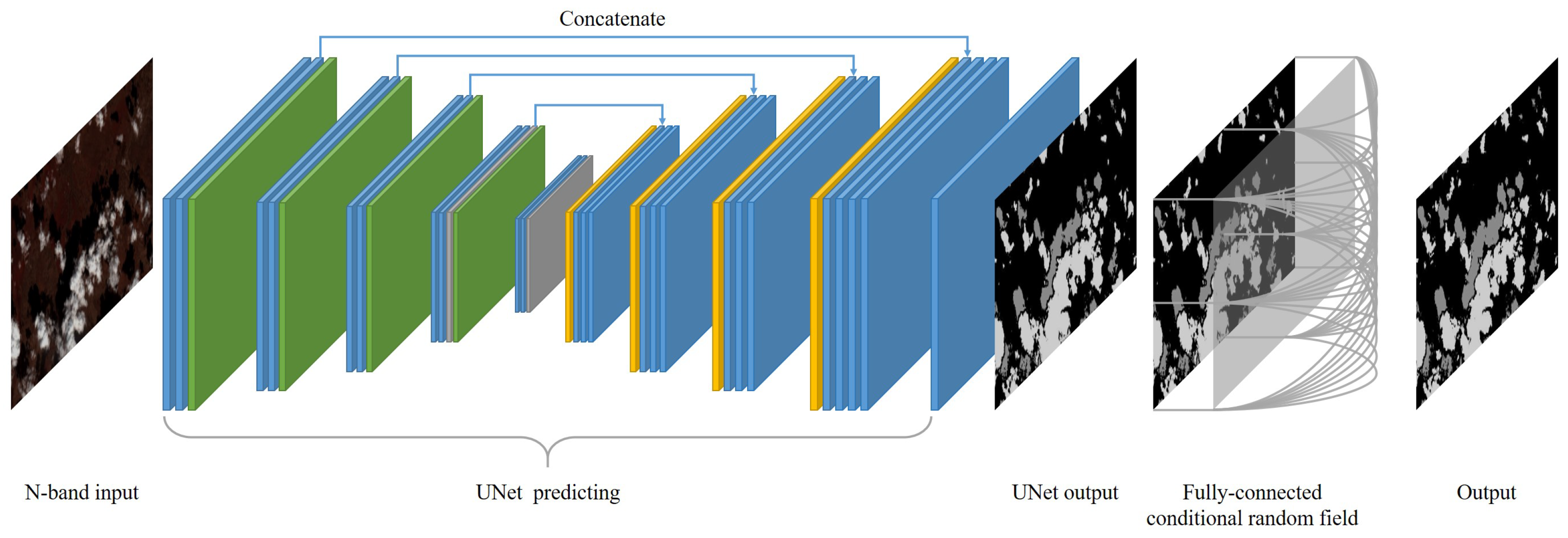
3.1. UNet Prediction
3.2. Fully-Connected Conditional Random Field (Dense CRF) Postprocessing
3.3. Concatenation of UNet Prediction and Dense CRF Refinement
- The entire images are rescaled, padded, and cropped into patches with the size of . The trained UNet infers the pixel-level categories for the patches. The rough segmentation proposal is constructed from the results.
- Taking as input the entire UNet proposal and a three-channel edge-sensitive image, Dense CRF refines the segmentation proposal to make the boundaries of clouds and shadows more precise.
4. Experiments and Discussion
4.1. Experimental Data Acquisition and Preprocessing
- 2013: 2013-04-20, 2013-06-07, 2013-07-09, 2013-08-26, 2013-09-11, 2013-10-13, and 2013-12-16
- 2014: 2014-03-22, 2014-04-23, 2014-05-09, 2016-06-10, and 2014-07-28
- 2015: 2015-06-13, 2015-07-15, 2015-08-16, 2015-09-01, and 2015-11-04
- 2013: 2013-06-23, 2013-09-27, and 2013-10-29
- 2014: 2014-02-18, and 2014-05-25
- 2015: 2015-07-31, 2015-09-17, and 2015-11-20
- 2016: 2016-03-27, 2016-04-12, 2016-04-28, 2016-05-14, 2016-05-30, 2016-06-15, 2016-07-17, 2016-08-02, 2016-08-18, 2016-10-21, and 2016-11-06
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Comparisons of Refined UNet and Novel Methods
4.5. Comparisons of References and Refined UNet
4.6. Effect of the Dense CRF Refinement
4.7. Hyperparameter Sensitivity with Respect to Dense CRF
4.8. Effect of the Adaptive Weights Regarding Imbalanced Categories
4.9. Cross-Validation over the Entire Dataset
- 2013: 2013-04-20, 2013-06-07, 2013-07-09, 2013-08-26, and 2013-09-11
- 2014: 2014-03-22, 2014-04-23, 2014-05-09, 2014-06-10, and 2014-07-28
- 2015: 2015-06-13, 2015-07-15, 2015-08-16, 2015-09-01, and 2015-11-04
- 2016: 2016-03-27, 2016-04-12, 2016-04-28, 2016-05-14, and 2016-05-30
4.10. Evaluation on Four-Band Imageries
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chai, D.; Newsam, S.; Zhang, H.K.; Qiu, Y.; Huang, J. Cloud and cloud shadow detection in Landsat imagery based on deep convolutional neural networks. Remote Sens. Environ. 2019, 225, 307–316. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. 2016, pp. 770–778. Available online: http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html (accessed on 18 December 2019).
- Huang, G.; Liu, Z.; Der Maaten, L.V.; Weinberger, K.Q. Densely Connected Convolutional Networks. 2017, pp. 2261–2269. Available online: http://openaccess.thecvf.com/content_cvpr_2017/html/Huang_Densely_Connected_Convolutional_CVPR_2017_paper.html (accessed on 18 December 2019).
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. 2015, pp. 3431–3440. Available online: https://www.cv-foundation.org/openaccess/content_cvpr_2015/html/Long_Fully_Convolutional_Networks_2015_CVPR_paper.html (accessed on 18 December 2019).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding. arXiv 2015, arXiv:1511.02680. [Google Scholar]
- Sun, L.; Liu, X.; Yang, Y.; Chen, T.; Wang, Q.; Zhou, X. A cloud shadow detection method combined with cloud height iteration and spectral analysis for Landsat 8 OLI data. ISPRS J. Photogramm. Remote Sens. 2018, 138, 193–207. [Google Scholar] [CrossRef]
- Qiu, S.; He, B.; Zhu, Z.; Liao, Z.; Quan, X. Improving Fmask cloud and cloud shadow detection in mountainous area for Landsats 4–8 images. Remote Sens. Environ. 2017, 199, 107–119. [Google Scholar] [CrossRef]
- Vermote, E.F.; Justice, C.O.; Claverie, M.; Franch, B. Preliminary analysis of the performance of the Landsat 8/OLI land surface reflectance product. Remote Sens. Environ. 2016, 185, 46–56. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Shen, H.; Li, H.; Xia, G.; Gamba, P.; Zhang, L. Multi-feature combined cloud and cloud shadow detection in GaoFen-1 wide field of view imagery. Remote Sens. Environ. 2017, 191, 342–358. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Hughes, M.J.; Laue, B. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Helmer, E.H. An automatic method for screening clouds and cloud shadows in optical satellite image time series in cloudy regions. Remote Sens. Environ. 2018, 214, 135–153. [Google Scholar] [CrossRef]
- Frantz, D.; Roder, A.; Udelhoven, T.; Schmidt, M. Enhancing the Detectability of Clouds and Their Shadows in Multitemporal Dryland Landsat Imagery: Extending Fmask. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1242–1246. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Automated cloud, cloud shadow, and snow detection in multitemporal Landsat data: An algorithm designed specifically for monitoring land cover change. Remote Sens. Environ. 2014, 152, 217–234. [Google Scholar] [CrossRef]
- Ricciardelli, E.; Romano, F.; Cuomo, V. Physical and statistical approaches for cloud identification using Meteosat Second Generation-Spinning Enhanced Visible and Infrared Imager Data. Remote Sens. Environ. 2008, 112, 2741–2760. [Google Scholar] [CrossRef]
- Amato, U.; Antoniadis, A.; Cuomo, V.; Cutillo, L.; Franzese, M.; Murino, L.; Serio, C. Statistical cloud detection from SEVIRI multispectral images. Remote Sens. Environ. 2008, 112, 750–766. [Google Scholar] [CrossRef]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. 2018, pp. 4510–4520. Available online: http://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html (accessed on 18 December 2019).
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. 2019. Available online: http://openaccess.thecvf.com/content_ICCV_2019/html/Howard_Searching_for_MobileNetV3_ICCV_2019_paper.html (accessed on 18 December 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. 2017, pp. 1175–1183. Available online: http://openaccess.thecvf.com/content_cvpr_2017_workshops/w13/html/Jegou_The_One_Hundred_CVPR_2017_paper.html (accessed on 18 December 2019).
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. 2017, pp. 5168–5177. Available online: http://openaccess.thecvf.com/content_cvpr_2017/html/Lin_RefineNet_Multi-Path_Refinement_CVPR_2017_paper.html (accessed on 18 December 2019).
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. 2017, pp. 6230–6239. Available online: http://openaccess.thecvf.com/content_cvpr_2017/html/Zhao_Pyramid_Scene_Parsing_CVPR_2017_paper.html (accessed on 18 December 2019).
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. 2017, pp. 1743–1751. Available online: http://openaccess.thecvf.com/content_cvpr_2017/html/Peng_Large_Kernel_Matters_CVPR_2017_paper.html (accessed on 18 December 2019).
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. 2018, pp. 432–448. Available online: http://openaccess.thecvf.com/content_ECCV_2018/html/Tete_Xiao_Unified_Perceptual_Parsing_ECCV_2018_paper.html (accessed on 18 December 2019).
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation. 2019. Available online: http://openaccess.thecvf.com/content_ICCV_2019/html/Takikawa_Gated-SCNN_Gated_Shape_CNNs_for_Semantic_Segmentation_ICCV_2019_paper.html (accessed on 18 December 2019).
- Papandreou, G.; Chen, L.; Murphy, K.; Yuille, A.L. Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation. 2015, pp. 1742–1750. Available online: http://openaccess.thecvf.com/content_iccv_2015/html/Papandreou_Weakly-_and_Semi-Supervised_ICCV_2015_paper.html (accessed on 18 December 2019).
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2007. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. 2018. Available online: http://openaccess.thecvf.com/content_ECCV_2018/html/Liang-Chieh_Chen_Encoder-Decoder_with_Atrous_ECCV_2018_paper.html (accessed on 18 December 2019).
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. 2017, pp. 1800–1807. Available online: http://openaccess.thecvf.com/content_cvpr_2017/html/Chollet_Xception_Deep_Learning_CVPR_2017_paper.html (accessed on 18 December 2019).
- Zheng, S.; Jayasumana, S.; Romeraparedes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H.S. Conditional Random Fields as Recurrent Neural Networks. 2015, pp. 1529–1537. Available online: https://www.cv-foundation.org/openaccess/content_iccv_2015/html/Zheng_Conditional_Random_Fields_ICCV_2015_paper.html (accessed on 17 September 2019).
- Liu, Z.; Li, X.; Luo, P.; Loy, C.C.; Tang, X. Semantic Image Segmentation via Deep Parsing Network. 2015, pp. 1377–1385. Available online: http://openaccess.thecvf.com/content_iccv_2015/html/Liu_Semantic_Image_Segmentation_ICCV_2015_paper.html (accessed on 18 December 2019).
- Chandra, S.; Kokkinos, I. Fast, Exact and Multi-Scale Inference for Semantic Image Segmentation with Deep Gaussian CRFs; Springer: Cham, Switzerland, 2016; pp. 402–418. [Google Scholar]
- Krahenbuhl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. 2011, pp. 109–117. Available online: papers.nips.cc/paper/4296-efficient-inference-in-fully-connected-crfs-with-gaussian-edge-potentials.pdf (accessed on 11 September 2019).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wilcoxon, F. Individual Comparisons by Ranking Methods. Biometrics 1945, 1, 196–202. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class No. | Class Name | Evaluation | PSPNet (%) | UNet (%) | Refined UNet (%) |
|---|---|---|---|---|---|
| Accuracy+ | 84.88 ± 7.59 | 93.04 ± 5.45 | 93.51 ± 5.45 | ||
| 0 | Background | Precision+ | 65.49 ± 19.62 | 93.34 ± 4.88 | 90.33 ± 7.04 |
| Recall+ | 98.57 ± 2.18 | 81.52 ± 15.3 | 85.58 ± 17.4 | ||
| F1+ | 77.06 ± 15.04 | 86.35 ± 11.04 | 86.92 ± 12.18 | ||
| 1 | Fill Values | Precision+ | 100 ± 0 | 100 ± 0 | 99.89 ± 0.06 |
| Recall+ | 95.97 ± 0.19 | 100 ± 0 | 100 ± 0 | ||
| F1+ | 97.94 ± 0.1 | 100 ± 0 | 99.94 ± 0.03 | ||
| 2 | Shadows | Precision+ | 46.81 ± 24.98 | 34.74 ± 14.77 | 36.28 ± 20.4 |
| Recall+ | 7.83 ± 5.95 | 54.31 ± 18.72 | 21.51 ± 11.91 | ||
| F1+ | 12.74 ± 9.14 | 40.43 ± 14.74 | 24.63 ± 11.49 | ||
| 3 | Clouds | Precision+ | 94.09 ± 17 | 87.28 ± 18.78 | 87.57 ± 19.11 |
| Recall+ | 48.22 ± 22.81 | 95.96 ± 3.63 | 96.03 ± 3.17 | ||
| F1+ | 60.99 ± 22.56 | 90.12 ± 13.77 | 90.22 ± 14.09 |
| Class No. | Class Name | Evaluation | UNet (%) | UNet (%) | UNet (%) | UNet (%) | UNet (%) | UNet (%) |
|---|---|---|---|---|---|---|---|---|
| Accuracy+ | 92.92 ± 6.68 | 92.89 ± 6.6 | 92.15 ± 6.89 | 91.81 ± 6.51 | 90.85 ± 6.85 | 93.51 ± 5.45 | ||
| 0 | Background | Precision+ | 90.58 ± 7.73 | 91.75 ± 6.94 | 94.64 ± 4.72 | 95.23 ± 4.47 | 95.80 ± 3.98 | 90.33 ± 7.04 |
| Recall+ | 81.60 ± 26.76 | 80.11 ± 27.31 | 76.06 ± 28.00 | 75.01 ± 23.87 | 70.46 ± 27.14 | 85.58 ± 17.40 | ||
| F1+ | 83.15 ± 24.10 | 82.42 ± 25.37 | 80.24 ± 27.68 | 81.25 ± 20.76 | 77.20 ± 27.35 | 86.92 ± 12.18 | ||
| 1 | Fill Values | Precision+ | 99.91 ± 0.05 | 99.89 ± 0.06 | 99.89 ± 0.06 | 99.88 ± 0.06 | 99.90 ± 0.04 | 99.89 ± 0.06 |
| Recall+ | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 | ||
| F1+ | 99.95 ± 0.03 | 99.94 ± 0.03 | 99.94 ± 0.03 | 99.94 ± 0.03 | 99.95 ± 0.02 | 99.94 ± 0.03 | ||
| 2 | Shadows | Precision+ | 48.69 ± 40.98 | 44.20 ± 23.46 | 36.64 ± 20.75 | 27.62 ± 13.33 | 23.39 ± 10.36 | 36.28 ± 20.40 |
| Recall+ | 1.01 ± 1.54 | 13.44 ± 11.37 | 21.55 ± 15.82 | 27.38 ± 16.51 | 35.92 ± 17.02 | 21.51 ± 11.91 | ||
| F1+ | 1.91 ± 2.86 | 18.78 ± 13.51 | 25.16 ± 16.28 | 26.25 ± 13.47 | 27.67 ± 12.23 | 24.63 ± 11.49 | ||
| 3 | Clouds | Precision+ | 82.02 ± 19.64 | 81.99 ± 19.45 | 79.68 ± 19.94 | 80.52 ± 19.74 | 80.78 ± 19.82 | 87.57 ± 19.11 |
| Recall+ | 98.95 ± 0.81 | 99.03 ± 0.73 | 99.25 ± 0.63 | 99.20 ± 0.69 | 99.13 ± 0.71 | 96.03 ± 3.17 | ||
| F1+ | 88.19 ± 15.24 | 88.26 ± 14.97 | 86.84 ± 15.51 | 87.38 ± 15.37 | 87.50 ± 15.32 | 90.22 ± 14.09 |
| Class No. | Class Name | Evaluation | UNet (%) | UNet (%) | UNet (%) | UNet (%) | UNet (%) | UNet (%) |
|---|---|---|---|---|---|---|---|---|
| Accuracy+ | 93.1 ± 6.45 | 93.02 ± 6.29 | 91.91 ± 6.81 | 91.59 ± 6.41 | 90.47 ± 6.84 | 93.04 ± 5.45 | ||
| 0 | Background | Precision+ | 92.84 ± 5.81 | 94.50 ± 5.13 | 96.72 ± 2.98 | 97.87 ± 1.72 | 97.94 ± 1.73 | 93.34 ± 4.88 |
| Recall+ | 81.83 ± 24.23 | 78.88 ± 24.23 | 73.91 ± 25.79 | 73.23 ± 20.10 | 67.95 ± 25.57 | 81.52 ± 15.30 | ||
| F1+ | 84.91 ± 20.54 | 83.83 ± 21.25 | 80.78 ± 24.42 | 82.15 ± 16.06 | 76.87 ± 25.55 | 86.35 ± 11.04 | ||
| 1 | Fill Values | Precision+ | 99.99 ± 0.00 | 99.98 ± 0.01 | 99.99 ± 0.01 | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 |
| Recall+ | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 | ||
| F1+ | 99.99 ± 0.00 | 99.99 ± 0.01 | 99.99 ± 0.01 | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 | ||
| 2 | Shadows | Precision+ | 63.65 ± 38.27 | 46.68 ± 20.38 | 34.72 ± 15.54 | 28.56 ± 12.45 | 25.40 ± 11.44 | 34.74 ± 14.77 |
| Recall+ | 5.35 ± 6.17 | 30.36 ± 20.30 | 39.33 ± 22.31 | 49.08 ± 19.79 | 57.49 ± 21.22 | 54.31 ± 18.72 | ||
| F1+ | 9.38 ± 10.27 | 34.15 ± 18.25 | 35.66 ± 16.76 | 35.45 ± 14.54 | 34.67 ± 14.56 | 40.43 ± 14.74 | ||
| 3 | Clouds | Precision+ | 80.39 ± 19.34 | 80.80 ± 19.24 | 78.98 ± 19.79 | 80.62 ± 19.47 | 80.65 ± 19.82 | 87.28 ± 18.78 |
| Recall+ | 99.43 ± 0.87 | 99.49 ± 0.62 | 99.59 ± 0.59 | 99.42 ± 0.67 | 99.21 ± 0.79 | 95.96 ± 3.63 | ||
| F1+ | 87.45 ± 15.10 | 87.77 ± 14.82 | 86.57 ± 15.41 | 87.59 ± 15.07 | 87.49 ± 15.15 | 90.12 ± 13.77 |
| Class No. | Class Name | Evaluation | 2013 (%) | 2014 (%) | 2015 (%) | 2016 (%) |
|---|---|---|---|---|---|---|
| Accuracy+ | 88.35 ± 9.4 | 93.23 ± 8.87 | 92.36 ± 4.14 | 89.1 ± 3.48 | ||
| 0 | Background | Precision+ | 89.22 ± 7.35 | 95.98 ± 2.43 | 95.33 ± 3.29 | 93.56 ± 4.16 |
| Recall+ | 79.29 ± 28.77 | 84.73 ± 26.05 | 85.91 ± 12.32 | 65.24 ± 28.75 | ||
| F1+ | 82 ± 22.23 | 87.93 ± 18.74 | 89.98 ± 7.53 | 73.12 ± 25.75 | ||
| 1 | Fill Values | Precision+ | 99.98 ± 0.01 | 99.96 ± 0.03 | 99.95 ± 0.04 | 99.96 ± 0.03 |
| Recall+ | 100 ± 0 | 100 ± 0 | 100 ± 0 | 100 ± 0 | ||
| F1+ | 99.99 ± 0.01 | 99.98 ± 0.02 | 99.98 ± 0.02 | 99.98 ± 0.01 | ||
| 2 | Shadows | Precision+ | 7.25 ± 5.3 | 6.96 ± 9.76 | 26.65 ± 17.78 | 15.26 ± 6.28 |
| Recall+ | 18.95 ± 17.61 | 5.16 ± 6.17 | 45.99 ± 14.27 | 54.4 ± 12 | ||
| F1+ | 6.33 ± 3.2 | 5.59 ± 7.76 | 31.38 ± 14.82 | 23.65 ± 9.06 | ||
| 3 | Clouds | Precision+ | 90.63 ± 19.24 | 85.74 ± 17.37 | 92.57 ± 6.32 | 93.52 ± 8.05 |
| Recall+ | 76.06 ± 36.04 | 89.51 ± 14.2 | 92.31 ± 9.67 | 84.35 ± 17.64 | ||
| F1+ | 75.57 ± 31.36 | 85.77 ± 11.19 | 91.97 ± 4.23 | 87.59 ± 11.21 |
| Class No. | Class Name | Evaluation | Band 2 to 5 (%) | Band 1 to 7 (%) |
|---|---|---|---|---|
| Accuracy+ | 93.43 ± 6.56 | 93.51 ± 5.45 | ||
| 0 | Background | Precision+ | 89.52 ± 7.99 | 90.33 ± 7.04 |
| Recall+ | 84.31 ± 25.85 | 85.58 ± 17.40 | ||
| F1+ | 84.56 ± 21.81 | 86.92 ± 12.18 | ||
| 1 | Fill Values | Precision+ | 99.89 ± 0.07 | 99.89 ± 0.06 |
| Recall+ | 99.99 ± 0.00 | 99.99 ± 0.00 | ||
| F1+ | 99.95 ± 0.03 | 99.94 ± 0.03 | ||
| 2 | Cloud Shadows | Precision+ | 41.36 ± 24.98 | 36.28 ± 20.40 |
| Recall+ | 9.03 ± 9.10 | 21.51 ± 11.91 | ||
| F1+ | 13.99 ± 13.1 | 24.63* ± 11.49 | ||
| 3 | Clouds | Precision+ | 85.49 ± 19.89 | 87.57 ± 19.11 |
| Recall+ | 97.17 ± 2.37 | 96.03 ± 3.17 | ||
| F1+ | 89.50 ± 14.61 | 90.22 ± 14.09 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, L.; Huo, L.; Hu, C.; Tang, P. Refined UNet: UNet-Based Refinement Network for Cloud and Shadow Precise Segmentation. Remote Sens. 2020, 12, 2001. https://doi.org/10.3390/rs12122001
Jiao L, Huo L, Hu C, Tang P. Refined UNet: UNet-Based Refinement Network for Cloud and Shadow Precise Segmentation. Remote Sensing. 2020; 12(12):2001. https://doi.org/10.3390/rs12122001
Chicago/Turabian StyleJiao, Libin, Lianzhi Huo, Changmiao Hu, and Ping Tang. 2020. "Refined UNet: UNet-Based Refinement Network for Cloud and Shadow Precise Segmentation" Remote Sensing 12, no. 12: 2001. https://doi.org/10.3390/rs12122001
APA StyleJiao, L., Huo, L., Hu, C., & Tang, P. (2020). Refined UNet: UNet-Based Refinement Network for Cloud and Shadow Precise Segmentation. Remote Sensing, 12(12), 2001. https://doi.org/10.3390/rs12122001