Multi-Image Super Resolution of Remotely Sensed Images Using Residual Attention Deep Neural Networks





Abstract
:
1. Introduction
- The use of 3D convolutions to efficiently extract, directly from the stack of multiple low-resolution images, high-level representations, simultaneously exploiting spatial and temporal correlations.
- The introduction of a novel feature attention mechanism for 3D convolutions that lets the network focus on most promising high-frequency information largely overcoming main locality limitations of convolutional operations. Moreover, the concurrent use of multiple nested residuals, inside the network, let low-frequency components flow directly to the output of the model.
- The conceptualization and development of an efficient, highly replicable, deep learning neural network for MISR that makes use of 2D and 3D convolutions exclusively in the low-resolution space. It has been extensively evaluated on a major multi-frame open-source remote-sensing dataset proving state-of-the-art results with a considerable margin. Therefore, it constitutes an exceptional tool and opportunity for the remote-sensing research community.
2. Related Work
2.1. Single-Image Super-Resolution
2.2. SR for Remotely Sensed Imagery
2.3. Multi-Image Super-Resolution
3. Methodology
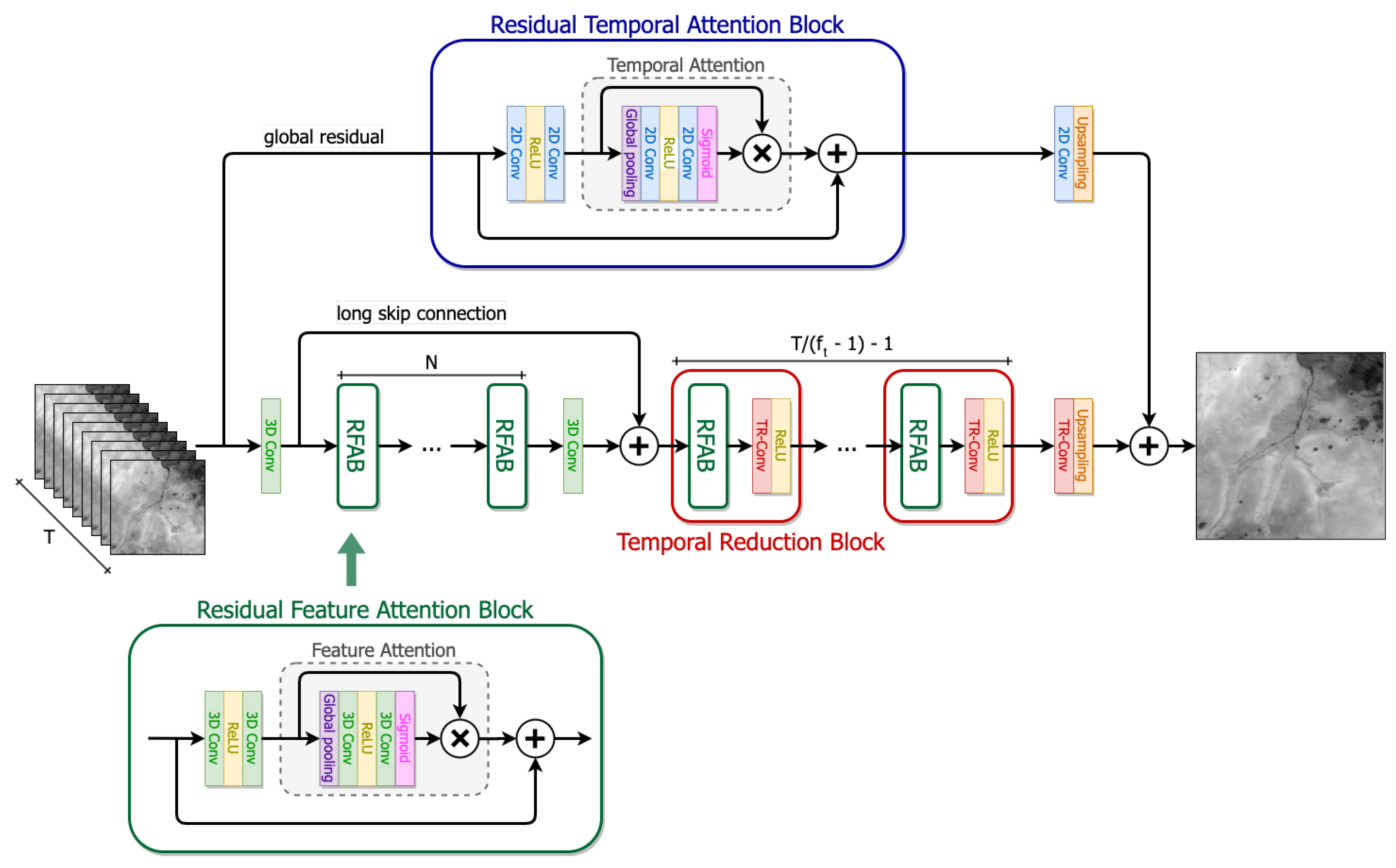
3.1. Network Architecture
3.2. Residual Attention Blocks
3.2.1. Residual Feature Attention
3.2.2. Residual Temporal Attention
3.3. Temporal Reduction Blocks
3.4. Training Process
4. Experiments and Discussion
4.1. The Proba-V Dataset
4.2. Data Pre-Processing
- register each LR image using as reference the one with maximum clearance c
- select the clearest T images from each scene that are above a certain clearance threshold
- pre-augment the training dataset with temporal permutations of the LR input images
- normalize the images by subtracting the dataset mean intensity value and dividing by the standard deviation
4.3. Experimental Settings
4.4. Quantitative Results
4.4.1. Temporal Self-Ensemble (RAMS+)
4.4.2. Comparison with State-of-The-Art Methods
4.4.3. Importance of the Residual Temporal Attention Branch
4.5. Qualitative Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Valsesia, D.; Magli, E. A novel rate control algorithm for onboard predictive coding of multispectral and hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6341–6355. [Google Scholar] [CrossRef] [Green Version]
- Benecki, P.; Kawulok, M.; Kostrzewa, D.; Skonieczny, L. Evaluating super-resolution reconstruction of satellite images. Acta Astronaut. 2018, 153, 15–25. [Google Scholar] [CrossRef]
- Valsesia, D.; Boufounos, P.T. Universal encoding of multispectral images. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4453–4457. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Yu, J.; Fan, Y.; Yang, J.; Xu, N.; Wang, Z.; Wang, X.; Huang, T. Wide activation for efficient and accurate image super-resolution. arXiv 2018, arXiv:1808.08718. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, California, CA, USA, 16–20 June 2019; pp. 11065–11074. [Google Scholar]
- Borman, S.; Stevenson, R.L. Super-resolution from image sequences-a review. In Proceedings of the 1998 Midwest Symposium on Circuits and Systems (Cat. No. 98CB36268), Notre Dame, Indiana, 9–12 August 1998; pp. 374–378. [Google Scholar]
- Tsai, R. Multiframe image restoration and registration. Adv. Comput. Vis. Image Process. 1984, 1, 317–339. [Google Scholar]
- Kim, S.; Bose, N.K.; Valenzuela, H.M. Recursive reconstruction of high resolution image from noisy undersampled multiframes. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1013–1027. [Google Scholar] [CrossRef]
- Irani, M.; Peleg, S. Super resolution from image sequences. In Proceedings of the 10th International Conference on Pattern Recognition, Atlantic City, NJ USA, 16–21 June 1990; Volume 2, pp. 115–120. [Google Scholar]
- Irani, M.; Peleg, S. Improving resolution by image registration. CVGIP 1991, 53, 231–239. [Google Scholar] [CrossRef]
- Irani, M.; Peleg, S. Motion analysis for image enhancement: Resolution, occlusion, and transparency. J. Vis. Commun. Image Represent. 1993, 4, 324–335. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 391–407. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 4539–4547. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 694–711. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sajjadi, M.S.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 4491–4500. [Google Scholar]
- Lanaras, C.; Bioucas-Dias, J.; Galliani, S.; Baltsavias, E.; Schindler, K. Super-resolution of Sentinel-2 images: Learning a globally applicable deep neural network. ISPRS J. Photogramm. Remote Sens. 2018, 146, 305–319. [Google Scholar] [CrossRef] [Green Version]
- Liebel, L.; Körner, M. Single-image super resolution for multispectral remote sensing data using convolutional neural networks. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 883–890. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ma, W.; Pan, Z.; Yuan, F.; Lei, B. Super-Resolution of Remote Sensing Images via a Dense Residual Generative Adversarial Network. Remote Sens. 2019, 11, 2578. [Google Scholar] [CrossRef] [Green Version]
- Dong, X.; Xi, Z.; Sun, X.; Gao, L. Transferred Multi-Perception Attention Networks for Remote Sensing Image Super-Resolution. Remote Sens. 2019, 11, 2857. [Google Scholar] [CrossRef] [Green Version]
- Gargiulo, M.; Mazza, A.; Gaetano, R.; Ruello, G.; Scarpa, G. Fast Super-Resolution of 20 m Sentinel-2 Bands Using Convolutional Neural Networks. Remote Sens. 2019, 11, 2635. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; He, Z.; Hu, J. Sentinel-2 Sharpening via Parallel Residual Network. Remote Sens. 2020, 12, 279. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.; Luo, B. Bidirectional Convolutional LSTM Neural Network for Remote Sensing Image Super-Resolution. Remote Sens. 2019, 11, 2333. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Sun, X.; Zhang, Y.; Fu, K.; Wang, L. Deep Residual Squeeze and Excitation Network for Remote Sensing Image Super-Resolution. Remote Sens. 2019, 11, 1817. [Google Scholar] [CrossRef] [Green Version]
- Yue, L.; Shen, H.; Li, J.; Yuan, Q.; Zhang, H.; Zhang, L. Image super-resolution: The techniques, applications, and future. Signal Process. 2016, 128, 389–408. [Google Scholar] [CrossRef]
- Elad, M.; Hel-Or, Y. A fast super-resolution reconstruction algorithm for pure translational motion and common space-invariant blur. IEEE Trans. Image Process. 2001, 10, 1187–1193. [Google Scholar] [CrossRef] [Green Version]
- Stark, H.; Oskoui, P. High-resolution image recovery from image-plane arrays, using convex projections. JOSA A 1989, 6, 1715–1726. [Google Scholar] [CrossRef]
- Lertrattanapanich, S.; Bose, N.K. High resolution image formation from low resolution frames using Delaunay triangulation. IEEE Trans. Image Process. 2002, 11, 1427–1441. [Google Scholar] [CrossRef]
- Takeda, H.; Farsiu, S.; Milanfar, P. Kernel regression for image processing and reconstruction. IEEE Trans. Image Process. 2007, 16, 349–366. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, H.; Ng, M.K.; Li, P.; Zhang, L. Super-resolution reconstruction algorithm to MODIS remote sensing images. The Comput. J. 2009, 52, 90–100. [Google Scholar] [CrossRef] [Green Version]
- Kato, T.; Hino, H.; Murata, N. Double sparsity for multi-frame super resolution. Neurocomputing 2017, 240, 115–126. [Google Scholar] [CrossRef]
- Schultz, R.R.; Stevenson, R.L. Extraction of high-resolution frames from video sequences. IEEE Trans. Image Process. 1996, 5, 996–1011. [Google Scholar] [CrossRef] [Green Version]
- Farsiu, S.; Robinson, M.D.; Elad, M.; Milanfar, P. Fast and robust multiframe super resolution. IEEE Trans. Image Process. 2004, 13, 1327–1344. [Google Scholar] [CrossRef]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kappeler, A.; Yoo, S.; Dai, Q.; Katsaggelos, A.K. Video super-resolution with convolutional neural networks. IEEE Trans. Comput. Imaging 2016, 2, 109–122. [Google Scholar] [CrossRef]
- Caballero, J.; Ledig, C.; Aitken, A.; Acosta, A.; Totz, J.; Wang, Z.; Shi, W. Real-time video super-resolution with spatio-temporal networks and motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4778–4787. [Google Scholar]
- Jo, Y.; Wug Oh, S.; Kang, J.; Joo Kim, S. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3224–3232. [Google Scholar]
- Kawulok, M.; Benecki, P.; Piechaczek, S.; Hrynczenko, K.; Kostrzewa, D.; Nalepa, J. Deep learning for multiple-image super-resolution. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1062–1066. [Google Scholar] [CrossRef]
- Kawulok, M.; Benecki, P.; Kostrzewa, D.; Skonieczny, L. Evolving imaging model for super-resolution reconstruction. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Koyoto, Japan, 15–19 July 2018; pp. 284–285. [Google Scholar]
- Molini, A.B.; Valsesia, D.; Fracastoro, G.; Magli, E. DeepSUM: Deep neural network for Super-resolution of Unregistered Multitemporal images. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3644–3656. [Google Scholar] [CrossRef] [Green Version]
- Deudon, M.; Kalaitzis, A.; Goytom, I.; Arefin, M.R.; Lin, Z.; Sankaran, K.; Michalski, V.; Kahou, S.E.; Cornebise, J.; Bengio, Y. HighRes-net: Recursive Fusion for Multi-Frame Super-Resolution of Satellite Imagery. arXiv 2020, arXiv:2002.06460. [Google Scholar]
- Van Noord, N.; Postma, E. A learned representation of artist-specific colourisation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 2907–2915. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1874–1883. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2599–2613. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Märtens, M.; Izzo, D.; Krzic, A.; Cox, D. Super-resolution of PROBA-V images using convolutional neural networks. Astrodynamics 2019, 3, 387–402. [Google Scholar] [CrossRef]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2016, 3, 47–57. [Google Scholar] [CrossRef]
- Padfield, D. Masked object registration in the Fourier domain. IEEE Trans. Image Process. 2011, 21, 2706–2718. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Timofte, R.; Rothe, R.; Van Gool, L. Seven ways to improve example-based single image super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1865–1873. [Google Scholar]
- Molini, A.B.; Valsesia, D.; Fracastoro, G.; Magli, E. DeepSUM++: Non-local Deep Neural Network for Super-Resolution of Unregistered Multitemporal Images. arXiv 2020, arXiv:2001.06342. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band | NIR | RED | ||
|---|---|---|---|---|
| Metric | cPSNR | cSSIM | cPSNR | cSSIM |
| Bicubic | 45.12 | 0.9767 | 47.63 | 0.9846 |
| IBP [13] | 45.96 | 0.9796 | 48.21 | 0.9865 |
| BTV [43] | 45.93 | 0.9794 | 48.12 | 0.9861 |
| RCAN [7] | 45.66 | 0.9798 | 48.22 | 0.9870 |
| VSR-DUF [47] | 47.20 | 0.9850 | 49.59 | 0.9902 |
| HighRes-net [51] | 47.55 | 0.9855 | 49.75 | 0.9904 |
| DeepSUM [50] | 47.84 | 0.9858 | 50.00 | 0.9908 |
| DeepSUM++ [64] | 47.93 | 0.9862 | 50.08 | 0.9912 |
| RAMS (ours) | 48.23 | 0.9875 | 50.17 | 0.9913 |
| RAMS+ (ours) | 48.51 | 0.9880 | 50.44 | 0.9917 |
| without RTA | with RTA | |||
|---|---|---|---|---|
| cPSNR | cSSIM | cPSNR | cSSIM | |
| NIR | 47.96 | 0.9869 | 48.23 | 0.9875 |
| RED | 47.98 * | 0.9863 * | 50.17 | 0.9913 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salvetti, F.; Mazzia, V.; Khaliq, A.; Chiaberge, M. Multi-Image Super Resolution of Remotely Sensed Images Using Residual Attention Deep Neural Networks. Remote Sens. 2020, 12, 2207. https://doi.org/10.3390/rs12142207
Salvetti F, Mazzia V, Khaliq A, Chiaberge M. Multi-Image Super Resolution of Remotely Sensed Images Using Residual Attention Deep Neural Networks. Remote Sensing. 2020; 12(14):2207. https://doi.org/10.3390/rs12142207
Chicago/Turabian StyleSalvetti, Francesco, Vittorio Mazzia, Aleem Khaliq, and Marcello Chiaberge. 2020. "Multi-Image Super Resolution of Remotely Sensed Images Using Residual Attention Deep Neural Networks" Remote Sensing 12, no. 14: 2207. https://doi.org/10.3390/rs12142207
APA StyleSalvetti, F., Mazzia, V., Khaliq, A., & Chiaberge, M. (2020). Multi-Image Super Resolution of Remotely Sensed Images Using Residual Attention Deep Neural Networks. Remote Sensing, 12(14), 2207. https://doi.org/10.3390/rs12142207