Improving Urban Land Cover/Use Mapping by Integrating A Hybrid Convolutional Neural Network and An Automatic Training Sample Expanding Strategy



Abstract
:
1. Introduction
2. Data and Methods
2.1. Study Area
2.2. Data Source and Preprocessing
2.3. Land Cover Categories
3. Methods
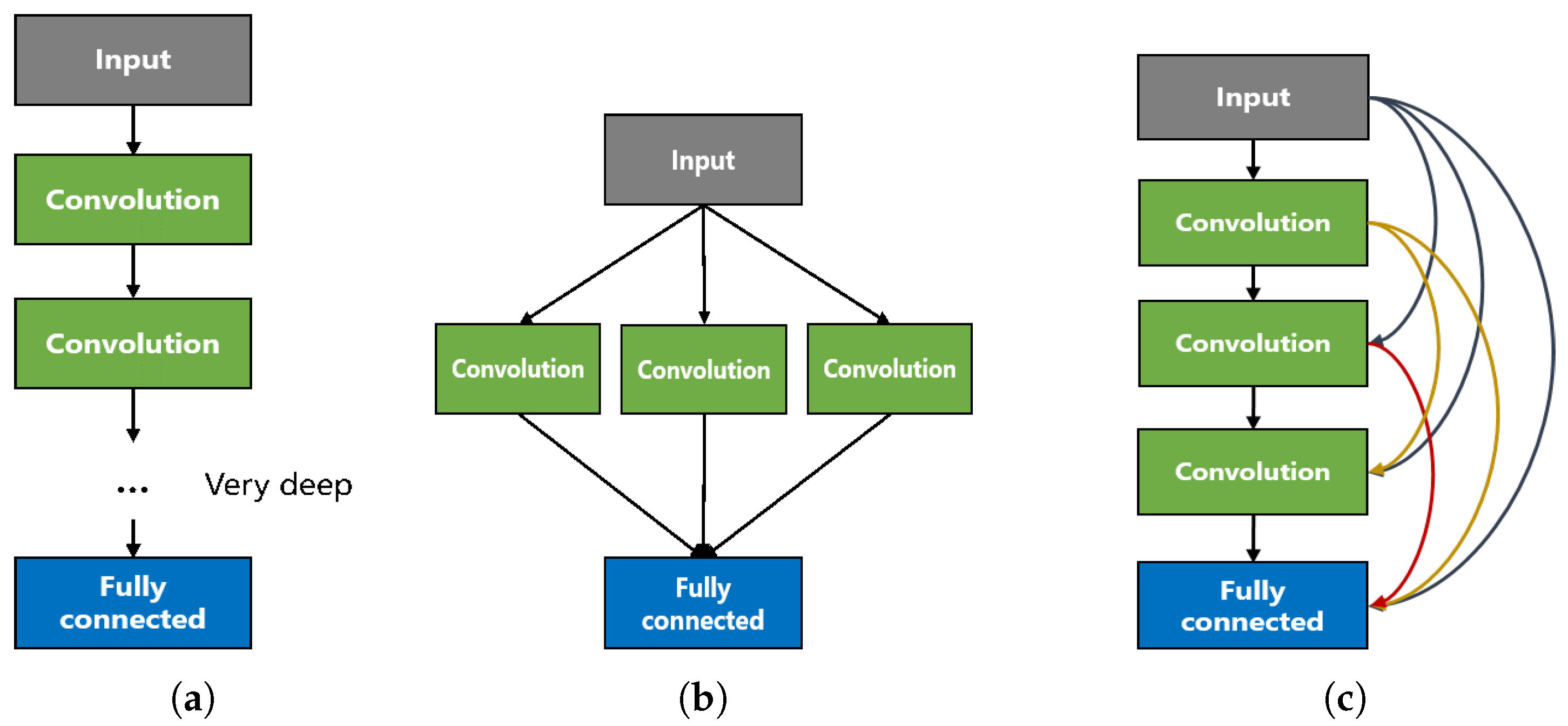
3.1. Architecture of H-ConvNet
3.1.1. 1d Convnet for Spectral Feature Learning
3.1.2. 2d Convnet for Context Feature Learning
3.2. Automatic Training Sample Expansion
3.3. Model Training and Classification
3.3.1. Model Training
3.3.2. Land Cover Category Determination
3.4. Methods Comparison
4. Results
4.1. H-ConvNet, 1D ConvNet and 2D ConvNet
4.2. H-Convnet Validation and Comparison
4.2.1. Classification in Terms of the Biophysical Composition and Land Use
4.2.2. Urban Land Cover Mapping with Additional Test Regions
5. Analysis and Discussion
5.1. The Improvement in the Convnet with the Expanded Sample Training
5.2. Applicability of Spectral/Context Feature-Based Urban Mapping
5.3. Comparison to Semantic Segmentation Models and Further Research
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Turner, B.L.; Lambin, E.F.; Reenberg, A. The emergence of land change science for global environmental change and sustainability. Proc. Natl. Acad. Sci. USA 2007, 104, 20666–20671. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, W.; Zhou, W.; Qian, Y.; Yan, J. A new approach for land cover classification and change analysis: Integrating backdating and an object-based method. Remote Sens. Environ. 2016, 177, 37–47. [Google Scholar] [CrossRef]
- Zhou, W.; Huang, G.; Troy, A.; Cadenasso, M. Object-based land cover classification of shaded areas in high spatial resolution imagery of urban areas: A comparison study. Remote Sens. Environ. 2009, 113, 1769–1777. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef] [Green Version]
- Momeni, R.; Aplin, P.; Boyd, D.S. Mapping complex urban land cover from spaceborne imagery: The influence of spatial resolution, spectral band set and classification approach. Remote Sens. 2016, 8, 88. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Huang, K.Y. A synergistic automatic clustering technique (SYNERACT) for multispectral image analysis. Photogramm. Eng. Remote. Sens. 2002, 68, 33–40. [Google Scholar]
- Strahler, A.H. The use of prior probabilities in maximum likelihood classification of remotely sensed data. Remote Sens. Environ. 1980, 10, 135–163. [Google Scholar] [CrossRef]
- Mas, J.F.; Flores, J.J. The application of artificial neural networks to the analysis of remotely sensed data. Int. J. Remote Sens. 2008, 29, 617–663. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Kraaijenbrink, P.; Shea, J.; Pellicciotti, F.; De Jong, S.; Immerzeel, W. Object-based analysis of unmanned aerial vehicle imagery to map and characterise surface features on a debris-covered glacier. Remote Sens. Environ. 2016, 186, 581–595. [Google Scholar] [CrossRef]
- Chen, Y.; Ge, Y.; Heuvelink, G.B.; An, R.; Chen, Y. Object-based superresolution land-cover mapping from remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 328–340. [Google Scholar] [CrossRef]
- Li, M.; Ma, L.; Blaschke, T.; Cheng, L.; Tiede, D. A systematic comparison of different object-based classification techniques using high spatial resolution imagery in agricultural environments. Int. J. Appl. Earth Obs. Geoinf. 2016, 49, 87–98. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, H.; Zhao, M.; Chu, D.; Li, Y. Integrating spectral and spatial features for hyperspectral image classification using low-rank representation. In Proceedings of the 2017 IEEE International Conference on Industrial Technology (ICIT), Toronto, ON, Canada, 22–25 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1024–1029. [Google Scholar]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Sharma, A.; Liu, X.; Yang, X.; Shi, D. A patch-based convolutional neural network for remote sensing image classification. Neural Netw. 2017, 95, 19–28. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Tsai, C.F. Bag-of-words representation in image annotation: A review. ISRN Artif. Intell. 2012, 2012. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.; Dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef] [Green Version]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Xu, X.; Li, W.; Ran, Q.; Du, Q.; Gao, L.; Zhang, B. Multisource remote sensing data classification based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 56, 937–949. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Li, Z.; Han, J.; Yao, X.; Guo, L. Exploring hierarchical convolutional features for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6712–6722. [Google Scholar] [CrossRef]
- Zhou, P.; Han, J.; Cheng, G.; Zhang, B. Learning compact and discriminative stacked autoencoder for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4823–4833. [Google Scholar] [CrossRef]
- Lin, L.; Chen, C.; Xu, T. Spatial-spectral hyperspectral image classification based on information measurement and CNN. Eurasip J. Wirel. Commun. Netw. 2020, 2020, 1–16. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Rouse, J.; Haas, R.; Schell, J.; Deering, D. Monitoring vegetation systems in the Great Plains with ERTS. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Bruch, S.; Wang, X.; Bendersky, M.; Najork, M. An analysis of the softmax cross entropy loss for learning-to-rank with binary relevance. In Proceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval, Santa Clara, CA, USA, 2–5 October 2019; pp. 75–78. [Google Scholar]
- Luo, H.; Wang, L.; Shao, Z.; Li, D. Development of a multi-scale object-based shadow detection method for high spatial resolution image. Remote Sens. Lett. 2015, 6, 59–68. [Google Scholar] [CrossRef]
- Zhang, H.; Fritts, J.E.; Goldman, S.A. Image segmentation evaluation: A survey of unsupervised methods. Comput. Vis. Image Underst. 2008, 110, 260–280. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.; Madden, M.; Warner, T. Estimation of optimal image object size for the segmentation of forest stands with multispectral IKONOS imagery. In Object-Based Image Analysis; Springer: Berlin/Heidelberg, Germany, 2008; pp. 291–307. [Google Scholar]
- Drăguţ, L.; Csillik, O.; Eisank, C.; Tiede, D. Automated parameterisation for multi-scale image segmentation on multiple layers. ISPRS J. Photogramm. Remote Sens. 2014, 88, 119–127. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, B.; Xie, Z. Unsupervised image segmentation evaluation and refinement using a multi-scale approach. ISPRS J. Photogramm. Remote Sens. 2011, 66, 473–483. [Google Scholar] [CrossRef]
- Wang, L.; Liu, J. Texture classification using multiresolution Markov random field models. Pattern Recognit. Lett. 1999, 20, 171–182. [Google Scholar] [CrossRef]
- Xia, J.; Chanussot, J.; Du, P.; He, X. Spectral–spatial classification for hyperspectral data using rotation forests with local feature extraction and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2532–2546. [Google Scholar] [CrossRef]
- Platt, J. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Adv. Large Margin Classif. 1999, 10, 61–74. [Google Scholar]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Liu, C.; Chen, L.C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Li, F.-F. Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 82–92. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Running Time | Overall Accuracy | ||||
|---|---|---|---|---|---|---|
| Initial Probability Threshold | Adaptive Probability Growth | Maximum Number | Initial Sample-Trained | Expanded Sample-Trained | ||
| Group 1 | 0.95 | 0.001 | 30,000 | 7 s | 70.96% | 77.58% |
| Group 2 | 0.9 | 0.0005 | 20,000 | 86 s | 77.29% | |
| Group 3 | 0.85 | 0.02 | 40,000 | 40 s | 78.59% | |
| Parameter | Maximum Ratio | None | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|---|
| Result | Sample ratios | 14:40:1:49 | 1:1:1:1 | 1:1.7:1:2 | 1:2.3:1:3 | 1:2.9:1:4 | 1:3.5:1:5 | 1:4:1:6 |
| Overall accuracy | 55.03% | 76.28% | 77.30% | 77.58% | 76.65% | 70.24% | 61.85% |
| 1D ConvNet | 2D ConvNet | H-ConvNet | |
|---|---|---|---|
| Average accuracy | 77.55% | 77.86% | 79.05% |
| Standard deviation of the accuracies | 1.11% | 1.34% | 0.92% |
| Time consumed | 86 s | 693 s | 800 s |
| Patch density (McGarigal et al., 2002) (Number per 100 hectares) | 102.8 | 38.24 | 52.23 |
| Common Semantic Segmentation Models | H-ConvNet | |
|---|---|---|
| Training conditions (sample quantity/sample design) | Large/patch based | Small/pixel based |
| Network architecture | 2-D architecture with deep layers | 3-D architecture with a lightweight design |
| Computing resource requirement | GPU acceleration is required | CPU configuration only |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, X.; Tong, X.; Hu, Z.; Wu, G. Improving Urban Land Cover/Use Mapping by Integrating A Hybrid Convolutional Neural Network and An Automatic Training Sample Expanding Strategy. Remote Sens. 2020, 12, 2292. https://doi.org/10.3390/rs12142292
Luo X, Tong X, Hu Z, Wu G. Improving Urban Land Cover/Use Mapping by Integrating A Hybrid Convolutional Neural Network and An Automatic Training Sample Expanding Strategy. Remote Sensing. 2020; 12(14):2292. https://doi.org/10.3390/rs12142292
Chicago/Turabian StyleLuo, Xin, Xiaohua Tong, Zhongwen Hu, and Guofeng Wu. 2020. "Improving Urban Land Cover/Use Mapping by Integrating A Hybrid Convolutional Neural Network and An Automatic Training Sample Expanding Strategy" Remote Sensing 12, no. 14: 2292. https://doi.org/10.3390/rs12142292