Multi-Scale Residual Deep Network for Semantic Segmentation of Buildings with Regularizer of Shape Representation



Abstract
:
1. Introduction
- (1)
- We first proposed an end-to-end residual deep U-Net with the regularizer of shape representation, which can capture morphological features of the buildings within the models to reduce over-fitting;
- (2)
- We first used two ways of multiple scales to improve the generalization in prediction: embedding of multi-scale modules through atrous spatial pyramid pooling (ASPP) in the models and ensemble learning of multi-scale models.
2. Deep Residual Segmentation Method with Shape Representation and Multi-Scaling
2.1. U-Net Architecture
2.2. Residual Learning
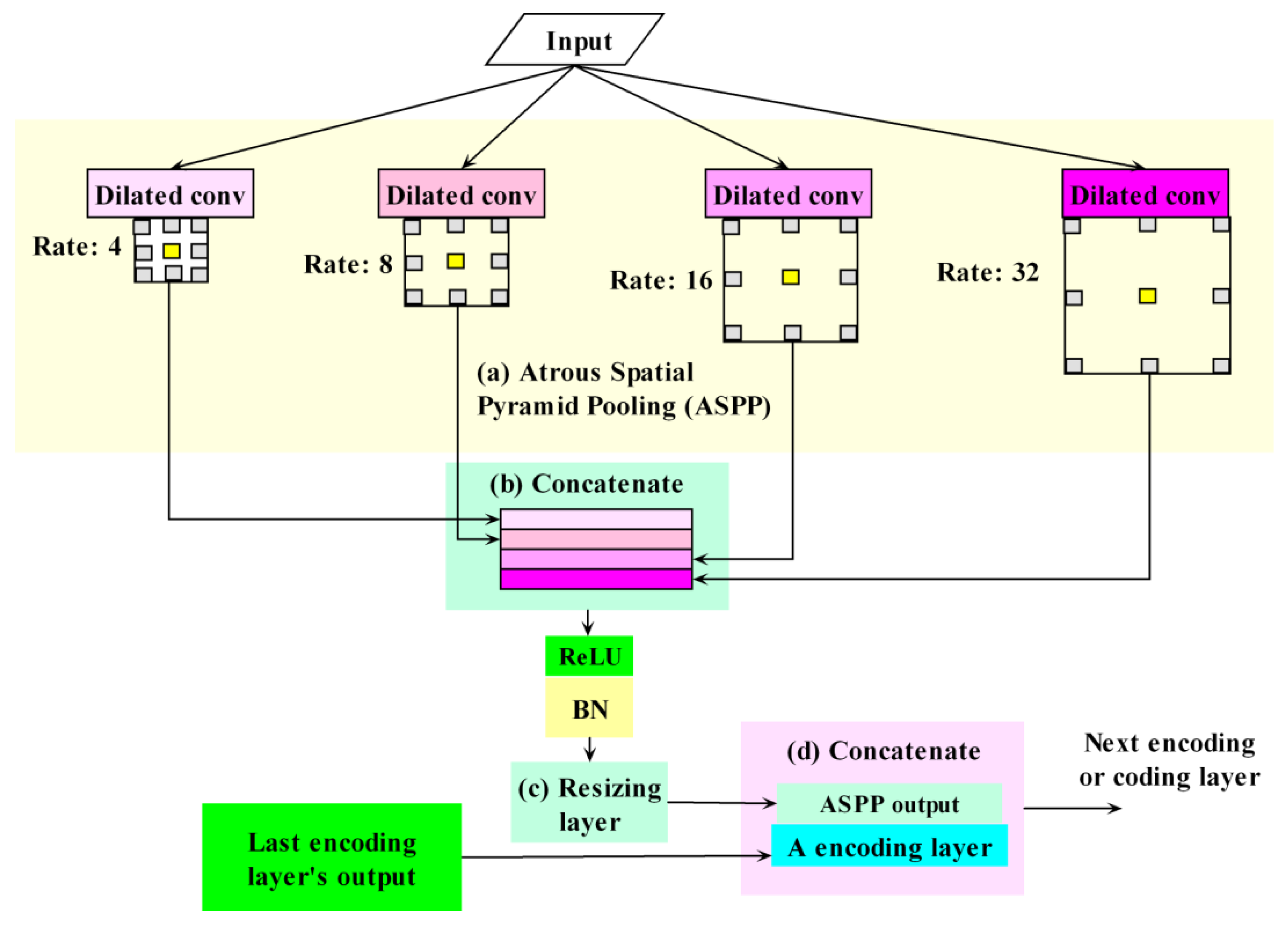
2.3. ASPP
2.4. Regularizer of the Shape Representation Autoencoder
2.5. Loss Function, Multi-Scale and Boundary Effects
3. Experimental Datasets and Evaluation
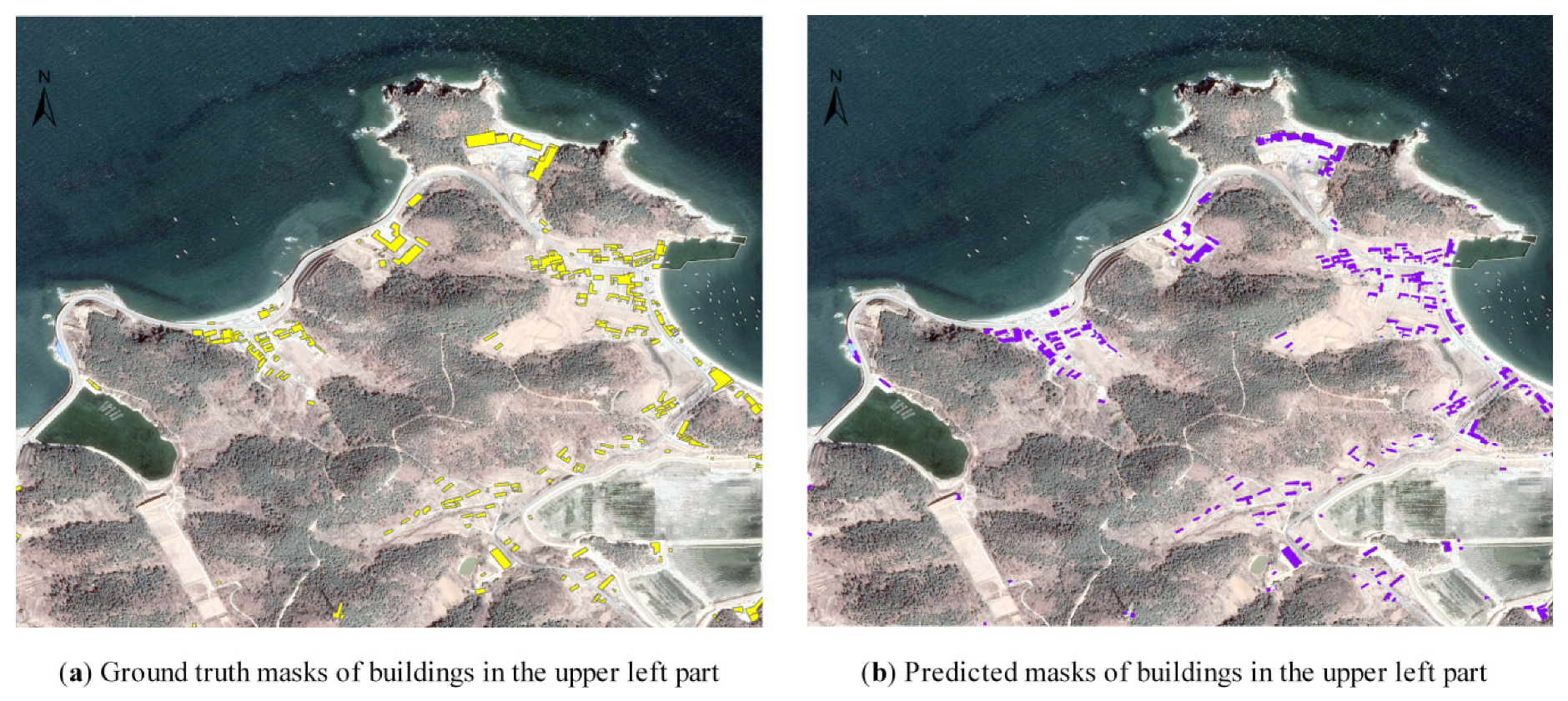
3.1. Study Region
3.2. Evaluation
- (1)
- The Kaggle dataset from the Defence Science and Technology Laboratory (DSTL) Satellite Imagery Feature Detection challenge in 2017 [48]. The dataset has high-resolution panchromatic images with a 31 cm resolution, 8–band (M–band) images with a 1.24 m resolution, and shortwave infrared (A–band) images with a 7.5 m resolution (all by the WorldView–3 satellite). Panchromatic sharpening [49] was performed to fuse high-res panchromatic images and low-res images to obtain 25 images with a 31 cm resolution. We extracted binary building labels from six class labels (buildings, crops, roads, trees, vehicles and background) for semantic segmentation of buildings.
- (2)
- The dataset of 20 multispectral ultra-high resolution images collected by the QuickBird satellite in Zurich, Switzerland in 2002 [50]. The spatial resolution of the pan-sharpened images was 0.61 m, with 4 channels, spanning the near infrared to visible spectrum (NIR–R–G–B). We extracted binary building labels from nine class labels (road, trees, bare soil, rail, buildings, grass, water, pools and background) for semantic segmentation of buildings.
- (3)
- The dataset of DroneDeploy Segmentation [51], including the aerial scenes captured from drones with a ground resolution of 10 cm in 2019. The images are RGB TIFFs and the labels are PNGs with 7 colors representing 7 classes (building, clutter, vegetation, water, ground, car and background). In total, we had 36 small images (spatial resolution: 256×256) for training, 130 small images for validation, and 130 small images for testing. Due to the small number of training samples for building labels, we trained the models to perform image segmentation on all the classes (including buildings) to evaluate our model.
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-task learning for segmentation of building footprints with deep neural networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1480–1484. [Google Scholar]
- Lin, X.; Zhang, J. Object-based morphological building index for building extractionfrom high resolution remote sensing imagery. Acta Geod. Cartogr. Sin. 2017, 46, 724–733. [Google Scholar]
- Yi, Y.N.; Zhang, Z.J.; Zhang, W.C.; Zhang, C.R.; Li, W.D.; Zhao, T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Qin, Q.; Ye, Q.; Wang, J.; Qin, X.; Yang, X. A Survey of Building Extraction Methods from Optical High Resolution Remote Sensing Imagery. Remote Sens. Technol. Appl. 2016, 31, 653–662. [Google Scholar]
- Akçay, H.G.; Aksoy, S. Automatic detection of geospatial objects using multiple hierarchical segmentations. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2097–2111. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.Q.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic object-based image analysis—towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [Green Version]
- Tian, H.; Yang, J.; Wang, Y.; Li, G. Towards Automatic Building Extraction: Variational Level Set Model Using Prior Shape Knowledge. Acta Autom. Sin. 2010, 36, 1502–1511. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. A multidirectional and multiscale morphological index for automatic building extraction from multispectral GeoEye-1 imagery. Photogramm. Eng. Remote Sens. 2011, 77, 721–732. [Google Scholar] [CrossRef]
- Pesaresi, M.; Gerhardinger, A.; Kayitakire, F. A robust built-up area presence index by anisotropic rotation-invariant textural measure. IEEE J. Select. Top. Appl. Earth Obser. Remote Sens. 2008, 1, 180–192. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. Morphological building/shadow index for building extraction from high-resolution imagery over urban areas. IEEE J. Select. Top. Appl. Earth Obser. Remote Sens. 2011, 5, 161–172. [Google Scholar] [CrossRef]
- Adams, R.; Bischof, L. Seeded region growing. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 641–647. [Google Scholar] [CrossRef] [Green Version]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef] [Green Version]
- Rother, C.; Kolmogorov, V.; Blake, A. Interactive foreground extraction using iterated graph cuts. ACM Trans. Gr. 2004, 23, 3. [Google Scholar]
- Aytekın, Ö.; Erener, A.; Ulusoy, İ.; Düzgün, Ş. Unsupervised building detection in complex urban environments from multispectral satellite imagery. Int. J. Remote Sens. 2012, 33, 2152–2177. [Google Scholar] [CrossRef]
- Das, S.; Mirnalinee, T.; Varghese, K. Use of salient features for the design of a multistage framework to extract roads from high-resolution multispectral satellite images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Song, M.; Civco, D. Road extraction using SVM and image segmentation. Photogramm. Eng. Remote Sens. 2004, 70, 1365–1371. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Song, H.; Zhang, Y. Spectral-spatial classification of hyperspectral images using joint bilateral filter and graph cut based model. Remote Sens. 2016, 8, 748. [Google Scholar] [CrossRef] [Green Version]
- Tian, S.; Zhang, X.; Tian, J.; Sun, Q. Random forest classification of wetland landcovers from multi-sensor data in the arid region of Xinjiang, China. Remote Sens. 2016, 8, 954. [Google Scholar] [CrossRef] [Green Version]
- Li, L.F. Deep Residual Autoencoder with Multiscaling for Semantic Segmentation of Land-Use Images. Remote Sens. 2019, 11, 2142. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zhang, L.P.; Zhang, L.F.; Du, B. Deep Learning for Remote Sensing Data A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.C.; Xia, G.S.; Zhang, L.P.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVRP), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Yu, H.S.; Yang, Z.G.; Tan, L.; Wang, Y.N.; Sun, W.; Sun, M.G.; Tang, Y.D. Methods and datasets on semantic segmentation: A review. Neurocomputing 2018, 304, 82–103. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:14127062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zuo, T. Research of Building Extraction Technology for High-Resolution Remote Sensing Images; University of Science and Technology of China: Hefei, China, 2017. (In Chinese) [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Mei, T.; Zhong, S. Application of Convolutional Neural Netowrk using region information to remote sensing image classification. Comput. Eng. Appl. 2018, 54, 188–195. [Google Scholar]
- Qin, Y.; Wu, Y.; Li, B.; Gao, S.; Liu, M.; Zhan, Y. Semantic Segmentation of Building Roof in Dense Urban Environment with Deep Convolutional Neural Network: A Case Study Using GF2 VHR Imagery in China. Sensors 2019, 19, 1164. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.; Li, Q.; Zhu, X.X. Building segmentation through a gated graph convolutional neural network with deep structured feature embedding. ISPRS J. Photogramm. 2020, 159, 184–197. [Google Scholar] [CrossRef]
- Ge, Y.; Jin, Y.; Stein, A.; Chen, Y.; Wang, J.; Wang, J.; Cheng, Q.; Bai, H.; Liu, M.; Atkinson, P.M. Principles and methods of scaling geospatial Earth science data. Earth Sci. Rev. 2019, 197, 102897. [Google Scholar] [CrossRef]
- Li, L.; Fang, Y.; Wu, J.; Wang, C.; Ge, Y. Encoder-Decoder Full Residual Deep Networks for Robust Regression and Spatiotemporal Estimation. IEEE Trans. Nerual Netw. Learn. Syst. 2020. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:170406857. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Identity Mappings in Deep Residual Networks. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9908, pp. 630–645. [Google Scholar]
- Wiki, Residual Neural Network. 2020. Available online: https://en.wikipedia.org/wiki/Residual_neural_network (accessed on 1 April 2020).
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:170605587. [Google Scholar]
- Sethi, A. One-Hot Encoding vs. Label Encoding using Scikit-Learn. 2020. Available online: https://www.analyticsvidhya.com/blog/2020/03/one-hot-encoding-vs-label-encoding-using-scikit-learn (accessed on 1 February 2020).
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Cui, W.; Wang, F.; He, X.; Zhang, D.; Xu, X.; Yao, M.; Wang, Z.; Huang, J. Multi-Scale Semantic Segmentation and Spatial Relationship Recognition of Remote Sensing Images Based on an Attention Model. Remote Sens. 2019, 11, 1044. [Google Scholar] [CrossRef] [Green Version]
- Iglovikov, V.; Mushinskiy, S.; Osin, V. Satellite imagery feature detection using deep convolutional neural network: A kaggle competition. arXiv 2017, arXiv:170606169. [Google Scholar]
- Dstl Satellite Imagery Feature Detection. Available online: https://www.kaggle.com/c/dstl-satellite-imagery-feature-detection (accessed on 10 January 2020).
- Padwick, C.; Deskevich, M.; Pacifici, F.; Smallwood, S. WorldView-2 pan-sharpening. In Proceedings of the American Society for Photogrammetry and Remote Sensing Annual Conference, San Diego, CA, USA, 26–30 April 2010. [Google Scholar]
- Volpi, M.; Ferrari, V. Semantic segmentation of urban scenes by learning local class interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Workshops. Looking from Above: When Earth Observation Meets Vision (EARTHVISION), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Aburas, M.M.; Ho, Y.M.; Ramli, M.F.; Ash’aari, Z.H. The simulation and prediction of spatio-temporal urban growth trends using cellular automata models: A review. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 380–389. [Google Scholar] [CrossRef]
- Tong, N.; Gou, S.; Yang, S.; Ruan, D.; Sheng, K. Fully automatic multi-organ segmentation for head and neck cancer radiotherapy using shape representation model constrained fully convolutional neural networks. Med. Phys. 2018, 45, 4558–4567. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-Scale Context Aggregation for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef] [Green Version]
- Lin, D.; Ji, Y.; Lischinski, D.; Cohen-Or, D.; Huang, H. Multi-scale context intertwining for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 603–619. [Google Scholar]
- Kaggle Team. Dstl Satellite Imagery Competition, 1st Place Winner’s Interview: Kyle Lee. 2018. Available online: https://medium.com/kaggle-blog/dstl-satellite-imagery-competition-1st-place-winners-interview-kyle-lee-6571ce640253 (accessed on 10 November 2019).
- Hoberg, T.; Rottensteiner, F.; Feitosa, R.Q.; Heipke, C. Conditional random fields for multitemporal and multiscale classification of optical satellite imagery. IEEE Trans. Geosci. Remote Sens. 2014, 53, 659–673. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
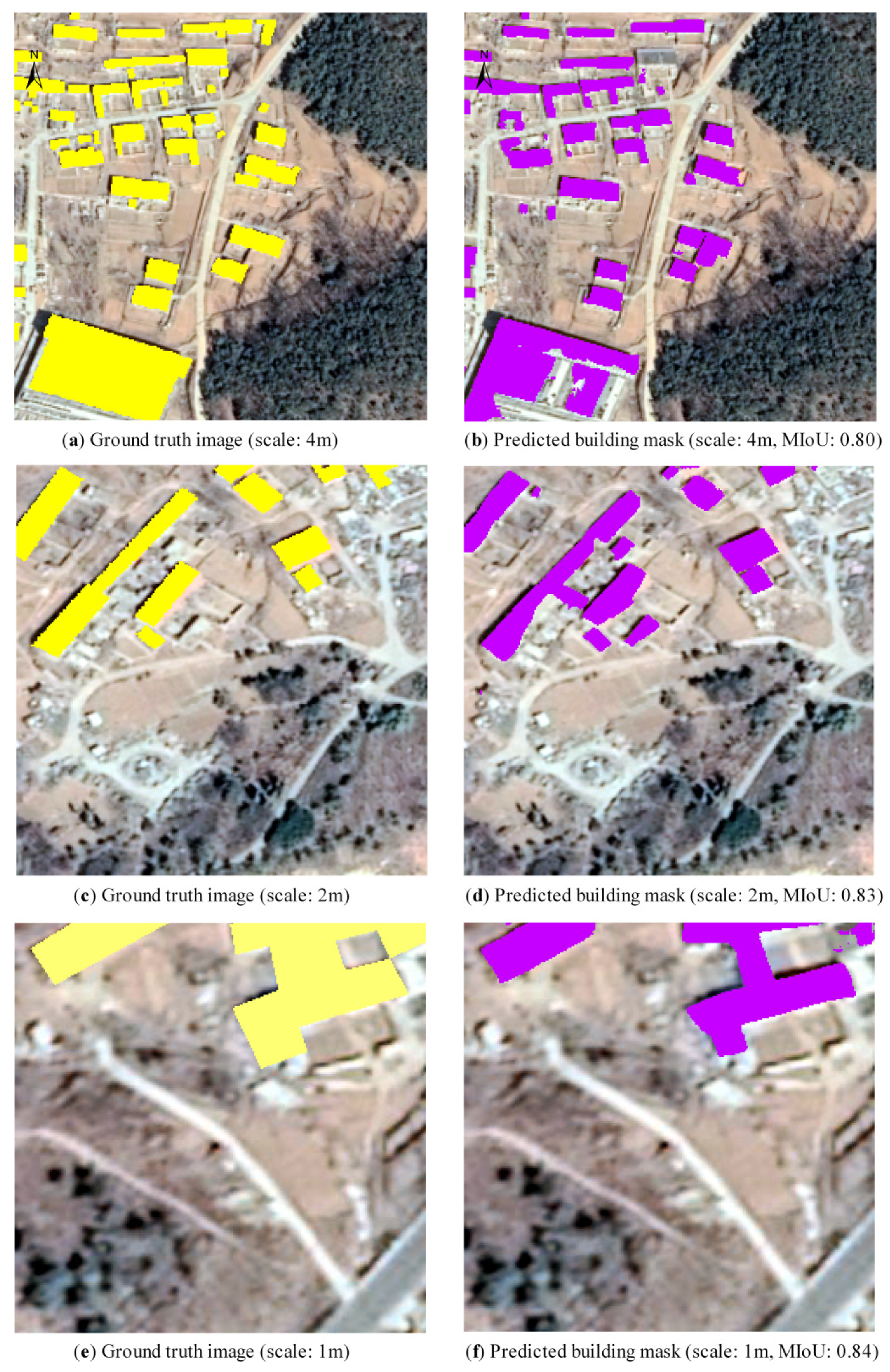
| Scale (Resolution) | Metric | Training | Validation | Testing | Independent Test |
|---|---|---|---|---|---|
| 4m | Number of Samples | 4595 | 1531 | 1531 | 2245 |
| PA | 0.99 | 0.99 | 0.99 | 0.99 | |
| JI | 0.92 | 0.92 | 0.91 | 0.86 | |
| MIoU | 0.94 | 0.93 | 0.93 | 0.82 | |
| 2m | Number of Samples | 7531 | 2510 | 2510 | 9464 |
| PA | 0.99 | 0.98 | 0.98 | 0.99 | |
| JI | 0.94 | 0.92 | 0.92 | 0.88 | |
| MIoU | 0.93 | 0.93 | 0.93 | 0.82 | |
| 1m | Number of Samples | 7540 | 2513 | 2513 | 43,708 |
| PA | 0.99 | 0.98 | 0.98 | 0.99 | |
| JI | 0.95 | 0.89 | 0.90 | 0.71 | |
| MIoU | 0.91 | 0.91 | 0.91 | 0.82 |
| Target Class, Sample Size, Model and Metrics | DSTL | Zurich | DroneDeploy | Dachangshan | |
|---|---|---|---|---|---|
| Target Class | Building | Building | All Classes b | Building | |
| Size of training samples | 2426 | 1932 | 36 | 4595 | |
| U-Net | MIoU | 0.72 | 0.86 | 0.41 | 0.77 |
| PA | 0.95 | 0.90 | 0.59 | 0.95 | |
| Recall | 0.69 | 0.90 | 0.65 | 0.79 | |
| Precision | 0.78 | 0.89 | 0.45 | 0.80 | |
| F-measure | 0.73 | 0.90 | 0.53 | 0.80 | |
| DeepLab V3+ | MIoU | 0.70 | 0.85 | 0.42 | 0.76 |
| PA | 0.93 | 0.92 | 0.64 | 0.88 | |
| Recall | 0.66 | 0.91 | 0.63 | 0.79 | |
| Precision | 0.75 | 0.92 | 0.64 | 0.73 | |
| F-measure | 0.70 | 0.92 | 0.63 | 0.75 | |
| Global CNN | MIoU | 0.77 | 0.92 | 0.39 | 0.82 |
| PA | 0.97 | 0.98 | 0.63 | 0.97 | |
| Recall | 0.72 | 0.96 | 0.75 | 0.86 | |
| Precision | 0.81 | 0.93 | 0.45 | 0.81 | |
| F-measure | 0.76 | 0.96 | 0.56 | 0.83 | |
| Residual Autoencoder a | MIoU | 0.75 | 0.89 | 0.50 | 0.80 |
| PA | 0.96 | 0.92 | 0.61 | 0.97 | |
| Recall | 0.69 | 0.95 | 0.81 | 0.83 | |
| Precision | 0.79 | 0.97 | 0.56 | 0.84 | |
| F-measure | 0.74 | 0.96 | 0.66 | 0.83 | |
| Residual multi-scale model with shape regularizer | MIoU | 0.79c | 0.91 | 0.51 | 0.83 |
| PA | 0.98 | 0.97 | 0.65 | 0.99 | |
| Recall | 0.73 | 0.95 | 0.86 | 0.87 | |
| Precision | 0.84 | 0.94 | 0.61 | 0.87 | |
| F-measure | 0.78 | 0.95 | 0.71 | 0.87 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Li, L. Multi-Scale Residual Deep Network for Semantic Segmentation of Buildings with Regularizer of Shape Representation. Remote Sens. 2020, 12, 2932. https://doi.org/10.3390/rs12182932
Wang C, Li L. Multi-Scale Residual Deep Network for Semantic Segmentation of Buildings with Regularizer of Shape Representation. Remote Sensing. 2020; 12(18):2932. https://doi.org/10.3390/rs12182932
Chicago/Turabian StyleWang, Chengyi, and Lianfa Li. 2020. "Multi-Scale Residual Deep Network for Semantic Segmentation of Buildings with Regularizer of Shape Representation" Remote Sensing 12, no. 18: 2932. https://doi.org/10.3390/rs12182932