LS-SSDD-v1.0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images



 ,
,  , ,
, ,  and
and
Abstract
1. Introduction
- (i)
- Large-scale background: Except AIR-SARShip-1.0, the other datasets did not consider large-scale practical engineering application of space-borne SAR. One possible reason is that small-size ship chips are beneficial to ship classification [7], but they contain fewer scattering information from land. Thus, models trained by ship chips will have trouble locating ships near highly-reflective objects in large-scale backgrounds [7]. Although images in AIR-SARShip-1.0 have a relatively large size (3000 × 3000 pixels), their coverage area is only about 9 km wide, which is still not consistent with the large-scale and wide-swath characteristics of space-borne SAR that often cover hundreds of kilometers, e.g., 240–400 km of Sentinel-1. In fact, ship detection in large-scale SAR images is closer to practical application in terms of global ship surveillance. Thus, we collect 15 large-scale SAR images with 250 km swath width to construct LS-SSDD-v1.0. See Section 4.1 for more details.
- (ii)
- Small ship detection: The existing datasets all consider multi-scale ship detection [13,17], so there are many ships with different sizes in their datasets. One possible reason is that multi-scale ship detection is an important research topic that is one of the important factors to evaluate detectors’ performance. Today, using these datasets, there have been many scholars who have achieved great success in multi-scale SAR ship detection [13,17]. However, small ship detection is an another important research topic that has received much attention by other scholars [19,24,66] because small target detection is still a challenging issue in the deep learning community (it should be noted that “small ship” in the deep learning community refers to occupying minor pixels in the whole image according to the definition of the Common Objects in COntext (COCO) dataset [74] instead of the actual physical size of the ship, which is also recognized by other scholars [19,24,66].). However, at present, there is still lack of deep learning datasets for SAR small ship detection, so to make up for such a vacancy, we collect large-scene SAR images with small ships to construct LS-SSDD-v1.0. Most importantly, ships in large-scene SAR images are always small, from the perspective of pixel proportion, so the small ship detection task is more in line with the practical engineering application of space-borne SAR. See Section 4.2 for more details.
- (iii)
- Abundant pure backgrounds: In the existing datasets, all image samples contain at least one ship, meaning that pure background image samples (i.e., no ships in images) are abandoned artificially. In fact, such practice is controversial in application, because (1) for one thing, human intervention practically destroyed the raw SAR image real property (i.e., there are indeed many sub-samples not containing ships in large-scale space-borne SAR images); and (2) for another thing, detection models may not be able to effectively learn features of pure backgrounds, causing more false alarms. Although models may learn partial backgrounds’ features from the difference between ship ground truths and ship backgrounds in the same SAR image, false alarms of brightened dots will still emerge in pure backgrounds, e.g., urban areas, agricultural regions, etc. Thus, we include all sub-images into LS-SSDD-v1.0, regardless of sub-images contain ships or not. See Section 4.3 for more details.
- (iv)
- Fully automatic detection flow: In previous studies [1,2,3,4,6,10,34], many scholars have trained detection models on the training set of open datasets and then tested models on the test set. Finally, they always verified the migration capability of models on other wide-region SAR images. However, their process of authenticating model migration capability is a lack of sufficient automation for the domain mismatch between datasets and practical wide-region images. Thus, artificial interference is incorporated to select ship candidate regions from the raw large-scale images, which is troublesome and insufficiently intelligent, but if using LS-SSDD-v1.0, one can directly evaluate models’ migration capability because we keep the original status of large-scale space-borne SAR images (i.e., the pure background samples without ships are not discarded manually and the ship candidate regions are not selected by human involvement.), and the final detection results can also be better presented by simple sub-image stitching without complex coordinate transformation or other post-processing means, so LS-SSDD-v1.0 can enable a fully automatic detection flow without any human involvement that is closer to the engineering applications of deep learning. See Section 4.4 for more details.
- (v)
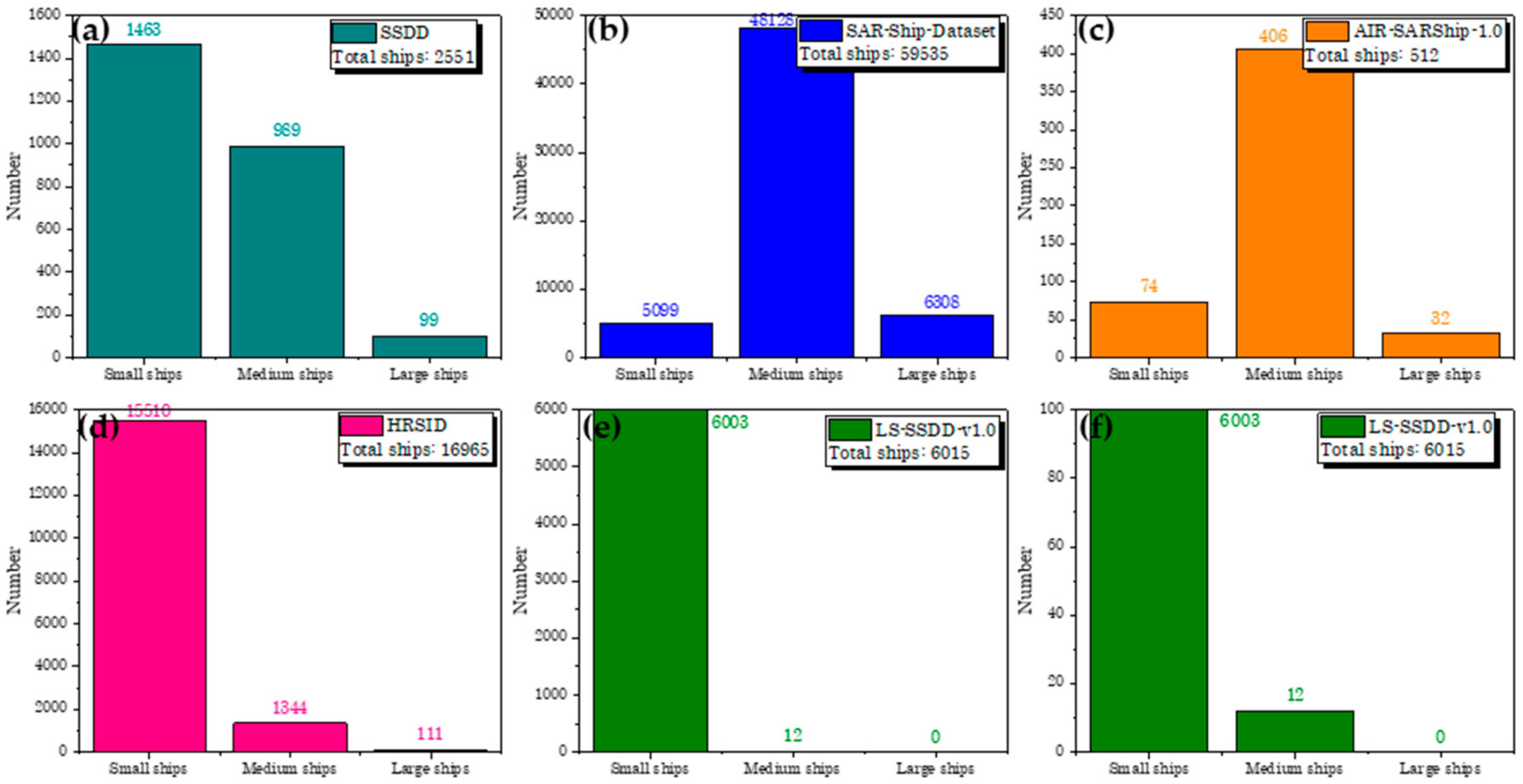
- Numerous and standardized research baselines: The existing datasets all provides research baselines (e.g., Faster R-CNN [75], SSD [76], RetinaNet [77], Cascade R-CNN [78], etc.), but (1) for one thing, the numbers of their provided baselines are all relatively a few that cannot facilitate adequate comparison for other scholars, i.e., two baselines for SSDD, six for SAR-Ship-Dataset, nine for AIR-SAR-Ship-1.0, and eight for HRSID; and (2) for another thing, they provided non-standardized baselines because these baselines are run under different deep learning frameworks, different training strategies, different image preprocessing means, different hyper-parameter configurations, different hardware environments, different programing languages, etc., bringing possible uncertainties in accuracy and speed. Although the research baselines of HRSID is standardized, they followed the COCO evaluation criteria [74], which is rarely used in the SAR ship detection community. Thus, we provide numerous and standardized research baselines with the PASCAL VOC evaluation criteria [79]: (1) 30 research baselines and (2) under the same detection framework, the same training strategies, the same image preprocessing means, almost the same hyper-parameter configuration, the same development environment, the same programing language, etc. See Section 4.5 for more details.
- LS-SSDD-v1.0 is the first open large-scale ship detection dataset, considering migration applications of space-borne SAR and also the first one for small ship detection, to our knowledge;
- LS-SSDD-v1.0 is provided with five advantages that can solve five defects of existing datasets.
2. Related Work
2.1. SSDD
2.2. SAR-Ship-Dataset
2.3. AIR-SARShip-1.0
2.4. HRSID
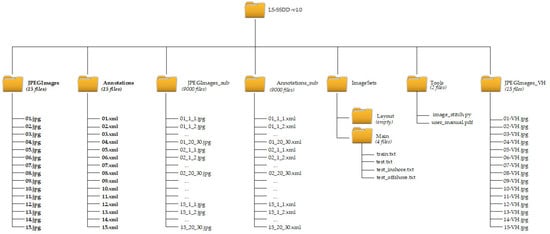
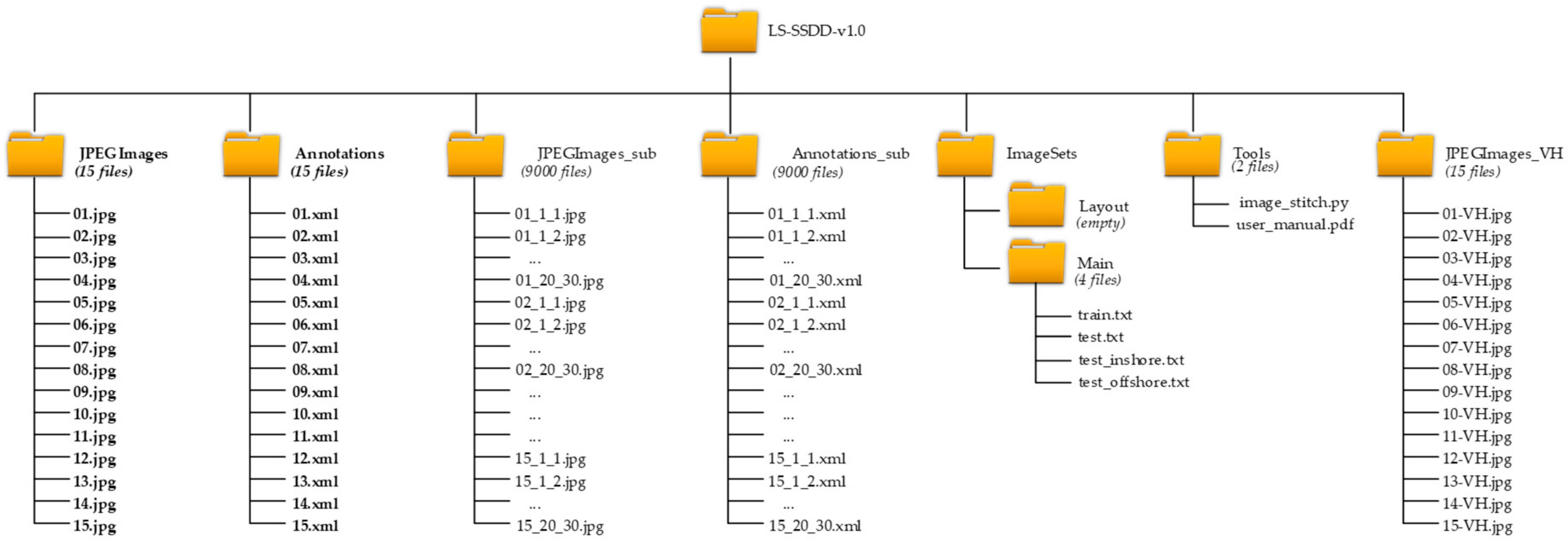
3. Establishment Process
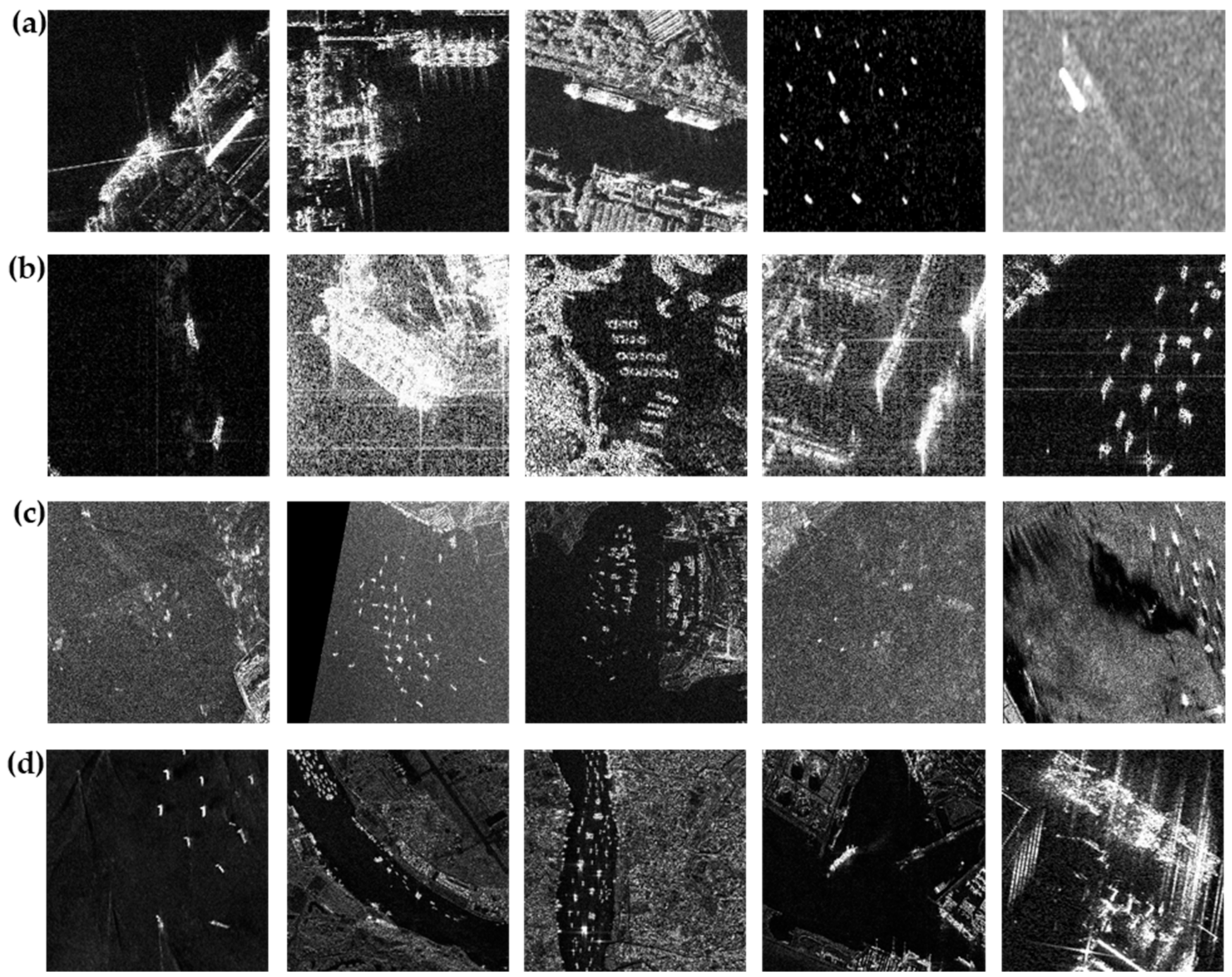
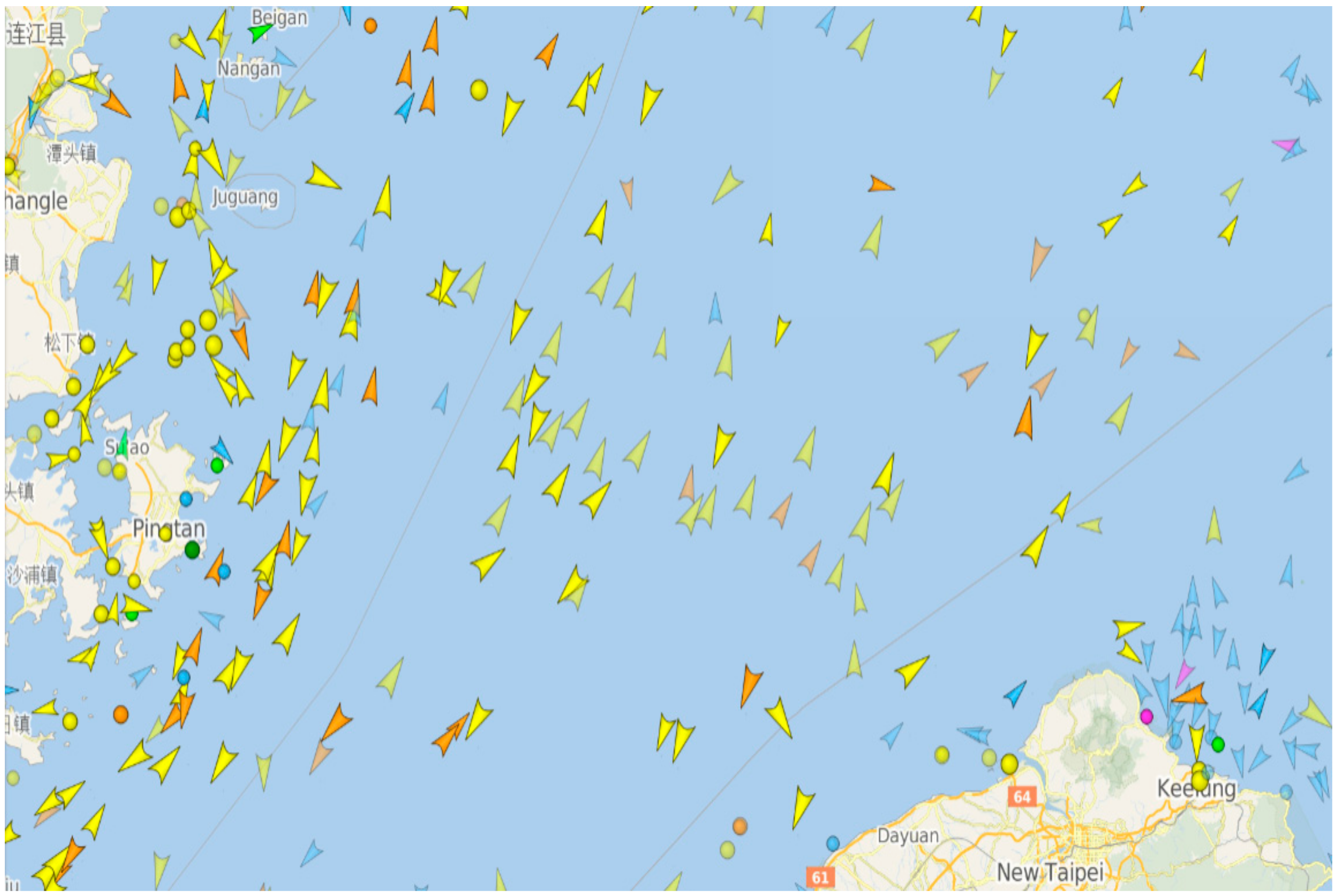
3.1. Step 1: Raw Data Acquisition
3.2. Step 2: Image Format Conversion
3.3. Step 3: Image Resizing
3.4. Step 4: Image Cutting
3.5. Step 5: AIS Support
3.6. Step 6: Expert Annotation
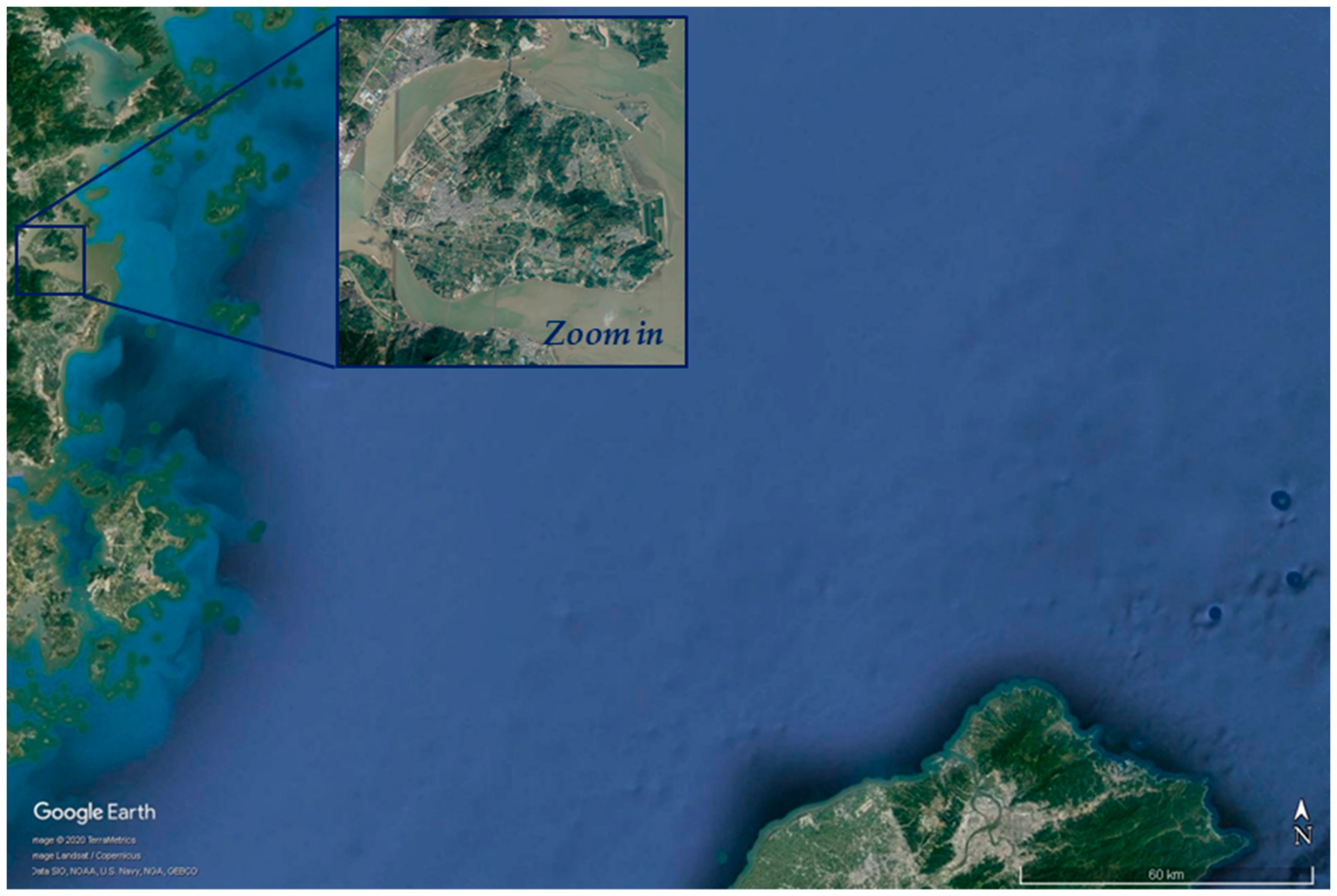
3.7. Step 7: Google Earth Correction
4. Advantages
4.1. Advantage 1: Large-Scale Backgrounds
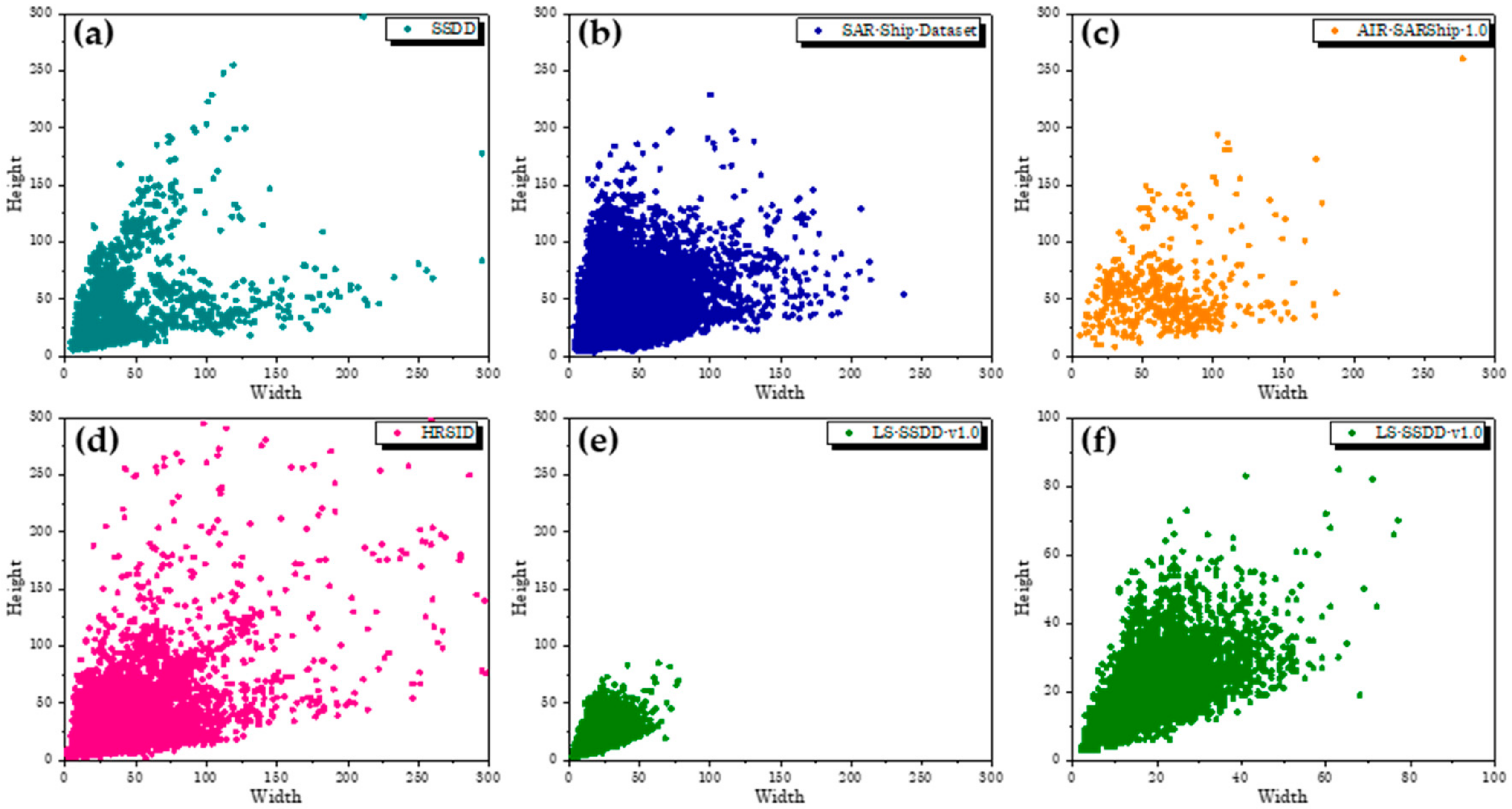
4.2. Advantage 2: Small Ship Detection
4.3. Advantage 3: Abundant Pure Backgrounds
4.4. Advantage 4: Fully Automatic Detection Flow
4.5. Advantage 5: Numerous and Standardized Research Baselines
- Standardized. In Table 8, the research baselines of LS-SSDD-v1.0 are run under the same detection framework (MMDetection with Pytorch), the same training strategies, the same image preprocessing method, almost the same hyper-parameter configuration (it is impossible for different models to have the same hyper-parameters, but we try to keep them basically the same), the same experimental environments, the same programing language (Python), etc. Moreover, HRSID provided standardized ones, but their detection accuracy evaluation indexes followed the evaluation protocol on COCO [74], which is scarcely used by other scholars. One possible reason is that the COCO evaluation protocol only can reflect the detection probability but not the false alarm probability, so many scholars generally abandon it. Thus, LS-SSDD-v1.0 uses the evaluation protocol on PASCAL VOC [79], i.e., Recall, Precision, mAP and F1 as accuracy criteria.
- Numerous. From Table 8, the number of research baselines of LS-SSDD-v1.0 is far more than other datasets, i.e., 30 of LS-SSDD-v1.0 >> 9 of AIR-SAR-Ship-1.0 > 8 of HRSID > 6 of SAR-Ship-Dataset > 2 of SSDD. Therefore, in the future, other scholars can make more research on the basis of these 30 research baselines.
5. Experiments
5.1. Experimental Details
5.2. Evaluation Indices
6. Results
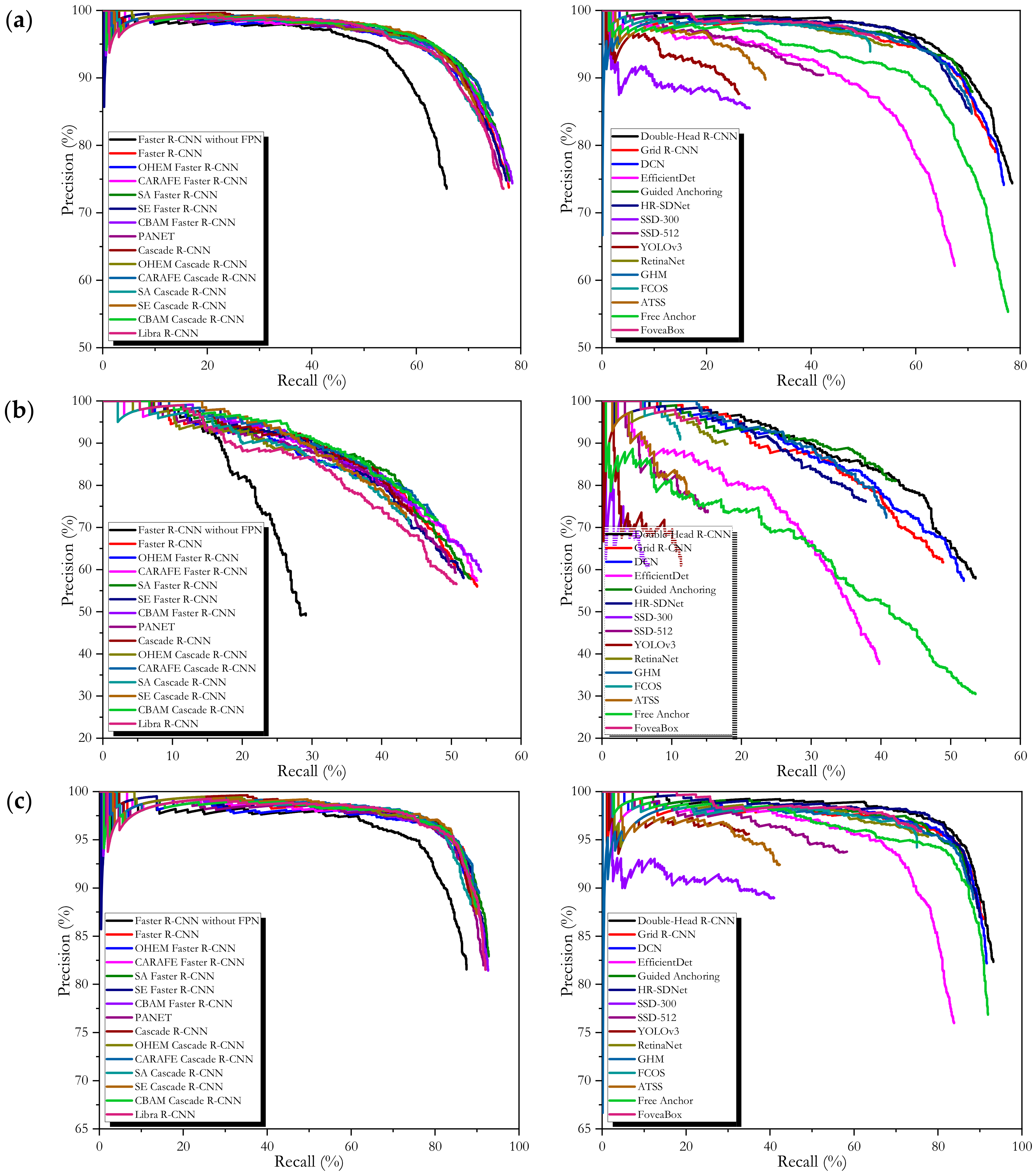
- If using mAP as the accuracy criteria, among the 30 detectors, the best on the entire scenes is 75.74% of double-head R-CNN, that on the inshore scenes is 47.70% of CBAM Faster R-CNN, and that on the offshore scenes is 91.34% of Double-Head R-CNN. If using F1 as the accuracy criteria, the best on the entire scenes is 0.79 of CARAFE Cascade R-CNN and CBAM Faster R-CNN, that on the inshore scenes is 0.59 of Faster R-CNN, and that on the offshore scenes is 0.90 of CARAFE Cascade R-CNN and CBAM Faster R-CNN. If using Pd as the accuracy criteria, the best on the entire scenes is 78.47% of Double-Head R-CNN, that on the inshore scenes is 54.25% of CBAM Faster R-CNN, and that on the offshore scenes is 93.18% of Double-Head R-CNN.
- There is a huge accuracy gap between the inshore scenes and the offshore ones, e.g., the inshore accuracy of Faster R-CNN is far inferior to the offshore one (46.76% mAP << 89.99% mAP and 0.59 F1 << 0.87 F1). This phenomenon is consistent with common sense, because ships in the inshore scenes are harder to detect than the offshore, due to the severe interference of land, harbor facilities, etc. Thus, one can use LS-SSDD-v1.0 to emphatically study the inshore ship detection.
- On the entire dataset, the optimal accuracies are 75.74% mAP of Double-Head R-CNN, 0.79 F1 of CARAFE Cascade R-CNN and CBAM Faster R-CNN, and 78.47% Pd of Double-Head R-CNN. Therefore, there is still a huge research space for future scholars. However, so far, the existing four datasets have almost reached a satisfactory accuracy (about 90% mAP), e.g., for SSDD, the existing open reports [1,2,4,5,6,15] have reached >95% mAP. Thus, related scholars may have resistance in driving the emergence of more excellent research results. In particular, it needs to be clarified that the accuracies on LS-SSDD-v1.0 are universally lower that on the other datasets if using same detectors. This phenomenon is because small ship detection in large-scale space-borne SAR images is a challenging task, instead of the problem from our annotation process. In fact, the seven steps in Section 3 has been able to guarantee the authenticity of dataset annotation. In short, LS-SSDD-v1.0 can promote a new round of SAR ship detection research upsurge.
- Last but not least, to facilitate the understanding of these 30 research baselines, we make a general analysis of them. (1) Faster R-CNN with FPN has a better accuracy than Faster R-CNN without FPN because FPN can improve detection performance of ships with different sizes. (2) OHEM Faster R-CNN has a worse accuracy than Faster R-CNN because OHEM can suppress false alarms but miss-detect many ships. (3) CARAFE Faster R-CNN has a similar accuracy to Faster R-CNN; probably, its up-sampling module is insensitive to small ships. (4) SA Faster R-CNN has a better accuracy than Faster R-CNN because space attention can capture more valuable information. (5) SE Faster R-CNN has a similar accuracy to Faster R-CNN; probably, its squeeze and excitation mechanism cannot respond small ships. (6) CBAM Faster R-CNN has a better accuracy than Faster R-CNN because its spatial and channel attention can promote information flow. (7) PANET has a worse accuracy than Faster R-CNN, probably its pyramid network losses much information of small ships due to excessive feature integration. (8) Cascade R-CNN has a worse accuracy than Faster R-CNN because its cascaded IOU threshold mechanism can improve the quality of boxes but miss-detect other ships. (9) Cascade R-CNN with other improvements have a similar change rule to Faster R-CNN with these improvements (10) Libra R-CNN has a worse accuracy than Faster R-CNN; probably, it has resistance in solving lots of negative samples leading to learning imbalance. (11) Double-Head R-CNN has a best accuracy because it has strong performance to distinguish ships and backgrounds, from its double head for classification and location. (12) Grid R-CNN has a worse accuracy than Faster R-CNN because its grid mechanism on the RPN network may not capture useful features from rather small ships. (13) DCN has a worse accuracy than Faster R-CNN because its deformed convolution kernel only captures larger receptive field that may miss small ships with small receptive field. (14) EfficientDet has a worse accuracy than Faster RCNN even Faster R-CNN without FPN, and one possible reason is that its pyramid network overemphasizes multi-scale information and leads to information loss of small ships. (15) Guided Anchoring has a worse accuracy than Faster R-CNN, probably because its anchor guidance mechanism can generate good suggestions of small ships. (16) HR-SDNet has a modest accuracy because its high-resolution backbone networks may not capture useful features of small ships which is not suitable low-resolution small ships. (17) SSD-300 and YOLOv3 have the worst accuracy than others, because they are not good at small ships. (18) SSD-512 has a better accuracy than SSD-300 because its input image size is bigger than SSD-300, so it can obtain more image information. (19) RetinaNet has a better accuracy than SSD-300, SSD-512, and YOLOv3 because its focal loss can address the imbalance between positive samples and negative ones. (20) GHM has a better accuracy than RetinaNet because its gradient harmonizing mechanism seems to be a hedging for the disharmonies. (21) FCOS has a worse accuracy than RetinaNet, and a possible reason is that its object detection in a per-pixel prediction fashion may be able to solve the low-solution SAR images. (22) ATSS has a bad accuracy, probably coming from its oscillation of loss function due to too much negative samples. (23) FreeAnchor has a better accuracy than other one-stage detectors because its anchor matching mechanism is similar to two-stage detectors. (24) FoveaBox has a modest accuracy but lower than RetinaNet because it directly learns the object existing possibility and the bounding box coordinates without anchor reference [118]. (25) Finally, the two-stage detectors (from No. 1 to No. 21) generally have better detection performance than one-stage ones (from No. 22 to No. 30) because two-stage detectors can achieve better region proposals.
7. Discussions
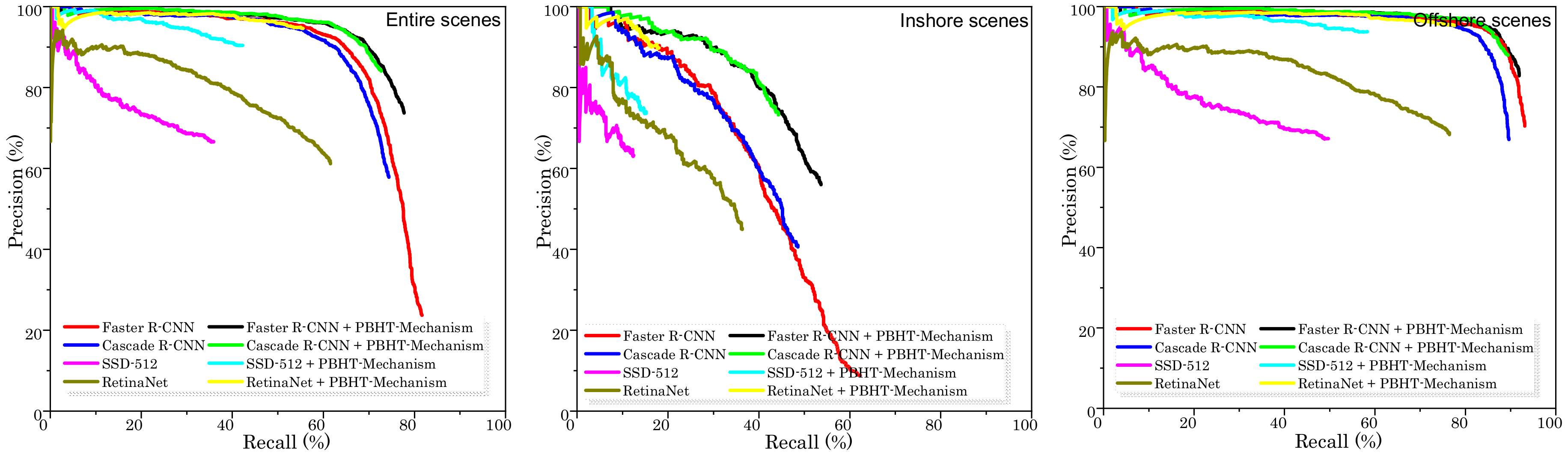
- PBHT-mechanism can effectively suppress the false alarm probability Pf, i.e., (1) on the entire scenes, 26.26% Pf of Faster R-CNN with PBHT-mechanism << 76.27% Pf of Faster R-CNN without PBHT-Mechanism, 15.91% Pf of Cascade R-CNN with PBHT-mechanism << 42.15% Pf of Cascade R-CNN without PBHT-mechanism, 9.53% Pf of SSD-512 with PBHT-mechanism << 33.41% Pf of SSD-512 without PBHT-mechanism, and 5.38% Pf of RetinaNet with PBHT-mechanism << 38.80% Pf of RetinaNet without PBHT-mechanism; (2) on the inshore scenes, 44.04% Pf of Faster R-CNN with PBHT-mechanism << 91.13% Pf of Faster R-CNN without PBHT-mechanism, 26.78% Pf of Cascade R-CNN with PBHT-mechanism << 59.38% Pf of Cascade R-CNN without PBHT-mechanism, 26.37% Pf of SSD-512 with PBHT-mechanism << 36.78% Pf of SSD-512 without PBHT-mechanism and 10.17% Pf of RetinaNet with PBHT-mechanism << 55.04% Pf of RetinaNet without PBHT-mechanism; (3) on the offshore scenes, 17.18% Pf of Faster R-CNN with PBHT-mechanism << 29.73% Pf of Faster R-CNN without PBHT-mechanism, 12.10% Pf of Cascade R-CNN with PBHT-mechanism << 33.07% Pf of Cascade R-CNN without PBHT-mechanism, 6.24% Pf of SSD-512 with PBHT-mechanism << 32.88% Pf of SSD-512 without PBHT-mechanism, and 4.68% Pf of RetinaNet with PBHT-mechanism << 31.88% Pf of RetinaNet without PBHT-mechanism.
- If using PBHT-mechanism, the detection probability Pd has a slight drop for some detectors. We hold the view that it is worth sacrificing a slight detection probability for a huge false alarm probability reduction, because the final good balance between Pf and Pd can be achieved. In other words, finally, mAP and F1, which simultaneously consider Pf and Pd, are obviously improved.
8. Conclusions
- We will update LS-SSDD-v1.0 into v2.0 or higher, e.g., expanding the sample number, adding more typical scenarios, providing preferable research baselines, etc., in the future.
- We will study more SAR ship detection methods based on LS-SSDD-v1.0, e.g., further improving the accuracy of the state-of-the-art, further enhancing the accuracy of inshore ships, etc.
- We will combine deep learning abstract features and traditional concrete ones to further improve accuracy (e.g., Ai et al. [125]). So far, most scholars in this SAR ship detection community still scarcely focus on much information of SAR images and ship identification, when they applied those object detectors in the deep learning filed to this SAR ship detection field.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. HyperLi-Net: A hyper-light deep learning network for high-accurate and high-speed ship detection from synthetic aperture radar imagery. ISPRS J. Photogramm. Remote Sens. 2020, 167, 123–153. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. ShipDeNet-20: An only 20 convolution layers and <1-MB lightweight SAR ship detector. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. High-speed ship detection in SAR images based on a grid convolutional neural network. Remote Sens. 2019, 10, 1206. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Depthwise separable convolution neural network for high-speed SAR ship detection. Remote Sens. 2019, 11, 2483. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, T.; Shi, J.; Wei, S. High-speed and high-accurate SAR ship detection based on a depthwise separable convolution neural network. J. Radars 2019, 8, 841–851. [Google Scholar]
- Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and robust ship detection for high-resolution SAR imagery based on HR-SDNet. Remote Sens. 2020, 12, 167. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Chang, Y.-L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.-Y.; Lee, W.-H. Ship detection based on YOLOv2 for SAR imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef]
- Pelich, R.; Chini, M.; Hostache, R.; Matgen, P.; Lopez-Martinez, C.; Nuevo, M.; Ries, P.; Eiden, G. Large-scale automatic vessel monitoring based on dual-polarization Sentinel-1 and AIS data. Remote Sens. 2019, 11, 1078. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR dataset of ship detection for deep learning under complex backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, J.; Zhan, R. R2FA-Det: Delving into high-quality rotatable boxes for ship detection in SAR images. Remote Sens. 2020, 12, 2031. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved Faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Cui, Z.; Wang, X.; Liu, N.; Cao, Z.; Yang, J. Ship detection in large-scale SAR images via spatial shuffle-group enhance attention. IEEE Trans. Geosci. Remote Sens. 2020. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention receptive pyramid network for ship detection in SAR images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank Faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 751–755. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J. Learning deep ship detector in SAR images from scratch. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4021–4039. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, W.; Zhang, Z.; Yu, W. A coupled convolutional neural network for small and densely clustered ship detection in SAR images. Sci. China Inf. Sci. 2018, 62, 42301. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, Z.; Yu, W.; Truong, T.-K. A cascade coupled convolutional neural network guided visual attention method for ship detection from SAR images. IEEE Access 2018, 6, 50693–50708. [Google Scholar] [CrossRef]
- Jiao, J.; Zhang, Y.; Sun, H.; Yang, X.; Gao, X.; Hong, W.; Fu, K.; Sun, X. A densely connected end-to-end neural network for multiscale and multiscene SAR ship detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Sun, X.; Wang, Z.; Sun, Y.; Diao, W.; Zhang, Y.; Fu, K. AIR-SARShip-1.0: High-resolution SAR ship detection dataset. J. Radars 2019, 8, 852–862. [Google Scholar]
- Fan, W.; Zhou, F.; Bai, X.; Tao, M.; Tian, T. Ship detection using deep convolutional neural networks for PolSAR images. Remote Sens. 2019, 11, 2862. [Google Scholar] [CrossRef]
- Jin, K.; Chen, Y.; Xu, B.; Yin, J.; Wang, X.; Yang, J. A patch-to-pixel convolutional neural network for small ship detection with PolSAR Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6623–6638. [Google Scholar] [CrossRef]
- Song, J.; Kim, D.-J.; Kang, K.-M. Automated procurement of training data for machine learning algorithm on ship detection using AIS information. Remote Sens. 2020, 12, 1443. [Google Scholar] [CrossRef]
- Gao, F.; Shi, W.; Wang, J.; Yang, E.; Zhou, H. Enhanced feature extraction for ship detection from multi-resolution and multi-scene synthetic aperture radar (SAR) images. Remote Sens. 2019, 11, 2694. [Google Scholar] [CrossRef]
- Gao, F.; Shi, W.; Wang, J.; Hussain, A.; Zhou, H. Anchor-free Convolutional Network with Dense Attention Feature Aggregation for Ship Detection in SAR Images. Remote Sens. 2020, 12, 2619. [Google Scholar] [CrossRef]
- An, Q.; Pan, Z.; You, H. Ship detection in Gaofen-3 SAR images based on sea clutter distribution analysis and deep convolutional neural network. Sensors 2018, 18, 334. [Google Scholar] [CrossRef]
- An, Q.; Pan, Z.; Liu, L.; You, H. DRBox-v2: An improved detector with rotatable boxes for target detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8333–8349. [Google Scholar] [CrossRef]
- Yang, R.; Wang, G.; Pan, Z.; Lu, H.; Zhang, H.; Jia, X. A novel false alarm suppression method for CNN-based SAR ship detector. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Chen, C.; He, C.; Hu, C.; Pei, H.; Jiao, L. MSARN: A deep neural network based on an adaptive recalibration mechanism for multiscale and arbitrary-oriented SAR ship detection. IEEE Access 2019, 7, 159262–159283. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, H.; Xu, C.; Lv, Y.; Fu, C.; Xiao, H.; He, Y. A lightweight feature optimizing network for ship detection in SAR image. IEEE Access 2019, 7, 141662–141678. [Google Scholar] [CrossRef]
- Fan, Q.; Chen, F.; Cheng, M.; Lou, S.; Xiao, R.; Zhang, B.; Wang, C.; Li, J. Ship detection using a fully convolutional network with compact polarimetric SAR images. Remote Sens. 2019, 11, 2171. [Google Scholar] [CrossRef]
- Mao, Y.; Yang, Y.; Ma, Z.; Li, M.; Su, H.; Zhang, J. Efficient low-cost ship detection for SAR imagery based on simplified U-Net. IEEE Access 2020, 8, 69742–69753. [Google Scholar] [CrossRef]
- Fu, J.; Sun, X.; Wang, Z.; Fu, K. An anchor-free method based on feature balancing and refinement network for multiscale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2020. [Google Scholar] [CrossRef]
- Eldhuset, K. An automatic ship and ship wake detection system for space-borne SAR images in coastal regions. IEEE Trans. Geosci. Remote Sens. 1996, 34, 1010–1019. [Google Scholar] [CrossRef]
- Lin, I.I.; Keong, K.L.; Yuan-Chung, L.; Khoo, V. Ship and ship wake detection in the ERS SAR imagery using computer-based algorithm. In Proceedings of the 1997 IEEE International Geoscience and Remote Sensing Symposium Proceedings. Remote Sensing—A Scientific Vision for Sustainable Development, Singapore, 3–8 August 1997; pp. 151–153. [Google Scholar]
- Renga, A.; Graziano, M.D.; Moccia, A. Segmentation of marine SAR images by sublook analysis and application to sea traffic monitoring. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1463–1477. [Google Scholar] [CrossRef]
- Ai, J.; Qi, X.; Yu, W.; Deng, Y.; Liu, F.; Shi, L. A new CFAR ship detection algorithm based on 2-D joint log-normal distribution in SAR images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 806–810. [Google Scholar] [CrossRef]
- Ai, J.; Yang, X.; Song, J.; Dong, Z.; Jia, L.; Zhou, F. An adaptively truncated clutter-statistics-based two-parameter CFAR detector in SAR imagery. IEEE J. Ocean. Eng. 2018, 43, 267–279. [Google Scholar] [CrossRef]
- Ai, J.; Luo, Q.; Yang, X.; Yin, Z.; Xu, H. Outliers-robust CFAR detector of gaussian clutter based on the truncated-maximum-likelihood-estimator in SAR imagery. IEEE Trans. Intell. Transp. Syst. 2020, 21, 2039–2049. [Google Scholar] [CrossRef]
- Brizi, M.; Lombardo, P.; Pastina, D. Exploiting the shadow information to increase the target detection performance in SAR images. In Proceedings of the 5th international conference and exhibition on radar systems, Brest, France, 17–21 May 1999. [Google Scholar]
- Iervolino, P.; Guida, R. A novel ship detector based on the generalized-likelihood ratio test for SAR imagery. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2017, 10, 3616–3630. [Google Scholar] [CrossRef]
- Sciotti, M.; Pastina, D.; Lombardo, P. Exploiting the polarimetric information for the detection of ship targets in non-homogeneous SAR images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Toronto, ON, Canada, 24–28 June 2002; pp. 1911–1913. [Google Scholar]
- Tello, M.; Lopez-Martinez, C.; Mallorqui, J.J. A novel algorithm for ship detection in SAR imagery based on the wavelet transform. IEEE Geosci. Remote Sens. Lett. 2005, 2, 201–205. [Google Scholar] [CrossRef]
- Schwegmann, C.P.; Kleynhans, W.; Salmon, B.P. Synthetic aperture radar ship detection using Haar-like features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 154–158. [Google Scholar] [CrossRef]
- Marino, A.; Sanjuan-Ferrer, M.J.; Hajnsek, I.; Ouchi, K. Ship detection with spectral analysis of synthetic aperture radar: A comparison of new and well-known algorithms. Remote Sens. 2015, 7, 5416–5439. [Google Scholar] [CrossRef]
- Xie, T.; Zhang, W.; Yang, L.; Wang, Q.; Huang, J.; Yuan, N. Inshore ship detection based on level set method and visual saliency for SAR images. Sensors 2018, 18, 3877. [Google Scholar] [CrossRef] [PubMed]
- Zhai, L.; Li, Y.; Su, Y. Inshore ship detection via saliency and context information in high-resolution SAR Images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1870–1874. [Google Scholar] [CrossRef]
- Cui, X.; Su, Y.; Chen, S. A saliency detector for polarimetric SAR ship detection using similarity test. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 3423–3433. [Google Scholar] [CrossRef]
- Wang, X.; Li, G.; Zhang, X.P.; He, Y. Ship detection in SAR images via local contrast of fisher vectors. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6467–6479. [Google Scholar] [CrossRef]
- Wang, X.; Chen, C.; Pan, Z.; Pan, Z. Superpixel-based LCM detector for faint ships hidden in strong noise background SAR imagery. IEEE Geosci. Remote Sens. Lett. 2019, 16, 417–421. [Google Scholar] [CrossRef]
- Lin, H.; Chen, H.; Jin, K.; Zeng, L.; Yang, J. Ship detection with superpixel-level fisher vector in high-resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2020, 17, 247–251. [Google Scholar] [CrossRef]
- Tings, B.; Pleskachevsky, A.; Velotto, D.; Jacobsen, S. Extension of ship wake detectability model for non-linear influences of parameters using satellite-based X-band synthetic aperture radar. Remote Sens. 2019, 11, 563. [Google Scholar] [CrossRef]
- Biondi, F. A polarimetric extension of low-rank plus sparse decomposition and radon transform for ship wake detection in synthetic aperture radar images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 75–79. [Google Scholar] [CrossRef]
- Karakuş, O.; Rizaev, I.; Achim, A. Ship Wake Detection in SAR Images via Sparse Regularization. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1665–1677. [Google Scholar] [CrossRef]
- Cao, C.; Zhang, J.; Meng, J.; Zhang, X.; Mao, X. Analysis of ship detection performance with full-, compact- and dual-polarimetric SAR. Remote Sens. 2019, 11, 18. [Google Scholar] [CrossRef]
- Hwang, J.-I.; Jung, H.-S. Automatic Ship detection using the artificial neural network and support vector machine from X-band SAR satellite images. Remote Sens. 2018, 10, 1799. [Google Scholar] [CrossRef]
- Guo, R.; Cui, J.; Jing, G.; Zhang, S.; Xing, M. Validating GEV model for reflection symmetry-based ocean ship detection with Gaofen-3 dual-polarimetric data. Remote Sens. 2020, 12, 1148. [Google Scholar] [CrossRef]
- Liang, Y.; Sun, K.; Zeng, Y.; Li, G.; Xing, M. An adaptive hierarchical detection method for ship targets in high-resolution SAR images. Remote Sens. 2020, 12, 303. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, T.; Lei, P.; Bai, X. A hierarchical convolution neural network (CNN)-based ship target detection method in space-borne SAR imagery. Remote Sens. 2019, 11, 620. [Google Scholar] [CrossRef]
- Ma, M.; Chen, J.; Liu, W.; Yang, W. Ship classification and detection based on CNN using GF-3 SAR images. Remote Sens. 2018, 10, 2043. [Google Scholar] [CrossRef]
- Marino, A.; Hajnsek, I. Ship detection with TanDEM-X data extending the polarimetric notch filter. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2160–2164. [Google Scholar] [CrossRef]
- Zhang, T.; Marino, A.; Xiong, H.; Yu, W. A ship detector applying principal component analysis to the polarimetric notch filter. Remote Sens. 2018, 10, 948. [Google Scholar] [CrossRef]
- Dechesne, C.; Lefèvre, S.; Vadaine, R.; Hajduch, G.; Fablet, R. Ship identification and characterization in Sentinel-1 SAR images with multi-task deep learning. Remote Sens. 2019, 11, 2997. [Google Scholar] [CrossRef]
- Liu, G.; Zhang, X.; Meng, J. A small ship target detection method based on polarimetric SAR. Remote Sens. 2019, 11, 2938. [Google Scholar] [CrossRef]
- Greidanus, H.; Alvarez, M.; Santamaria, C.; Thoorens, F.; Kourti, N.; Argentieri, P. The SUMO ship detector algorithm for satellite radar images. Remote Sens. 2017, 9, 246. [Google Scholar] [CrossRef]
- Joshi, S.K.; Baumgartner, S.; Silva, A.; Krieger, G. Range-doppler based CFAR ship detection with automatic training data selection. Remote Sens. 2019, 11, 1270. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, W.; Dong, X.; Hu, C.; Sun, Y. GRFT-based moving ship target detection and imaging in geosynchronous SAR. Remote Sens. 2018, 10, 2002. [Google Scholar] [CrossRef]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual region-based convolutional neural network with multilayer fusion for SAR ship detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Zhang, M.; Xu, P.; Guo, Z. SAR ship detection using sea-land segmentation-based convolutional neural network. In Proceedings of the International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Sentinel Online. Available online: https://sentinel.esa.int/web/sentinel/ (accessed on 15 July 2020).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Doll´ar, P.; Zitnick, C. Microsoft COCO: Common objects in context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. arXiv 2017, arXiv:1712.00726. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Huang, L.; Liu, B.; Li, B.; Guo, W.; Yu, W.; Zhang, Z.; Yu, W. OpenSARShip: A dataset dedicated to Sentinel-1 ship interpretation. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2018, 11, 195–208. [Google Scholar] [CrossRef]
- Hou, X.; Ao, W.; Song, Q.; Lai, J.; Wang, H.; Xu, F. FUSAR-Ship: Building a high-resolution SAR-AIS matchup dataset of Gaofen-3 for ship detection and recognition. Sci. China Inf. Sci. 2020, 63, 140303. [Google Scholar] [CrossRef]
- Copernicus Open Access Hub. Available online: https://scihub.copernicus.eu/ (accessed on 15 July 2020).
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Potin, P.; Rommen, B.; Floury, N.; Brown, M.; et al. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Zhou, S.; Xing, X.; Zou, H. Discriminating ship from radio frequency interference based on noncircularity and non-gaussianity in Sentinel-1 SAR imagery. IEEE Trans. Geosci. Remote Sens 2019, 57, 352–363. [Google Scholar] [CrossRef]
- Sentinel-1 Toolbox. Available online: https://sentinels.copernicus.eu/web/ (accessed on 15 July 2020).
- GDAL Documentation Edit on GitHub. Available online: https://gdal.org/ (accessed on 15 July 2020).
- Xiao, F.; Ligteringen, H.; Gulijk, C.; Ale, B. Comparison study on AIS data of ship traffic behavior. Ocean Eng. 2015, 95, 84–93. [Google Scholar] [CrossRef]
- IMO. Available online: http://www.imo.org/ (accessed on 15 July 2020).
- World Glacier Inventory. Available online: http://nsidc.org/data/glacier_inventory/ (accessed on 15 July 2020).
- Bentes, C.; Frost, A.; Velotto, D.; Tings, B. Ship-Iceberg Discrimination with Convolutional Neural Networks in High Resolution SAR Images. In Proceedings of the 11th European Conference on Synthetic Aperture Radar, Hamburg, Germany, 6–9 June 2016; pp. 1–4. [Google Scholar]
- World Meteorological Organization. Available online: https://worldweather.wmo.int/en/home.html (accessed on 15 July 2020).
- Park, J.; Lee, J.; Seto, K.; Hochberg, T.; Wong, B.A.; Miller, N.A.; Takasaki, K.; Kubota, H.; Oozeki, Y.; Doshi, S.; et al. Illuminating dark fishing fleets in North Korea. Sci. Adv. 2020, 6, eabb1197. [Google Scholar] [CrossRef]
- Wang, J.; Lu, C.; Jiang, W. Simultaneous Ship Detection and Orientation Estimation in SAR Images Based on Attention Module and Angle Regression. Sensors 2018, 18, 2851. [Google Scholar] [CrossRef]
- Liu, C.; Yang, J.; Yin, J.; An, W. Coastline detection in SAR images using a hierarchical level set segmentation. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2016, 9, 4908–4920. [Google Scholar] [CrossRef]
- Modava, M.; Akbarizadeh, G.; Soroosh, M. Hierarchical coastline detection in SAR images based on spectral-textural features and global–local information. IET Radar Sonar Navig. 2019, 13, 2183–2195. [Google Scholar] [CrossRef]
- Modava, M.; Akbarizadeh, G.; Soroosh, M. Integration of Spectral Histogram and Level Set for Coastline Detection in SAR Images. IEEE Trans. Aerosp. Electron. Syst. 2019, 55, 810–819. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Sergios, T. Stochastic gradient descent. Mach. Learn. 2015, 161–231. [Google Scholar] [CrossRef]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 h. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Lin, T.-Y.; Doll´ar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Change Loy, C.; Lin, D. CARAFE: Content-aware reassembly of features. arXiv 2019, arXiv:1905.02188. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6687–6696. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; So Kweon, I. CBAM: Convolutional block attention module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. arXiv 2018, arXiv:1803.01534. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. arXiv 2019, arXiv:1904.02701. [Google Scholar]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking classification and localization for object detection. arXiv 2019, arXiv:1904.06493. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid R-CNN. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7355–7364. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. arXiv 2019, arXiv:1911.09070. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Change Loy, C.; Lin, D. Region proposal by guided anchoring. arXiv 2019, arXiv:1901.03278. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, B.; Liu, Y.; Wang, X. Gradient harmonized single-stage detector. arXiv 2018, arXiv:1811.05181. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. arXiv 2019, arXiv:1912.02424. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ye, Q. FreeAnchor: Learning to match anchors for visual object detection. arXiv 2019, arXiv:1909.02466. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. FoveaBox: Beyond anchor-based object detector. arXiv 2019, arXiv:1904.03797. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Girshick, R.; Doll´ar, P. Rethinking ImageNet pre-training. arXiv 2018, arXiv:1811.08883. [Google Scholar]
- Hosang, J.; Benenson, R.; Schiele, B. Learning non-maximum suppression. arXiv 2017, arXiv:1705.02950. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving object detection with one line of code. arXiv 2017, arXiv:1704.04503. [Google Scholar]
- Eric, Q. Floating-Point Fused Multiply–Add Architectures. Ph.D. Thesis, The University of Texas at Austin, Austin, TX, USA, 2007. [Google Scholar]
- Ai, J.; Tian, R.; Luo, Q.; Jin, J.; Tang, B. Multi-scale rotation-invariant Haar-Like feature integrated CNN-based ship detection algorithm of multiple-target environment in SAR imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10070–10087. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | SSDD | SAR-Ship-Dataset | AIR-SARShip-1.0 | HRSID | LS-SSDD-v1.0 |
|---|---|---|---|---|---|
| Satellite | RadarSat-2, TerraSAR-X, Sentinel-1 | Gaofen-3, Sentinel-1 | Gaofen-3 | Sentinel-1, TerraSAR-X | Sentinel-1 |
| Sensor mode | -- | UFS, FSI, QPSI FSII, SM, IW | Stripmap, Spotlight | SM, ST, HS | IW |
| Location | Yantai, Visakhapatnam | -- | -- | Houston, Sao Paulo, etc. | Tokyo, Adriatic Sea, etc. |
| Resolution (m) | 1–15 | 5 × 5, 8 × 8, 10 × 10, etc. | 1, 3 | 0.5, 1, 3 | 5 × 20 |
| Polarization | HH, HV, VV, VH | Single, Dual, Full | Single | HH, HV, VV | VV, VH |
| Image size (pixel) | 500 × 500 | 256 × 256 | 3000 × 3000 | 800 × 800 | 24,000 × 16,000 |
| Cover width (km) | ~10 | ~0.4 | ~9 | ~4 | ~250 |
| Image number | 1160 | 43,819 | 31 | 5604 | 15 |
| No. | Place | Date | Time | Duration (s) | Mode | Incident Angle (°) | Image Size (Pixels) |
|---|---|---|---|---|---|---|---|
| 1 | Tokyo Port | 20 June 2020 | 12:01:56 | 2.509 | IW | 27.6–34.8 | 25,479 × 16,709 |
| 2 | Adriatic Sea | 20 June 2020 | 19:47:56 | 1.140 | IW | 27.6–34.8 | 26,609 × 16,687 |
| 3 | Skagerrak | 20 June 2020 | 19:57:58 | 1.227 | IW | 27.6–34.8 | 26,713 × 16,687 |
| 4 | Qushm Islands | 11 June 2020 | 06:50:06 | 0.652 | IW | 27.6–34.8 | 25,729 × 16,717 |
| 5 | Campeche | 21 June 2020 | 03:55:27 | 1.353 | IW | 27.6–34.8 | 25,629 × 16,742 |
| 6 | Alboran Sea | 17 June 2020 | 08:55:11 | 0.896 | IW | 27.6–34.8 | 26,446 × 16,672 |
| 7 | Plymouth | 21 June 2020 | 09:52:22 | 1.153 | IW | 27.6–34.8 | 26,474 × 16,689 |
| 8 | Basilan Islands | 21 June 2020 | 03:05:52 | 0.681 | IW | 27.6–34.8 | 25,538 × 16,810 |
| 9 | Gulf of Cadiz | 21 June 2020 | 21:01:21 | 1.260 | IW | 27.6–34.8 | 25,710 × 16,707 |
| 10 | English Channel | 19 June 2020 | 20:43:04 | 0.794 | IW | 27.6–34.8 | 26,275 × 16,679 |
| 11 | Taiwan Strait | 16 June 2020 | 13:36:24 | 0.741 | IW | 27.6–34.8 | 26,275 × 16,720 |
| 12 | Singapore Strait | 6 June 2020 | 14:38:09 | 1.721 | IW | 27.6–34.8 | 25,650 × 16,768 |
| 13 | Malacca Strait | 12 April 2020 | 05:16:40 | 0.935 | IW | 27.6–34.8 | 25,427 × 16,769 |
| 14 | Gulf of Cadiz | 18 June 2020 | 09:15:04 | 1.458 | IW | 27.6–34.8 | 25,644 × 16,722 |
| 15 | Gibraltarian Strait | 16 June 2020 | 21:20:42 | 0.782 | IW | 27.6–34.8 | 25,667 × 16,705 |
| No. | Dataset | Image Size W.×H. (Pixels) | Cover Width (km) |
|---|---|---|---|
| 1 | SSDD | 500 × 500 | ~10 |
| 2 | SAR-Ship-Dataset | 256 × 256 | ~0.4 |
| 3 | AIR-SARShip-1.0 | 3000 × 3000 | ~9 |
| 4 | HRSID | 800 × 800 | ~4 |
| 5 | LS-SSDD-v1.0 (Ours) | 24,000× 16,000 | ~250 |
| No. | Dataset | Smallest (Pixels2) | Largest (Pixels2) | Average (Pixels2) | Proportion |
|---|---|---|---|---|---|
| 1 | SSDD | 28 | 62,878 | 1882 | 0.7500% |
| 2 | SAR-Ship-Dataset | 24 | 26,703 | 1134 | 1.7300% |
| 3 | AIR-SARShip-1.0 | 90 | 72,297 | 4027 | 0.0447% |
| 4 | HRSID | 3 | 522,400 | 1808 | 0.2800% |
| 5 | LS-SSDD-v1.0 (Ours) | 6 | 5822 | 381 | 0.0001% |
| No. | Dataset | Training Avg. Size (Pixels) | Total Pixel Number | Small Pixels/Proportion | Medium Pixels/Proportion | Large Pixels/Proportion |
|---|---|---|---|---|---|---|
| 0 | COCO (Standard) | 484 × 578 | 279,752 | (0, 1024]/ (0, 0.37%] | (1024, 9216]/ (0.37%, 3.29%] | (9216, ∞]/ (3.29%, ∞] |
| 1 | SSDD | 500 × 500 | 250,000 | (0, 915]/ (0, 0.37%] | (915, 8235]/ (0.37%, 3.29%] | (8235, ∞]/ (3.29%, ∞] |
| 2 | SAR-Ship-Dataset | 256 × 256 | 65,536 | (0, 240]/ (0, 0.37%] | (240, 2159]/ (0.37%, 3.29%] | (2159, ∞]/ (3.29%, ∞] |
| 3 | AIR-SARShip-1.0 | 500 × 500 | 250,000 | (0, 915]/ (0, 0.37%] | (915, 8235]/ (0.37%, 3.29%] | (8235, ∞]/ (3.29%, ∞] |
| 4 | HRSID | 800 × 800 | 640,000 | (0, 2342]/ (0, 0.37%] | (2342, 21056]/ (0.37%, 3.29%] | (21056, ∞]/ (3.29%, ∞] |
| 5 | LS-SSDD-v1.0 | 800 × 800 | 640,000 | (0, 2342]/ (0, 0.37%] | (2342, 21056]/ (0.37%, 3.29%] | (21056, ∞]/ (3.29%, ∞] |
| No. | Dataset | Abundant Pure Background |
|---|---|---|
| 1 | SSDD | 🗴 |
| 2 | SAR-Ship-Dataset | 🗴 |
| 3 | AIR-SARShip-1.0 | 🗴 |
| 4 | HRSID | 🗴 |
| 5 | LS-SSDD-v1.0(Ours) | ✓ |
| No. | Dataset | Fully Automatic Detection Flow |
|---|---|---|
| 1 | SSDD | 🗴 |
| 2 | SAR-Ship-Dataset | 🗴 |
| 3 | AIR-SARShip-1.0 | 🗴 |
| 4 | HRSID | 🗴 |
| 5 | LS-SSDD-v1.0 (Ours) | ✓ |
| No. | Dataset | Standardized Research Baselines | Number of Research Baselines |
|---|---|---|---|
| 1 | SSDD | 🗴 | 2 |
| 2 | SAR-Ship-Dataset | 🗴 | 6 |
| 3 | AIR-SARShip-1.0 | 🗴 | 9 |
| 4 | HRSID | ✓ | 8 |
| 5 | LS-SSDD-v1.0 (Ours) | ✓ | 30 |
| No. | Method | Pd | Pf | Pm | Recall | Precision | mAP | F1 |
|---|---|---|---|---|---|---|---|---|
| 1 | Faster R-CNN without FPN [75] | 65.81% | 26.42% | 34.19% | 65.81% | 73.58% | 63.00% | 0.69 |
| 2 | Faster R-CNN [100] | 77.71% | 26.26% | 22.29% | 77.71% | 73.74% | 74.80% | 0.76 |
| 3 | OHEM Faster R-CNN [101] | 71.40% | 13.50% | 28.60% | 71.40% | 86.50% | 69.25% | 0.78 |
| 4 | CARAFE Faster R-CNN [102] | 77.67% | 25.37% | 22.33% | 77.67% | 74.63% | 74.70% | 0.76 |
| 5 | SA Faster R-CNN [103] | 77.88% | 25.20% | 22.12% | 77.88% | 74.80% | 75.17% | 0.76 |
| 6 | SE Faster R-CNN [104] | 77.21% | 25.21% | 22.79% | 77.21% | 74.79% | 74.34% | 0.76 |
| 7 | CBAM Faster R-CNN [105] | 78.39% | 25.62% | 21.61% | 78.39% | 74.38% | 75.32% | 0.76 |
| 8 | PANET [106] | 76.32% | 25.09% | 23.68% | 76.32% | 74.91% | 73.33% | 0.76 |
| 9 | Cascade R-CNN [78] | 72.67% | 15.91% | 27.33% | 72.67% | 84.09% | 70.88% | 0.78 |
| 10 | OHEM Cascade R-CNN [101] | 64.05% | 6.79% | 35.95% | 64.05% | 93.21% | 62.90% | 0.76 |
| 11 | CARAFE Cascade R-CNN [102] | 74.60% | 15.52% | 25.40% | 74.60% | 84.48% | 72.66% | 0.79 |
| 12 | SA Cascade R-CNN [103] | 71.99% | 16.37% | 28.01% | 71.99% | 83.63% | 69.94% | 0.77 |
| 13 | SE Cascade R-CNN [104] | 72.71% | 16.47% | 27.29% | 72.71% | 83.53% | 70.92% | 0.78 |
| 14 | CBAM Cascade R-CNN [105] | 74.31% | 16.49% | 25.69% | 74.31% | 83.51% | 72.20% | 0.79 |
| 15 | Libra R-CNN [107] | 76.70% | 26.45% | 23.30% | 76.70% | 73.55% | 73.68% | 0.75 |
| 16 | Double-Head R-CNN [108] | 78.47% | 25.63% | 21.53% | 78.47% | 74.37% | 75.74% | 0.76 |
| 17 | Grid R-CNN [109] | 75.23% | 20.98% | 24.77% | 75.23% | 79.02% | 72.28% | 0.77 |
| 18 | DCN [110] | 76.87% | 25.87% | 23.13% | 76.87% | 74.13% | 73.84% | 0.75 |
| 19 | EfficientDet [111] | 67.49% | 37.86% | 32.51% | 67.49% | 62.14% | 61.35% | 0.65 |
| 20 | Guided Anchoring [112] | 70.86% | 12.06% | 29.14% | 70.86% | 87.94% | 69.02% | 0.78 |
| 21 | HR-SDNet [6] | 70.56% | 15.04% | 29.44% | 70.56% | 84.96% | 68.80% | 0.77 |
| 22 | SSD-300 [76] | 28.26% | 14.50% | 71.74% | 28.26% | 85.50% | 25.37% | 0.42 |
| 23 | SSD-512 [76] | 42.30% | 9.53% | 57.70% | 42.30% | 90.47% | 40.60% | 0.58 |
| 24 | YOLOv3 [113] | 26.24% | 12.36% | 73.76% | 26.24% | 87.64% | 24.63% | 0.40 |
| 25 | RetinaNet [77] | 55.51% | 5.38% | 44.49% | 55.51% | 94.62% | 54.31% | 0.70 |
| 26 | GHM [114] | 70.73% | 15.31% | 29.27% | 70.73% | 84.69% | 68.52% | 0.77 |
| 27 | FCOS [115] | 51.30% | 6.08% | 48.70% | 51.30% | 93.92% | 50.33% | 0.66 |
| 28 | ATSS [116] | 31.29% | 10.25% | 68.71% | 31.29% | 89.75% | 30.10% | 0.46 |
| 29 | FreeAnchor [117] | 77.67% | 44.70% | 22.33% | 77.67% | 55.30% | 71.04% | 0.65 |
| 30 | FoveaBox [118] | 53.03% | 4.25% | 46.97% | 53.03% | 95.75% | 52.32% | 0.68 |
| No. | Method | Pd | Pf | Pm | Recall | Precision | mAP | F1 |
|---|---|---|---|---|---|---|---|---|
| 1 | Faster R-CNN without FPN [75] | 29.11% | 50.86% | 70.89% | 29.11% | 49.14% | 25.27% | 0.37 |
| 2 | Faster R-CNN [100] | 53.68% | 44.04% | 46.32% | 53.68% | 55.96% | 46.76% | 0.59 |
| 3 | OHEM Faster R-CNN [101] | 41.90% | 22.11% | 58.10% | 41.90% | 77.89% | 38.31% | 0.54 |
| 4 | CARAFE Faster R-CNN [102] | 53.68% | 42.62% | 46.32% | 53.68% | 57.38% | 46.98% | 0.55 |
| 5 | SA Faster R-CNN [103] | 52.66% | 42.09% | 47.34% | 52.66% | 57.91% | 46.61% | 0.55 |
| 6 | SE Faster R-CNN [104] | 51.76% | 42.01% | 57.99% | 51.76% | 57.99% | 45.52% | 0.55 |
| 7 | CBAM Faster R-CNN [105] | 54.25% | 40.50% | 45.75% | 54.25% | 59.50% | 47.70% | 0.57 |
| 8 | PANET [106] | 50.62% | 40.72% | 49.38% | 50.62% | 59.28% | 44.39% | 0.55 |
| 9 | Cascade R-CNN [78] | 44.28% | 26.78% | 55.72% | 44.28% | 73.22% | 40.77% | 0.55 |
| 10 | OHEM Cascade R-CNN [101] | 29.11% | 12.59% | 70.89% | 29.11% | 87.41% | 27.44% | 0.44 |
| 11 | CARAFE Cascade R-CNN [102] | 47.68% | 28.40% | 52.32% | 47.68% | 71.60% | 43.66% | 0.57 |
| 12 | SA Cascade R-CNN [103] | 44.05% | 29.14% | 55.95% | 44.05% | 70.86% | 39.68% | 0.54 |
| 13 | SE Cascade R-CNN [104] | 43.49% | 27.55% | 56.51% | 43.49% | 72.45% | 40.21% | 0.54 |
| 14 | CBAM Cascade R-CNN [105] | 48.02% | 28.26% | 51.98% | 48.02% | 71.74% | 44.02% | 0.58 |
| 15 | Libra R-CNN [107] | 50.74% | 43.43% | 49.26% | 50.74% | 56.57% | 43.25% | 0.53 |
| 16 | Double-Head R-CNN [108] | 53.57% | 42.11% | 46.43% | 53.57% | 57.89% | 47.53% | 0.57 |
| 17 | Grid R-CNN [109] | 48.92% | 38.29% | 51.08% | 48.92% | 61.71% | 43.08% | 0.55 |
| 18 | DCN [110] | 51.87% | 42.68% | 48.13% | 51.87% | 57.32% | 45.31% | 0.54 |
| 19 | EfficientDet [111] | 39.75% | 62.38% | 60.25% | 39.75% | 37.62% | 30.48% | 0.37 |
| 20 | Guided Anchoring [112] | 42.13% | 18.95% | 57.87% | 42.13% | 81.05% | 39.30% | 0.55 |
| 21 | HR-SDNet [6] | 37.83% | 23.92% | 62.17% | 37.83% | 76.08% | 34.83% | 0.51 |
| 22 | SSD-300 [76] | 6.68% | 39.18% | 93.32% | 6.68% | 60.82% | 4.92% | 0.12 |
| 23 | SSD-512 [76] | 15.18% | 26.37% | 84.82% | 15.18% | 73.63% | 13.15% | 0.25 |
| 24 | YOLOv3 [113] | 11.44% | 38.79% | 88.56% | 11.44% | 61.21% | 8.64% | 0.19 |
| 25 | RetinaNet [77] | 18.01% | 10.17% | 81.99% | 18.01% | 89.83% | 17.29% | 0.30 |
| 26 | GHM [114] | 40.77% | 27.71% | 59.23% | 40.77% | 72.29% | 37.85% | 0.52 |
| 27 | FCOS [115] | 11.21% | 9.17% | 88.79% | 11.21% | 90.83% | 11.01% | 0.20 |
| 28 | ATSS [116] | 12.57% | 22.92% | 87.43% | 12.57% | 77.08% | 11.31% | 0.22 |
| 29 | FreeAnchor [117] | 53.57% | 69.52% | 46.43% | 53.57% | 30.48% | 34.73% | 0.39 |
| 30 | FoveaBox [118] | 14.16% | 5.30% | 85.84% | 14.16% | 94.70% | 13.92% | 0.25 |
| No. | Method | Pd | Pf | Pm | Recall | Precision | mAP | F1 |
|---|---|---|---|---|---|---|---|---|
| 1 | Faster R-CNN without FPN [75] | 87.49% | 18.45% | 12.51% | 87.49% | 81.55% | 84.62% | 0.84 |
| 2 | Faster R-CNN [100] | 91.91% | 17.18% | 8.09% | 91.91% | 82.82% | 89.99% | 0.87 |
| 3 | OHEM Faster R-CNN [101] | 88.83% | 10.75% | 11.17% | 88.83% | 89.25% | 86.84% | 0.89 |
| 4 | CARAFE Faster R-CNN [102] | 91.84% | 16.74% | 8.16% | 91.84% | 83.26% | 89.78% | 0.87 |
| 5 | SA Faster R-CNN [103] | 92.78% | 17.10% | 7.22% | 92.78% | 82.90% | 90.89% | 0.88 |
| 6 | SE Faster R-CNN [104] | 92.24% | 17.28% | 7.76% | 92.24% | 82.72% | 90.22% | 0.87 |
| 7 | CBAM Faster R-CNN [105] | 92.64% | 18.58% | 7.36% | 92.64% | 81.42% | 90.50% | 0.87 |
| 8 | PANET [106] | 91.51% | 18.03% | 8.49% | 91.51% | 81.97% | 89.25% | 0.86 |
| 9 | Cascade R-CNN [78] | 89.43% | 12.10% | 10.57% | 89.43% | 87.90% | 88.02% | 0.89 |
| 10 | OHEM Cascade R-CNN [101] | 84.68% | 5.52% | 15.32% | 84.68% | 94.48% | 83.51% | 0.89 |
| 11 | CARAFE Cascade R-CNN [102] | 90.50% | 10.52% | 9.50% | 90.50% | 89.48% | 88.99% | 0.90 |
| 12 | SA Cascade R-CNN [103] | 88.49% | 11.68% | 11.51% | 88.49% | 88.32% | 86.92% | 0.88 |
| 13 | SE Cascade R-CNN [104] | 89.97% | 12.66% | 10.03% | 89.97% | 87.34% | 88.48% | 0.89 |
| 14 | CBAM Cascade R-CNN [105] | 89.83% | 11.93% | 10.17% | 89.83% | 88.07% | 88.12% | 0.90 |
| 15 | Libra R-CNN [107] | 92.04% | 18.48% | 7.96% | 92.04% | 81.52% | 90.09% | 0.86 |
| 16 | Double-Head R-CNN [108] | 93.18% | 17.67% | 6.82% | 93.18% | 82.33% | 91.34% | 0.87 |
| 17 | Grid R-CNN [109] | 90.77% | 13.24% | 9.23% | 90.77% | 86.76% | 88.43% | 0.89 |
| 18 | DCN [110] | 91.64% | 17.82% | 8.36% | 91.64% | 82.18% | 89.45% | 0.87 |
| 19 | EfficientDet [111] | 83.88% | 24.00% | 16.12% | 83.88% | 76.00% | 80.37% | 0.80 |
| 20 | Guided Anchoring [112] | 87.83% | 9.88% | 12.17% | 87.83% | 90.12% | 86.15% | 0.89 |
| 21 | HR-SDNet [6] | 89.90% | 12.50% | 10.10% | 89.90% | 87.50% | 88.37% | 0.89 |
| 22 | SSD-300 [76] | 41.00% | 11.03% | 59.00% | 41.00% | 88.97% | 37.69% | 0.56 |
| 23 | SSD-512 [76] | 58.33% | 6.24% | 41.67% | 58.33% | 93.76% | 56.73% | 0.72 |
| 24 | YOLOv3 [113] | 37.98% | 4.39% | 65.02% | 34.98% | 95.61% | 33.98% | 0.51 |
| 25 | RetinaNet [77] | 77.66% | 4.68% | 22.34% | 77.66% | 95.32% | 76.15% | 0.86 |
| 26 | GHM [114] | 88.43% | 11.16% | 11.57% | 88.43% | 88.84% | 86.20% | 0.89 |
| 27 | FCOS [115] | 74.98% | 5.80% | 25.02% | 74.98% | 94.20% | 73.59% | 0.84 |
| 28 | ATSS [116] | 42.34% | 7.59% | 57.66% | 42.34% | 92.41% | 40.95% | 0.58 |
| 29 | FreeAnchor [117] | 91.91% | 23.15% | 8.09% | 91.91% | 76.85% | 88.67% | 0.84 |
| 30 | FoveaBox [118] | 75.99% | 4.14% | 24.01% | 75.99% | 95.86% | 75.01% | 0.85 |
| No. | Method | t (ms) | T (s) | FPS | Parameters (M) | FLOPs (GMACs) | Model Size |
|---|---|---|---|---|---|---|---|
| 1 | Faster R-CNN without FPN [74] | 207 | 124.45 | 4.82 | 33.04 | 877.13 | 252 MB |
| 2 | Faster R-CNN [100] | 98 | 58.67 | 10.23 | 41.35 | 134.38 | 320 MB |
| 3 | OHEM faster R-CNN [101] | 99 | 59.31 | 10.12 | 41.35 | 134.38 | 320 MB |
| 4 | CARAFE faster R-CNN [102] | 102 | 61.38 | 9.78 | 46.96 | 136.27 | 322 MB |
| 5 | SA faster R-CNN [103] | 120 | 72.04 | 8.33 | 47.26 | 138.10 | 365 MB |
| 6 | SE faster R-CNN [104] | 96 | 57.63 | 10.41 | 42.05 | 134.40 | 325 MB |
| 7 | CBAM faster R-CNN [105] | 107 | 63.92 | 9.39 | 46.92 | 134.44 | 362 MB |
| 8 | PANET [106] | 106 | 63.46 | 9.45 | 44.89 | 149.87 | 356 MB |
| 9 | Cascade R-CNN [77] | 113 | 67.97 | 8.83 | 69.15 | 162.18 | 532 MB |
| 10 | OHEM cascade R-CNN [101] | 114 | 62.28 | 8.79 | 69.15 | 162.18 | 532 MB |
| 11 | CARAFE cascade R-CNN [102] | 119 | 71.42 | 8.40 | 74.76 | 164.07 | 534 MB |
| 12 | SA cascade R-CNN [103] | 140 | 83.92 | 7.15 | 75.06 | 165.90 | 577 MB |
| 13 | SE cascade R-CNN [104] | 116 | 69.58 | 8.62 | 69.85 | 162.20 | 537 MB |
| 14 | CBAM cascade R-CNN [105] | 126 | 75.31 | 7.97 | 74.72 | 162.24 | 575 MB |
| 15 | Libra R-CNN [107] | 109 | 65.57 | 9.15 | 41.62 | 135.04 | 322 MB |
| 16 | Double-head R-CNN [108] | 160 | 95.97 | 6.25 | 46.94 | 408.58 | 363 MB |
| 17 | Grid R-CNN [109] | 99 | 59.39 | 10.10 | 64.47 | 257.14 | 496 MB |
| 18 | DCN [110] | 100 | 59.71 | 10.05 | 41.93 | 116.82 | 324 MB |
| 19 | EfficientDet [111] | 88 | 131.33 | 11.42 | 39.40 | 107.52 | 302 MB |
| 20 | Guided anchoring [112] | 137 | 82.23 | 7.30 | 41.89 | 134.31 | 324 MB |
| 21 | HR-SDNet [6] | 135 | 80.99 | 7.41 | 90.92 | 260.39 | 694 MB |
| 22 | SSD-300 [75] | 27 | 16.38 | 36.63 | 23.75 | 30.49 | 181 MB |
| 23 | SSD-512 [75] | 38 | 23.09 | 25.99 | 24.39 | 87.72 | 186 MB |
| 24 | YOLOv3 [113] | 46 | 27.57 | 21.76 | 20.94 | 121.15 | 314 MB |
| 25 | RetinaNet [76] | 87 | 52.06 | 11.53 | 36.33 | 127.82 | 277 MB |
| 26 | GHM [114] | 88 | 53.04 | 11.31 | 36.33 | 127.82 | 277 MB |
| 27 | FCOS [115] | 87 | 52.28 | 11.48 | 32.06 | 126.00 | 245 MB |
| 28 | ATSS [116] | 94 | 56.30 | 10.66 | 32.11 | 126.00 | 245 MB |
| 29 | Free anchor [117] | 87 | 52.32 | 11.47 | 36.33 | 127.82 | 277 MB |
| 30 | FoveaBox [118] | 79 | 47.16 | 12.72 | 36.24 | 126.59 | 277 MB |
| Type | Method | PBHT-Mechanism | Pd | Pf | Pm | Recall | Precision | mAP | F1 |
|---|---|---|---|---|---|---|---|---|---|
| Two-Stage | Faster R-CNN | 🗴 | 81.67% | 76.27% | 18.33% | 81.67% | 23.73% | 74.09% | 0.37 |
| ✓ | 77.71% | 26.26% | 22.29% | 77.71% | 73.74% | 74.80% | 0.76 | ||
| Cascade R-CNN | 🗴 | 74.39% | 42.15% | 25.61% | 74.39% | 57.85% | 69.99% | 0.65 | |
| ✓ | 72.67% | 15.91% | 27.33% | 72.67% | 84.09% | 70.88% | 0.78 | ||
| One-Stage | SSD-512 | 🗴 | 35.87% | 33.41% | 64.13% | 35.87% | 66.59% | 27.66% | 0.47 |
| ✓ | 42.30% | 9.53% | 57.70% | 42.30% | 90.47% | 40.60% | 0.58 | ||
| RetinaNet | 🗴 | 61.56% | 38.80% | 38.44% | 61.56% | 61.20% | 50.38% | 0.61 | |
| ✓ | 55.51% | 5.38% | 44.49% | 55.51% | 94.62% | 54.31% | 0.70 |
| Type | Method | PBHT-Mechanism | Pd | Pf | Pm | Recall | Precision | mAP | F1 |
|---|---|---|---|---|---|---|---|---|---|
| Two-Stage | Faster R-CNN | 🗴 | 62.29% | 91.13% | 37.71% | 62.29% | 8.87% | 41.18% | 0.16 |
| ✓ | 53.68% | 44.04% | 46.32% | 53.68% | 55.96% | 46.76% | 0.59 | ||
| Cascade R-CNN | 🗴 | 48.58% | 59.38% | 51.42% | 48.58% | 40.62% | 38.26% | 0.44 | |
| ✓ | 44.28% | 26.78% | 55.72% | 44.28% | 73.22% | 40.77% | 0.55 | ||
| One-Stage | SSD-512 | 🗴 | 12.46% | 36.78% | 87.54% | 12.46% | 63.22% | 9.22% | 0.21 |
| ✓ | 15.18% | 26.37% | 84.82% | 15.18% | 73.63% | 13.15% | 0.25 | ||
| RetinaNet | 🗴 | 36.35% | 55.04% | 63.65% | 36.25% | 44.96% | 25.56% | 0.40 | |
| ✓ | 18.01% | 10.17% | 81.99% | 18.01% | 89.83% | 17.29% | 0.30 |
| Type | Method | PBHT-Mechanism | Pd | Pf | Pm | Recall | Precision | mAP | F1 |
|---|---|---|---|---|---|---|---|---|---|
| Two-Stage | Faster R-CNN | 🗴 | 93.11% | 29.73% | 6.89% | 93.11% | 70.27% | 90.48% | 0.80 |
| ✓ | 91.91% | 17.18% | 8.09% | 91.91% | 82.82% | 89.99% | 0.87 | ||
| Cascade R-CNN | 🗴 | 89.63% | 33.07% | 10.37% | 89.63% | 66.93% | 86.75% | 0.77 | |
| ✓ | 89.43% | 12.10% | 10.57% | 89.43% | 87.90% | 88.02% | 0.89 | ||
| One-Stage | SSD-512 | 🗴 | 49.70% | 32.88% | 50.30% | 49.70% | 67.12% | 38.69% | 0.57 |
| ✓ | 58.33% | 6.24% | 41.67% | 58.33% | 93.76% | 56.73% | 0.72 | ||
| RetinaNet | 🗴 | 76.45% | 31.88% | 23.55% | 76.45% | 68.12% | 64.70% | 0.72 | |
| ✓ | 77.66% | 4.68% | 22.34% | 77.66% | 95.32% | 76.15% | 0.86 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y.; et al. LS-SSDD-v1.0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images. Remote Sens. 2020, 12, 2997. https://doi.org/10.3390/rs12182997
Zhang T, Zhang X, Ke X, Zhan X, Shi J, Wei S, Pan D, Li J, Su H, Zhou Y, et al. LS-SSDD-v1.0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images. Remote Sensing. 2020; 12(18):2997. https://doi.org/10.3390/rs12182997
Chicago/Turabian StyleZhang, Tianwen, Xiaoling Zhang, Xiao Ke, Xu Zhan, Jun Shi, Shunjun Wei, Dece Pan, Jianwei Li, Hao Su, Yue Zhou, and et al. 2020. "LS-SSDD-v1.0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images" Remote Sensing 12, no. 18: 2997. https://doi.org/10.3390/rs12182997
APA StyleZhang, T., Zhang, X., Ke, X., Zhan, X., Shi, J., Wei, S., Pan, D., Li, J., Su, H., Zhou, Y., & Kumar, D. (2020). LS-SSDD-v1.0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images. Remote Sensing, 12(18), 2997. https://doi.org/10.3390/rs12182997