Adaptive Geoparsing Method for Toponym Recognition and Resolution in Unstructured Text

 ,
,  , , and
, , and
Abstract
:
1. Introduction
2. Related Work
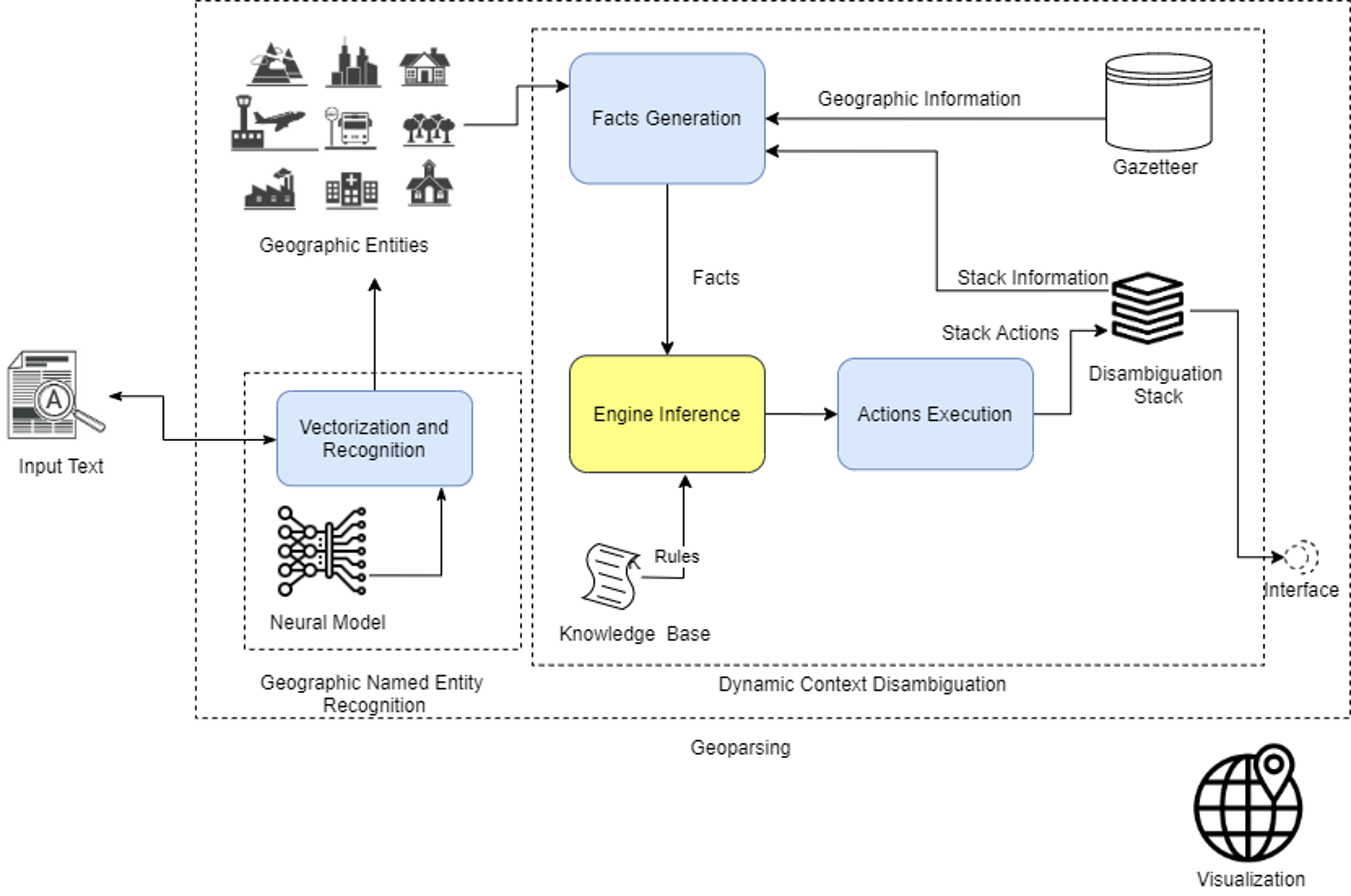
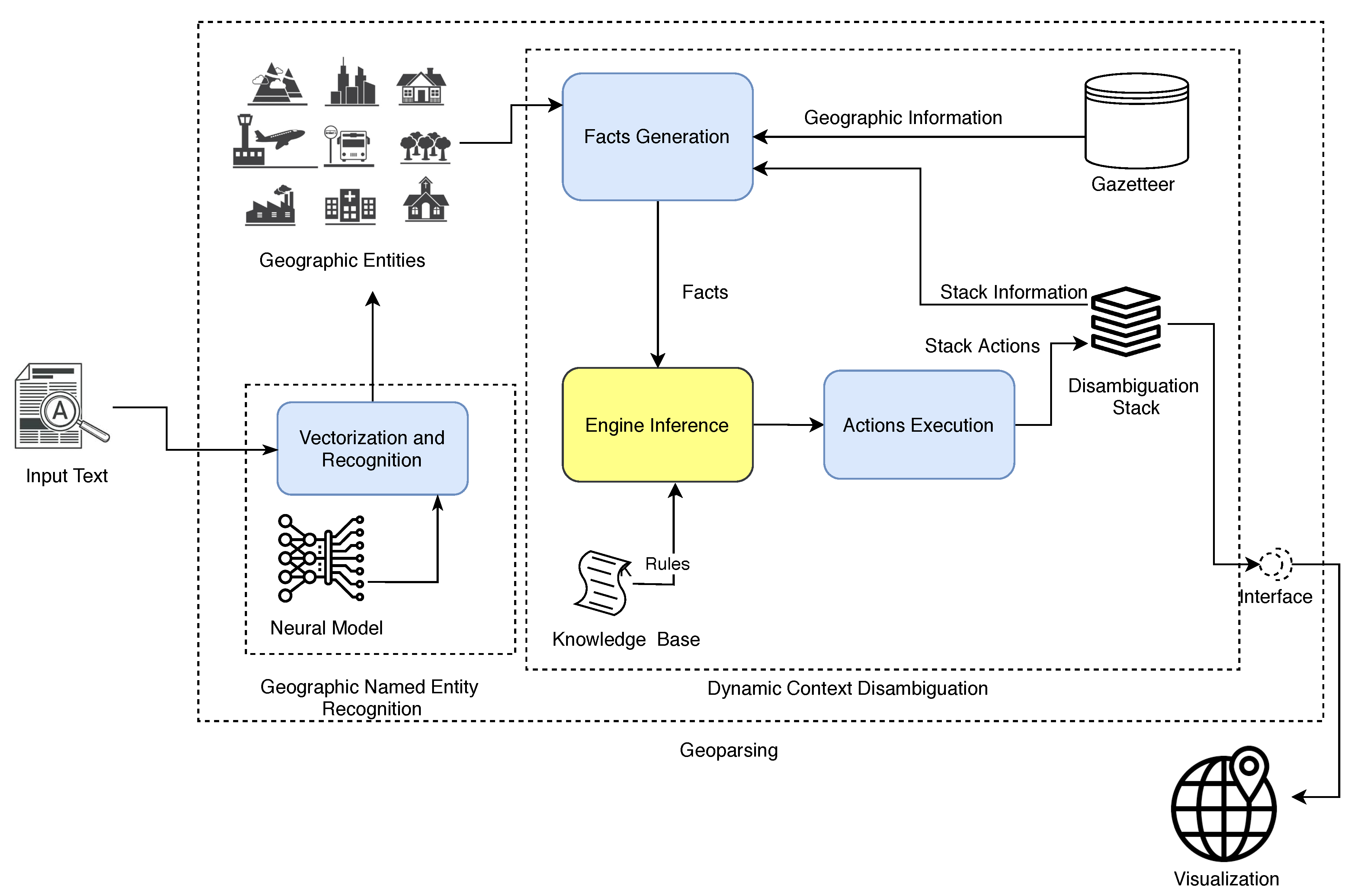
3. Geoparsing Approach
3.1. Geographic-Named Entity Recognition
3.1.1. Preprocessing and Vectorization
3.1.2. Neural Network GNER Classifier
3.2. Dynamic Context Disambiguation
- Knowledge base (KB): A set of rules which mimic human knowledge about how a place mentioned in a text must be solved. A rule is an IF-THEN clause with an antecedent and a consequent. The IF part of the clause is made up of a series of clauses connected by a logic AND operator that causes the rule to be applicable, while the THEN part is made up of a set of actions to be executed when the rule is applicable.
- Gazetteer: Reservoir of places and geographic information.
- Facts generation (FG): Creates instances of facts defined in the rules. The instances are deduced from a grammar and the Gazetteer on the fly during the execution of the toponym resolution algorithm.
- Inference engine (IE): Determines what rules should be triggered. Then, when a rule is triggered, other facts could be generated; these, in turn, would trigger other rules which make the IE context dynamic.
- Action execution (AE): Executes the consequents of the rules that have been activated. This execution involves read and write operations on a disambiguation stack.
- Disambiguation stack (DS): Data structure in which the entities that have been solved are stored. By “solved,” we mean that their most likely geographic locations have been determined.
- Visualization: Once all place names have been solved, this module allows us to visualize, on a map, the resulting place names in DS.
3.2.1. Notation
| A gazetteer containing tuples of the form: | ||
| . | ||
| The ith rule defined as a Horn clause of the form , where is a fact and Q is an action or set of actions to be executed when the antecedent is true. | ||
| Input text document containing the entities to be georeferenced. | ||
| Geographic entities in | ||
| Stack data structure, in what follows disambiguation stack, wherein the entities will be stored as soon as the rules are activated and executed. | ||
| Auxiliary stack used in situations, in which we lack information to solve the ambiguities relative to a place name. |
3.2.2. Base Facts and Rules
- P1
- A matches a location name in .
- P2
- The disambiguation stack is empty.
- P3
- A has a more specific administrative level than B (but A is not necessarily contained in B).
- P4
- There is a relationship between A and B, meaning that there is a path between A and B in the administrative hierarchy.
- P5
- There are no entities in to be processed.
- P6
- There are elements in that must be processed.
3.3. Geoparsing Process
| Algorithm 1: Geoparsing algorithm |
 |
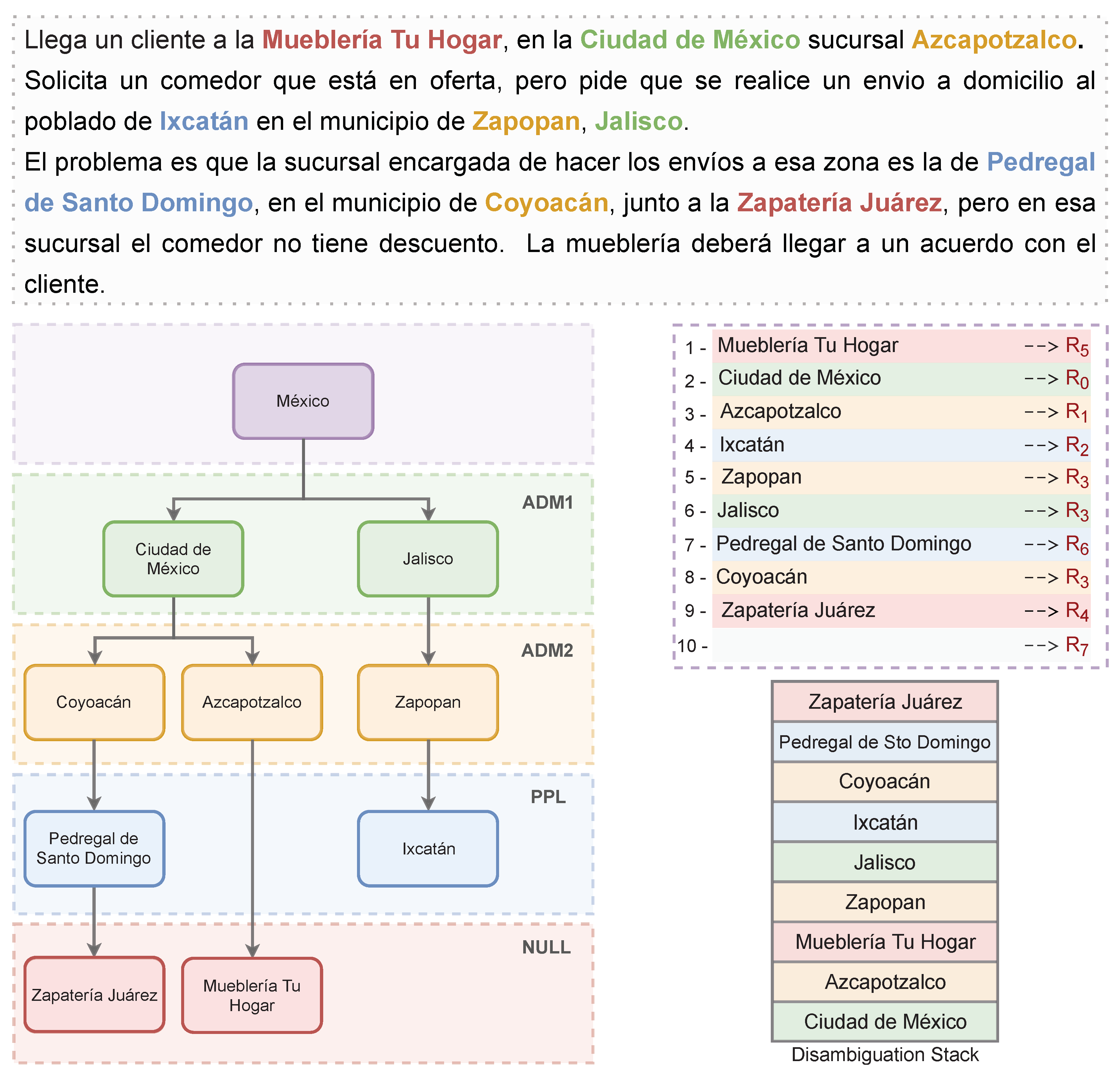
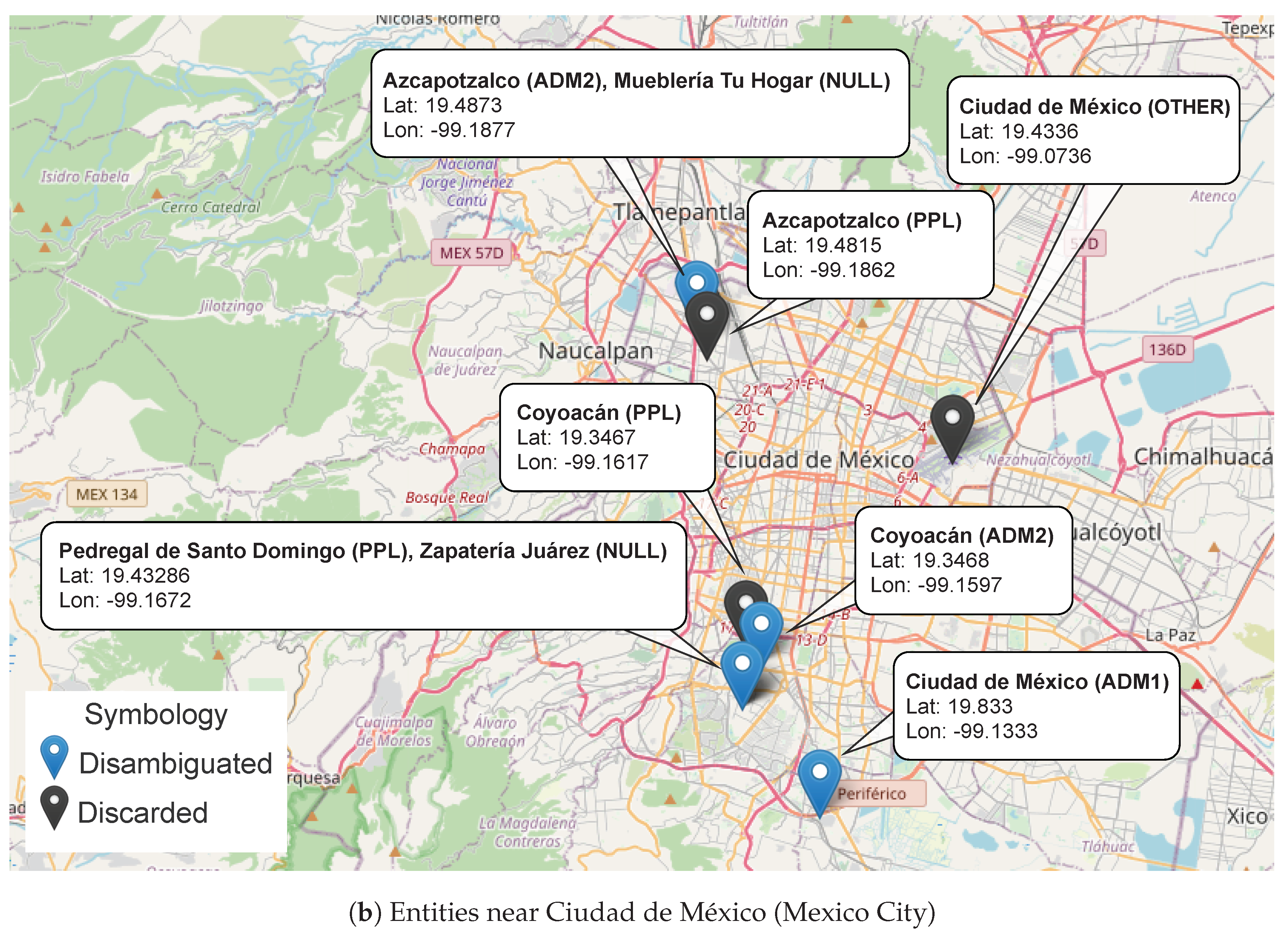
Geoparsing Example
- The entity in to be processed (Mueblería Tu Hogar) does not have a match in and, at this point, is empty. This means that there is not enough information to determine the geographic properties of the entity, in which case the rule is activated and applied. As a consequence, the conflict condition is met, and so the entity is pushed onto .
- The next entity in (Ciudad de México) has several matches in , from which the one with the highest geographic level is taken and pushed onto according to .
- At this point, the entity in to be processed (Azcapotzalco) has a match in , with Ciudad de México being the top of , so the rule is activated, in which case, Azcapotzalco is pushed onto as a child entity of Ciudad de México.
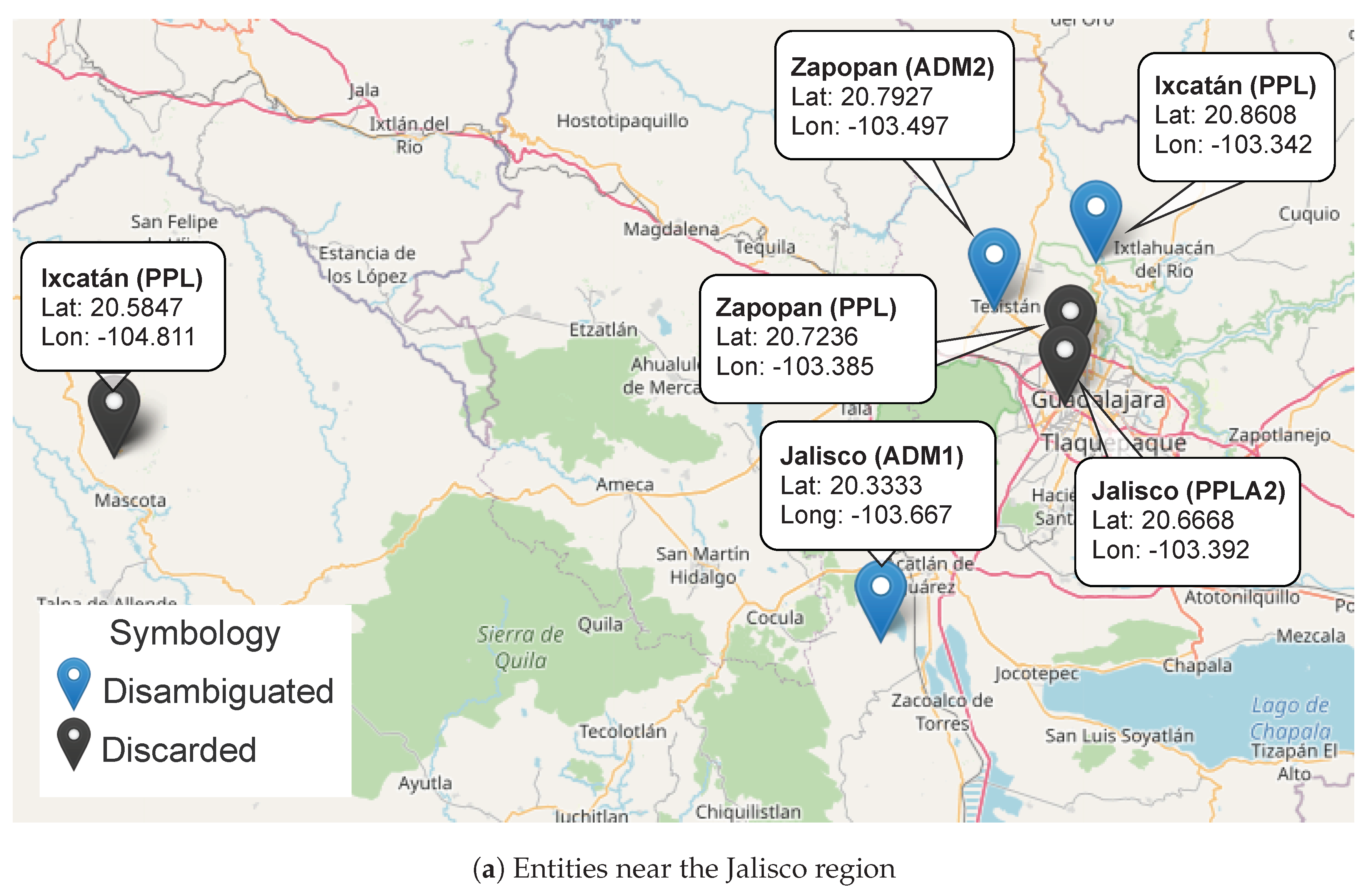
- The entity to be processed (Ixcatán) has two matches in . In this case, these names have the same geographic level, in which case, either one can be selected and pushed onto , according to .
- At this point, the top of is Ixcatán and the entity in to be processed is Zapopan. This has two matches in , and thus the place with the highest feature level is selected to be added to . However, this place (Zapopan) is not lower than the top of (Ixcatán), though there is a relationship between them. This situation causes rule to be triggered.
- Similarly, the entity in to be processed (Jalisco) is not the predecessor of the current top (Ixcatán), and there is a relationship between them, so the rule is applied again.
- Then, given that the entity in to be processed (Pedregal de Santo Domingo) does not have any relationship with the top of (Ixcatán), the rule proceeds.
- At this point, the top of is Pedregal de Santo Domingo. When the entity in to be processed (Coyoacán) is evaluated, it happens that the top of is its predecessor, and so must be applied.
- The entity in to be processed (Zapatería Juarez) appears in the text, but not in , implying .
4. Data and Annotation Criteria
- Named entities are considered geo-entities only when it is possible to assign them geographic coordinates.
- A place name composed of many words, expressions or other entities must be spanned by a single label. For example, <loc>Hermosillo, Sonora</loc> must be a single geo-entity.
- Imprecise references such as “at the south of” or “on the outskirts of” must not be included as part of the geo-entity. For instance, in “on the outskirts of Mexico”, only <loc>Mexico</loc> must be labeled.
- Place names that are part of other entity types such as “the president of Mexico” or “Bishop of Puebla” or the band name “Los tucanes de Tijuana” must not be labeled.
- The names of sports teams accompanied by names of places such as countries, states or municipalities, such as “Atletico de San Luis”, must not be considered place names. Instead, the names of the stadiums, sports centers or gyms, such as <loc>Estadio Azteca</loc>, must be considered place names.
- Country names must be considered as place names when they point to the territory, but they must not be labeled when they refer to the government. For example, in ‘California sends help to those affected by the earthquake in Mexico City”, only <loc>Mexico City</loc> must be labeled.
5. Experiments and Results
5.1. Geographic-Named Entity Recognition
5.2. Geographic Level Assignment
5.3. Ranking of Closeness
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Appendix A. Geographic Levels Based on GeoNames

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Geographic Level | Description | Examples |
|---|---|---|
| ADM1 | first-order administrative division | States Departments Provinces |
| PPLA | seat of a first-order administratie division | Capital city in a country Capital city in a state Capital city in a province |
| ADM2 | second-order administrative division | Counties Districts Municipalities |
| PPLA2 | seat of a second-order administrative division | City council Village council Community council |
| PPL | small populated place | Village Town |
| LCTY | a minor area of unspecified character and indefinite boundaries | Basin of Hudson river Valley of Flowers El Zapote |
| OTHER | specific places | Volcán Popocatepetl Túnel de Tenecoxco Arroyo el Zapote |
| NULL | places not found in the gazetteer | Centro de Justicia Penal Federal de Puebla Autopista Puebla – Orizaba Hospital Regional de Apatzingán |
References
- Aguirre, E.; Alegria, I.; Artetxe, M.; Aranberri, N.; Barrena, A.; Branco, A.; Popel, M.; Burchardt, A.; Labaka, G.; Osenova, P.; et al. Report on the State of the Art of Named Entity and Word Sense Disambiguation; Technical Report 4; Faculdade de Ciências da Universidade de Lisboa on behalf of QTLeap: Lisboa, Portugal, 2015. [Google Scholar]
- Andogah, G.; Bouma, G.; Nerbonne, J. Every document has a geographical scope. Data Knowl. Eng. 2012, 81–82, 1–20. [Google Scholar] [CrossRef]
- Gritta, M.; Pilehvar, M.; Collier, N. A pragmatic guide to geoparsing evaluation. Lang. Resour. Eval. 2020, 54, 683–712. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buscaldi, D.; Rosso, P. A conceptual density-based approach for the disambiguation of toponyms. Int. J. Geogr. Inf. Sci. 2008, 22, 301–313. [Google Scholar] [CrossRef]
- Agirre, E.; Rigau, G. Word sense disambiguation using conceptual density. In Proceedings of the 16th Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996; pp. 16–22. [Google Scholar]
- Miller, G. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Michael, H.; Lieberman, D.; Sankaranayananan, J. Geotagging: Using proximity, sibling, and prominence clues to understand comma groups. In Proceedings of the 6th Workshop on Geographic Information Retrieval. ACM, Zurich, Switzerland, 18–19 February 2010; pp. 1–8. [Google Scholar]
- Radke, M.; Gautam, N.; Tambi, A.; Deshpande, U.; Syed, Z. Geotagging Text Data on the Web A Geometrical Approach. IEEE Access 2018, 06, 30086–30099. [Google Scholar] [CrossRef]
- Woodruff, A.; Plaunt, C. GIPSY: Automated Geographic Indexing of Text Documents. J. Am. Soc. Inf. Sci. 1996, 45. [Google Scholar] [CrossRef]
- Inkpen, D.; Liu, J.; Farzindar, A.; Kazemi, F.; Ghazi, D. Location detection and disambiguation from twitter messages. J. Intell. Inf. Syst. 2017, 49, 237–253. [Google Scholar] [CrossRef]
- Gupta, R. Conditional Random Fields. In Computer Vision: A Reference Guide; Springer: Boston, MA, USA, 2014; p. 146. [Google Scholar]
- Middleton, S.E.; Kordopatis-Zilos, G.; Papadopoulos, S.; Kompatsiaris, Y. Location Extraction from Social Media: Geoparsing, Location Disambiguation and Geotagging. ACM Trans. Inf. Syst. 2018, 36, Article 40. [Google Scholar] [CrossRef] [Green Version]
- Karimzadeh, M.; Pezanowski, S.; MacEachren, A.; Wallgrun, J. GeoTxt: A scalable geoparsing system for unstructured text geolocation. Trans. GIS 2019, 23, 118–136. [Google Scholar] [CrossRef]
- Rupp, C.; Rayson, P.; Baron, A.; Donaldson, C.; Gregory, I.; Hardie, A.; Murrieta-Flores, P. Customising geoparsing and georeferencing for historical texts. In Proceedings of the IEEE International Conference on Big Data, Big Data, Silicon Valley, CA, USA, 6–9 October 2013; pp. 59–62. [Google Scholar]
- Tobin, R.; Grover, C.; Byrne, K.; Reid, J.; Walsh, J. Evaluation of Georeferencing. In Proceedings of the 6th Workshop on Geographic Information Retrieval; ACM: New York, NY, USA, 2010; pp. 1–8. [Google Scholar]
- Mani, I.; Hitzeman, J.; Richer, J.; Harris, D.; Quimby, R.; Wellner, B. SpatialML: Annotation Scheme, Corpora, and Tools. In Proceedings of the Sixth International Conference on Language Resources and Evaluation, LREC 2008, Marrakech, Morocco, 28–30 May 2008. [Google Scholar]
- Ardanuy, M.C.; Sporleder, C. Toponym disambiguation in historical documents using semantic and geographic features. In Proceedings of the 2nd International Conference on Digital Access to Textual Cultural Heritage, Göttingen, Germany, 1–2 June 2017; pp. 175–180. [Google Scholar]
- Pantaleo, G.; Nesi, P. Ge(o)Lo(cator): Geographic Information Extraction from Unstructured Text Data and Web Documents. In Proceedings of the 2014 9th International Workshop on Semantic and Social Media Adaptation and Personalization, Corfu, Greece, 6–7 November 2014; pp. 60–65. [Google Scholar]
- Martins, B.; Silva, M. A Graph-Ranking Algorithm for Geo-Referencing Documents. In Proceedings of the Fifth IEEE International Conference on Data Mining, Houston, TX, USA, 27–30 November 2005; pp. 741–744. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report 1999-66; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Silva, M.J.; Martins, B.; Chaves, M.; Afonso, A.P.; Nuno, C. Adding geographic scopes to web resources. Comput. Environ. Urban Syst. 2006, 30, 378–399. [Google Scholar] [CrossRef] [Green Version]
- Gelernter, J.; Zhang, W. Cross-lingual geo-parsing for non-structured data. In Proceedings of the 7th Workshop on Geographic Information Retrieval, Orlando, FL, USA, 5 November 2013; pp. 64–71. [Google Scholar]
- Moncla, L.; Renteria-Agualimpia, W.; Nogueras-Iso, J.; Gaio, M. Geocoding for texts with fine-grain toponyms: An experiment on a geoparsed hiking descriptions corpus. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas/Fort Worth, TX, USA, 4–7 November 2014; pp. 183–192. [Google Scholar]
- Molina-Villegas, A.; Siordia, O.S.; Aldana-Bobadilla, E.; Aguilar, C.A.; Acosta, O. Extracción automática de referencias geoespaciales en discurso libre usando técnicas de procesamiento de lenguaje natural y teoría de la accesibilidad. J. Nat. Lang. Process. 2019, 63, 143–146. [Google Scholar]
- Cucerzan, S.; Yarowsky, D. Language independent named entity recognition combining morphological and contextual evidence. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, College Park, MD, USA, 21–22 June 1999. [Google Scholar]
- Li, P.; Fu, T.; Ma, W. Why Attention? Analyze BiLSTM Deficiency and Its Remedies in the Case of NER. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI Press, 2020; pp. 8236–8244. [Google Scholar]
- Luo, Y.; Xiao, F.; Zhao, H. Hierarchical Contextualized Representation for Named Entity Recognition. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-2020), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Li, X.; Feng, J.; Meng, Y.; Han, Q.; Wu, F.; Li, J. A Unified MRC Framework for Named Entity Recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 5849–5859. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Horn, F. Context encoders as a simple but powerful extension of word2vec. arXiv 2017, arXiv:1706.02496. [Google Scholar]
- Trapala, J.A. Reconocimiento de Entidades Nombradas Georeferenciables con Word Embeddings. Master’s Thesis, Centro de Investigación en Matemáticas, Monterrey, Mexico, 2019. [Google Scholar]
- Amorim, M.; Antunes, F.; Ferreira, S.; Couto, A. An integrated approach for strategic and tactical decisions for the emergency medical service: Exploring optimization and metamodel-based simulation for vehicle location. Comput. Ind. Eng. 2019, 137, 106057. [Google Scholar] [CrossRef]
- Hsiao, Y.H.; Chen, M.C.; Liao, W.C. Logistics service design for cross-border E-commerce using Kansei engineering with text-mining-based online content analysis. Telemat. Inform. 2017, 34, 284–302. [Google Scholar] [CrossRef]






| RULE | DESCRIPTION | ANTECEDENT | CONSEQUENT |
|---|---|---|---|
| The entity to be processed (A) has a match in and is empty. |
| ||
| The entity to be processed (A) has a match in , is not empty, A is lower than the entity (T) at the top of and there is a relationship between A and T. |
| ||
| The entity to be processed (A) has a match in , is not empty, A is lower than the entity (T) at the top of and there is no relationship between A and T. |
| ||
| The entity to be processed (A) has a match in , is not empty, A is not lower than the entity (T) at the top of and there is a relationship between A and T. |
| ||
| The entity to be processed (A) does not have a match in , and is not empty. |
| ||
| The entity to be processed (A) does not have a match in , and is empty. |
| ||
| The entity to be processed (A) has a match in , is not empty, A is not lower than the entity (T) at the top of and there is no relationship between A and T. |
| ||
| There are no more entities from the text to be processed, but there are still entities in the conflicts stack . |
|
| Data | Description | Num. of Docs | Tags | Num. of Entities | Purpose |
|---|---|---|---|---|---|
| C1 | News documents from the main digital media in Mexico. | 165,354 | None | Unknown | Word Embeddings |
| C2 | News documents from the main digital media in Mexico. | 1233 | GNER | 5870 | GNER Model |
| C3 | Documents from a news agency (El gráfico) which is not included in the above corpora. | 500 | GNER Actual Coordinates Geographic levels | 1956 | Disambiguation |
| Accuracy | Precision | Recall | F-Measure | |
|---|---|---|---|---|
| word2vec | 0.9454 | 0.3953 | 0.07545 | 0.5348 |
| Global Encoder | 0.9633 | 0.7085 | 0.5663 | 0.8071 |
| Global & Local Encoder | 0.9626 | 0.7055 | 0.5761 | 0.8093 |
| ADM1 | PPLA | ADM2 | PPLA2 | PPL | LCTY | OTHER | NULL | |
|---|---|---|---|---|---|---|---|---|
| ADM1 | 222 | 1 | 2 | 0 | 8 | 0 | 1 | 2 |
| PPLA | 3 | 49 | 2 | 0 | 0 | 0 | 1 | 0 |
| ADM2 | 6 | 5 | 655 | 0 | 16 | 0 | 1 | 3 |
| PPLA2 | 2 | 3 | 0 | 73 | 0 | 0 | 0 | 1 |
| PPL | 2 | 0 | 6 | 1 | 265 | 0 | 1 | 11 |
| LCTY | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| OTHER | 14 | 0 | 4 | 1 | 4 | 0 | 26 | 5 |
| NULL | 17 | 5 | 17 | 2 | 28 | 0 | 2 | 488 |
| Accuracy | Recall | F-Measure | Precision | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unseen | Micro | Macro | Micro | Macro | Micro | Macro | ||||
| News corpus | 0.9089 | 0.9089 | 0.7489 | 0.9089 | 0.7493 | 0.9089 | 0.7634 | |||
| All Entities | Only Georeferenced Entities | ||||||||||
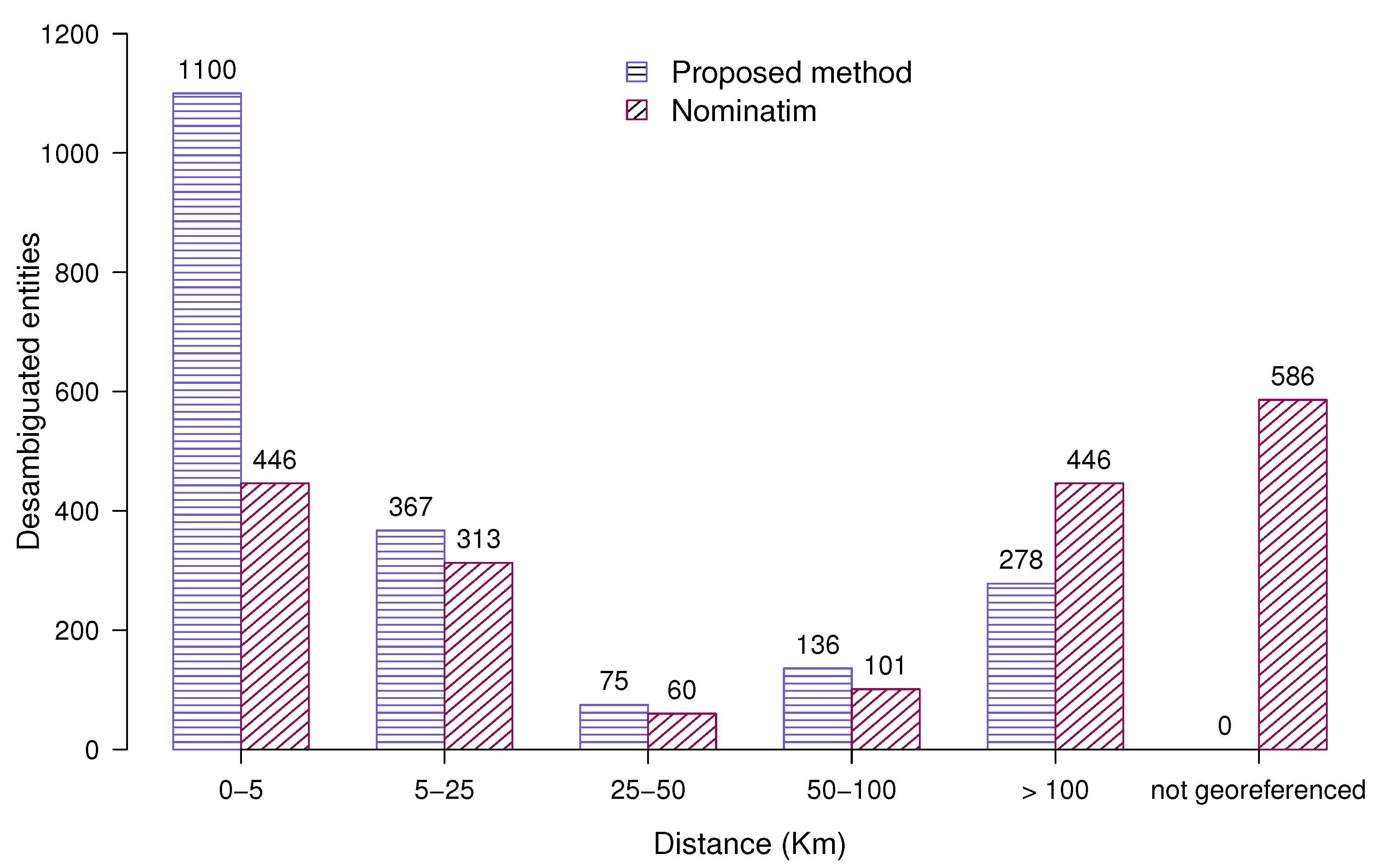
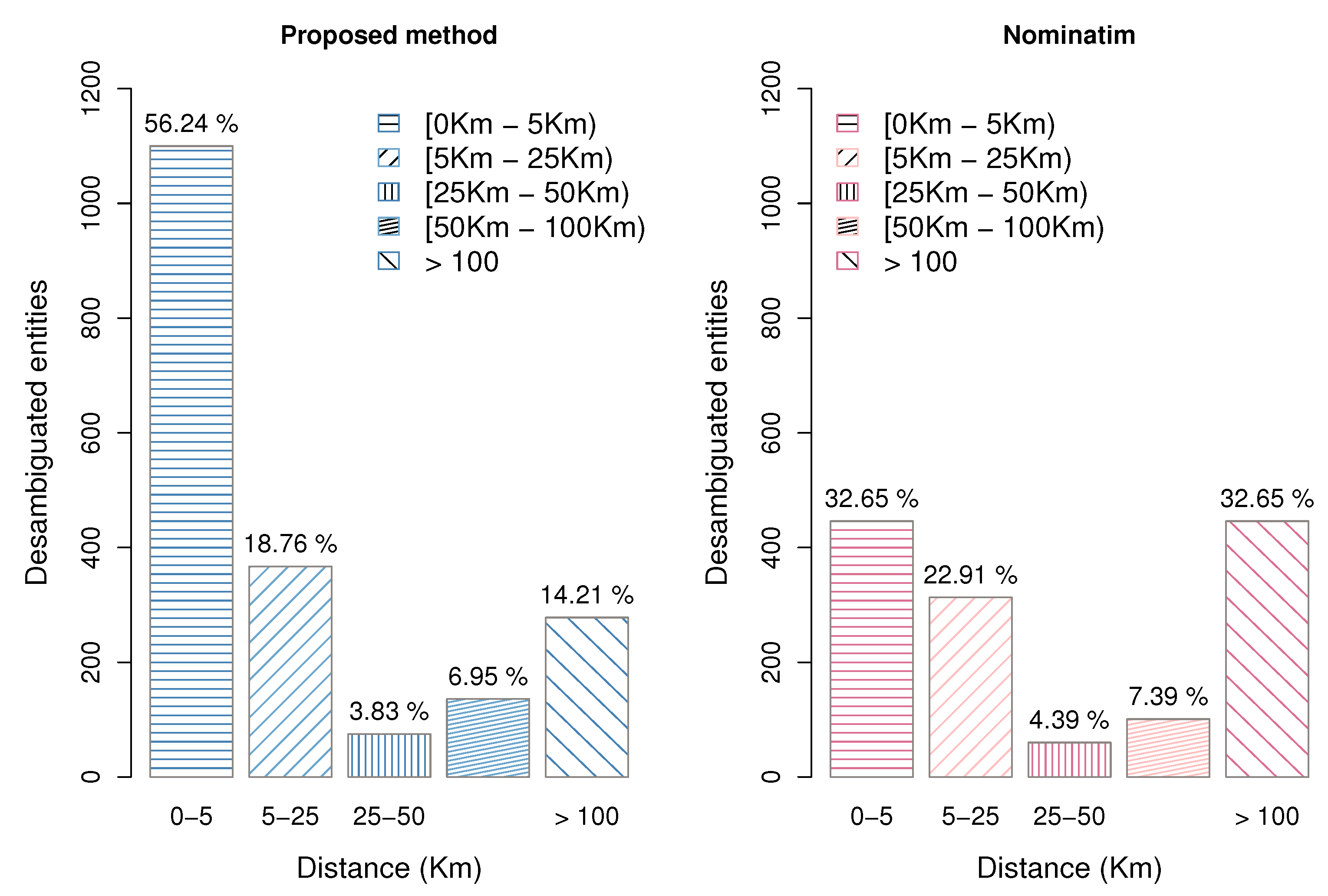
|---|---|---|---|---|---|---|---|---|---|---|---|
| Proposed Method | Nominatim | Proposed Method | Nominatim | ||||||||
| Distance Range to the | No. of Entities | No. of Entities | No. of Entities | No. of Entities | |||||||
| Actual Coordinates (km) | |||||||||||
| [0–5) | 1100 | 56.24% | 446 | 22.80% | 1100 | 56.24% | 446 | 32.65% | |||
| [5–25) | 367 | 18.76% | 313 | 16.00% | 367 | 18.76% | 313 | 22.91% | |||
| [25–50) | 75 | 3.83% | 60 | 3.06% | 75 | 3.83% | 60 | 4.39% | |||
| [50–100) | 136 | 6.95% | 101 | 5.16% | 136 | 6.95% | 101 | 7.39% | |||
| [100–2000) | 278 | 14.21% | 446 | 22.80% | 278 | 14.21% | 446 | 32.65% | |||
| Not georeferenced | 0 | 0% | 594 | 30.36% | - | - | - | - | |||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldana-Bobadilla, E.; Molina-Villegas, A.; Lopez-Arevalo, I.; Reyes-Palacios, S.; Muñiz-Sanchez, V.; Arreola-Trapala, J. Adaptive Geoparsing Method for Toponym Recognition and Resolution in Unstructured Text. Remote Sens. 2020, 12, 3041. https://doi.org/10.3390/rs12183041
Aldana-Bobadilla E, Molina-Villegas A, Lopez-Arevalo I, Reyes-Palacios S, Muñiz-Sanchez V, Arreola-Trapala J. Adaptive Geoparsing Method for Toponym Recognition and Resolution in Unstructured Text. Remote Sensing. 2020; 12(18):3041. https://doi.org/10.3390/rs12183041
Chicago/Turabian StyleAldana-Bobadilla, Edwin, Alejandro Molina-Villegas, Ivan Lopez-Arevalo, Shanel Reyes-Palacios, Victor Muñiz-Sanchez, and Jean Arreola-Trapala. 2020. "Adaptive Geoparsing Method for Toponym Recognition and Resolution in Unstructured Text" Remote Sensing 12, no. 18: 3041. https://doi.org/10.3390/rs12183041
APA StyleAldana-Bobadilla, E., Molina-Villegas, A., Lopez-Arevalo, I., Reyes-Palacios, S., Muñiz-Sanchez, V., & Arreola-Trapala, J. (2020). Adaptive Geoparsing Method for Toponym Recognition and Resolution in Unstructured Text. Remote Sensing, 12(18), 3041. https://doi.org/10.3390/rs12183041