Object Detection in UAV Images via Global Density Fused Convolutional Network



Abstract
:1. Introduction
- We propose a novel global density fused convolutional network (GDF-Net) for object detection in UAV images, which cascades a novel Global Density Model to base networks. Via the application of GDM, the proposed GDF-Net achieves a distribution learning that integrates global patterns from the input image with features extracted by existing object detection networks.
- We introduce a novel Global Density Model into the base networks to improve the performance of object detection in UAV images. GDM applies dilated convolutional networks to deliver large reception fields, facilitating the learning of global patterns in targets.
2. Related Work
3. Methodology
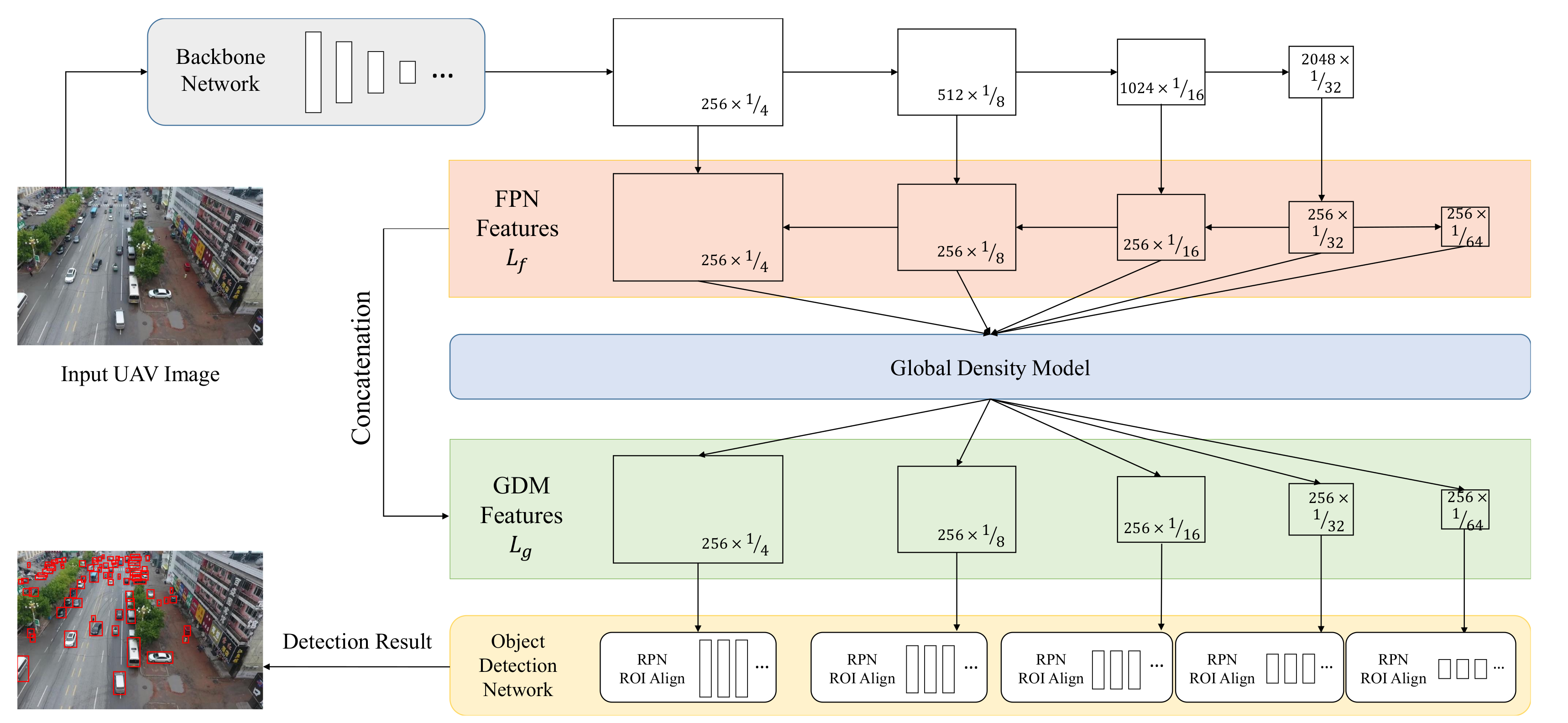
3.1. Approach Overview
3.2. Backbone Network
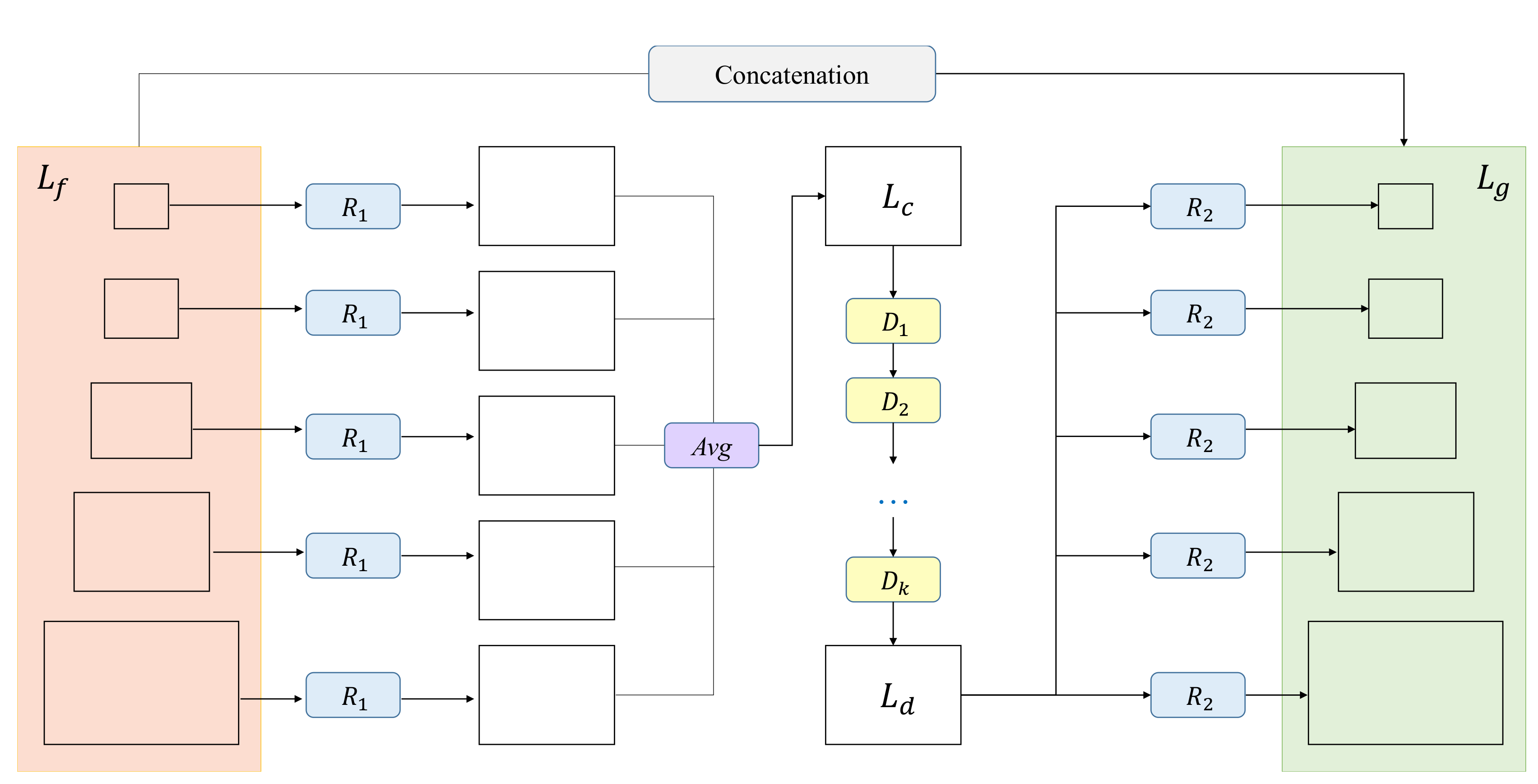
3.3. Global Density Model (GDM)
3.4. Object Detection Network
4. Experimental Results and Analysis
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Evaluation of Gdf-Net
4.2.1. Quantitative Evaluation
4.2.2. Qualitative Evaluation
4.2.3. Sensitivity Analysis
5. Limitations and Future Directions
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, R.; Li, H.; Duan, K.; You, S.; Liu, K.; Wang, F.; Hu, Y. Automatic Detection of Earthquake-Damaged Buildings by Integrating UAV Oblique Photography and Infrared Thermal Imaging. Remote Sens. 2020, 12, 2621. [Google Scholar] [CrossRef]
- Zhou, G.; Ambrosia, V.; Gasiewski, A.J.; Bland, G. Foreword to the special issue on unmanned airborne vehicle (UAV) sensing systems for earth observations. IEEE Trans. Geosci. Remote Sens. 2009, 47, 687–689. [Google Scholar] [CrossRef]
- Hird, J.N.; Montaghi, A.; McDermid, G.J.; Kariyeva, J.; Moorman, B.J.; Nielsen, S.E.; McIntosh, A. Use of unmanned aerial vehicles for monitoring recovery of forest vegetation on petroleum well sites. Remote Sens. 2017, 9, 413. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Li, C.; Li, D.; Altan, O.; Zhang, L.; Ding, L. An Accurate Matching Method for Projecting Vector Data into Surveillance Video to Monitor and Protect Cultivated Land. ISPRS Int. J. Geo-Inf. 2020, 9, 448. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep Learning Based Oil Palm Tree Detection and Counting for High-Resolution Remote Sensing Images. Remote Sens. 2016, 9, 22. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, Y.; Yu, J.G.; Tan, Y.; Tian, J.; Ma, J. A novel spatio-temporal saliency approach for robust dim moving target detection from airborne infrared image sequences. Inf. Sci. 2016, 369, 548–563. [Google Scholar] [CrossRef]
- Kapania, S.; Saini, D.; Goyal, S.; Thakur, N.; Jain, R.; Nagrath, P. Multi Object Tracking with UAVs using Deep SORT and YOLOv3 RetinaNet Detection Framework. In Proceedings of the 1st ACM Workshop on Autonomous and Intelligent Mobile Systems, Aviero, Portugal, 25–27 June 2020; pp. 1–6. [Google Scholar]
- Benjamin, K.; Diego, M.; Devis, T. Detecting Mammals in UAV Images: Best Practices to address a substantially Imbalanced Dataset with Deep Learning. Remote Sens. Environ. 2018, 216, 139–153. [Google Scholar]
- Kellenberger, B.; Volpi, M.; Tuia, D. Fast animal detection in UAV images using convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Gu, J.; Su, T.; Wang, Q.; Du, X.; Guizani, M. Multiple Moving Targets Surveillance Based on a Cooperative Network for Multi-UAV. IEEE Commun. Mag. 2018, 56, 82–89. [Google Scholar] [CrossRef]
- Meng, L.; Peng, Z.; Zhou, J.; Zhang, J.; Lu, Z.; Baumann, A.; Du, Y. Real-Time Detection of Ground Objects Based on Unmanned Aerial Vehicle Remote Sensing with Deep Learning: Application in Excavator Detection for Pipeline Safety. Remote Sens. 2020, 12, 182. [Google Scholar] [CrossRef] [Green Version]
- Qian, X.; Lin, S.; Cheng, G.; Yao, X.; Wang, W. Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion. Remote Sens. 2020, 12, 143. [Google Scholar] [CrossRef] [Green Version]
- Wang, G. Vision-Based Real-Time Aerial Object Localization and Tracking for UAV Sensing System. IEEE Access 2017, 5, 23969–23978. [Google Scholar]
- Cong, M.; Han, L.; Ding, M.; Xu, M.; Tao, Y. Salient man-made object detection based on saliency potential energy for unmanned aerial vehicles remote sensing image. Geocarto Int. 2019, 34, 1634–1647. [Google Scholar] [CrossRef]
- Portmann, J.; Lynen, S.; Chli, M.; Siegwart, R. People detection and tracking from aerial thermal views. In Proceedings of the IEEE international conference on robotics and automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1794–1800. [Google Scholar]
- Bazi, Y.; Melgani, F. Convolutional SVM networks for object detection in UAV imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3107–3118. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Papadomanolaki, M.; Vakalopoulou, M.; Karantzalos, K. A novel object-based deep learning framework for semantic segmentation of very high-resolution remote sensing data: Comparison with convolutional and fully convolutional networks. Remote Sens. 2019, 11, 684. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Zhou, W.; Deng, X.; Zhang, M.; Cheng, Q. Multilabel Remote Sensing Image Retrieval Based on Fully Convolutional Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 318–328. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A Fully Convolutional Neural Network for Automatic Building Extraction From High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Wang, X.; Cheng, P.; Liu, X.; Uzochukwu, B. Fast and accurate, convolutional neural network based approach for object detection from UAV. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3171–3175. [Google Scholar]
- Aguilar, W.G.; Quisaguano, F.J.; Rodríguez, G.A.; Alvarez, L.G.; Limaico, A.; Sandoval, D.S. Convolutional neuronal networks based monocular object detection and depth perception for micro UAVs. In International Conference on Intelligent Science and Big Data Engineering; Springer: Berlin/Heidelberg, Germany, 2018; pp. 401–410. [Google Scholar]
- Carrio, A.; Vemprala, S.; Ripoll, A.; Saripalli, S.; Campoy, P. Drone detection using depth maps. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1034–1037. [Google Scholar]
- Chen, C.; Zhang, Y.; Lv, Q.; Wei, S.; Dong, J. RRNet: A Hybrid Detector for Object Detection in Drone-Captured Images. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Seoul, Korea, 27–28 October 2019; pp. 100–108. [Google Scholar]
- Zhang, X.; Izquierdo, E.; Chandramouli, K. Dense and Small Object Detection in UAV Vision Based on Cascade Network. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Seoul, Korea, 27–28 October 2019; pp. 118–126. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1091–1100. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Ling, H.; Hu, Q.; Nie, Q.; Cheng, H.; Liu, C.; Liu, X.; et al. Visdrone-det2018: The vision meets drone object detection in image challenge results. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ji, R.; Ye, Q. FreeAnchor: Learning to Match Anchors for Visual Object Detection. In Neural Information Processing Systems (NIPS); NIPS: Grenada, Spain, 2019. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Kalantar, B.; Mansor, S.B.; Halin, A.A.; Shafri, H.Z.M.; Zand, M. Multiple Moving Object Detection from UAV Videos Using Trajectories of Matched Regional Adjacency Graphs. IEEE Trans. Geosci. Remote Sens. 2017, 1–16. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2016; pp. 354–370. [Google Scholar]
- Yang, B.; Yan, J.; Lei, Z.; Li, S.Z. Craft objects from images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 6043–6051. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Najibi, M.; Rastegari, M.; Davis, L.S. G-cnn: An iterative grid based object detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2369–2377. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Chen, Y.; Xue, X. Dsod: Learning deeply supervised object detectors from scratch. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1919–1927. [Google Scholar]
- Kyrkou, C.; Plastiras, G.; Theocharides, T.; Venieris, S.I.; Bouganis, C.S. DroNet: Efficient convolutional neural network detector for real-time UAV applications. In Proceedings of the Design, Automation and Test in Europe Conference and Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 967–972. [Google Scholar]
- Li, Y.; Dong, H.; Li, H.; Zhang, X.; Zhang, B.; Xiao, Z. Multi-block SSD Based Small Object Detection for UAV Railway Scene Surveillance. Chin. J. Aeronaut. 2020. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, J.; Zhuo, L.; Li, Y.; Tian, Q. Small Object Detection in Unmanned Aerial Vehicle Images Using Feature Fusion and Scaling-Based Single Shot Detector With Spatial Context Analysis. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1758–1770. [Google Scholar] [CrossRef]
- Tijtgat, N.; Ranst, W.V.; Volckaert, B.; Goedeme, T.; Turck, F.D. Embedded Real-Time Object Detection for a UAV Warning System. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, P.; Zhong, Y.; Li, X. SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Seoul, Korea, 27–28 October 2019; pp. 37–45. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010, Paris, France, 22–27 August 2010. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Seattle, WA, USA, 14 June 2020; pp. 10781–10790. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4974–4983. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn. Res. 2010, 9, 249–256. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-aware R-CNN: detecting pedestrians in a crowd. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 637–653. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1222–1230. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | 31.0 | 17.5 | 17.2 | 8.0 | 26.9 | 34.9 | 7.8 | 23.5 | 28.2 | 16.5 | 42.8 | 50.3 |
| Faster GDF (ours) | 31.8 | 17.9 | 17.7 | 8.2 | 27.7 | 35.8 | 7.9 | 23.8 | 28.8 | 17.0 | 43.7 | 49.7 |
| Cascade R-CNN | 31.1 | 19.3 | 18.3 | 8.5 | 28.3 | 36.3 | 8.2 | 23.8 | 28.4 | 16.8 | 42.7 | 50.2 |
| Cascade GDF (ours) | 31.7 | 19.4 | 18.7 | 8.7 | 28.7 | 38.7 | 8.4 | 24.2 | 28.8 | 17.0 | 43.5 | 52.4 |
| Free Anchor | 27.9 | 15.8 | 15.6 | 7.1 | 23.7 | 28.8 | 7.0 | 22.1 | 29.9 | 18.8 | 41.9 | 55.1 |
| Free Anchor GDF (ours) | 28.5 | 16.0 | 15.9 | 7.2 | 23.7 | 33.5 | 7.1 | 22.1 | 29.9 | 18.7 | 41.8 | 56.0 |
| Grid R-CNN | 30.4 | 18.9 | 17.9 | 8.3 | 27.8 | 35.7 | 8.1 | 23.9 | 28.5 | 17.2 | 42.8 | 49.7 |
| Grid GDF (ours) | 30.8 | 19.2 | 18.2 | 8.6 | 27.9 | 37.9 | 8.1 | 24.1 | 28.7 | 17.3 | 43.0 | 52.8 |
| Method | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | 25.8 | 14.7 | 14.4 | 9.1 | 25.2 | 21.8 | 13.2 | 22.5 | 27.3 | 14.8 | 42.9 | 40.6 |
| Faster GDF (ours) | 27.5 | 16.7 | 15.6 | 9.6 | 27.1 | 25.4 | 13.4 | 23.6 | 28.2 | 15.4 | 44.2 | 42.3 |
| Cascade R-CNN | 25.3 | 16.0 | 14.8 | 9.7 | 25.2 | 28.0 | 12.3 | 22.0 | 26.6 | 15.6 | 40.7 | 45.0 |
| Cascade GDF (ours) | 26.0 | 16.2 | 15.0 | 9.4 | 26.1 | 23.1 | 12.4 | 22.4 | 27.1 | 14.8 | 42.4 | 44.4 |
| Free Anchor | 27.9 | 16.0 | 15.6 | 9.9 | 26.5 | 22.9 | 13.9 | 24.5 | 29.4 | 16.3 | 45.4 | 40.3 |
| Free Anchor GDF (ours) | 27.9 | 16.3 | 15.7 | 9.5 | 27.5 | 25.0 | 14.3 | 24.8 | 29.4 | 15.8 | 46.4 | 39.4 |
| Grid R-CNN | 24.5 | 15.7 | 14.4 | 8.7 | 25.4 | 25.5 | 12.2 | 22.5 | 27.0 | 15.2 | 42.1 | 40.6 |
| Grid GDF (ours) | 26.1 | 17.0 | 15.4 | 8.9 | 27.3 | 24.4 | 13.2 | 23.1 | 27.6 | 15.2 | 43.3 | 40.9 |
| Experiment | Params | FLOPs | Speed | |
|---|---|---|---|---|
| Faster R-CNN | 25.8 | 41.2 M | 118.8 GMac | 23.7 fps |
| Faster GDF (ours) | 27.5 | 48.9 M | 135.1 GMac | 21.1 fps |
| Cascade R-CNN | 25.3 | 69.0 M | 146.6 GMac | 17.6 fps |
| Cascade GDF (ours) | 26.0 | 76.7 M | 162.8 GMac | 16.2 fps |
| Free Anchor | 27.9 | 36.3 M | 113.5 GMac | 24.3 fps |
| Free Anchor GDF (ours) | 27.9 | 44.0 M | 117.6 GMac | 22.6 fps |
| Grid R-CNN | 24.5 | 64.3 M | 241.4 GMac | 19.4 fps |
| Grid GDF (ours) | 26.1 | 72.0 M | 257.6 GMac | 17.9 fps |
| Method | Para | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster GDF | r = 1 | 31.7 | 17.8 | 17.7 | 8.2 | 27.5 | 35.2 | 7.8 | 23.6 | 28.5 | 16.8 | 43.4 | 50.5 |
| Faster GDF | r = 2 | 31.8 | 17.9 | 17.7 | 8.2 | 27.7 | 35.8 | 7.9 | 23.8 | 28.8 | 17.0 | 43.7 | 49.7 |
| Faster GDF | r = 3 | 31.5 | 18.0 | 17.6 | 8.0 | 27.6 | 34.8 | 7.9 | 23.7 | 28.7 | 16.8 | 43.7 | 49.4 |
| Cascade GDF | r = 1 | 31.2 | 19.2 | 18.4 | 8.5 | 28.3 | 36.9 | 8.1 | 23.9 | 28.6 | 16.8 | 43.0 | 52.3 |
| Cascade GDF | r = 2 | 31.7 | 19.4 | 18.7 | 8.7 | 28.7 | 38.7 | 8.4 | 24.2 | 28.8 | 17.0 | 43.5 | 52.4 |
| Cascade GDF | r = 3 | 31.7 | 19.8 | 18.7 | 8.5 | 29.1 | 38.7 | 8.4 | 24.2 | 28.8 | 16.9 | 43.8 | 50.9 |
| Grid GDF | r = 1 | 30.6 | 19.0 | 18.0 | 8.4 | 27.8 | 36.7 | 8.0 | 24.1 | 28.8 | 16.5 | 42.8 | 50.3 |
| Grid GDF | r = 2 | 30.8 | 19.2 | 18.2 | 8.6 | 27.9 | 37.9 | 8.1 | 24.1 | 28.7 | 17.3 | 43.3 | 50.9 |
| Grid GDF | r = 3 | 30.5 | 19.3 | 18.2 | 8.4 | 28.0 | 37.3 | 8.1 | 24.2 | 28.7 | 17.5 | 43.2 | 51.4 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Shao, Z.; Huang, X.; Wang, J.; Li, D. Object Detection in UAV Images via Global Density Fused Convolutional Network. Remote Sens. 2020, 12, 3140. https://doi.org/10.3390/rs12193140
Zhang R, Shao Z, Huang X, Wang J, Li D. Object Detection in UAV Images via Global Density Fused Convolutional Network. Remote Sensing. 2020; 12(19):3140. https://doi.org/10.3390/rs12193140
Chicago/Turabian StyleZhang, Ruiqian, Zhenfeng Shao, Xiao Huang, Jiaming Wang, and Deren Li. 2020. "Object Detection in UAV Images via Global Density Fused Convolutional Network" Remote Sensing 12, no. 19: 3140. https://doi.org/10.3390/rs12193140
APA StyleZhang, R., Shao, Z., Huang, X., Wang, J., & Li, D. (2020). Object Detection in UAV Images via Global Density Fused Convolutional Network. Remote Sensing, 12(19), 3140. https://doi.org/10.3390/rs12193140