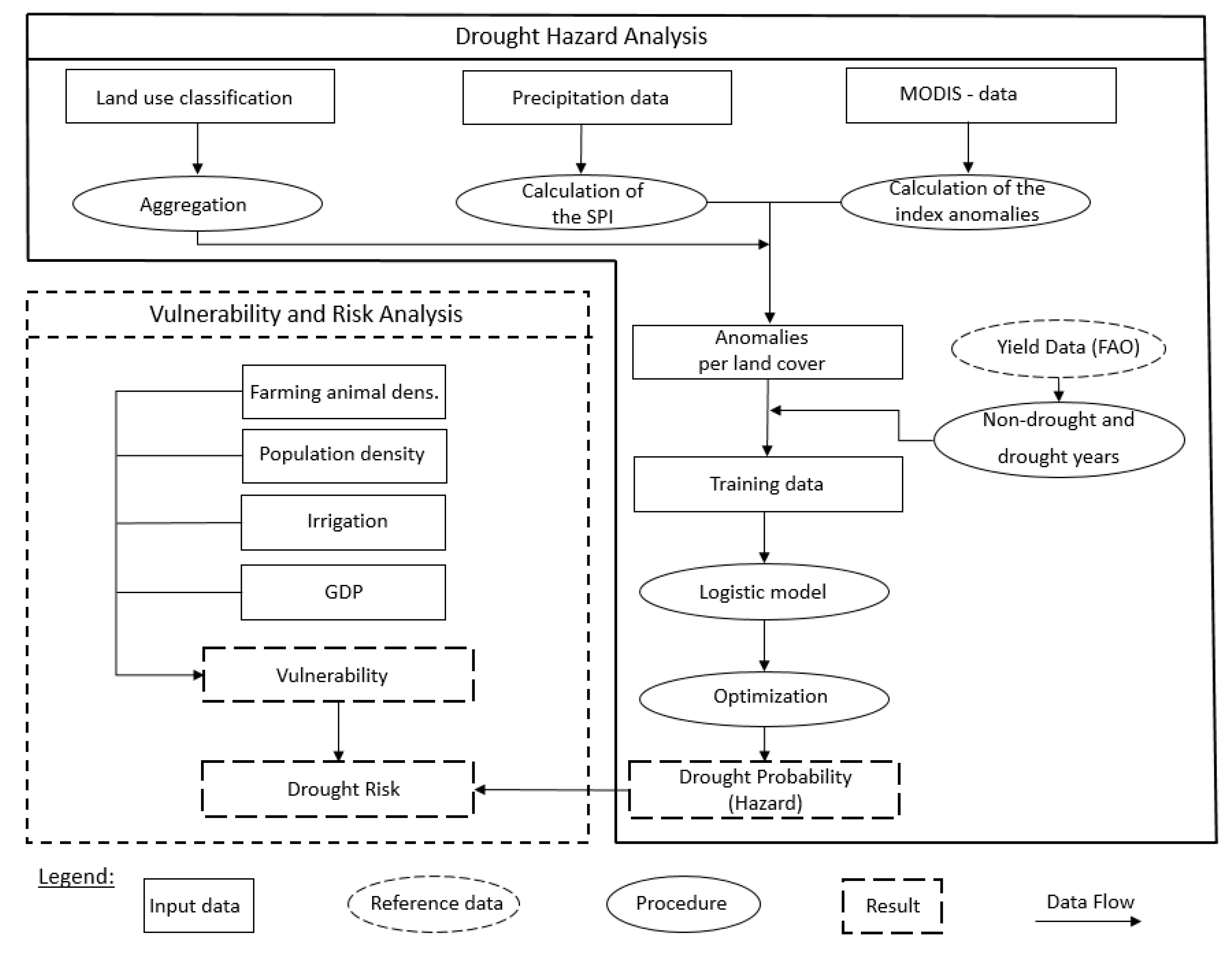
2.3.1. Drought Hazard Analysis
(1) Processing and Calculation of the Model Predictors
The precipitation data was used to produce the Standardized Precipitation Index (SPI), with the methodology from Mckee et al. [
40]. The study at hand used the three-monthly SPI. For each month, rainfall data from the present month and the two previous months was accumulated from 1981 to 2017 before the SPI was calculated.
The MODIS data was processed differently for each product. The 8-day composites of the MOD09A1 product were corrected with the quality state flags to remove cloudy pixels. Subsequently, the Normalized Difference Vegetation Index (NDVI) [
41] and the Normalized Difference Infrared Index (NDII) [
22] were produced from the cloud masked MODIS bands between 2001 and 2017 at its original spatial resolution of 500 m. The indices were processed by calculating their monthly maxima and thus further reducing cloud influence [
42]. The 8-day composites of the MOD11A2 product, on the other hand, were not corrected for clouds since the land surface temperature (LST) was only produced for cloud-free pixels [
43]. Monthly maxima were also calculated for the LST. The 16-day composite MOD43A3 albedo product was selected on the 15th of each month and was assumed to be the monthly mean. From the MODIS albedo product, the mean of all three albedo bands (visual, near infrared, short wave infrared) was calculated and used as an input variable in this study.
In addition, index anomalies were produced to develop a normalized and spatially invariant measure that reduces the influence of spatially varying vegetation and land cover types. This was done for all MODIS-based indices used as model predictors (NDVI, NDII, LST, mean albedo). The anomalies were calculated as the deviation of the long-term mean standardized with the standard deviation (“
z-score”) [
22]:
Zkxy represents the anomaly value for kernel k during the time span x, which was 2001–2017 in this study, for a given month y. DIkxy stands for the drought index value for kernel k during the time span x in month y and αkx und σkx represent the mean and standard deviation of kernel k over the time span x. The index anomalies were then used as predictors for the logistic regression model.
(2) Identification of Drought Periods
After the vegetation and rainfall index anomalies were derived, they were masked with the aggregated land use classification (
Figure 1). Subsequently, drought and non-drought periods were determined within the growing periods of the main crops maize, green maize, sorghum, soybean, and wheat. For the USA, the growing season was assumed to last from May to September and for southern Africa from November to March. Drought periods were identified as drought seasons or drought years, using a segmented regression of the FAO’s annual yield data [
29]. Long term shifts in the total yield are possible for example due to advances in technologization, widespread use of fertilizers or the implementation of irrigation. To consider these shifts in the modeling framework, the regression divided the time series into several segments and assigned a stable regression relationship to each segment [
44]. Considering a standardized linear regression model
where
yi represents the estimate of the linear relationship of the response to
xi that includes the yield observations sorted by time
i after applying ordinary least squares to the linear regression model.
βi represents the linear parameter estimates and
ui the constant. Assuming that there are
m breakpoints, this model changes to
where
j represents the segment index. Zeileis et al. [
44] developed an algorithm in “
R”, a software environment for statistical computing, to automatically determine these breakpoints, which was used in this study. It was assumed that a segment would last a minimum of four years. This limits the total number of breakpoints for each crop type in each study area to three, given the assessed time period spans 2001 to 2017. Muggeo [
45] transcribed the segmented regression model as a function in
R that could be applied to the data using the breakpoints defined from the breakpoint analysis. In each study area, the residuals of the model for each crop type were subsequently determined individually and then accumulated. The five crops used in this study stand as representatives for the total agricultural yield in the three study areas. The standard deviation was calculated from the summed residuals in each region. The growing periods where residuals fell below one negative standard deviation were defined as drought years or periods. Non-drought years were periods in which the residuals exceeded one positive standard deviation. Any growing periods with values with a standard deviation between −1 and 1 were not considered, in order to ensure clean and distinctive training classes for the model. As a result, the drought years identified for model parametrization were only those years where a large-scale drought caused yield deficits and which affected the entire country during each respective growing period. A potential effect of yield losses caused by floods, pests or diseases (other than drought effects) in the training data was minimized by considering not only one crop type to determine drought, but rather five crop types. Since national yearly yield statistics for five crop types were used to identify a drought year, potential effects from small scale yield losses of non-drought causes on the training data are minimized. The drought and non-drought periods identified between 2001 and 2010 served as training data for the logistic regression model described in the following section.
(3) Logistic Regression Model
Binary logistic modeling has been successfully proven in numerous studies using remote sensing variables as predictors. Such models are also known to render robust variable relevancies, when correlation among variables is accounted for [
46,
47].
For the identified drought and non-drought years, monthly anomaly data from the NDVI, NDII, LST, albedo and 3-month SPI data were extracted for the relevant land use classes in the 2001–2010 training period for all months of the growing season. 2011 to 2017 was used to test the model. The anomalies were resampled to a spatial resolution of 0.01° and used as predictors for the logistic regression model (
Figure 1). Thus, each pixel classified as agricultural, grass or bushland was defined as either a drought or a non-drought observation within the entire study area over the entire respective crop growing season. A random sample of 100,000 pixels (=observations) was taken per class (drought or non-drought) as training data.
Subsequently, the five input indices were tested for autocorrelation and multicollinearity using a Pearson correlation matrix and the condition index. Dormann et al. [
48] suggest that a threshold of 0.7 in the pairwise Pearson correlation matrix indicates variables that strongly influence the model. For the condition index, values that exceed a value of 30 are considered critical and indicate strong multicollinearity [
48]. Only variables that exhibited no multicollinearity according to the Pearson correlation and the condition index were included in the model as predictors. A logistic model was used to predict a binary classification of the dependent variable y (drought or non-drought). The probability produced by the logistic model with values between 0 and 1 were considered to be drought hazard. The calculation of the probability values
p(
X), that are translated into drought hazard, are defined using the logistic function [
49]:
with a linear regression function as basis [
49]:
After setting up the model, the
z and
p values of the individual predictors were analyzed. High
z values (>|+/−2|) indicate a decisive influence of the variable on the modeling results. This finding can be confirmed with significant
p values (<0.01) [
49].
To evaluate the goodness of fit for the logistic regression model McFadden’s Pseudo
R² was used [
50]:
lM represents the log-likelihood of the estimated model and
l0 the log-likelihood of the zero model, which consists of only one constant. Values greater than 0 indicate predictive qualities of the model, while 1 reflects a perfect predictive power [
50]. The values of McFadden’s Pseudo
R² are generally much lower than those of the
R² of general linear regression models. Values between 0.2 and 0.4 indicate an excellent model fit for McFadden’s Pseudo
R² [
51].
(4) Verification of the model results
In addition to the statistical evaluation described above, the model was also checked for plausibility. The Missouri Basin study area in the USA was the only site, where an operational drought model (USDM) was available. The USDM is recognized as an advanced tool for drought monitoring in science (e.g., [
12]). The data is produced by the National Drought Mitigation Center of the University of Nebraska-Lincoln, the United States Department of Agriculture, and the National Oceanic and Atmospheric Administration and is available on the USDM’s homepage (
http://droughtmonitor.unl.edu/Data/Datadownload/ComprehensiveStatistics.aspx). A visual comparison between the USDM maps and those produced by the logistic regression model provided a qualitative assessment of the model’s plausibility.
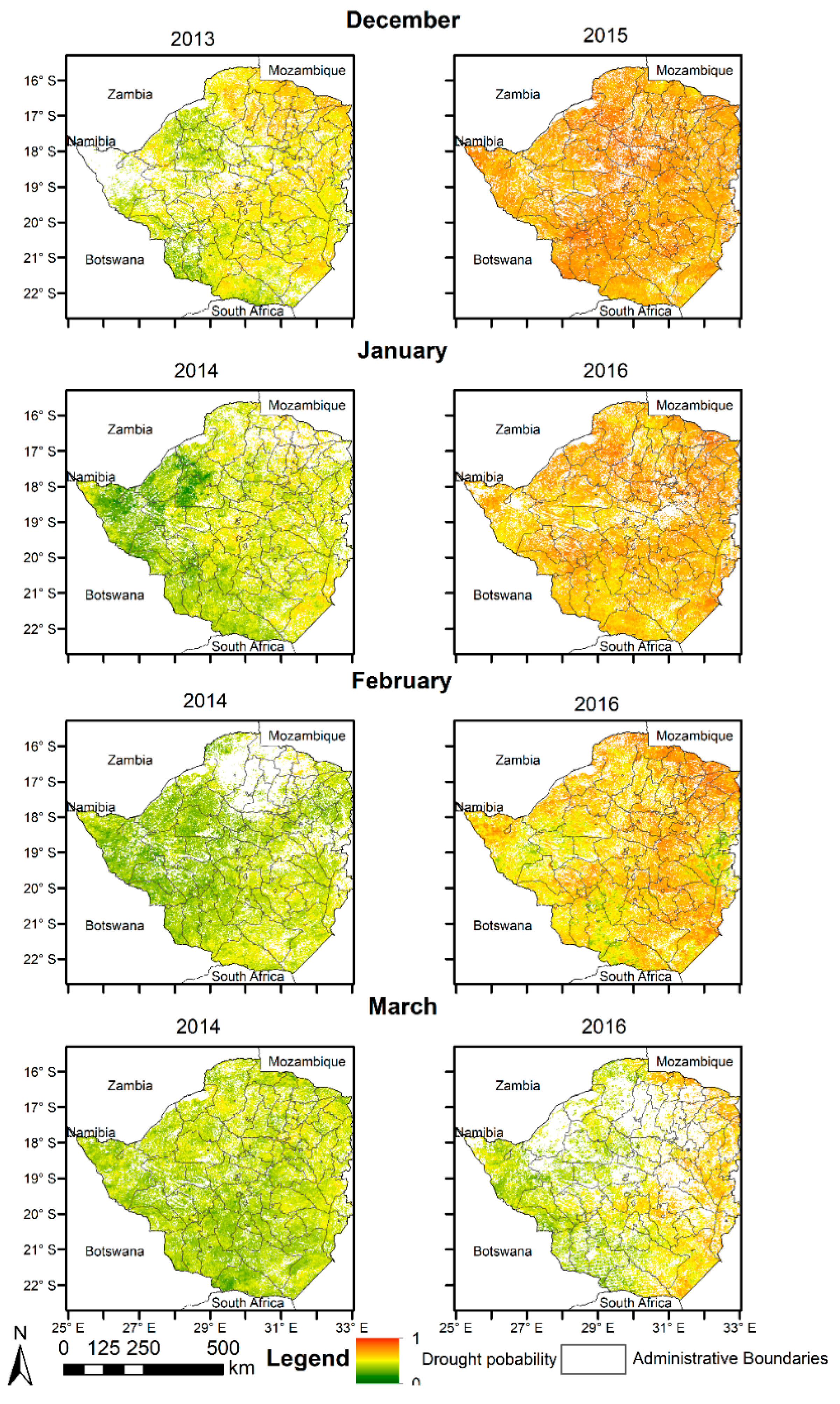
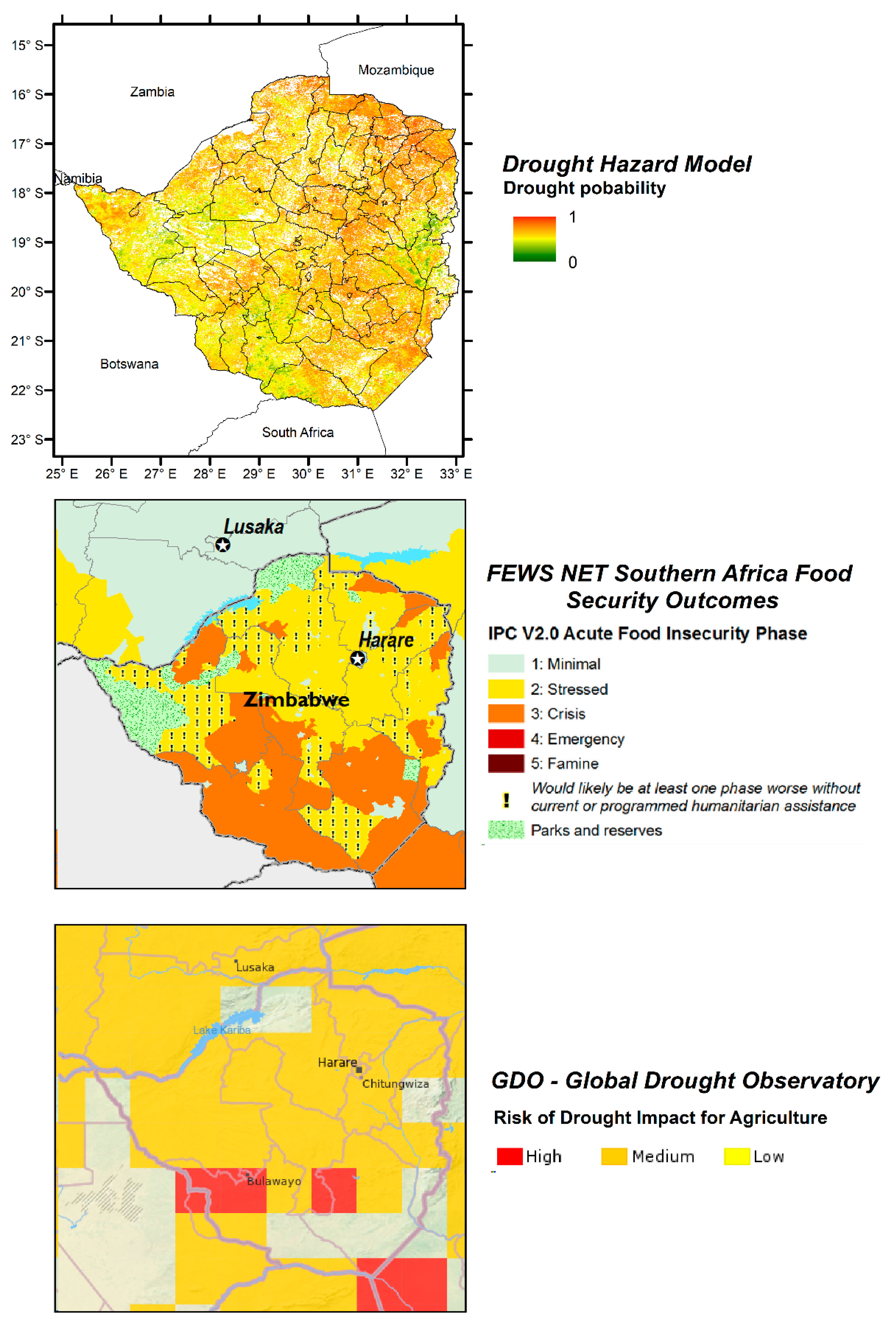
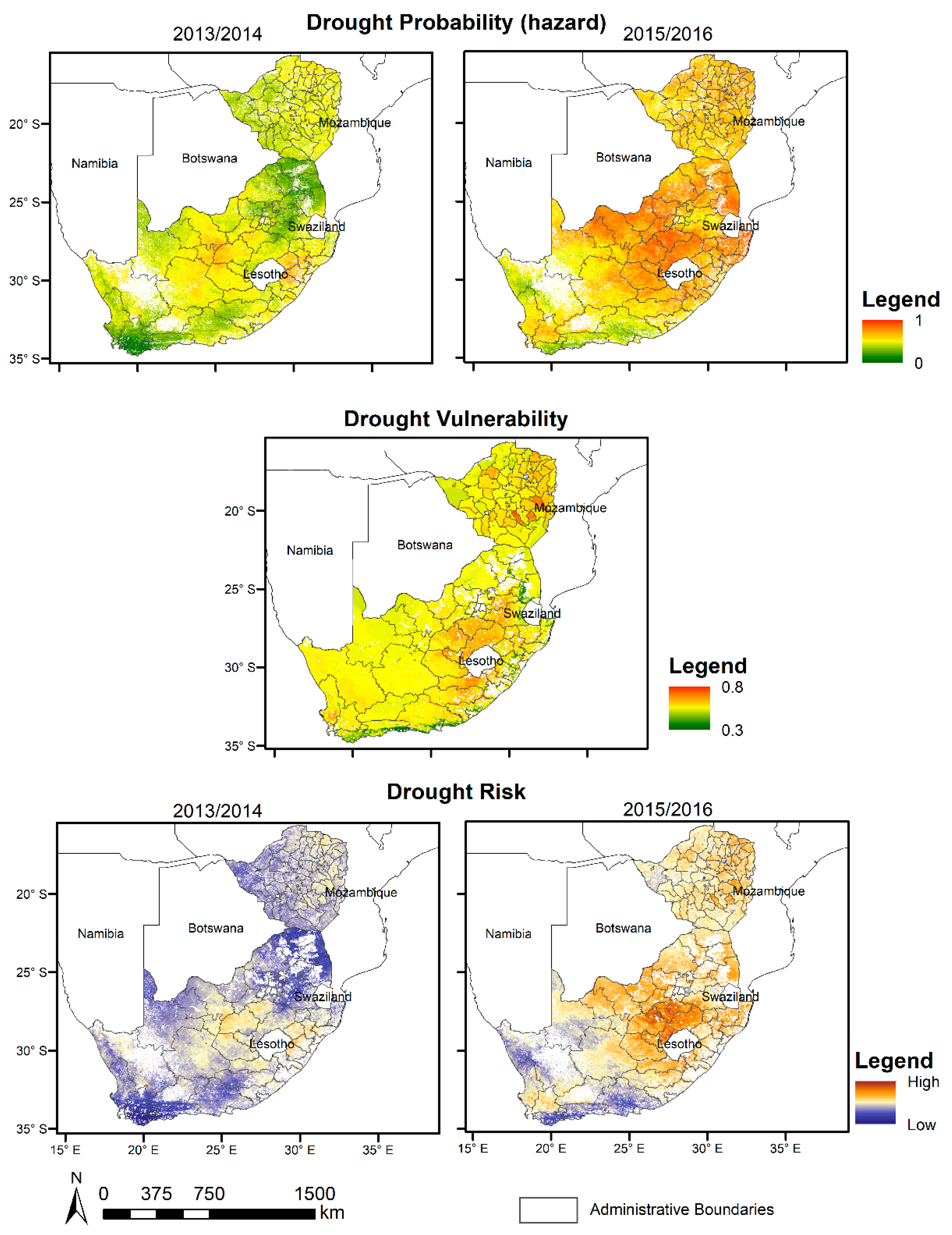
Due to the lack of spatial drought information besides global drought models, the verification in South Africa and Zimbabwe was based on newspaper reports and reports from aid agencies published in the World Wide Web (e.g., BBC News) about time periods and areas affected by drought. In addition, model results were compared against occurrence information of El Niño events, as teleconnections of the El Niño phenomenon are known to cause drought in southern Africa [
52]. By comparing the data to the teleconnections caused by the El Niño and the drought reports, the model plausibility was assessed for Zimbabwe and South Africa. Finally, the model output was also compared to the Global Drought Observatory provided by the Joint Research Center (JRC) with the key input variables derived from meteorological, soil moisture and vegetation greenness data for drought hazard, population data and baseline water stress for drought exposure and social, economic and infrastructural factors like the level of well-being of individuals for vulnerability. Additionally, we used food security classification data from the Famine Early Warning Systems Network (FEWS NET) for Zimbabwe as a cross-verification source for the drought hazard model.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}