A Pseudo-Label Guided Artificial Bee Colony Algorithm for Hyperspectral Band Selection



Abstract
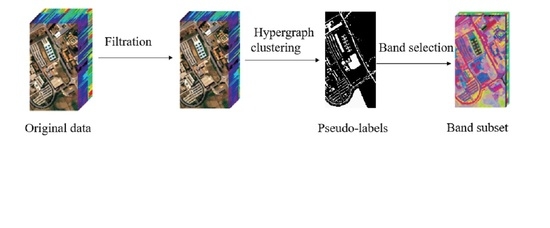
1. Introduction
- Designing a noise filtering mechanism based on grid division. By deleting those noise bands, this method can ensure the accuracy of generated pseudo-labels.
- Proposing a hypergraph evolutionary clustering to generate pseudo-labels. By replacing traditional pixels by the centers of super-pixels, this technology significantly reduces the computational cost of generating pseudo-labels, and the designed multi-population ABC obviously improves the quality of clustering.
- Developing a supervised band selection algorithm based on artificial bee colony optimization, which significantly improves the classification accuracy of selected bands.
2. Related Work
2.1. Super-Pixel Segmentation
2.2. Hypergraph Clustering
2.3. Artificial Bee Colony
3. The Proposed Band Selection Algorithm
3.1. Framework of The Algorithm
3.2. Noise Band Filtering Strategy Based on Grid Division
3.3. Pseudo-Label Generation with Hypergraph Evolutionary Clustering
3.3.1. Super-Pixel Segmentation
3.3.2. ABC-Based Hypergraph Evolutionary Clustering
| Algorithm 1: The proposed hypergraph evolutionary clustering based on ABC, HC-ABC. |
| Input: Hyperspectral image data, X; |
| Output: Optimal solution set, ; |
| 1. Initialize the parameters of SLIC, and normalize the X to 0–255; |
| 2. Filter out irrelevant or noise bands by the method in Section 3.2; |
| 3. Execute the method in Section 3.3.1 to get the super-pixel centers; |
| 4. Initialize the parameters of ABC, and randomly initialize the N populations; |
| 5. While () |
| 6. For % Simultaneously update the food sources in the N populations. |
| 7. Calculate the fitness value of each food source in the population by formula (10), |
| and find the optimal solution, ; |
| 8. Employed bee phase: Update all the food sources by formula (11); |
| 9. Onlooker bee phase: Update the selected food sources by formula (3); |
| 10. Scout bee phase: Reinitialize the stagnant food sources by formula (6); |
| 11. End for |
| 12. Execute the multi-population coordination strategy, update the of each population; |
| 13. ; |
| 14. End while |
| 15. Output the obtained by every population. |
3.3.3. Generation of The Pseudo-Labels
3.4. ABC-Based Supervised Band Selection Algorithm
3.5. Algorithm Complexity
4. Experiment and Analysis
4.1. Experiment Preparation
4.2. Data Description
4.3. Analysis of Parameters
4.4. Analysis on the Hypergraph Evolutionary Clustering
4.5. Comparison Results
4.5.1. Comparison on the Classification Performance
4.5.2. Significance Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Acosta, I.C.C.; Khodadadzadeh, M.; Tusa, L.; Ghamisi, P.; Gloaguen, R. A machine learning framework for drill-core mineral mapping using hyperspectral and high-resolution mineralogical data fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4829–4842. [Google Scholar] [CrossRef]
- Nguyen, H.D.; Nansen, C. Hyperspectral remote sensing to detect leafminer-induced stress in bok-choy and spinach according to fertilizer regime and timing. Pest Manag. Sci. 2020, 76, 2208–2216. [Google Scholar] [CrossRef]
- Li, Y.; Lu, T.; Li, S.T. Subpixel-pixel-superpixel-based multiview active learning for hyperspectral images classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4976–4988. [Google Scholar] [CrossRef]
- Azar, S.G.; Meshgini, S.; Rezaii, T.Y.; Beheshti, S. Hyperspectral image classification based on sparse modeling of spectral blocks. Neurocomputing 2020, 407, 12–23. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Xie, F.; Li, F.; Lei, C.; Ke, L. Representative band selection for hyperspectral image classification. ISPRS Int. J. Geo-Inf. 2018, 7, 338. [Google Scholar] [CrossRef]
- Pham, D.S.; Ridley, J.; Lazarescu, M. An efficient feature extraction method for the detection of material rings in rotary kilns. IEEE Trans. Ind. Inform. 2020, 16, 5914–5923. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, S.; Gong, D.W.; Shi, Y.H.; Zhao, X.C. Cost-sensitive feature selection using two-archive multi-objective artificial bee colony algorithm. Expert Syst. Appl. 2019, 137, 46–58. [Google Scholar] [CrossRef]
- Li, M.M.; Wang, H.F.; Yang, L.F.; Liang, Y.; Shang, Z.G.; Wang, H. Fast hybrid dimensionality reduction method for classification based on feature selection and grouped feature extraction. Expert Syst. Appl. 2020. [Google Scholar] [CrossRef]
- Habermann, M.; Fremont, V.; Shiguemori, E.H. Supervised band selection in hyperspectral images using single-layer neural networks. Int. J. Remote Sens. 2019, 40, 3900–3926. [Google Scholar] [CrossRef]
- Cao, X.H.; Xiong, T.; Jiao, L.C. Supervised band selection using local spatial information for hyperspectral image. IEEE Geosci. Remote Sens. Lett. 2016, 13, 329–333. [Google Scholar] [CrossRef]
- Song, X.F.; Zhang, Y.; Guo, Y.N.; Sun, X.Y. Variable-size cooperative coevolutionary particle swarm optimization for feature selection on high-dimensional data. IEEE Trans. Evol. Comput. 2020. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, Y.; Gong, D.W. Multi-objective particle swarm optimization for feature selection with fuzzy cost. IEEE Trans. Cybern. 2020. [Google Scholar] [CrossRef] [PubMed]
- Sui, C.H.; Li, C.; Feng, J.; Mei, X.G. Unsupervised manifold-preserving and weakly redundant band selection method for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1156–1170. [Google Scholar] [CrossRef]
- Bevilacqua, M.; Berthoumieu, Y. Multiple-feature kernel-based probabilistic clustering for unsupervised band selection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6675–6689. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Q.; Gong, D.W.; Song, X.F. Nonnegative Laplacian embedding guided subspace learning for unsupervised feature selection. Pattern Recognit. 2019, 93, 337–352. [Google Scholar] [CrossRef]
- Varade, D.; Maurya, A.K.; Dikshit, O. Unsupervised hyperspectral band selection using ranking based on a denoising error matching approach. Int. J. Remote Sens. 2019, 40, 8031–8053. [Google Scholar] [CrossRef]
- Wang, Q.; Lin, J.Z.; Yuan, Y. Salient band selection for hyperspectral image classification via manifold ranking. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1279–1289. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.W.; Peng, J.T.; Yang, G.; Du, Q. Fast and latent low-rank subspace clustering for hyperspectral band selection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3906–3915. [Google Scholar] [CrossRef]
- Zeng, M.; Cai, Y.M.; Cai, Z.H.; Liu, X.B.; Hu, P.; Ku, J.H. Unsupervised hyperspectral image band selection based on deep subspace clustering. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1889–1893. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, X.F.; Gong, D.W. A return-cost-based binary firefly algorithm for feature selection. Inf. Sci. 2017, 418, 561–574. [Google Scholar] [CrossRef]
- Zhang, W.Q.; Li, X.R.; Dou, Y.X.; Zhao, L.Y. A Geometry-based band selection approach for hyperspectral image analysis. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4318–4333. [Google Scholar] [CrossRef]
- Ding, X.H.; Li, H.P.; Yang, J.; Dale, P.; Chen, X.C.; Jiang, C.L.; Zhang, S.Q. An improved ant colony algorithm for optimized band selection of hyperspectral remotely sensed imagery. IEEE Access 2020, 8, 25789–25799. [Google Scholar] [CrossRef]
- Zhang, M.Y.; Gong, M.G.; Chan, Y.Q. Hyperspectral band selection based on multi-objective optimization with high information and low redundancy. Appl. Soft Comput. 2018, 70, 604–621. [Google Scholar] [CrossRef]
- Xu, Y.; Du, Q.; Younan, N.H. Particle swarm optimization-based band selection for hyperspectral target detection. IEEE Geosci. Remote Sens. Lett. 2017, 14, 554–558. [Google Scholar] [CrossRef]
- Song, L.C.; Xu, Y.H.; Zhang, L.F.; Du, B.; Zhang, Q.; Wang, X.G. Learning from synthetic images via active pseudo-labeling. IEEE Trans. Image Process. 2020, 29, 6452–6465. [Google Scholar] [CrossRef]
- Ding, G.; Zhang, S.S.; Khan, S.; Tang, Z.M.; Zhang, J.; Porikli, F. Feature affinity-based pseudo labeling for semi-supervised person re-identification. IEEE Trans. Multimed. 2019, 21, 2891–2902. [Google Scholar] [CrossRef]
- Felzenszwalb, P.; Huttenlocher, D. Efficient graph-based image segmentation. Int. J. Comput. Vis. (IJCV) 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Levinshtein, A.; Stere, A.; Nkutulakos, K. Turbo pixels: Fast super pixels using geometric flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef]
- Zhang, Y.X.; Liu, K.; Dong, Y.N.; Wu, K.; Hu, X.Y. Semi-supervised classification based on SLIC segmentation for hyperspectral image. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1440–1444. [Google Scholar] [CrossRef]
- Glory, H.A.; Vigneswaran, C.; Sriram, V.S.S. Unsupervised bin-wise pre-training: A fusion of information theory and hypergraph. Knowl. Based Syst. 2020, 195. [Google Scholar] [CrossRef]
- Kim, S.J.; Ha, J.W.; Zhang, B.T. Constructing higher-order miRNA-mRNA interaction networks in prostate cancer via hypergraph-based learning. BMC Syst. Biol. 2013, 7, 47. [Google Scholar] [CrossRef] [PubMed]
- Xiao, L.; Wang, J.Q.; Kassani, P.H.; Zhang, Y.P.; Bai, Y.T.; Stephen, J.M.; Wilson, T.W.; Calhoun, V.D.; Wang, Y.P. Multi-hypergraph learning-based brain functional connectivity analysis in FMRI data. IEEE Trans. Med. Imaging 2020, 39, 1746–1758. [Google Scholar] [CrossRef]
- Yuan, H.; Tang, Y.Y. Learning with hypergraph for hyperspectral image feature extraction. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1695–1699. [Google Scholar] [CrossRef]
- An, L.; Chen, X.; Yang, S.; Li, L.Z. Person re-identification by multi-hypergraph fusion. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2763–2774. [Google Scholar] [CrossRef] [PubMed]
- Tang, C.; Liu, X.W.; Wang, P.C.; Zhang, C.Q.; Li, M.M.; Wang, L.Z. Adaptive hypergraph embedded semi-supervised multi-label image annotation. IEEE Trans. Multimed. 2019, 21, 2837–2849. [Google Scholar] [CrossRef]
- Karaboga, D. An Idea Based on Honey Bee Swarm for Numerical Optimization; Erciyes University: Ksyseri, Turkey, 2005. [Google Scholar]
- Li, J.Q.; Song, M.X.; Wang, L.; Duan, P.Y.; Han, Y.Y.; Sang, H.Y.; Pan, Q.K. Hybrid artificial bee colony algorithm for a parallel batching distributed flow-shop problem with deteriorating jobs. IEEE Trans. Cybern. 2020, 50, 2425–2439. [Google Scholar] [CrossRef]
- Chen, L.; Ma, L.; Xu, Y.B.; Leung, V.C.M. Hypergraph spectral clustering-based spectrum resource allocation for dense NOMA-Het net. IEEE Wirel. Commun. Lett. 2019, 8, 305–308. [Google Scholar] [CrossRef]
- He, C.L.; Zhang, Y.; Gong, D.W.; Wu, B. Multi-objective feature selection based on artificial bee colony for hyperspectral images. In International Conference on Bio-Inspired Computing: Theories and Applications; Springer: Singapore, 2020. [Google Scholar]
- Martfnez-Usomartinez, U.A.; Pla, F.; Sotoca, J.M. Clustering based hyperspectral band selection using information measures. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4158–4171. [Google Scholar] [CrossRef]
- Yang, R.C.; Kan, J.M. An unsupervised hyperspectral band selection method based on shared nearest neighbor and correlation analysis. IEEE Access 2019, 7, 185532–185542. [Google Scholar] [CrossRef]
- Bajcsy, P.; Groves, P. Methodology for hyperspectral band selection. Photogramm. Eng. Remote Sens. 2004, 70, 793–802. [Google Scholar] [CrossRef]
- Chang, C.I.; Du, Q.; Sun, T.L. A joint band prioritization and band-decorrelation approach to band selection for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2631–2641. [Google Scholar] [CrossRef]
- Tschannerl, J.; Ren, J.C.; Yuen, P.; Sun, G.Y.; Zhao, H.M.; Yang, Z.J.; Wang, Z.; Marshall, S. MIMR-DGSA: Unsupervised hyperspectral band selection based on information theory and a modified discrete gravitational search algorithm. Inf. Fusion 2019, 51, 189–200. [Google Scholar] [CrossRef]
- Xie, F.D.; Li, F.F.; Lei, C.K.; Yang, J.; Zhang, Y. Unsupervised band selection based on artificial bee colony algorithm for hyperspectral image classification. Appl. Soft Comput. 2019, 75, 428–440. [Google Scholar] [CrossRef]
- Chu, J.H.; Min, H.; Liu, L.; Lu, W. A novel computer aided breast mass detection scheme based on morphological enhancement and SLIC superpixel segmentation. Med. Phys. 2015, 42, 3859–3869. [Google Scholar] [CrossRef] [PubMed]
- Song, A.; Chen, W.N.; Gong, Y.J.; Luo, X.; Zhang, J. A divide-and-conquer evolutionary algorithm for large-scale virtual network embedding. IEEE Trans. Evol. Comput. 2019, 24, 566–580. [Google Scholar] [CrossRef]
- Wang, H.; Tan, L.J.; Niu, B. Feature selection for classification of microarray gene expression cancers using Bacterial Colony Optimization with multi-dimensional population. Swarm Evol. Comput. 2019, 48, 172–181. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 |
|---|---|---|---|---|---|---|---|---|
| OA % | 73.374 | 74.465 | 75.132 | 75.653 | 75.680 | 75.665 | 75.700 | 75.662 |
| Number of | 10 | 20 | 30 | 40 | b | 60 | 70 | 80 |
|---|---|---|---|---|---|---|---|---|
| OA % | 72.992 | 73.742 | 74.563 | 75.3463 | 75.678 | 75.669 | 75.672 | 75.681 |
| Data | Algorithms | KNN | RAF | SVM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OA | AA | KC | OA | AA | KC | OA | AA | KC | ||
| Indian Pines | Waludi | 0.6769 | 0.6323 | 0.6297 | 0.7057 | 0.6078 | 0.6624 | 0.7448 | 0.6852 | 0.7052 |
| ±0.0596 | ±0.0679 | ±0.0684 | ±0.0455 | ±0.0402 | ±0.0524 | ±0.0754 | ±0.1102 | ±0.0919 | ||
| ER | 0.6324 | 0.5609 | 0.5792 | 0.6449 | 0.5469 | 0.5907 | 0.6584 | 0.5639 | 0.5996 | |
| ±0.0665 | ±0.0678 | ±0.0761 | ±0.0668 | ±0.0743 | ±0.0773 | ±0.1039 | ±0.1415 | ±0.1280 | ||
| MI-DGSA | 0.6375 | 0.5875 | 0.5851 | 0.6748 | 0.6119 | 0.6257 | 0.7231 | 0.6710 | 0.6798 | |
| ±0.0273 | ±0.0283 | ±0.0313 | ±0.0303 | ±0.0337 | ±0.0349 | ±0.0583 | ±0.0908 | ±0.0717 | ||
| ISD-ABC | 0.6215 | 0.5657 | 0.5666 | 0.6563 | 0.5855 | 0.6041 | 0.7069 | 0.6432 | 0.6607 | |
| ±0.0247 | ±0.0242 | ±0.0284 | ±0.0287 | ±0.0303 | ±0.0340 | ±0.0556 | ±0.0837 | ±0.0691 | ||
| MVPCA | 0.6916 | 0.6415 | 0.6467 | 0.7098 | 0.6133 | 0.6707 | 0.7564 | 0.7011 | 0.7196 | |
| ±0.0500 | ±0.0512 | ±0.0577 | ±0.0436 | ±0.0368 | ±0.0501 | ±0.0672 | ±0.1021 | ±0.0808 | ||
| SNNCA | 0.7084 | 0.6394 | 0.6669 | 0.7198 | 0.6232 | 0.6809 | 0.7680 | 0.7114 | 0.7340 | |
| ±0.0313 | ±0.0323 | ±0.0359 | ±0.0310 | ±0.0262 | ±0.0354 | ±0.0564 | ±0.0843 | ±0.0676 | ||
| HC-ABC | 0.7302 | 0.6520 | 0.6908 | 0.7275 | 0.6300 | 0.6854 | 0.7807 | 0.7295 | 0.7477 | |
| ±0.0402 | ±0.0344 | ±0.0260 | ±0.0294 | ±0.0195 | ±0.0337 | ±0.0521 | ±0.0785 | ±0.0617 | ||
| Pavia university | Waludi | 0.8432 | 0.8130 | 0.7902 | 0.8551 | 0.8215 | 0.8102 | 0.8912 | 0.8617 | 0.8718 |
| ±0.0232 | ±0.0256 | ±0.0314 | ±0.0259 | ±0.0283 | ±0.0353 | ±0.0434 | ±0.0646 | ±0.0618 | ||
| ER | 0.8029 | 0.7506 | 0.7359 | 0.8075 | 0.7372 | 0.7387 | 0.8403 | 0.7439 | 0.7789 | |
| ±0.1025 | ±0.1295 | ±0.1399 | ±0.0951 | ±0.1220 | ±0.1321 | ±0.0915 | ±0.1495 | ±0.1354 | ||
| MI-DGSA | 0.8577 | 0.8276 | 0.7841 | 0.8587 | 0.8189 | 0.7899 | 0.8867 | 0.8394 | 0.8403 | |
| ±0.0194 | ±0.0245 | ±0.0262 | ±0.0208 | ±0.0256 | ±0.0284 | ±0.0232 | ±0.0446 | ±0.0339 | ||
| ISD-ABC | 0.8331 | 0.8015 | 0.7577 | 0.8478 | 0.8056 | 0.7767 | 0.8734 | 0.8248 | 0.8256 | |
| ±0.0227 | ±0.0277 | ±0.0307 | ±0.0240 | ±0.0282 | ±0.0327 | ±0.0257 | ±0.0477 | ±0.0376 | ||
| MVPCA | 0.8545 | 0.8273 | 0.8078 | 0.8605 | 0.8254 | 0.8160 | 0.8905 | 0.8551 | 0.8792 | |
| ±0.0352 | ±0.0425 | ±0.0474 | ±0.0364 | ±0.0442 | ±0.0493 | ±0.0530 | ±0.0822 | ±0.0754 | ||
| SNNCA | 0.8515 | 0.8304 | 0.8106 | 0.8670 | 0.8390 | 0.8249 | 0.8998 | 0.8730 | 0.8801 | |
| ±0.0206 | ±0.0203 | ±0.0279 | ±0.0184 | ±0.0174 | ±0.0248 | ±0.0378 | ±0.0502 | ±0.0532 | ||
| HC-ABC | 0.8700 | 0.8407 | 0.8244 | 0.8863 | 0.8549 | 0.8463 | 0.9056 | 0.8596 | 0.8918 | |
| ±0.0237 | ±0.0287 | ±0.0324 | ±0.0249 | ±0.0250 | ±0.0336 | ±0.0386 | ±0.0593 | ±0.0547 | ||
| Salinas | Waludi | 0.8745 | 0.9261 | 0.8802 | 0.9009 | 0.9410 | 0.8896 | 0.8977 | 0.9337 | 0.8855 |
| ±0.0332 | ±0.0384 | ±0.0371 | ±0.0238 | ±0.0266 | ±0.0265 | ±0.0418 | ±0.0491 | ±0.0474 | ||
| ER | 0.8364 | 0.8671 | 0.8377 | 0.8524 | 0.8747 | 0.8354 | 0.8527 | 0.8714 | 0.8350 | |
| ±0.0434 | ±0.0596 | ±0.0487 | ±0.0400 | ±0.0550 | ±0.0448 | ±0.0429 | ±0.0739 | ±0.0489 | ||
| MI-DGSA | 0.8709 | 0.9241 | 0.8762 | 0.8920 | 0.9319 | 0.8797 | 0.8953 | 0.9324 | 0.8830 | |
| ±0.0136 | ±0.0163 | ±0.0152 | ±0.0133 | ±0.0138 | ±0.0148 | ±0.0222 | ±0.0255 | ±0.0250 | ||
| ISD-ABC | 0.8658 | 0.9195 | 0.8706 | 0.8840 | 0.9252 | 0.8708 | 0.8930 | 0.9299 | 0.8806 | |
| ±0.0117 | ±0.0137 | ±0.0131 | ±0.0123 | ±0.0122 | ±0.0137 | ±0.0207 | ±0.0232 | ±0.0233 | ||
| MVPCA | 0.8816 | 0.9313 | 0.8893 | 0.9061 | 0.9469 | 0.8954 | 0.9087 | 0.9463 | 0.8980 | |
| ±0.0095 | ±0.0082 | ±0.0106 | ±0.0126 | ±0.0098 | ±0.0140 | ±0.0158 | ±0.0138 | ±0.0177 | ||
| SNNCA | 0.8814 | 0.9302 | 0.8890 | 0.9034 | 0.9450 | 0.8924 | 0.9095 | 0.9461 | 0.8990 | |
| ±0.0166 | ±0.0153 | ±0.0185 | ±0.0163 | ±0.0137 | ±0.0182 | ±0.0230 | ±0.0234 | ±0.0259 | ||
| HC-ABC | 0.8919 | 0.9442 | 0.8998 | 0.9156 | 0.9602 | 0.9082 | 0.9222 | 0.9549 | 0.9157 | |
| ±0.0176 | ±0.0126 | ±0.0188 | ±0.0193 | ±0.0165 | ±0.0180 | ±0.0227 | ±0.0157 | ±0.0221 | ||
| Classifier | Waludi | ER | MI-DGSA | ISD-ABC | MVPCA | SNNCA | HC-ABC |
|---|---|---|---|---|---|---|---|
| KNN | + | + | + | + | + | + | \ |
| RAF | + | + | + | + | + | ≈ | \ |
| SVM | + | + | + | + | + | ≈ | \ |
| Classifier | Waludi | ER | MI-DGSA | ISD-ABC | MVPCA | SNNCA | HC-ABC |
|---|---|---|---|---|---|---|---|
| KNN | + | + | + | + | + | + | \ |
| RAF | + | + | + | + | ≈ | + | \ |
| SVM | + | + | + | + | + | - | \ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, C.; Zhang, Y.; Gong, D. A Pseudo-Label Guided Artificial Bee Colony Algorithm for Hyperspectral Band Selection. Remote Sens. 2020, 12, 3456. https://doi.org/10.3390/rs12203456
He C, Zhang Y, Gong D. A Pseudo-Label Guided Artificial Bee Colony Algorithm for Hyperspectral Band Selection. Remote Sensing. 2020; 12(20):3456. https://doi.org/10.3390/rs12203456
Chicago/Turabian StyleHe, Chunlin, Yong Zhang, and Dunwei Gong. 2020. "A Pseudo-Label Guided Artificial Bee Colony Algorithm for Hyperspectral Band Selection" Remote Sensing 12, no. 20: 3456. https://doi.org/10.3390/rs12203456
APA StyleHe, C., Zhang, Y., & Gong, D. (2020). A Pseudo-Label Guided Artificial Bee Colony Algorithm for Hyperspectral Band Selection. Remote Sensing, 12(20), 3456. https://doi.org/10.3390/rs12203456