Implementation of Artificial Intelligence Based Ensemble Models for Gully Erosion Susceptibility Assessment

 , , , ,
, , , ,  ,
,  ,
,  and
and
Abstract
1. Introduction
2. Materials and Methods
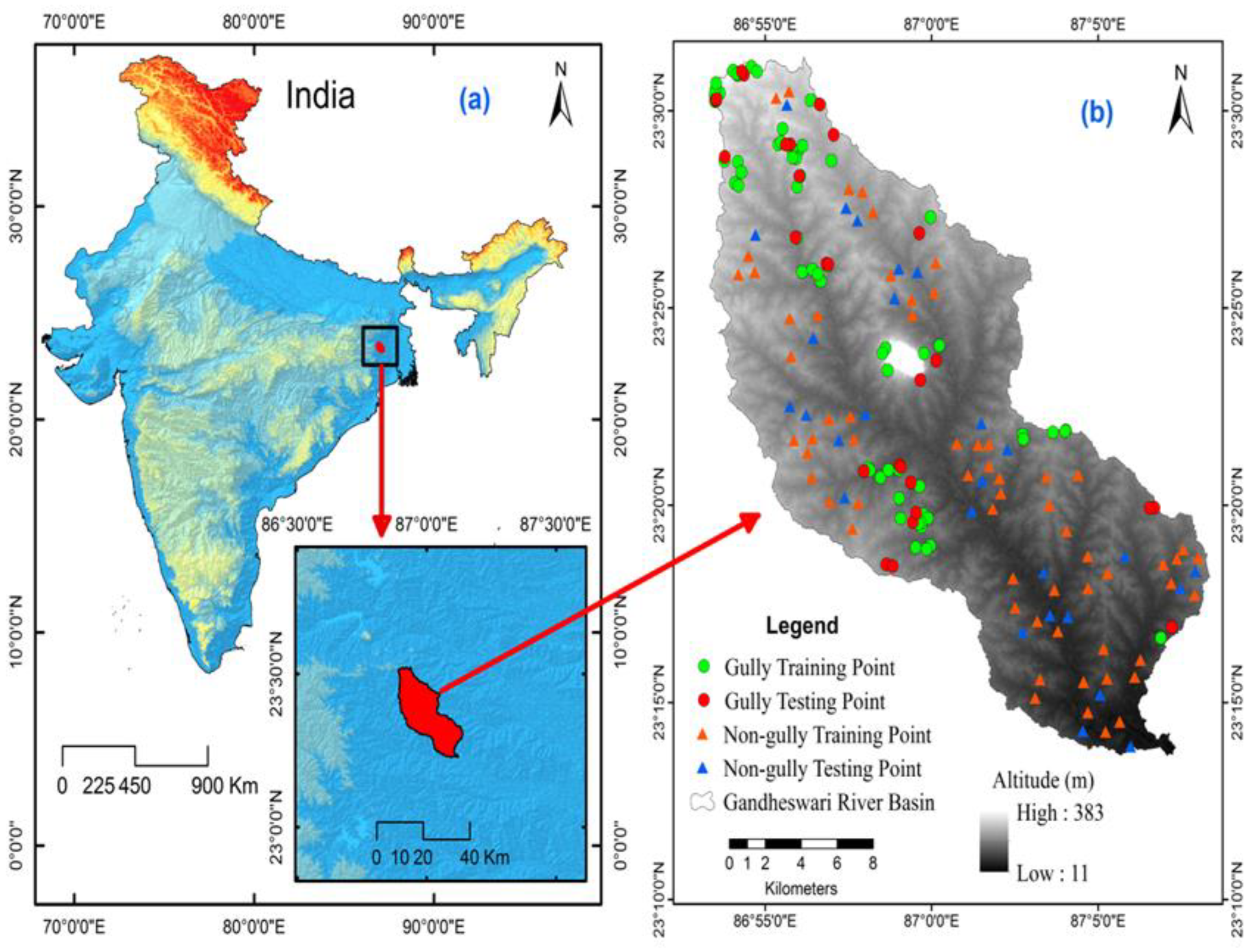
2.1. Description of the Study Area
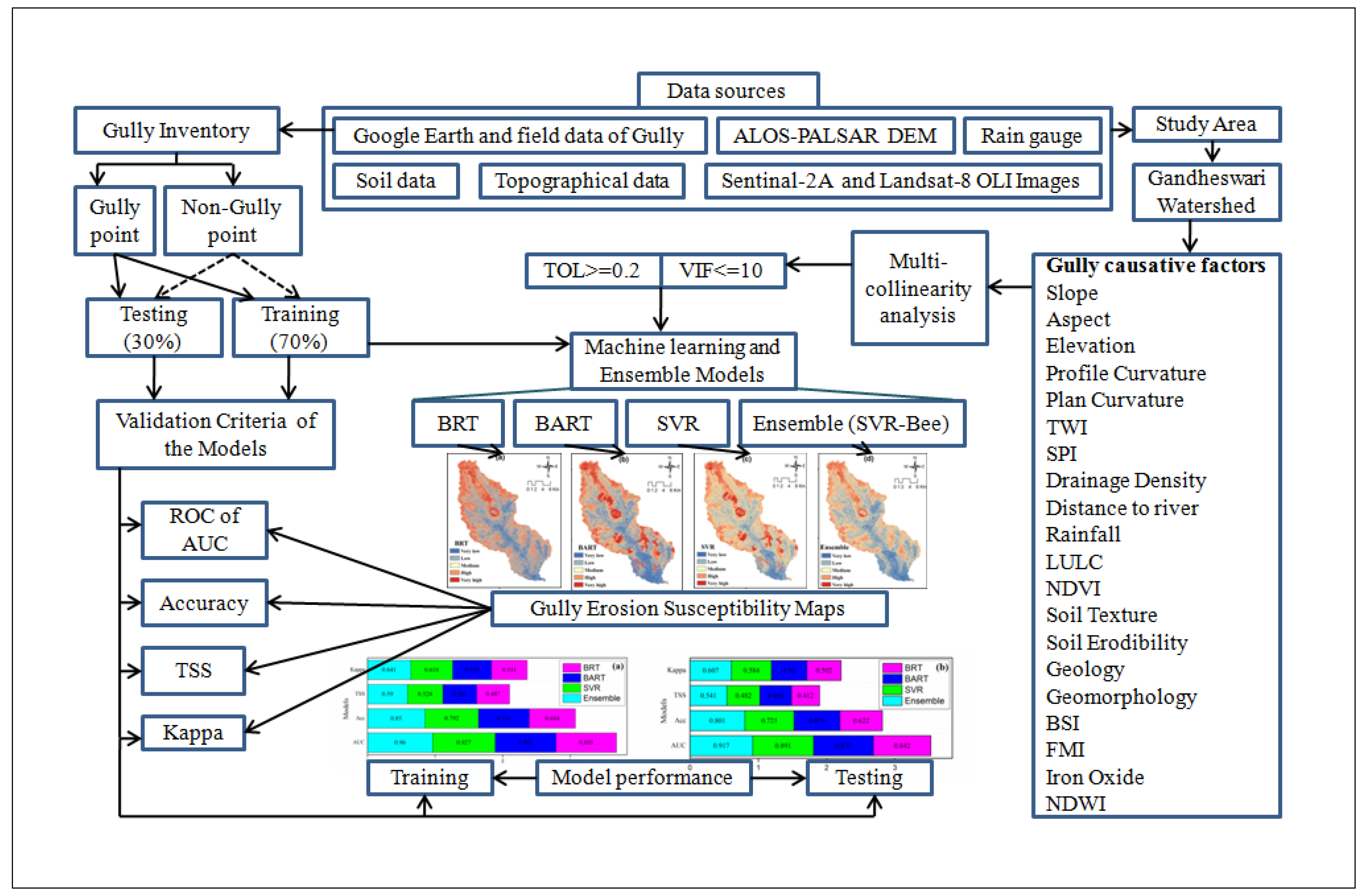
2.2. Methodology
- A total of 178 (89 each for gully and non-gully) gully erosion points were used to prepare a gully erosion inventory map. A total of 20 GECFs were used for the different GESMs.
- The variance inflation factor (VIF) and tolerance (TOL) techniques were used for multi-collinearity (MC) analysis.
- The importance of several GECFs was determined using the random forest (RF) algorithm and step-wise weight assessment ratio analysis (SWARA).
- GESMs wereprepared based on the boosted regression tree (BRT), Bayesian additive regression tree (BART), support vector regression (SVR), ML models and the SVR-Bee ensemble model. All of these ML models and the ensemble approach were run in MATLAB and the ‘R’ statistical programming package by using the respective algorithms.
- Every model was validated using the receiver operating characteristic curve with the area under curve (ROC-AUC), accuracy (ACC), true skill statistic (TSS), and the Kappa coefficient index analysis.
2.2.1. Gully Erosion Inventory Map (GEIM)
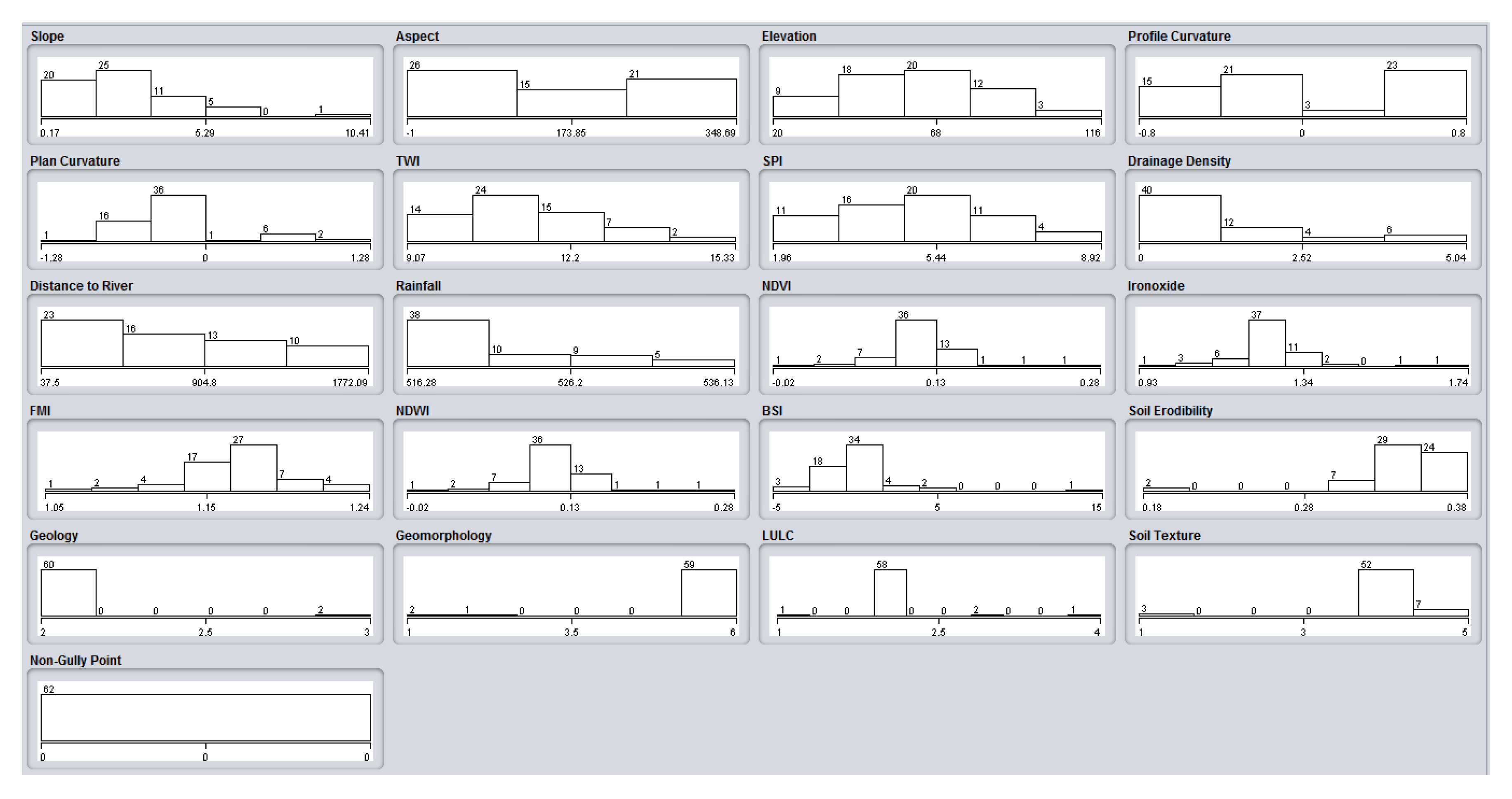
2.2.2. Gully Erosion Conditioning Factors (GECFs)
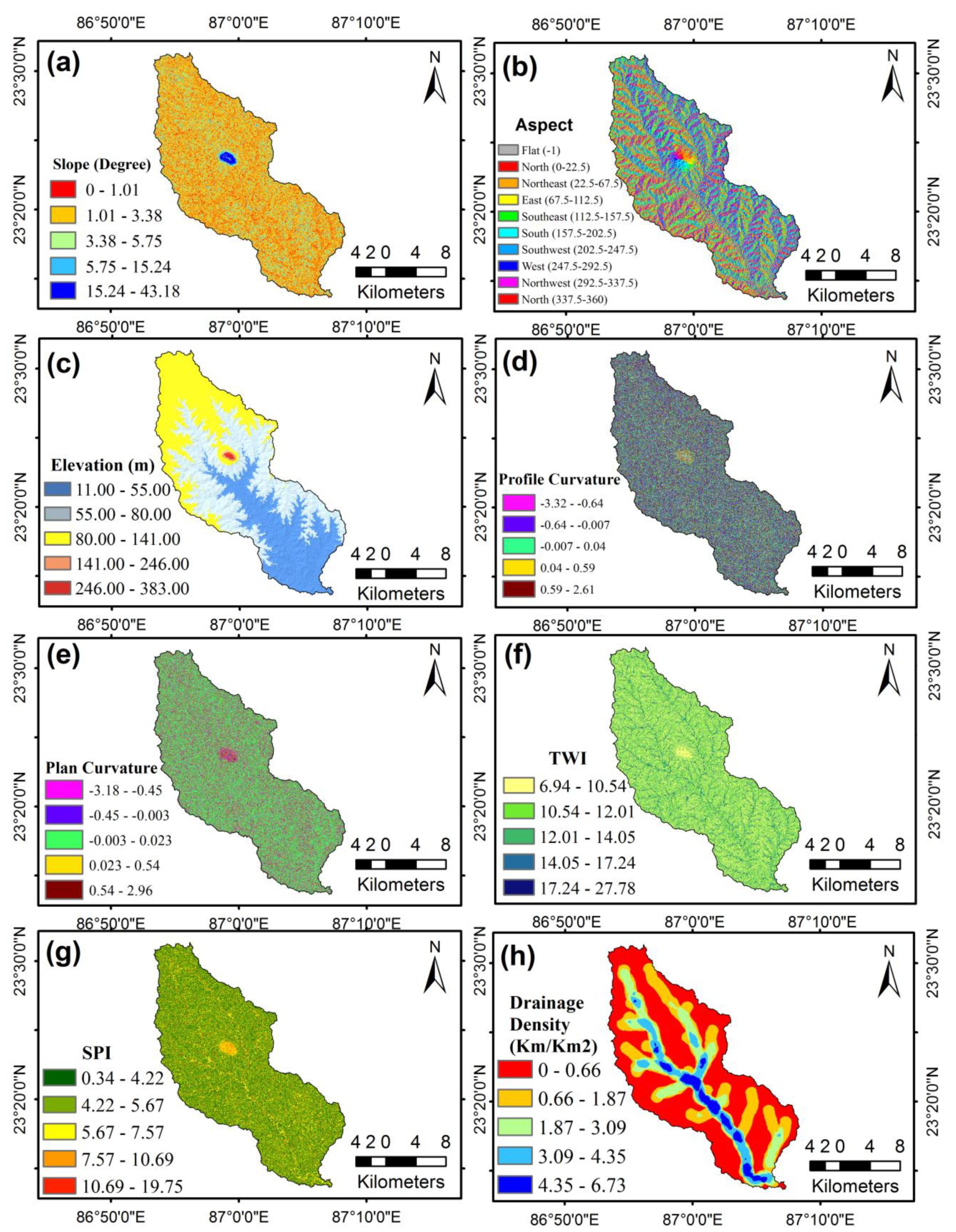
Slope
Aspect
Elevation
Profile Curvature
Plan Curvature
Topographic Wetness Index (TWI)
Stream Power Index (SPI)
Drainage Density (DD)
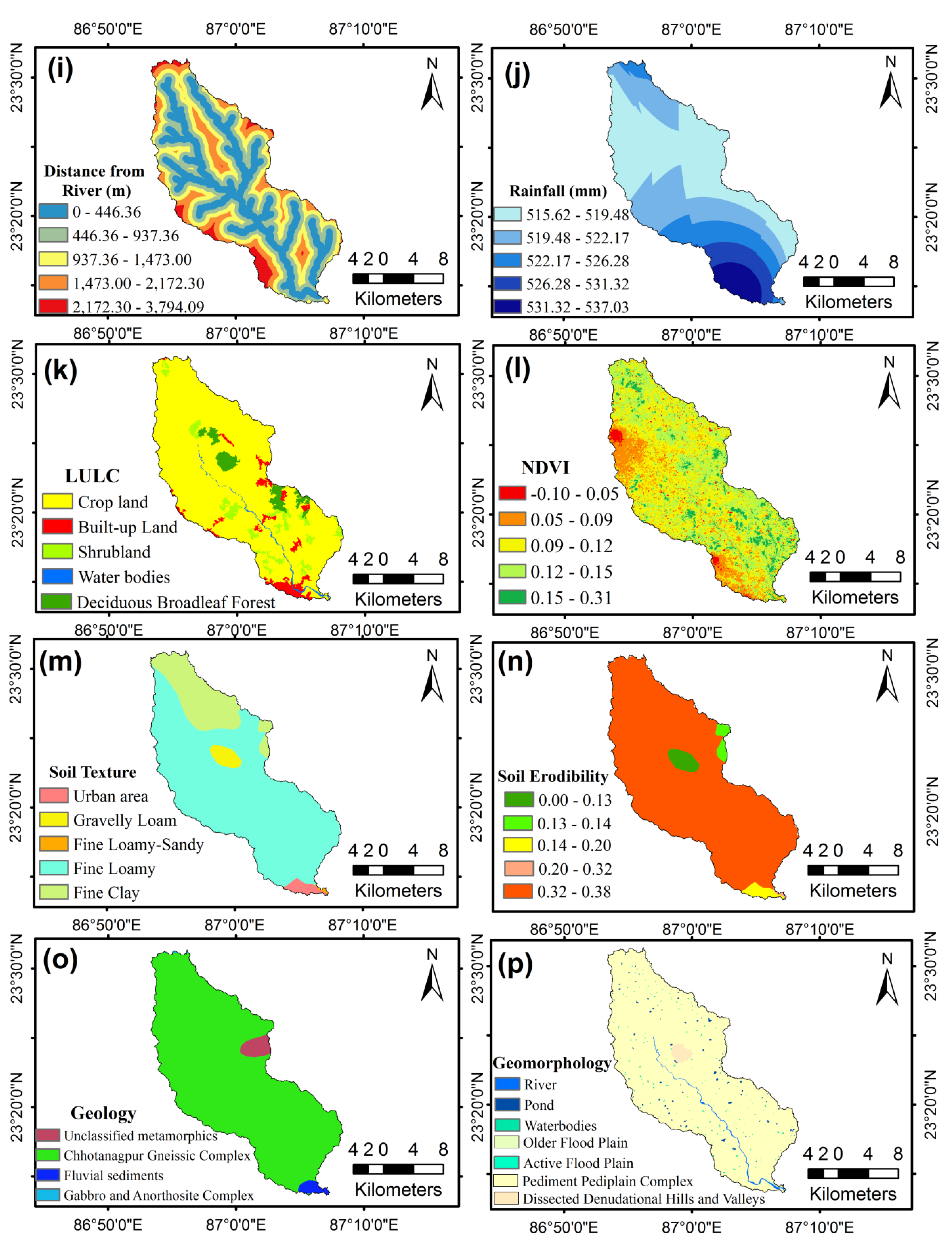
Distance from River
Rainfall
Land Use Land Cover (LULC)
Normalized Difference Vegetation Index (NDVI)
Soil Texture
Soil Erodibility
Geology
Geomorphology
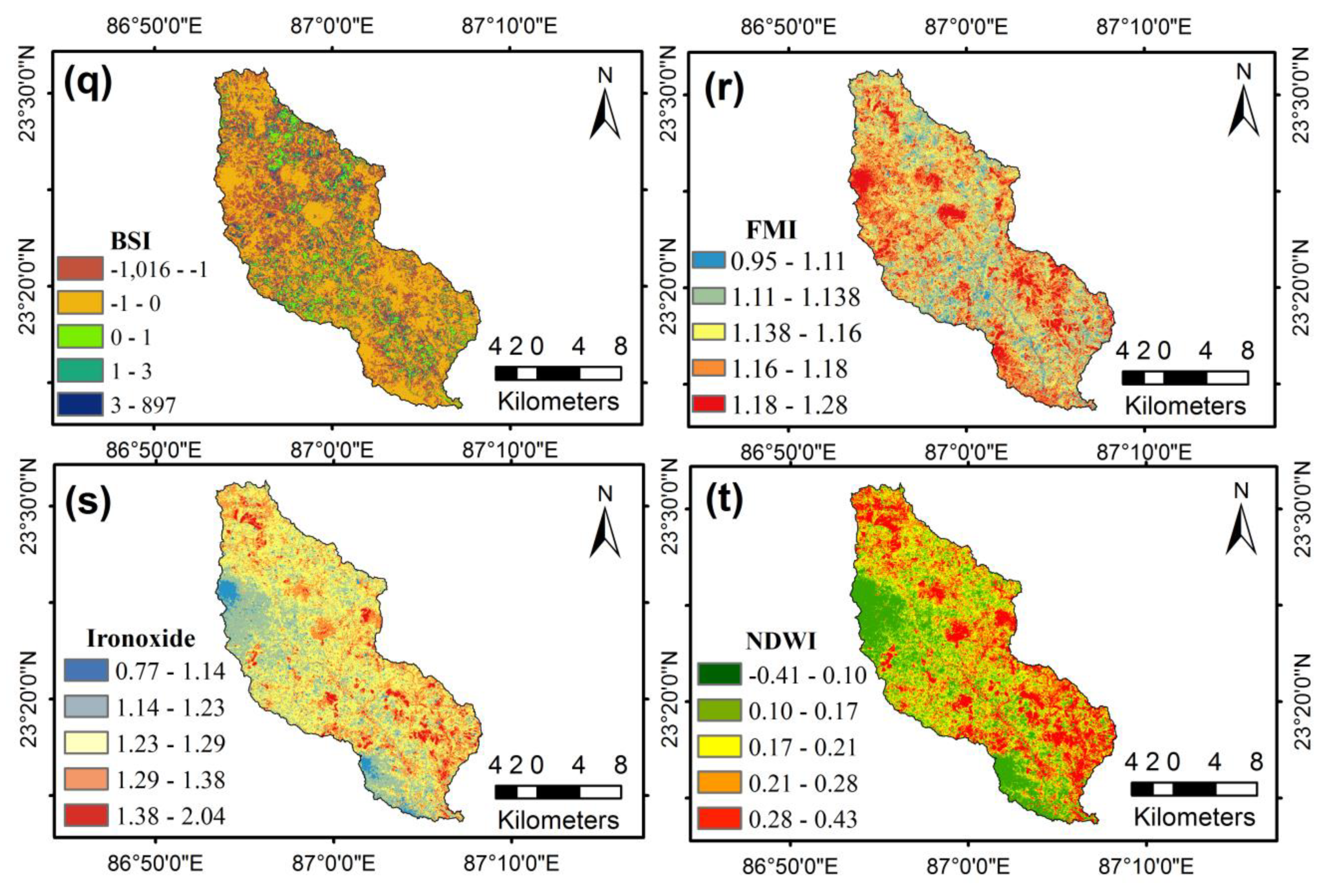
Bare Soil Index (BSI)
Ferrous Minerals Index (FMI)
Iron Oxide
Normalized Difference Water Index (NDWI)
2.2.3. Multi-Collinearity (MC) Analysis
2.2.4. Importance of GECFs by Random Forest (RF) and SWARA Weight
Random Forest (RF)
Step-Wise Weight Assessment Ratio Analysis (SWARA)
- Ordering the criteria based on expert opinion.
- Endow with relative importance among the criteria.An expert gives the importance of the criteria with respect to the previous criteria according to the average value () ratio.
- Determining the coefficient :
- Computation of the recalculated weight :
- Computation of the final weights of the criteria:
2.2.5. Gully Erosion Susceptibility Modelling (GESM)
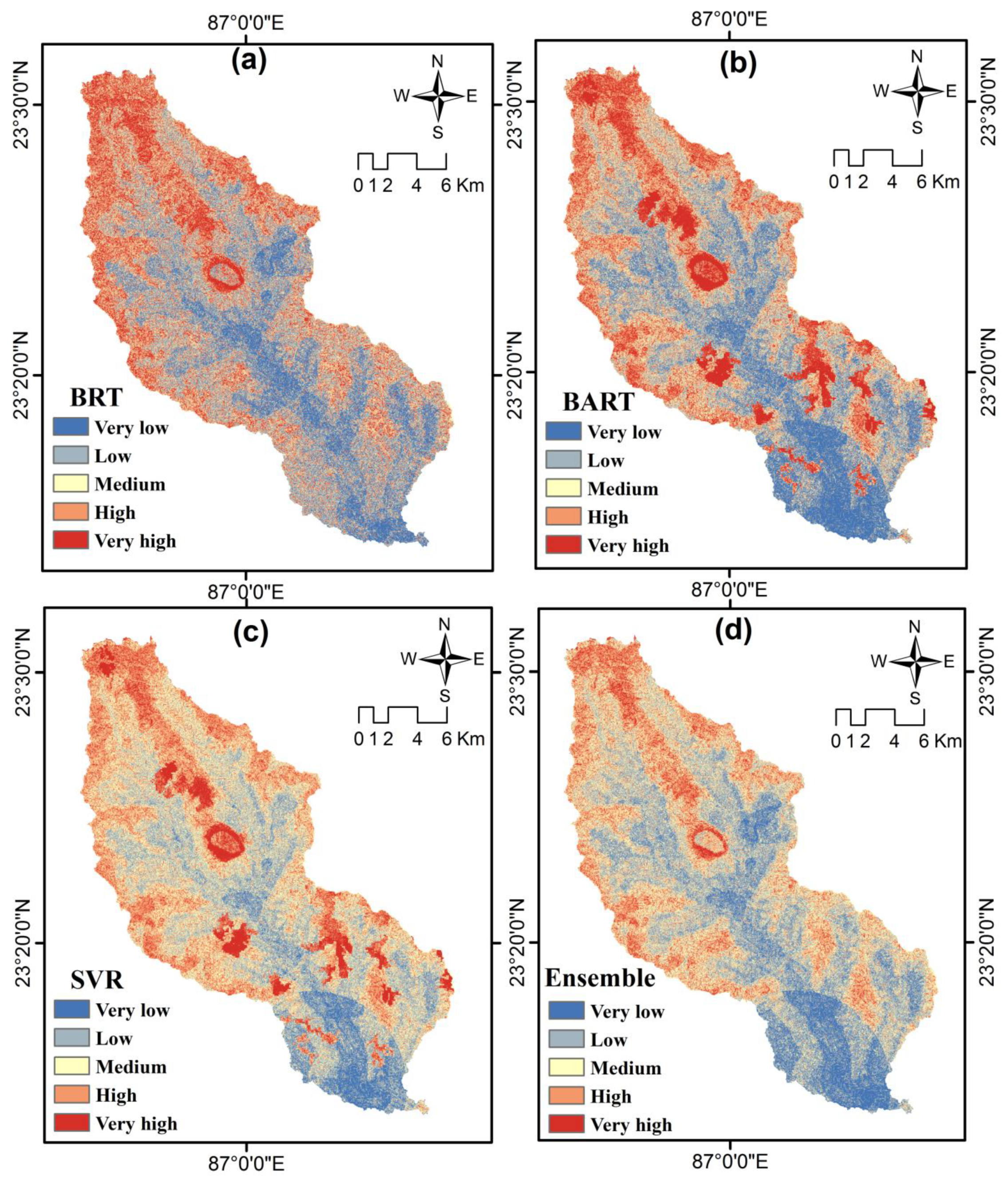
Boosted Regression Tree (BRT)
Bayesian Additive Regression Tree (BART)
Support Vector Regression (SVR)
Bee Algorithm (BA)
Ensemble of SVR and Bee Algorithm
2.2.6. Validation and Accuracy Assessment
3. Results
3.1. Multi-Collinearity Analysis
3.2. Exploratory Data Analysis
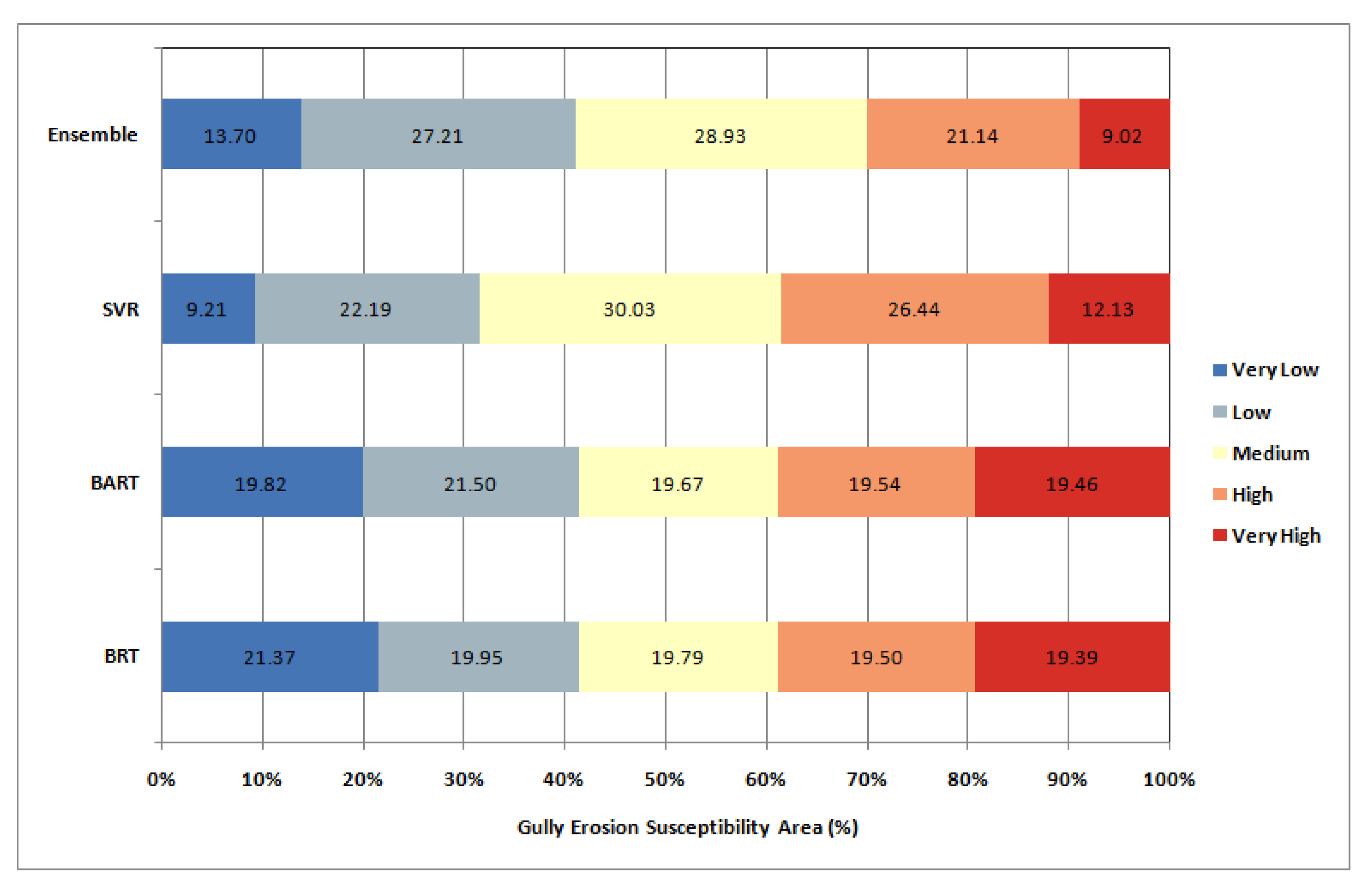
3.3. Spatial Mapping of Gully Erosion Susceptibility
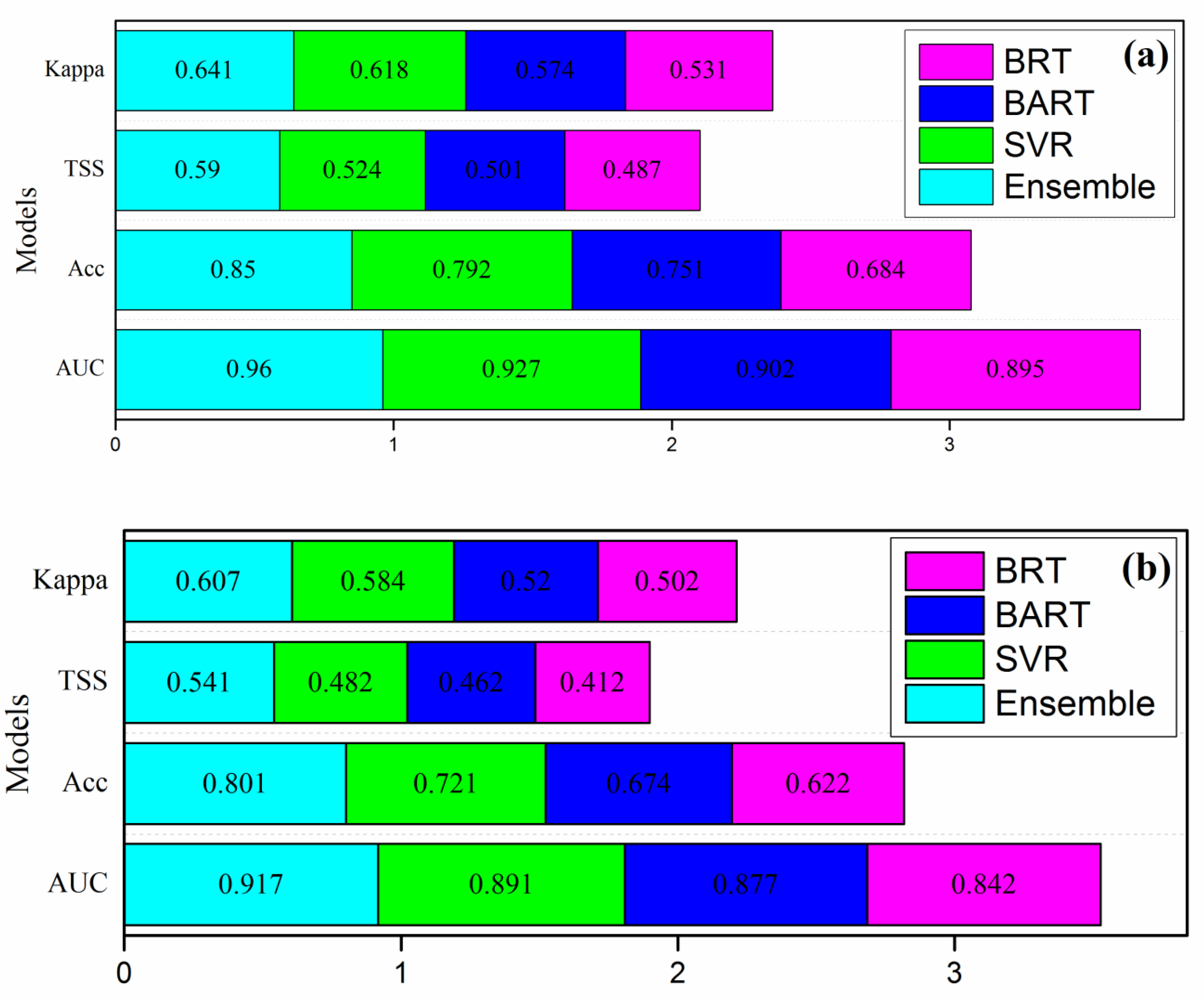
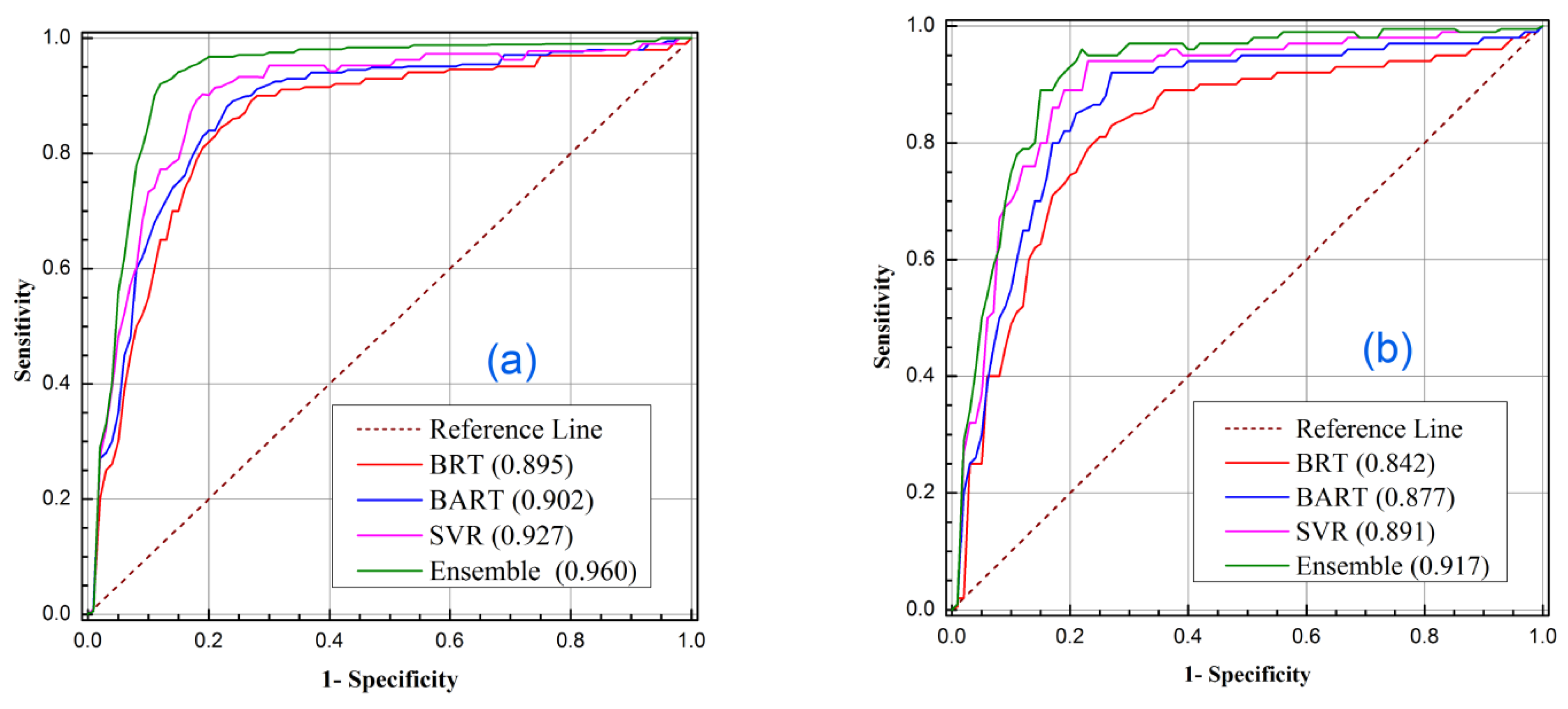
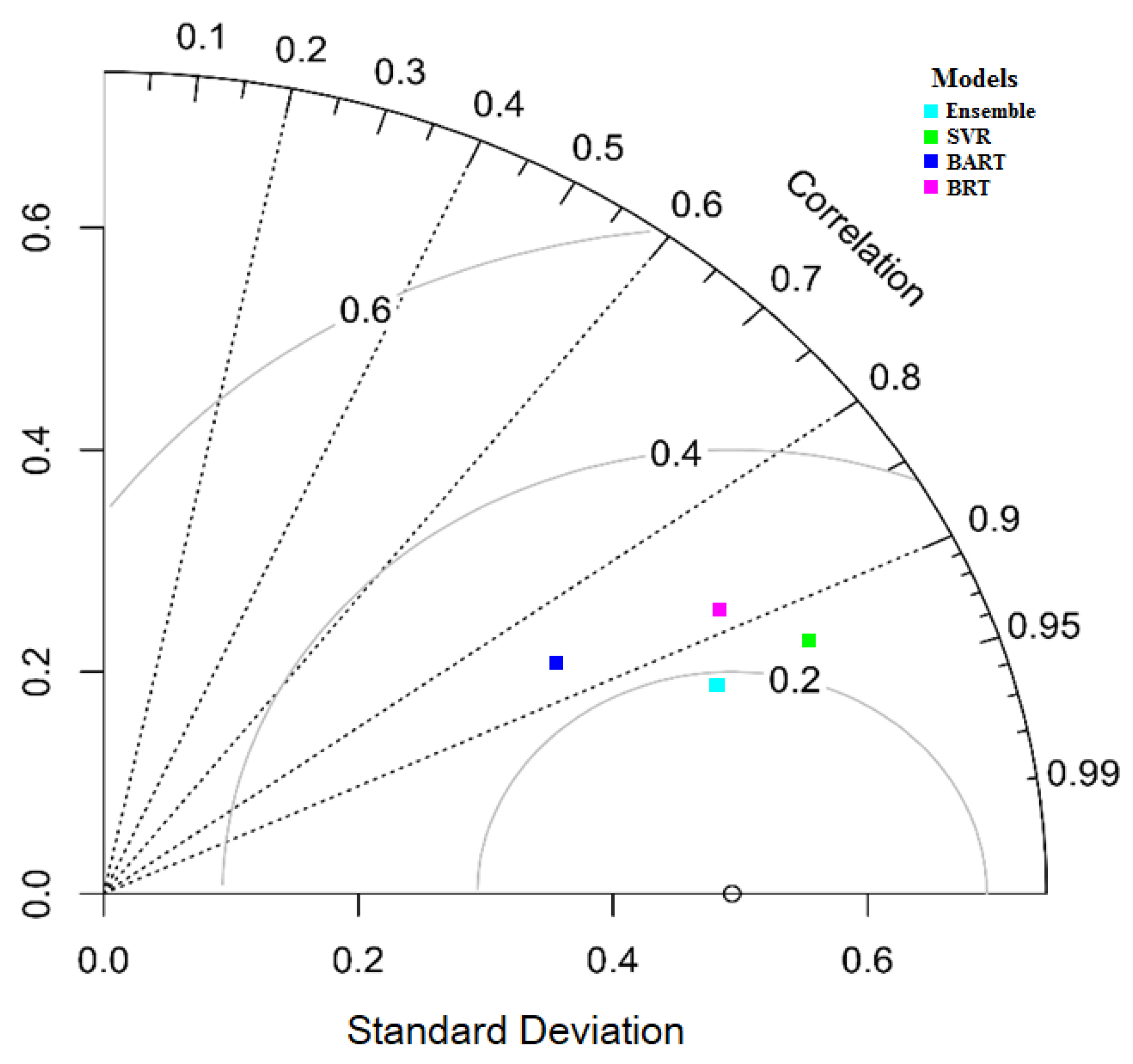
3.4. Model Evaluation Performance Result
3.5. Relative Importance of the Variables
3.6. Relative Importance of Sub-Classes of the Variables
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Billi, P.; Dramis, F. Geomorphological investigation on gully erosion in the Rift Valley and the northern highlands of Ethiopia. Catena 2003, 50, 353–368. [Google Scholar] [CrossRef]
- Saha, A.; Ghosh, M.; Pal, S.C. Understanding the Morphology and Development of a Rill-Gully: An Empirical Study of Khoai Badland, West Bengal, India. In Gully Erosion Studies from India and Surrounding Regions; Springer International Publishing: Cham, Switzerland, 2020; pp. 147–161. [Google Scholar]
- Lal, R. Offsetting global CO2 emissions by restoration of degraded soils and intensification of world agriculture and forestry. Land Degrad. Dev. 2003, 14, 309–322. [Google Scholar] [CrossRef]
- Poesen, J.; Nachtergaele, J.; Verstraeten, G.; Valentin, C. Gully erosion and environmental change: Importance and research needs. Catena 2003, 50, 91–133. [Google Scholar] [CrossRef]
- Valentin, C.; Poesen, J.; Li, Y. Gully erosion: Impacts, factors and control. Catena 2005, 63, 132–153. [Google Scholar] [CrossRef]
- Imeson, A.C.; Kwaad, F.J.P.M.; Mucher, H.J. Hillslope processes and deposits in forested areas of Luxembourg. In Timescales in Geomorphology; John Wiley and Sons Ltd.: Hoboken, NJ, USA, 1980; pp. 31–42. [Google Scholar]
- Poesen, J. Soil erosion in the Anthropocene: Research needs. Earth Surf. Process. Landf. 2018, 43, 64–84. [Google Scholar] [CrossRef]
- Ghosh, S.; Guchhait, S.K. Geomorphic threshold estimation for gully erosion in the lateritic soil of Birbhum, West Bengal, India. Soil Discuss. 2016, 1–29. [Google Scholar] [CrossRef]
- Sinha, D.; Joshi, V.U. Application of Universal Soil Loss Equation (USLE) to recently reclaimed badlands along the Adula and Mahalungi Rivers, Pravara Basin, Maharashtra. J. Geol. Soc. India 2012, 80, 341–350. [Google Scholar] [CrossRef]
- Bhattacharyya, T.; Babu, R.; Sarkar, D.; Mandal, C.; Dhyani, B.L.; Nagar, A.P. Soil loss and crop productivity model in humid subtropical India. Curr. Sci. 2007, 93, 1397–1403. [Google Scholar]
- Sharda, V.N.; Dogra, P.; Prakash, C. Assessment of production losses due to water erosion in rainfed areas of India. J. Soil Water Conserv. 2010, 65, 79–91. [Google Scholar] [CrossRef]
- Kachouri, S.; Achour, H.; Abida, H.; Bouaziz, S. Soil erosion hazard mapping using Analytic Hierarchy Process and logistic regression: A case study of Haffouz watershed, central Tunisia. Arab. J. Geosci. 2015, 8, 4257–4268. [Google Scholar] [CrossRef]
- Achour, Y.; Boumezbeur, A.; Hadji, R.; Chouabbi, A.; Cavaleiro, V.; Bendaoud, E.A. Landslide susceptibility mapping using analytic hierarchy process and information value methods along a highway road section in Constantine, Algeria. Arab. J. Geosci. 2017, 10, 194. [Google Scholar] [CrossRef]
- Kheir, R.B.; Wilson, J.; Deng, Y. Use of terrain variables for mapping gully erosion susceptibility in Lebanon. Earth Surf. Process. Landf. 2007, 32, 1770–1782. [Google Scholar] [CrossRef]
- Arabameri, A.; Rezaei, K.; Pourghasemi, H.R.; Lee, S.; Yamani, M. GIS-based gully erosion susceptibility mapping: A comparison among three data-driven models and AHP knowledge-based technique. Environ. Earth Sci. 2018, 77, 628. [Google Scholar] [CrossRef]
- Azareh, A.; Rahmati, O.; Rafiei-Sardooi, E.; Sankey, J.B.; Lee, S.; Shahabi, H.; Ahmad, B.B. Modelling gully-erosion susceptibility in a semi-arid region, Iran: Investigation of applicability of certainty factor and maximum entropy models. Sci. Total Environ. 2019, 655, 684–696. [Google Scholar] [CrossRef] [PubMed]
- Arabameri, A.; Cerda, A.; Tiefenbacher, J.P. Spatial Pattern Analysis and Prediction of Gully Erosion Using Novel Hybrid Model of Entropy-Weight of Evidence. Water 2019, 11, 1129. [Google Scholar] [CrossRef]
- Arabameri, A.; Pradhan, B.; Rezaei, K.; Yamani, M.; Pourghasemi, H.R.; Lombardo, L. Spatial modelling of gully erosion using evidential belief function, logistic regression, and a new ensemble of evidential belief function-logistic regression algorithm. Land Degrad. Dev. 2018, 29, 4035–4049. [Google Scholar] [CrossRef]
- Band, S.S.; Janizadeh, S.; Chandra Pal, S.; Saha, A.; Chakrabortty, R.; Shokri, M.; Mosavi, A. Novel Ensemble Approach of Deep Learning Neural Network (DLNN) Model and Particle Swarm Optimization (PSO) Algorithm for Prediction of Gully Erosion Susceptibility. Sensors 2020, 20, 5609. [Google Scholar] [CrossRef]
- Arabameri, A.; Yamani, M.; Pradhan, B.; Melesse, A.; Shirani, K.; Tien Bui, D. Novel ensembles of COPRAS multi-criteria decision-making with logistic regression, boosted regression tree, and random forest for spatial prediction of gully erosion susceptibility. Sci. Total Environ. 2019, 688, 903–916. [Google Scholar] [CrossRef]
- Arabameri, A.; Pradhan, B.; Lombardo, L. Comparative assessment using boosted regression trees, binary logistic regression, frequency ratio and numerical risk factor for gully erosion susceptibility modelling. Catena 2019, 183, 104223. [Google Scholar] [CrossRef]
- Arabameri, A.; Chen, W.; Loche, M.; Zhao, X.; Li, Y.; Lombardo, L.; Cerda, A.; Pradhan, B.; Bui, D.T. Comparison of machine learning models for gully erosion susceptibility mapping. Geosci. Front. 2020, 11, 1609–1620. [Google Scholar] [CrossRef]
- Roy, P.; Chakrabortty, R.; Chowdhuri, I.; Malik, S.; Das, B.; Pal, S.C. Development of Different Machine Learning Ensemble Classifier for Gully Erosion Susceptibility in Gandheswari Watershed of West Bengal, India. Mach. Learn. Intell. Decis. Sci. 2020, 1–26. [Google Scholar] [CrossRef]
- Chen, W.; Panahi, M.; Khosravi, K.; Pourghasemi, H.R.; Rezaie, F.; Parvinnezhad, D. Spatial prediction of groundwater potentiality using ANFIS ensembled with teaching-learning-based and biogeography-based optimization. J. Hydrol. 2019, 572, 435–448. [Google Scholar] [CrossRef]
- Ghosh, S.; Guchhait, S.K. Estimation of geomorphic threshold in permanent gullies of lateritic terrain in Birbhum, West Bengal, India. Curr. Sci. (00113891) 2017, 113, 478–485. [Google Scholar] [CrossRef]
- Hembram, T.K.; Saha, S. Prioritization of sub-watersheds for soil erosion based on morphometric attributes using fuzzy AHP and compound factor in Jainti River basin, Jharkhand, Eastern India. Environ. Dev. Sustain. 2020, 22, 1241–1268. [Google Scholar] [CrossRef]
- Chakrabortty, R.; Pal, S.C.; Chowdhuri, I.; Malik, S.; Das, B. Assessing the Importance of Static and Dynamic Causative Factors on Erosion Potentiality Using SWAT, EBF with Uncertainty and Plausibility, Logistic Regression and Novel Ensemble Model in a Sub-tropical Environment. J. Indian Soc. Remote Sens. 2020, 48, 1–25. [Google Scholar] [CrossRef]
- Chakrabortty, R.; Pal, S.C.; Sahana, M.; Mondal, A.; Dou, J.; Pham, B.T.; Yunus, A.P. Soil erosion potential hotspot zone identification using machine learning and statistical approaches in eastern India. Nat. Hazards 2020, 104, 1259–1294. [Google Scholar] [CrossRef]
- Ghosh, D.; Mandal, M.; Karmakar, M.; Banerjee, M.; Mandal, D. Application of geospatial technology for delineating groundwater potential zones in the Gandheswari watershed, West Bengal. Sustain. Water Resour. Manag. 2020, 6, 14. [Google Scholar] [CrossRef]
- Chakrabortty, R.; Pal, S.C.; Malik, S.; Das, B. Modeling and mapping of groundwater potentiality zones using AHP and GIS technique: A case study of Raniganj Block, Paschim Bardhaman, West Bengal. Model. Earth Syst. Environ. 2018, 4, 1085–1110. [Google Scholar] [CrossRef]
- Das, B.; Nandy, M. Tectono-stratigraphic studies of the supra-crustal rocks at the southern contact of the Chhotanagpur Granite Gneiss with Proterozoic Mobile Belt in Bankura and Purulia districts West Bengal. Rec. Geol. Surv. India 1997, 129 Pt 3. [Google Scholar]
- Shit, P.K.; Nandi, A.S.; Bhunia, G.S. Soil erosion risk mapping using RUSLE model on jhargram sub-division at West Bengal in India. Model. Earth Syst. Environ. 2015, 1, 28. [Google Scholar] [CrossRef]
- Shit, P.K.; Maiti, R.K. Mechanism of Gully-Head Retreat—A Study at Ganganir Danga, Paschim Medinipur, West Bengal. Ethiop. J. Environ. Stud. Manag. 2012, 5, 332–342. [Google Scholar] [CrossRef][Green Version]
- Lay, U.S.; Pradhan, B.; Yusoff, Z.B.M.; Abdallah, A.F.B.; Aryal, J.; Park, H.-J. Data Mining and Statistical Approaches in Debris-Flow Susceptibility Modelling Using Airborne LiDAR Data. Sensors 2019, 19, 3451. [Google Scholar] [CrossRef]
- Aertsen, W.; Kint, V.; Van Orshoven, J.; Özkan, K.; Muys, B. Comparison and ranking of different modelling techniques for prediction of site index in Mediterranean mountain forests. Ecol. Model. 2010, 221, 1119–1130. [Google Scholar] [CrossRef]
- Panahi, M.; Gayen, A.; Pourghasemi, H.R.; Rezaie, F.; Lee, S. Spatial prediction of landslide susceptibility using hybrid support vector regression (SVR) and the adaptive neuro-fuzzy inference system (ANFIS) with various metaheuristic algorithms. Sci. Total Environ. 2020, 741, 139937. [Google Scholar] [CrossRef]
- Arabameri, A.; Chen, W.; Lombardo, L.; Blaschke, T.; Tien Bui, D. Hybrid computational intelligence models for improvement gully erosion assessment. Remote Sens. 2020, 12, 140. [Google Scholar] [CrossRef]
- Arabameri, A.; Pradhan, B.; Bui, D.T. Spatial modelling of gully erosion in the Ardib River Watershed using three statistical-based techniques. Catena 2020, 190, 104545. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Gayen, A.; Haque, S.M.; Bai, S. Gully Erosion Susceptibility Assessment Through the SVM Machine Learning Algorithm (SVM-MLA). In Gully Erosion Studies from India and Surrounding Regions; Springer International Publishing: Cham, Switzerland, 2020; pp. 415–425. [Google Scholar]
- Arabameri, A.; Saha, S.; Mukherjee, K.; Blaschke, T.; Chen, W.; Ngo, P.T.T.; Band, S.S. Modeling Spatial Flood using Novel Ensemble Artificial Intelligence Approaches in Northern Iran. Remote Sens. 2020, 12, 3423. [Google Scholar] [CrossRef]
- Saha, S.; Roy, J.; Arabameri, A.; Blaschke, T.; Tien Bui, D. Machine Learning-Based Gully Erosion Susceptibility Mapping: A Case Study of Eastern India. Sensors 2020, 20, 1313. [Google Scholar] [CrossRef]
- Conforti, M.; Aucelli, P.P.; Robustelli, G.; Scarciglia, F. Geomorphology and GIS analysis for mapping gully erosion susceptibility in the Turbolo stream catchment (Northern Calabria, Italy). Nat. Hazards 2011, 56, 881–898. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R.; Zeinivand, H. Flood susceptibility mapping using frequency ratio and weights-of-evidence models in the Golastan Province, Iran. Geocarto Int. 2016, 31, 42–70. [Google Scholar] [CrossRef]
- Conoscenti, C.; Agnesi, V.; Angileri, S.; Cappadonia, C.; Rotigliano, E.; Märker, M. A GIS-based approach for gully erosion susceptibility modelling: A test in Sicily, Italy. Environ. Earth Sci. 2013, 70, 1179–1195. [Google Scholar] [CrossRef]
- Wilson, J.P.; Gallant, J.C. Terrain Analysis: Principles and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2000; ISBN 978-0-471-32188-0. [Google Scholar]
- Rahmati, O.; Pourghasemi, H.R.; Melesse, A.M. Application of GIS-based data driven random forest and maximum entropy models for groundwater potential mapping: A case study at Mehran Region, Iran. Catena 2016, 137, 360–372. [Google Scholar] [CrossRef]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Kadavi, P.R.; Lee, C.-W.; Lee, S. Application of Ensemble-Based Machine Learning Models to Landslide Susceptibility Mapping. Remote Sens. 2018, 10, 1252. [Google Scholar] [CrossRef]
- Conoscenti, C.; Angileri, S.; Cappadonia, C.; Rotigliano, E.; Agnesi, V.; Märker, M. Gully erosion susceptibility assessment by means of GIS-based logistic regression: A case of Sicily (Italy). Geomorphology 2014, 204, 399–411. [Google Scholar] [CrossRef]
- Zakerinejad, R.; Maerker, M. An integrated assessment of soil erosion dynamics with special emphasis on gully erosion in the Mazayjan basin, southwestern Iran. Nat. Hazards 2015, 79, 25–50. [Google Scholar] [CrossRef]
- Malik, S.; Pal, S.C.; Das, B.; Chakrabortty, R. Assessment of vegetation status of Sali River basin, a tributary of Damodar River in Bankura District, West Bengal, using satellite data. Environ. Dev. Sustain. 2020, 22, 5651–5685. [Google Scholar] [CrossRef]
- Wu, Y.; Li, W.; Wang, Q.; Liu, Q.; Yang, D.; Xing, M.; Pei, Y.; Yan, S. Landslide susceptibility assessment using frequency ratio, statistical index and certainty factor models for the Gangu County, China. Arab. J. Geosci. 2016, 9, 84. [Google Scholar] [CrossRef]
- Deng, L.; Zeng, G.; Fan, C.; Lu, L.; Chen, X.; Chen, M.; Wu, H.; He, X.; He, Y. Response of rhizosphere microbial community structure and diversity to heavy metal co-pollution in arable soil. Appl. Microbiol. Biotechnol. 2015, 99, 8259–8269. [Google Scholar] [CrossRef]
- Abd-El Monsef, H.; Smith, S.E. A new approach for estimating mangrove canopy cover using Landsat 8 imagery. Comput. Electron. Agric. 2017, 135, 183–194. [Google Scholar] [CrossRef]
- Malik, S.; Pal, S.C.; Das, B.; Chakrabortty, R. Intra-annual variations of vegetation status in a sub-tropical deciduous forest-dominated area using geospatial approach: A case study of Sali watershed, Bankura, West Bengal, India. Geol. Ecol. Landsc. 2019, 1–12. [Google Scholar] [CrossRef]
- Pal, S.C.; Chakrabortty, R.; Malik, S.; Das, B. Application of forest canopy density model for forest cover mapping using LISS-IV satellite data: A case study of Sali watershed, West Bengal. Model. Earth Syst. Environ. 2018, 4, 853–865. [Google Scholar] [CrossRef]
- Gao, B. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Alin, A. Multicollinearity. Wires Comput. Stat. 2010, 2, 370–374. [Google Scholar] [CrossRef]
- Jensen, D.R.; Ramirez, D.E. Revision: Variance inflation in regression. Adv. Decis. Sci. 2013, 2013, 671204. [Google Scholar] [CrossRef]
- Ravì, D.; Bober, M.; Farinella, G.M.; Guarnera, M.; Battiato, S. Semantic segmentation of images exploiting DCT based features and random forest. Pattern Recognit. 2016, 52, 260–273. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Sevgen, E.; Kocaman, S.; Nefeslioglu, H.A.; Gokceoglu, C. A novel performance assessment approach using photogrammetric techniques for landslide susceptibility mapping with logistic regression, ANN and random forest. Sensors 2019, 19, 3940. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. Isprs J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Masetic, Z.; Subasi, A. Congestive heart failure detection using random forest classifier. Comput. Methods Programs Biomed. 2016, 130, 54–64. [Google Scholar] [CrossRef] [PubMed]
- Saaty, T.L. The Analytic Hierarchy Process; International, Translated to Russian, Portuguesses and Chinese, Revised edition, Paperback (1996, 2000); Mcgrew Hill: New York, NY, USA; RWS Publications: Pittsburgh, PA, USA, 1980; Volume 9, pp. 19–22. [Google Scholar]
- Saaty, T.L.; Vargas, L.G. Models, Methods, Concepts & Applications of the Analytic Hierarchy Process; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 175, ISBN 1-4614-3596-X. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Zolfani, S.H.; Chatterjee, P. Comparative evaluation of sustainable design based on Step-Wise Weight Assessment Ratio Analysis (SWARA) and Best Worst Method (BWM) methods: A perspective on household furnishing materials. Symmetry 2019, 11, 74. [Google Scholar] [CrossRef]
- Keršuliene, V.; Zavadskas, E.K.; Turskis, Z. Selection of rational dispute resolution method by applying new step-wise weight assessment ratio analysis (SWARA). J. Bus. Econ. Manag. 2010, 11, 243–258. [Google Scholar] [CrossRef]
- Stanujkic, D.; Karabasevic, D.; Zavadskas, E.K. A framework for the selection of a packaging design based on the SWARA method. Eng. Econ. 2015, 26, 181–187. [Google Scholar] [CrossRef]
- Vafaeipour, M.; Zolfani, S.H.; Varzandeh, M.H.M.; Derakhti, A.; Eshkalag, M.K. Assessment of regions priority for implementation of solar projects in Iran: New application of a hybrid multi-criteria decision making approach. Energy Convers. Manag. 2014, 86, 653–663. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Pourghasemi, H.R.; Dixon, B. GIS-based groundwater potential mapping using boosted regression tree, classification and regression tree, and random forest machine learning models in Iran. Environ. Monit. Assess. 2016, 188, 44. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Vafakhah, M.; Hashemi, H.; Pradhan, B.; Alavi, S.J. Groundwater augmentation through the site selection of floodwater spreading using a data mining approach (case study: Mashhad Plain, Iran). Water 2018, 10, 1405. [Google Scholar] [CrossRef]
- Rahmati, O.; Naghibi, S.A.; Shahabi, H.; Bui, D.T.; Pradhan, B.; Azareh, A.; Rafiei-Sardooi, E.; Samani, A.N.; Melesse, A.M. Groundwater spring potential modelling: Comprising the capability and robustness of three different modeling approaches. J. Hydrol. 2018, 565, 248–261. [Google Scholar] [CrossRef]
- Motevalli, A.; Pourghasemi, H.R.; Hashemi, H.; Gholami, V. Assessing the vulnerability of groundwater to salinization using GIS-based data-mining techniques in a coastal aquifer. In Spatial Modeling in GIS and R for Earth and Environmental Sciences; Elsevier: Amsterdam, The Netherlands, 2019; pp. 547–571. [Google Scholar]
- Kuhn, M.; Weston, S.; Keefer, C.; Coulter, N.; Quinlan, R. Cubist: Rule-and Instance-Based Regression Modeling; R Package Version 0.0; CRAN: Vienna, Austria, 2014; p. 13. [Google Scholar]
- Leathwick, J.R.; Elith, J.; Francis, M.P.; Hastie, T.; Taylor, P. Variation in demersal fish species richness in the oceans surrounding New Zealand: An analysis using boosted regression trees. Mar. Ecol. Prog. Ser. 2006, 321, 267–281. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine 1 function estimation 2 numerical optimization in function space. North 1999, 1, 1–10. [Google Scholar]
- Hernández, B.; Raftery, A.E.; Pennington, S.R.; Parnell, A.C. Bayesian additive regression trees using Bayesian model averaging. Stat. Comput. 2018, 28, 869–890. [Google Scholar] [CrossRef]
- Sparapani, R.A.; Logan, B.R.; McCulloch, R.E.; Laud, P.W. Nonparametric survival analysis using Bayesian additive regression trees (BART). Stat. Med. 2016, 35, 2741–2753. [Google Scholar] [CrossRef] [PubMed]
- Chipman, H.A.; George, E.I.; McCulloch, R.E. BART: Bayesian additive regression trees. Ann. Appl. Stat. 2010, 4, 266–298. [Google Scholar] [CrossRef]
- Vapnik, V.; Golowich, S.E.; Smola, A.J. Support vector method for function approximation, regression estimation and signal processing. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1996; pp. 281–287. [Google Scholar]
- Lu, C.-J.; Lee, T.-S.; Chiu, C.-C. Financial time series forecasting using independent component analysis and support vector regression. Decis. Support Syst. 2009, 47, 115–125. [Google Scholar] [CrossRef]
- Li, D.; Simske, S. Example based single-frame image super-resolution by support vector regression. J. Pattern Recognit. Res. 2010, 1, 104–118. [Google Scholar] [CrossRef]
- Kalantar, B.; Pradhan, B.; Naghibi, S.A.; Motevalli, A.; Mansor, S. Assessment of the effects of training data selection on the landslide susceptibility mapping: A comparison between support vector machine (SVM), logistic regression (LR) and artificial neural networks (ANN). Geomat. Nat. Hazards Risk 2018, 9, 49–69. [Google Scholar] [CrossRef]
- Su, H.; Li, X.; Yang, B.; Wen, Z. Wavelet support vector machine-based prediction model of dam deformation. Mech. Syst. Signal Process. 2018, 110, 412–427. [Google Scholar] [CrossRef]
- Wang, J.; Li, L.; Niu, D.; Tan, Z. An annual load forecasting model based on support vector regression with differential evolution algorithm. Appl. Energy 2012, 94, 65–70. [Google Scholar] [CrossRef]
- Eberhart, R.C.; Shi, Y.; Kennedy, J. Swarm Intelligence; Elsevier: Amsterdam, The Netherlands, 2001; ISBN 0-08-051826-5. [Google Scholar]
- Pham, D.T.; Otri, S.; Afify, A.; Mahmuddin, M.; Al-Jabbouli, H. Data clustering using the bees algorithm. In Proceedings of the 40th CIRP International Manufacturing Systems Seminar, Liverpool, UK, 30 May–1 June 2007. [Google Scholar]
- Kavousi, A.; Vahidi, B.; Salehi, R.; Bakhshizadeh, M.K.; Farokhnia, N.; Fathi, S.H. Application of the bee algorithm for selective harmonic elimination strategy in multilevel inverters. IEEE Trans. Power Electron. 2011, 27, 1689–1696. [Google Scholar] [CrossRef]
- Gayen, A.; Pourghasemi, H.R. Spatial modeling of gully erosion: A new ensemble of CART and GLM data-mining algorithms. In Spatial Modeling in GIS and R for Earth and Environmental Sciences; Elsevier: Amsterdam, The Netherlands, 2019; pp. 653–669. [Google Scholar]
- Chowdhuri, I.; Pal, S.C.; Chakrabortty, R. Flood susceptibility mapping by ensemble evidential belief function and binomial logistic regression model on river basin of eastern India. Adv. Space Res. 2020, 65, 1466–1489. [Google Scholar] [CrossRef]
- Thai Pham, B.; Shirzadi, A.; Shahabi, H.; Omidvar, E.; Singh, S.K.; Sahana, M.; Talebpour Asl, D.; Bin Ahmad, B.; Kim Quoc, N.; Lee, S. Landslide susceptibility assessment by novel hybrid machine learning algorithms. Sustainability 2019, 11, 4386. [Google Scholar] [CrossRef]
- Pal, S.C.; Chowdhuri, I. GIS-based spatial prediction of landslide susceptibility using frequency ratio model of Lachung River basin, North Sikkim, India. SN Appl. Sci. 2019, 1, 416. [Google Scholar] [CrossRef]
- Bui, D.T.; Ho, T.-C.; Pradhan, B.; Pham, B.-T.; Nhu, V.-H.; Revhaug, I. GIS-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with AdaBoost, Bagging, and MultiBoost ensemble frameworks. Environ. Earth Sci. 2016, 75, 1101. [Google Scholar]
- Fukuda, S.; De Baets, B.; Waegeman, W.; Verwaeren, J.; Mouton, A.M. Habitat prediction and knowledge extraction for spawning European grayling (Thymallus thymallus L.) using a broad range of species distribution models. Environ. Model. Softw. 2013, 47, 1–6. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Dou, J.; Yunus, A.P.; Merghadi, A.; Shirzadi, A.; Nguyen, H.; Hussain, Y.; Avtar, R.; Chen, Y.; Pham, B.T.; Yamagishi, H. Different sampling strategies for predicting landslide susceptibilities are deemed less consequential with deep learning. Sci. Total Environ. 2020, 720, 137320. [Google Scholar] [CrossRef]
- Arabameri, A.; Cerda, A.; Rodrigo-Comino, J.; Pradhan, B.; Sohrabi, M.; Blaschke, T.; Tien Bui, D. Proposing a Novel Predictive Technique for Gully Erosion Susceptibility Mapping in Arid and Semi-arid Regions (Iran). Remote Sens. 2019, 11, 2577. [Google Scholar] [CrossRef]
- Nhu, V.-H.; Janizadeh, S.; Avand, M.; Chen, W.; Farzin, M.; Omidvar, E.; Shirzadi, A.; Shahabi, H.; Clague, J.J.; Jaafari, A.; et al. GIS-Based Gully Erosion Susceptibility Mapping: A Comparison of Computational Ensemble Data Mining Models. Appl. Sci. 2020, 10, 2039. [Google Scholar] [CrossRef]
- Arabameri, A.; Pradhan, B.; Rezaei, K.; Conoscenti, C. Gully erosion susceptibility mapping using GIS-based multi-criteria decision analysis techniques. Catena 2019, 180, 282–297. [Google Scholar] [CrossRef]
- Malik, S.; Pal, S.C.; Chowdhuri, I.; Chakrabortty, R.; Roy, P.; Das, B. Prediction of highly flood prone areas by GIS based heuristic and statistical model in a monsoon dominated region of Bengal Basin. Remote Sens. Appl. Soc. Environ. 2020, 19, 100343. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Omidvar, E.; Shirzadi, A.; Geertsema, M.; Clague, J.J.; Khosravi, K.; Pradhan, B.; Pham, B.T.; Chapi, K.; et al. Shallow Landslide Prediction Using a Novel Hybrid Functional Machine Learning Algorithm. Remote Sens. 2019, 11, 931. [Google Scholar] [CrossRef]
- Xiao, L.; Zhang, Y.; Peng, G. Landslide Susceptibility Assessment Using Integrated Deep Learning Algorithm along the China-Nepal Highway. Sensors 2018, 18, 4436. [Google Scholar] [CrossRef]
- Mezaal, M.R.; Pradhan, B.; Shafri, H.Z.M.; Mojaddadi, H.; Yusoff, Z.M. Optimized hierarchical rule-based classification for differentiating shallow and deep-seated landslide using high-resolution LiDAR data. In Proceedings of the Global Civil Engineering Conference, Kuala Lumpur, Malaysia, 25–28 June 2017; pp. 825–848. [Google Scholar]
- Rahmati, O.; Tahmasebipour, N.; Haghizadeh, A.; Pourghasemi, H.R.; Feizizadeh, B. Evaluating the influence of geo-environmental factors on gully erosion in a semi-arid region of Iran: An integrated framework. Sci. Total Environ. 2017, 579, 913–927. [Google Scholar] [CrossRef]
- Amiri, M.; Pourghasemi, H.R.; Ghanbarian, G.A.; Afzali, S.F. Assessment of the importance of gully erosion effective factors using Boruta algorithm and its spatial modeling and mapping using three machine learning algorithms. Geoderma 2019, 340, 55–69. [Google Scholar] [CrossRef]
- Gómez-Gutiérrez, Á.; Conoscenti, C.; Angileri, S.E.; Rotigliano, E.; Schnabel, S. Using topographical attributes to evaluate gully erosion proneness (susceptibility) in two mediterranean basins: Advantages and limitations. Nat. Hazards 2015, 79, 291–314. [Google Scholar] [CrossRef]
- Arabameri, A.; Pradhan, B.; Rezaei, K. Spatial prediction of gully erosion using ALOS PALSAR data and ensemble bivariate and data mining models. Geosci. J. 2019, 23, 669–686. [Google Scholar] [CrossRef]
- Gayen, A.; Pourghasemi, H.R.; Saha, S.; Keesstra, S.; Bai, S. Gully erosion susceptibility assessment and management of hazard-prone areas in India using different machine learning algorithms. Sci. Total Environ. 2019, 668, 124–138. [Google Scholar] [CrossRef] [PubMed]
- Zabihi, M.; Pourghasemi, H.R.; Motevalli, A.; Zakeri, M.A. Gully Erosion Modeling Using GIS-Based Data Mining Techniques in Northern Iran: A Comparison Between Boosted Regression Tree and Multivariate Adaptive Regression Spline. In Natural Hazards GIS-Based Spatial Modeling Using Data Mining Techniques; Pourghasemi, H.R., Rossi, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 1–26. ISBN 978-3-319-73383-8. [Google Scholar]
- Gholami, H.; Mohamadifar, A.; Collins, A.L. Spatial mapping of the provenance of storm dust: Application of data mining and ensemble modelling. Atmos. Res. 2020, 233, 104716. [Google Scholar] [CrossRef]
- Panahi, M.; Sadhasivam, N.; Pourghasemi, H.R.; Rezaie, F.; Lee, S. Spatial prediction of groundwater potential mapping based on convolutional neural network (CNN) and support vector regression (SVR). J. Hydrol. 2020, 588, 125033. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Yousefi, S.; Kornejady, A.; Cerdà, A. Performance assessment of individual and ensemble data-mining techniques for gully erosion modeling. Sci. Total Environ. 2017, 609, 764–775. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sl. No. | GECFs | Source | Time | Spatial Resolution/Scale |
|---|---|---|---|---|
| 1 | Slope | ALOSPALSAR DEM | 2011 | 12.5 m |
| 2 | Aspect | ALOSPALSAR DEM | 2011 | 12.5 m |
| 3 | Elevation | ALOSPALSAR DEM | 2011 | 12.5 m |
| 4 | Profile Curvature | ALOSPALSAR DEM | 2011 | 12.5 m |
| 5 | Plan Curvature | ALOSPALSAR DEM | 2011 | 12.5 m |
| 6 | TWI | ALOSPALSAR DEM | 2011 | 12.5 m |
| 7 | SPI | ALOSPALSAR DEM | 2011 | 12.5 m |
| 8 | Drainage Density | ALOSPALSAR DEM | 2011 | 12.5 m |
| 9 | Distance to River | ALOSPALSAR DEM | 2011 | 12.5 m |
| 10 | Rainfall | India Meteorological Department (IMD) | January to December, 2019 | - |
| 11 | LULC | Sentinel 2A satellite image | October, 2019 | 10 m |
| 12 | NDVI | Landsat 8 OLI satellite image | September, 2019 | 30 m |
| 13 | Soil Texture | National Bureau of Soil Survey and land use planning (NBSS & LUP) | 1991 | 1:500,000 |
| 14 | Soil Erodibility | National Bureau of Soil Survey and land use planning (NBSS & LUP) | 1991 | 1:500,000 |
| 15 | Geology | Geological Survey of India (GSI) | 1995 | 1:2,500,000 |
| 16 | Geomorphology | Geological Survey of India (GSI) | 1995 | 1:2,500,000 |
| 17 | BSI | Landsat 8 OLI satellite image | September, 2019 | 30 m |
| 18 | FMI | Landsat 8 OLI satellite image | September, 2019 | 30 m |
| 19 | Iron Oxide | Landsat 8 OLI satellite image | September, 2019 | 30 m |
| 20 | NDWI | Landsat 8 OLI satellite image | September, 2019 | 30 m |
| Row | Variable | Tolerance | VIF |
|---|---|---|---|
| 1 | Slope | 0.735 | 1.3601633 |
| 2 | Aspect | 0.261 | 3.8378052 |
| 3 | Elevation | 0.240 | 4.1678048 |
| 4 | Profile Curvature | 0.553 | 1.8092101 |
| 5 | Plan Curvature | 0.447 | 2.2355713 |
| 6 | TWI | 0.277 | 3.6039329 |
| 7 | SPI | 0.383 | 2.6086181 |
| 8 | Drainage Density | 0.407 | 2.4592634 |
| 9 | Distance to River | 0.244 | 4.0997097 |
| 10 | Rainfall | 0.375 | 2.6667942 |
| 11 | LULC | 0.886 | 1.1289734 |
| 12 | NDVI | 0.372 | 2.6892045 |
| 13 | Soil Texture | 0.266 | 3.7618335 |
| 14 | Soil Erodibility | 0.859 | 1.1639245 |
| 15 | Geology | 0.769 | 1.3011402 |
| 16 | Geomorphology | 0.621 | 1.6098024 |
| 17 | BSI | 0.287 | 3.4843206 |
| 18 | FMI | 0.781 | 1.2803682 |
| 19 | Iron Oxide | 0.353 | 2.8344049 |
| 20 | NDWI | 0.368 | 2.7173913 |
| Row | Variable | Importance |
|---|---|---|
| 1 | Slope | 7.51 |
| 2 | Aspect | 1.32 |
| 3 | Elevation | 10.02 |
| 4 | Profile Curvature | 1.49 |
| 5 | Plan Curvature | 20.24 |
| 6 | TWI | 1.13 |
| 7 | SPI | 16.48 |
| 8 | Drainage Density | 14.51 |
| 9 | Distance to River | 3.06 |
| 10 | Rainfall | 8.68 |
| 11 | LULC | 5.42 |
| 12 | NDVI | 22.62 |
| 13 | Soil Texture | 3.24 |
| 14 | Soil Erodibility | 2.123 |
| 15 | Geology | 15.41 |
| 16 | Geomorphology | 13.21 |
| 17 | BSI | 1.84 |
| 18 | FMI | 0.94 |
| 19 | Iron oxide | 0.42 |
| 20 | NDWI | 1.76 |
| Conditioning Factor | Class | No. of Pixel | Pixel (%) | No. of Gully Point | Percentage of Gully Point | SWARA Weight |
|---|---|---|---|---|---|---|
| Slope (In degree) | 0 to 1.01 | 458,112 | 18.23 | 10 | 16.13 | 0.18 |
| 1.01 to 3.38 | 1,326,437 | 52.78 | 28 | 45.16 | 0.17 | |
| 3.38 to 5.75 | 577,799 | 22.99 | 17 | 27.42 | 0.24 | |
| 5.75 to 15.24 | 137,842 | 5.48 | 7 | 11.29 | 0.41 | |
| 15.24 to 43.18 | 12,941 | 0.51 | 0 | 0.00 | 0.00 | |
| Aspect | Flat | 263,299 | 10.48 | 3 | 4.84 | 0.05 |
| North | 243,704 | 9.70 | 10 | 16.13 | 0.18 | |
| Northeast | 302,795 | 12.05 | 7 | 11.29 | 0.10 | |
| East | 265,277 | 10.56 | 11 | 17.74 | 0.19 | |
| Southeast | 335,165 | 13.34 | 8 | 12.90 | 0.11 | |
| South | 275,716 | 10.97 | 9 | 14.52 | 0.15 | |
| Southwest | 306,121 | 12.18 | 7 | 11.29 | 0.10 | |
| West | 240,232 | 9.56 | 3 | 4.84 | 0.06 | |
| Northwest | 280,822 | 11.17 | 4 | 6.45 | 0.06 | |
| Elevation (m) | 11 to 55 | 744,812 | 29.64 | 6 | 9.68 | 0.11 |
| 55 to 80 | 1,025,400 | 40.80 | 22 | 35.48 | 0.28 | |
| 80 to 141 | 730,786 | 29.08 | 34 | 54.84 | 0.61 | |
| 141 to 246 | 7224 | 0.29 | 0 | 0.00 | 0.00 | |
| 246 to 383 | 4909 | 0.20 | 0 | 0.00 | 0.00 | |
| Profile Curvature | −3.32 to −0.90 | 22,376 | 0.89 | 0 | 0.00 | 0.00 |
| −0.90 to −0.34 | 700,738 | 27.88 | 17 | 27.42 | 0.32 | |
| −0.34 to 0.28 | 1,043,997 | 41.54 | 23 | 37.10 | 0.29 | |
| 0.28 to 0.84 | 722,010 | 28.73 | 22 | 35.48 | 0.40 | |
| 0.84 to 2.61 | 24,010 | 0.96 | 0 | 0.00 | 0.00 | |
| Plan Curvature | −3.18 to −0.91 | 31,580 | 1.26 | 1 | 1.61 | 0.20 |
| −0.91 to −0.33 | 450,581 | 17.93 | 9 | 14.52 | 0.13 | |
| −0.33 to 0.26 | 1,527,599 | 60.78 | 38 | 61.29 | 0.16 | |
| 0.26 to 0.86 | 467,912 | 18.62 | 12 | 19.35 | 0.16 | |
| 0.86 to 2.96 | 35,459 | 1.41 | 2 | 3.23 | 0.36 | |
| TWI | 6.94 to 10.54 | 896,095 | 35.66 | 21 | 33.87 | 0.16 |
| 10.54 to 12.01 | 846,419 | 33.68 | 15 | 24.19 | 0.12 | |
| 12.01 to 14.05 | 528,698 | 21.04 | 13 | 20.97 | 0.17 | |
| 14.05 to 17.24 | 197,434 | 7.86 | 12 | 19.35 | 0.41 | |
| 17.24 to 27.78 | 44,486 | 1.77 | 1 | 1.61 | 0.15 | |
| SPI | 0.34 to 4.22 | 833,825 | 33.18 | 9 | 14.52 | 0.08 |
| 4.22 to 5.67 | 862,326 | 34.31 | 24 | 38.71 | 0.21 | |
| 5.67 to 7.57 | 578,440 | 23.02 | 15 | 24.19 | 0.19 | |
| 7.57 to 10.69 | 198,164 | 7.89 | 14 | 22.58 | 0.52 | |
| 10.69 to 19.75 | 40,376 | 1.61 | 0 | 0.00 | 0.00 | |
| Drainage Density (km/sq.km) | 0 to 0.66 | 1,401,389 | 55.76 | 45 | 72.58 | 0.36 |
| 0.66 to 1.87 | 512,310 | 20.39 | 6 | 9.68 | 0.13 | |
| 1.87 to 3.090 | 309,690 | 12.32 | 7 | 11.29 | 0.26 | |
| 3.09 to 4.35 | 183,664 | 7.31 | 4 | 6.45 | 0.25 | |
| 4.35 to 6.730 | 106,078 | 4.22 | 0 | 0.00 | 0.00 | |
| Distance from River (m) | 0 to 446.360 | 771,695 | 30.71 | 15 | 24.19 | 0.11 |
| 446.36 to 937.36 | 720,846 | 28.68 | 9 | 14.52 | 0.07 | |
| 937.36 to 1473.00 | 585,113 | 23.28 | 18 | 29.03 | 0.17 | |
| 1473.00 to 2172.300 | 344,412 | 13.70 | 13 | 20.97 | 0.21 | |
| 2172.30 to 3794.09 | 91,065 | 3.62 | 7 | 11.29 | 0.43 | |
| Rainfall (mm) | 515.62 to 519.48 | 1,129,207 | 44.93 | 25 | 40.32 | 0.24 |
| 519.48 to 522.17 | 727,191 | 28.94 | 25 | 40.32 | 0.37 | |
| 522.17 to 526.28 | 327,188 | 13.02 | 12 | 19.35 | 0.39 | |
| 526.28 to 531.32 | 178,568 | 7.11 | 0 | 0.00 | 0.00 | |
| 531.32 to 537.03 | 150,977 | 6.01 | 0 | 0.00 | 0.00 | |
| LULC | Crop land (2) | 2,158,587 | 85.89 | 44 | 70.97 | 0.11 |
| Built-up area (3) | 110,573 | 4.40 | 0 | 0.00 | 0.00 | |
| Shrubland (4) | 119,196 | 4.74 | 12 | 19.35 | 0.56 | |
| Water bodies (5) | 21,557 | 0.86 | 0 | 0.00 | 0.00 | |
| Deciduous Broadleaf forest (1) | 103,219 | 4.11 | 6 | 9.68 | 0.32 | |
| NDVI | −0.10 to 0.05 | 58,303 | 2.32 | 0 | 0.00 | 0.00 |
| 0.05 to 0.09 | 330,550 | 13.15 | 4 | 6.45 | 0.12 | |
| 0.09 to 0.12 | 1,035,882 | 41.22 | 27 | 43.55 | 0.26 | |
| 0.12 to 0.15 | 909,469 | 36.19 | 25 | 40.32 | 0.28 | |
| 0.15 to 0.31 | 178,927 | 7.12 | 6 | 9.68 | 0.34 | |
| Soil texture | Urban area | 38,904 | 1.55 | 1 | 1.61 | 0.15 |
| Gravelly loam | 55,662 | 2.21 | 4 | 6.45 | 0.42 | |
| Fine loamy-sandy | 4071 | 0.16 | 0 | 0.00 | 0.00 | |
| Fine loamy | 1,994,650 | 79.37 | 33 | 53.23 | 0.10 | |
| Fine clay | 419,844 | 16.71 | 24 | 38.71 | 0.33 | |
| Soil erodibility | 0.00 to 0.13 | 55,601 | 2.21 | 5 | 8.06 | 0.79 |
| 0.13 to 0.14 | 35,051 | 1.39 | 0 | 0.00 | 0.00 | |
| 0.14 to 0.20 | 38,904 | 1.55 | 0 | 0.00 | 0.00 | |
| 0.20 to 0.32 | 4064 | 0.16 | 0 | 0.00 | 0.00 | |
| 0.32 to 0.38 | 2,379,512 | 94.68 | 57 | 91.94 | 0.21 | |
| Geology | Unclassified Metamorphics | 57,209 | 2.28 | 0 | 0.00 | 0.00 |
| Chotanagpur Gneissic Complex | 2,423,383 | 96.43 | 62 | 100.00 | 1.00 | |
| Fluvial sediments | 30,930 | 1.23 | 0 | 0.00 | 0.00 | |
| Gabbro and Anorthosite Complex | 1608 | 0.06 | 0 | 0.00 | 0.00 | |
| Geomorplogyho | River | 21,787 | 0.87 | 0 | 0.00 | 0.00 |
| pond | 17,422 | 0.69 | 0 | 0.00 | 0.00 | |
| Water bodies | 13,582 | 0.54 | 0 | 0.00 | 0.00 | |
| Older flood plain | 5954 | 0.24 | 0 | 0.00 | 0.00 | |
| Active flood plain | 39 | 0.00 | 0 | 0.00 | 0.00 | |
| Pediment Pediplain Complex | 2,422,453 | 96.39 | 57 | 91.94 | 0.13 | |
| Dissected Denudational Hills and Valleys | 31,894 | 1.27 | 5 | 8.06 | 0.87 | |
| BSI | −1016 to −391 | 948 | 0.04 | 0 | 0.00 | 0.00 |
| −391 to −82 | 5079 | 0.20 | 0 | 0.00 | 0.00 | |
| −82 to 86 | 2,501,714 | 99.55 | 62 | 100.00 | 1.00 | |
| 86 to 406 | 4466 | 0.18 | 0 | 0.00 | 0.00 | |
| 406 to 897 | 924 | 0.04 | 0 | 0.00 | 0.00 | |
| FMI | 0.95 to 1.11 | 122,659 | 4.88 | 3 | 4.84 | 0.20 |
| 1.11 to 1.138 | 504,745 | 20.08 | 7 | 11.29 | 0.11 | |
| 1.138 to 1.160 | 737,875 | 29.36 | 19 | 30.65 | 0.21 | |
| 1.16 to 1.18 | 711,738 | 28.32 | 19 | 30.65 | 0.22 | |
| 1.18 to 1.28 | 436,114 | 17.35 | 14 | 22.58 | 0.26 | |
| Ironoxide | 0.77 to 1.14 | 97,282 | 3.87 | 1 | 1.61 | 0.08 |
| 1.14 to 1.23 | 595,379 | 23.69 | 12 | 19.35 | 0.16 | |
| 1.23 to 1.290 | 1,169,281 | 46.53 | 26 | 41.94 | 0.18 | |
| 1.29 to 1.38 | 536,239 | 21.34 | 19 | 30.65 | 0.29 | |
| 1.38 to 2.04 | 114,949 | 4.57 | 4 | 6.45 | 0.28 | |
| NDWI | −0.41 to 0.10 | 41,513.00 | 1.65 | 2.00 | 3.23 | 0.31 |
| 0.10 to 0.17 | 314,512.00 | 12.51 | 8.00 | 12.90 | 0.16 | |
| 0.17 to 0.21 | 914,621.00 | 36.39 | 21.00 | 33.87 | 0.15 | |
| 0.21 to 0.28 | 1,046,142.00 | 41.63 | 24.00 | 38.71 | 0.15 | |
| 0.28 to 0.43 | 196,343.00 | 7.81 | 7.00 | 11.29 | 0.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chowdhuri, I.; Pal, S.C.; Arabameri, A.; Saha, A.; Chakrabortty, R.; Blaschke, T.; Pradhan, B.; Band, S.S. Implementation of Artificial Intelligence Based Ensemble Models for Gully Erosion Susceptibility Assessment. Remote Sens. 2020, 12, 3620. https://doi.org/10.3390/rs12213620
Chowdhuri I, Pal SC, Arabameri A, Saha A, Chakrabortty R, Blaschke T, Pradhan B, Band SS. Implementation of Artificial Intelligence Based Ensemble Models for Gully Erosion Susceptibility Assessment. Remote Sensing. 2020; 12(21):3620. https://doi.org/10.3390/rs12213620
Chicago/Turabian StyleChowdhuri, Indrajit, Subodh Chandra Pal, Alireza Arabameri, Asish Saha, Rabin Chakrabortty, Thomas Blaschke, Biswajeet Pradhan, and Shahab. S. Band. 2020. "Implementation of Artificial Intelligence Based Ensemble Models for Gully Erosion Susceptibility Assessment" Remote Sensing 12, no. 21: 3620. https://doi.org/10.3390/rs12213620
APA StyleChowdhuri, I., Pal, S. C., Arabameri, A., Saha, A., Chakrabortty, R., Blaschke, T., Pradhan, B., & Band, S. S. (2020). Implementation of Artificial Intelligence Based Ensemble Models for Gully Erosion Susceptibility Assessment. Remote Sensing, 12(21), 3620. https://doi.org/10.3390/rs12213620