1. Introduction
Remote sensing imaging techniques have opened doors for people to understand the earth better. In recent years, as the resolution of remote sensing images has increased, remote sensing target detection (e.g., the detection of aeroplanes, ships, oil-pots, and so on) has become a research hotspot [
1,
2,
3,
4,
5]. Remote sensing target detection has a broad range of applications, such as military investigation, disaster rescue, and urban traffic management. Differing from natural images taken from low-altitude perspectives, aerial images are taken from a bird’s-eye view, which implies that the objects in aerial images are arbitrarily oriented. Moreover, in many circumstances, the background is complex and the targets are densely arranged, often varying in shape and orientation. These problems make target detection using aerial images very challenging. Most advanced object detection methods rely on rectangular-shaped horizontal/vertical bounding boxes drawn on the object to accurately locate its position. In the most common cases, this approach works; however, when it comes to aerial images, its use is limited, as shown in
Figure 1a. Such orthogonal bounding boxes ignore the object pose and shape, resulting in reduced object localization and limiting downstream tasks (e.g., object understanding and tracking). In this case, an oriented bounding box is needed to mark the image area more accurately, as shown in
Figure 1b.
Benefitting from R-CNN frameworks [
2,
4,
6,
7,
8,
9,
10,
11], many recent works on object detection in aerial images have reported promising detection performances. They have used the region proposal network (RPN) to generate regions of interest (RoIs) from horizontal bounding boxes, followed by identifying their category through region-based features. However, [
5,
12] showed that these horizontal RoIs (HRoIs) typically lead to misalignments between the bounding boxes and objects. As a result, it is usually difficult to train a detector to extract object features and identify the object’s localization accurately. Instead of using horizontal bounding boxes, many methods regress the oriented bounding boxes by using rotated RoIs (RRoIs). In [
5,
12,
13,
14,
15], rotated anchors are added on the basis of the original. In order to achieve a higher recall rate in the regional proposal stage, they use anchors with different angles, scales, and aspect ratios. The rapid increase in the number of anchors makes the algorithm very time-consuming, however. [
16,
17] designed a converter to transform HRoIs into RRoIs. Although this method reduces the time consumption due to anchors, it also has a more complex network structure.
FCN [
18] brought semantic segmentation into the deep learning era, being the first pixels-to-pixels semantic segmentation method which was end-to-end trained. Compared with patch-wise classification for object detection, semantic segmentation can better carry out spatial context modeling and avoid redundant computation on overlapping areas between patches. Many applications using semantic segmentation techniques have been proposed in the remote sensing literature, such as building extraction [
19,
20,
21,
22], road extraction [
23,
24,
25,
26,
27], vehicle detection [
28], land-use and land-cover (LULC) classification [
29,
30,
31], and so on. The main methodologies in these works follow general semantic segmentation but, for some special application scenarios (e.g., vehicles or buildings), many improved techniques [
20,
25,
27] have been proposed for the application scenario. However, semantic segmentation requires pixel-wise annotation, which greatly increases the cost of data annotation. At the same time, due to its inability to distinguish intra-class instances, it is not suitable for scenes with densely arranged targets.
We start with the structure of the network. Features encoded in the deeper layers of a CNN are beneficial for category recognition, but not conducive to localizing objects. The pooling layers in a CNN preserve strength information and broaden the receptive field, while losing location information to a great extent. Relative works [
9,
32,
33,
34] have shown that the descriptors have a feeble ability to locate the objects, relative to the center of the filter. On the other hand, many related works [
35,
36,
37] have shown that learning with segmentation can lead to great results. Edges and boundaries are the essential elements that constitute human visual cognition [
38,
39]. As the feature of semantic segmentation tasks captures the boundary of an object well, segmentation may be helpful for category recognition. Secondly, the ground-truth bounding box of an object is determined by its (well-defined) boundary. For some objects with non-rectangular shapes (e.g., a slender ship), it is challenging to predict high IoU locations. As object boundaries can be well-encoded in semantic segmentation features, learning with segmentation can be helpful in achieving accurate object localization.
To this end, we propose the ellipse field network (EFN), a detector with a more efficient network structure and a training method that preserves location information. EFN can be regarded as the supplement and upgrade of general semantic segmentation, which has a strong ability for pixel-by-pixel classification and can achieve fine-grained region division. The main problem is that pixels of the same kind are connected, while the sort of each pixel is isolated, such that we cannot obtain the comprehensive information of an object, nor the number of objects, which is difficult to carry out without adequate semantic understanding. EFN proposes the concept of an object field (OF), which is defined as a probability density function describing the distribution of objects in image space; it is composed of a center field (CF) and an edge field (EF). Luo et al. [
40] showed that an effective receptive field follows a Gaussian distribution. In combination with practical results, we consider that the 2D Gaussian distribution is an appropriate choice for the object field [
41]. The intensity distribution of the Gaussian distribution is related to the elliptic equation (as shown in
Figure 2b), which is why we call this method the ellipse field network. Besides, we designed a special post-processing step for the object field—ellipse region fitting (ERF)—which combines the center field and the edge field, in order to finally obtain the ellipse region set of objects. In summary, our work provides several advantages:
The unique field-based framework design, combined with the feature map concatenation operation, enables the network to learn features and location information better.
It combines the advantages of object detection and semantic segmentation and, so, can finely locate and classify each instance.
Ellipse region fitting: the corresponding post-processing process makes the results more robust and reliable.
An effective image mosaic method called spray painting is proposed, in order to process high-resolution images.
The rest of the paper is organized as follows: After the introductory
Section 1, detailing object detection in aerial images, we enter
Section 2, which is dedicated to the details of the proposed EFN.
Section 3 then introduces the spray painting and post-processing step we designed for EFN, while
Section 4 provides data set information, implementation details, experimental results, and discussion. Finally,
Section 5 concludes the paper.
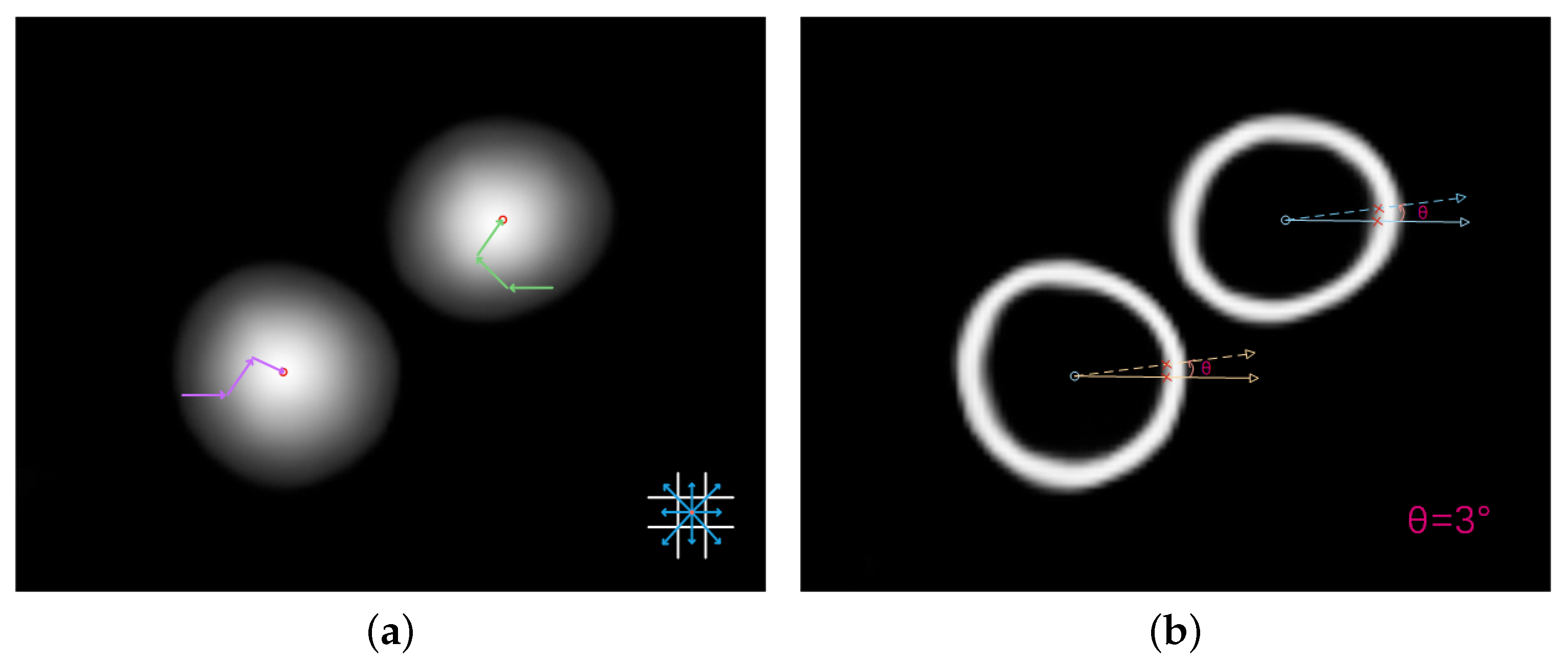
Figure 2.
Overall pipeline: (a) input; (b) Center Field (top) and Edge Field (bottom); (c) post-processing by ellipse region fitting (ERF); and (d) the detection result.
Figure 2.
Overall pipeline: (a) input; (b) Center Field (top) and Edge Field (bottom); (c) post-processing by ellipse region fitting (ERF); and (d) the detection result.
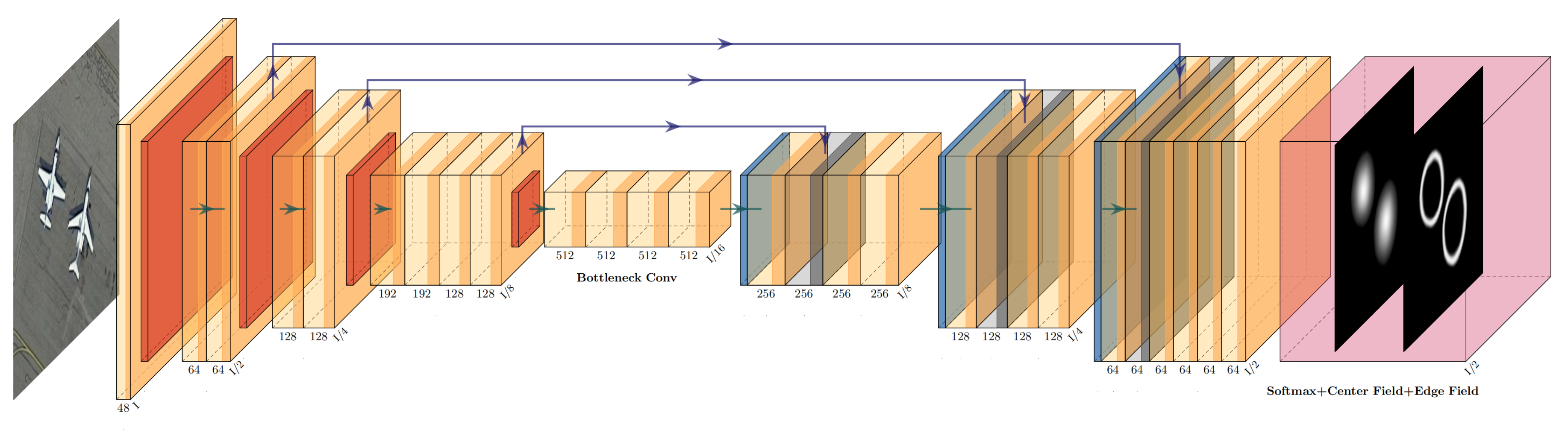
2. Ellipse Field Network
Figure 3 illustrates our network architecture. EFN is orthogonal to special network design and, so, any FCN backbone architecture can adapt to it. Here, we use U-net [
42] as an example. EFN takes images with proper resolution as input and processes them through several convolutional, max pool, and concatenate layers. Then, the output is branched into two sibling output layers: one is the object field, while the other is the edge field. Each output layer has several channels corresponding to the number of categories. After that, the ERF algorithm processes the output to obtain the center and edge points of each object and finally outputs an ellipse. As shown in Equation (
1), we use five parameters:
,
,
a,
b, and
to define an ellipse, where
are the co-ordinates of the center point of the ellipse,
are the semi-major axis and the semi-minor axis, respectively, and
is the angle of rotation. The function
describes the relationship between a point and an ellipse.
2.1. Center Field
The center field represents the distribution of intensity, which describes the distance between the pixels and center point of objects. According to Equation (
1), if a pixel is inside an object or on its edge,
. Based on this, we define
, the center field intensity of a pixel, in Equation (
2). In the equation,
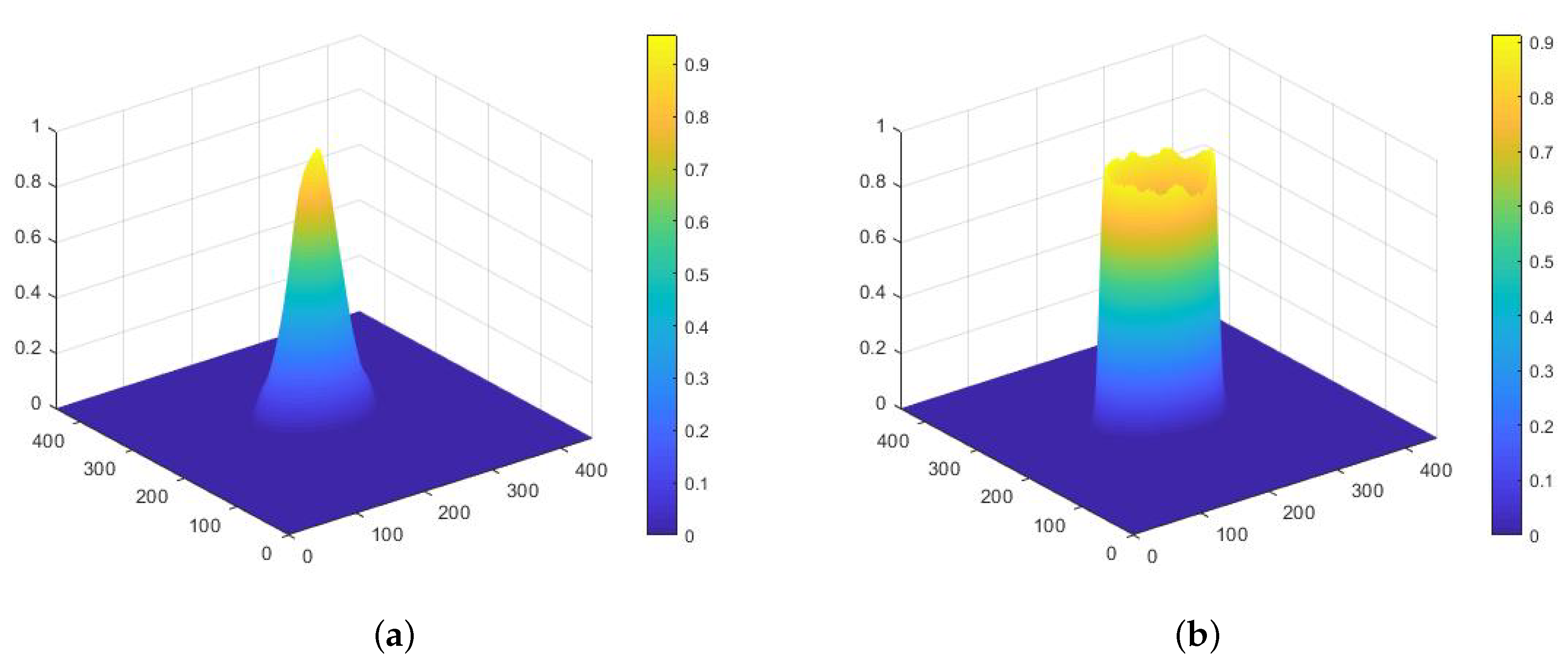
is a coefficient which we call the center field decay index (with default value of 2.5), which determines the decay rate. When objects are densely packed, some points may belong to more than one ellipse; in this case, we choose the ellipse which has minimum distance to the point. One pixel corresponds to one target, which solves the problem that semantic segmentation can not distinguish intra-class instances. The intensity decays from 1 at the center of an object to
at the edge, with a specific rate. In areas containing no objects, the intensity is 0.
Figure 4a shows an intensity distribution.
2.2. Edge Field
Similarly, the edge field represents the distribution of edge intensity, which describes the distance between pixels and the edges of objects. According to Equation (
1), the sufficient and necessary condition of a pixel being on an edge is
. Based on this, we define the center field intensity
of a pixel
in Equation (
3). Theoretically, the edge of an object is an elliptic boundary formed by a sequence of connected pixels. In other words, the edge is very slim, which makes it difficult to recognize. To reduce the impact of this, we define a parameter,
, called the edge width, in order to adjust the width of the edges. We set the default value as 0.1. Visualization of an edge field is shown in
Figure 4b.
2.3. Training Process
When calculating the loss function, the influence of targets with different sizes should be similar. As there are more pixels in a large object and less in a small one, the calculation of loss by pixel accumulation should give a higher weight to the small target. We obtain the area
of the rectangle to which the pixel belongs and, then, set the weight according to the reciprocal of the area size, as in Equation (
4), where
is a bias and the default setting is 0.1:
Finally, the output layer scans the whole output array to determine the distance between each pixel and each ellipse. Then, we obtain the loss, as given in Equation (
5), where
p represents the pixel of the images,
and
are the center intensity and edge intensity predicted by the network, respectively, and
and
are the respective ground truths. In this way, the impact of object size can be reduced, to some extent.
5. Conclusions
In this paper, we proposed a novel method for detecting objects in aerial images with oriented bounding boxes. Unlike typical region proposal and semantic segmentation methods, we introduced the field concept into our work, using a remoulded FCN network to calculate the center field and edge field. Then, we used the robust ellipse region fitting algorithm to precisely identify objects. This is a pixel-wise framework using patch-wise annotation, which dramatically reduces the difficulty of network training. Experiments on the DOTA and HRSC2016 data sets showed that EFN can outperform many prior methods, in terms of both speed and accuracy. In the DOTA test set, the mAP of our method reached 75.72; 2.66 higher than the second place. In the HRSC2016 test set, our method also achieved 86.6, the best mAP. Although our test on VOC2012 was not the best, it was only 0.7 less than the first place, verifying the generality of our techniques. Furthermore, we carried out an ablation study, discussed how different factors influence the performance of EFN, and found an appropriate way to train it. In the future, we intend to carry out more research on EFN and to continuously improve our method.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}