1. Introduction
Accurate building information extracted from earth observation (EO) data is essential for a wide range of urban applications, such as three-dimensional modeling, infrastructure planning, and urban expansion analysis. Since high-resolution imagery (HRI) became more accessible and affordable, extracting buildings from HRI has been of great interest. HRI provides valuable spectral, geometric, and texture information that are useful to distinguish buildings from non-building objects. However, building extraction from HRI is still challenging due to the large intra-class and low inter-class variation of building objects [
1], shadow effect, and relief displacement of high buildings [
2]. Airborne light detection and ranging (LiDAR) technology provides a promising alternative for extracting buildings. Compared with optical sensors, LiDAR measurements are not influenced by shadows, and offer height information of the land surface which can help to separate buildings from other manmade objects (e.g., roads and squares). Nevertheless, LiDAR-based building extraction methods are limited due to the lack of texture and boundary information [
3].
A lot of fusion techniques have been developed to integrate HRI and LiDAR data for building extraction and have been shown to perform better than using a single modality. In the early stage, the methods were relatively simple, in which elevation and intensity information derived from LiDAR data were stacked with HRI bands to obtain more informative images [
4,
5]. However, a simple concatenation of raw data may not be powerful enough to separate the classes of interest [
6]. Pixel-wise prediction requires more discriminative feature representation. To address this issue, a set of hand-crafted features (e.g., spectral, shape, height, and textural features) [
7,
8] were extracted and fed into the supervised classifier(s) using advanced machine learning algorithms (e.g., support vector machine, ensemble learning, or active and semi-supervised learning) [
9]. Although these feature-level fusion methods perform much better than using simply stacked raw data, they still have some limitations. Firstly, these methods require careful engineering and remarkable expert knowledge to design feature extractors, which are always goal-specific and not allowed to be directly applied from one specific task to another. Meanwhile, due to the heterogeneity gap existing in multimodal data, hand-crafted low-level or middle-level features derived from HRI and LiDAR data are usually in unequal subspaces, making vector representations associated with similar semantics completely different. A higher level of abstract features will be helpful to narrow the heterogeneity gap.
In recent years, deep learning (DL) has become the fastest-growing trend in big data analysis. DL models, especially the convolutional neural networks (CNNs), achieved significant improvement in RS image analysis tasks including scene classification [
10,
11,
12], land use and land cover (LULC) classification [
13,
14], and urban object extraction [
15,
16,
17]. The advantage of CNNs is that hierarchical deep features from a low-level to high-level can be automatically extracted via a common end-to-end learning process, instead of manually designing or handcrafting features [
18]. These high-level features can help to bridge the heterogeneity gap between different data modalities at the feature level. The fully convolutional network (FCN) [
19] has been shown to perform well on urban object extraction due to the ability of pixel-wise labeling [
1,
20,
21]. However, these advanced CNNs and FCNs are mostly restrained to three-channel RGB images, which cannot be directly adopted to multimodal RS data. It is necessary to build a comprehensive DL-based model to integrate HRI and LiDAR data for more accurate and robust building extraction.
Building a DL-based multimodal fusion network has two architectural design choices: “where” and “how” to fuse different modalities. Based on “where” to fuse different modalities, current fusion methods can be categorized into data-level, feature-level, and decision-level fusion. Data-level fusion methods combine data from each modality as a single input of the model. A common way of data-level fusion in a deep network is to concatenate different data sources into a single data cube to be processed [
1,
22]. Feature-level fusion methods integrate features obtained from each modality at the feature-learning stage: two networks are trained in parallel to learn features of different modalities, and their activations are then fused into one stream, e.g., by feature concatenation or element-wise summation [
23,
24,
25,
26,
27]. Decision-level fusion methods perform integrations of different outputs. In the case of classification, different models predict the classes, and their predictions are then fused, e.g., by averaging or majority-voting [
28,
29]. “How” to fuse different modalities refers to how to construct a fusion operation that can merge representations of different modalities, thereby forcing the network to learn a joint representation. Feature concatenation and element-wise summation are the most commonly used fusion operations.
Table 1 shows the architectures, advantages, and limitations of current DL-based fusion methods. Especially, there are several limitations that should be properly addressed. Firstly, these methods cannot fully leverage all kinds of useful features (e.g., individual modal and cross-modal), which may lead to insufficient feature learning and unsatisfied building extraction results. Individual modal features refer to the features derived from a single modality, and the cross-modal features are newly learned by fusing features from different modalities. Benefiting from the complementary information provided by all modalities, cross-modal features are considered to be more discriminative and representative than individual features. However, some useful individual modal information which is helpful for building extraction will be inevitably lost after the fusion operations. Therefore, a reliable and robust building extraction result requires sufficient learning and utilizing not only cross-modal features but also individual modal features. As a matter of fact, neither of the current fusion methods can sufficiently leverage the two types of features due to their architecture designs (cf.
Table 1). Secondly, the most commonly used fusion operations, feature concatenation and element-wise summation may yield fusion ambiguity in the scenarios of the feature redundancy and noises among different modalities. When only one modality carries discriminative information while the counterpart one provides only some useful or even misleading information, negative features will be inevitably introduced via simple feature concatenation or summation operation. For example, when distinguishing buildings from trees with similar height, the features derived from LiDAR data may carry misleading information. A simple concatenation or summation of the two modalities will inevitably introduce negative height information. In this case, the features of HRI should be highlighted and the features of LiDAR data should be suppressed. A selection module is required to adaptively highlight the discriminative features and suppress the irrelevant features for more effective multimodal fusion.
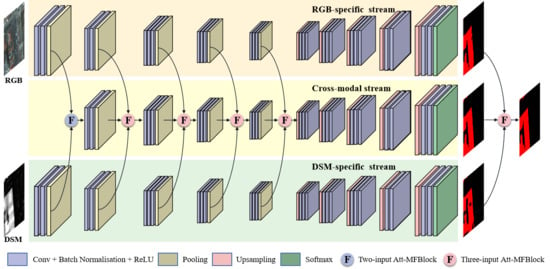
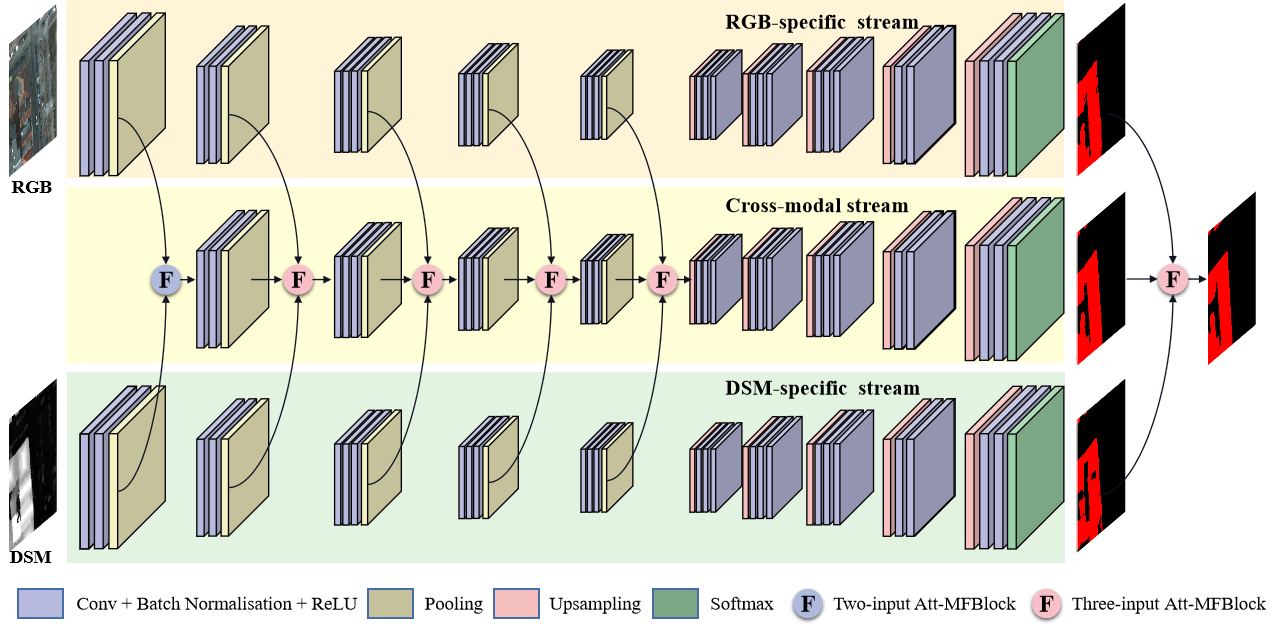
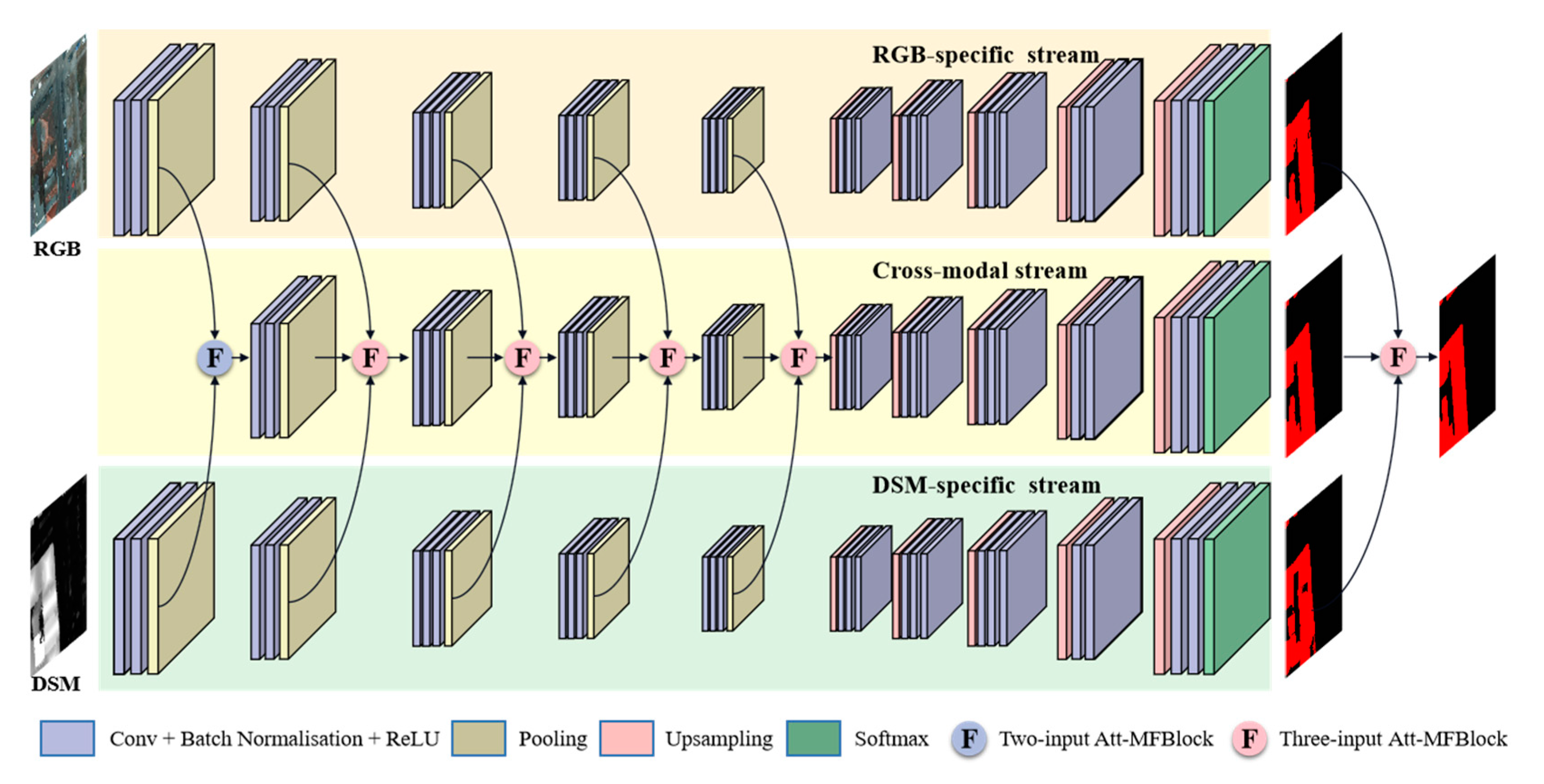
To fully leverage both individual modal and cross-modal features, a novel hybrid fusion architecture is proposed to make full use of cross-modal and individual modal features. In this hybrid fusion architecture, two streams are employed to learn individual features from HRI and LiDAR data, respectively. Another stream is specially designed to explore cross-modal complements by feature-level fusion of the other two streams. At the decision stage, the predictions from the three streams are also combined to produce a comprehensive building extraction result. Thus, cross-modal features can be sufficiently learned by the third stream and individual features are preserved and contribute to the final prediction of buildings. Compared with traditional fusion networks, the proposed hybrid network can fully leverage the benefits from both individual modal and cross-modal features, aiming to obtain more robust and reliable building extraction results.
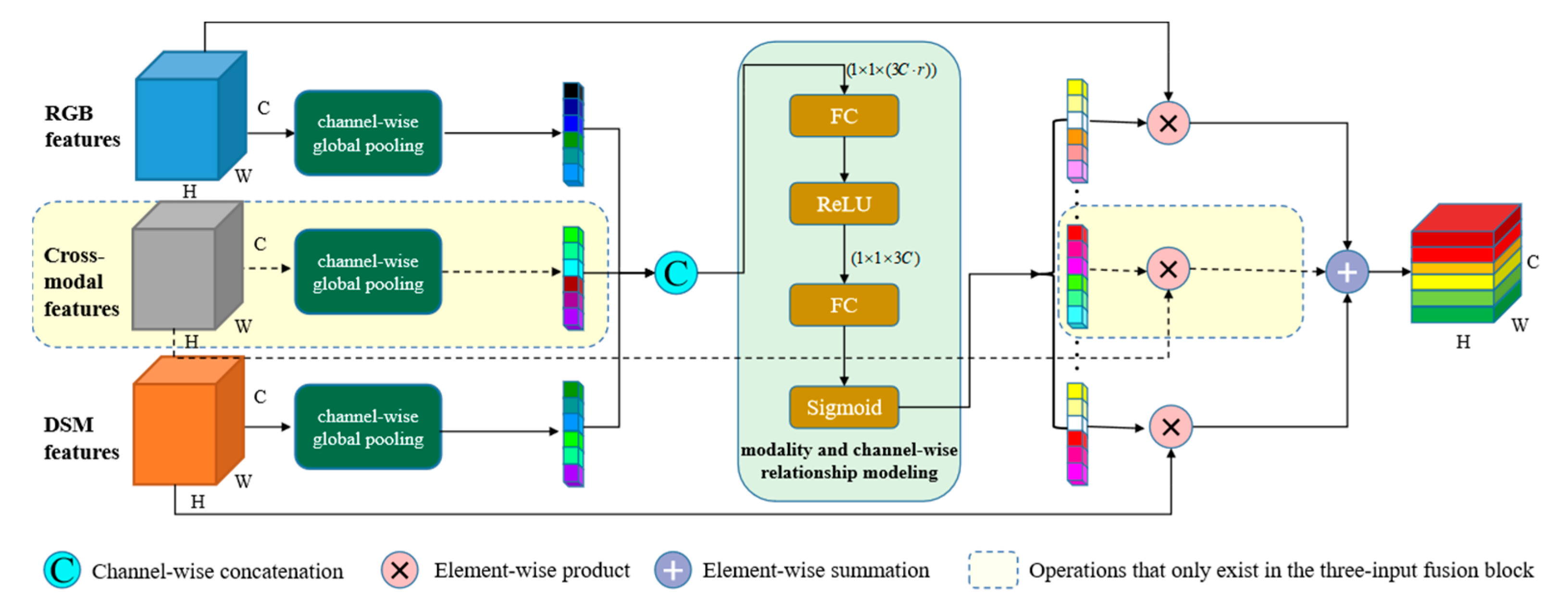
To overcome the cross-modal fusion ambiguity resulting from simple concatenation or summation, an attention-aware multimodal fusion block (Att-MFBlock) is introduced to adaptively highlight the discriminative features and suppress the irrelevant features. Attention mechanism refers to the strategy of highlighting the most pertinent piece of information instead of paying equal attention to all available information. Channel-wise attention [
30] was demonstrated to improve the representational power by explicitly modeling the interdependencies between the channels of its convolutional features. Recently some researchers [
31,
32] attempted to exploit the potential of channel-wise attention in combining multimodal features and demonstrate its ability to select complements from each modality. Motivated by these works, we proposed an attention-aware multimodal fusion block (Att-AFBlock) that extends the core idea of channel-wise attention to boost the fusion efficiency and sufficiency of HRI and LiDAR data.
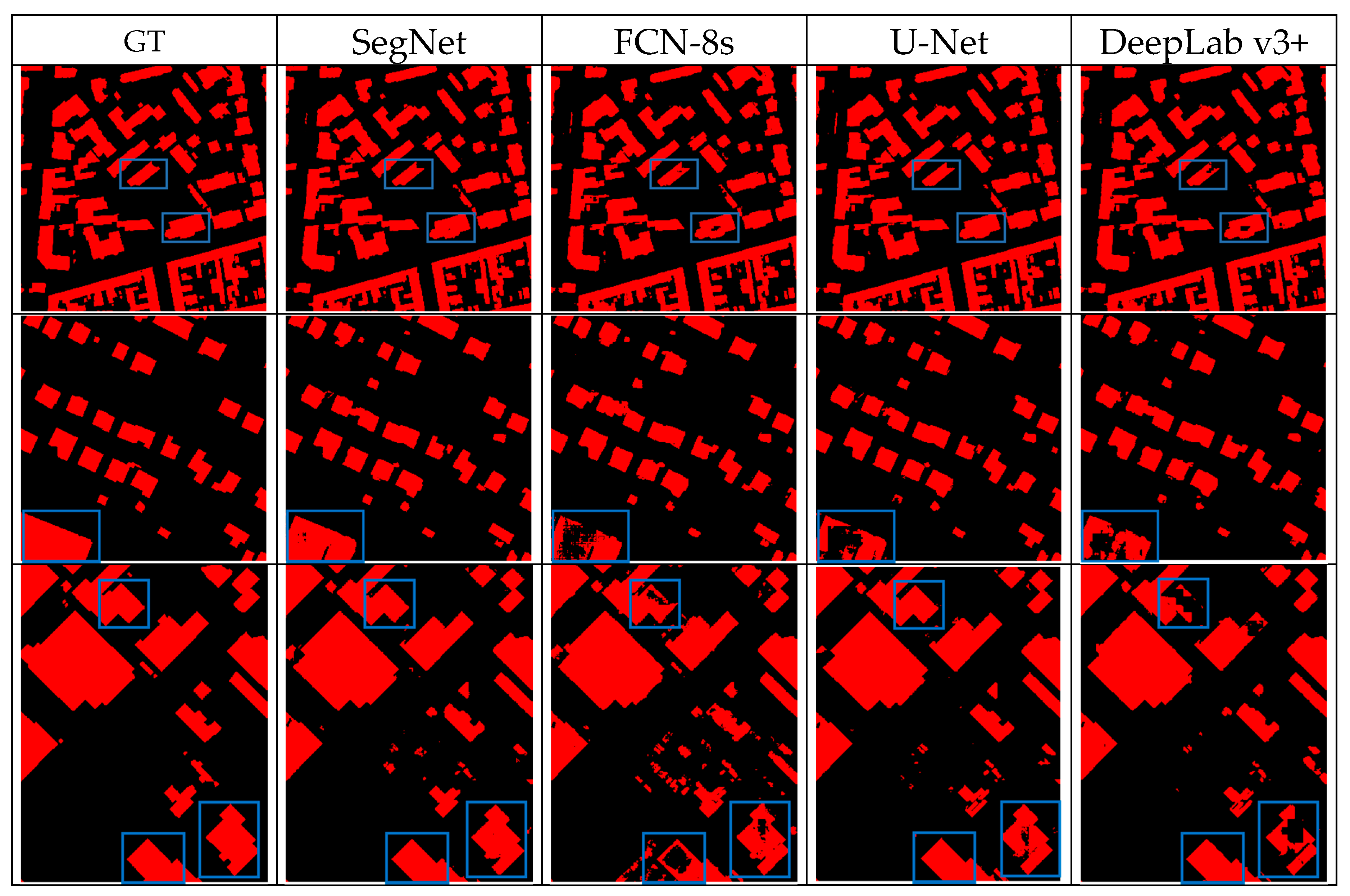
The main contributions of this study are: (1) proposing a novel hybrid attention-aware fusion network (HAFNet) that could be used to extract buildings from HRI and LiDAR data, (2) analyzing how the proposed hybrid fusion architecture and attention-aware multimodal fusion block (Att-AFBlock) affect multimodal data fusion and building extraction results, and (3) comparing the proposed HAFNet with other classical fusion models in two public urban datasets.
This paper is organized as follows.
Section 2 discusses related work.
Section 3 describes the details of the proposed HAFNet. Experiment design is presented in
Section 4. Results and discussions are presented in
Section 5. Finally, the main conclusions of the study are summarized in
Section 6.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


