1. Introduction
Asphalt is a dark brown to black, cement-like semisolid, solid, or viscous liquid produced by the non-destructive distillation of crude oil during petroleum refining [
1]. A flexible pavement profile commonly consists of five different layers, as shown in
Figure 1 [
2]. After setting the foundation with a subgrade layer, from bottom to top, the subbase layer is placed for foundational support through compacted aggregates, soils or chemical additions. Following that, a base layer is built, frequently above the subbase layer, for drainage purposes. As the top layers, flexible pavement systems have a binder layer—a mixture of aggregate and asphalt—and an asphalt surface layer—the top (crown) of the dense asphalt. This dense asphalt pavement should ideally be structurally resilient for distortion, and skid-resistant under traffic loadings, which is usually evaluated by the automated collection of roughness, rutting, and faulting data across the road networks [
2,
3].
Pavement management is defined as a set of tools that help decision makers identify optimal plans to provide, evaluate, and maintain pavements in a serviceable condition over a period [
4]. The systematic assessment through pavement management systems (PMS) not only enables the identification of current pavement preservation and rehabilitation needs, it also provides a historical angle for better judgments of the road network, especially to evaluate the long-term impacts of material changes, construction implementations or design procedures. In other words, pavement management systems offer help to allocate available resources most effectively by justifying the needs through regularly collected data and dynamic analysis, optimizing the budgetary limitations [
3,
4]. According to Torres-Machi [
5], USD 400 billion is invested each year globally in pavement construction and maintenance, emphasizing the technical, economic, and environmental aspects of the sustainable management of pavement [
4,
5].
Over time, all pavements’ quality degrades because of structural parameters, such as pavement material or soil characteristics, as well as environmental effects or traffic density [
3]. Several conceptual models reveal the same, yet not surprising, trend, which is that the older the pavement gets, the more expensive it is to fix. Based on current pavement conditions and the desired serviceability, several treatment options can be applied on the pavements, as follows [
3,
4]:
Figure 2 shows pavement performance change in relation to pavement age. In
Figure 2a, you can see the decline in quality within the lifetime of the pavement, associated with the required renovation costs per kilometer. As seen, a poor first strategy will cost about four to five times more in comparison to implementing rehabilitative actions at around the half-life time-point of paved roads [
6,
7].
Figure 2b illustrates the pavements’ proper treatment type across years, emphasizing that good and fair pavements will also continue to deteriorate unless preventive or rehabilitative actions are taken. To this end, determining and prioritizing the pavement conditions and taking necessary actions at the network level is profoundly significant in terms of economic, technical, and management aspects.
Solving challenging transportation management issues and forming road safety strategies in a timely and cost-efficient manner [
8] have specifically driven the focus on remote sensing applications [
9,
10,
11,
12,
13]. At this juncture, mapping asphalt road quality parameters presents itself as one of the more significant aspects of transportation management issues, which require regular supervision, and does so in a more practical and feasible manner. Pavement surfaces have particularly observable spectral features not only due to their physical–structural characteristics but also in relation to the asphalt layer’s chemical composition [
9,
10,
11,
12]. Combining the properties of digital cameras and spectroscopy devices, hyperspectral imaging sensors enable the collection of detailed spectral features of materials in narrow, contagious bands. The acquisition of such information allows identifying target materials in each image pixel through comparisons with existing spectral libraries or via classification algorithms. In this respect, understanding the spectral behavior of the road surfaces and generating accessible spectral libraries can help researchers to perceive road aging and trace deterioration levels in a fully automated manner, as required by authorities. Such a monitoring system would facilitate data collection and analysis, as opposed to the field-intensive demands of traditional systems, which are based on field observations. These field surveys usually require collection of geographical physical parameters of road surfaces (e.g., cracking, rutting and raveling), and analysis of aggregated measures, such as the pavement condition index (PCI) and structure index (SI) [
2,
14].
The main purpose of this paper is to evaluate the capacity of visible-near infrared (VNIR) hyperspectral image classification and spectral identification algorithms in determining pavement conditions. For this purpose, we propose an age-based classification as a proxy to identify and prioritize the roads that need maintenance in a controlled setting, where we have detailed ground truth information. Several conceptual models elaborate on the inevitable increase in the maintenance costs as the pavement gets older, which might quadruple if past the critical time after mid-age. Given performance change in relation to pavement age, we have acquired well-recorded information of the pavement surfaces in our campus area during our field campaign and determined our testing regions in this controlled setting. Three different predetermined categories, namely good (5-year), medium (10-year) and poor (25-year), are designated during the experimentations based on the ground truth information of the focused study area. Identifying and classifying these pavement categories will enable authorities to simply categorize the road networks via regularly collected and processed image sets, and provide better management of the pavements, as well as budgetary adjustments as to when and which maintenance actions are needed.
In the study, after a comprehensive literature survey on the hyperspectral detection and spectral characteristics of asphalt surfaces (
Section 2), a fast and novel methodology for mapping the condition of asphalt surfaces (i.e., good, medium, poor) is presented. For a fair comparison, benchmarking with support vector machine (SVM), artificial neural network (ANN), stacked autoencoder (SAE) classification algorithms are also performed. In
Section 3, the algorithms used in the study are detailed, followed by the methodology and data collection in
Section 4 and
Section 5, respectively. Experimental results are presented with the related performance metrics of the new methodology, along with their comparisons with the benchmarking algorithm outputs in
Section 6. General discussion of experiments is given in
Section 7 with the conclusions in
Section 8.
3. Algorithms
Artificial neural networks (ANNs) have been widely used to classify hyperspectral images [
22,
23,
24]. Plaza et al. [
25] use ANNs with small training sets to characterize mixed pixels in hyperspectral images. Similarly, Subramanian et al. [
26] implement neural networks with small training samples for classification by utilizing singular value decomposition (SVD) as a pre-processing tool to improve the computation time for the hyperspectral AVIRIS data. With their non-linear capabilities, ANN models do not make any assumptions about data distribution, increasing their classification power. Neurons function as partial simulators through inherent non-linear activation functions, arranged under each layer [
27,
28].
A simple artificial neuron is the smallest unit of the neural network, on which the weighted sum of its inputs is computed [
28]. To overcome the simple linear dependence of this weighted sum on its input features, this score is then passed through an activation function, σ. This non-linear sigma activation function enables the modeling of nontrivial–complex functions, eliminating the flat dependence between the inputs and output scores [
27,
28].
Figure 4 illustrates the general model used in the study, where
X is the input layer connected to
H, the hidden layer, and
O, the output layer, with weights
wij and
hij. In the classification experiments with neural networks, a network with one hidden layer is established. Backpropagation and gradient descent algorithms are used in the ANN experiments for convergence, where parameter
n is the number of bands (360),
k is the size of the hidden layer (64) and m is the class size (8).
Deep learning methods, widely used in the last decade, are shown to yield high accuracy when extensive learning data are used. To compare the proposed algorithm, we employ a stacked autoencoder (SAE) based classifier and multilayer feed-forward neural networks as deep learning algorithms [
29]. A stacked autoencoder is a special form of neural network, designed to learn by stacking additional unsupervised feature learning layers, and can be trained using greedy methods for each additional layer [
30]. It consists of multiple layers in which the outputs of each layer are wired to the inputs of the successive layer, and is used for learning unsupervised representations of data through each layer, which are fine-tuned using backpropagation. A deep representation of the input data is provided at the last layer’s output with more than one encoder layer. That is, a layer is trained with the parameters obtained after the training of the previous layer is over. A stacked automatic encoder is created by stacking these hidden input layers. There are different versions of stacked auto-encoder algorithms, such as stacked denoise auto-encoders [
31,
32] and stacked sparse encoders [
33,
34].
In our implementation, no dimensionality reduction is applied to high spectral resolution data prior to classification. The network model class outputs eight-element unit vectors, returning binary values to indicate whether that output neuron belongs to the given class. The input layer consists of as many nodes as the number of spectral bands, with three hidden layers fully connected to the output layer. The input is a vector of n × 1, n being the number of bands. A network similar to the one Chen et al. [
35] used is illustrated in
Figure 5, where
X is the input layer connected to
H, the hidden layers, and
O, the output softmax classifier, with weights
wij and
hij.. The system consists of a four-layer structure with three fully connected layers, and the output layer is a softmax classifier layer. In this figure,
n is the number of bands,
m is the class size, and
k and
j are the sizes of the hidden layers, which are selected as 128 and 16, respectively.
The spectral angle mapper (SAM) algorithm measures the angular similarity between two spectra by calculating the spectral angle between the target spectrum and image pixels [
36]. SAM is used for both classification and target detection purposes [
36,
37]. In the following expression, s = [s
1 s
2 …. s
n] is the spectral signature of the pixel and d = [d
1 d
2 …. d
n] is the target spectral signature utilized for calculating angular distance:
The support vector machine [
38] (SVM) is an effective method, which has been frequently implemented for hyperspectral data classification [
29,
31,
39,
40,
41]. The SVM training algorithm tries to determine the optimal decision boundary (hyperplane) separating the dataset. Keerthi and Lin [
42] studied the different kernel functions for SVM classifiers, such as linear, polynomial, radial basis function (RBF) and sigmoid. RBF kernel, which has been found to be more successful in hyperspectral classification, is selected in this study [
39,
41]. The equation of gaussian RBF is:
where γ is the kernel parameter [
40,
42].
4. Proposed Methodology Based on Neural Networks
The proposed methodology integrates the two main algorithms. Firstly, classification via ANN and SAM is performed separately. The acquired output scores of the two methods are integrated at the second step. After obtaining the outcome scores from a neural network for each class, a new score is calculated as the ratio of the NN prediction scores and the spectral angular distance of the pixels. A pseudo-code of the implemented methodology is presented in
Figure 6 and the algorithms are made available for convenience (
https://github.com/okanbilge/nnRoad). This combined use of ANN and SAM algorithms does not change the results for which ANN makes better decisions, but does direct the classifier output to the one SAM favors when ANN is uncertain. For example, in a two-class problem, the effect of the SAM score is virtually absent when the ANN score is close to one or zero, whereas it might be critical for a non-binary ANN score scenario.
To test the model robustness and observe the effect of training size on overall accuracy, four different experiments are conducted using different numbers of training pixels (5, 10, 20, and 50 pixels per class) on the captured images. The flowchart of the methodology is presented in
Figure 7.
The classification performance is calculated based on the prepared ground truth of the asphalt condition categories. The overall classification accuracy is the ratio of correctly classified data points to the total number of classified pixels, which is computed to assess the performance of the proposed algorithm as well as the benchmark methods.
5. Study Area and Data Collection
The study was conducted at the Middle East Technical University campus in Ankara, Turkey. Having a priori knowledge about the infrastructure in the campus region, in the data collection phase, different asphalt types, paving stones, asphalt paints, and soils were captured. In order to avoid complications due to inadequate sunlight, data collection was performed in a cloudless environment in the afternoon. Due to the need for ground truth data, data acquisition was performed in three different low-circulation roads for which the age information is known by the university authorities.
The data collection was performed with a custom-designed system, specifically optimized for proximal image acquisition with a Headwall A-series VNIR camera. The camera has 408 bands, collecting data in the range of 400 nm–1000 nm. It was mounted on an SUV car with a metal cage positioned about two meters in height, as shown in
Figure 8.
The size of the collected data in the study is 5000 × 1000 pixels along the track and cross track directions. The spatial resolution of this image is about 5 cm along the track and 1 cm along the cross track direction. The last 68 bands (900–1000 nm) are not used due to the low signal to noise ratio. In the field campaign, six different datasets captured from the designated roads have been utilized for analysis. The constructed spectral library has eight different classes comprising three different asphalt classes (good (5-year), medium (10-year), and poor (25-year)), white and yellow road paint, shadow, paving stone, and soil. The sample pictures from each class are shown in
Figure 9.
The experiments were performed to classify pavement classes (good, medium, and poor) with high accuracy, while separating the soil, paving stone, dye, and shadow classes in the acquired images. Four different experiments were conducted using different numbers of training pixels (5, 10, 20, and 50 pixels per class) on the captured images to assess the model’s performance and robustness. Training samples were randomly selected from the existing spectral library. The mean values of the spectral signatures for each class are given in
Figure 10a.
As seen in
Figure 10a, the three asphalt classes have similar spectral signatures; therefore, each algorithm’s sensitivity to capture the subtle differences will be a key factor in accuracy assessment. The spectral angle mapper algorithm enables us to fine-tune our predictions, with its sensitivity to the characteristic absorption features of spectral signatures that are not visible to the human eye due to scaling or inherent noise. For our asphalt classes, the angular difference ranges between 0.06 and 0.09 radians, pointing out spectral dissimilarities between them. To make it more visually recognizable, we demonstrate our asphalt class signatures in
Figure 10b with a closer look, using focused scaling after applying a smoothing filter to remove the noise component. After these operations, the absorption feature around 870 nm was more discernable for medium- and old-age asphalt classes. This absorption characteristic is associated with iron oxide minerals that are exposed within the pavement structure in the literature [
11,
14].
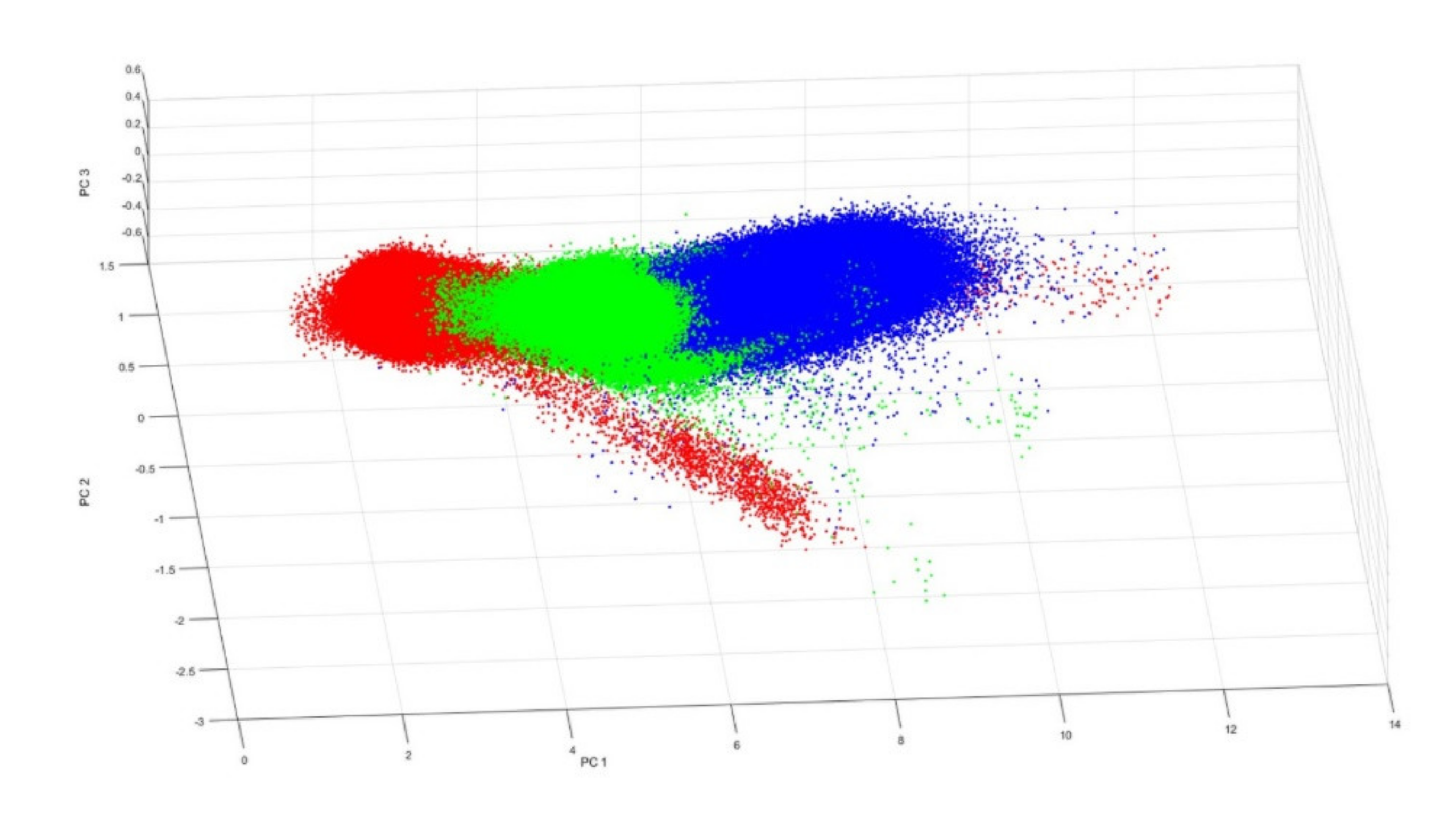
Furthermore, to explore the between-class variation of the present asphalt classes, we illustrate the class pixels by plotting them across the first three principal components in
Figure 11. This plot shows that the three asphalt classes are separated from each other in the 3D space of principal components, although the first visual implication is that they are similar to each other. Contrary to that, these classes are separated from each other in an n-D space provided by the hyperspectral imaging.
6. Experimental Results
In this section, firstly, benchmarking algorithm outputs are presented individually. We then compare them with the classification accuracies of the proposed methodology by also presenting the corresponding output images. To test the model robustness and the effect of training size on the test images, we present the results of four different experiments on each test image.
6.1. The Performance of the Benchmark Algorithms
ANN results in a significantly different classification performance depending on the seed point and the training data. This variation is much more evident, especially when a small set of training data is used. Knowing that the algorithm is sensitive to the size of the training data, several experiments have been carried out to reveal the effect on the collected images.
Among the four performed experiments on the first image set, the average classification accuracy values of the first experiment (5 training samples for each class) are 67.54%, 45.96%, and 49.60% for the ANN implementation. According to the obtained results, ANN can hardly separate different asphalt classes from each other, given the difficulty of distinguishing between shadow, soil, and paving stone classes.
In the fourth experiment (50 training samples per class), SVM results in 75.86%, 70.03%, and 59.76% classification accuracy, while SAM outputs 75.02%, 62.90%, and 57.70% classification performance. The main problem of SVM is the inadequate separation of different pavement classes, as in the case of ANN. At the same time, SAM is found to be more successful in separating asphalt classes to a better extent, which is, however, not sufficient. Unlike the general increase in accuracy rates with higher training samples in SVM, ANN, and SAE, the same tendency is not observed with SAM. The increase in the training data size significantly improves the SAE algorithm’s performance, among other things. In the first and last experiments, the SAE algorithm achieved performance rates of 11.52% and 58.58% for Image 1, 20.58% and 61.87% for Image 2, and 20.58% and 55.63% for Image 3, respectively. The mean performance values for each experiment and the performances of each individual algorithm are given in
Table 2.
Based on the training samples per class, a steady increase in accuracy is observed as the training samples increase, specifically with the feed-forward neural network and our proposed methodology. In order to observe the rate of change of performance in relation to the training sample size, the instances were increased to an adequate level, enabling us to observe the algorithm’s robustness and achieved performances for each method. For all of the implemented algorithms, the performance primarily depends on the discrimination of the three asphalt classes rather than the remaining yellow dye, white dye, soil, paving stone, and shadow categories. The white and yellow paint, shadow, soil, and paving stone classes are most effectively distinguished from each other with the SAM algorithm.
After observing the algorithm’s performance compared to the baseline methods for the first image set (Image 1–3), the proposed methodology was implemented on a second image set, including three more images for testing purposes (Image 4–6). The new experiments validate the previously observed incremental increase with the training data, with an accuracy improvement of 1–17% in comparison to ANN scores. For this image set, the spectral angle inclusion results in a slightly better class separation. The classification accuracies for the second set of images are given in
Table 3.
6.2. Experimental Results for the Proposed Methodology
The proposed methodology combines ANN and SAM scores for the improved differentiation of asphalt classes. In implementing this joint method, the prediction scores of ANN and the calculated angular values of SAM are stored together. For each class, a new estimation value is obtained by taking the ratio of the prediction values by ANN and SAM scores for each class separately. The outputs of the proposed methodology are shown in
Figure 12c, along with their corresponding RGB image and ground truths in
Figure 12a,b. The algorithm outputs for the first set of images are plotted together in
Figure 13, showing the improved performance of the joint methodology over individual benchmark methods.
For the first image set, the overall accuracy is improved from 75.69% to 94.32% for Image 1, from 67.78% to 85.93% for Image 2, and from 68.14% to 91.59% for Image 3, with the proposed method, with an improvement between 1 and 21% over the baseline ANN algorithm. The experiments show that the proposed method performs better for non-binary classification problems, with significant improvements over the baseline ANN method for images with three or more classes. The results also show that the separation between asphalt classes is better with the joint methodology, which indicates its potential for pavement condition assessment.
For the second set of images, which is shown in
Figure 14, the overall accuracy is improved from 72.32% to 92.33% for Image 4, from 55.66% to 75.90% for Image 5 and from 78.03% to 92.18% for Image 6 with the proposed method, with an improvement between 1 and 16% over the baseline ANN algorithm.
Figure 15 illustrates the change in performance across the experiments for the second data set. The experiments show that the proposed method provides significant improvements over the baseline ANN method for images with three or more classes.
7. Discussion
The experiments with benchmarking algorithms reveal a performance improvement between 1.2–21% across the acquired six images. We observe a gradual increase with SVM algorithm (35–68%), with comparatively higher rates as the training data increase in the first image set. SAM, on the other hand, results in similar scores (58–65%) with less sensitivity to the number of training data, while autoencoder persistently results in poor performance compared to these methods. Through the pixel-wise integration of spectral metrics on neural network prediction scores, proposed methodology outputs consistently higher accuracies to these benchmark methods along with the implemented neural network scores (70–90%).
In order to depict the performance gains through hyperspectral sensor, the algorithm is implemented with also three RGB bands as an input.
Table 4 demonstrates the scores acquired with RGB channels as an input with the proposed method. When the full spectrum is used as an input, the algorithm performances are 5–10% better depending on the training data across the six experiments. As far as the intensity is concerned, our approach outputs better scores when there are three or more classes in the image, as the effect of the SAM score is virtually absent when the ANN score is close to one or zero for a binary scenario. For instance, while the asphalt classes are separated successfully from the paving stone class with the hyperspectral image, it is mixed with the medium age asphalt class with RGB input, resulting in lower classification accuracies.
Across the six experiments, the increase in training samples reduces the dependence on arbitrary seed points. When only five training data for each class are employed, the performance of the algorithm changes in the range of 56–78%, whereas it varies between 76–95% for fifty training samples across the six experiments. With the proposed methodology, the observed variance across experiments is reduced significantly, while the average accuracy is increased consistently regardless of the number of training samples. This improvement is more profound where the training samples are low, revealing the proposed method’s potential.
Furthermore, in order to explore the effect of the presence of secondary classes in the experimental scenes (white dye, yellow dye, shadow, soil) on our overall classification accuracy, we calculate the percentages of these classes by the image size across each experiment. Our calculations reveal that these non-asphalt classes have 1.6 to 7.9% coverage across the captured images. In
Table 5, we provide a sample confusion matrix for one of our runs on Image 2, whereby we can investigate all asphalt classes along with all non-asphalt categories. This confusion matrix illustrates the numerical impact of these non-asphalt classes on our reported overall accuracies.
Our results show that the asphalt detection accuracy is, in fact, slightly better when we do not include the non-asphalt classes in our calculations. This is due to the small coverage of these categories across the scenes that could hardly affect the reported overall accuracies.
As a final step, we proceed to calculate the average and standard deviation of the accuracy for each experiment in order to evaluate the impact of the training data across the six experiments.
Figure 16 demonstrates the standard deviations and mean values of the classification accuracy for the proposed model and neural networks. The average classification accuracy is improved with the increased training data size, as expected, accompanied by the lower standard deviation of the classification accuracy, emphasizing the profound impact of the proposed methodology when the training sample size is small. The model’s efficiency is proven by the consistent improvement in average performance and the lower variances across experiments in comparison to the benchmarking methods.
8. Conclusions
Pavement sustainability and condition assessment have remained a long-lasting issue for the transportation management authorities [
2]. Assessments of road networks and introducing multi-year maintenance plans are essential organizational tasks in terms of strategic asset management by agencies and decision-makers. PMSs integrate technical, economic and environmental factors in these decisions for the sustainable operation of road network conditions. At this point, data collection stands as a crucial and challenging issue due its costly and labor-intensive nature, along with its direct relation to business decisions.
This study presents a new methodology for automated pavement condition assessment based on artificial neural networks and hyperspectral detection methods. To this end, a custom-designed vehicular system was built for data collection, and image acquisition was performed with a Headwall A-series VNIR camera. In the experiments, an age-based classification is implemented using six different images, including three different asphalt classes (good (5-year), medium (10-year) and poor (25-year)) along with the paving stone, white paint, yellow paint, soil and shadow classes, captured on the METU campus area. The spectral detectability of asphalt quality with VNIR brightness indexes has encouraged the research in this controlled setting, offering an alternative pavement management system to identify and prioritize the needed maintenance action. For classification purposes, the ANN, SVM, SAM and SAE algorithms, which are widely used in the literature, are implemented. To overcome the limitations of these widely used algorithms, a novel algorithm combining ANN and SAM scores is presented. The classification performances of individual ANN and SAM are significantly enhanced with their joint use, representing a 1 to 21% classification accuracy improvement across all experiments.
During the experiments, the need for more learning data came forward as a key driver to obtain better classification accuracy in the implemented methods. Especially in the case of the low number of training samples, the classification performance has been found to be low, as the algorithms could not differentiate between asphalt classes. This is because the captured images have different classes of pavement condition with similar spectral signatures. The proposed methodology overcomes this challenge with its combined approach of both neural networks and spectral angle proximity at the same time. Not only would the overall performance of this integrated methodology provide opportunities for identifying the worn pavement surface, but the system could also be useful for the regular monitoring of high-circulation roads. Despite the lack of structural deformities in the controlled test environment of campus roads, the results also suggest their detectability through the proposed methodology. Therefore, the study confirms the applicability of hyperspectral analyses to support strategic asset management and maintenance plans as a component of pavement management systems in agencies, enabling regular and cost-efficient data collection for sustainable pavement management. Future studies will be carried out to identify asphalt surface components using hyperspectral unmixing techniques to capture sub-pixel level information. In addition, new methods of accelerating algorithms will be implemented for the real-time monitoring of asphalt surfaces.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}