ℱ3-Net: Feature Fusion and Filtration Network for Object Detection in Optical Remote Sensing Images


Abstract
:
1. Introduction
- Small objects. Due to the long distance of imaging and low spatial resolutions of sensors, RS images often contain objects with small sizes, leading to limited information of object features.
- Appearance variance. Objects in the same class tend to appear in arbitrary orientations, varied sizes, and sometimes, extreme aspect ratios such as bridges and boats.
- Background complexity. Objects are often overwhelmed by cluttered background which potentially introduces more false positives and noise.
2. Related Works
2.1. Object Detection in Natural Images
2.2. Context Information in RS Object Detection
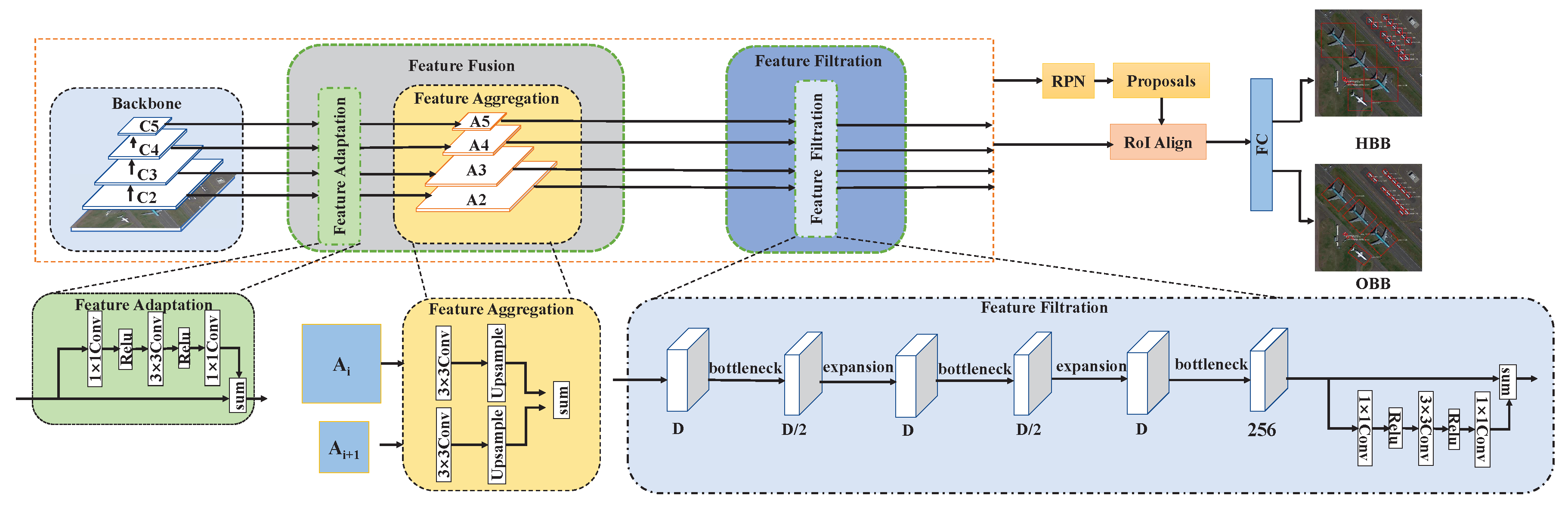
- First, our method adapts the feature extraction backbone trained on natural images to RS images before capturing the context information. As mentioned earlier, RS images are different from nature images in many aspects. Directly fusing the feature maps yielded by the backbone trained on natural images cannot effectively characterize RS images. In contrast, our network can better explore these characteristics thanks to the additional feature adaptation step.
- Second, the number of feature channels is hierarchically reduced in the process of feature fusion instead of directly mapping to a fixed value, i.e., the feature sizes are still different with varied resolutions after fusion. In this way, our method has stronger information retention capability, enabling the network to better distinguish the target from the background.
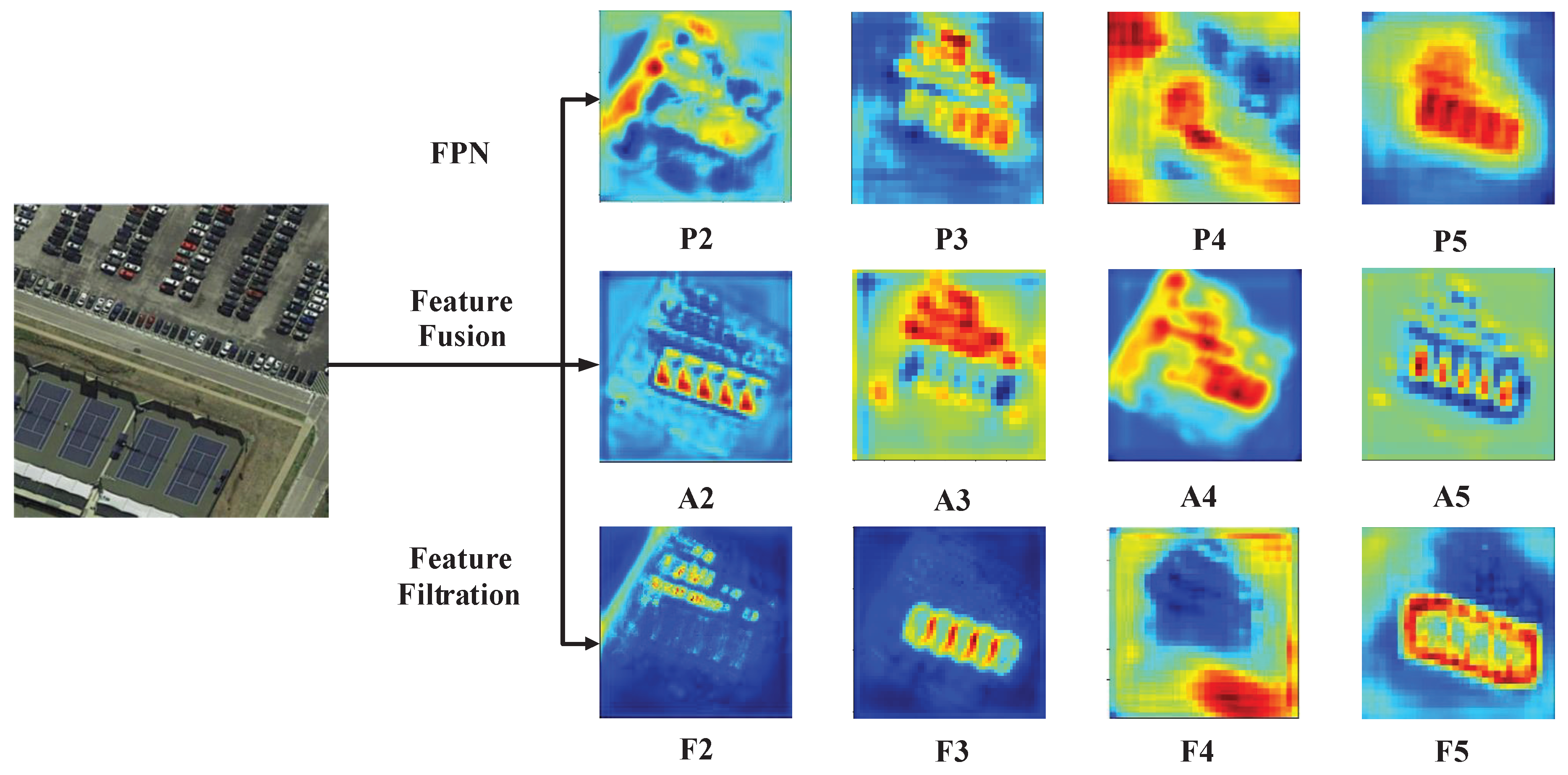
- Third, the fused feature map is refined by a feature filter module with bottleneck structure before subsequent detection and classification. The top-down structure in the feature fusion module, which starts from the uppermost layers to earlier layers, may also introduce undesirable noise [49,50] due to the limited context information in deeper layers. This introduced unrelated information is not conducive to object detection, especially for small objects with dense arrangement. The bottleneck structure helps to suppress the influence of irrelevant information, such as clutter background and noise, and make the network focus more on the foreground regions.
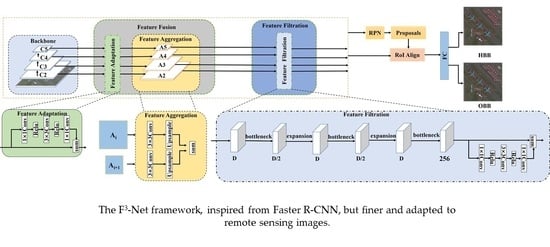
3. Proposed -Net Detector
3.1. Overall Architecture
3.2. Feature Fusion Module
3.3. Feature Filtration Module
3.4. Loss Function
4. Experiments
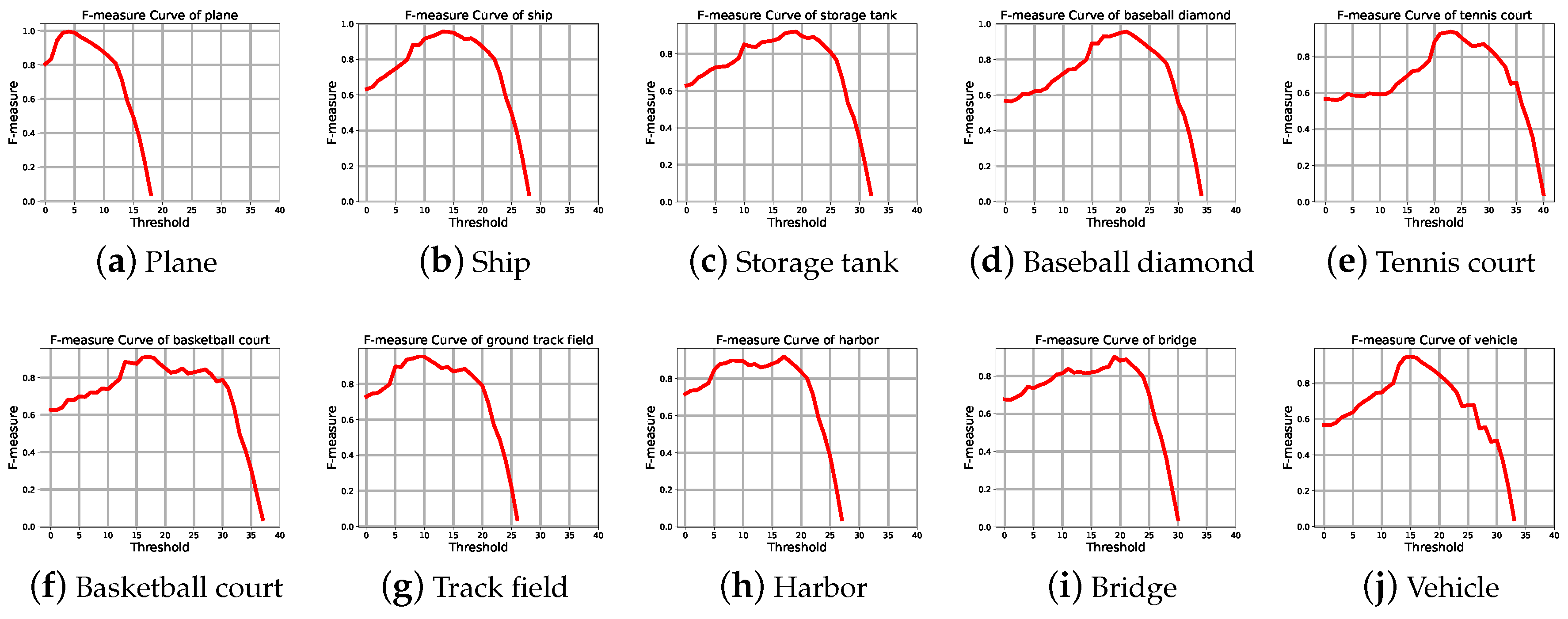
4.1. Datasets and Evaluation Metric
4.2. Implementation Details
4.2.1. Dataset Preprocessing
4.2.2. Network Setup
4.3. Experimental Results
4.3.1. DOTA Dataset
4.3.2. NWPU VHR-10 and UCAS AOD Datasets
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dong, Z.; Wang, M.; Wang, Y.; Zhu, Y.; Zhang, Z. Object Detection in High Resolution Remote Sensing Imagery Based on Convolutional Neural Networks With Suitable Object Scale Features. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2104–2114. [Google Scholar] [CrossRef]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Braga, A.M.; Marques, R.C.; Rodrigues, F.A.; Medeiros, F.N. A median regularized level set for hierarchical segmentation of SAR images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1171–1175. [Google Scholar] [CrossRef]
- Ciecholewski, M. River channel segmentation in polarimetric SAR images: Watershed transform combined with average contrast maximisation. Expert Syst. Appl. 2017, 82, 196–215. [Google Scholar] [CrossRef]
- Jin, R.; Yin, J.; Zhou, W.; Yang, J. Level set segmentation algorithm for high-resolution polarimetric SAR images based on a heterogeneous clutter model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4565–4579. [Google Scholar] [CrossRef]
- Lang, F.; Yang, J.; Yan, S.; Qin, F. Superpixel segmentation of polarimetric synthetic aperture radar (sar) images based on generalized mean shift. Remote Sens. 2018, 10, 1592. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Moustakidis, S.; Mallinis, G.; Koutsias, N.; Theocharis, J.B.; Petridis, V. SVM-Based Fuzzy Decision Trees for Classification of High Spatial Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 149–169. [Google Scholar] [CrossRef]
- Aytekin, O.; Zöngür, U.; Halici, U. Texture-Based Airport Runway Detection. IEEE Geosci. Remote Sens. Lett. 2013, 10, 471–475. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 4th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection. IEEE Trans. Image Process. 2019, 28, 265–278. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Zhang, J.; Liu, J.; Zhang, C.; Shi, G.; Hu, J. Bayesian Transfer Learning for Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 7705–7719. [Google Scholar] [CrossRef]
- Dong, R.; Xu, D.; Zhao, J.; Jiao, L.; An, J. Sig-NMS-Based Faster R-CNN Combining Transfer Learning for Small Target Detection in VHR Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8534–8545. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimedia 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Ding, P.; Zhang, Y.; Deng, W.J.; Jia, P.; Kuijper, A. A light and faster regional convolutional neural network for object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 141, 208–218. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Zhu, Y.; Du, J.; Wu, X. Adaptive Period Embedding for Representing Oriented Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7247–7257. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-Insensitive and Context-Augmented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2337–2348. [Google Scholar] [CrossRef]
- Xu, Z.; Xu, X.; Wang, L.; Yang, R.; Pu, F. Deformable convnet with aspect ratio constrained nms for object detection in remote sensing imagery. Remote Sens. 2017, 9, 1312. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Zhu, C.; Xiao, S. Deformable Faster R-CNN with aggregating multi-layer features for partially occluded object detection in optical remote sensing images. Remote Sens. 2018, 10, 1470. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Bai, X.; Wang, S.; Zhou, J.; Ren, P. Multiscale Visual Attention Networks for Object Detection in VHR Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 310–314. [Google Scholar] [CrossRef]
- Chen, J.; Wan, L.; Zhu, J.; Xu, G.; Deng, M. Multi-Scale Spatial and Channel-wise Attention for Improving Object Detection in Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2020, 17, 681–685. [Google Scholar] [CrossRef]
- Lu, X.; Zhang, Y.; Yuan, Y.; Feng, Y. Gated and Axis-Concentrated Localization Network for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 179–192. [Google Scholar] [CrossRef]
- Pang, J.; Li, C.; Shi, J.; Xu, Z.; Feng, H. R2 -CNN: Fast Tiny Object Detection in Large-Scale Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5512–5524. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tian, Z.; Wang, W.; Zhan, R.; He, Z.; Zhang, J.; Zhuang, Z. Cascaded Detection Framework Based on a Novel Backbone Network and Feature Fusion. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2019, 12, 3480–3491. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Liu, X.; Liang, D.; Yan, S.; Chen, D.; Qiao, Y.; Yan, J. FOTS: Fast Oriented Text Spotting With a Unified Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5676–5685. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 8232–8241. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the Computer Vision and Pattern Recognition. IEEE/CVF Conference 2018 (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Sun, P.; Chen, G.; Shang, Y. Adaptive Saliency Biased Loss for Object Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7154–7165. [Google Scholar] [CrossRef]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-Merged Single-Shot Detection for Multiscale Objects in Large-Scale Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3377–3390. [Google Scholar] [CrossRef]
- Gong, Y.; Xiao, Z.; Tan, X.; Sui, H.; Xu, C.; Duan, H.; Li, D. Context-Aware Convolutional Neural Network for Object Detection in VHR Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 34–44. [Google Scholar] [CrossRef]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Korner, M.; Reinartz, P. Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery. In Proceedings of the ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 4–6 December 2018; pp. 150–165. [Google Scholar]
- Guo, H.; Yang, X.; Wang, N.; Song, B.; Gao, X. A Rotational Libra R-CNN Method for Ship Detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5772–5781. [Google Scholar] [CrossRef]
- Liu, W.; Ma, L.; Wang, J.; Chen, H. Detection of Multiclass Objects in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 791–795. [Google Scholar] [CrossRef]
- Li, Z.; Tang, X.; Wu, X.; Liu, J.; He, R. Progressively Refined Face Detection Through Semantics-Enriched Representation Learning. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1394–1406. [Google Scholar] [CrossRef]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. PyramidBox: A Context-assisted Single Shot Face Detector. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 797–813. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 1–26 July 2017; pp. 1925–1934. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. arXiv 2019, arXiv:1908.05612. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Method | Region Proposal | Accuracy (%) | Highlights | |
|---|---|---|---|---|---|
| CV methods | two-stage | R-CNN | selective search | - | CNN+SVM |
| Fast R-CNN | selective search | - | RoI pooling layer | ||
| Faster R-CNN | RPN | 39.95 | Regional proposal network | ||
| R-FCN | RPN | 30.84 | Translation-invariant localization and classification | ||
| one-stage | YOLOv2 | No | 25.49 | The adoption of preset anchor boxes | |
| SSD | No | 17.84 | instead of region proposals | ||
| Retina-Net | No | 62.02 | Focal loss overcoming foreground-background imbalance | ||
| RS methods | one-stage | R3Det | No | 73.74 | Feature alignment for accurate localization |
| FMSSD | No | - | Atrous spatial feature pyramid | ||
| two-stage | Faster R-CNN-O | RPN | 54.13 | Fine-tuned with oriented bounding box | |
| ICN | RPN | 68.16 | Image cascade and FPN | ||
| RoI-Transformer | RPN | 69.56 | Rotated RoI learner for oriented objects | ||
| CAD-Net | RPN | 69.90 | Global and local contexts exploitation | ||
| SCR-Det | RPN | 75.35 | Sampling fusion network | ||
| APE | RPN | 75.75 | Representing oriented objects with periodic vectors |
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Two-stage methods | ||||||||||||||||
| FR-O [2] | 79.09 | 69.12 | 17.17 | 63.49 | 34.20 | 37.16 | 36.20 | 89.19 | 69.60 | 58.96 | 49.4 | 52.52 | 46.69 | 44.80 | 46.30 | 52.93 |
| ICN [46] | 81.36 | 74.30 | 47.70 | 70.32 | 64.89 | 67.82 | 69.98 | 90.76 | 79.06 | 78.20 | 53.64 | 62.90 | 67.02 | 64.17 | 50.23 | 68.16 |
| RoI-Transformer [20] | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| SCRDet [41] | 89.98 | 80.65 | 52.09 | 68.36 | 68.36 | 60.32 | 72.41 | 90.85 | 87.94 | 86.86 | 65.02 | 66.68 | 66.25 | 68.24 | 65.21 | 72.61 |
| APE [24] | 89.96 | 83.62 | 53.42 | 76.03 | 74.01 | 77.16 | 79.45 | 90.83 | 87.15 | 84.51 | 67.72 | 60.33 | 74.61 | 71.84 | 65.55 | 75.75 |
| One-stage methods | ||||||||||||||||
| SSD [13] | 39.83 | 9.09 | 0.64 | 13.18 | 0.26 | 0.39 | 1.11 | 16.24 | 27.57 | 9.23 | 27.16 | 9.09 | 3.03 | 1.05 | 1.01 | 10.59 |
| YOLOV2 [54] | 39.57 | 20.29 | 36.58 | 23.42 | 8.85 | 2.09 | 4.82 | 44.34 | 38.25 | 34.65 | 16.02 | 37.62 | 47.23 | 25.19 | 7.45 | 21.39 |
| R3Det [55] | 89.49 | 81.17 | 50.53 | 66.10 | 70.92 | 78.66 | 78.21 | 90.81 | 85.26 | 84.23 | 61.81 | 63.77 | 68.16 | 69.83 | 67.17 | 73.74 |
| -Net | 88.89 | 78.48 | 54.62 | 74.43 | 72.80 | 77.52 | 87.54 | 90.78 | 87.64 | 85.63 | 63.80 | 64.53 | 78.06 | 72.36 | 63.19 | 76.02 |
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Two-stage methods | ||||||||||||||||
| FR-H [2] | 80.32 | 77.55 | 32.86 | 68.13 | 53.66 | 52.49 | 50.04 | 90.41 | 75.05 | 59.59 | 57.00 | 49.81 | 61.69 | 56.46 | 41.85 | 60.46 |
| ICN [46] | 89.97 | 77.71 | 53.38 | 73.26 | 73.46 | 65.02 | 78.22 | 90.79 | 79.05 | 84.81 | 57.20 | 62.11 | 73.45 | 70.22 | 58.08 | 72.45 |
| SCRDet [41] | 90.18 | 81.88 | 55.30 | 73.29 | 72.09 | 77.65 | 78.06 | 90.91 | 82.44 | 86.39 | 64.53 | 63.45 | 75.77 | 78.21 | 60.11 | 75.35 |
| One-stage methods | ||||||||||||||||
| SSD [13] | 57.85 | 32.79 | 16.14 | 18.67 | 0.05 | 36.93 | 24.74 | 81.16 | 25.10 | 47.47 | 11.22 | 31.53 | 14.12 | 9.09 | 0.00 | 29.86 |
| YOLOV2 [54] | 76.90 | 33.87 | 22.73 | 34.88 | 38.73 | 32.02 | 52.37 | 61.65 | 48.54 | 33.91 | 29.27 | 36.83 | 36.44 | 38.26 | 11.61 | 39.20 |
| FMSSD [44] | 89.11 | 81.51 | 48.22 | 67.94 | 69.23 | 73.56 | 76.87 | 90.71 | 82.67 | 73.33 | 52.65 | 67.52 | 72.37 | 80.57 | 60.15 | 72.43 |
| -Net | 88.91 | 78.50 | 56.20 | 74.43 | 73.00 | 77.53 | 87.72 | 90.78 | 87.64 | 85.71 | 64.27 | 63.93 | 78.70 | 74.00 | 65.85 | 76.48 |
| Method | Plane | Ship | ST | BD | TC | BC | GTF | Harbor | Bridge | Vehicle | mAP (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RICNN [19] | 88.35 | 77.34 | 85.27 | 88.12 | 40.83 | 58.45 | 87.63 | 68.60 | 61.51 | 71.10 | 72.63 |
| Deformable R-FCN [26] | 87.30 | 81.40 | 63.60 | 90.40 | 81.60 | 74.10 | 90.30 | 75.30 | 71.40 | 75.50 | 79.10 |
| Deformable Faster R-CNN [27] | 90.70 | 87.10 | 70.50 | 89.50 | 89.30 | 87.30 | 97.20 | 73.50 | 69.90 | 88.80 | 84.40 |
| Li et al. [25] | 99.70 | 90.80 | 90.60 | 92.90 | 90.30 | 80.10 | 90.80 | 80.30 | 68.50 | 87.10 | 87.10 |
| FMSSD [44] | 99.70 | 89.90 | 90.30 | 98.20 | 86.00 | 96.08 | 99.60 | 75.60 | 80.10 | 88.20 | 90.40 |
| -Net | 99.31 | 92.62 | 92.89 | 97.14 | 91.38 | 86.16 | 98.00 | 90.30 | 82.18 | 88.90 | 91.89 |
| Task | Method | mAP (%) | Plane | Car |
|---|---|---|---|---|
| OBB | ICN [46] | 95.67 | - | - |
| Ours | 96.03 | 98.14 | 93.92 | |
| HBB | Xia et al. [2] | 89.41 | 90.66 | 88.17 |
| Ours | 96.90 | 98.12 | 95.68 |
| Faster RCNN | Backbone Network | FPN | Feature Fusion | Feature Filtration | Data Augmentation | Multi- Scale | mAP (%) @OBB | mAP (%) @HBB |
|---|---|---|---|---|---|---|---|---|
| 🗸 | ResNet-50 | 🗸 | - | - | - | - | 69.35 | 71.32 |
| 🗸 | ResNet-50 | - | 🗸 | - | - | - | 70.87 (↑1.52) | 72.03 (↑0.71) |
| 🗸 | ResNet-50 | - | - | 🗸 | - | - | 70.96 (↑1.61) | 72.19 (↑0.87) |
| 🗸 | ResNet-50 | - | 🗸 | 🗸 | - | - | 72.23 (↑2.88) | 73.02 (↑1.70) |
| 🗸 | ResNet-101 | - | 🗸 | 🗸 | 🗸 | - | 73.14 (↑3.79) | 74.62 (↑3.30) |
| 🗸 | ResNet-152v1d | - | 🗸 | 🗸 | 🗸 | - | 74.26 (↑4.91) | 75.03 (↑3.71) |
| 🗸 | ResNet-152v1d | - | 🗸 | 🗸 | 🗸 | 🗸 | 76.02 (↑6.67) | 76.48 (↑5.16) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, X.; Xiong, F.; Lu, J.; Zhou, J.; Qian, Y. ℱ3-Net: Feature Fusion and Filtration Network for Object Detection in Optical Remote Sensing Images. Remote Sens. 2020, 12, 4027. https://doi.org/10.3390/rs12244027
Ye X, Xiong F, Lu J, Zhou J, Qian Y. ℱ3-Net: Feature Fusion and Filtration Network for Object Detection in Optical Remote Sensing Images. Remote Sensing. 2020; 12(24):4027. https://doi.org/10.3390/rs12244027
Chicago/Turabian StyleYe, Xinhai, Fengchao Xiong, Jianfeng Lu, Jun Zhou, and Yuntao Qian. 2020. "ℱ3-Net: Feature Fusion and Filtration Network for Object Detection in Optical Remote Sensing Images" Remote Sensing 12, no. 24: 4027. https://doi.org/10.3390/rs12244027
APA StyleYe, X., Xiong, F., Lu, J., Zhou, J., & Qian, Y. (2020). ℱ3-Net: Feature Fusion and Filtration Network for Object Detection in Optical Remote Sensing Images. Remote Sensing, 12(24), 4027. https://doi.org/10.3390/rs12244027