1. Introduction
Polarimetric synthetic aperture radar (PolSAR) is a side-looking active imaging system and it has the advantages of working all day and night, working under all weather conditions, large scope, and certain penetration capacity. PolSAR has developed rapidly recent years, and it plays a significant role in Earth observation, such as land use planning, disaster prevention, environment monitoring, target detection, and so on [
1,
2,
3].
PolSAR image classification is one of the fundamental applications in PolSAR image interpretation. Supervised PolSAR image classification has achieved excellent performance. Many traditional statistical model-based methods and non-neural machine learning [
4] methods can achieve good results, such as the CoAS model [
5], random forest (RF) [
6], support vector machine (SVM) [
7], and XGBoost [
8]. In [
9], two mixture models were proposed for modeling heterogeneous regions in single-look and multi-look polarimetric SAR images, along with their corresponding maximum likelihood classifiers for land cover classification. Feng et al. [
10] proposed a classification scheme for forest growth stage types and other cover types while using a SVM that was based on the Polarimetric SAR Interferometric (PolInSAR) data. The interferometric polarimetric SAR multi-chromatic analysis (MCA-PolInSAR) signal processing method that was proposed in [
11] can confirm the feasibility to resolve the volume-oriented indetermination problem. Deep learning is a branch of machine learning and it provides the state-of-the-art solutions to many problems in natural image processing field [
12,
13]. It also shows excellent performance in supervised PolSAR image classification [
14,
15,
16]. Chen et al. [
17] used the roll-invariant polarimetric features and hidden polarimetric features in the rotation domain in order to drive deep convolutional neural network and improved the classification performance. Liu et al. [
18] proposed a polarimetric convolutional neural network that was based on a new polarimetric scattering coding method to classify PolSAR images by making full use of polarimetric information. Deep learning can automatically learn the discriminative feature representation of input data. With sufficient labeled training samples, the performance of deep learning based PolSAR image classification methods far surpass traditional machine learning methods [
17,
19].
Labeled PolSAR data are often insufficient and labeling PolSAR data accurately is expensive and time consuming [
20]. Unsupervised image classification is one of the fundamental problems in information processing and it does not need labeled data. Central grouping approaches, such as k-means, were popular in early computer versions, since they could be computed efficiently. Lee et al. [
21] proposed the iterative Wishart classifier, which is the most widely used classifier for PolSAR covariance matrix data. Spectral clustering, which is based on eigendecomposition of matrices, has good performance on arbitrary shape cluster and it is also often used for unsupervised SAR image classification [
22,
23]. Song et al. [
24] designed a computationally tractable and memory-saving affinity matrix for spectral clustering and could be used for large size PolSAR image clustering. With the development of machine learning, increasing methods have been proposed based on machine learning for unsupervised PolSAR image classification. Hua et al. [
25] presented an unsupervised classification algorithm with an adaptive number of classes for PolSAR data, which is capable of automatically estimating the class numbers. Zou et al. [
26] proposed an unsupervised classification framework for PolSAR images by combining the superpixel segmentation, Gaussian kernels, consensus similarity network fusion, spectral clustering, and a new post-processing procedure. The non-neural machine learning based methods have achieved promising results for unsupervised PolSAR image classification [
27,
28], but the current methods still suffer some problems. First, some methods have cumbersome pipelines, such as pre-processing, feature extraction, clustering, post processing, and so on. For example, superpixel segmentation is usually used to take advantage of the spatial information of pixels [
24,
26,
28,
29]. Some methods over-cluster PolSAR images and manually merge the similar classes to improve the performance [
24]. Second, the separation of feature extraction and clustering will make the solution sub-optimal [
30]. Third, some methods require huge computing resources and they cannot classify large size PolSAR images [
31].
Image clustering methods that are based on deep learning develop rapidly in natural image processing and they can be coarsely divided to three categories: (1) the combination of traditional clustering algorithms and deep learning. Deep Subspace Clustering (DSC) [
32] introduced a novel self-expressive layer between the encoder and decoder of a deep auto-encoder to mimic the “self-expressiveness” property. Subsequently, from the parameters of the self-expressive layer, an affinity matrix was constructed in order to perform spectral clustering to obtain the final clusters. Zhou et al. [
33] combined DSC with Generative Adversarial Networks (GAN) to faithfully evaluate the clustering quality. However, these methods often lead to degenerate solutions and they have cumbersome pipelines, such as pre-training, feature post-processing, and clustering mechanisms external to the network [
34]. (2) Deep discriminative feature representation learning methods. Donahue et al. [
35] added an encoder to GANs for better visual feature extraction. Hjelm et al. [
36] performed unsupervised learning of representations by maximizing mutual information between an input and the output of a deep neural network encode. DeepCluster [
37] used the pseudo-label that was computed by k-means as supervision to train the deep neural networks. These methods still require extra classifiers or clustering algorithms to output classification results. (3) Deep mutual information based methods. Invariant Information Clustering (IIC) [
34] involved a simple mutual information objective function for paired data in a neural network, which was end-to-end and without any labels. An end-to-end classification method in deep learning can classify images by a single neural network model. The input of the model is the image or low level feature and the output is the classification result. For exploring and taking full advantage of various kinds of correlations behind the unlabeled data, Deep Comprehensive Correlation Mining (DCCM) [
30] combined the Deep Adaptive Clustering (DAC) [
38] architecture with pseudo-graph supervision, pseudo-label supervision, and triplet mutual information for unsupervised image clustering. Deep learning provides a new way for unsupervised PolSAR image classification. Bi et al. [
39] proposed an unsupervised PolSAR image classification method that incorporated polarimetric image factorization and deep convolutional networks into a principled framework. At present, deep learning has great potential to further improve the performance of unsupervised PolSAR image classification. Deep learning based unsupervised PolSAR image classification methods are worthy of further investigation. Some methods [
25,
40] can obtain the optimal number of clusters in the cluster algorithms. Most unsupervised classification methods use a predefined number of classes in both natural image processing and remote sensing image interpretation fields [
24,
26,
30,
34,
41]. In this paper, we also focus on the unsupervised PolSAR image classification method with a predefined number of classes.
The mutual information based methods IIC and DCCM are end-to-end deep clustering frameworks, which could be used for unsupervised PolSAR image classification. Different methods use different deep features in order to compute mutual information. IIC used the deep prediction features—the output feature of the softmax layer for classification task—of sample and its randomly geometry transformed version in order to compute mutual information. DCCM constructed the positive pairs and negative pairs based on the pseudo-graph and extracted the shallow layer and deep layer features to compute the triplet mutual information. The geometry transformations, which are suitable for natural image processing, are used in both DCCM and IIC. However, because of the image mechanism of SAR, it is hard to learn the deep mutual information representation of PolSAR data only via geometry transformations. For unsupervised PolSAR image classification, IIC is hard to converge with the use of mutual information alone. DCCM also cannot learn discriminative feature representation of PolSAR images and the performance is unsatisfactory.
This paper aims to propose an end-to-end unsupervised PolSAR image classification method, which does not have cumbersome pipelines and it is simple to apply to practical applications. In order to further improve the unsupervised classification performance, the state-of-the-art unsupervised deep learning algorithms are adopted to unsupervised PolSAR image classification. Therefore, an unsupervised PolSAR image classification method that is based on Convolution Long Short Term Memory (ConvLSTM) [
42] network while using Rotation Domain Deep Mutual Information(RDDMI) of polarimetric coherent matrix is proposed in this paper. Two improvements are introduced in proposed method in order to better learn the deep mutual information of PolSAR data. First, the mutual information algorithms of IIC and DCCM are combined to better learn the PolSAR image feature representation and improve the unsupervised PolSAR image classification performance. Second, as a unique data transformation algorithm in PolSAR data interpretation field, the polarimetric matrix rotation is used in order to improve the deep mutual information learning. The polarimetric response of a target is related to the orientation of the target. The hide features in rotation domain can provide useful polarimetric information and be used to improve the classification performance [
43,
44,
45]. Different Polarimetric Orientation Angles (POAs) are used in order to generate a sequence of polarimetric coherent matrices and then the ConvLSTM is used to learn the rotation domain features of the sequence. ConvLSTM can process long-term dependent sequential data with spatial-temporal information and it has been applied to remote sensing image interpretation [
46,
47,
48]. The advantages of proposed method are summarized, as follows: (1) the deep mutual information in rotation domain is introduced for unsupervised PolSAR image classification. (2) Proposed method is an end-to-end model and do not have cumbersome pipelines. The input is the low level polarimetric features and the output is the class label of a pixel in a PolSAR image. Extra preprocessing or post-processing is not required. By introducing the mutual information algorithms of IIC and DCCM and the unique polarimetric matrix rotation, the proposed method can extract more discriminative feature representation and the performance of unsupervised PolSAR image classification is improved.
2. Methods
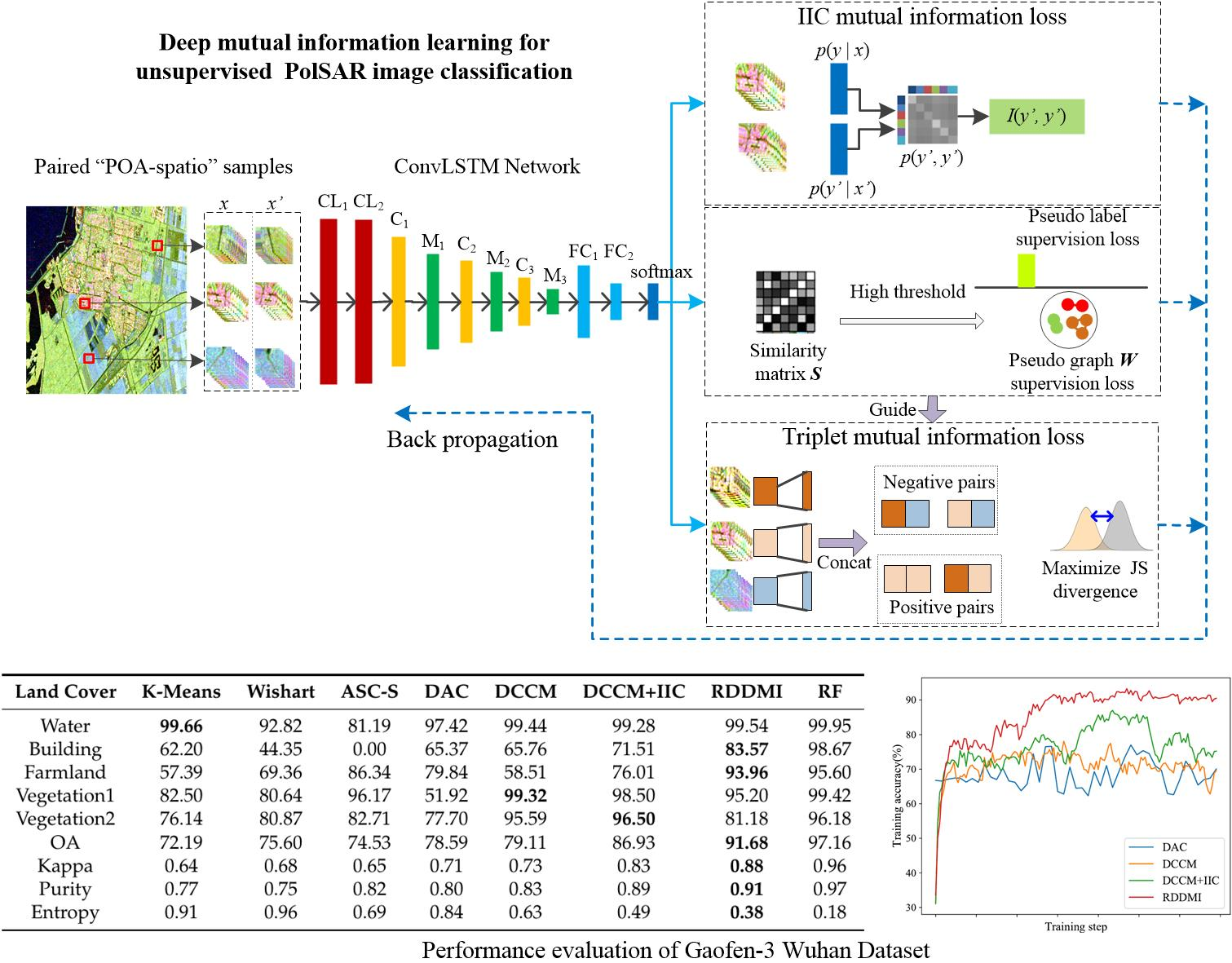
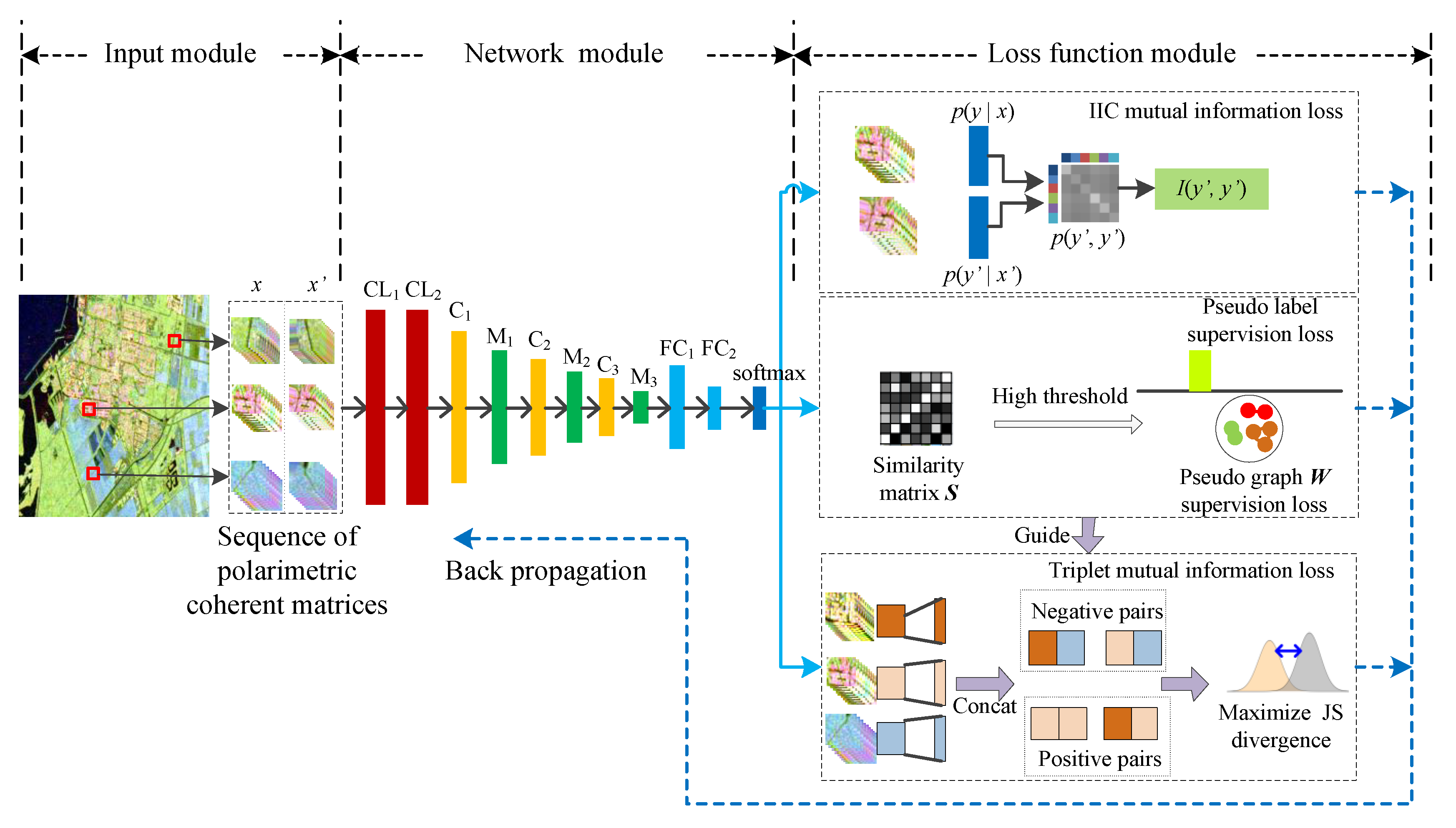
Figure 1 shows the proposed architecture and it consists of three modules: the first one is the input module, the second one is the network module, and the latter one is the loss function module.
The input data are the sequence of polarimetric coherent matrices in rotation domain, which is one of the most common used low level features for PolSAR image classification. For each pixel in a PolSAR image, the polarimetric matrix rotation along with geometry transformations is used in order to generate paired sequences of polarimetric coherent matrices, and , as the inputs of deep neural network.
The network used in proposed method is a convolutional LSTM network. It mainly contains two ConvLSTM layers (CL
and CL
), three convolutional layers (C
, C
, and C
), three max-pooling layers (M
, M
and M
), two fully connected layers (FC
and FC
), a softmax layer, and other auxiliary layers, such as ReLU and batch normalization [
49].
The loss functions are pseudo-label loss, pseudo-graph loss, and two mutual information losses, which are used to guide the network training. The computation of the IIC mutual information is based on the prediction features of and . The pseudo-label supervision loss, pseudo-graph supervision loss, and triplet mutual information loss were first introduced in DCCM for image clustering. The prediction features of the network are used in order to compute the similarity matrix among samples. Subsequently, the similarity matrix is used to construct pseudo-graph and pseudo-label to guide the network training. Based on the pseudo-graph, the positive pairs and negative pairs are selected to construct triplet correlations. Finally, the shallow layer and deep layer features of samples, which have triplet correlations, are used in order to compute the triplet mutual information loss. The following sections introduce the detailed information.
2.1. Input Polarimetric Features
The deep mutual information learning of each pixel in a PolSAR image requires paired data and , which are both the low level features of the pixel. A simple way to generate paired features for a pixel is to transform the low level feature to by two transformation algorithms. One is the random geometry transformation algorithm, which is used in IIC and DCCM. The other one is the unique polarimetric matrix rotation algorithm of PolSAR data. It can further improve the deep mutual learning and improve the performance of unsupervised PolSAR image classification. In this paper, and are two sequences of polarimetric coherent matrices in rotation domain with different POAs.
Polarimetric information of PolSAR data can be expressed by polarimetric coherent matrix
. The polarimetric matrix rotation on
is defined, as follows [
43]:
where
denotes POA and rotation matrix
=
.
According to Equation (
1), the elements
in
are
where
and
denote the real part and imaginary part of a complex
, respectively. We change the POA from 0 to
with step
and obtain nine POAs
. Subsequently,
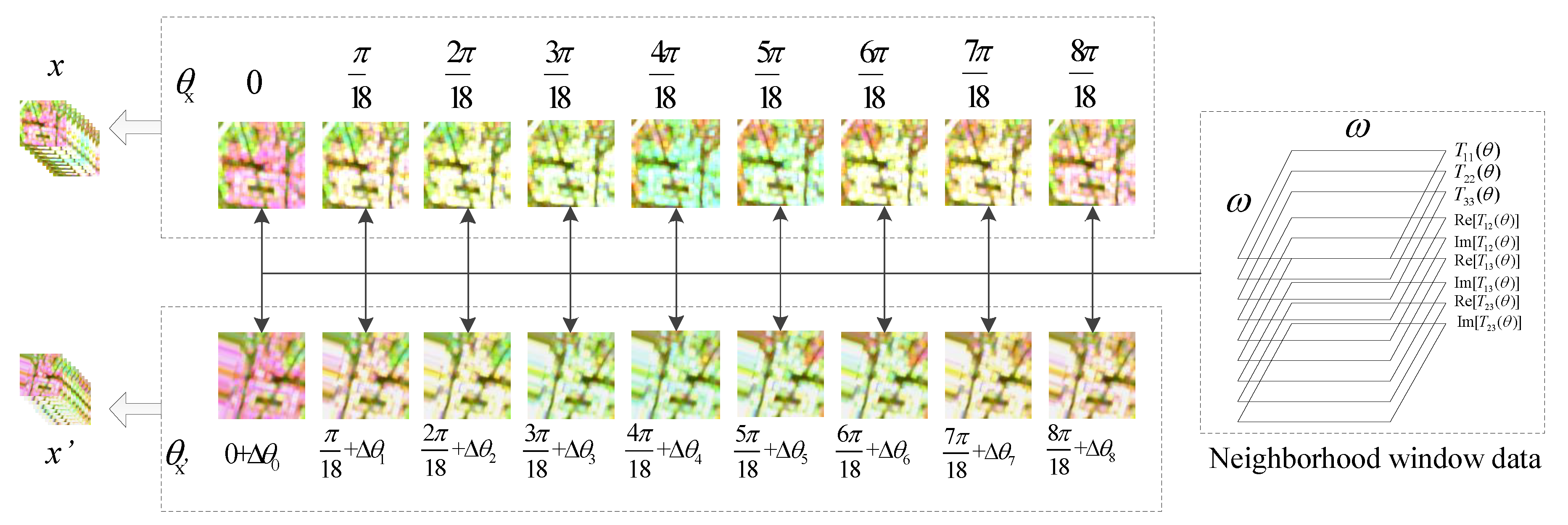
are used to generate nine polarimetric coherent matrices. The polarimetric coherent matrices have different POAs and contain spatial information, so it is named “POA-spatio” sequences. For example,
Figure 2 shows the Pauli pseudo-color images of the polarimetric coherent matrices of RADARSAT-2 Flevoland dataset. The polarimetric coherent matrices in the rotation domain have different polarimetric properties, which can be used to improve the PolSAR image classification performance.
The rotation domain polarimetric data of each pixel can be defined as a vector
,
For each pixel, the neighborhood window data are used to better reserve the spatial information. The vectors of all pixels in a neighborhood window are used in order to generate the sample
from the nine polarimetric coherent matrices. The size of each sample
is
, where
w denotes the window size, the first nine is the number of POAs, and the second nine is number of channels, as shown in
Figure 3. Each pseudo-color image patch presented in
Figure 3 is generated from
, and it denotes the neighborhood window data of a pixel. The deep mutual information learning requires paired data, so the other sample
is also shown in
Figure 3. There are two steps to generate sample
. First, sample
is also generated from polarimetric coherent matrices with nine POAs
, which are different from
. Sample
should be similar to
, so the nine POAs
of
are close to
. We make small changes to
, and then the POAs
, where
. For each training epoch, the value of
is randomly selected in the range
. Second, the random geometry transformations are applied to
. The geometry transformations include rotation, skewing, scaling, flipping, channel shifting, and so on.
In other words, for each pixel, sample is generated from the rotation domain polarimetric coherent matrices, and then is converted to by two procedures, which are the polarimetric matrix rotation and random geometry transformations. The network can better learn the deep mutual information of PolSAR data by introducing the unique polarimetric matrix rotation.
2.2. Network Architecture
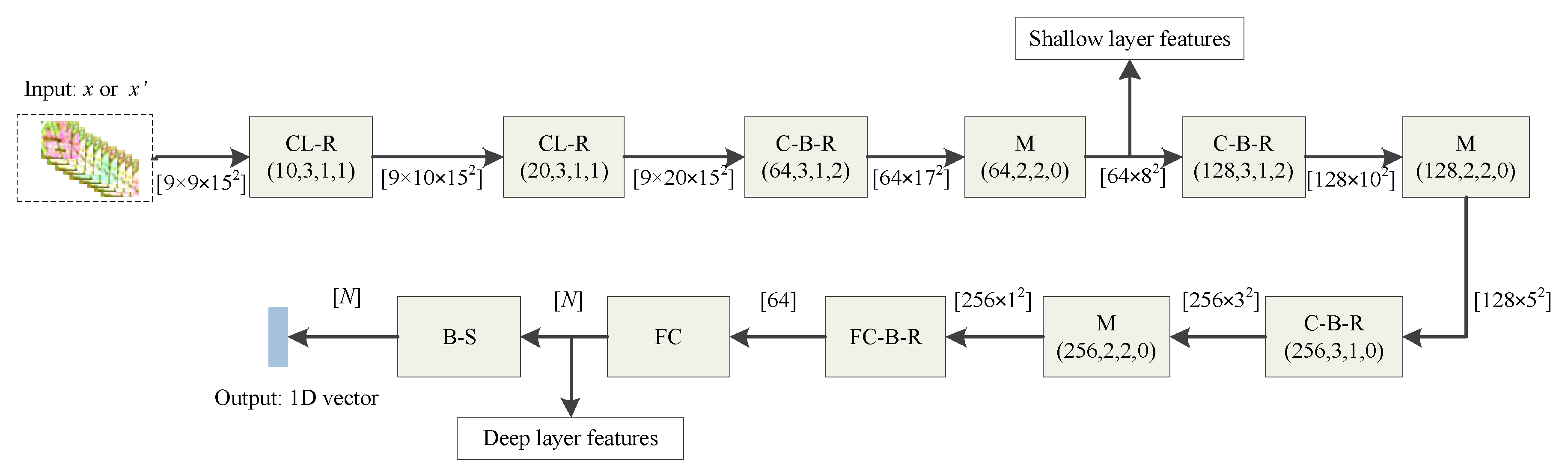
Figure 4 shows the network used in our method, where
N denotes the number of classes. The input sample
or
is sequence data and it has spatial information, so the first two ConvLSTM layers are used in order to capture the rotation domain features from the sequence of polarimetric coherent matrices. Subsequently, some convolution layers, as well as fully connected layers, are used in order to further learn deep features of the input sample. Finally, the softmax layer outputs a one-hot vector and the argmax function is used in order to compute the class of the sample. The shallow and deep layer features, which are used to compute the triplet mutual formation loss, are the outputs of the first max-pooling layer and second fully-connected layer, respectively.
LSTM can model long-range dependencies, but it contains too much redundancy for spatial data [
42]. ConvLSTM is proposed in order to solve this problem. ConvLSTM replaces the fully connected gate layers of the LSTM with convolutional layers, so it is capable of encoding sequence data that have spatial information [
47]. The main equations of ConvLSTM are shown below:
where * denotes the convolution operation, ∘ denotes the Hadamard product,
W denotes learnable weights,
b denotes the bias,
denotes the input of time
t,
and
denote the hidden state,
denotes the output gate, and
denotes the final output state of time
t.
and tanh are the activation functions.
The “POA-spatio” polarimetric coherent matrices can be regarded as the time steps of ConvLSTM, and sample or is “POA-spatio” sequence data. Therefore, ConvLSTM fits well with the deep feature representation learning of the PolSAR “POA-spatio” sequence data.
2.3. Loss Functions
2.3.1. IIC Mutual Information
Let
and
be paired samples in a PolSAR image, where
or
is the
i-th sample and
K is the number of total sample pairs. IIC aims to learn a representation
that preserves what is in common between paired data
and
, while discarding instance-specific details [
34], which can be achieved by maximizing the mutual information (MI):
where
is a neural network. The output of the softmax layer
, which is the prediction feature of sample
, can be interpreted as the distribution of a discrete random variable
y over
N classes, formally given by
[
34]. Let
y and
be the cluster assignment variables of
and
, respectively. Because
y and
are not independent after marginalization over the dataset [
34], the joint probability distribution of
y and
is given by a
matrix
. Each element at row
n and column
of the matrix
is
. Subsequently,
has the following form:
The marginals
and
can be computed by summing the elements of the rows and columns of the matrix
[
34]. Plugging the matrix
into the mutual information expression [
50] and Equation (
5) can be computed equivalently:
Subsequently, the IIC mutual information loss can be formulated as:
2.3.2. Pseudo Graph and Pseudo Label Supervision Loss
The pseudo graph and pseudo label are used in order to guide the network training and the computation of triplet mutual information. The pseudo-graph is used to explore the binary correlation between samples and the pseudo-label loss is used to make full use of category information behind the data [
30].
The neural network
can output the prediction feature of the input data
. Based on the prediction feature vector
of the softmax layer, the cosine similarity of two samples can be calculated by the following equation:
In [
30], a large
is set to the similarity matrix
in order to construct pseudo-graph
:
If the cosine similarity of two samples is larger than
, then the two samples are considered to be the same class. During the network training, the cosine similarity of these samples will be maximized. Otherwise, the samples are thought to be different classes and the cosine similarity will be minimized. The pseudo-graph supervision loss has the following form:
where
is the binary cross-entropy loss [
38].
If
is assumed to be distinctive to each other in similarity matrix
, then
can be divided into exactly
N partitions
by a threshold
t [
30]. The samples that have high cosine similarity will be in the same partition and partition
n can be set as the pseudo-label of each
. The pseudo-label can be formulated as:
where
denotes the
n-th component of the prediction vector. The probability of the predicted pseudo-label is
. Because of the optimization problem, by setting a large threshold
, only a highly confident pseudo-label is selected to train the network [
30].
The pseudo-label supervision loss is formulated as:
where
is the cross-entropy loss.
The local robustness assumption is used in [
30]. The feature representations between
and the transformed version
should be invariant, which means
and the labels of
and
should be the same. Accordingly, the feature invariant loss has the following form:
where
denotes the
-norm, which measures the distance between the deep features of
and
. Subsequently, the pseudo-graph and pseudo-label information computed based on transformed samples should be consistent with the original samples. The loss function can be formulated as:
2.3.3. Triplet Mutual Information
The instance-level mutual information between the shallow layer and deep layer features of the same sample should be maximized. The instance-level mutual information of two random variables (
D,
S) is equal to the Jensen–Shannon divergence (JSD) between samples coming from the joint distribution
and their product of marginals
[
36,
51]. Different layer features of the same sample should follow the joint distribution. If the features are from different samples, then they should follow the marginal product distribution [
36]. The JSD version mutual information is defined as:
where
d denotes the deep layer features,
s denotes the shallow layer features, and
is the softplus function
. The discriminator
T is used to distinguish whether
d and
s are sampled from the joint distribution or not. It is a convolutional neural network, which uses the deep layer and shallow layer features of samples as input. The output feature maps of
T are the inputs of
. The detailed implementation of the discriminator
T is introduced in [
36].
For two different samples,
and
, which belong to the same class, the mutual information between
’s shallow-layer representation and
’s deep-layer representation should also be maximized. Therefore, in [
30], the pseudo-graph
in Equation (
10) is used to select positive pairs and negative pairs to construct triplet correlations. When two samples are the same class, their features are positive pairs; otherwise, the features are negative pairs. In this way, the deep neural network can learn triplet-level mutual information other than instance-level mutual information. The Equation (
18) can be expanded in order to calculate the triplet mutual information. Let
and
denote the deep layer features and shallow layer features of sample
j and the class of the sample is
i. Subsequently,
and
are the features sets of class
i. Variables
and
are defined by
and
, respectively. Triplet mutual information can be formulated as:
Afterwards, the triplet mutual information loss has the following form:
The triplet mutual information has the advantage that, for two different samples and , which are the same class, the mutual information between ’s shallow layer representation and ’s deep layer representation is also maximized. Subsequently, the deep neural network can learn more discriminative representations through the triplet mutual information.
2.4. Model Optimization
By combining the investigations of IIC and DCCM, the final objective of proposed method can be formulated as:
where
,
, and
control the importance of corresponding loss functions,
, and
.
The proposed method is trained in a minibatch based end-to-end manner. After the model is trained, the cluster label can be computed by Equation (
12) while using the output one-hot vector of the softmax layer. The overall training steps are similar to [
30], as shown below:
generate paired “POA-spatio” samples and from the polarimetric coherent matrices in rotation domain.
initialize the parameters of network randomly;
for each randomly selected minibatch and , compute the shadow layer, deep layer, and softmax layer features of and ;
compute the similarity matrix , pseudo-graph , and the pseudo-labels;
select positive and negative pairs based on ;
compute the final loss by Equation (
21);
update the parameters of ; and,
calculate the unsupervised classification label by Equation (
12) after the network is well trained.
4. Experiments
The implementation of proposed method is based on the Pytorch implementation of DCCM (
https://github.com/Cory-M/DCCM) and IIC (
https://github.com/xu-ji/IIC), and most of the training parameters are not changed. The RMSprop optimizer with
is used. The thresholds
and
are set to 0.9. The parameters that control the importance of different losses are
,
, and
. The probability outputs of softmax layer are used in order to compute IIC mutual information and the similarity matrix
. The shallow layer feature and deep layer feature that are used to compute triplet mutual information are the outputs of M
and FC
. The discriminator of triplet mutual information estimation is the same to DCCM. For all of the PolSAR dataset, the neighborhood window size
w is 15.
The overall accuracy (OA), kappa coefficient, purity, and entropy [
28,
41] are used in order to evaluate the classification performances.
OA is one of the most common used measures for classification performance evaluation and it can be formulated as
where
K denotes the number of total samples and
denotes the correctly classified samples.
Kappa is an indicator of consistency and it can be computed by the following equation
where
is OA,
,
is the number of samples that belong to class
i, and
is the number of samples that are classified to class
i.
Purity and entropy are two commonly used measures for clustering performance evaluation. The purity is the higher the better and the entropy is the lower the better. The two measures are defined, as follows [
53]
where
q is the number of classes,
k the number of clusters,
is the size of cluster
r, and
is the number of data points in class
i clustered in cluster
r.
DAC [
38], DCCM, DCCM+IIC, and three traditional unsupervised PolSAR image classification methods, which are k-means, wishart cluster, and ASC-S [
31], are used to compare the performance with proposed method. The original implementation of ASC-S over-clustered PolSAR images and merged similar classes manually. In this paper, ASC-S clusters the PolSAR image to the number of classes that are defined in the ground truth map directly. DCCM+IIC just combines the DCCM with IIC mutual information loss. The input data of DCCM+IIC are generated from polarimetric coherent matrix
, and only random geometry transformations are used to generate paired samples. No rotation domain data are used. In this way, we can more clearly show that the polarimetric matrix rotation in the proposed method can improve deep mutual information learning and the performance of unsupervised PolSAR image classification. The random forest (RF) is used as baseline and it is trained in a supervised manner. For each PolSAR data, 25,000 labeled samples are randomly selected in order to train RF. We run all of the methods multiple times and choose the best classification results.
4.1. Results of GF-3 Wuhan
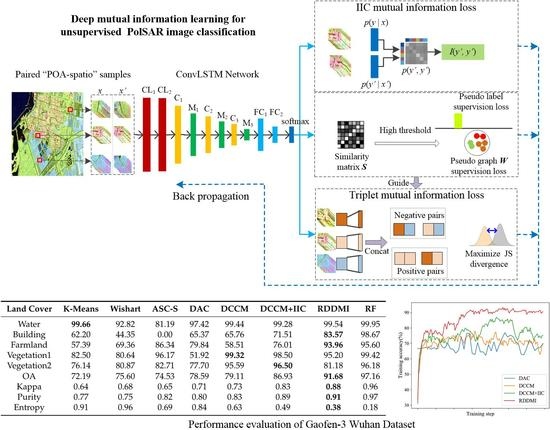
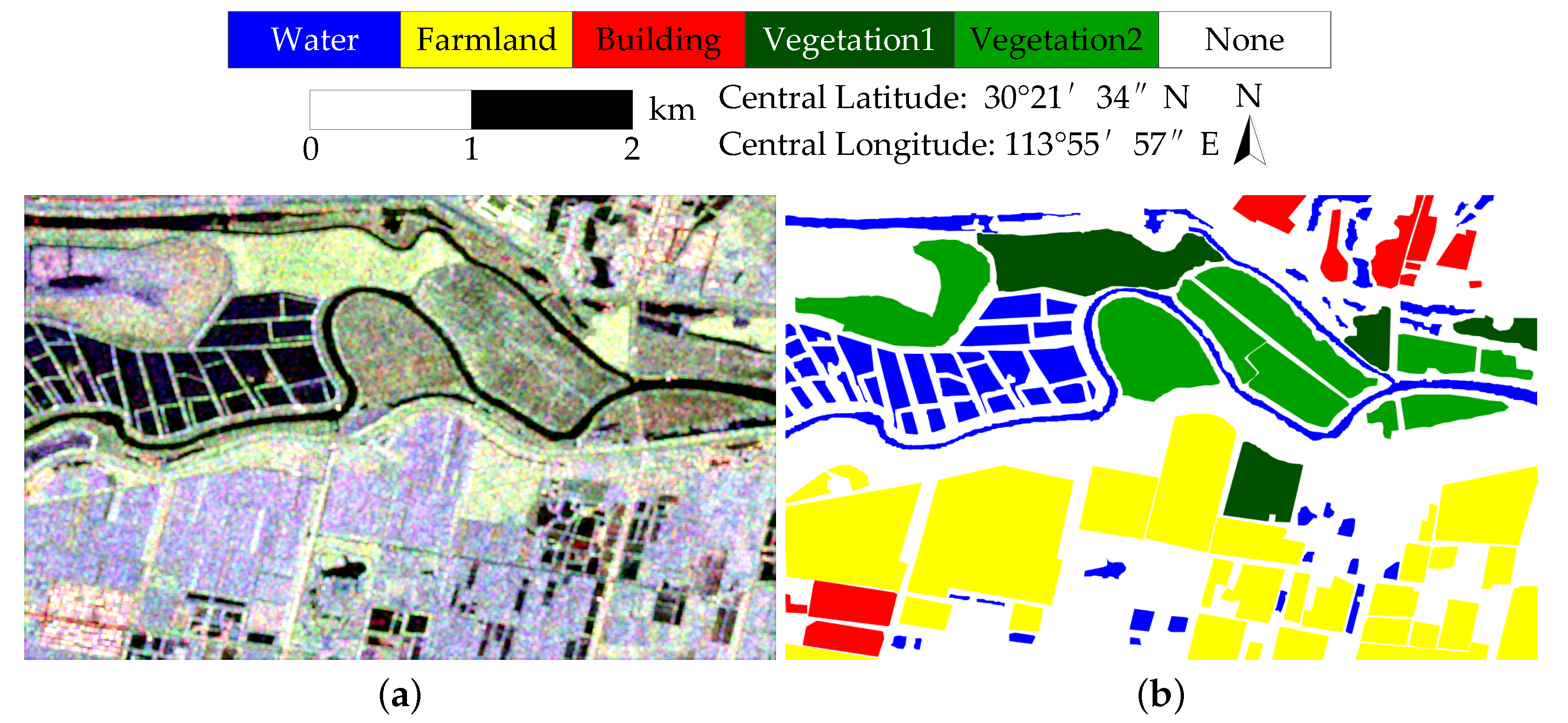
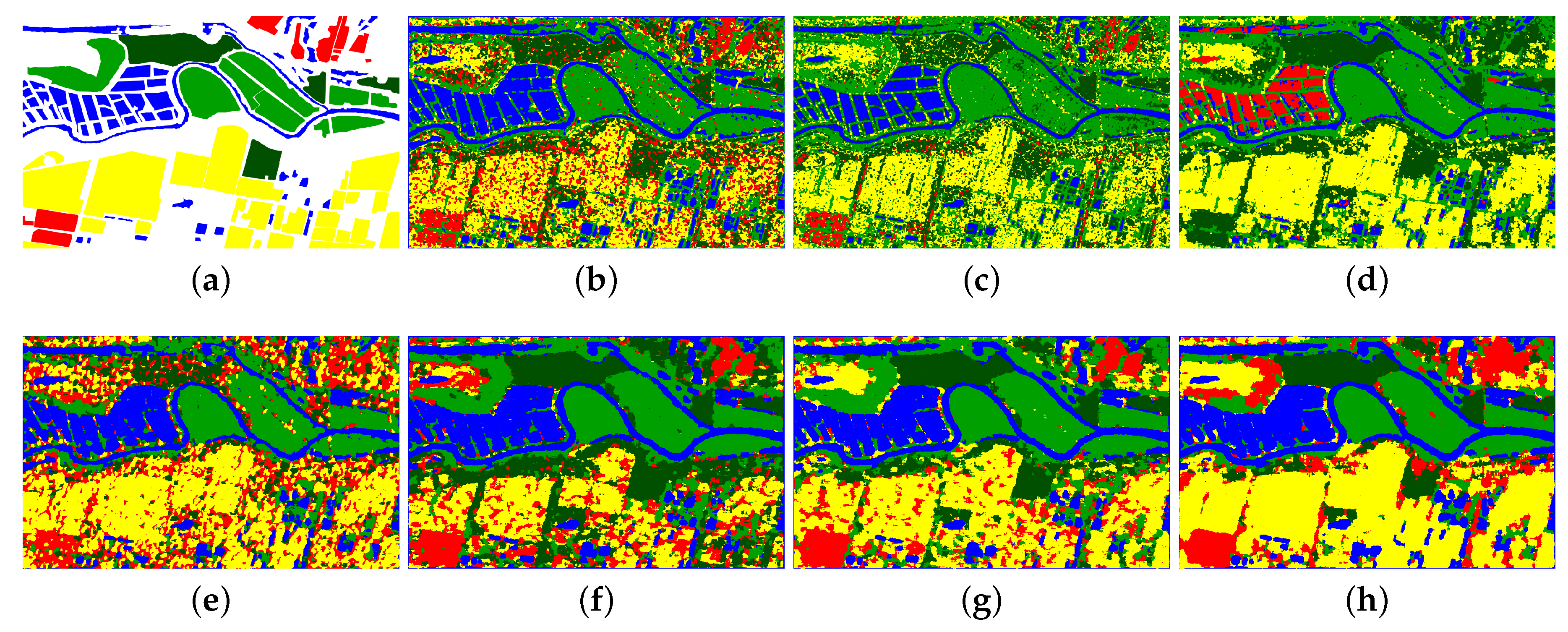
Figure 9 shows the classification results of GF-3 Wuhan dataset and
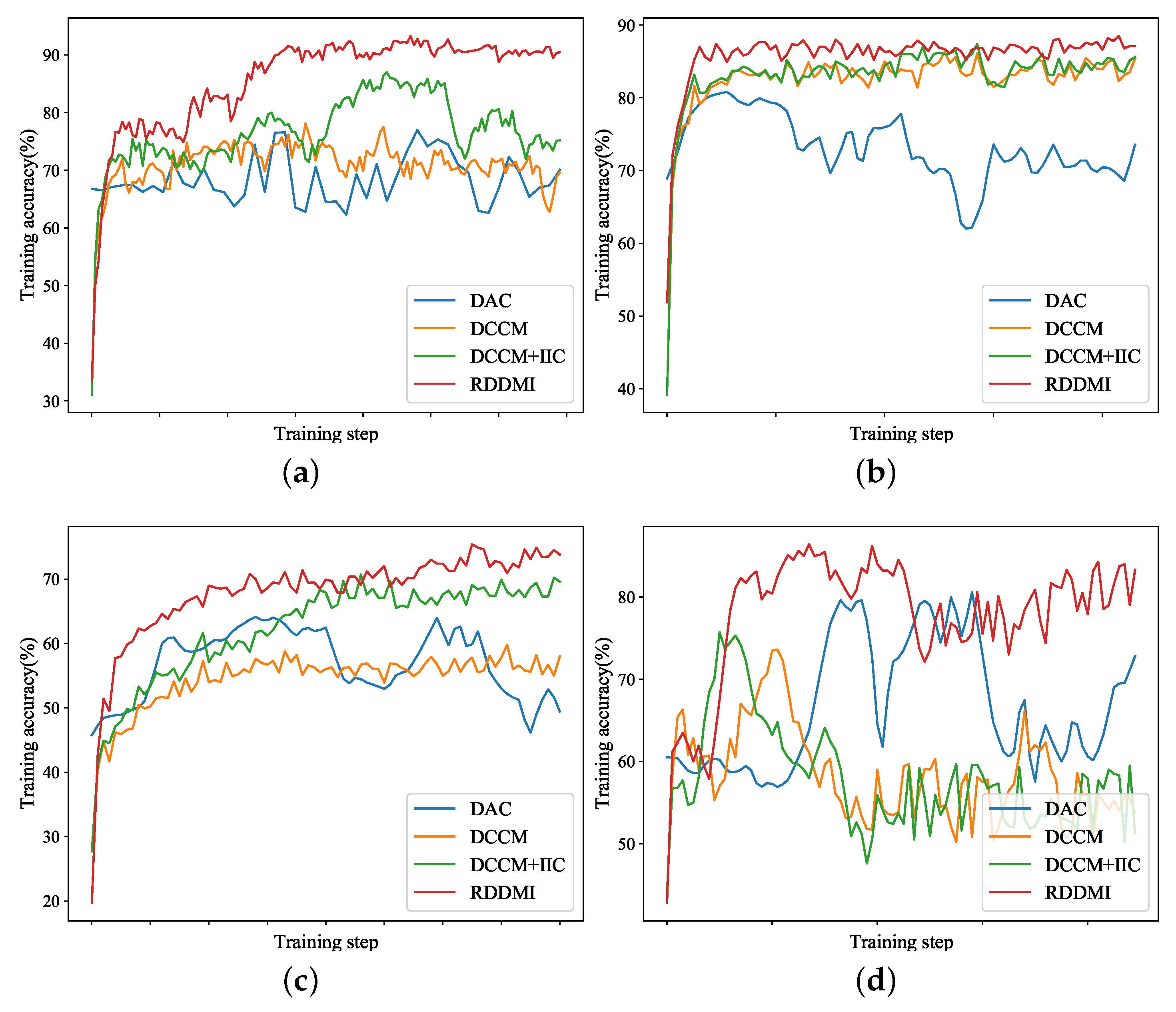
Table 2 shows the performance evaluation. Because the backscattering property of some pixels in the farmland area is similar to the building type, so the farmland and building areas are difficult to cluster in this dataset. The classification accuracies of k-means, wishart, and ASC-S are low. ASC-S classifies water area to two land cover types and cannot distinguish farmland and building types. The results of DAC and DCCM are comparable. The result of DCCM+IIC is much better. The proposed RDDMI achieves the best classification result, especially the classification accuracies of farmland and building types are both good, and the OA is 4.75% higher than DCCM+IIC. The kappa coefficient, purity, and entropy of the proposed method are also the best. Therefore, the polarimetric features in rotation domain can improve the unsupervised PolSAR data classification.
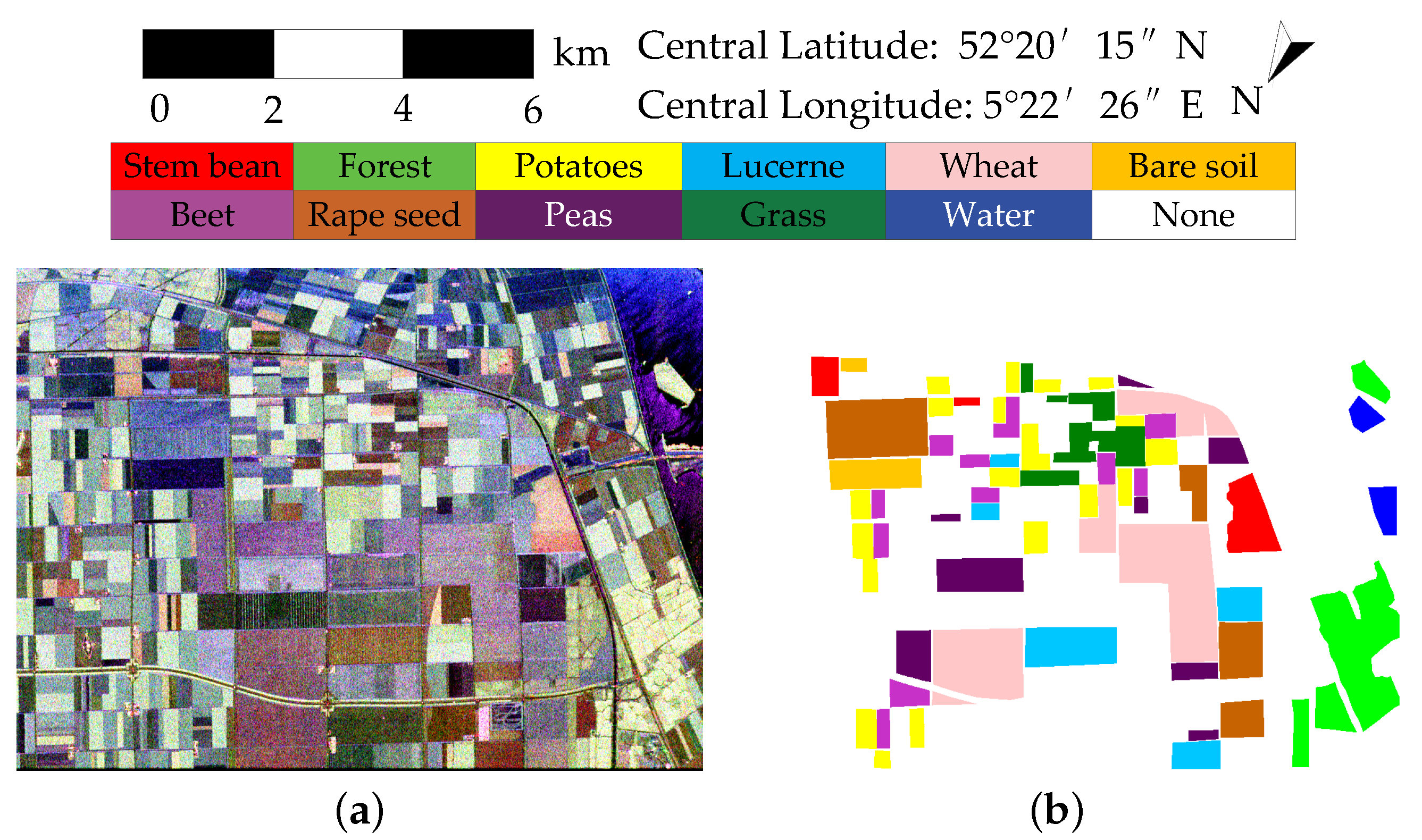
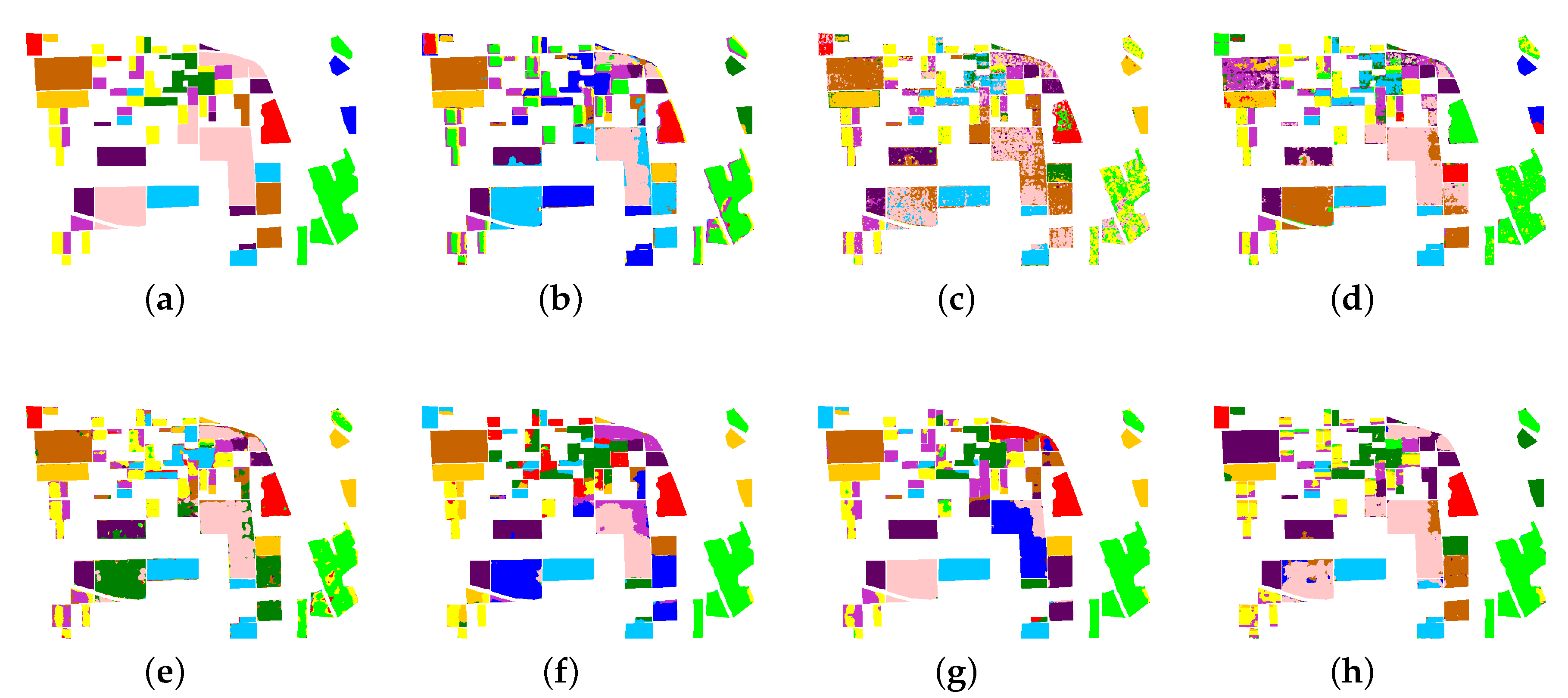
4.2. Results of RS-2 Flevoland
In the RS-2 Flevoland dataset, the farmland type has different backscattering properties. The backscattering property of some small farmland areas is similar to the forest type. Besides, some small forest areas are interspersed among the building areas, and the forest and building types are hard to cluster.
Figure 10 and
Table 3 illustrate that k-means, wishart, ASC-S, and DAC achieve bad results for farmland, forest, or building types. The classification accuracies of DCCM, DCCM+IIC, and proposed method are much better than the above four methods and the OA of proposed method is 1.07% high than DCCM+IIC. Furthermore, the performance of proposed method is very close to the supervised RF, which shows the superiority of proposed method.
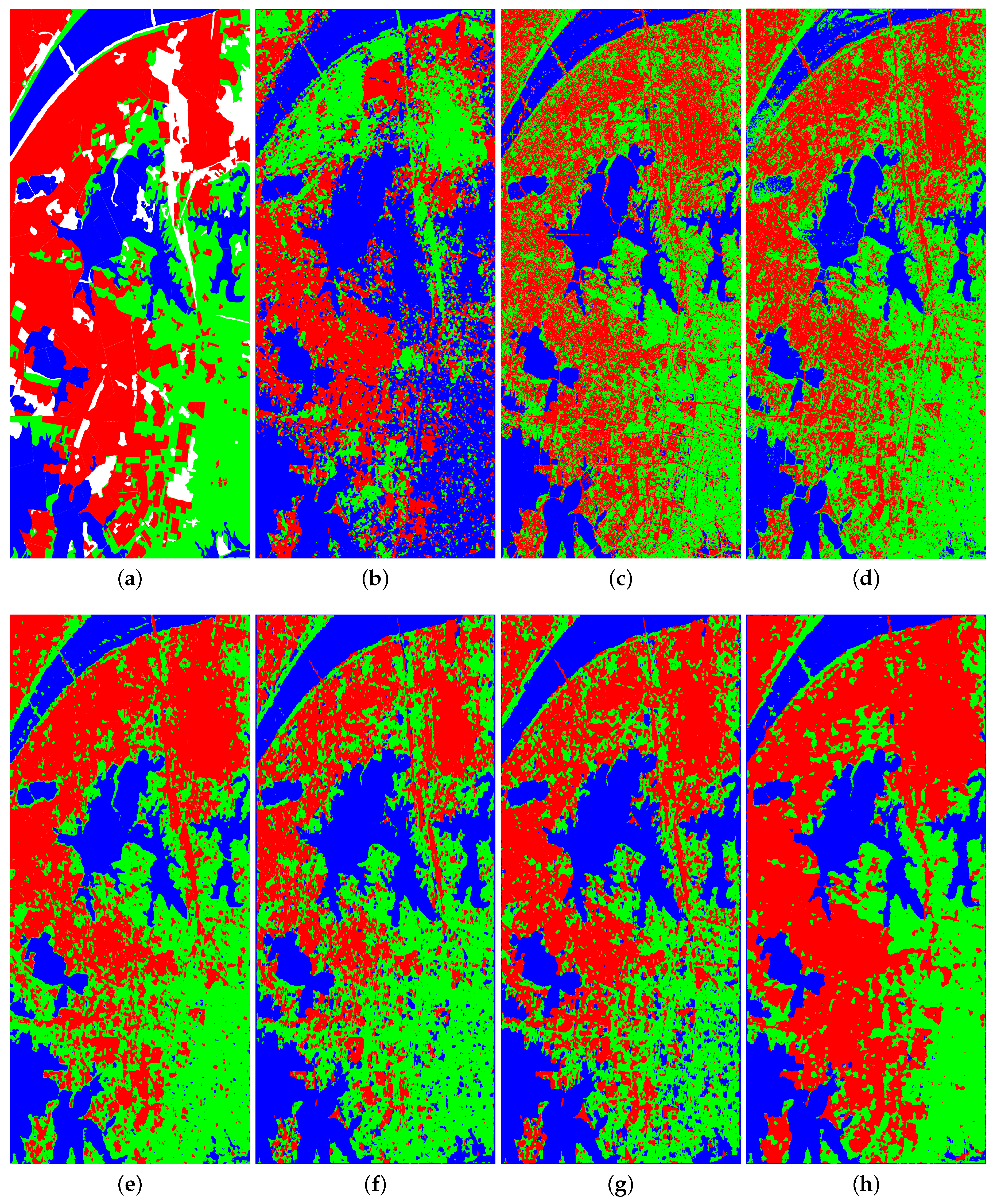
4.3. Results of AIRSAR Flevoland
A total of 11 land cover types are identified in the AIRSAR Flevoland dataset and it is a challenge for unsupervised classification. This dataset contains too many unidentified areas, which may contain new land cover types; hence, only the labeled areas are used for training and evaluation. In this dataset, some land cover types have similar backscattering properties. Besides, the observed polarimetric matrices from the same land cover type may also be quite different. The seven methods all do not achieve impressive classification results, as shown in
Figure 11 and
Table 4. The classification accuracies of many land cover types in the results of k-means, wishart, ASC-S, DAC, and DCCM are zero or very low. The backscattering property of water type is similar to other types, so DCCM+IIC and proposed method also do not classify water types correctly. However, the OA, kappa, purity, and entropy of proposed method are still much better than the other six methods. The OA of RDDMI is 5.11% higher than DCCM+IIC. It again shows that the polarimetric matrix rotation is helpful for deep mutual information learning and it can improve the performance of unsupervised PolSAR image classification.
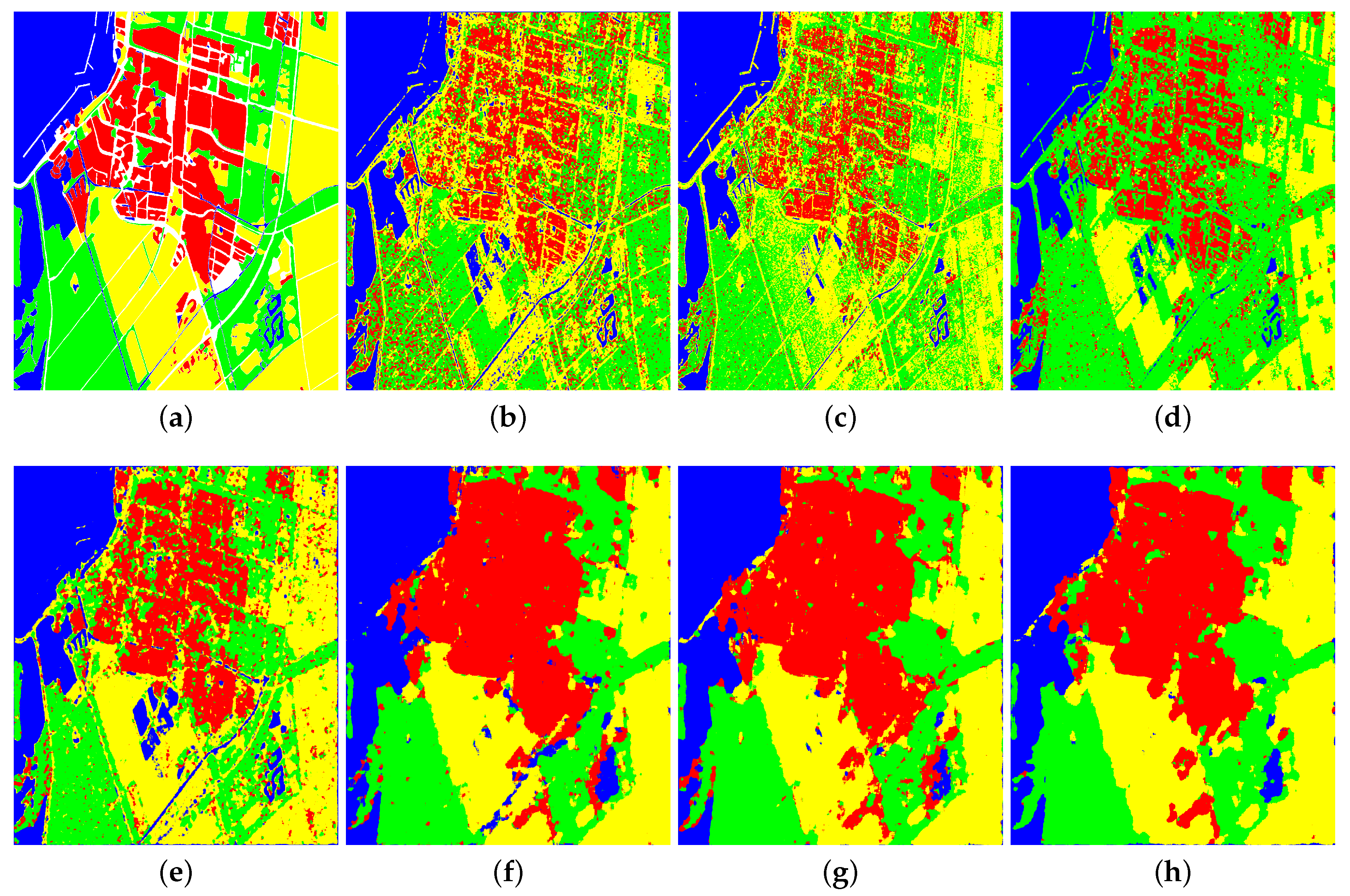
4.4. Results of RS-2 Wuhan
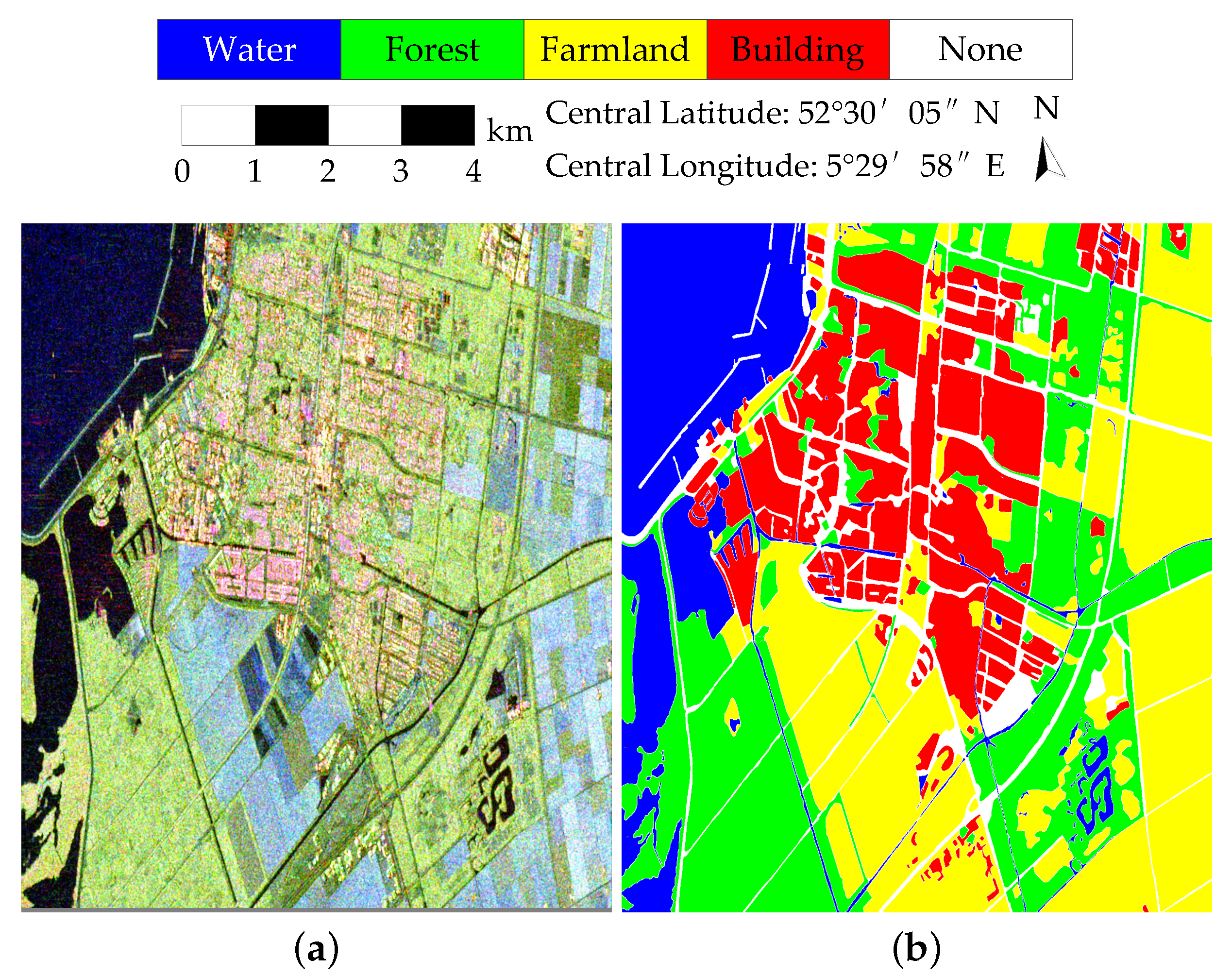
The RS-2 Wuhan dataset contains buildings with different orientations, and it is difficult to classify building type correctly.
Figure 12 and
Table 5 illustrate the classification results and the performance evaluation, respectively. The result of k-means is very bad. The results of Wishart, DAC, DCCM, and DCCM+IIC are better, but the accuracy of building type or forest type is not high. The OA of RDDMI is the best and the accuracies of building and forest types are both high. The kappa, purity, and entropy of RDDMI are also the best. The proposed method uses rotation domain polarimetric coherent matrices and it shows high robustness to buildings with different orientations. Besides, the OA of the proposed method is close to supervised RF, only 2.14% lower than RF, and it again shows that the proposed method has high performance for unsupervised PolSAR image classification.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}