Air Pollution Prediction with Multi-Modal Data and Deep Neural Networks

 ,
,  ,
,  ,
,  , ,
, ,  ,
,  and
and 
Abstract
:
1. Introduction
2. Related Work
2.1. Deep Learning Classification in Remote Sensing
2.2. Imbalanced Data in Remote Sensing
2.3. Imbalanced Data in Images
2.4. Air Pollution Prediction
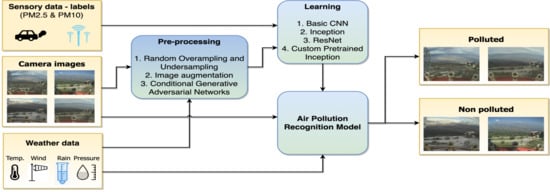
3. Methods
3.1. Architectures of the Predictive Models
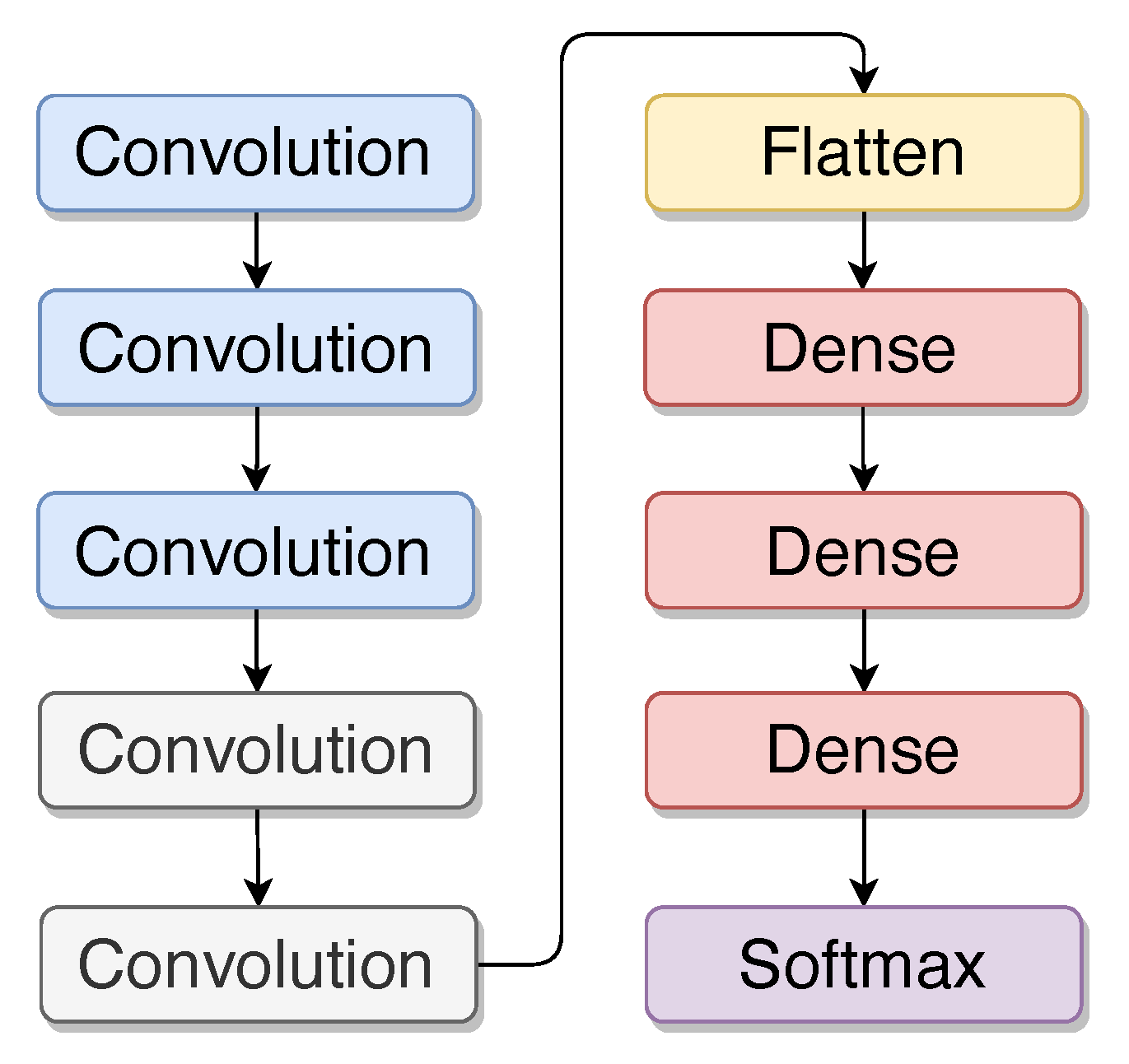
3.1.1. Basic Convolutional Neural Network Model
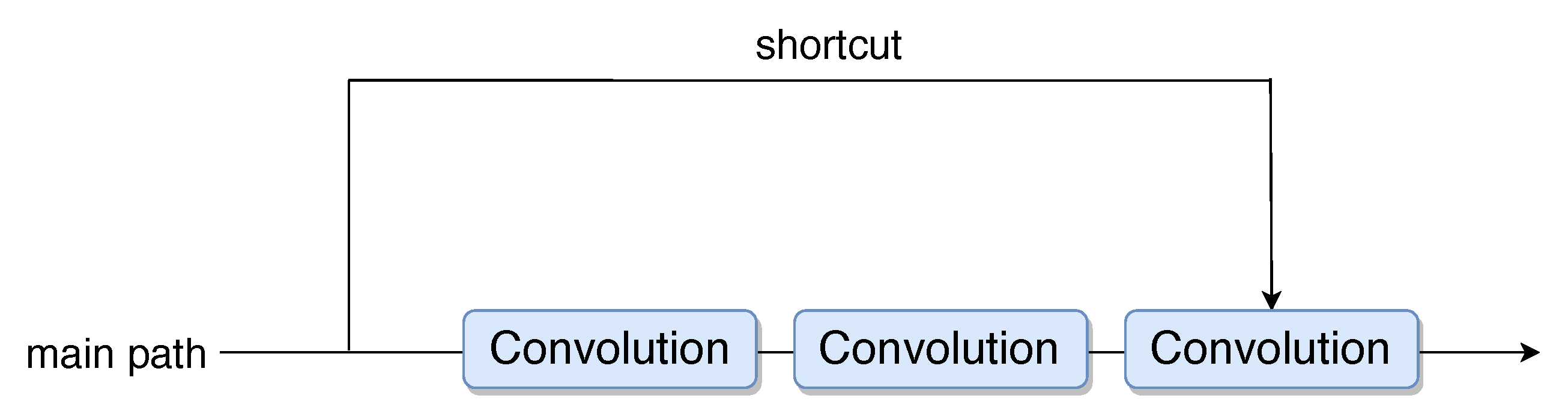
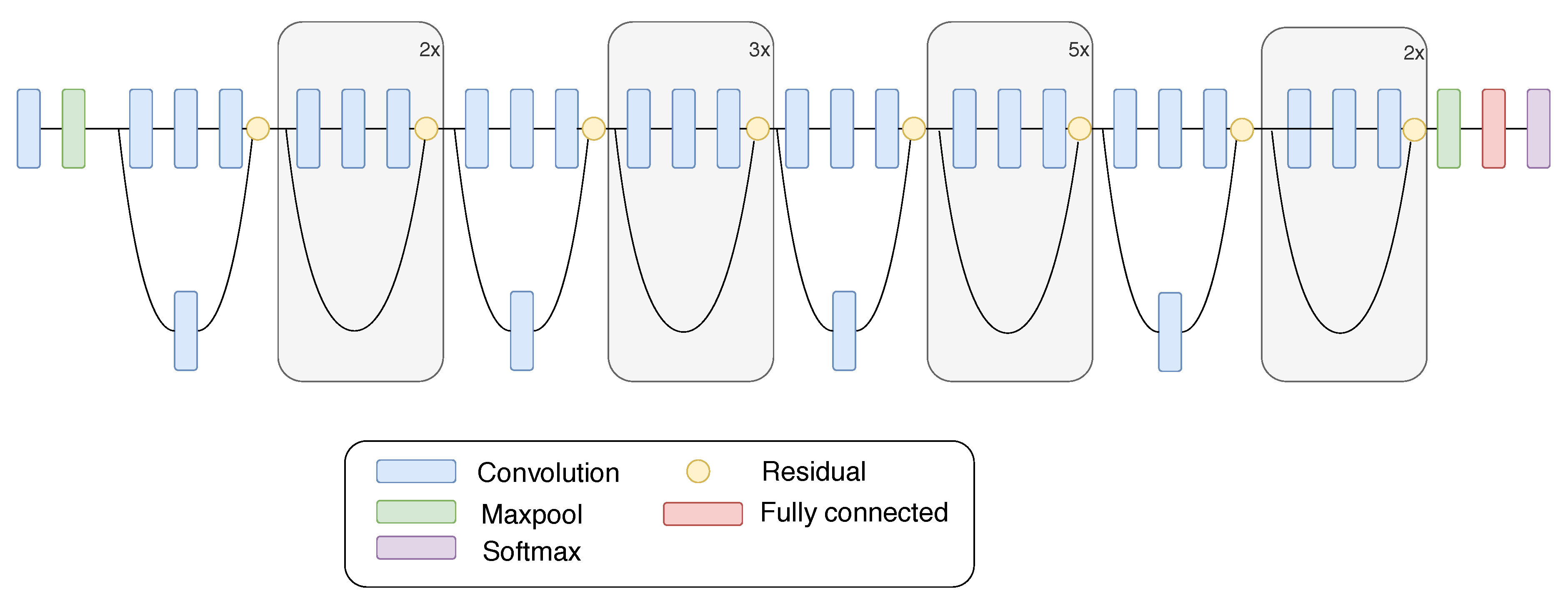
3.1.2. Residual Network Model
3.1.3. Inception Model
3.1.4. Custom Pretrained Inception
3.2. Data Preprocessing
3.2.1. Random Oversampling and Undersampling
3.2.2. Image Augmentation
3.2.3. Conditional Generative Adversarial Networks (CGAN)
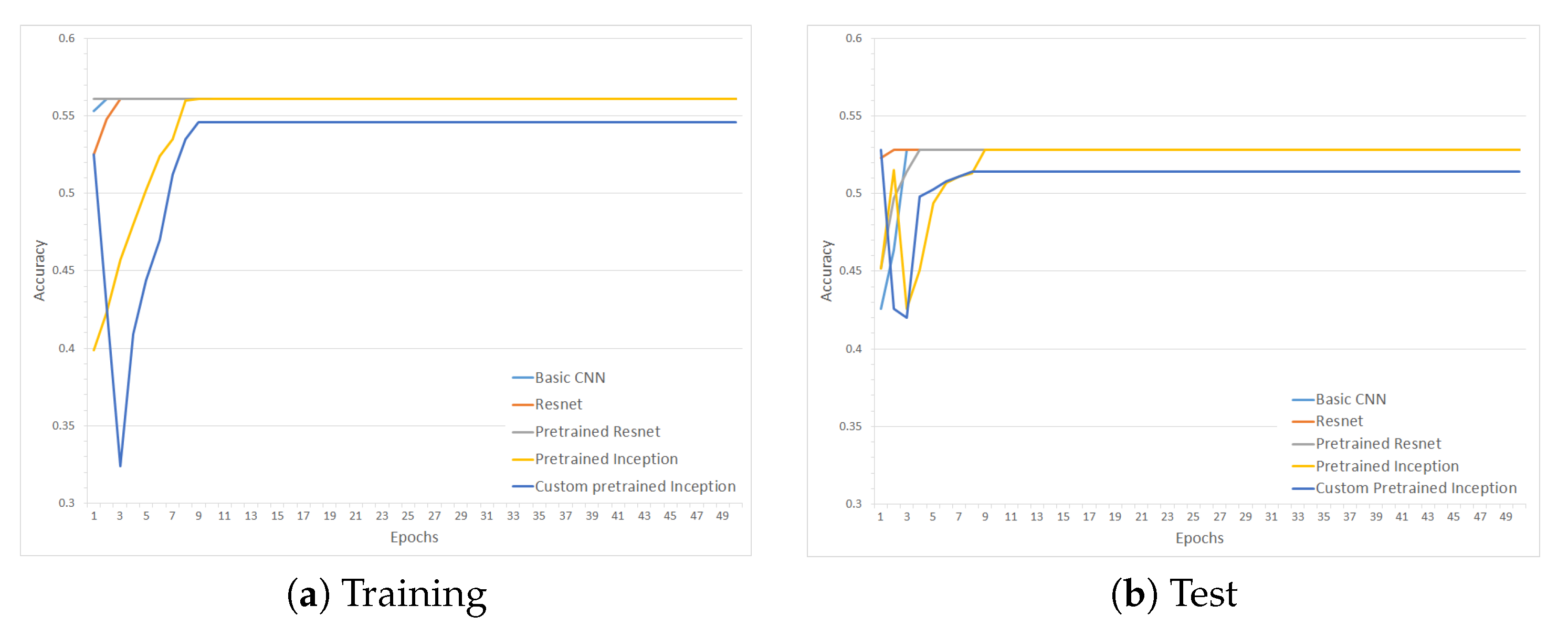
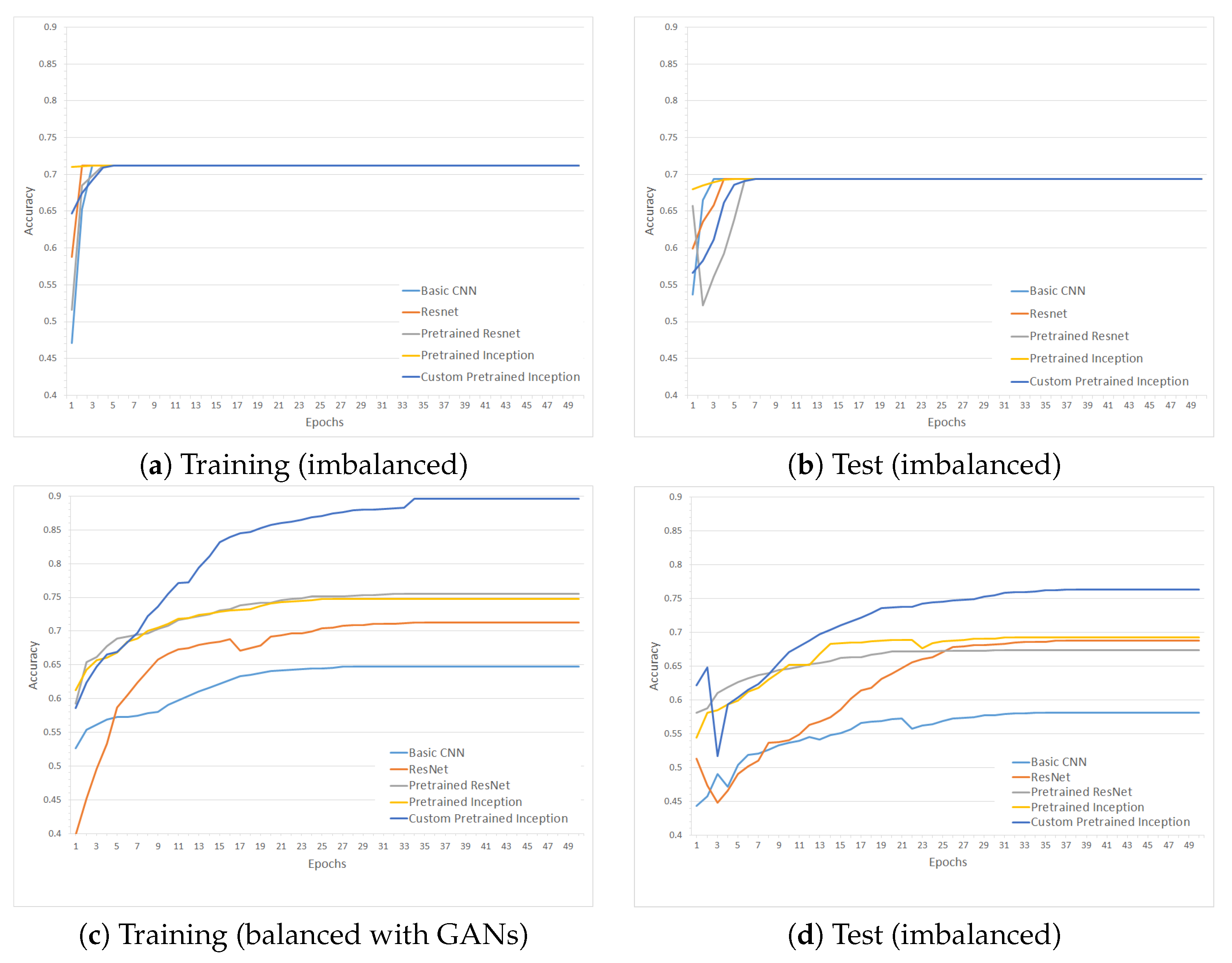
4. Results
4.1. Experimental Setup
4.2. Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Molano, J.I.R.; Bobadilla, L.M.O.; Nieto, M.P.R. Of cities traditional to smart cities. In Proceedings of the 2018 13th Iberian Conference on Information Systems and Technologies (CISTI), Cáceres, Spain, 13–16 June 2018; pp. 1–6. [Google Scholar]
- Hoffmann, B. Air pollution in cities: Urban and transport planning determinants and health in cities. In Integrating Human Health into Urban and Transport Planning; Springer: Berlin/Heisenberg, Germany, 2019; pp. 425–441. [Google Scholar]
- WHO. More than 90% of the World’s Children Breathe Toxic Air Every Day; WHO: Geneva, Switzerland, 2018. [Google Scholar]
- World Health Organization. WHO Releases Country Estimates on Air Pollution Exposure and Health Impact; World Health Organization: Geneva, Switzerland, 2016. [Google Scholar]
- World Bank. Air Pollution Deaths Cost Global Economy US$225 Billion; World Bank: Washington, DC, USA, 2016. [Google Scholar]
- Atzori, L.; Iera, A.; Morabito, G. The internet of things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Zdravevski, E.; Lameski, P.; Apanowicz, C.; Slezak, D. From Big Data to business analytics: The case study of churn prediction. Appl. Soft Comput. 2020, 90, 106164. [Google Scholar] [CrossRef]
- Marques, G.; Pires, I.M.; Miranda, N.; Pitarma, R. Air Quality Monitoring Using Assistive Robots for Ambient Assisted Living and Enhanced Living Environments through Internet of Things. Electronics 2019, 8, 1375. [Google Scholar] [CrossRef] [Green Version]
- Kalajdjieski, J.; Korunoski, M.; Stojkoska, B.R.; Trivodaliev, K. Smart City Air Pollution Monitoring and Prediction: A Case Study of Skopje. In Proceedings of the International Conference on ICT Innovations, Skopje, North Macedonia, 24–26 September 2020; pp. 15–27. [Google Scholar]
- Fan, J.; Li, Q.; Hou, J.; Feng, X.; Karimian, H.; Lin, S. A spatiotemporal prediction framework for air pollution based on deep RNN. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 15. [Google Scholar] [CrossRef] [Green Version]
- Yi, X.; Zhang, J.; Wang, Z.; Li, T.; Zheng, Y. Deep distributed fusion network for air quality prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 965–973. [Google Scholar]
- Li, T.; Shen, H.; Yuan, Q.; Zhang, X.; Zhang, L. Estimating ground-level PM2.5 by fusing satellite and station observations: A geo-intelligent deep learning approach. Geophys. Res. Lett. 2017, 44, 11–985. [Google Scholar] [CrossRef] [Green Version]
- Qi, Z.; Wang, T.; Song, G.; Hu, W.; Li, X.; Zhang, Z. Deep air learning: Interpolation, prediction, and feature analysis of fine-grained air quality. IEEE Trans. Knowl. Data Eng. 2018, 30, 2285–2297. [Google Scholar] [CrossRef] [Green Version]
- Kök, İ.; Şimşek, M.U.; Özdemir, S. A deep learning model for air quality prediction in smart cities. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1983–1990. [Google Scholar]
- Li, X.; Peng, L.; Hu, Y.; Shao, J.; Chi, T. Deep learning architecture for air quality predictions. Environ. Sci. Pollut. Res. 2016, 23, 22408–22417. [Google Scholar] [CrossRef]
- Ceci, M.; Corizzo, R.; Japkowicz, N.; Mignone, P.; Pio, G. ECHAD: Embedding-Based Change Detection From Multivariate Time Series in Smart Grids. IEEE Access 2020, 8, 156053–156066. [Google Scholar] [CrossRef]
- Liu, B.; Yan, S.; Li, J.; Qu, G.; Li, Y.; Lang, J.; Gu, R. A sequence-to-sequence air quality predictor based on the n-step recurrent prediction. IEEE Access 2019, 7, 43331–43345. [Google Scholar] [CrossRef]
- Masarczyk, W.; Głomb, P.; Grabowski, B.; Ostaszewski, M. Effective Training of Deep Convolutional Neural Networks for Hyperspectral Image Classification through Artificial Labeling. Remote Sens. 2020, 12, 2653. [Google Scholar] [CrossRef]
- Valentijn, T.; Margutti, J.; van den Homberg, M.; Laaksonen, J. Multi-Hazard and Spatial Transferability of a CNN for Automated Building Damage Assessment. Remote Sens. 2020, 12, 2839. [Google Scholar] [CrossRef]
- Petrovska, B.; Atanasova-Pacemska, T.; Corizzo, R.; Mignone, P.; Lameski, P.; Zdravevski, E. Aerial scene classification through fine-tuning with adaptive learning rates and label smoothing. Appl. Sci. 2020, 10, 5792. [Google Scholar] [CrossRef]
- Petrovska, B.; Zdravevski, E.; Lameski, P.; Corizzo, R.; Štajduhar, I.; Lerga, J. Deep learning for feature extraction in remote sensing: A case-study of aerial scene classification. Sensors 2020, 20, 3906. [Google Scholar] [CrossRef] [PubMed]
- Cabezas, M.; Kentsch, S.; Tomhave, L.; Gross, J.; Caceres, M.L.L.; Diez, Y. Detection of Invasive Species in Wetlands: Practical DL with Heavily Imbalanced Data. Remote Sens. 2020, 12, 3431. [Google Scholar] [CrossRef]
- Valle, D.; Hyde, J.; Marsik, M.; Perz, S. Improved Inference and Prediction for Imbalanced Binary Big Data Using Case-Control Sampling: A Case Study on Deforestation in the Amazon Region. Remote Sens. 2020, 12, 1268. [Google Scholar] [CrossRef] [Green Version]
- Roudier, P.; Burge, O.R.; Richardson, S.J.; McCarthy, J.K.; Grealish, G.J.; Ausseil, A.G. National Scale 3D Mapping of Soil pH Using a Data Augmentation Approach. Remote Sens. 2020, 12, 2872. [Google Scholar] [CrossRef]
- Naboureh, A.; Li, A.; Bian, J.; Lei, G.; Amani, M. A Hybrid Data Balancing Method for Classification of Imbalanced Training Data within Google Earth Engine: Case Studies from Mountainous Regions. Remote Sens. 2020, 12, 3301. [Google Scholar] [CrossRef]
- Naboureh, A.; Ebrahimy, H.; Azadbakht, M.; Bian, J.; Amani, M. RUESVMs: An Ensemble Method to Handle the Class Imbalance Problem in Land Cover Mapping Using Google Earth Engine. Remote Sens. 2020, 12, 3484. [Google Scholar] [CrossRef]
- Ren, Y.; Zhang, X.; Ma, Y.; Yang, Q.; Wang, C.; Liu, H.; Qi, Q. Full Convolutional Neural Network Based on Multi-Scale Feature Fusion for the Class Imbalance Remote Sensing Image Classification. Remote Sens. 2020, 12, 3547. [Google Scholar] [CrossRef]
- Ren, Y.; Yu, Y.; Guan, H. DA-CapsUNet: A Dual-Attention Capsule U-Net for Road Extraction from Remote Sensing Imagery. Remote Sens. 2020, 12, 2866. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, L.; Wang, Z.; Yu, Y.; Liu, X.; Xu, F. Intelligent Ship Detection in Remote Sensing Images Based on Multi-Layer Convolutional Feature Fusion. Remote Sens. 2020, 12, 3316. [Google Scholar] [CrossRef]
- Yap, B.W.; Abd Rani, K.; Abd Rahman, H.A.; Fong, S.; Khairudin, Z.; Abdullah, N.N. An application of oversampling, undersampling, bagging and boosting in handling imbalanced datasets. In Proceedings of the First International Conference on Advanced Data and Information Engineering (DaEng-2013), Kuala Lumpur, Malaysia, 16–18 December 2014; pp. 13–22. [Google Scholar]
- Mariani, G.; Scheidegger, F.; Istrate, R.; Bekas, C.; Malossi, C. Bagan: Data augmentation with balancing gan. arXiv 2018, arXiv:1803.09655. [Google Scholar]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Madani, A.; Moradi, M.; Karargyris, A.; Syeda-Mahmood, T. Chest X-ray generation and data augmentation for cardiovascular abnormality classification. In Proceedings of the Medical Imaging 2018: Image Processing, International Society for Optics and Photonics, Houston, TX, USA, 11–13 February 2018; Volume 10574, p. 105741M. [Google Scholar]
- Bowles, C.; Chen, L.; Guerrero, R.; Bentley, P.; Gunn, R.; Hammers, A.; Dickie, D.A.; Hernández, M.V.; Wardlaw, J.; Rueckert, D. Gan augmentation: Augmenting training data using generative adversarial networks. arXiv 2018, arXiv:1810.10863. [Google Scholar]
- Zheng, Y.; Yi, X.; Li, M.; Li, R.; Shan, Z.; Chang, E.; Li, T. Forecasting fine-grained air quality based on big data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10 August 2015; pp. 2267–2276. [Google Scholar]
- Corani, G.; Scanagatta, M. Air pollution prediction via multi-label classification. Environ. Model. Softw. 2016, 80, 259–264. [Google Scholar] [CrossRef] [Green Version]
- Corizzo, R.; Ceci, M.; Fanaee-T, H.; Gama, J. Multi-aspect renewable energy forecasting. Inf. Sci. 2020, 546, 701–722. [Google Scholar] [CrossRef]
- Arsov, M.; Zdravevski, E.; Lameski, P.; Corizzo, R.; Koteli, N.; Mitreski, K.; Trajkovik, V. Short-term air pollution forecasting based on environmental factors and deep learning models. In Proceedings of the 2020 Federated Conference on Computer Science and Information Systems, Sofia, Bulgaria, 6–9 September 2020; Ganzha, M., Maciaszek, L., Paprzycki, M., Eds.; IEEE: New York, NY, USA, 2020; Volume 21, pp. 15–22. [Google Scholar] [CrossRef]
- Corizzo, R.; Ceci, M.; Zdravevski, E.; Japkowicz, N. Scalable auto-encoders for gravitational waves detection from time series data. Expert Syst. Appl. 2020, 151, 113378. [Google Scholar] [CrossRef]
- Liu, D.R.; Lee, S.J.; Huang, Y.; Chiu, C.J. Air pollution forecasting based on attention-based LSTM neural network and ensemble learning. Expert Syst. 2019, 37, e12511. [Google Scholar] [CrossRef]
- Kalajdjieski, J.; Mircheva, G.; Kalajdziski, S. Attention Models for PM2.5 Prediction. In Proceedings of the IEEE/ACM International Conferencce on Utility and Cloud Computing, Online, 7–10 December 2020. [Google Scholar]
- Huang, C.J.; Kuo, P.H. A deep cnn-lstm model for particulate matter (PM2.5) forecasting in smart cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef] [Green Version]
- Qin, D.; Yu, J.; Zou, G.; Yong, R.; Zhao, Q.; Zhang, B. A novel combined prediction scheme based on CNN and LSTM for urban PM 2.5 concentration. IEEE Access 2019, 7, 20050–20059. [Google Scholar] [CrossRef]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A novel spatiotemporal convolutional long short-term neural network for air pollution prediction. Sci. Total Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef] [PubMed]
- Steininger, M.; Kobs, K.; Zehe, A.; Lautenschlager, F.; Becker, M.; Hotho, A. MapLUR: Exploring a New Paradigm for Estimating Air Pollution Using Deep Learning on Map Images. ACM Trans. Spat. Algorithms Syst. (TSAS) 2020, 6, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Li, K.; Han, Y.; Yang, J. Image-based air pollution estimation using hybrid convolutional neural network. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 471–476. [Google Scholar]
- Yue, J.; Zhao, W.; Mao, S.; Liu, H. Spectral–spatial classification of hyperspectral images using deep convolutional neural networks. Remote Sens. Lett. 2015, 6, 468–477. [Google Scholar] [CrossRef]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable object detection using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2147–2154. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Toshevska, M.; Stojanovska, F.; Zdravevski, E.; Lameski, P.; Gievska, S. Explorations into Deep Learning Text Architectures for Dense Image Captioning. In Proceedings of the 2020 Federated Conference on Computer Science and Information Systems, Sofia, Bulgaria, 6–9 September 2020; Ganzha, M., Maciaszek, L., Paprzycki, M., Eds.; IEEE: New York, NY, USA, 2020; Volume 21, pp. 129–136. [Google Scholar] [CrossRef]
- Liu, A.C. The Effect of Oversampling and Undersampling on Classifying Imbalanced Text Datasets. Master’s Thesis, The University of Texas at Austin, Austin, TX, USA, 2004. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Han, S.; Sun, B. Impact of Population Density on PM2.5 Concentrations: A Case Study in Shanghai, China. Sustainability 2019, 11, 1968. [Google Scholar] [CrossRef] [Green Version]
- Xie, R.; Sabel, C.E.; Lu, X.; Zhu, W.; Kan, H.; Nielsen, C.P.; Wang, H. Long-term trend and spatial pattern of PM2.5 induced premature mortality in China. Environ. Int. 2016, 97, 180–186. [Google Scholar] [CrossRef]
- Sun, Y.; Zhuang, G.; Wang, Y.; Han, L.; Guo, J.; Dan, M.; Zhang, W.; Wang, Z.; Hao, Z. The air-borne particulate pollution in Beijing—concentration, composition, distribution and sources. Atmos. Environ. 2004, 38, 5991–6004. [Google Scholar] [CrossRef]
- Pui, D.Y.; Chen, S.C.; Zuo, Z. PM2.5 in China: Measurements, sources, visibility and health effects, and mitigation. Particuology 2014, 13, 1–26. [Google Scholar] [CrossRef]
- Wu, D.; Lau, A.K.; Leung, Y.; Bi, X.; Li, F.; Tan, H.; Liao, B.; Chen, H. Hazy weather formation and visibility deterioration resulted from fine particulate (PM2.5) pollutions in Guangdong and Hong Kong. Huanjing Kexue Xuebao 2012, 32, 2660. [Google Scholar]
- Ma, Z.; Zhao, X.; Meng, W.; Meng, Y.; He, D.; Liu, H. Comparison of influence of fog and haze on visibility in Beijing. Environ. Sci. Res. 2012, 25, 1208–1214. [Google Scholar]
- Zhao, X.; Zhou, W.; Han, L.; Locke, D. Spatiotemporal variation in PM2.5 concentrations and their relationship with socioeconomic factors in China’s major cities. Environ. Int. 2019, 133, 105145. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AQI Category | PM2.5 Range | 6-Class Labels | Binary Labels |
|---|---|---|---|
| Good | 0–50 | AQI-1 | Not polluted |
| Moderate | 51–100 | AQI-2 | Not polluted |
| Unhealthy for Sensitive Groups | 101–150 | AQI-3 | Polluted |
| Unhealthy | 151–200 | AQI-4 | Polluted |
| Very Unhealthy | 201–300 | AQI-5 | Polluted |
| Hazardous | 301 and above | AQI-6 | Polluted |
| Dataset | AQI-1 | AQI-2 | AQI-3 | AQI-4 | AQI-5 | AQI-6 |
|---|---|---|---|---|---|---|
| Train | 80,331 | 21,623 | 13,954 | 11,087 | 9862 | 6337 |
| % | 56.1% | 15.1% | 9.7% | 7.7% | 6.9% | 4.4% |
| Test | 13,342 | 4219 | 3022 | 1987 | 1564 | 1135 |
| % | 52.8% | 16.7% | 12.0% | 7.9% | 6.2% | 4.5% |
| Dataset | Not Polluted | Polluted | Total |
|---|---|---|---|
| Train | 101,954 | 41,240 | 143,194 |
| % | 71.2% | 28.8% | |
| Test | 17,561 | 7708 | 25,269 |
| % | 69.5% | 30.5% | |
| Total | 168,463 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kalajdjieski, J.; Zdravevski, E.; Corizzo, R.; Lameski, P.; Kalajdziski, S.; Pires, I.M.; Garcia, N.M.; Trajkovik, V. Air Pollution Prediction with Multi-Modal Data and Deep Neural Networks. Remote Sens. 2020, 12, 4142. https://doi.org/10.3390/rs12244142
Kalajdjieski J, Zdravevski E, Corizzo R, Lameski P, Kalajdziski S, Pires IM, Garcia NM, Trajkovik V. Air Pollution Prediction with Multi-Modal Data and Deep Neural Networks. Remote Sensing. 2020; 12(24):4142. https://doi.org/10.3390/rs12244142
Chicago/Turabian StyleKalajdjieski, Jovan, Eftim Zdravevski, Roberto Corizzo, Petre Lameski, Slobodan Kalajdziski, Ivan Miguel Pires, Nuno M. Garcia, and Vladimir Trajkovik. 2020. "Air Pollution Prediction with Multi-Modal Data and Deep Neural Networks" Remote Sensing 12, no. 24: 4142. https://doi.org/10.3390/rs12244142
APA StyleKalajdjieski, J., Zdravevski, E., Corizzo, R., Lameski, P., Kalajdziski, S., Pires, I. M., Garcia, N. M., & Trajkovik, V. (2020). Air Pollution Prediction with Multi-Modal Data and Deep Neural Networks. Remote Sensing, 12(24), 4142. https://doi.org/10.3390/rs12244142