1. Introduction
Liquefaction is an important ground failure to be identified and mapped after a major earthquake. Detecting liquefaction surface effects in near-real time after an earthquake can expedite clean-up efforts, rescue operation, and loss estimation. Detailed maps of liquefaction surface effects are also useful for the research community. After a major earthquake occurs, a geotechnical/geologic reconnaissance team such as those launched by the US Geological Survey (USGS) or Geotechnical Extreme Event Reconnaissance (GEER) may travel to the region to observe and map liquefaction along with other impacts. Field mapping generally occurs several days or weeks after the event and has a heavy logistical burden as well as a high cost. Satellite and aerial imageries as remote sensing data are valuable tools to aid with disaster relief and damage mapping and therefore, an automated classification that is available in the planning stage of a field reconnaissance can significantly improve the efficiency and impact of a field reconnaissance trip [
1]. Aerial imagery usually has a higher spatial resolution than satellite imagery but requires some lead time to plan the flight. Satellites can be redirected quickly to acquire imagery that is often made available very soon after an event for disaster response.
In many studies, human visual interpreter(s) look at the pre- and post-event imagery and note the changes to the ground and map the liquefaction [
2,
3,
4]. After the 1995 Kobe earthquake in Japan, [
2] manually detected and mapped the liquefaction using high resolution aerial imagery taken prior and after the event; however, this method would take long if the affected area is large and is beyond rapid response framework. After the 2014 Iquique earthquake in Chile, [
3] used a small drone (unmanned aerial system) to capture aerial imagery from two liquefied sites and interpreted the extent and damage to the built environment visually; they only processed imagery captured after the event and visually detected the liquefaction on images with no automatic procedure. In [
4], the liquefaction extent after the Canterbury earthquake sequences in New Zealand (2010–2011) was mapped by visually looking at the satellite and aerial imageries after the events and incorporating them with the field observation surveys; this process again took weeks to finish and cannot be suggested to first responders. As an alternative, investigators have mapped liquefaction automatically using remotely sensed data. In [
5], researchers used the optical satellite imagery with 0.5 m resolution after the 2010 Darfield, February 2011 Christchurch, and 2011 Tohoku Earthquakes to map the liquefaction and measure the lateral displacement using pre- and post-event imagery by detecting the changes. Furthermore, [
6] detected the liquefaction-induced water bodies by combining different spectral bands from Indian Remote Sensing Satellite (IRS-1C) imagery with spatial resolution ranging from 5.8 to 188 m and using a wetness index as a proxy for soil moisture after the Bhuj 2001 earthquake in India; however, they used pre- and post-event imageries with very low resolution and cannot be recommended for loss estimation and rescue operation. For the same earthquake, [
7] related the changes in temperature and moisture content of the earth’s surface to the surficial manifestation of earthquake-induced liquefaction using Landsat imagery (which has a low spatial resolution) before and after the event. In [
8], investigators detected and classified the liquefied materials on the ground using object-based image analysis on high resolution (10 cm) airborne RGB imagery along with LiDAR (light detection and range) data that was acquired 2 days after the event. They treated each liquefaction patch on the ground as an object and then statistically classified objects on the ground into two different liquefaction classes; however, this process may take long for larger area as it needs to treat each object differently. Similarly, [
9] used an automated workflow for mapping the liquefaction manifestation after the 2011 Tohoku earthquake in Japan using object-based classification methods on a high-resolution (2 m) Word-View 2 optical imagery before and after the event. They concluded that in highly urban areas, detecting liquefaction is more challenging despite the availability of imagery pair of pre- and post-event.
Using automated supervised methods with optical imagery for liquefaction mapping is a promising step in providing detailed, region-scale maps of liquefaction extent very quickly after an earthquake; however, it is still primarily a research undertaking and has yet to become operational. This paper takes a step toward making automated classification of optical imagery operational by providing important recommendations on how to construct an appropriate training dataset. This paper will help elucidate questions such as: “Should I use aerial or satellite imagery? What spectral bands are most important to include? How many training pixels are required? What accuracy should I expect? Are liquefaction surface effects detectable? Can geospatial information be used to improve classification accuracy?”
One approach to automatically detect liquefaction surface effects is to compare the pre- and post-event imagery and measure the difference (multi-temporal change detection process) as used by [
6,
7,
9]; however, this method requires both images to have the same acquisition characteristics (sensor, looking angle, time of the day, etc.) to generate reliable results. Differences in looking angle and shadows can have a significant detrimental effect on classification accuracy as shown by [
9]. Furthermore, a close-date pre-event image is not always available or useable. Another approach for liquefaction detection is pixel-based or object-based image classification using a single imagery (mono-temporal) as demonstrated by [
8]. Object-based classification integrates neighboring homogeneous pixels into objects, segments the image accordingly, and finally performs the classification object by object [
10,
11]. Object-based analysis requires several parameters for image segmentation that are difficult to select, especially for urban areas [
12,
13]. Pixel-based classifications assign pixels to landcover classes using unsupervised or supervised techniques. Unsupervised pixel-based classifications group pixels with similar spectral values into unique clusters according to statistically predefined thresholds and can be applied faster; however, they are usually less accurate and require more data cleaning than supervised methods. Supervised pixel-based classifications need training data set (samples of known identity) to classify unknown image pixels and take longer to apply but tend to result in more accurate and robust classifications.
The accuracy of automated supervised methods in image classification mainly depends on the quantity and quality of training samples, and number of spectral bands. For parametric classifiers (e.g., maximum likelihood and minimum distance), there is a direct relation between the size of the training dataset and the classifier’s accuracy and reliability [
14]. Digitizing a large number of high-quality training samples from an event may not be feasible in the desired timeframe for rapid response as the training pixels for each class should be typical and accurately represent the spectral diversity of that specific class [
15]. In satellite or aerial imagery, it is possible for different classes on the ground to have similar spectral information, which make the sampling process harder and could eventually weaken the classifier performance. Furthermore, the availability of spectral bands beyond the visible spectrum (RGB) in satellite or aerial imagery can impact the image classification performance. To further improve the classification performance, prior knowledge of landcover/use (e.g., GIS spatial layers) can be used to remove objects that have high spectral variation and overlap with other classes, which users desire to detect and classify. In summary, the quality and quantity of the training data as well as the number of available spectral bands and additional land use knowledge will all impact automated classification performance.
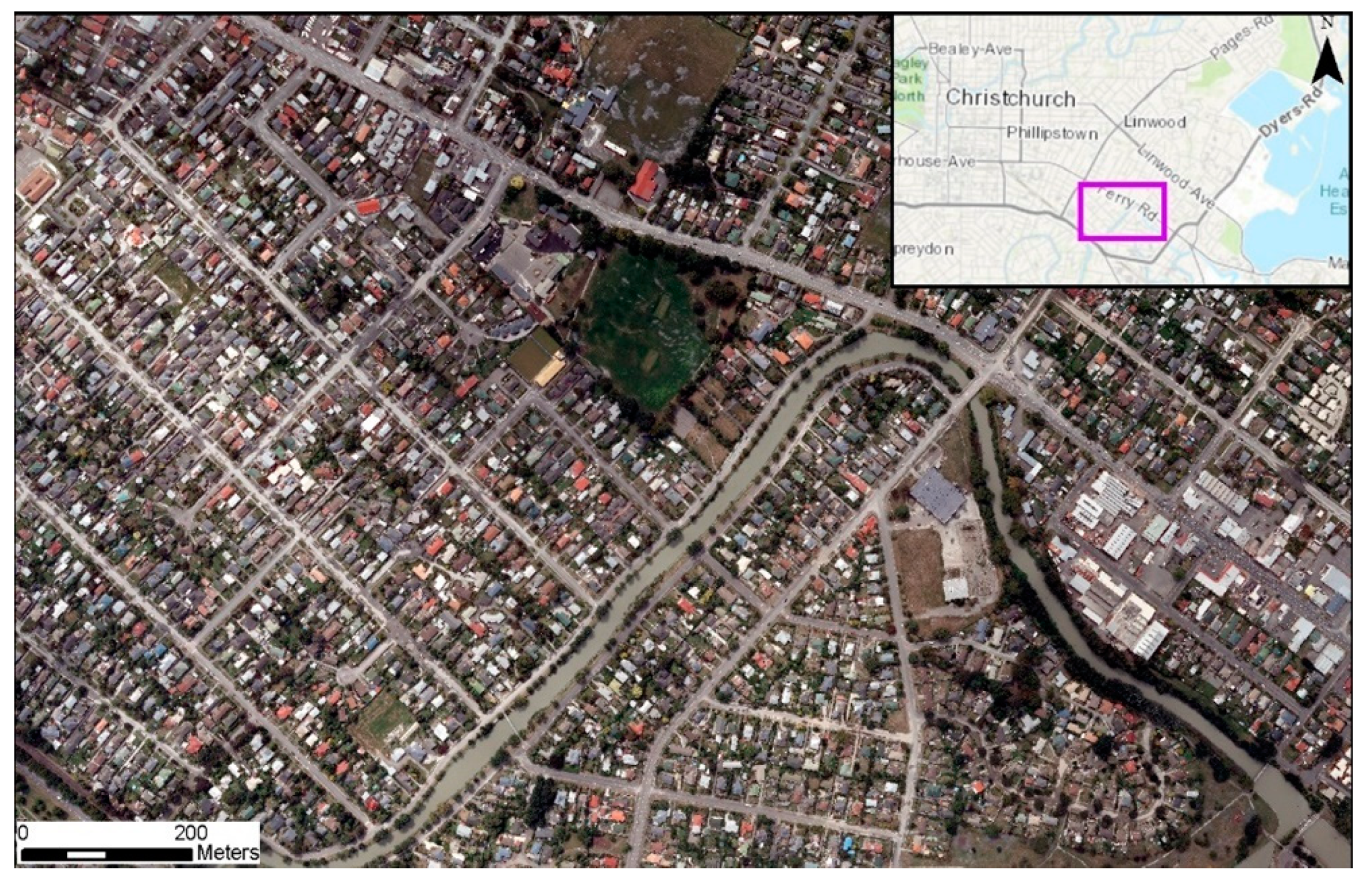
To perform automated classification to detect liquefaction surface effects with reliable results, we need to understand how to build an optimal training dataset. This study investigates the effects of quantity of high-quality training pixel samples as well as the number of spectral bands on the performance of a pixel-based parametric supervised classifier for liquefaction detection using both satellite and aerial imageries. The study compares aerial and satellite imageries for liquefaction classification as they have different radiometric resolution. The study also uses a building footprint mask as prior land use information to improve the accuracy of the classifier. The goal is to provide guidance on building training data for automated classification of liquefaction surface effects in terms of the optimum number of high-quality pixels, spectral bands, platform, and landcover masks considering performance accuracy. To this end, we use very high resolution (VHR) optical satellite imagery with eight spectral bands (coastal blue, blue, green, yellow, red, red-edge, near infrared 1, and near infrared 2) and VHR aerial imagery with four spectral bands (red, green, blue, and near infrared) to classify the liquefaction surface effects after the 22 February, 2011 Christchurch earthquake using a maximum likelihood supervised classifier. We evaluate classifier performance depending on the pixel size of datasets (50, 100, 500, 1000, 2000. 4000) and number of spectral bands: red, green, blue (RGB) versus RGB+NIR versus all eight spectral bands.
3. Methodology
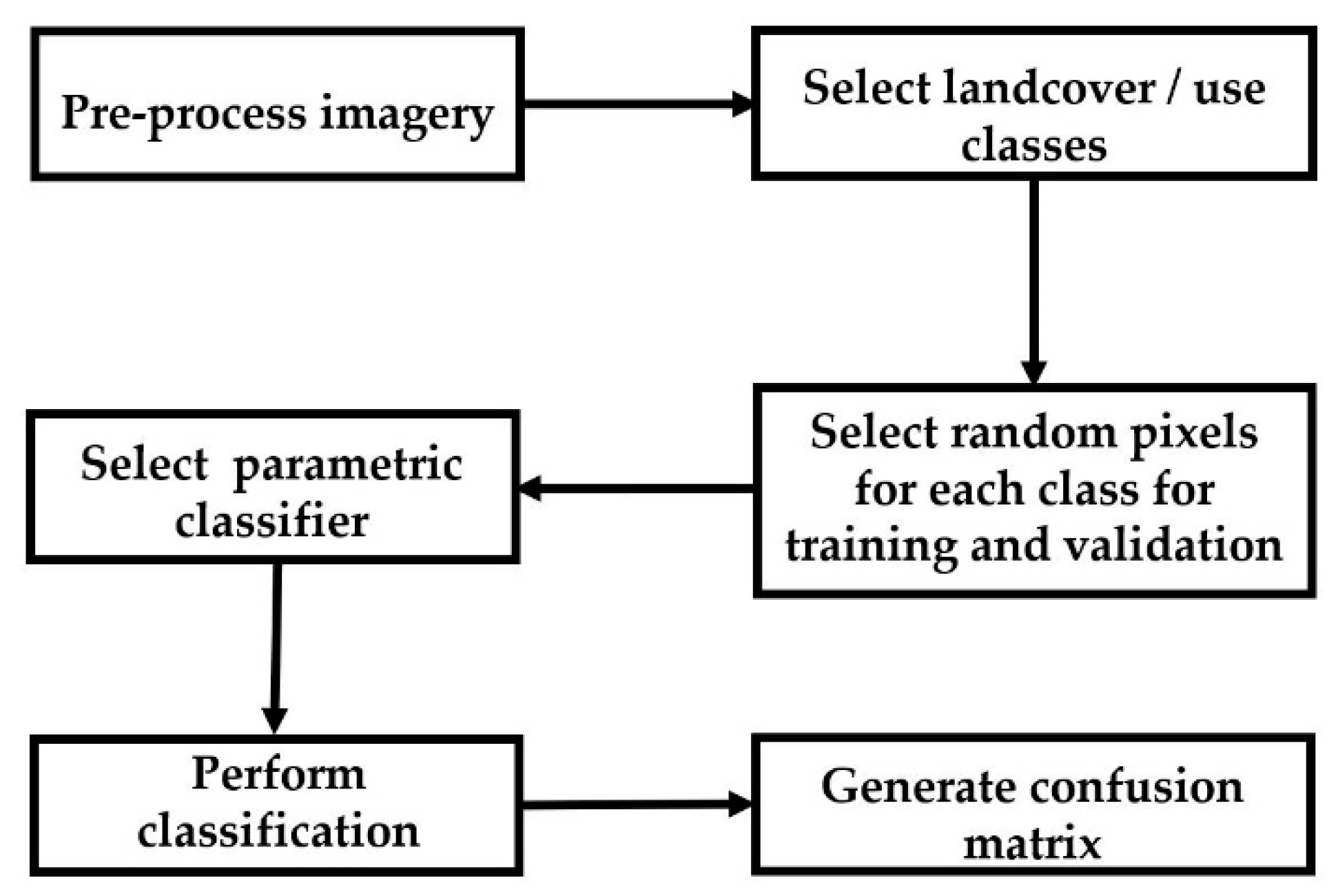
Imagery analysis and supervised classification include several steps. First the images should be preprocessed. Next, the landcover/use classes are defined. Once the landcover/use classes are defined, the image is sampled to generate the training and validation pixels within each class. Once the training and validation datasets are ready, a classifier is chosen. The classifier’s accuracies are usually evaluated using performance metrics. We used a single classifier across a variety of training datasets to compare performance.
Figure 2 presents a schematic workflow of these steps and each is described in following section. We have done all of the steps using ENVI 5 software.
3.1. Preprocessing
As part of the image preprocessing, the satellite imagery was pan-sharpened. In pan-sharpening, the panchromatic band (which has a higher spatial resolution than the other spectral bands) is fused with multi-spectral bands image (which have higher spectral resolution) to benefit from both high spatial and spectral resolutions. Therefore, the final satellite imagery used for classification has 8 multi-spectral bands with roughly 50 cm spatial and 11-bit radiometric resolution. Although the aerial imagery was collected at 15 cm, we chose to down sample to 50 cm using nearest neighbor method to reduce the computational time and to discard changes due to different spatial resolutions as this is not the goal of this study. Therefore, the final aerial imagery has 50 cm spatial and 8-bit radiometric resolutions.
3.2. Landcover/Use Classes
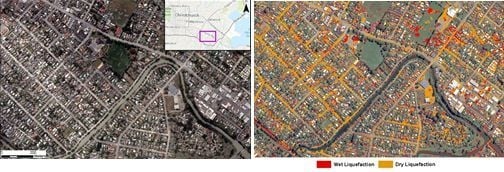
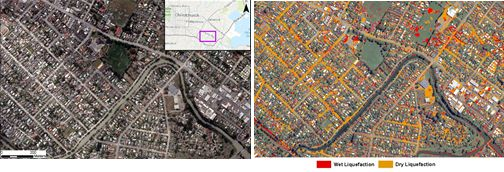
For classifying landcover/use, five classes are considered: water, vegetation, shadow, building roof, and asphalt as shown in
Figure 3. By comparing pre- and post-event imageries (
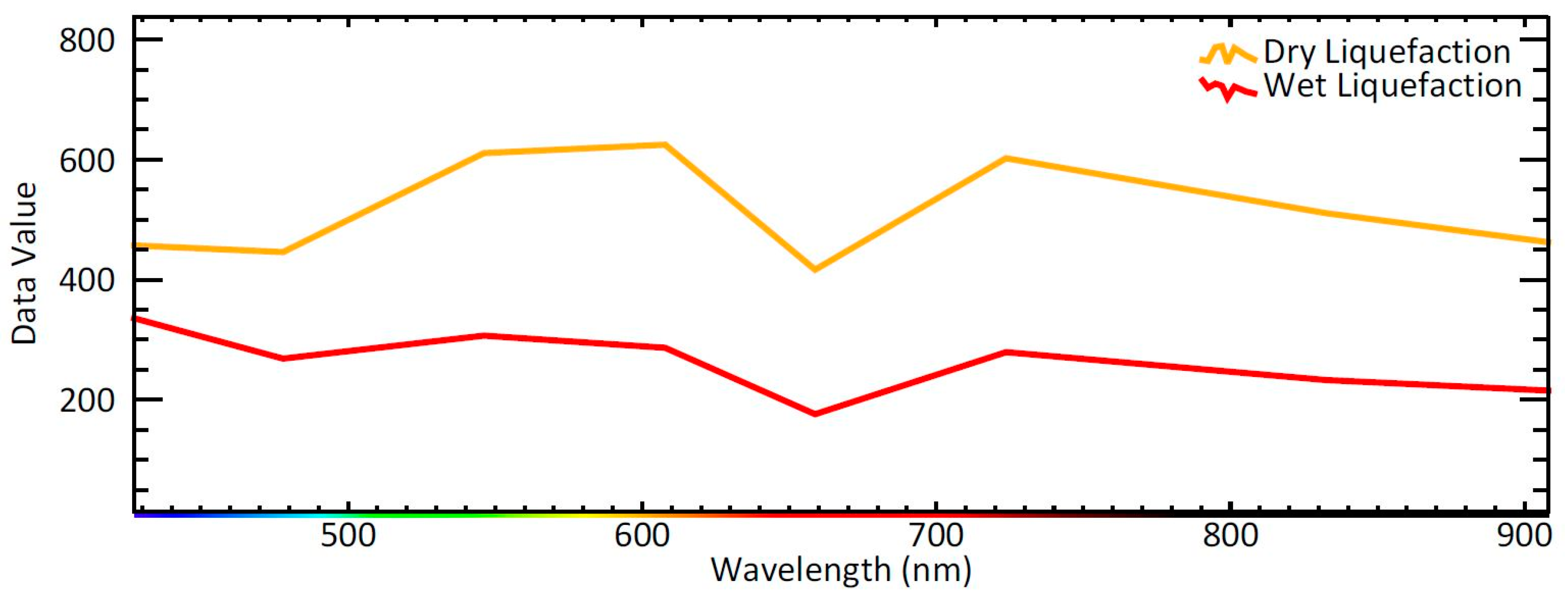
Figure 4), two classes of liquefaction are also identified: wet liquefaction and dry liquefaction. The reason for considering two classes is that the water contents of the liquefied materials are different, resulting in different spectral behavior as shown in
Figure 5.
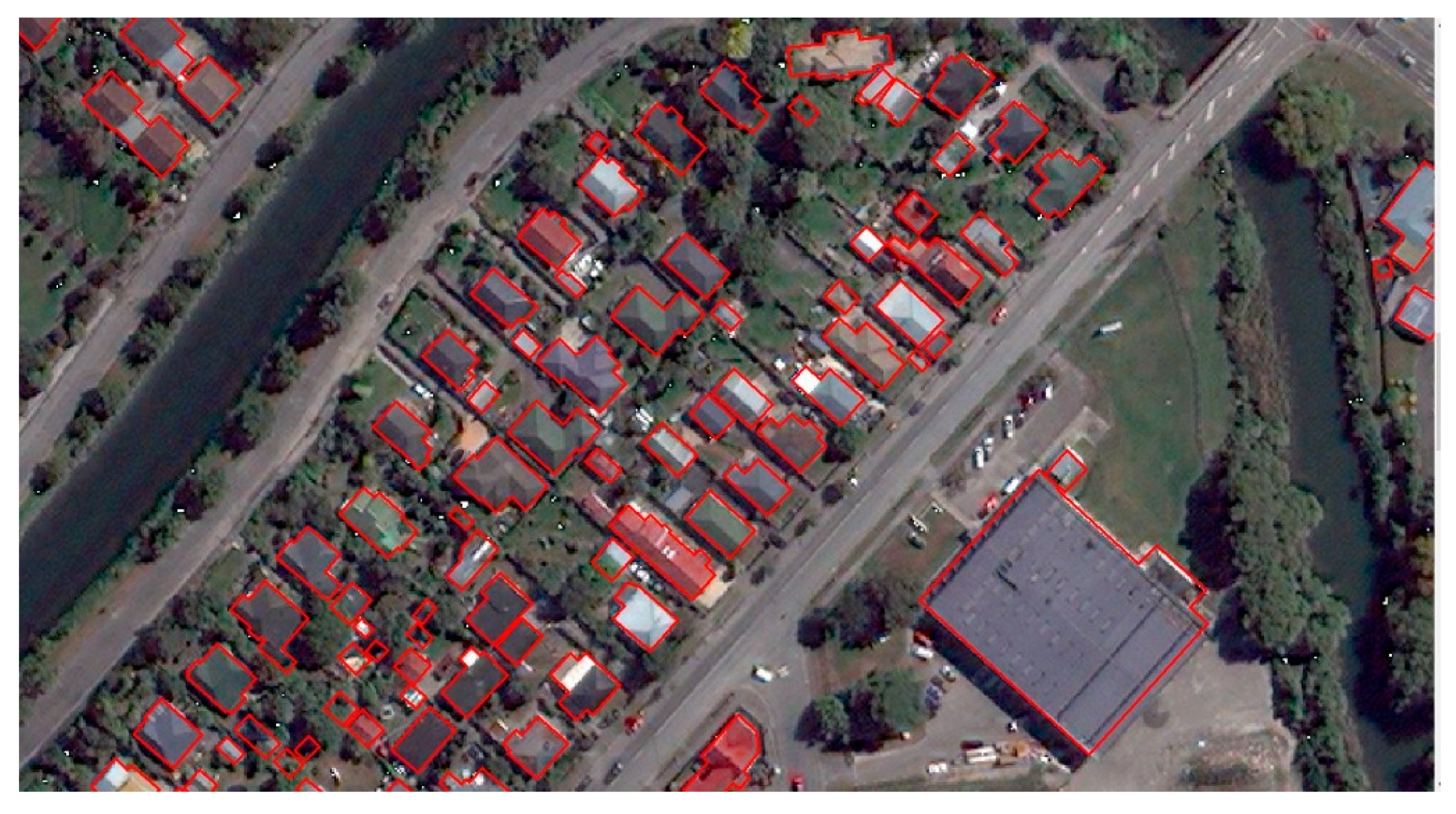
Figure 6a shows two types of liquefaction investigated. As the building roofs are highly variable in terms of colors and materials, they have a high spectral variation that makes it difficult to discriminate them from other classes in a pixel-wise classification framework. Therefore, we will introduce a geospatial layer of building footprints as a mask to improve the classifier’s performance.
3.3. Sampling
For preparing the training and validation datasets, first, polygons for each landcover/use class were drawn across the study area. The polygons for a given class are distributed across the whole image to guarantee that pixels in each class cover the full range of spectral information. The polygons have been visually drawn with extensive care and with near pixel resolution to make sure they represent the corresponding class on the ground and therefore, serve as ground truth for that class. To avoid the influence of boundary (edge effect) and mixed landcover/use pixels on the classification accuracy, polygons were drawn within the boundaries of each landcover/use class. Then, all polygons are pixelated at 50 cm resolution and 4000 pixels are randomly selected as ground truth for each class. This number represents the total available number of pixels for each landcover/use class for training and validation datasets.
Figure 6 shows the sampling process for liquefaction classes as an example. The number of pixels per class is equal to represent a balanced sampling approach; This will make sure that the classifier statistics are not biased toward any categories due to larger sample size. A biased classifier can assign more pixels to the majority class. However, in reality, data often exhibit class imbalance (e.g., vegetation: wet liquefaction), where some classes are represented by large number of pixels while other classes by a few [
17].
3.4. Maximum Likelihood Classifier
Maximum likelihood (ML) is a method of estimating the parameters of a statistical model given observations, by finding the parameter values that maximize the likelihood of making the observations given the parameters [
18]. maximum likelihood (ML) is a parametric classifier that assumes a normal spectral distribution for each landcover class. With the assumption that the distribution of a class sample is normal, a class can be characterized by the mean vector and the covariance matrix. The classifier works based on the probability that a pixel belongs to a specific class (prior probability among all classes is equal). ENVI calculates the likelihood of a pixel belongs to a specific class according to Equation (1) [
19] as follows:
where “
i” is the specific class, “
x” is the
n-dimensional data (where
n is the number of bands),
p(
wi) is the probability that class
wi occurs in the image and is assumed the same for all classes, |∑
i| is the determinant of the covariance matrix of the data in class
wi,
is the inverse matrix and finally
mi is the mean vector.
As the ML classifier accounts for the variability of classes by using the mean vector and covariance matrix, it demands a sufficient number of training pixels to precisely calculate the moments and covariance [
20]. A set of high quality training samples will provide an accurate estimate of the mean vector and the covariance matrix. This is achieved when the training samples only include the landcover class (minimum noise in the data) and the population of training samples are sufficient to sample the full spectral distribution observed in the landcover class. When the training samples are not high quality (not representing spectral variation for a class) or limited in number, the ML classifier will perform poorly due to inaccurate calculation of moments and covariance. The ML classifier is among the most popular and common classifiers used for satellite imagery classification due to the well-founded theory behind it and its feasibility in practice [
20].
3.5. Classification Approach and Accuracy Measurements
The classification accuracy is evaluated across all different datasets and spectral content for both satellite and aerial imageries. For training and validation datasets, samples for each class are increased from 50 to 100, 500, 2000, and 4000 to evaluate classifier performance across different sample sizes. 80% of the samples are allocated for training and the remaining 20% are for validation using a 5-fold cross-validation technique. Five-fold cross validation is an iterative process in which the complete dataset is first split into five subsets of equal size; then in each iteration, one subset is withheld and the maximum likelihood classifier is fit to the other four subsets (training set) using the chosen spectral bands. The performance measures are calculated on the held-out subset (validation). This is repeated five times so that each subset is held out for validation exactly once. The validation dataset is always independent from the training dataset to avoid any possible biases. The effect of increasing the number of spectral bands (from 3 to 4, and 8 in satellite and from 3 to 4 in aerial imagery) across each sample size has also been investigated. Note that by stating different number of spectral bands, the authors mean using full spectrum for 8 bands, red green blue Near-Infrared channels for 4 bands, and red green blue channels for 3 bands. Therefore, there are overall 15 scenarios for the satellite imagery and 10 scenarios for aerial imagery.
As explained previously, for measuring the accuracy of the classifier in each case, the training data is used to train the classifier and then a confusion matrix is generated for that classifier against the validation data. A confusion matrix is a table that summarizes the performance of a classifier by presenting the number of ground truth pixels for each class and how they have been classified by the classifier. There are three important accuracy measurements that can be calculated from a confusion matrix: 1—overall accuracy, 2—producer’s accuracy, and 3—user’s accuracy. Overall accuracy is calculated as the ratio of the total number of correctly classified pixels to the total number of the test pixels. The overall accuracy is an average value for the whole classification method and does not reveal the performance of the method for each class. Producer’s and user’s accuracies are defined for each of the classes. The producer’s accuracy corresponds to error of omission (exclusion) and shows how many of the pixels on the classified image are labeled correctly for a given class in the reference data. Producer’s accuracy is calculated as:
User’s accuracy corresponds to the error of commission (inclusion) and shows how many pixels on classified image are correctly classified. User’s accuracy is calculated as:
In addition, the classified map is compared with ground truth to enable the readers to visually evaluate the classification performance as well.
5. Conclusions
In this study, satellite and aerial imageries as remote sensing data have been used to detect the liquefaction on the ground after the 21 February, 2011 Christchurch earthquake. To this end, a maximum likelihood (ML) classifier was used to perform a pixel-based 5-fold cross-validation classification across a variety of training datasets and spectral bands. The objectives of the study were to find the effect of number of training pixels and the choice of spectral bands across VHR satellite and aerial imageries on the final accuracy of the classifier. Furthermore, building footprints, as a priory GIS knowledge, was utilized to increase the accuracy and reliability of the classified image. The number of training and validating pixels were increased from 50 to 100, 500, 2000, and 4000. For satellite imagery, the classification was performed on eight (coastal blue, blue, green, yellow, red, red Edge, NIR1 and 2), four (RGB + NIR), and three (RGB) spectral bands and for aerial imagery on four (RGB + NIR) and three (RGB) spectral bands. To identify liquefaction surface effects, we selected two different landcover modes, one for wet liquefaction and one for dry liquefaction because their spectral characteristics were different.
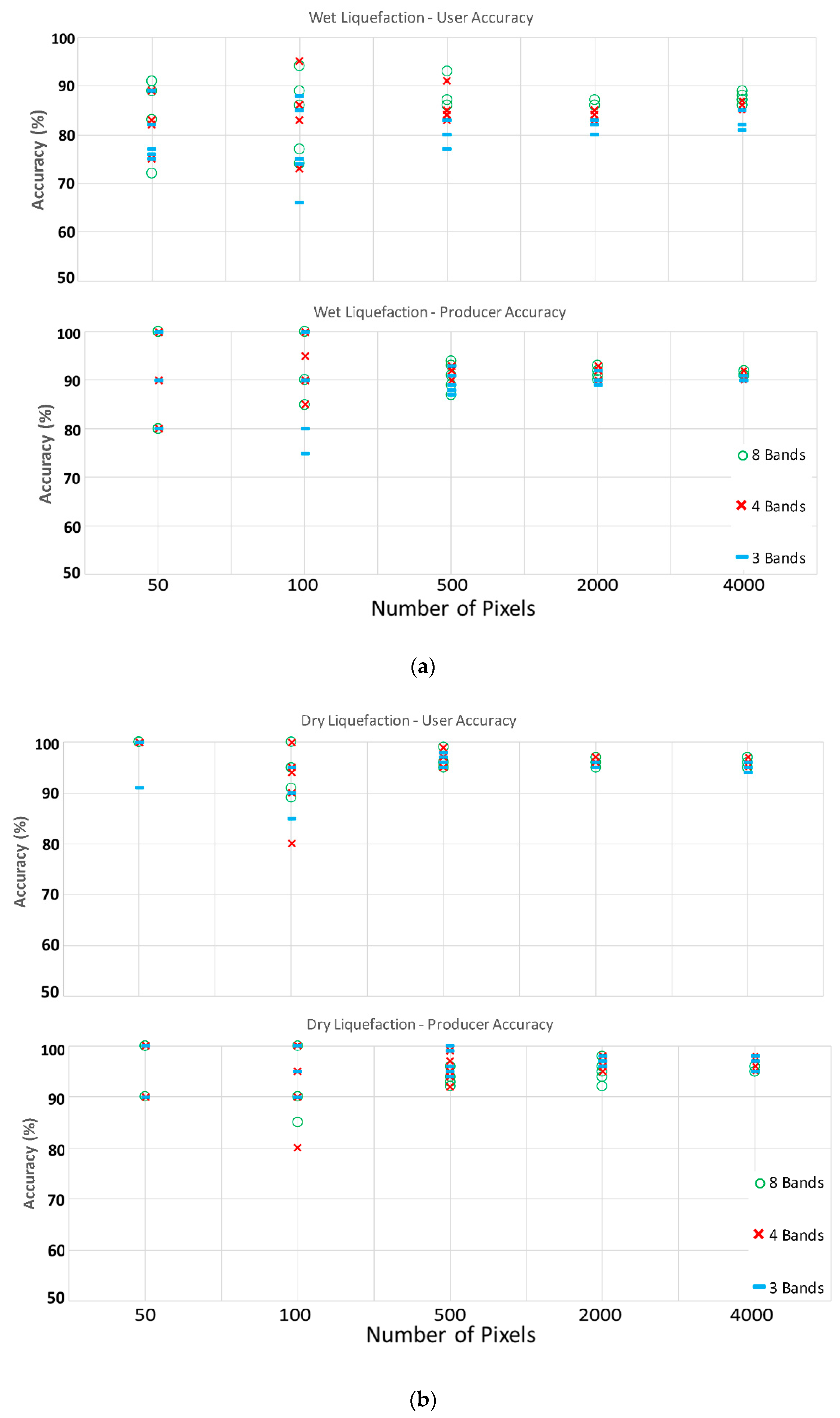
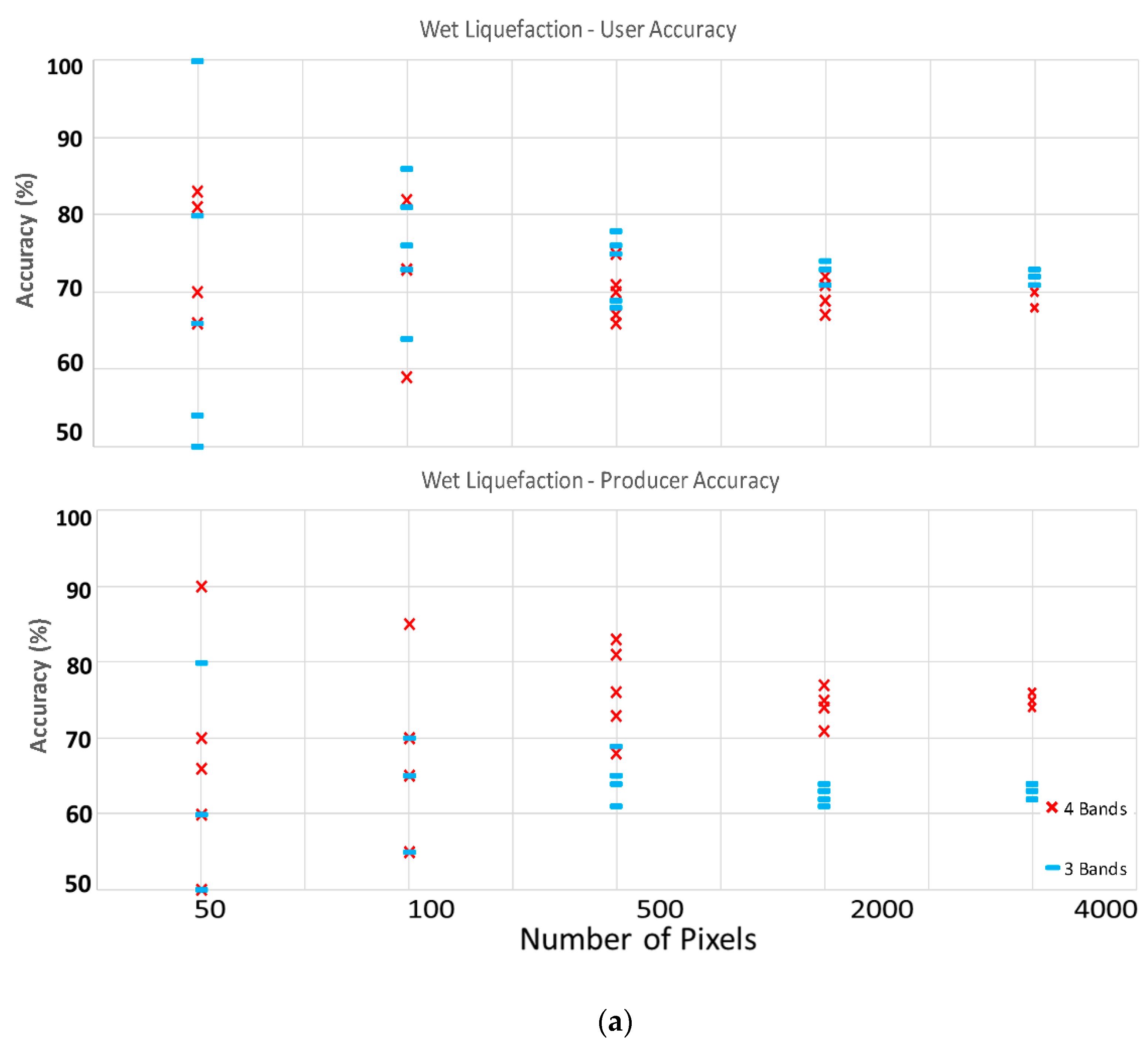
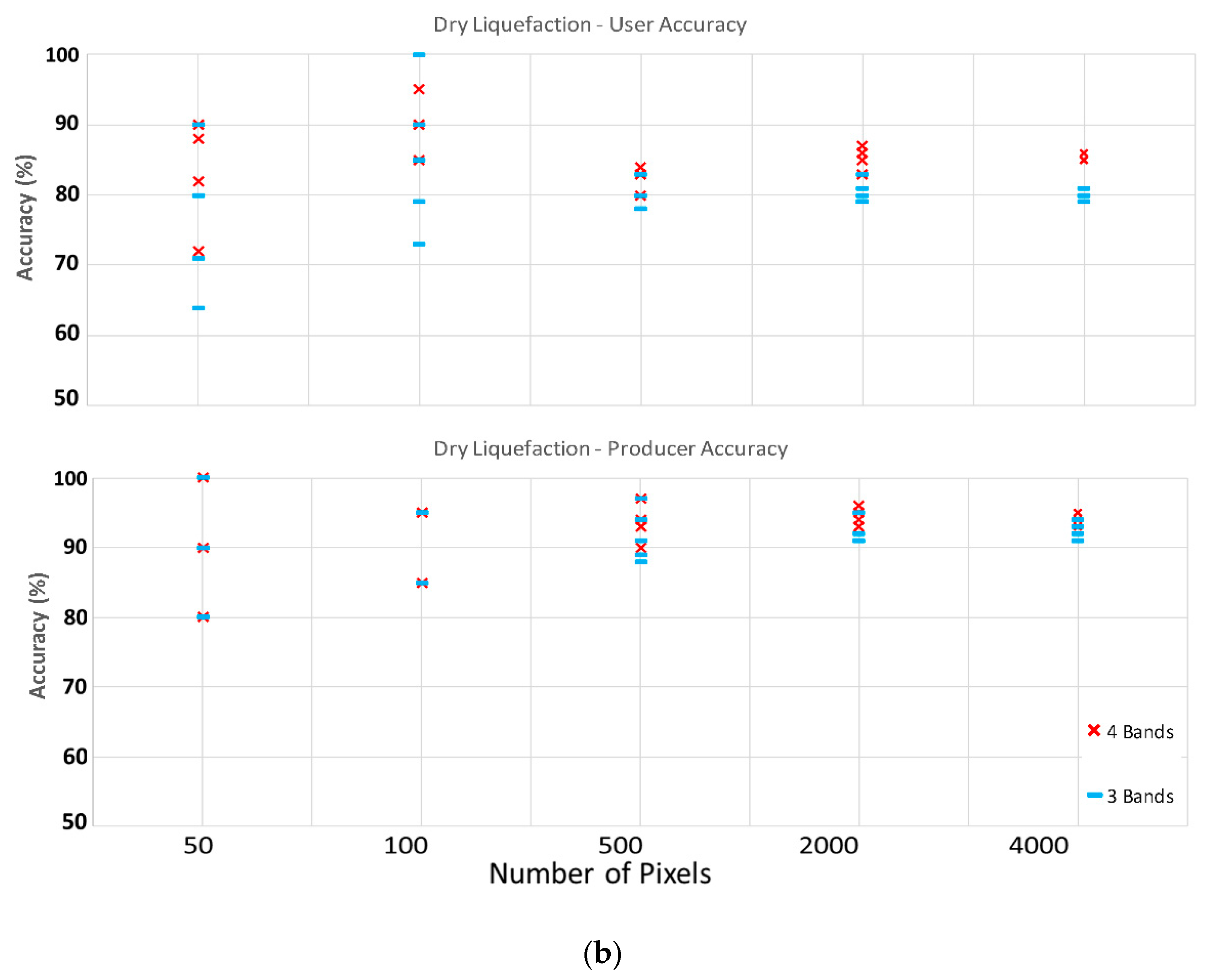
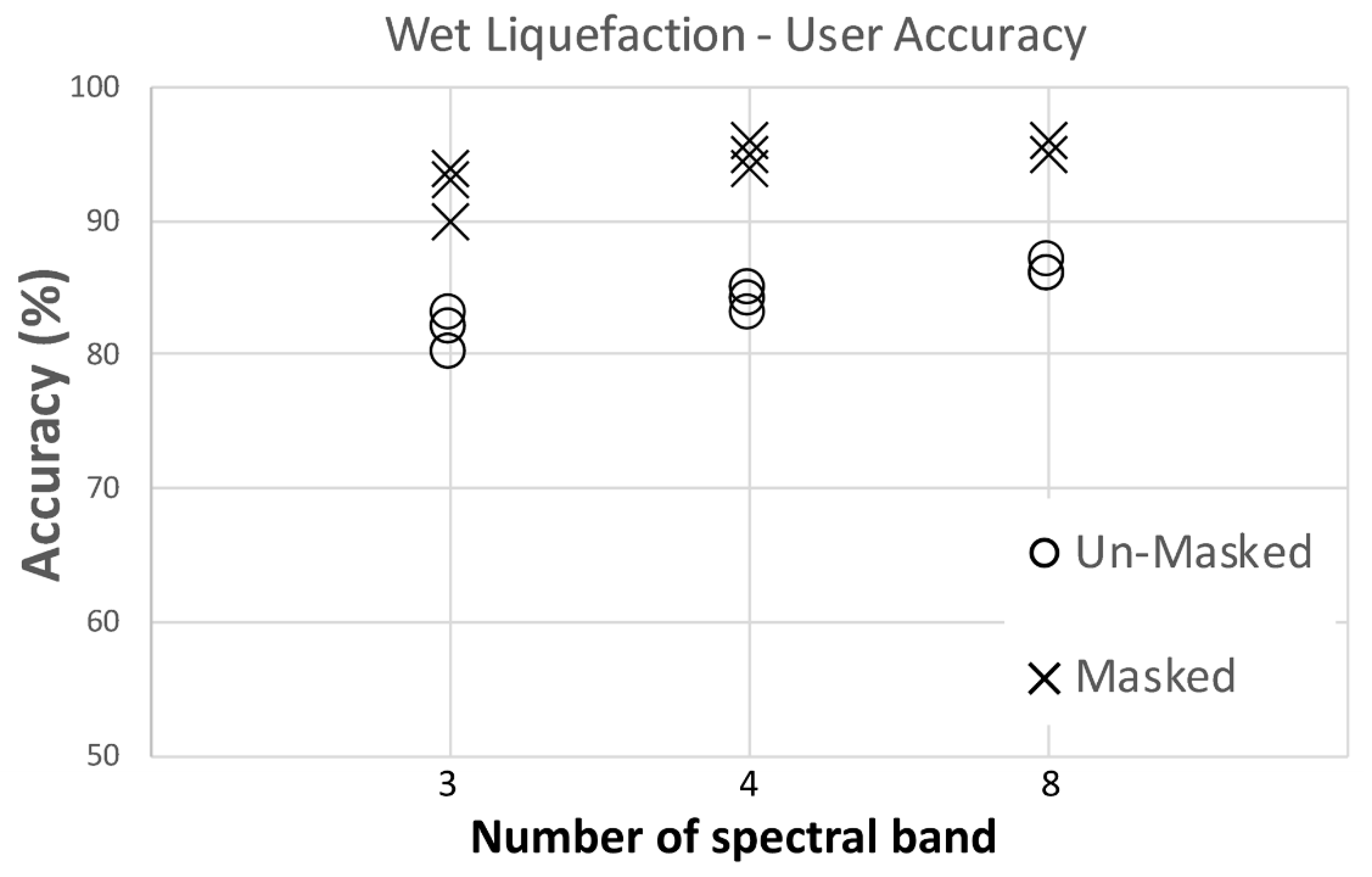
Overall, 15 and 10 scenarios for satellite and aerial imageries were investigated. It was observed that increasing the number of training pixels will decrease the variation between each fold of individual scenarios; in other words, by increasing the number of training pixels, the reliability and repeatability of the classifier increases. The reduction in folds’ variation is not meaningful when moving from 2000 to 4000 pixels dataset (look at
Table 2); therefore, we recommend using 2000 training and validation pixels for the classification of liquefaction on aerial and satellite imageries. When considering the choice of spectral bands, it was observed that increasing from four (RGB+NIR) spectral bands to the full available spectrum of eight bands in satellite imagery does not considerably affect the classifier performance in detecting the liquefied materials on the ground specially the dry one. However, when removing the NIR band from the analysis in both satellite and aerial imageries (only uses RGB), a reduction in accuracy specially for wet liquefaction will occur. Therefore, using 2000 pixels for training and validation and utilizing the NIR band as well as visible bands (RGB) are the most time and cost-effective combination for liquefaction classification. Overall, the classifier can detect dry liquefied materials with higher accuracies in compare to wet liquefied materials. The satellite imagery has higher accuracies in detecting liquefied materials on the ground than the aerial imagery. Note that training and validation pixels locations are different for each imagery.
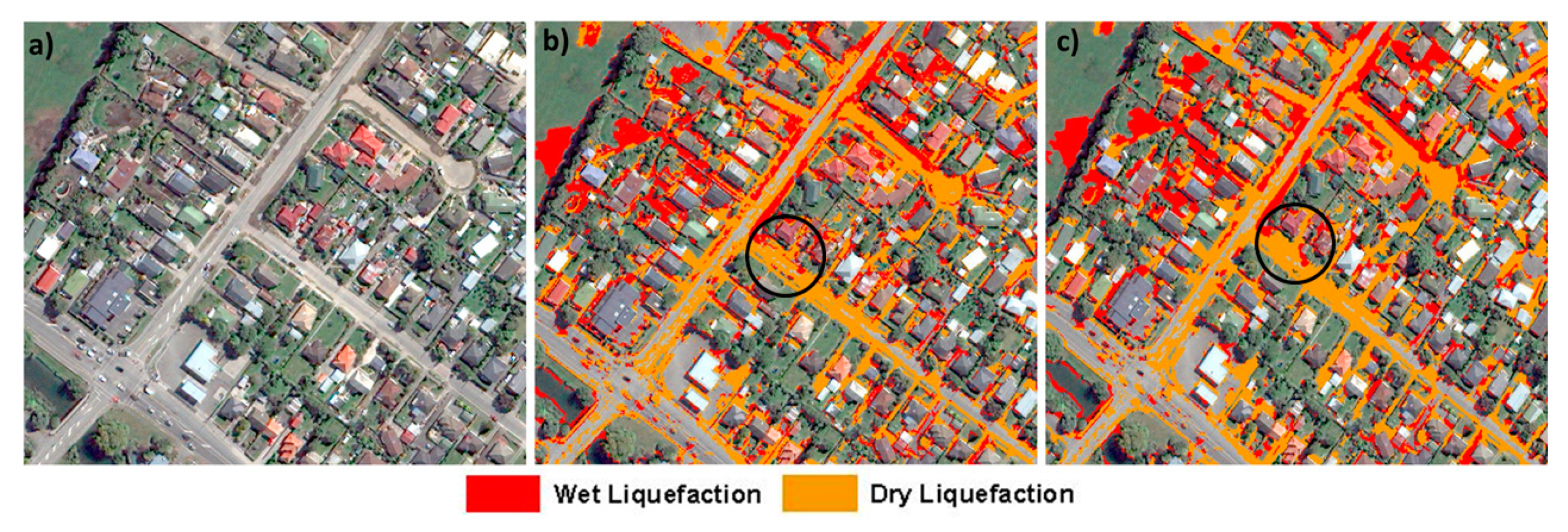
To improve the accuracy of wet liquefaction detection, a geospatial layer of building footprints was used to exclude the roofs from automatic classification. Building roofs have very broad spectral distribution due to the variety of materials and colors; therefore, the spectral data distribution for building roofs overlap with other landcover/use on the ground. After removing the building footprints from classification, the user accuracy of wet liquefaction was increased by 10% in all scenarios using the satellite imagery.
The final recommended combination of imagery, spectral bands, and training pixels is to use satellite imagery with near-infrared, red, green, and blue channels and 2000 pixels for training and validation. We also recommend using the building footprint to mask out building roofs. The producer’s and user’s accuracies for this case are both 98% for dry liquefaction and 92% and 95% for wet liquefaction, respectively. Using this final combination, the classified map of the study area not only has high accuracy but also has a good visual correlation between the number of liquefied pixels on the roads detected by the classifier and the quantity of liquefied materials on the road recorded by the reconnaissance team after the event.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}