1. Introduction
Land-cover classification of high resolution data is an intensively investigated area of research in remote sensing [
1,
2,
3]. The classification often assumes applications to top-view images (e.g., orthographic satellite images and orthophotos of photogrammetric products) or information of other modalities (e.g., digital surface models (DSMs)) [
4,
5,
6]. Spectral and spatial features are two basic types of image features which separately record the optical reflections at different wavelengths and the texture information in a continued spatial domain. Since different objects have different reflection characteristics corresponding to different spectral bands, many indexes have proposed as classification clues, such as normalized difference vegetation index (NDVI) [
7], normalized difference water index (NDWI) [
8] and normalized differenced snow index (NDSI_snow) [
9]. Based on these indexes, there are many variations, including near surface moisture index (NSMI), which models the relative surface snow moisture [
10], and normalized difference soil index (NDSI_soil) [
11]. For hyper-spectral imagery which can contain hundreds of bands, principal component analysis (PCA) and independent component analysis (ICA) are used to reduce the dimension of spectral characteristics and extract the features [
12,
13]. In some scenarios, spectral information is inadequate, especially for the high-resolution images [
14,
15]. Therefore, in most current research, the spectral features are usually complemented by spatial features, such as wavelet textures [
16], the pixel shape index [
17] and morphological filters and profiles [
18,
19]. In addition, the object-based image analyzes (OBIA) for land-cover classification has attracted significant attention [
4]. The OBIA methods usually group the pixels into different segments first and then perform the classification at the segment-level instead of the pixel-level. The segment-level classification can reduce the local distributed spectral variation, generalize the spectral information and offer useful shape-related spatial descriptions [
20].
The idea of adding height information from the digital surface model (DSM) for remote sensing interpretation has recently been popularized by the advanced development of photogrammetric techniques, and light detection and ranging (LiDAR) data. With a dense matching algorithm, the DSM and orthophoto can be generated from photogrammetric oblique images. By combining the orthophoto and DSM, many methods involving 3D space features have been proposed and improved the performance of land classification [
21], change detection [
22] and individual tree detection [
23]. The height information can be directly used as a classification feature or be further processed to hierarchy features, such as the dual morphological top-hat profile (DMTHP) proposed in [
24]. Compared to the imagery derived elevation, LiDAR data can offer highly precise 3D information of more areas where the dense matching does not work. In [
3], the data from a multi-spectral airborne laser scanner has been analyzed for the land-cover classification showing great advantages in illustration conditions. Also, in [
25], they introduced a multi-wavelength LiDAR that can acquire both topographic and hydro-graphic information to improve the accuracy of land-cover classification.
Although the top-view based land-cover classification has been well practiced, it is known that the high intra-class variability and inter-class similarity constitute the major challenges in such a task. Difficult surfaces include concrete roads; building roofs; and occasionally, green roofs compared to grasses. The use of elevation data (such as DSM) was concluded to be effective in addressing such ambiguities [
24], yet the height information alone still has limitations in complex scenarios where off-terrain objects are difficult to extract, and scenarios where more demanding classification tasks are needed, such as classifying types of building roofs.
With the development of multi-camera/head imaging systems, such as Microsoft/UltraCam Osprey, Hexagon/Leica RCD30 and Track’Air MIDAS, many remote sensing platforms can simultaneously capture the top-view and side-view images that toward different directions. This oblique imagery is widely used for photogrammetric 3D reconstruction, especially for building modelling, which not only offers façade textures but also greatly helps to identify the buildings, as has been proven in several studies [
26,
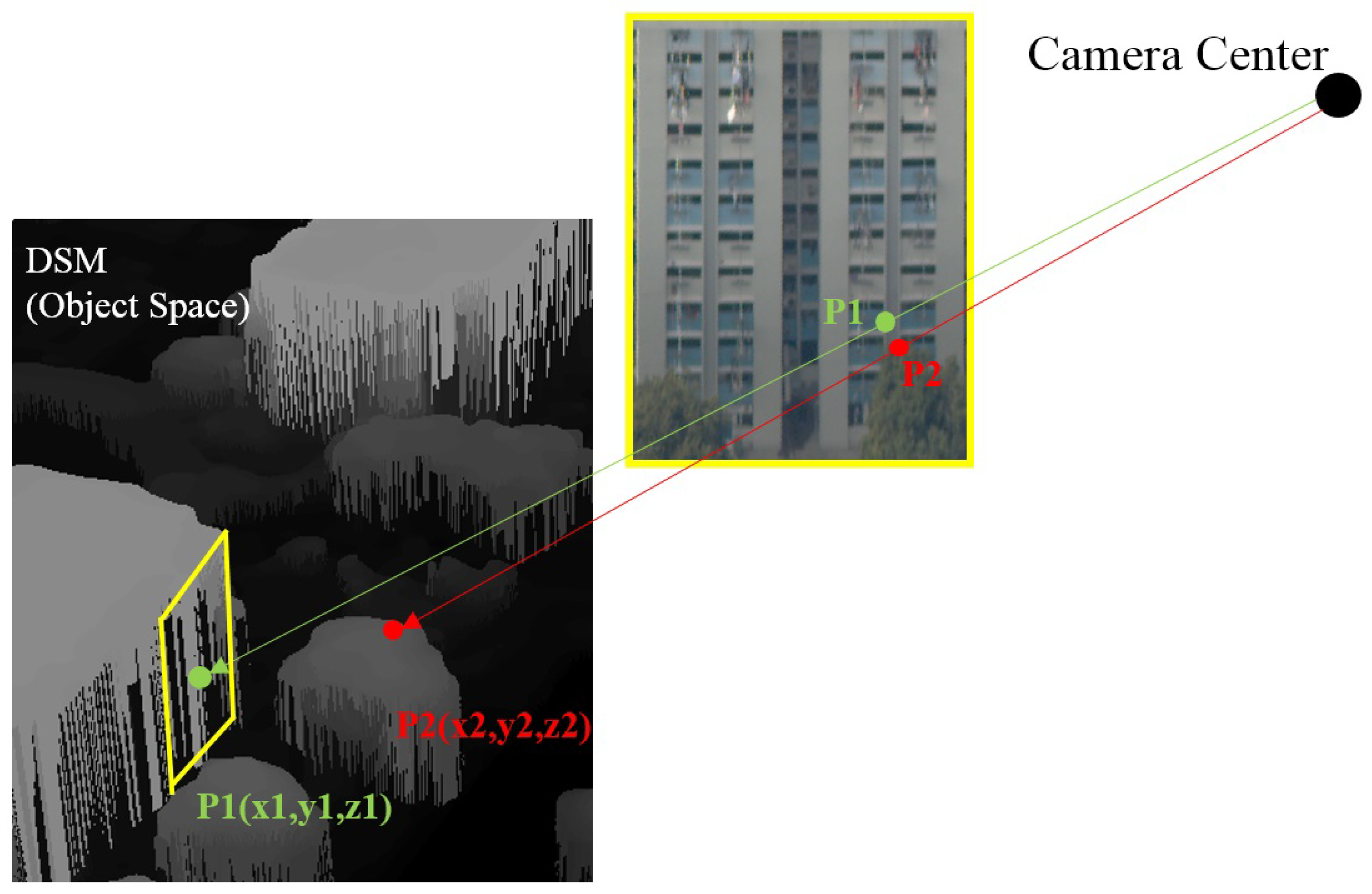
27]. Although being widely used in 3D reconstruction and texture mapping, such oblique information is not well utilized in classification tasks to distinguish confusing object classes. For example,
Figure 1 demonstrates how oblique images are able to support the classification of above-ground objects with confusing top-views, as the roofs are full of greenery. In addition to buildings, the side-view is also useful for object detection, such as in [
28], wherein the unmanned aerial vehicle (UAV) oblique images were used for tree detection. However, in all these studies, the side-view from oblique images was not effectively utilized in a general land-cover classification task.
One oblique aerial imagery based urban object classification work has been introduced in [
29], which seems very close to our study. In their work, the ground objects/areas, including building façades are classified and segmented directly in the oblique images with gradient and height features. However, the classification map on a perspective oblique image is not typically useful from a mapping point of view, and associating the façade features at the segment level with top-view image segments can be challenging. Therefore, we developed means to address this challenge to incorporate the side-view information in a typical top-view based land-cover classification framework. However, to find and attach the vertical side-views to their hosts in the overview of orthographic images, could be a challenging problem. There is no direct connection between a region in the orthographic image and its possible side textures in most remote sensing data, even we schematically linked them in
Figure 1.
Oblique images are not purposed for cartographic mapping, but their mapping products, such as orthophoto and DSM have been extensively analyzed for the land-cover classification [
24]. By observing the geometric constraints between the oblique images and the orthophoto and DSM, finally, we found a way to incorporate the side-view information for land-cover classification. Firstly, from the DSM, the above-ground objects can be segmented out as individual regions that could have side-view information. Then, for each above-ground region, a virtual polygon boundary would be calculated to map the side-view textures in the oblique images via a perspective transformation. Finally, from these textures, the side-view information of each above-ground segment can be extracted and incorporated in the land-cover classification with their top-view features.
Following this idea, in this study, we aimed to leverage the extra side-view information to improve the land-cover classification with the oblique imagery. In general, the main contributions of this work include: (1) to the authors’ best knowledge, this is the first work which proposes using the side-view textures to support the top-view based land-cover classification; (2) a feasible framework is proposed to extract the side-view features that can be precisely incorporated into top-view segments and can improve the classification accuracy, especially when the training samples are very limited.
2. Materials and Methods
To incorporate side-view information in land-cover classification, firstly, we segment the above-ground objects with which the textures can be mapped to the side-views. Then, based on the segmentation boundaries, their side-view textures are mapped and selected from oblique images via a perspective transformation. Finally, side-view information, including color and texture features, are extracted for each above-ground segment.
2.1. Above-Ground Object Segmentation
Above-ground object segmentation is a complicated problem which has been studied for years [
30,
31], but still does not have a general solution. To simplify this problem, we assume all above-ground objects have flat roofs; for example, if a building has two conjoint parts with different heights, then the two parts are treated as two objects. With this assumption we are able to efficiently segment the above-ground objects at the individual level with a simple height clustering algorithm, in which the connected pixels that share similar heights are grouped as one above-ground object. To implement, firstly, we use the DSM to calculate a gradient map which can approximate the above-ground height with respect to surrounding areas. Then, from the highest to the lowest, the connected pixels with height differences within 1 m are sequentially grouped as individual segments. Finally, the segments which have 2.5 m average above-surroundings heights are classified as above-ground objects, as shown in
Figure 2.
It is possible that the resulting clusters may contain errors, such as incomplete segments and incorrect above-ground heights, which are mainly in multi-layer objects (e.g., the towers on the roof and the gullies on the ground). To fix these errors, we post-process these segments by simply using neighboring merge technique.
2.2. Side-View Texture Cropping and Selection
Similar to 3D building façade texture mapping [
32], the vertical faces of above-ground objects can be mapped and cropped from oblique images. However, unlike buildings which often have well-defined plane/multi-plane structures in their façades, many above-ground objects, for example, trees, do not possess a specified vertical face. To solve this problem, we convert the boundaries of above-ground segments into polygons with the Douglas–Peucker algorithm [
33], thereby creating pseudo vertical faces by cascading the top edges of each object to the ground, as shown in
Figure 3, image (a) and (b). In the experiment, only the three longest lines are used to extract side-view textures. As illustrated in
Figure 3, image (b), the vertical face is defined as a rectangle with four space points
. The upper points
are the two ending points of a polygon line with the object height, while the lower points
are at the same positions but with ground height. The georeferenced 3D coordinates
of the four points in the object space can be acquired from the orthophoto and DSM; thus, their corresponding oblique image coordinates can be calculated via a perspective transformation:
where
are the 2D homogeneous coordinates in the oblique image with s as a scale factor, and
is a perspective transform matrix which contains the intrinsic and extrinsic camera parameters that are calibrated in the photogrammetric 3D processing. The reader can find more details about the photogrammetry in [
34]. As illustrated in
Figure 3, image (c) and (d), after this perspective transform, the four points can define a region of the side-view in many multi-view oblique image. To get better side-views for the later feature extractions, we rectify the textures to the front view through a homography transform that maps the points in one image to the corresponding points in the other image (e.g., mapping
,
,
and
to the top-left, top-right, bottom-left and bottom right corner of a rectangle image, separately), as shown in
Figure 3e. The readers can find more details about homography in [
34].
There is in general more than one oblique image that can capture the side-view of an object. To select the best one, we consider three factors: (1)
, the quality of the angle between the normal of the face plane and the camera imaging plane, (2)
, the quality of the angle between the face normal and the line through camera and face centers, (3)
, the proportion of the observable part. Based on these factors, the best side-view is selected by a texture quality measurement:
where the
measures the quality of side-view f, while the
,
and
are the weights of different quality factors. In the experiment,
,
and
are set as 0.25, 0.25 and 0.5, respectively, as we found the visibility is more important. While the first two factors can be easily calculated, the visibility is complicated to measure due to the fact that occlusions often exist in urban areas. Inspired by a Z-buffer based occlusion detection [
29], we examine the visibility with a distance measurement, as illustrated in
Figure 4.
For each side-view region in the multi-view oblique images, we can simulate emitting rays from the camera center through the side-view texture and reach the DSM in the object space. If a pixel is not part of the plane (e.g., due to occlusion), as with
in
Figure 4, we determine that as an invalid pixel for feature extraction. The resulting masked image is shown in
Figure 3e.
2.3. Side-View Feature Description
To capture the side-view features, we compute the average color and the standard deviation in R, G, B channels. The histogram of oriented gradients (HOG) [
35] and Haar-like features [
36,
37] are also adopted for the texture description.
HOG descriptor counts occurrences of the gradient orientation in different localized portions of an image with a histogram. By normalizing and concatenating all local HOGs, such as different parts of a human body, we are able to effectively describe object boundaries. In our case, the entire side-view texture is treated as a single patch because there is no dominant or specified distribution. On the other hand, considering that the elements (e.g., windows) in the building façades usually have a regular and repetitive layout, we adopt the rectangle Haar-like features to the side-view images, as has been shown to be highly descriptive. The rectangle Haar-like feature is defined as the difference of the sums of the pixel intensities inside different rectangles. For the side-view textures, a triple-rectangle pattern Haar-like structure (e.g., black-white-black) is designed and used at the vertical and horizontal direction, separately, at 3 different sizes (total 6 feature vectors). Finally, from pixels to blocks, the color, gradient and Haar-like features are combined to describe the side-view for each above-ground segment.
2.4. Classification with Side-View and Top-View
Following the idea of object-based image classification, we first segment the top-view image into small segments as basic classification units. Then, for each segment, top-view features are directly extracted from orthophoto and DSM, while the side-view features are assigned based on the overlaps between the segments and above-ground objects. Finally, with the top-view and side-view features, a random forest classifier is trained to perform the classification.
2.4.1. Image Segmentation with Superpixels
Several image segmentation algorithms have been used for the remote sensing data, such as mean-shift [
20,
22] and superpixel segmentation [
38,
39]. Without valuing the shape as a main rule, the mean-shift algorithm can generate well-articulated segments, but the size of segments may vary and the result is sensitive to the algorithm parameters, leading to unpredictable segments. The superpixel algorithm generates compact segments with regular shapes and scales, which are more robust and suitable to associate with the side-view features without unexpected mistakes. Hence, in this study, we generated the SLIC superpixel segments [
40] and assigned each segment the side-view features based on its overlap with the above-ground objects, as illustrated in
Figure 5. On the other hand, for superpixels which are not in the above-ground areas, their side-view features will be set as zeros.
2.4.2. Classification Workflow
Side-view serves as a piece of complementary information and can be incorporated in any land-cover classification framework with top-view features. Hence, in this work, we directly adopted the framework introduced in [
24] which uses a dual morphological top-hat profile (DMTHP) to extract the top-view features and the random forest to classify the segments. More specifically, the top-view features include the DMTHP features extracted from the DSM and brightness and darkness orthophoto images produced by the principal component analysis (PCA) [
41]. The DMTHP extracts the spatial features with class-dependent sizes which are adaptively estimated by the training data. This mechanism avoids exhaustive morphology computation of a set of sizes with regular intervals and greatly reduces the dimensions of the feature space. On the other hand, the random forest classifier is widely used for hierarchical feature classifications [
42]. The voting strategy of multiple decision trees and the hierarchical examination of the feature elements make this method have high accuracy. The entire classification workflow can be found in
Figure 6, and more details about the top-view feature extraction and the random forest classifier can be discovered in [
24].
3. Results
In the experiment, 306 aerial images were used as the study data, including 73 top-view, 64 forward-view, 47 backward-view, 62 left-view and 60 right-view images taken by a 5-head Leica RCD30 airborne camera. The size of all images is 10,336 × 7788 pixels; the four oblique cameras were mounted with a tilt angle of 35 degrees (see
Table 1). These images were calibrated by a professional photogrammetric software called Pix4DMapper software (Pix4D SA, Switzerland) which was also used to produce the orthophoto and DSM. The georeferencing accuracy, computed from 9 ground control points, is 2.9 cm. The ground sampling distance (GSD) of the orthophoto and DSM is 7.8 cm. The study area centers around the campus of the National University of Singapore (NUS), where the terrain contains a hilly ridge with tall and low buildings, dense vegetation, roads and manufacturing structures, as illustrated in
Figure 7. To analyze the improvement using our method, six sites that each contain all the types with different scenarios were selected. As shown in
Figure 7, site A is a complex campus area which includes dormitories, dining halls, study rooms and multi-function buildings. Site B and Site E are residential areas with different types of residential buildings. Site C is a secondary school containing challenging scenarios: the education buildings and a playground are on the roof. Site D is a parking site. Site F, with a complicated land-cover classes, is a much larger area which is used to test the generalization capability of the method.
In this study, the image was classified into (1) ground classes, including road, bare ground and impervious surfaces; (2) grassland; (3) trees; (4) rain-shed including pedestrian overpasses; and (5) building. Other objects, such as cars, rivers/pools and lower vegetation, were not considered. The reference masks of the land-cover were manually drawn by an operator who visually identified the objects in the orthophoto, DSM and oblique images. For each test site (except site F), around 2% of the labeled superpixel segments were used to train the classifier, and more statistics about the experimental setup are listed in
Table 2. For the random forest classifier [
43], 500 decision trees were used for training, while the number of variables for classification was set as the square root of the feature dimension, which was 35 in the experiment.
3.1. Validation of Above-Ground Object Segmentation
The above-ground object segmentation is an initial and critical step for the side-view information extraction. To validate the above-ground segments, we compared the segments with the reference labels of tree, rain-shed and building. The above-ground segmentation accuracy for the five test sites is shown in
Table 3. The evaluation metrics include the accuracy per-class, overall accuracy and commission error, each corresponding to the percentage of correctly identified above-ground pixels in the class, in total, and the miss-classified above-ground pixels, respectively.
As observed from
Table 3, most of the above-ground pixels were successfully segmented (92.7% overall accuracy), and only a few were misclassified (2.42% commission error). For class accuracy, most of the buildings were identified correctly, but with some fuzzy edges. This was mainly caused by the smoothing operation in the generation of DSM, and this operation also reduced the accuracy of the rain-shed, which is low and close to buildings. On the other hand, some pixels of trees were not identified mainly due to the complex structures, such as tree branches, generally not being reconstructed well in current 3D reconstruction approaches, as illustrated by rectangles in
Figure 8. In addition, different objects may be segmented as one single object if they are close and have similar heights. This kind of error may make objects have wrong side-views; for instance, the rain-shed would have the side-views of trees, as marked by the circles in
Figure 8. However, this error will not significantly impact the final classification, because the side-view is just a piece of complementary information; the top-view features still play an important role in the final classification.
3.2. Classification with Different Samples
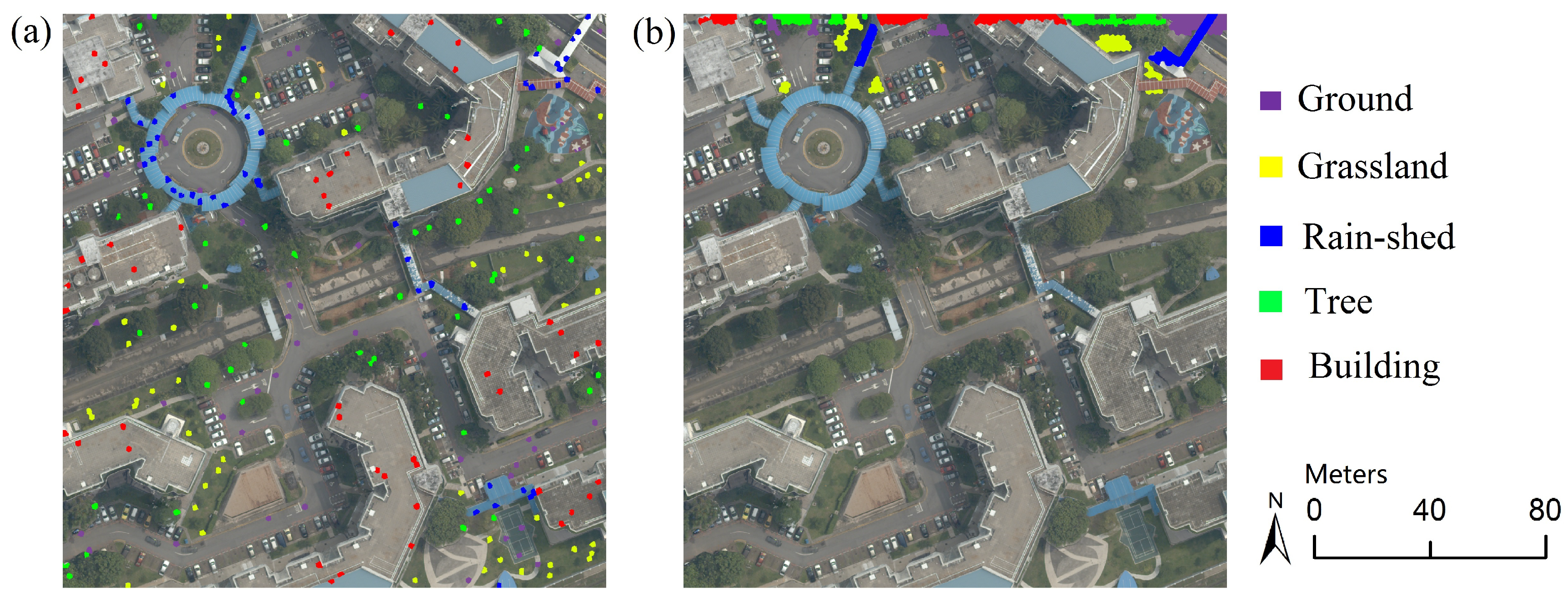
For supervised land-cover classification, the training samples are critical. In practice, depending on the distribution, there are two kinds of samples: (1) evenly collected samples over the entire test site, which we refer to as evenly distributed samples; (2) selectively collected samples covering part of the test site, which we refer to as non-evenly distributed samples. As illustrated in
Figure 9a, the evenly distributed samples can offer abundant intra/inter-class information, but they need a considerable amount of labor with scrutiny over the entire image. On the other hand, using non-evenly distributed samples can reduce the manual work and is more efficient at larger scales, but they may not sufficiently represent the data distribution. Considering that these two sample concepts are both very common in practice, we experimented with both of them in our tests.
Classification with Evenly Distributed Samples
The evenly distributed training samples of each class were evenly picked up from reference data with certain intervals. Following the training and prediction process, as described in
Section 2.4.2, we performed the classification with/without side-view features, and the results are shown in
Table 4 with user accuracy (calculated by taking the total number of correct classifications for a particular class and dividing it by the row total).
As we can observe from
Table 4, the results with side-view have higher overall accuracy and Kappa values (on average our method improved 1.1% and 1.5%, separately) which means the side-view information offers useful clues for the land-cover classification. The improvement seems to be limited, as the training samples supply the full capacity of the classifier that is difficult to be further improved. As proven by the experiment, the side-view can still improve the classification if we do not consider the ground objects (ground, grassland) which are not benefited by this extra information. The average per-class accuracy improvement is 1.7%.
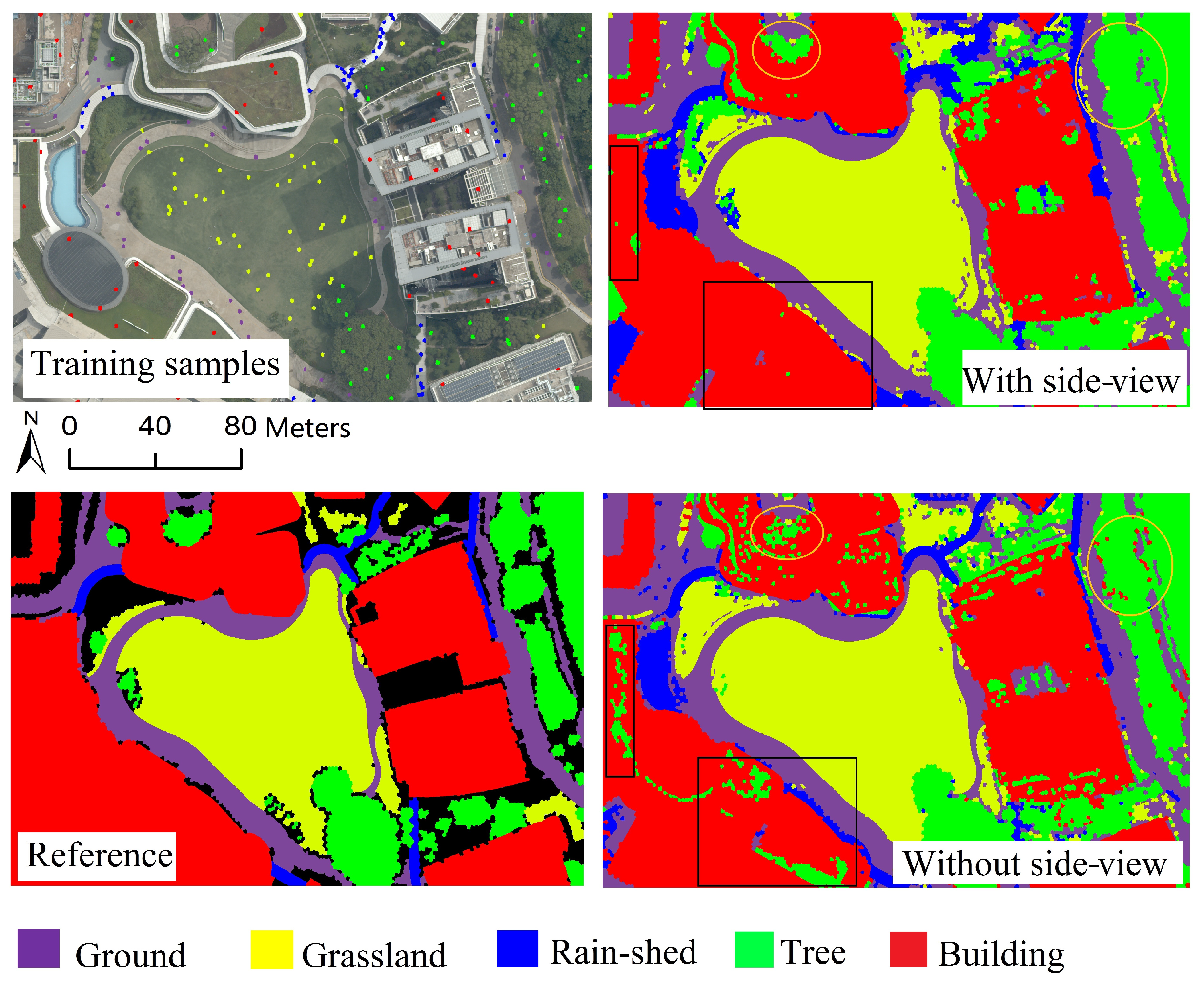
As shown from
Figure 10, the classification without side-view incorrectly classified some trees into buildings (marked by circles). This misclassification is mainly caused by the fact that many vegetation-covered roofs would make their top-view features have high similarity to the trees. On the other hand, some tropical trees with dense and flat crowns, could have very similar top-view features compared to vegetation-covered roofs. Besides, low vegetation on the roof, as marked by the rectangles in
Figure 10, could be misclassified as trees, since it has enough height. However, with the differences in side-views, for example, trees are usually more green and darker, the classifier could identify fewer trees as buildings, and vice versa.
It is possible that the side-view information can be incorrect and damage the classification, as is shown in the circle in
Figure 11, where the trees are better identified without side-view information. From the 3D visualization of this area, we observe that the trees are growing through a roof, making the trees have building side-views. This kind of error is mainly caused by the incorrect above-ground segmentation, as we discussed in
Section 3.1. Different objects are segmented together, leading to a mismatching of side-views. However, even though the superpixels of trees are assigned with building side-views, their top-views still insure some of them are correctly classified.
3.3. Classification with Non-Evenly Distributed Samples
Usually, the non-evenly distributed samples are more common and practical in real applications. As illustrated in
Figure 9b, in the experiment, the non-evenly distributed training samples were generated by selecting training samples of a sub-region of an image. With the same training and prediction process, the user accuracies of classification with/without side-view features are given in
Table 5.
As compared to the results of evenly distributed training samples, the non-evenly distributed samples have a degraded performance (around 10% and 16% lower overall accuracy for classification with/without side-view, separately). It is well-understood such a training sample selection process may not sufficiently represent the data distribution. However, in such a situation, the side-view still improved the average overall accuracy by 5.6%, the building was even improved by 9.3%. However, in sites B, D and E, the side-view information reduced the accuracy of the tree class. Trees close to buildings and the rain-shed could have unstable side-view features due to the occlusion and the 3D structure of some trees not being reconstructed, which may introduce errors in tree recognition. Thus, if with only limited training samples, this instability may damage the training leading to unreliable predictions. Nevertheless, with high quality training samples, or even limited-quality ones, the involvement of side-views can still greatly improve the land-cover classification, as demonstrated by the classification of the buildings.
4. Discussion
As demonstrated in the experiments, the side-view information can steadily improve the classification performance. However, there are still some issues we need to further discuss. Firstly, as mentioned, the above-ground objects segmentation which decides the boundaries of each object and the corresponding textures is critical for the side-view information extraction. In this study, we tried several methods to segment the above-ground objects [
30,
31]. However, it is a quite complicated problem and we did not find an obviously better solution than the adopted height-grouping algorithm. There are two issues in the segmentation, incorrect boundaries and under-segmentation of multi-objects. We observed the first issue will not damage the side-view information due to the fact that incorrect boundary can still offer appropriate locations for the side-view texture. On the other hand, the under-segmentation of multi-objects cannot be ignored. It will confuse the side-views between different objects and classes. To solve this, the color difference could be considered, with the height-grouping in the above-ground object segmentation. However, this introduction usually causes over-segmentation, fragmenting objects into pieces and hindering the side-view extraction. The deep learning neural networks [
44,
45,
46] could be promising solutions which we would explore in the future.
The selection of training samples is another important fact that decides the classification performance. As mentioned in the results, the evenly-distributed samples have much better performance than non-evenly distributed ones, because this kind of training sample can supply category-level features, instead of object-level ones. The classifier can be well trained with complete data, leading to ideal performance which is hard to be further improved. On the contrary, the dataset underrepresented by the non-evenly distributed samples and the classifier training will be partial, leading to poor classification. This is mainly caused by the high intra-class variability of top-view features that makes the classifier vulnerable to untrained data. As shown in the results, the side-view information is more robust and consistent. This also inspires us to consider multiple dimension features for object classification and recognition in future works.
In our experiment, we also observed a few misclassified areas, for example, many rain-sheds were not classified correctly. There are two main challenges for rain-shed identification: the rain-sheds are short in height and are close to the buildings and trees, the side-view of which might be misleading. On the other hand, we found the ground objects have slightly worse classification results with the side-view. This is mainly caused by the errors in the above-ground segmentation. Many ground areas are wrongly segmented as above-ground objects due to the limited accuracy of the DSM. Particularly, objects in slope may be mixed with ground area in the slope. Hence, how to extract and use side-view information still needs further development.
5. Conclusions
In this study, we aimed to fully utilize the possible information acquired by the oblique aerial image and analyze the potential of using side-view information for land-cover classification. To contribute the side-view information to the top-view segments, we proposed a side-view information extraction method, described in
Section 2. More specially, to get the side-view information, we first segment out the above-ground segments with a height grouping algorithm. Then, based on the boundaries which have been converted to polygons, their 3D vertical side-view planes are defined. With the perspective transformation, the side-view textures of above-ground objects can be cropped and selected from oblique images. Finally, from these oblique textures, the side-view information, including color, HoG and Haar-like features, are extracted as extra information for the classification. Our experiment in different test sites shows that the side-view can steady improve the classification accuracy either with evenly distributed or non-evenly distributed training samples (by 1.1% and 5.6%, respectively). Also, the generalization ability of the side-view is evaluated and demonstrated as a 14.5% accuracy improvement as tested at a larger and untrained area.
Even though the side-view features show strong consistency and high robust to different sites, the training samples are still critical to the classification. In our experiments we observed some commission errors, which were primarily from incorrect segmentation results, which should be further improved.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}