Discriminative Feature Learning Constrained Unsupervised Network for Cloud Detection in Remote Sensing Imagery




Abstract
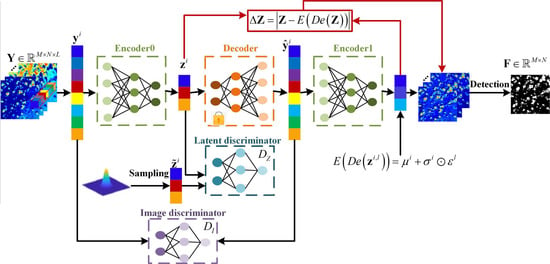
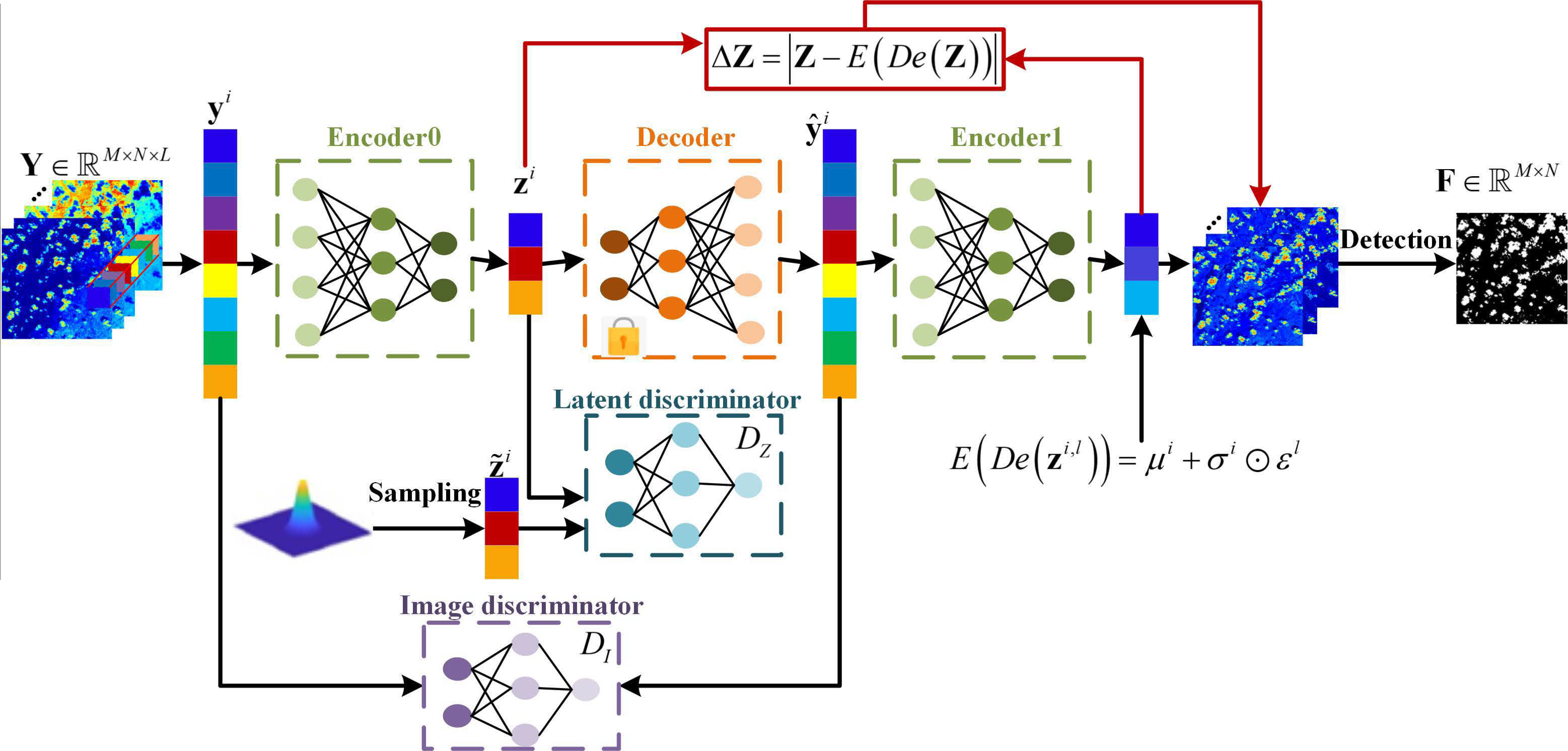
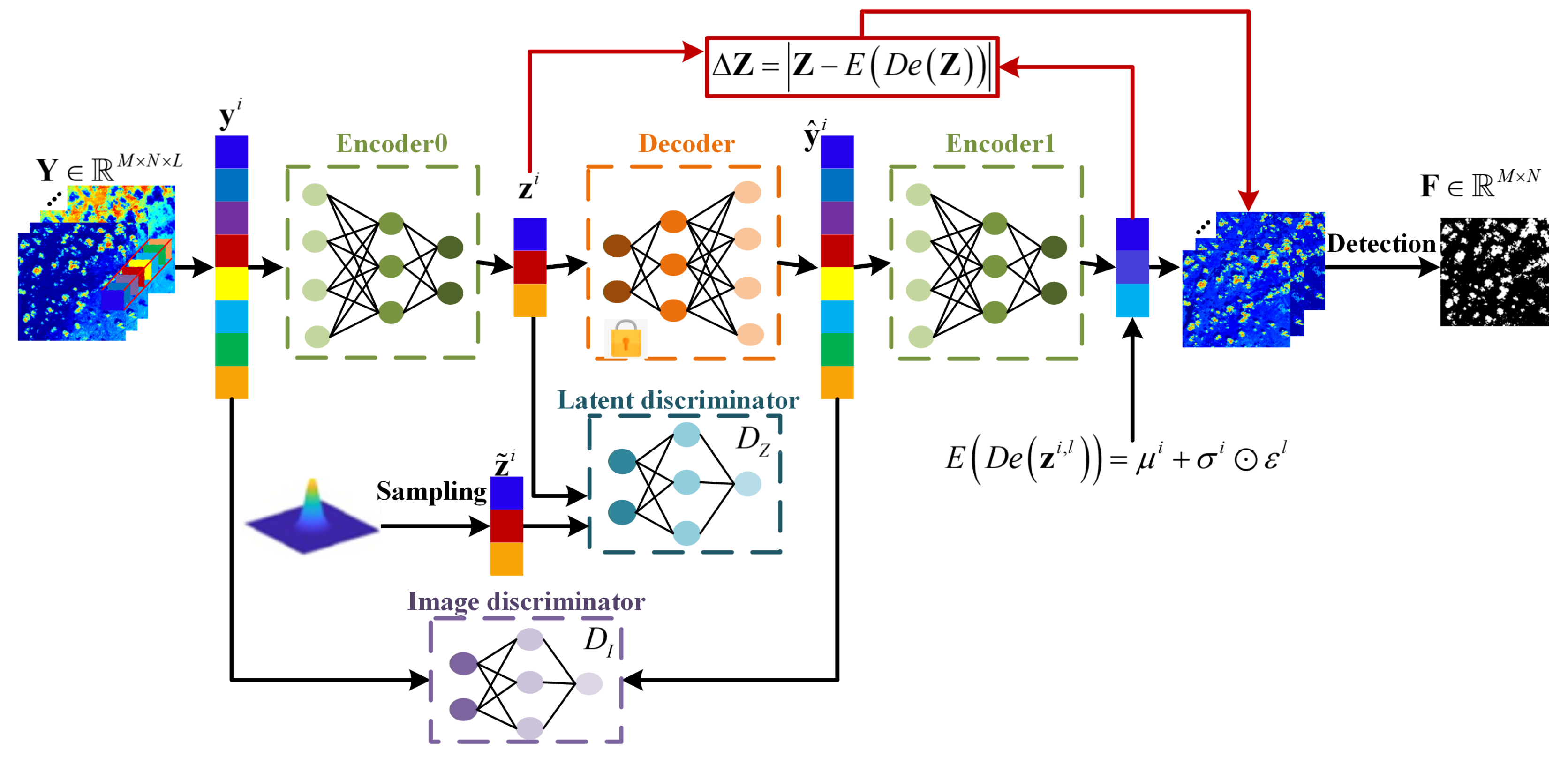
:
1. Introduction
- A novel UNCD method is proposed to address the issue of insufficient training data in remote sensing images, especially hyperspectral data, in the field of cloud detection. To the best of our knowledge, in this paper, such an unsupervised adversarial feature learning model is utilized for the first time for MS and HS cloud detection.
- Latent adversarial learning is introduced such that the AE focuses on extracting a compact representation of the input image in the latent space.
- An image discriminator is used to prevent the generalization of out-of-class features.
- A multivariate Gaussian distribution is adopted to extract a discriminative feature matrix of the background in the latent space, and the residual error between the low-dimensional representations of the original and background pixels is beneficial to cloud detection.
2. Related Work
2.1. Generative Adversarial Network
2.2. Variational Autoencoders
3. Proposed Method
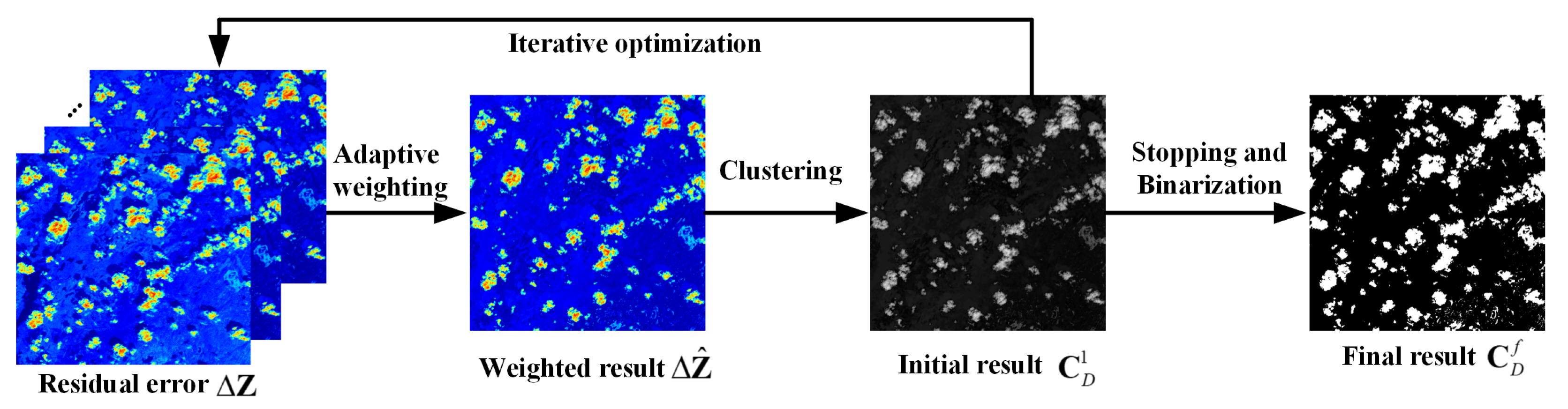
3.1. Constructing the Residual Error in the Latent Space
3.2. Adversarial Feature Learning Term
3.3. Adversarial Image Learning Term
3.4. Latent Representation of the Background
3.5. Reconstruction Loss
3.6. Data Description
3.6.1. Landsat 8 Dataset
3.6.2. GF-1 WFV Dataset
3.6.3. GF-5 Hyperspectral Dataset
4. Experimental Results
4.1. Experimental Setting
4.2. Compared Methods and Evaluation Criterion
4.3. Cloud Detection Results
4.3.1. Landsat 8 Dataset Results
4.3.2. GF-1 WFV Dataset
4.3.3. GF-5 Hyperspectral Dataset
4.4. Component Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AHSI | Advanced Hyperspectral Imager |
| AIUS | Atmospheric Infrared Ultra-spectral Sounder |
| AUC | Area under the curve |
| CDnet | Cloud detection neural network |
| CNN | Convolutional neural network |
| DNN | Deep neural network |
| DPC | Directional Polarization Camera |
| EMI | Environmental Monitoring Instrument |
| FN | False negative |
| FP | False positive |
| GAN | Generative adversarial network |
| GF-1 | GaoFen-1 |
| GF-5 | GaoFen-5 |
| GMI | Greenhouse Gases Monitoring Instrument |
| HRG | High-resolution geometric |
| HS | Hyperspectral |
| Kappa | Kappa coefficient |
| MS | Multispectral |
| MSCFF | Multiscale convolutional feature fusion |
| OA | Overall accuracy |
| OLI | Operational Land Imager |
| PCANet | Principal component analysis network |
| PRS | Progressive refinement scheme |
| ROC | Receiver operating characteristic |
| SGD | Stochastic gradient descent |
| SL | Scene learning |
| ST | Structure tensor |
| SVM | Support vector machine |
| TP | True positive |
| TN | True negative |
| TIRS | Thermal Infrared Sensor |
| UNCD | unsupervised network for cloud detection |
| VAE | Variational autoencoder |
| VIMI | Visual and Infrared Multispectral Imager |
| WFV | Wide field of view |
References
- Lei, J.; Xie, W.; Yang, J.; Li, Y.; Chang, C.I. Spectral-spatial feature extraction for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8131–8143. [Google Scholar] [CrossRef]
- Xie, W.; Shi, Y.; Li, Y.; Jia, X.; Lei, J. High-quality spectral-spatial reconstruction using saliency detection and deep feature enhancement. Pattern Recognit. 2019, 88, 139–152. [Google Scholar] [CrossRef]
- Jiang, T.; Li, Y.; Xie, W.; Du, Q. Discriminative reconstruction constrained generative adversarial network for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2020. to be published. [Google Scholar] [CrossRef]
- Nasrabadi, N.M. Hyperspectral target detection: An overview of current and future challenges. IEEE Signal Process. Mag. 2014, 31, 34–44. [Google Scholar] [CrossRef]
- Yuan, Y.; Ma, D.; Wang, Q. Hyperspectral anomaly detection by graph pixel selection. IEEE Trans. Cybern. 2016, 46, 3123–3134. [Google Scholar] [CrossRef]
- Li, Y.; Xie, W.; Li, H. Hyperspectral image reconstruction by deep convolutional neural network for classification. Pattern Recognit. 2017, 63, 371–383. [Google Scholar] [CrossRef]
- Zhang, Y.; Rossow, W.B.; Lacis, A.A.; Oinas, V.; Mishchenko, M.I. Calculation of radiative fluxes from the surface to top of atmosphere based on ISCCP and other global data sets: Refinements of the radiative transfer model and the input data. J. Geophys. Res. Atmos. 2004, 109, D19105. [Google Scholar] [CrossRef] [Green Version]
- Xie, W.; Li, Y.; Zhou, W.; Zheng, Y. Efficient coarse-to-fine spectral rectification for hyperspectral image. Neurocomputing 2018, 275, 2490–2504. [Google Scholar] [CrossRef]
- Fisher, A. Cloud and cloud-shadow detection in SPOT5 HRG imagery with automated morphological feature extraction. Remote Sens. 2014, 6, 776–800. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Xiao, C. Cloud detection of RGB color aerial photographs by progressive refinement scheme. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7264–7275. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Shen, H.; Li, H.; Xia, G.; Gamba, P.; Zhang, L. Multi-feature combined cloud and cloud shadow detection in GaoFen-1 wide field of view imagery. Remote Sens. Environ. 2017, 191, 342–358. [Google Scholar] [CrossRef] [Green Version]
- Zhong, B.; Chen, W.; Wu, S.; Hu, L.; Luo, X.; Liu, Q. A cloud detection method based on relationship between objects of cloud and cloud-shadow for Chinese moderate to high resolution satellite imagery. IEEE J. Sel. Top. Appl.Earth Observat. Remote Sens. 2017, 10, 4898–4908. [Google Scholar] [CrossRef]
- Ishida, H.; Oishi, Y.; Morite, K.; Moriwaki, K.; Nakajima, T.Y. Development of a support vector machine based cloud detection method for MODIS with the adjustability to various conditions. Remote Sens. Environ. 2018, 205, 309–407. [Google Scholar] [CrossRef]
- An, Z.; Shi, Z. Scene learning for cloud detection on remote-sensing images. IEEE J. Sel. Top. Appl.Earth Observat. Remote Sens. 2015, 8, 4206–4222. [Google Scholar] [CrossRef]
- Li, P.; Dong, L.; Xiao, H.; Xu, M. A cloud image detection method based on SVM vector machine. Neurocomputing 2015, 169, 34–42. [Google Scholar] [CrossRef]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient K-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Xie, W.; Jia, X.; Li, Y.; Lei, J. Hyperspectral image super-resolution using deep feature matrix factorization. IEEE Trans. Geosci. Remote Sens. 2019. to be published. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Semi-supervised deep learning using pseudo labels for hyperspectral image classification. IEEE Trans. Image Process. 2018, 27, 1259–1270. [Google Scholar] [CrossRef]
- Xie, W.; Li, L.; Hu, J.; Chen, D.Y. Trainable spectral difference learning with spatial starting for hyperspectral image denoising. IEEE Trans. Image Process. 2018, 108, 272–286. [Google Scholar] [CrossRef]
- Ienco, D.; Pensa, R.G.; Meo, R. A semisupervised approach to the detection and characterization of outliers in categorical data. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 1017–1029. [Google Scholar] [CrossRef] [Green Version]
- Shi, M.; Xie, F.; Zi, Y.; Yin, J. Cloud detection of remote sensing images by deep learning. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 701–704. [Google Scholar]
- Goff, M.L.; Tourneret, J.Y.; Wendt, H.; Ortner, M.; Spigai, M. Deep learning for cloud detection. In Proceedings of the International Conference of Pattern Recognition Systems(ICPRS), Fort Worth, TX, USA, 23–28 July 2017; pp. 1–6. [Google Scholar]
- Ozkan, S.; Efendioglu, M.; Demirpolat, C. Cloud detection from rgb color remote sensing images with deep pyramid networks. arXiv 2018, arXiv:cs.CV/1801.08706. [Google Scholar]
- Zi, Y.; Xie, F.; Jiang, Z. A cloud detection method for Landsat 8 images based on PCANet. Remote Sens. 2018, 10, 877. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud detection in remote sensing images based on multiscale features-convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Yang, J.; Guo, J.; Yue, H.; Liu, Z.; Hu, H.; Li, K. CDnet: CNN-based cloud detection for remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019. to be published. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote. Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Wen, F.; Gao, Z.; Ling, X. A coarse-to-fine framework for cloud removal in remote sensing image sequence. IEEE Trans. Geosci. Remote Sens. 2019. to be published. [Google Scholar] [CrossRef]
- Wen, F.; Zhang, Y.; Gao, Z.; Ling, X. Two-pass robust component analysis for cloud removal in satellite image sequence. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1090–1094. [Google Scholar] [CrossRef]
- Lorenzi, L.; Melgani, F.; Mercier, G. Missing-area reconstruction in multispectral images under a compressive sensing perspective. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3998–4008. [Google Scholar] [CrossRef]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, arXiv:cs.LG/1511.05644. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:cs.LG/1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Xie, W.; Jiang, T.; Li, Y.; Jia, X.; Lei, J. Structure tensor and guided filtering-based algorithm for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4218–4230. [Google Scholar] [CrossRef]
- Xie, W.; Lei, J.; Cui, Y.; Li, Y.; Du, Q. Hyperspectral pansharpening with deep priors. IEEE Trans. Neural Netw. Learn. Syst. 2019. to be published. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef] [Green Version]
- Cao, V.L.; Nicolau, M.; McDermott, J. A hybrid autoencoder and density estimation model for anomaly detection. In Proceedings of the IEEE International Parallel Problem Solving from Nature, Edinburgh, Scotland, 17–21 September 2016; pp. 717–726. [Google Scholar]
- Ferri, C.; Hernández-Orallo, J.; Flach, P. A coherent interpretation of AUC as a measure of aggregated classification performance. In Proceedings of the International Conference on Machine Learning, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 657–664. [Google Scholar]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A General End-to-End 2-D CNN Framework for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image I | Proposed | K-means | PRS | PCANet | SVM | SL |
|---|---|---|---|---|---|---|
| AUC | 0.9543 | 0.7979 | 0.8485 | 0.8468 | 0.8286 | 0.7401 |
| OA | 0.9526 | 0.6745 | 0.9391 | 0.9359 | 0.9343 | 0.8448 |
| Kappa | 0.8719 | 0.3545 | 0.7747 | 0.7646 | 0.7503 | 0.4814 |
| Image II | Proposed | K-means | PRS | PCANet | SVM | SL |
| AUC | 0.9637 | 0.8848 | 0.8184 | 0.8701 | 0.8762 | 0.8593 |
| OA | 0.9536 | 0.9062 | 0.7668 | 0.8962 | 0.8409 | 0.8821 |
| Kappa | 0.9016 | 0.7899 | 0.5560 | 0.7659 | 0.6845 | 0.7365 |
| Image III | Proposed | K-means | PRS | PCANet | SVM | SL |
|---|---|---|---|---|---|---|
| AUC | 0.9676 | 0.9310 | 0.8387 | 0.9168 | 0.8873 | 0.8840 |
| OA | 0.9957 | 0.9491 | 0.9726 | 0.9815 | 0.9835 | 0.9661 |
| Kappa | 0.9636 | 0.6646 | 0.7434 | 0.8403 | 0.8458 | 0.7261 |
| Image IV | Proposed | K-means | PRS | PCANet | SVM | SL |
| AUC | 0.9860 | 0.8753 | 0.8586 | 0.9304 | 0.8980 | 0.8280 |
| OA | 0.9934 | 0.8585 | 0.9623 | 0.9591 | 0.9743 | 0.9690 |
| Kappa | 0.9630 | 0.4621 | 0.7551 | 0.7732 | 0.8338 | 0.7743 |
| AUC | ||||
|---|---|---|---|---|
| Component | Image I | Image II | Image III | Image IV |
| Only AE | 0.9254 | 0.9025 | 0.9436 | 0.9462 |
| AE with | 0.9477 | 0.9379 | 0.9506 | 0.9689 |
| Proposed | 0.9543 | 0.9637 | 0.9676 | 0.9860 |
| OA | ||||
| Component | Image I | Image II | Image III | Image IV |
| Only AE | 0.9211 | 0.8749 | 0.9917 | 0.9897 |
| AE with | 0.9248 | 0.9310 | 0.9922 | 0.9923 |
| Proposed | 0.9526 | 0.9536 | 0.9959 | 0.9934 |
| Kappa | ||||
| Component | Image I | Image II | Image III | Image IV |
| Only AE | 0.8678 | 0.7469 | 0.9258 | 0.9336 |
| AE with | 0.8540 | 0.8535 | 0.9309 | 0.9515 |
| Proposed | 0.8719 | 0.9016 | 0.9636 | 0.9630 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, W.; Yang, J.; Li, Y.; Lei, J.; Zhong, J.; Li, J. Discriminative Feature Learning Constrained Unsupervised Network for Cloud Detection in Remote Sensing Imagery. Remote Sens. 2020, 12, 456. https://doi.org/10.3390/rs12030456
Xie W, Yang J, Li Y, Lei J, Zhong J, Li J. Discriminative Feature Learning Constrained Unsupervised Network for Cloud Detection in Remote Sensing Imagery. Remote Sensing. 2020; 12(3):456. https://doi.org/10.3390/rs12030456
Chicago/Turabian StyleXie, Weiying, Jian Yang, Yunsong Li, Jie Lei, Jiaping Zhong, and Jiaojiao Li. 2020. "Discriminative Feature Learning Constrained Unsupervised Network for Cloud Detection in Remote Sensing Imagery" Remote Sensing 12, no. 3: 456. https://doi.org/10.3390/rs12030456
APA StyleXie, W., Yang, J., Li, Y., Lei, J., Zhong, J., & Li, J. (2020). Discriminative Feature Learning Constrained Unsupervised Network for Cloud Detection in Remote Sensing Imagery. Remote Sensing, 12(3), 456. https://doi.org/10.3390/rs12030456