Extracting Impervious Surface from Aerial Imagery Using Semi-Automatic Sampling and Spectral Stability


Abstract
:
1. Introduction
2. Materials and Methods
2.1. Study Area and Data
2.2. Sample Generation
2.3. Spectral Stability
2.4. Classification and Accuracy Assessment
3. Results
3.1. Classification Results
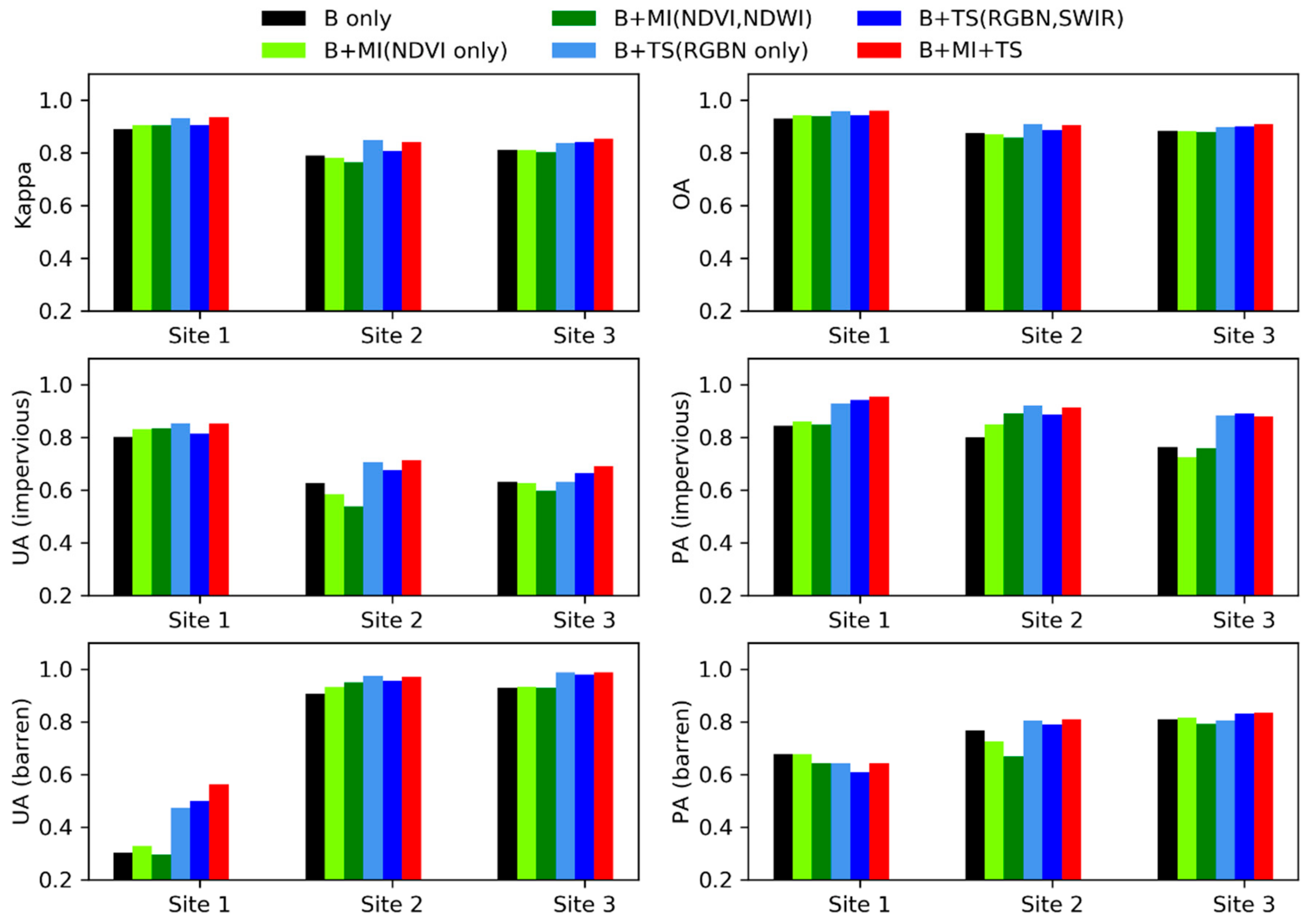
3.2. Selection of Predictor Variables
3.3. Training and Validation Samples
3.4. NDVI and NDWI Thresholds
3.5. Comparison to NLCD data
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- WHO. Global Report on Urban Health: Equitable, Healthier Cities for Sustainable Development; World Health Organization: Geneva, Switzerland, 2016. [Google Scholar]
- Sexton, J.O.; Song, X.P.; Huang, C.; Channan, S.; Baker, M.E.; Townshend, J.R. Urban growth of the Washington, D.C.—Baltimore, MD metropolitan region from 1984 to 2010 by annual, Landsat-based estimates of impervious cover. Remote Sens. Environ. 2013, 129, 42–53. [Google Scholar] [CrossRef]
- Paul, M.J.; Meyer, J.L. Streams in the urban landscape. Annu. Rev. Ecol. Syst. 2001, 32, 333–365. [Google Scholar] [CrossRef]
- Arnold, C.L.; Gibbons, C.J. Impervious surface coverage—The emergence of a key environmental indicator. J. Am. Plan. Assoc. 1996, 62, 243–258. [Google Scholar] [CrossRef]
- Weng, Q. Remote sensing of impervious surfaces in the urban areas: Requirements, methods, and trends. Remote Sens. Environ. 2012, 117, 34–49. [Google Scholar] [CrossRef]
- Mignot, E.; Paquier, A.; Haider, S. Modeling floods in a dense urban area using 2D shallow water equations. J. Hydrol. 2006, 327, 186–199. [Google Scholar] [CrossRef] [Green Version]
- Meyer, J.L.; Paul, M.J.; Taulbee, W.K. Stream ecosystem function in urbanizing landscapes. J. N. Am. Benthol. Soc. 2005, 24, 602–612. [Google Scholar] [CrossRef]
- Lu, D.S.; Weng, Q.H.; Li, G.Y. Residential population estimation using a remote sensing derived impervious surface approach. Int. J. Remote Sens. 2006, 27, 3553–3570. [Google Scholar] [CrossRef]
- Imhoff, M.L.; Zhang, P.; Wolfe, R.E.; Bounoua, L. Remote sensing of the urban heat island effect across biomes in the continental USA. Remote Sens. Environ. 2010, 114, 504–513. [Google Scholar] [CrossRef] [Green Version]
- Gobel, P.; Dierkes, C.; Coldewey, W.C. Storm water runoff concentration matrix for urban areas. J. Contam. Hydrol. 2007, 91, 26–42. [Google Scholar] [CrossRef] [PubMed]
- Brabec, E.; Schulte, S.; Richards, P.L. Impervious surfaces and water quality: A review of current literature and its implications for watershed planning. J. Plan. Lit. 2002, 16, 499–514. [Google Scholar] [CrossRef]
- Yang, L.; Jin, S.; Danielson, P.; Homer, C.; Gass, L.; Bender, S.M.; Case, A.; Costello, C.; Dewitz, J.; Fry, J.; et al. A new generation of the United States National Land Cover Database: Requirements, research priorities, design, and implementation strategies. ISPRS J. Photogramm. Remote Sens. 2018, 146, 108–123. [Google Scholar] [CrossRef]
- Wickham, J.D.; Stehman, S.V.; Gass, L.; Dewitz, J.; Fry, J.A.; Wade, T.G. Accuracy assessment of NLCD 2006 land cover and impervious surface. Remote Sens. Environ. 2013, 130, 294–304. [Google Scholar] [CrossRef]
- Cole, B.; Smith, G.; Balzter, H. Acceleration and fragmentation of CORINE land cover changes in the United Kingdom from 2006–2012 detected by Copernicus IMAGE2012 satellite data. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 107–122. [Google Scholar] [CrossRef]
- Yu, L.; Wang, J.; Li, X.; Li, C.; Zhao, Y.; Gong, P. A multi-resolution global land cover dataset through multisource data aggregation. Sci. China-Earth Sci. 2014, 57, 2317–2329. [Google Scholar] [CrossRef]
- Broxton, P.D.; Zeng, X.B.; Sulla-Menashe, D.; Troch, P.A. A Global Land Cover Climatology Using MODIS Data. J. Appl. Meteorol. Clim. 2014, 53, 1593–1605. [Google Scholar] [CrossRef]
- Nagel, P.; Yuan, F. High-resolution Land Cover and Impervious Surface Classifications in the Twin Cities Metropolitan Area with NAIP Imagery. Photogramm. Eng. Remote Sens. 2016, 82, 63–71. [Google Scholar] [CrossRef]
- Zhou, Y.Y.; Wang, Y.Q. Extraction of impervious, surface areas from high spatial resolution imagery by multiple agent segmentation and classification. Photogramm. Eng. Remote Sens. 2008, 74, 857–868. [Google Scholar] [CrossRef] [Green Version]
- Maxwell, A.E.; Strager, M.P.; Warner, T.A.; Ramezan, C.A.; Morgan, A.N.; Pauley, C.E. Large-Area, High Spatial Resolution Land Cover Mapping Using Random Forests, GEOBIA, and NAIP Orthophotography: Findings and Recommendations. Remote Sens. 2019, 11, 1409. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231. [Google Scholar] [CrossRef]
- Piyoosh, A.K.; Ghosh, S.K. Semi-automatic mapping of anthropogenic impervious surfaces in an urban/suburban area using Landsat 8 satellite data. GIScience Remote Sens. 2017, 54, 471–494. [Google Scholar] [CrossRef]
- Hu, X.F.; Weng, Q.H. Impervious surface area extraction from IKONOS imagery using an object-based fuzzy method. Geocarto Int. 2011, 26, 3–20. [Google Scholar] [CrossRef]
- Wang, J.; Song, J.W.; Chen, M.Q.; Yang, Z. Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Kuang, W.; Chi, W.; Lu, D.; Dou, Y. A comparative analysis of megacity expansions in China and the U.S.: Patterns, rates and driving forces. Landsc. Urban Plan. 2014, 132, 121–135. [Google Scholar] [CrossRef]
- Hamedianfar, A.; Shafri, H.Z.M.; Mansor, S.; Ahmad, N. Improving detailed rule-based feature extraction of urban areas from WorldView-2 image and lidar data. Int. J. Remote Sens. 2014, 35, 1876–1899. [Google Scholar] [CrossRef]
- Da Silva, V.S.; Salami, G.; Da Silva, M.I.O.; Silva, E.A.; Monteiro Junior, J.J.; Alba, E. Methodological evaluation of vegetation indexes in land use and land cover (LULC) classification. Geol. Ecol. Landsc. 2019, 1–11. [Google Scholar] [CrossRef]
- Faour, G.; Mhawej, M.; Nasrallah, A. Global trends analysis of the main vegetation types throughout the past four decades. Appl. Geogr. 2018, 97, 184–195. [Google Scholar] [CrossRef]
- Jia, K.; Liang, S.; Wei, X.; Yao, Y.; Su, Y.; Jiang, B.; Wang, X. Land Cover Classification of Landsat Data with Phenological Features Extracted from Time Series MODIS NDVI Data. Remote Sens. 2014, 6, 11518–11532. [Google Scholar] [CrossRef] [Green Version]
- Nasrallah, A.; Baghdadi, N.; Mhawej, M.; Faour, G.; Darwish, T.; Belhouchette, H.; Darwich, S. A Novel Approach for Mapping Wheat Areas Using High Resolution Sentinel-2 Images. Sensors 2018, 18, 2089. [Google Scholar] [CrossRef] [Green Version]
- Shao, Y.; Lunetta, R.S.; Wheeler, B.; Iiames, J.S.; Campbell, J.B. An evaluation of time-series smoothing algorithms for land-cover classifications using MODIS-NDVI multi-temporal data. Remote Sens. Environ. 2016, 174, 258–265. [Google Scholar] [CrossRef]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B 2010, 37, 682–703. [Google Scholar] [CrossRef] [Green Version]
- Matthews, J.W.; Skultety, D.; Zercher, B.; Ward, M.P.; Benson, T.J. Field Verification of Original and Updated National Wetlands Inventory Maps in three Metropolitan Areas in Illinois, USA. Wetlands 2016, 36, 1155–1165. [Google Scholar] [CrossRef]
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 National Land Cover Database for the Conterminous United States—Representing a Decade of Land Cover Change Information. Photogramm. Eng. Remote Sens. 2015, 81, 345–354. [Google Scholar] [CrossRef]
- Bacour, C.; Briottet, X.; Bréon, F.M.; Viallefont-Robinet, F.; Bouvet, M. Revisiting Pseudo Invariant Calibration Sites (PICS) Over Sand Deserts for Vicarious Calibration of Optical Imagers at 20 km and 100 km Scales. Remote Sens. 2019, 11. [Google Scholar] [CrossRef] [Green Version]
- Young, N.E.; Anderson, R.S.; Chignell, S.M.; Vorster, A.G.; Lawrence, R.; Evangelista, P.H. A survival guide to Landsat preprocessing. Ecology 2017, 98, 920–932. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Johnson, D.M. Using the Landsat archive to map crop cover history across the United States. Remote Sens. Environ. 2019, 232, 111286. [Google Scholar] [CrossRef]
- Zhang, H.; Zimba, P.V.; Nzewi, E.U. A New Pseudoinvariant Near-Infrared Threshold Method for Relative Radiometric Correction of Aerial Imagery. Remote Sens. 2019, 11. [Google Scholar] [CrossRef] [Green Version]
- Traganos, D.; Poursanidis, D.; Aggarwal, B.; Chrysoulakis, N.; Reinartz, P. Estimating Satellite-Derived Bathymetry (SDB) with the Google Earth Engine and Sentinel-2. Remote Sens. 2018, 10. [Google Scholar] [CrossRef] [Green Version]
- Small, C. Multitemporal analysis of urban reflectance. Remote Sens. Environ. 2002, 81, 427–442. [Google Scholar] [CrossRef]
- Singh, K.K.; Madden, M.; Gray, J.; Meentemeyer, R.K. The managed clearing: An overlooked land-cover type in urbanizing regions? PLoS ONE 2018, 13, e0192822. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wickham, J.; Herold, N.; Stehman, S.V.; Homer, C.G.; Xian, G.; Claggett, P. Accuracy assessment of NLCD 2011 impervious cover data for the Chesapeake Bay region, USA. ISPRS J. Photogramm. Remote Sens. 2018, 146, 151–160. [Google Scholar] [CrossRef] [PubMed]
- Stehman, S.V.; Fonte, C.C.; Foody, G.M.; See, L. Using volunteered geographic information (VGI) in design-based statistical inference for area estimation and accuracy assessment of land cover. Remote Sens. Environ. 2018, 212, 47–59. [Google Scholar] [CrossRef] [Green Version]
- Viana, C.M.; Encalada, L.; Rocha, J. The value of OpenStreetMap Historical Contributions as a Source of Sampling Data for Multi-temporal Land Use/Cover Maps. ISPRS Int. J. Geo-Inf. 2019, 8. [Google Scholar] [CrossRef] [Green Version]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning Aerial Image Segmentation From Online Maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Forget, Y.; Linard, C.; Gilbert, M. Supervised Classification of Built-Up Areas in Sub-Saharan African Cities Using Landsat Imagery and OpenStreetMap. Remote Sens. 2018, 10. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | |||||||
|---|---|---|---|---|---|---|---|
| Impervious Surface | Vegetation | Water | Barren | Row Total | UA | ||
| Classification | Impervious Surface | 279 | 12 | 8 | 11 | 309 | 90.0% |
| Vegetation | 2 | 389 | 0 | 0 | 392 | 99.5% | |
| Water | 1 | 0 | 766 | 0 | 766 | 99.9% | |
| Barren | 12 | 1 | 0 | 17 | 31 | 56.7% | |
| Column Total | 277 | 402 | 774 | 28 | Overall: | 96.2% | |
| PA | 94.9% | 96.8% | 99.0% | 60.7% | Kappa: | 0.939 | |
| Reference | |||||||
|---|---|---|---|---|---|---|---|
| Impervious Surface | Vegetation | Water | Barren | Row Total | UA | ||
| Classification | Impervious Surface | 200 | 31 | 0 | 49 | 280 | 71.4% |
| Vegetation | 10 | 788 | 0 | 38 | 836 | 94.3% | |
| Water | 1 | 0 | 2 | 0 | 3 | 66.7% | |
| Barren | 8 | 3 | 0 | 370 | 381 | 97.1% | |
| Column Total | 219 | 822 | 2 | 457 | Overall: | 91.5% | |
| PA | 91.3% | 95.9% | 100.0% | 81.0% | Kappa: | 0.855 | |
| Reference | |||||||
|---|---|---|---|---|---|---|---|
| Impervious Surface | Vegetation | Water | Barren | Row Total | UA | ||
| Classification | Impervious Surface | 160 | 15 | 4 | 53 | 232 | 69.0% |
| Vegetation | 17 | 725 | 7 | 32 | 781 | 92.8% | |
| Water | 3 | 0 | 49 | 0 | 52 | 94.2% | |
| Barren | 2 | 1 | 2 | 430 | 435 | 98.9% | |
| Column Total | 182 | 741 | 62 | 515 | Overall: | 90.6% | |
| PA | 86.8% | 97.4% | 80.6% | 83.3% | Kappa: | 0.849 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Gorelick, S.M.; Zimba, P.V. Extracting Impervious Surface from Aerial Imagery Using Semi-Automatic Sampling and Spectral Stability. Remote Sens. 2020, 12, 506. https://doi.org/10.3390/rs12030506
Zhang H, Gorelick SM, Zimba PV. Extracting Impervious Surface from Aerial Imagery Using Semi-Automatic Sampling and Spectral Stability. Remote Sensing. 2020; 12(3):506. https://doi.org/10.3390/rs12030506
Chicago/Turabian StyleZhang, Hua, Steven M. Gorelick, and Paul V. Zimba. 2020. "Extracting Impervious Surface from Aerial Imagery Using Semi-Automatic Sampling and Spectral Stability" Remote Sensing 12, no. 3: 506. https://doi.org/10.3390/rs12030506