Training Data Selection for Annual Land Cover Classification for the Land Change Monitoring, Assessment, and Projection (LCMAP) Initiative


Abstract
1. Introduction
2. Data and Study Area
2.1. Landsat Analysis Ready Data (ARD)
2.2. LCMAP Continuous Change Detection
2.3. Auxiliary Data
2.4. National Land Cover Database (NLCD)
2.5. Study Area
3. Methods
3.1. Auxiliary Data Refining
3.2. Training Sample Size Optimization
3.3. Training Data Source Optimization
4. Results and Discussion
4.1. Auxiliary Data Refining
4.2. Training Sample Size Optimization
4.3. Training Data Source Optimization
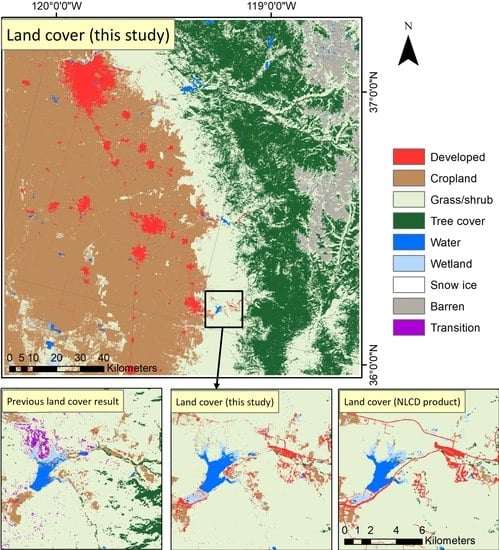
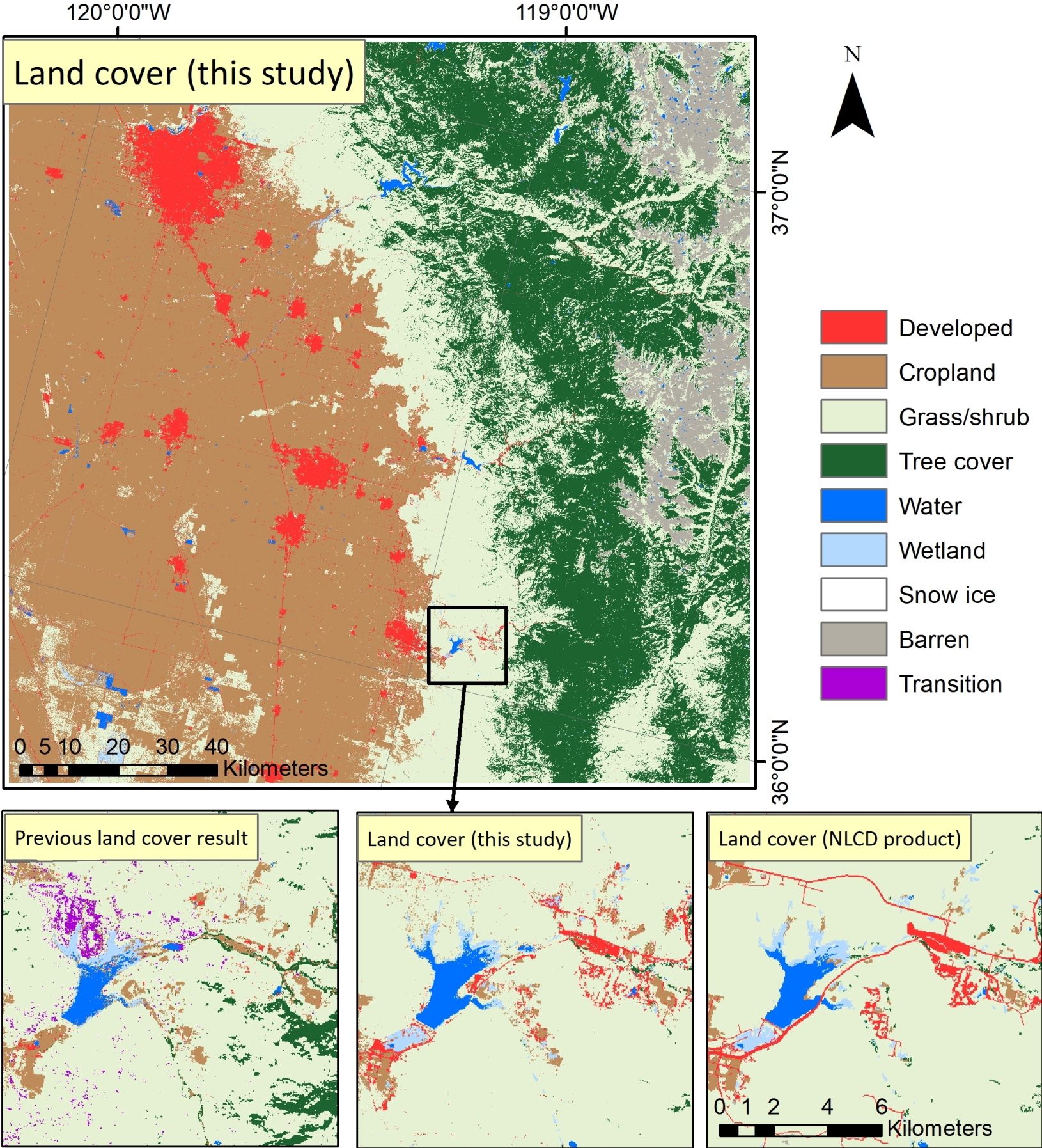
4.4. Comparison of Classification Results After the Optimization
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Friedl, M.A.; McIver, D.K.; Hodges, J.C.; Zhang, X.Y.; Muchoney, D.; Strahler, A.H.; Woodcock, C.E.; Gopal, S.; Schneider, A.; Cooper, A. Global land cover mapping from MODIS: Algorithms and early results. Remote Sens. Environ. 2002, 83, 287–302. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M. Global land cover mapping at 30 m resolution: A POK-based operational approach. Isprs J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Homer, C.; Dewitz, J.; Fry, J.; Coan, M.; Hossain, N.; Larson, C.; Herold, N.; McKerrow, A.; VanDriel, J.N.; Wickham, J. Completion of the 2001 national land cover database for the counterminous United States. Photogramm. Eng. Remote Sens. 2007, 73, 337. [Google Scholar]
- Loveland, T.R.; Reed, B.C.; Brown, J.F.; Ohlen, D.O.; Zhu, Z.; Yang, L.; Merchant, J.W. Development of a global land cover characteristics database and IGBP DISCover from 1 km AVHRR data. Int. J. Remote Sens. 2000, 21, 1303–1330. [Google Scholar] [CrossRef]
- Anderson, J.R. A land use and land cover classification system for use with remote sensor data; US Government Printing Office: Washington, DC, USA, 1976; Volume 964. [Google Scholar]
- Fry, J.A.; Xian, G.; Jin, S.; Dewitz, J.A.; Homer, C.G.; Yang, L.; Barnes, C.A.; Herold, N.D.; Wickham, J.D. Completion of the 2006 national land cover database for the conterminous United States. Photogramm. Eng. Remote Sens. 2011, 77, 858–864. [Google Scholar]
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 National Land Cover Database for the conterminous United States–representing a decade of land cover change information. Photogramm. Eng. Remote Sens. 2015, 81, 345–354. [Google Scholar]
- Vogelmann, J.E.; Sohl, T.L.; Campbell, P.; Shaw, D. Regional land cover characterization using Landsat Thematic Mapper data and ancillary data sources. Environ. Monit. Assess. 1998, 51, 415–428. [Google Scholar] [CrossRef]
- Rindfuss, R.R.; Walsh, S.J.; Turner, B.L.; Fox, J.; Mishra, V. Developing a science of land change: Challenges and methodological issues. Proc. Natl. Acad. Sci. USA 2004, 101, 13976–13981. [Google Scholar] [CrossRef]
- Turner, B.L.; Lambin, E.F.; Reenberg, A. The emergence of land change science for global environmental change and sustainability. Proc. Natl. Acad. Sci. USA 2007, 104, 20666–20671. [Google Scholar] [CrossRef]
- Brown, J.F.; Tollerud, H.J.; Barber, C.P.; Zhou, Q.; Dwyer, J.; Vogelmann, J.E.; Loveland, T.; Woodcock, C.E.; Stehman, S.V.; Zhu, Z. Lessons learned implementing an operational continuous United States national land change monitoring capability: The Land Change Monitoring, Assessment, and Projection (LCMAP) approach. Remote Sens. Environ. 2020, 111356. [Google Scholar] [CrossRef]
- Dwyer, J.; Roy, D.; Sauer, B.; Jenkerson, C.; Zhang, H.; Lymburner, L. Analysis ready data: Enabling analysis of the Landsat archive. Remote Sens. 2018, 10, 1363. [Google Scholar]
- Zhu, Z.; Woodcock, C.E.; Holden, C.; Yang, Z. Generating synthetic Landsat images based on all available Landsat data: Predicting Landsat surface reflectance at any given time. Remote Sens. Environ. 2015, 162, 67–83. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef]
- Zhu, Z.; Gallant, A.L.; Woodcock, C.E.; Pengra, B.; Olofsson, P.; Loveland, T.R.; Jin, S.; Dahal, D.; Yang, L.; Auch, R.F. Optimizing selection of training and auxiliary data for operational land cover classification for the LCMAP initiative. Isprs J. Photogramm. Remote Sens. 2016, 122, 206–221. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.; Townshend, J. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. Isprs J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Rani, S.; Dhingra, S. REVIEW ON SATELLITE IMAGE CLASSIFICATION BY MACHINE LEARNING AND OPTIMIZATION APPROACHES. Int. J. Adv. Res. Comput. Sci. 2017, 8. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. Isprs J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Millard, K.; Richardson, M. On the importance of training data sample selection in random forest image classification: A case study in peatland ecosystem mapping. Remote Sens. 2015, 7, 8489–8515. [Google Scholar] [CrossRef]
- Liu, H.; Dougherty, E.R.; Dy, J.G.; Torkkola, K.; Tuv, E.; Peng, H.; Ding, C.; Long, F.; Berens, M.; Parsons, L. Evolving feature selection. Ieee Intell. Syst. 2005, 20, 64–76. [Google Scholar] [CrossRef]
- Salehi, M.; Sahebi, M.R.; Maghsoudi, Y. Improving the accuracy of urban land cover classification using Radarsat-2 PolSAR data. Ieee J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 1394–1401. [Google Scholar]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabelling on random forest performance for large area land cover classification using the ensemble margin. Isprs J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Roy, D.P.; Ju, J.; Kline, K.; Scaramuzza, P.L.; Kovalskyy, V.; Hansen, M.; Loveland, T.R.; Vermote, E.; Zhang, C. Web-enabled Landsat Data (WELD): Landsat ETM+ composited mosaics of the conterminous United States. Remote Sens. Environ. 2010, 114, 35–49. [Google Scholar] [CrossRef]
- Gesch, D.; Oimoen, M.; Greenlee, S.; Nelson, C.; Steuck, M.; Tyler, D. The national elevation dataset. Photogramm. Eng. Remote Sens. 2002, 68, 5–32. [Google Scholar]
- Wilen, B.O.; Bates, M. The US fish and wildlife service’s national wetlands inventory project. In Classification and inventory of the world’s wetlands; Springer: Berlin, Germany, 1995; pp. 153–169. [Google Scholar]
- Soil Survey Staff. Natural Resources Conservation Service; United States Department of Agriculture: Washington, DC, USA, 2008. Available online: https://websoilsurvey.nrcs.usda.gov/ (accessed on 3 August 2016).
- Jin, S.; Homer, C.; Yang, L.; Danielson, P.; Dewitz, J.; Li, C.; Zhu, Z.; Xian, G.; Howard, D. Overall Methodology Design for the United States National Land Cover Database 2016 Products. Remote Sens. 2019, 11, 2971. [Google Scholar] [CrossRef]
- Yang, L.; Jin, S.; Danielson, P.; Homer, C.; Gass, L.; Bender, S.M.; Case, A.; Costello, C.; Dewitz, J.; Fry, J. A new generation of the United States National Land Cover Database: Requirements, research priorities, design, and implementation strategies. Isprs J. Photogramm. Remote Sens. 2018, 146, 108–123. [Google Scholar] [CrossRef]
- Wickham, J.; Stehman, S.V.; Gass, L.; Dewitz, J.A.; Sorenson, D.G.; Granneman, B.J.; Poss, R.V.; Baer, L.A. Thematic accuracy assessment of the 2011 national land cover database (NLCD). Remote Sens. Environ. 2017, 191, 328–341. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Freeman, E.A.; Moisen, G.G.; Coulston, J.W.; Wilson, B.T. Random forests and stochastic gradient boosting for predicting tree canopy cover: Comparing tuning processes and model performance. Can. J. For. Res. 2015, 46, 323–339. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Jin, H.; Stehman, S.V.; Mountrakis, G. Assessing the impact of training sample selection on accuracy of an urban classification: A case study in Denver, Colorado. Int. J. Remote Sens. 2014, 35, 2067–2081. [Google Scholar] [CrossRef]
- Hall, M.A.; Smith, L.A. Practical feature subset selection for machine learning. In Computer Science ’98, Proceedings of the 21st Australasian Computer Science Conference ACSC’98, Perth, Astralia, 4–6 February 1998; McDonald, C., Ed.; Springer: Berlin, Germany, 1998; pp. 1716–1741. [Google Scholar]
- Scornet, E.; Biau, G.; Vert, J.-P. Consistency of random forests. Ann. Stat. 2015, 43, 1716–1741. [Google Scholar] [CrossRef]
- National Agriculture Imagery Program (NAIP). Information Sheet. 2013. Available online: https://www.fsa.usda.gov/Internet/FSA_File/naip_info_sheet_2013.pdf (accessed on 29 April 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NLCD class | LCMAP class |
|---|---|
| Water (11) | Water |
| Perennial ice/snow (12) | Ice and Snow |
| Developed, open space (21) | Developed |
| Developed, low intensity (22) | Developed |
| Developed, medium intensity (23) | Developed |
| Developed, high intensity (24) | Developed |
| Barren (31) | Barren |
| Deciduous forest (41) | Tree Cover |
| Evergreen forest (42) | Tree Cover |
| Mixed forest (43) | Tree Cover |
| Shrubland (52) | Grass/shrub |
| Grassland (71) | Grass/shrub |
| Pasture (81) | Cropland |
| Cultivated crops (82) | Cropland |
| Woody wetlands (90) | Wetland |
| Herbaceous wetland (95) | Wetland |
| Tile | Developed | Cropland | Grass/Shrub | Tree | Water | Wetland | Snow Ice | Barren |
|---|---|---|---|---|---|---|---|---|
| H03V09 | 1.5 | 2.4 | 47.3 | 39.0 | 2.1 | 0.4 | 0 | 7 |
| H03V10 | 6.0 | 33.1 | 28.6 | 21.9 | 0.8 | 0.3 | 0 | 4.8 |
| H05V02 | 3.2 | 36.5 | 47.1 | 6.7 | 2.9 | 1.1 | 0 | 0 |
| H05V03 | 4.6 | 44.7 | 37.4 | 10.2 | 1.6 | 0.5 | 0 | 0 |
| H13V06 | 2.0 | 5.8 | 71.0 | 12.9 | 0.5 | 1.5 | 0 | 5.5 |
| H20V15 | 6.9 | 8.7 | 13.6 | 47.1 | 2.3 | 11.9 | 0 | 0.2 |
| H21V08 | 17.6 | 69.7 | 1.8 | 4.4 | 2.7 | 1.4 | 0 | 0.2 |
| H28V08 | 27.5 | 18.1 | 2.7 | 19.3 | 11.8 | 9.4 | 0 | 0.3 |
| Tile | 20K | 200K | 2M | 20M | 100M | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | STD | Accuracy | STD | Accuracy | STD | Accuracy | STD | Accuracy | STD | |
| H03V09 | 0.84 | 0.0135 | 0.89 | 0.0025 | 0.92 | 0.0007 | 0.94 | 0.0002 | 0.94 | 0.0001 |
| H03V10 | 0.83 | 0.0130 | 0.88 | 0.0022 | 0.91 | 0.0006 | 0.94 | 0.0002 | 0.94 | 0.0001 |
| H05V02 | 0.85 | 0.0105 | 0.88 | 0.0022 | 0.91 | 0.0009 | 0.93 | 0.0002 | 0.93 | 0.0001 |
| H05V03 | 0.84 | 0.0070 | 0.89 | 0.0029 | 0.91 | 0.0005 | 0.94 | 0.0002 | 0.94 | 0.0000 |
| H13V06 | 0.79 | 0.0097 | 0.85 | 0.0026 | 0.89 | 0.0008 | 0.91 | 0.0002 | 0.93 | 0.0001 |
| H20V15 | 0.84 | 0.0052 | 0.88 | 0.0022 | 0.90 | 0.0008 | 0.92 | 0.0002 | 0.93 | 0.0001 |
| H21V08 | 0.78 | 0.0102 | 0.83 | 0.0023 | 0.86 | 0.0006 | 0.90 | 0.0002 | 0.93 | 0.0001 |
| H28V08 | 0.80 | 0.0137 | 0.83 | 0.0024 | 0.86 | 0.0010 | 0.89 | 0.0002 | 0.91 | 0.0001 |
| Tile | 20K | 200K | 2M | 20M | 100M |
|---|---|---|---|---|---|
| H03V09 | 0.04 | 0.06 | 0.25 | 2.62 | 11.54 |
| H03V10 | 0.04 | 0.05 | 0.24 | 2.36 | 10.33 |
| H05V02 | 0.04 | 0.06 | 0.35 | 3.25 | 13.90 |
| H05V03 | 0.04 | 0.06 | 0.32 | 3.08 | 13.84 |
| H13V06 | 0.04 | 0.05 | 0.20 | 1.97 | 8.06 |
| H20V15 | 0.04 | 0.05 | 0.23 | 2.81 | 13.27 |
| H21V08 | 0.05 | 0.06 | 0.28 | 2.23 | 9.90 |
| H28V08 | 0.04 | 0.05 | 0.30 | 2.86 | 13.02 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Q.; Tollerud, H.; Barber, C.; Smith, K.; Zelenak, D. Training Data Selection for Annual Land Cover Classification for the Land Change Monitoring, Assessment, and Projection (LCMAP) Initiative. Remote Sens. 2020, 12, 699. https://doi.org/10.3390/rs12040699
Zhou Q, Tollerud H, Barber C, Smith K, Zelenak D. Training Data Selection for Annual Land Cover Classification for the Land Change Monitoring, Assessment, and Projection (LCMAP) Initiative. Remote Sensing. 2020; 12(4):699. https://doi.org/10.3390/rs12040699
Chicago/Turabian StyleZhou, Qiang, Heather Tollerud, Christopher Barber, Kelcy Smith, and Daniel Zelenak. 2020. "Training Data Selection for Annual Land Cover Classification for the Land Change Monitoring, Assessment, and Projection (LCMAP) Initiative" Remote Sensing 12, no. 4: 699. https://doi.org/10.3390/rs12040699
APA StyleZhou, Q., Tollerud, H., Barber, C., Smith, K., & Zelenak, D. (2020). Training Data Selection for Annual Land Cover Classification for the Land Change Monitoring, Assessment, and Projection (LCMAP) Initiative. Remote Sensing, 12(4), 699. https://doi.org/10.3390/rs12040699