Woody Cover Fractions in African Savannas From Landsat and High-Resolution Imagery


Abstract
:
1. Introduction
2. Materials and Methods
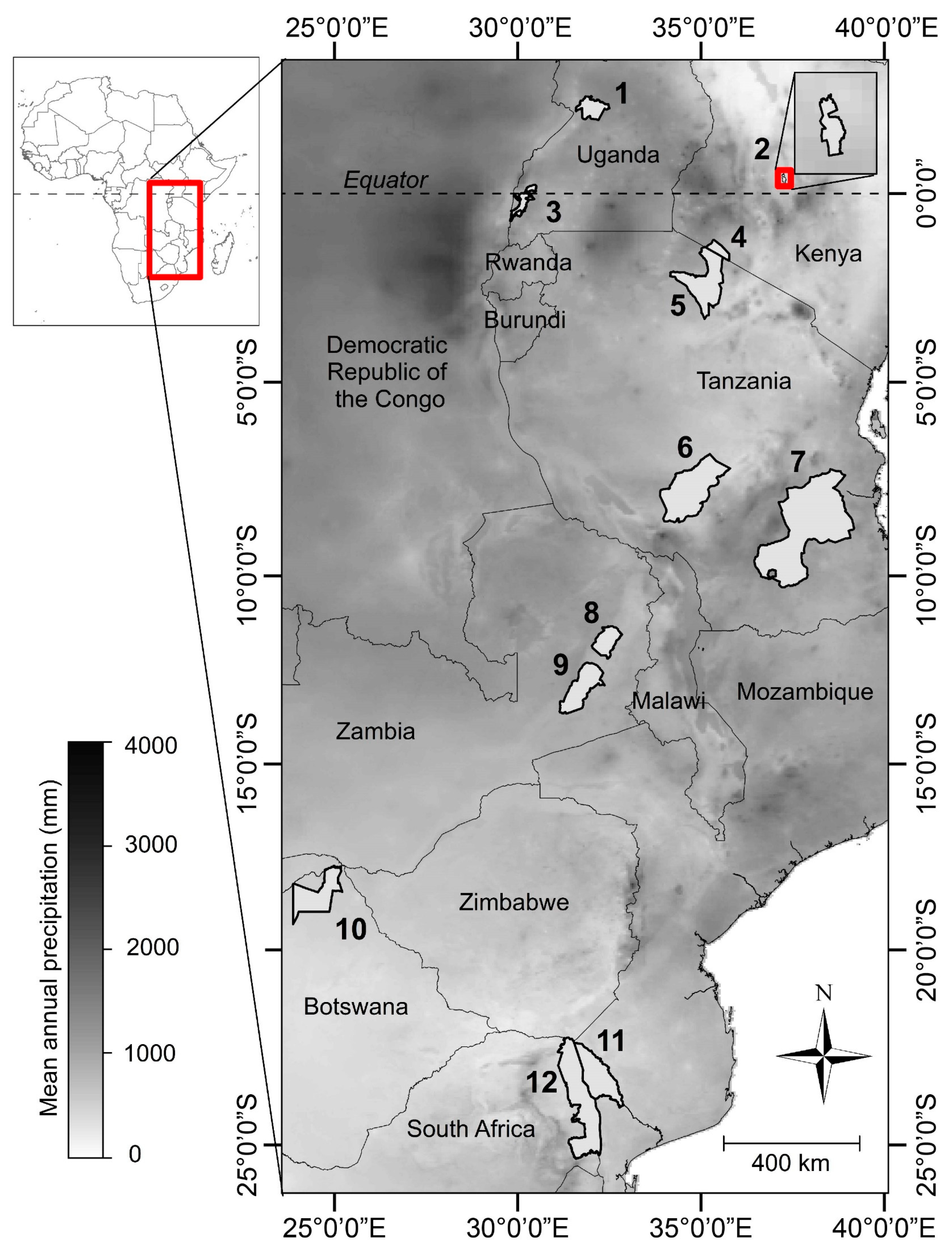
2.1. Study Sites
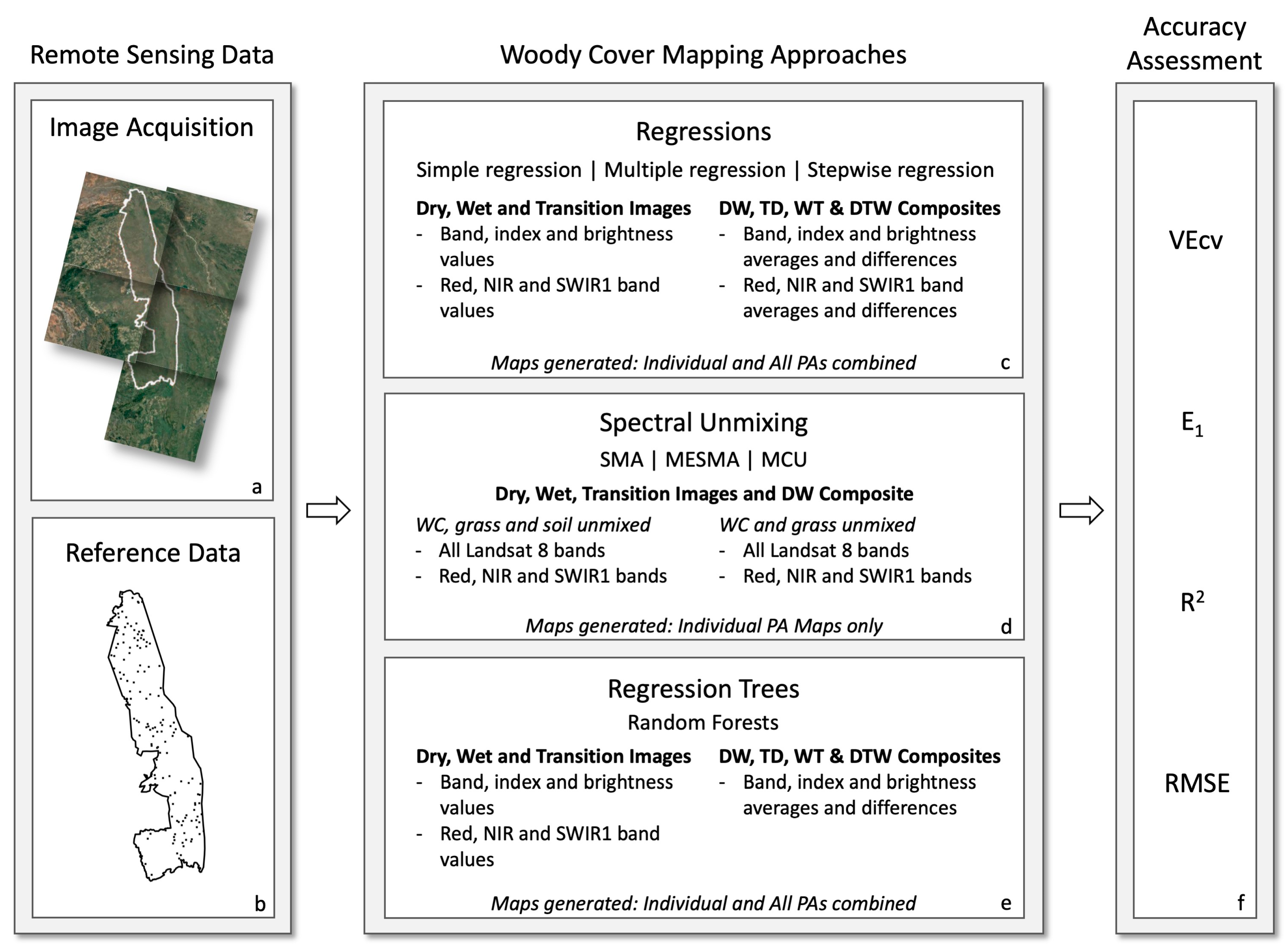
2.2. Remote Sensing Data
2.2.1. Reference Data
2.2.2. Landsat Image Collection and Processing
2.3. Mapping Woody Cover
2.3.1. Linear Regression
2.3.2. Spectral Unmixing
2.3.3. Regression Trees
2.4. Accuracy Assessment
2.5. Post-Processing
3. Results and Discussion
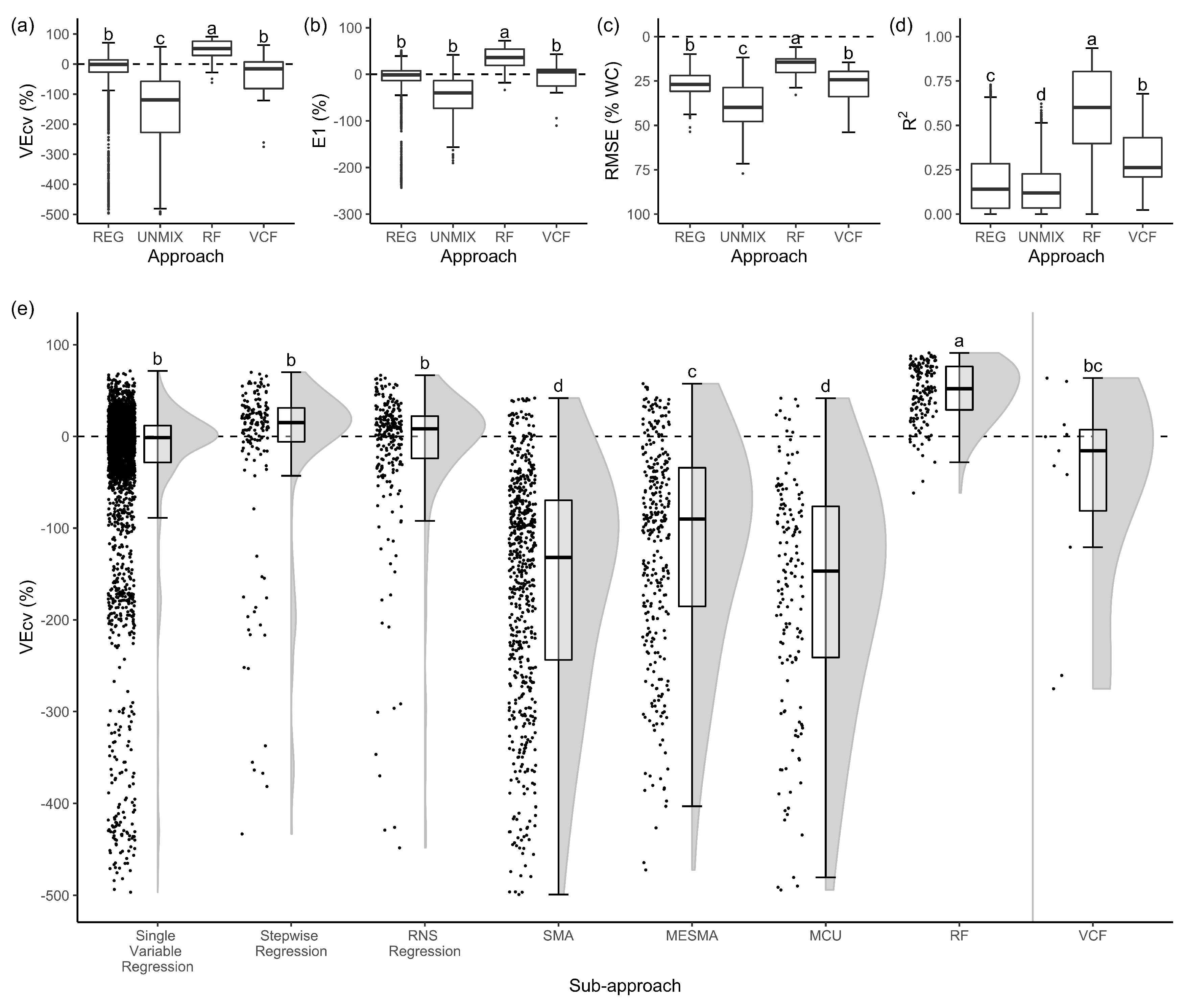
3.1. Evaluation of Accuracy Measures
3.2. Best Approaches and Sub-Approaches
3.3. Evaluation of Seasonal Images
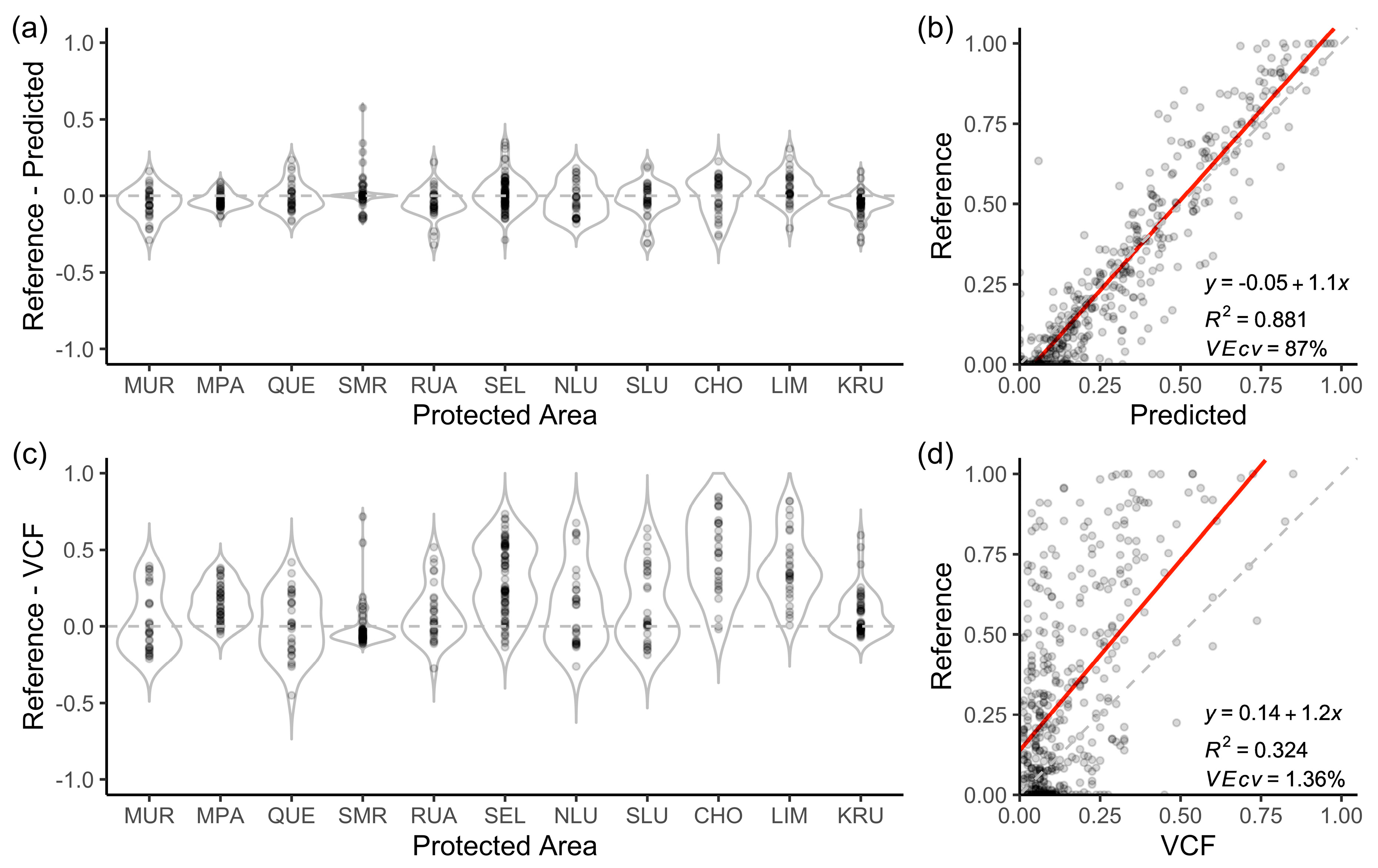
3.4. Evaluation of Protected Area Accuracies
3.5. Evaluation of Variables
3.6. Best Models
3.7. Map Comparisons
3.8. Caveats and Concerns
4. Conclusions
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Channan, S.; Collins, K.; Emanuel, W.R. Global mosaics of the standard MODIS land cover type data. Univ. Md. Pac. Northwest Natl. Lab. 2014, 30. [Google Scholar]
- Olson, D.M.; Dinerstein, E.; Wikramanayake, E.D.; Burgess, N.D.; Powell, G.V.N.; Underwood, E.C.; D’amico, J.A.; Itoua, I.; Strand, H.E.; Morrison, J.C.; et al. Terrestrial Ecoregions of the World: A New Map of Life on Earth. Bioscience 2001, 51, 933. [Google Scholar] [CrossRef]
- CIESIN. Gridded Population of the World, Version 4 (GPWv4): Population Count; NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA, 2016. [Google Scholar]
- Scholes, R.J.; Archer, S.R. Tree-Grass Interactions in Savannas. For. Sci. 1997, 517–544. [Google Scholar] [CrossRef]
- Reid, R. Savannas of Our Birth: People, Wildlife, and Change in East Africa, 1st ed.; University of California Press: Berkeley, CA, USA, 2012; ISBN 9780520273559. [Google Scholar]
- Malhi, Y.; Doughty, C.E.; Galetti, M.; Smith, F.A.; Svenning, J.; Terborgh, J.W. Megafauna and ecosystem function from the Pleistocene to the Anthropocene. Proc. Natl. Acad. Sci. USA 2016, 113, 838–846. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Balmford, A.; Green, J.M.H.; Anderson, M.; Beresford, J.; Huang, C.; Naidoo, R.; Walpole, M.; Manica, A. Walk on the Wild Side: Estimating the Global Magnitude of Visits to Protected Areas. PLoS Biol. 2015, 13, 1–6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naidoo, R.; Fisher, B.; Manica, A.; Balmford, A. Estimating economic losses to tourism in Africa from the illegal killing of elephants. Nat. Commun. 2016, 7, 13379. [Google Scholar] [CrossRef] [PubMed]
- Ahlström, A.; Raupach, M.R.; Schurgers, G.; Smith, B.; Arneth, A.; Jung, M.; Reichstein, M.; Canadell, J.G.; Friedlingstein, P.; Jain, A.K.; et al. The dominant role of semi-arid ecosystems in the trend and variability of the land CO2 sink. Science 2015, 348, 895–899. [Google Scholar] [CrossRef] [Green Version]
- Poulter, B.; Frank, D.; Ciais, P.; Myneni, R.B.; Andela, N.; Bi, J.; Broquet, G.; Canadell, J.G.; Chevallier, F.; Liu, Y.Y.; et al. Contribution of semi-arid ecosystems to interannual variability of the global carbon cycle. Nature 2014, 509, 600–603. [Google Scholar] [CrossRef] [Green Version]
- Gray, E.F.; Bond, W.J. Will woody plant encroachment impact the visitor experience and economy of conservation areas? Koedoe 2013, 55, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Smit, I.P.J.; Prins, H.H.T. Predicting the Effects of Woody Encroachment on Mammal Communities, Grazing Biomass and Fire Frequency in African Savannas. PLoS ONE 2015, 10, e0137857. [Google Scholar] [CrossRef] [Green Version]
- Belsky, A.J.; Amundson, R.G.; Duxbury, J.M.; Riha, S.J.; Ali, A.R.; Mwongat, S.M. The Effects of Trees on Their Physical, Chemical and Biological Environments in a Semi-Arid Savanna in Kenya. J. Appl. Ecol. 1989, 26, 1005–1024. [Google Scholar] [CrossRef]
- Bond, W.J. Large parts of the world are brown or black: A different view on the ‘Green World’ hypothesis. J. Veg. Sci. 2005, 16, 261–266. [Google Scholar] [CrossRef]
- Sankaran, M.; Hanan, N.P.; Scholes, R.J.; Ratnam, J.; Augustine, D.J.; Cade, B.S.; Gignoux, J.; Higgins, S.I.; Le Roux, X.; Ludwig, F.; et al. Determinants of woody cover in African savannas. Nature 2005, 438, 846–849. [Google Scholar] [CrossRef] [PubMed]
- Sankaran, M.; Ratnam, J.; Hanan, N. Woody cover in African savannas: the role of resources, fire and herbivory. Glob. Ecol. Biogeogr. 2008, 17, 236–245. [Google Scholar] [CrossRef]
- Holling, C.S. Resilience and stability of ecological systems. Annu. Rev. Ecol. Syst. 1973, 4, 1–23. [Google Scholar] [CrossRef] [Green Version]
- May, R.M. Thresholds and breakpoints in ecosystms with a multiplicity of stable states. Nature 1976, 260, 471–477. [Google Scholar]
- Smit, I.P.J.; Asner, G.P.; Govender, N.; Kennedy-Bowdoin, T.; Knapp, D.E.; Jacobson, J. Effects of fire on woody vegetation structure in African savanna. Ecol. Appl. 2010, 20, 1865–1875. [Google Scholar] [CrossRef] [PubMed]
- Bond, W.; Keeley, J. Fire as a global ‘herbivore’: the ecology and evolution of flammable ecosystems. Trends Ecol. Evol. 2005, 20, 387–394. [Google Scholar] [CrossRef]
- Hantson, S.; Scheffer, M.; Pueyo, S.; Xu, C.; Lasslop, G.; Van Nes, E.H.; Holmgren, M.; Mendelsohn, J. Rare, Intense, Big fires dominate the global tropics under drier conditions. Sci. Rep. 2017, 7, 7–11. [Google Scholar] [CrossRef]
- Porensky, L.M.; Wittman, S.E.; Riginos, C.; Young, T.P. Herbivory and drought interact to enhance spatial patterning and diversity in a savanna understory. Oecologia 2013, 173, 591–602. [Google Scholar] [CrossRef]
- Good, S.P.; Caylor, K.K. Climatological determinants of woody cover in Africa. Proc. Natl. Acad. Sci. USA 2011, 108, 4902–4907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Der Waal, C.; De Kroon, H.; De Boer, W.F.; Heitkönig, I.M.A.; Skidmore, A.K.; De Knegt, H.J.; Van Langevelde, F.; Van Wieren, S.E.; Grant, R.C.; Page, B.R.; et al. Water and nutrients alter herbaceous competitive effects on tree seedlings in a semi-arid savanna. J. Ecol. 2009, 97, 430–439. [Google Scholar] [CrossRef]
- Asner, G.P.; Vaughn, N.; Smit, I.P.J.; Levick, S. Ecosystem-scale effects of megafauna in African savannas. Ecography Cop. 2016, 39, 240–252. [Google Scholar] [CrossRef]
- Traore, S.; Tigabu, M.; Jouquet, P.; Ouedraogo, S.J.; Guinko, S.; Lepage, M. Long-term effects of Macrotermes termites, herbivores and annual early fire on woody undergrowth community in Sudanian woodland, Burkina Faso. Flora Morphol. Distrib. Funct. Ecol. Plants 2015, 211, 40–50. [Google Scholar] [CrossRef]
- Staver, A.C.; Bond, W.J. Is there a “browse trap”? Dynamics of herbivore impacts on trees and grasses in an African savanna. J. Ecol. 2014, 102, 595–602. [Google Scholar] [CrossRef]
- Holdo, R.M.; Sinclair, A.R.E.; Dobson, A.P.; Metzger, K.L.; Bolker, B.M.; Ritchie, M.E.; Holt, R.D. A disease-mediated trophic cascade in the Serengeti and its implications for ecosystem C. PLoS Biol. 2009, 7, e1000210. [Google Scholar] [CrossRef] [Green Version]
- Lehmann, C.E.R.; Anderson, T.M.; Sankaran, M.; Higgins, S.I.; Archibald, S.; Hoffmann, W.A.; Hanan, N.P.; Williams, R.J.; Fensham, R.J.; Felfili, J.; et al. Savanna Vegetation-Fire-Climate Relationships Differ Among Continents. Science 2014, 343, 548–553. [Google Scholar] [CrossRef]
- Staver, A.C. Prediction and scale in savanna ecosystems. N. Phytol. 2018, 219, 52–57. [Google Scholar] [CrossRef] [Green Version]
- Staver, A.C.; Archibald, S.; Levin, S.A. The Global Extent and Determinants of Savanna and Forest as Alternative Biome States. Science 2011, 334, 230–232. [Google Scholar] [CrossRef] [Green Version]
- Hirota, M.; Holmgren, M.; Van Nes, E.H.; Scheffer, M. Global Resilience of Tropical Forest and Savanna to Critical Transitions. Science 2011, 334, 232–235. [Google Scholar] [CrossRef] [Green Version]
- Scheffer, M.; Hirota, M.; Holmgren, M.; Van Nes, E.H.; Chapin, F.S. Thresholds for boreal biome transitions. Proc. Natl. Acad. Sci. USA 2012, 109, 21384–21389. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Favier, C.; Aleman, J.; Bremond, L.; Dubois, M.A.; Freycon, V.; Yangakola, J.M. Abrupt shifts in African savanna tree cover along a climatic gradient. Glob. Ecol. Biogeogr. 2012, 21, 787–797. [Google Scholar] [CrossRef]
- Murphy, B.P.; Bowman, D.M.J.S. What controls the distribution of tropical forest and savanna? Ecol. Lett. 2012, 15, 748–758. [Google Scholar] [CrossRef] [PubMed]
- Ratajczak, Z.; Nippert, J.B. Comment on “Global Resilience of to Critical Transitions”. Science 2012, 336, 541c–541d. [Google Scholar] [CrossRef] [Green Version]
- Hansen, M.C.; DeFries, R.S.; Townshend, J.R.G.; Carroll, M.; Dimiceli, C.; Sohlberg, R.A. Global Percent Tree Cover at a Spatial Resolution of 500 Meters: First Results of the MODIS Vegetation Continuous Fields Algorithm. Earth Interact. 2003, 7, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Staver, A.C.; Hansen, M.C. Analysis of stable states in global savannas: Is the CART pulling the horse? - a comment. Glob. Ecol. Biogeogr. 2015, 24, 985–987. [Google Scholar] [CrossRef]
- Hanan, N.P.; Tredennick, A.T.; Prihodko, L.; Bucini, G.; Dohn, J. Analysis of stable states in global savannas: Is the CART pulling the horse? Glob. Ecol. Biogeogr. 2014, 23, 259–263. [Google Scholar] [CrossRef]
- Hanan, N.P.; Tredennick, A.T.; Prihodko, L.; Bucini, G.; Dohn, J. Analysis of stable states in global savannas - A response to Staver and Hansen. Glob. Ecol. Biogeogr. 2015, 24, 988–989. [Google Scholar] [CrossRef]
- Levick, S.R.; Asner, G.P.; Kennedy-Bowdoin, T.; Knapp, D.E. The relative influence of fire and herbivory on savanna three-dimensional vegetation structure. Biol. Conserv. 2009, 142, 1693–1700. [Google Scholar] [CrossRef]
- Asner, G.P.; Levick, S.R. Landscape-scale effects of herbivores on treefall in African savannas. Ecol. Lett. 2012, 15, 1211–1217. [Google Scholar] [CrossRef]
- Levick, S.R.; Asner, G.P. The rate and spatial pattern of treefall in a savanna landscape. Biol. Conserv. 2013, 157, 121–127. [Google Scholar] [CrossRef]
- Asner, G.P.; Levick, S.R.; Kennedy-Bowdoin, T.; Knapp, D.E.; Emerson, R.; Jacobson, J.; Colgan, M.S.; Martin, R.E. Large-scale impacts of herbivores on the structural diversity of African savannas. Proc. Natl. Acad. Sci. USA 2009, 106, 4947–4952. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Settle, J.J.; Drake, N.A. Linear mixing and the estimation of ground cover proportions. Int. J. Remote Sens. 1993, 14, 1159–1177. [Google Scholar] [CrossRef]
- Lawton, W.H.; Sylvestre, E.A. Self Modeling Curve Resolution. Technometrics 1971, 13, 617–633. [Google Scholar] [CrossRef]
- Choodarathnakara, A.L.; Kumar, T.A.; Koliwad, S. Mixed Pixels: A Challenge in Remote Sensing Data Classification for Improving Performance. Int. J. Adv. Res. Comput. Eng. Technol. 2012, 1, 261. [Google Scholar]
- Ringrose, S.; Matheson, W.; Mogotsi, B.; Tempest, F. The darkening effect in drought affected savanna woodland environments relative to soil reflectance in Landsat and SPOT wavebands. Remote Sens. Environ. 1989, 30, 1–19. [Google Scholar] [CrossRef]
- Dawelbait, M.; Morari, F. Limits and potentialities of studying dryland vegetation using the optical remote sensing. Ital. J. Agron. 2008, 3, 97–106. [Google Scholar] [CrossRef] [Green Version]
- Poitras, T.B.; Villarreal, M.L.; Waller, E.K.; Nauman, T.W.; Miller, M.E.; Duniway, M.C. Identifying optimal remotely-sensed variables for ecosystem monitoring in Colorado Plateau drylands. J. Arid Environ. 2018, 153, 76–87. [Google Scholar] [CrossRef]
- Yang, X.; Crews, K. Fractional Woody Cover Mapping of Texas Savanna at Landsat Scale. Land 2019, 8, 9. [Google Scholar] [CrossRef] [Green Version]
- Marston, C.; Aplin, P.; Wilkinson, D.; Field, R.; O’Regan, H. Scrubbing Up: Multi-Scale Investigation of Woody Encroachment in a Southern African Savannah. Remote Sens. 2017, 9, 419. [Google Scholar] [CrossRef] [Green Version]
- Asner, G.P.; Lobell, D.B. A biogeophysical approach for automated SWIR unmixing of soils and vegetation. Remote Sens. Environ. 2000, 74, 99–112. [Google Scholar] [CrossRef]
- Bastin, J.; Berrahmouni, N.; Grainger, A.; Maniatis, D.; Mollicone, D.; Moore, R.; Patriarca, C.; Picard, N.; Sparrow, B.; Abraham, E.M.; et al. The extent of forest in dryland biomes. Science 2017, 356, 635–638. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Messina, M.; Cunliffe, R.; Farcomeni, A.; Malatesta, L.; Smit, I.P.J.; Testolin, R.; Ribeiro, N.S.; Nhancale, B.; Vitale, M.; Attorre, F. An innovative approach to disentangling the effect of management and environment on tree cover and density of protected areas in African savanna. For. Ecol. Manag. 2018, 419, 1–9. [Google Scholar] [CrossRef]
- Skowno, A.L.; Thompson, M.W.; Hiestermann, J.; Ripley, B.; West, A.G.; Bond, W.J. Woodland expansion in South African grassy biomes based on satellite observations (1990–2013): general patterns and potential drivers. Glob. Chang. Biol. 2017, 23, 2358–2369. [Google Scholar] [CrossRef] [PubMed]
- Ward, D.; Hoffman, M.T.; Collocott, S.J. A century of woody plant encroachment in the dry Kimberley savanna of South Africa. Afr. J. Range Forage Sci. 2014, 31, 107–121. [Google Scholar] [CrossRef]
- Western, D.; Maitumo, D. Woodland loss and restoration in a savanna park: a 20-year experiment. Afr. J. Ecol. 2004, 42, 111–121. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Loveland, T.R.; Woodcock, C.E.; Belward, A.S.; Cohen, W.B.; Fosnight, E.A.; Shaw, J.; Masek, J.G.; Roy, D.P. The global Landsat archive: Status, consolidation, and direction. Remote Sens. Environ. 2016, 185, 271–283. [Google Scholar] [CrossRef] [Green Version]
- Archibald, S.; Staver, A.C.; Levin, S.A. Evolution of human-driven fire regimes in Africa. Proc. Natl. Acad. Sci. USA 2012, 109, 847–852. [Google Scholar] [CrossRef] [Green Version]
- Archibald, S.; Lehmann, C.E.R.; Gómez-dans, J.L.; Bradstock, R.A. Defining pyromes and global syndromes of fire regimes. Proc. Natl. Acad. Sci. USA 2013, 110, 6442–6447. [Google Scholar] [CrossRef] [Green Version]
- Bowman, D.M.J.S.; Balch, J.; Artaxo, P.; Bond, W.J.; Cochrane, M.A.; D’Antonio, C.M.; DeFries, R.; Johnston, F.H.; Keeley, J.E.; Krawchuk, M.A.; et al. The human dimension of fire regimes on Earth. J. Biogeogr. 2011, 38, 2223–2236. [Google Scholar] [CrossRef] [Green Version]
- Funk, C.; Peterson, P.; Landsfeld, M.; Pedreros, D.; Verdin, J.; Shukla, S.; Husak, G.; Rowland, J.; Harrison, L.; Hoell, A.; et al. The climate hazards infrared precipitation with stations—a new environmental record for monitoring extremes. Sci. Data 2015, 2, 150066. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pengra, B.; Long, J.; Dahal, D.; Stehman, S.V.; Loveland, T.R. A global reference database from very high resolution commercial satellite data and methodology for application to Landsat derived 30m continuous field tree cover data. Remote Sens. Environ. 2015, 165, 234–248. [Google Scholar] [CrossRef]
- Michishita, R.; Jiang, Z.; Xu, B. Monitoring two decades of urbanization in the Poyang Lake area, China through spectral unmixing. Remote Sens. Environ. 2012, 117, 3–18. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–854. [Google Scholar] [CrossRef] [Green Version]
- Bey, A.; Díaz, A.S.P.; Maniatis, D.; Marchi, G.; Mollicone, D.; Ricci, S.; Bastin, J.F.; Moore, R.; Federici, S.; Rezende, M.; et al. Collect earth: Land use and land cover assessment through augmented visual interpretation. Remote Sens. 2016, 8, 807. [Google Scholar] [CrossRef] [Green Version]
- Nagelkirk, R.L.; Dahlin, K.M. Data from: Woody cover fractions in African savannas from Landsat and high-resolution imagery. Mendeley Data 2019, 1. Available online: https://data.mendeley.com/datasets/26djkgjzhf/1 (accessed on 2 March 2020).
- Loecher, M.; Ropkins, K. RgoogleMaps and loa: Unleashing R Graphics Power on Map Tiles. J. Stat. Softw. 2015, 63, 1–18. [Google Scholar] [CrossRef] [Green Version]
- R Core Team R. A language and environment for statistical computing; R Foundation for Statistical Computing: St. Louis, MO, USA; p. 2018.
- Motohka, T.; Nasahara, K.N.; Oguma, H.; Tsuchida, S. Applicability of Green-Red Vegetation Index for remote sensing of vegetation phenology. Remote Sens. 2010, 2, 2369–2387. [Google Scholar] [CrossRef] [Green Version]
- Qi, J.; Chehbouni, A.; Huete, A.R.; Kerr, Y.H.; Sorooshian, S. A modified soil adjusted vegetation index. Remote Sens. Environ. 1994, 48, 119–126. [Google Scholar] [CrossRef]
- Marsett, R.C.; Qi, J.; Heilman, P.; Biedenbender, S.H.; Watson, M.C.; Amer, S.; Weltz, M.; Goodrich, D.; Marsett, R. Remote sensing for grassland management in the arid Southwest. Rangel. Ecol. Manag. 2006, 59, 530–540. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Google Fusion Tables Team Notice: Google Fusion Tables Turndown. Available online: https://support.google.com/fusiontables/answer/9185417?hl=en (accessed on 2 March 2020).
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef] [Green Version]
- Brandt, M.; Tappan, G.; Diouf, A.A.; Beye, G.; Mbow, C.; Fensholt, R. Woody vegetation die off and regeneration in response to rainfall variability in the west african sahel. Remote Sens. 2017, 9, 39. [Google Scholar] [CrossRef] [Green Version]
- Bucini, G.; Saatchi, S.; Hanan, N.; Boone, R.B.; Smit, I. Woody cover and heterogeneity in the savannas of the Kruger National Park, South Africa. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Cape Town, South Africa, 12–17 July 2009; 4, pp. 334–337. [Google Scholar]
- Gizachew, B.; Solberg, S.; Næsset, E.; Gobakken, T.; Bollandsås, O.M.; Breidenbach, J.; Zahabu, E.; Mauya, E.W. Mapping and estimating the total living biomass and carbon in low-biomass woodlands using Landsat 8 CDR data. Carbon Balance Manag. 2016, 11, 13. [Google Scholar] [CrossRef] [Green Version]
- De Bie, S.; Ketner, P.; Paasse, M.; Geerling, C. Woody plant phenology in the West Africa savanna. J. Biogeogr. 1998, 25, 883–900. [Google Scholar] [CrossRef]
- Horion, S.; Fensholt, R.; Tagesson, T.; Ehammer, A. Using earth observation-based dry season NDVI trends for assessment of changes in tree cover in the Sahel. Int. J. Remote Sens. 2014, 35, 2493–2515. [Google Scholar] [CrossRef]
- Wagenseil, H.; Samimi, C. Woody vegetation cover in Namibian savannahs: a modelling approach based on remote sensing. Erdkunde 2007, 61, 325–334. [Google Scholar] [CrossRef] [Green Version]
- Murphy, P.G.; Lugo, A.E. Ecology of Tropical Dry Forest. Annu. Rev. Ecol. Syst. 1986, 17, 67–88. [Google Scholar] [CrossRef]
- Santiago, L.S.; Kitajima, K.; Wright, S.J.; Mulkey, S.S. Coordinated changes in photosynthesis, water relations and leaf nutritional traits of canopy trees along a precipitation gradient in lowland tropical forest. Oecologia 2004, 139, 495–502. [Google Scholar] [CrossRef] [Green Version]
- Gasparri, N.I.; Parmuchi, M.G.; Bono, J.; Karszenbaum, H.; Montenegro, C.L. Assessing multi-temporal Landsat 7 ETM+ images for estimating above-ground biomass in subtropical dry forests of Argentina. J. Arid Environ. 2010, 74, 1262–1270. [Google Scholar] [CrossRef]
- Brandt, M.; Hiernaux, P.; Tagesson, T.; Verger, A.; Rasmussen, K.; Diouf, A.A.; Mbow, C.; Mougin, E.; Fensholt, R. Woody plant cover estimation in drylands from Earth Observation based seasonal metrics. Remote Sens. Environ. 2016, 172, 28–38. [Google Scholar] [CrossRef] [Green Version]
- Hansen, M.C.; Loveland, T.R. A review of large area monitoring of land cover change using Landsat data. Remote Sens. Environ. 2012, 122, 66–74. [Google Scholar] [CrossRef]
- Neter, J.; Wasserman, W. Applied linear statistical models: regression, analysis of variance, and experimental designs, 1st ed.; Richard Irwin: Chicago, IL, USA, 1974; ISBN 0-256-01498-1. [Google Scholar]
- Yang, J.; Weisberg, P.J.; Bristow, N.A. Landsat remote sensing approaches for monitoring long-term tree cover dynamics in semi-arid woodlands: Comparison of vegetation indices and spectral mixture analysis. Remote Sens. Environ. 2012, 119, 62–71. [Google Scholar] [CrossRef]
- Adams, J.B.; Smith, M.O.; Johnson, P.E. Spectral mixture modeling: A new analysis of rock and soil types at the Viking Lander 1 Site. J. Geophys. Res. Solid Earth 1986, 91, 8098–8112. [Google Scholar] [CrossRef]
- Smith, M.O.; Adams, J.B.; Johnson, P.E. Quantitative determination of mineral types and abundances from reflectance spectra using principal components analysis. J. Geophys. Res. 1985, 90, C797–C804. [Google Scholar] [CrossRef]
- Roberts, D.; Halligan, K.; Dennison, P. VIPER Tools User Manual V1.5. 2007, 1–91. [Google Scholar]
- Roberts, D.A.; Smith, M.O.; Adams, J.B. Green vegetation, nonphotosynthetic vegetation, and soils in AVIRIS data. Remote Sens. Environ. 1993, 44, 255–269. [Google Scholar] [CrossRef]
- Roberts, D.A.; Gardner, M.; Church, R.; Ustin, S.; Scheer, G.; Green, R.O. Mapping chaparral in the Santa Monica Mountains using multiple endmember spectral mixture models. Remote Sens. Environ. 1998, 65, 267–279. [Google Scholar] [CrossRef]
- Fernández-Manso, A.; Quintano, C.; Roberts, D. Evaluation of potential of multiple endmember spectral mixture analysis (MESMA) for surface coal mining affected area mapping in different world forest ecosystems. Remote Sens. Environ. 2012, 127, 181–193. [Google Scholar] [CrossRef]
- Dennison, P.E.; Roberts, D.A. Endmember selection for multiple endmember spectral mixture analysis using endmember average RMSE. Remote Sens. Environ. 2003, 87, 123–135. [Google Scholar] [CrossRef]
- Roberts, D.A.; Dennison, P.E.; Gardner, M.E.; Hetzel, Y.; Ustin, S.L.; Lee, C.T. Evaluation of the potential of Hyperion for fire danger assessment by comparison to the airborne visible/infrared imaging spectrometer. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1297–1310. [Google Scholar] [CrossRef]
- Dennison, P.E.; Halligan, K.Q.; Roberts, D.A. A comparison of error metrics and constraints for multiple endmember spectral mixture analysis and spectral angle mapper. Remote Sens. Environ. 2004, 93, 359–367. [Google Scholar] [CrossRef]
- Asner, G.P.; Bustamante, M.M.C.; Townsend, A.R. Scale dependence of biophysical structure in deforested areas bordering the Tapajós National Forest, Central Amazon. Remote Sens. Environ. 2003, 87, 507–520. [Google Scholar] [CrossRef]
- Asner, G.P.; Knapp, D.E.; Balaji, A.; Paez-Acosta, G. Automated mapping of tropical deforestation and forest degradation: CLASlite. J. Appl. Remote Sens. 2009, 3, 33543. [Google Scholar] [CrossRef]
- Hansen, M.C.; DeFries, R.S.; Townshend, J.R.G.; Sohlberg, R.; Dimiceli, C.; Carroll, M. Towards an operational MODIS continuous field of percent tree cover algorithm: Examples using AVHRR and MODIS data. Remote Sens. Environ. 2002, 83, 303–319. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Naidoo, L.; Cho, M.A.; Mathieu, R.; Asner, G. Classification of savanna tree species, in the Greater Kruger National Park region, by integrating hyperspectral and LiDAR data in a Random Forest data mining environment. ISPRS J. Photogramm. Remote Sens. 2012, 69, 167–179. [Google Scholar] [CrossRef]
- Gessner, U.; Machwitz, M.; Conrad, C.; Dech, S. Estimating the fractional cover of growth forms and bare surface in savannas. A multi-resolution approach based on regression tree ensembles. Remote Sens. Environ. 2013, 129, 90–102. [Google Scholar] [CrossRef] [Green Version]
- Symeonakis, E.; Petroulaki, K.; Higginbottom, T. Landsat-based woody vegetation cover monitoring in Southern African savannahs. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2016, 41, 563–567. [Google Scholar] [CrossRef]
- Zhang, H.K.; Roy, D.P. Using the 500 m MODIS land cover product to derive a consistent continental scale 30 m Landsat land cover classification. Remote Sens. Environ. 2017, 197, 15–34. [Google Scholar] [CrossRef]
- Vogeler, J.C.; Yang, Z.; Cohen, W.B. Mapping post-fire habitat characteristics through the fusion of remote sensing tools. Remote Sens. Environ. 2016, 173, 294–303. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Wulder, M.A.; Coops, N.C.; Roy, D.P.; White, J.C.; Hermosilla, T. Land cover 2.0. Int. J. Remote Sens. 2018, 39, 4254–4284. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Li, J. Assessing the accuracy of predictive models for numerical data: Not r nor r2, why not? Then what? PLoS ONE 2017, 12, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Schloeder, C.A.; Jacobs, N. Comparison of methods for interpolating soil properties using limited data. Soil Sci. Soc. Am. J. 2001, 65, 470–479. [Google Scholar] [CrossRef]
- Nash, E.; Sutcliffe, V. River flow forecasting through conceptual models Part I - A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J. A refined index of model performance: A rejoinder. Int. J. Climatol. 2013, 33, 1053–1056. [Google Scholar] [CrossRef]
- Sexton, J.O.; Song, X.-P.; Feng, M.; Noojipady, P.; Anand, A.; Huang, C.; Kim, D.-H.; Collins, K.M.; Channan, S.; DiMiceli, C.; et al. Global, 30-m resolution continuous fields of tree cover: Landsat-based rescaling of MODIS vegetation continuous fields with lidar-based estimates of error. Int. J. Digit. Earth 2013, 6, 427–448. [Google Scholar]
- Powell, R.L.; Roberts, D.A.; Dennison, P.E.; Hess, L.L. Sub-pixel mapping of urban land cover using multiple endmember spectral mixture analysis: Manaus, Brazil. Remote Sens. Environ. 2007, 106, 253–267. [Google Scholar] [CrossRef]
- Degerickx, J.; Roberts, D.A.; Somers, B. Enhancing the performance of Multiple Endmember Spectral Mixture Analysis (MESMA) for urban land cover mapping using airborne lidar data and band selection. Remote Sens. Environ. 2019, 221, 260–273. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PA # | Name and Country | Abbr. | Latitude (Degrees) | Elev. (m) | MAP (mm) | Area (km2) |
|---|---|---|---|---|---|---|
| 1 | Murchison Falls National Park, Uganda | MUR | 2.27 | 846 | 1262 | 3877 |
| 2 | Mpala Research Center, Kenya | MPA | 0.40 | 1694 | 601 | 194 |
| 3 | Queen Elizabeth National Park, Uganda | QUE | −0.25 | 977 | 998 | 7395 |
| 4 | Masai Mara National Reserve, Kenya | MAR | −1.50 | 1624 | 950 | 1510 |
| 5 | Serengeti National Park, Tanzania | SER | −2.27 | 1546 | 850 | 14763 |
| 6 | Ruaha National Park, Tanzania | RUA | −7.80 | 1168 | 700 | 20226 |
| 7 | Selous Game Reserve, Tanzania | SEL | −8.86 | 396 | 1121 | 44800 |
| 8 | North Luangwa National Park, Zambia | NLU | −11.88 | 752 | 904 | 4636 |
| 9 | South Luangwa National Park, Zambia | SLU | −13.09 | 623 | 917 | 9050 |
| 10 | Chobe National Park, Botswana | CHO | −18.56 | 968 | 532 | 11000 |
| 11 | Limpopo National Park, Mozambique | LIM | −23.32 | 246 | 534 | 10000 |
| 12 | Kruger National Park, South Africa | KRU | −23.93 | 342 | 511 | 19175 |
| Index | Equation* |
|---|---|
| Green-Red Vegetation Index (GRVI) | |
| Normalized Difference Vegetation Index (NDVI) | |
| Soil Normalized Difference Index (SNDI) | |
| Soil Adjusted Total Vegetation Index (SATVI) | |
| Modified Soil Adjusted Vegetation Index (MSAVI2) |
| Accuracy Measure | Equation* |
|---|---|
| Variance Explained (VEcv) | |
| Coefficient of Determination (R2) | |
| Legates and McCabe’s (E1) | |
| Root Mean Square Error (RMSE) |
| PA Abbr. | Best Season | Best Approach | Best Locally Derived Model | Best Overall Model | Best General Model† | VCF | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Season | VEcv | Approach | VEcv | Model | VEcv | Model | VEcv | VEcv | VEcv | |
| MUR | DTW | 46.8 ± 24.5 | RF* | 79.3 ± 8.6 | RF - WT | 78.4 | RF - ALL - DW | 88.6 | 88.6 | 60.0 |
| MPA | Dry | 15.6 ± 16.6 | RF* | 55.7 ± 21 | RF - WT | 50.1 | RF - ALL - TD | 78.1 | 76.5 | −120.7 |
| QUE | Dry | −1.7 ± 20.3 | RF* | 55.4 ± 27.6 | RF - DW | 52.0 | RF - ALL - DW | 91.1 | 91.1 | 63.6 |
| SMR | DTW | 10.8 ± 18.5 | RF* | −2.8 ± 21.7 | MESMA EMC TG - Dry | 42.1 | MESMA EMC TG - Dry | 42.1 | 15.9 | 12.7 |
| RUA | WT | 1.2 ± 23.9 | RF* | 46.1 ± 25.4 | RF - DW | 35.6 | RF - ALL - DW | 76.3 | 76.3 | −0.2 |
| SEL | Tran | 37.1 ± 19.5 | RF* | 67.3 ± 16.3 | REG - TD - Mean NDVI & Band 5 Normalized Difference | 58.3 | RF - ALL - DTW | 86.2 | 80.2 | −32.1 |
| NLU | Tran | 20.6 ± 10.4 | RF* | 53.7 ± 30.1 | REG - TD - Mean NDVI | 40.1 | RF - ALL - DTW | 87.1 | 79.7 | −2.1 |
| SLU | Tran | 35.5 ± 19.6 | RF* | 67.3 ± 18.6 | RF - WT | 65.8 | RF - ALL - DTW | 86.6 | 77.6 | −15.6 |
| CHO | Tran | 29.9 ± 14.1 | RF* | 56.2 ± 18.5 | REG - DTW - Mean NDVI | 46.1 | RF - ALL - DW | 76.8 | 76.8 | −260.6 |
| LIM | TD | 23.2 ± 11 | RF* | 41 ± 27.2 | REG - Dry - Brightness & NDVI | 40.8 | RF - ALL - Dry | 75.4 | 71.5 | −275.1 |
| KRU | Dry | 0.7 ± 18.9 | RF* | 21.1 ± 31.2 | REG - Dry - MSAVI2 | 29.4 | RF - ALL - DW | 53.4 | 53.4 | −41.6 |
| ALL | Tran | 15.3 ± 10.5 | RF* | 46.2 ± 4.7 | RF - ALL - DTW | 51.1 | RF - ALL - DTW | 51.1 | 49.5 | −7.9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nagelkirk, R.L.; Dahlin, K.M. Woody Cover Fractions in African Savannas From Landsat and High-Resolution Imagery. Remote Sens. 2020, 12, 813. https://doi.org/10.3390/rs12050813
Nagelkirk RL, Dahlin KM. Woody Cover Fractions in African Savannas From Landsat and High-Resolution Imagery. Remote Sensing. 2020; 12(5):813. https://doi.org/10.3390/rs12050813
Chicago/Turabian StyleNagelkirk, Ryan L., and Kyla M. Dahlin. 2020. "Woody Cover Fractions in African Savannas From Landsat and High-Resolution Imagery" Remote Sensing 12, no. 5: 813. https://doi.org/10.3390/rs12050813