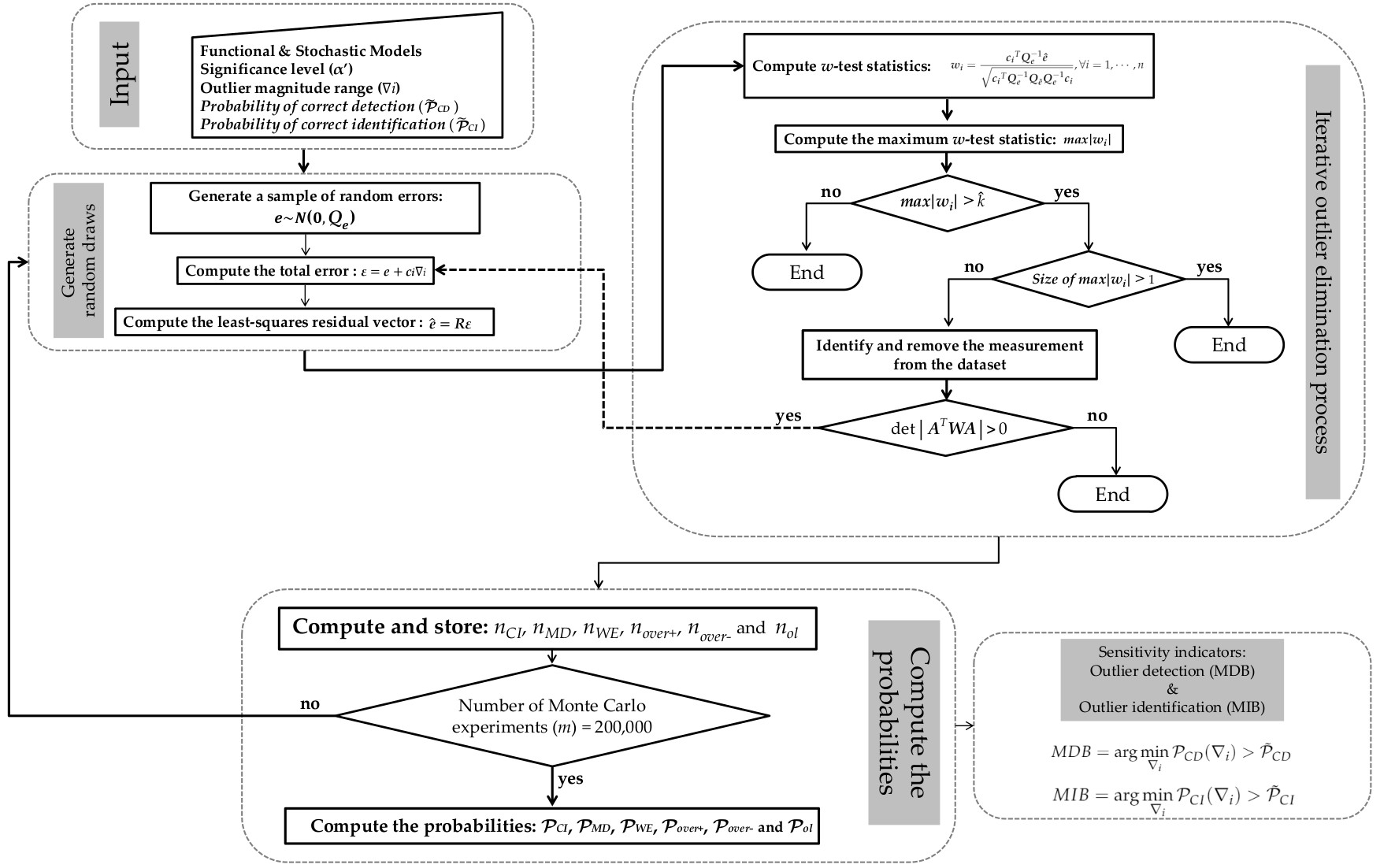
6.2.1. Geodetic Network with Low Correlation between Residuals
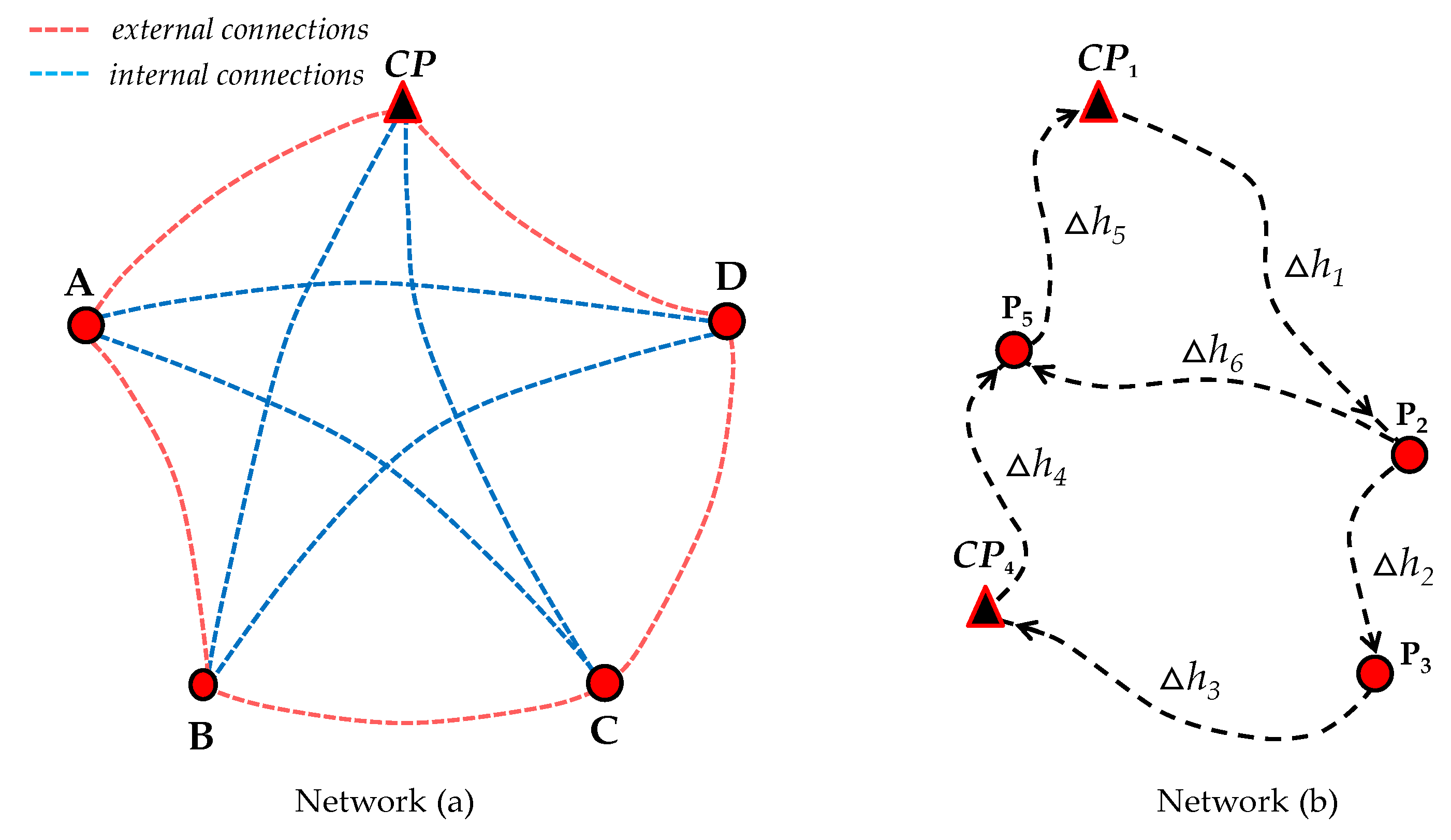
We start from network (
a) with a low correlation between residuals. We observe that there is a high degree of homogeneity for network (
a). This can be explained by the redundancy numbers, denoted by
. The redundancy numbers are the elements of the main diagonal of matrix
in Equation (
3). The redundancy number
is an internal reliability measure that represents the ability of a measurement to project the measurement error in the least-squares residuals. Then, the higher the number of redundancy, the higher the resistance of the measurement to outliers.
The redundancy numbers for the measurements constituting external connections are identical and equal to , whereas the measurements constituting external connections are also identical but equal to . Consequently, the probability levels associated with IDS are practically identical for both external and internal connections. Thus, we subdivided our result into two parts: mean values of the probability levels for external connections and mean values of the probability levels for internal connections.
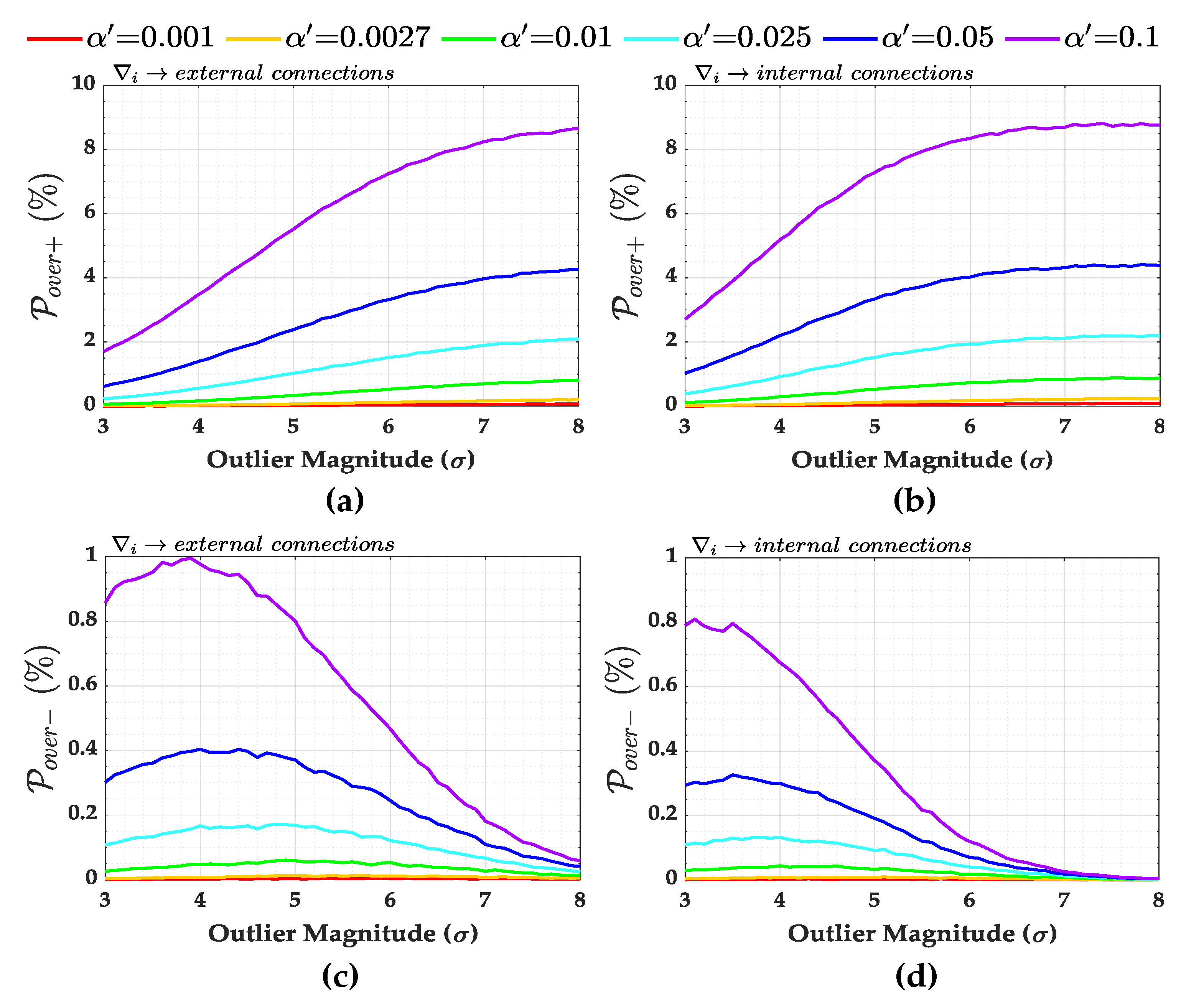
Figure 8 shows the probability of correct identification (
) and correct detection (
) in the presence of an outlier for both external and internal connections. In general, we observe that the larger the Type I Error
(or the lower the critical value
), the higher the rate of correct detection
. This is not fully true for outlier identification
.
We observe that the probability of correct identification becomes constant from a certain outlier magnitude. Moreover, the larger the , the faster the success rate at which outlier identification stabilizes. In other words, the larger the , the higher the , but only up to a certain limit of outlier magnitude. After this bound, there is an inversion: the larger the , the lower the probability of correct identification . This can be explained by the following: (i) the larger the , the larger the critical region (or the smaller the acceptance region) of the working hypothesis ; (ii) the larger the critical region, the smaller the size of the test; (iii) the smaller the size of the test, the less likely the hypothesis test will identify a small difference. In other words, there is no significant difference among the probabilities of correct identification for outliers lying within a certain location of the critical region. Therefore, the probabilities of correct identification for those outliers are practically identical.
Let us take the probability of correct identification
for external connections in
Figure 8 as an example. If the user chooses
, then the test will be limited to 90% of the acceptance region. In this case, an outlier of
will have a practically identical probability of correct identification of
of an outlier of
(or greater than
). However, if one chooses an
(99.9% of acceptance region), then a
outlier would not be identified at the same rate as an
outlier. Therefore, in that case, the Type I decision error
(or the critical value
) restricts the maximum rate of correct outlier identification
.
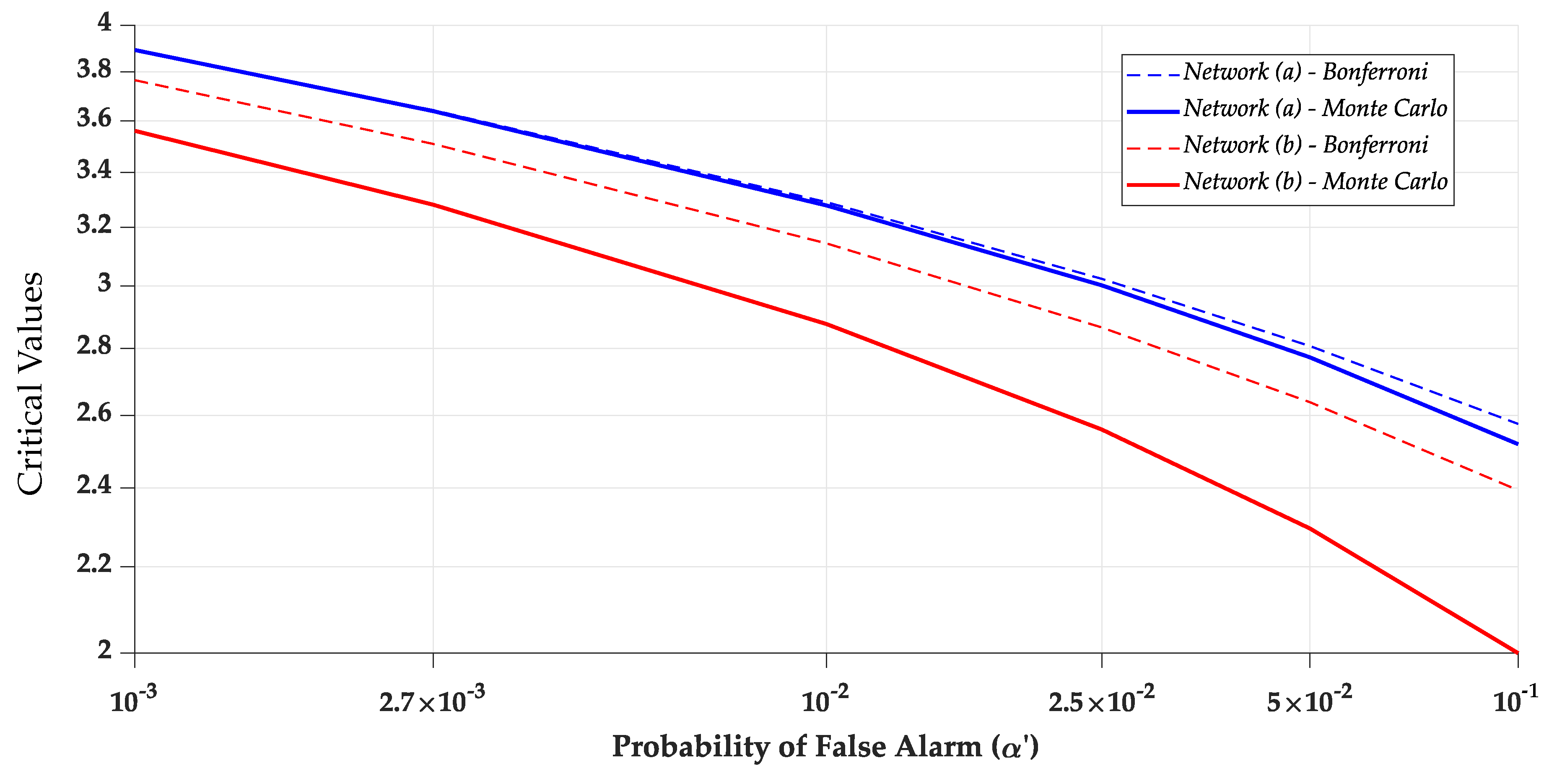
Note also that there are no significant differences between detection and identification rates for small Type I decision errors (see, e.g., and ).
Furthermore, the probabilities of correct detection and identification are greater for internal than external connections. For an outlier of and , for instance, the probability of correct identification is for external connections, whereas, for internal connections, it is .
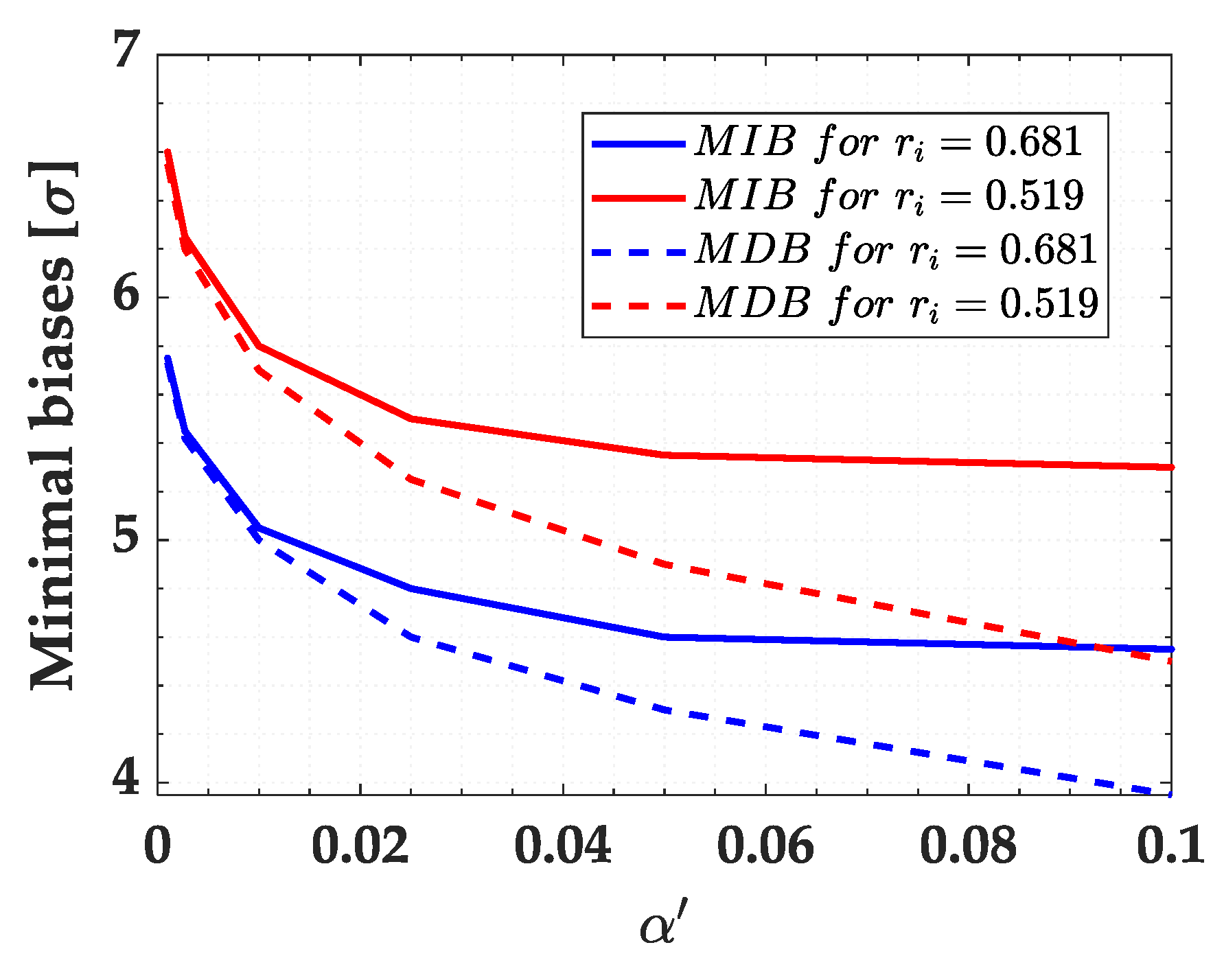
Next, we compared the sensitivity indicators MDB and MIB by considering a success rate of 0.8 (80%) for both outlier identification and outlier detection, i.e.,
(see Equations (
43) and (
44). The user can also find the MDB and MIB for other success rates. The result is displayed in
Figure 9. We observe that the larger the Type I decision error
, the more that the MDB deviates from the MIB. In other words, the MIB stabilizes for a certain
, whereas the MDB continues to decrease. It is harder to identify than it is to detect an outlier. Therefore, the MIB will always be greater than or equal to the MDB.
The standard deviations of estimated outlier
for external and internal connection measurements are 2.7 mm and 3 mm, respectively. These
values were obtained by means of the square-root in Equation (
14). Note from Equations (
45) and (
46) that the higher the accuracy of the outlier estimate, the lower the MDB and MIB, respectively. However, note from Equation (
47) that the relationship between the MIB and MDB does not depend on
. This is true when the outlier is treated as bias. In other words, if outliers are treated as bias, then they act like systematic errors by shifting the random error distribution by their own value [
13]. The result for
is summarised in
Table 5.
As can be seen from
Table 5, in general, the MIB does not deviate too much from the MDB. This is because of a low correlation between residuals. The difference becomes larger when the Type I decision error
is increased. Note, for instance, that the MDB and MIB are practically identical for Type I decision errors of
and
. In other words, an outlier is detected and identified with the same probability level when there is a low correlation between residuals and for small
. Therefore, we observe that the larger the
, the greater the difference between the MIB and MDB. In this case, the difference between the MIB and MDB is governed by the user-defined
.
From
Table 6, it can also be noted that the MIB is higher for internal than external connections. This is because internal connections are less precise than external connections. Therefore, the effect on the heights (model parameters) of an unidentified outlier is greater if the outlier magnitude is equal to the MIB of the internal connections. However, from
Figure 8, we observe that it would be easier to identify an outlier if it occurred in the measurements that constitute internal connections than if it occurred in external connections.
It is important to mention that both the MDB and MIB are ’invariant’ with respect to the control point position
. This is a well-known fact and can already follow from the MDB and MIB definitions in Equations (
45) and (
46), respectively, which show that both the MDB and MIB are driven by the variance matrices of the measurements and adjusted residuals.
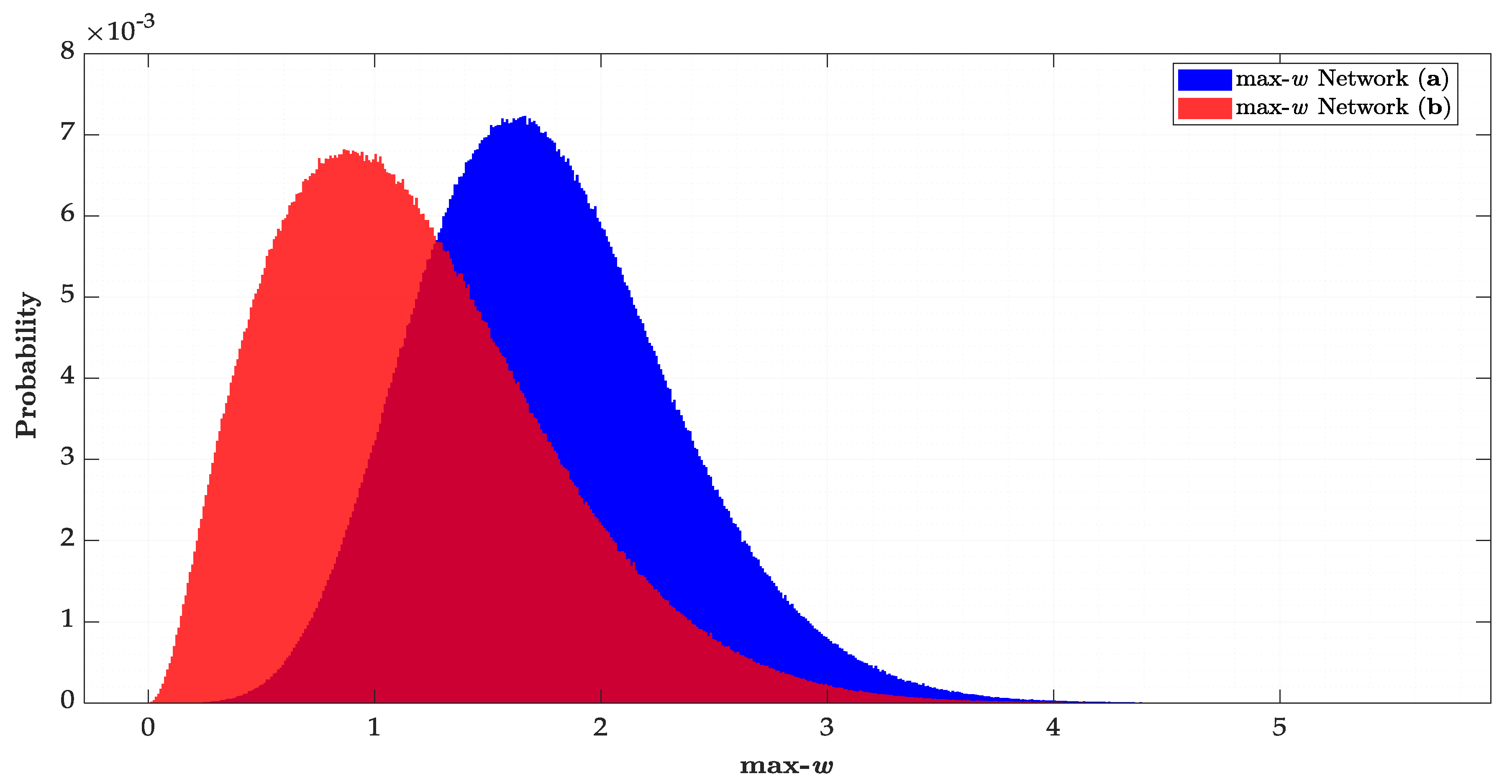
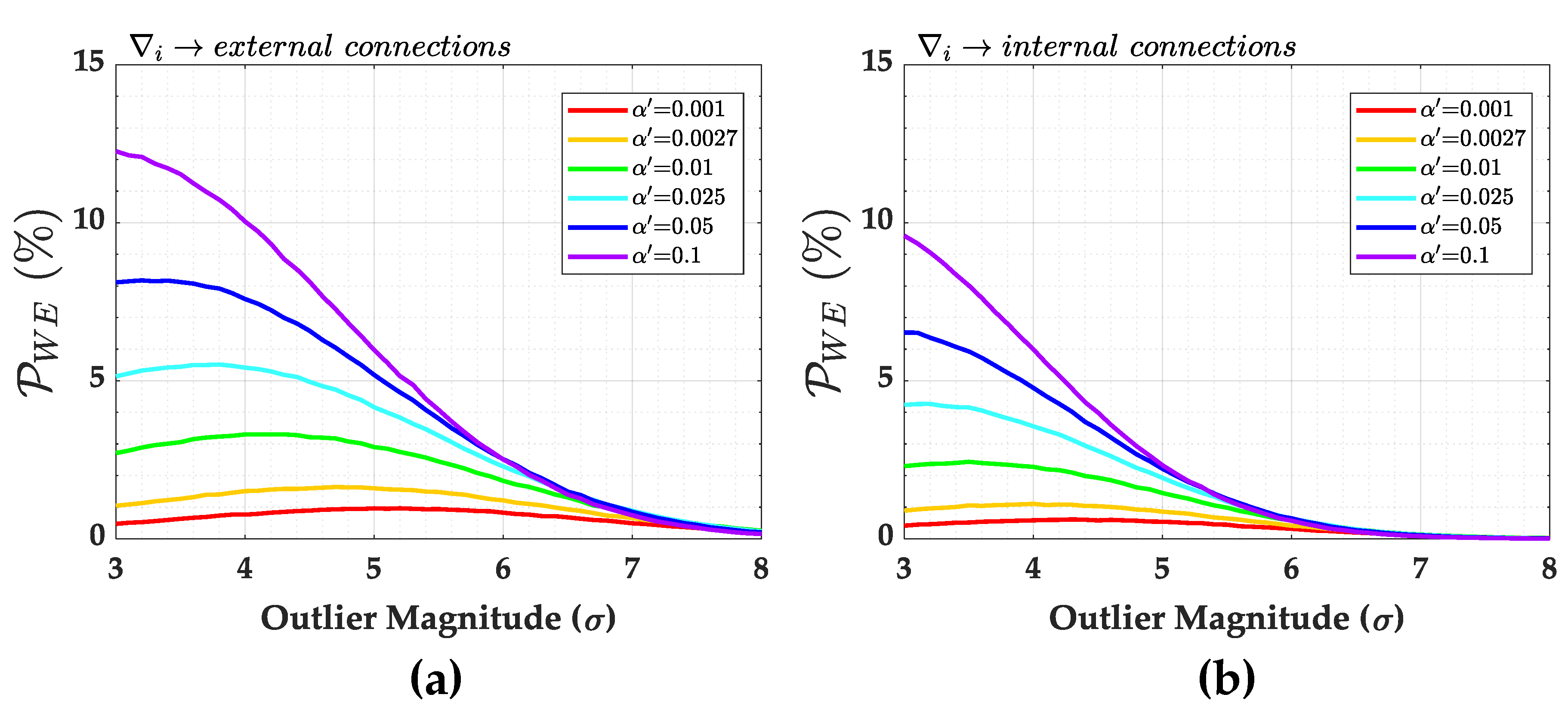
Figure 10 provides the result for the Type III decision error (
). In the worst case, we have
(12%) for
. In general,
is larger for external than internal connections. This is linked to the fact that the residual correlation
in
Table 2 is higher for external than internal connections. Furthermore, the larger the Type I error rate
, the larger the
for both internal and external connections. Because of the low probability of
decision errors for network (
a), the user may opt for a larger
so that the Type II decision error
is as small as possible. Thus, it is possible to guarantee a high outlier identification rate. This kind of analysis can be performed, for instance, during the design stage of a geodetic network (see, e.g., [
60]).
Figure 10 gives only the overall rate of
.
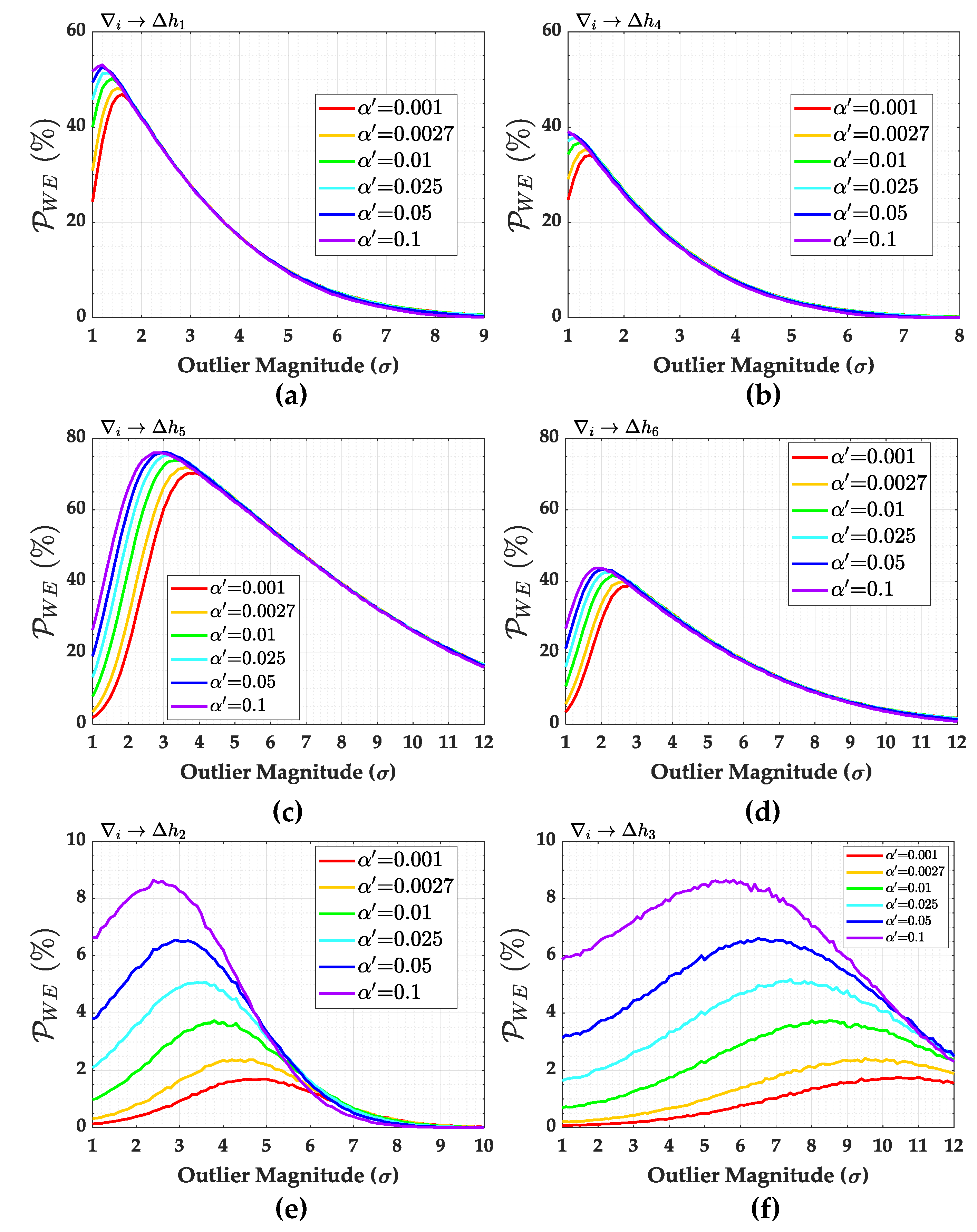
Figure 11, on the other hand, displays the individual contributions to
according to Equation (
40) for
. As expected, the higher the correlation coefficient between
w-test statistics
, the greater the contribution of the measurement to
(see, e.g., [
2]). In that case, we can also verify from
Figure 12 that the larger the redundancy number
, the smaller the
. Moreover, the larger the outlier magnitude, the smaller the
. We also observe from
Figure 13 that the larger the
, the larger the weighting factor
. The weighting factors
for the highest correlations (i.e.,
for
and
for
) increase as the outlier magnitude increases. However, this is not significant. While the weighting factor
for the highest correlation coefficient increases by around 1%, the overall
decreases by around 20%. In general, the weighting factor
is relatively constant. The weighting factor
was obtained by Equation (
41).
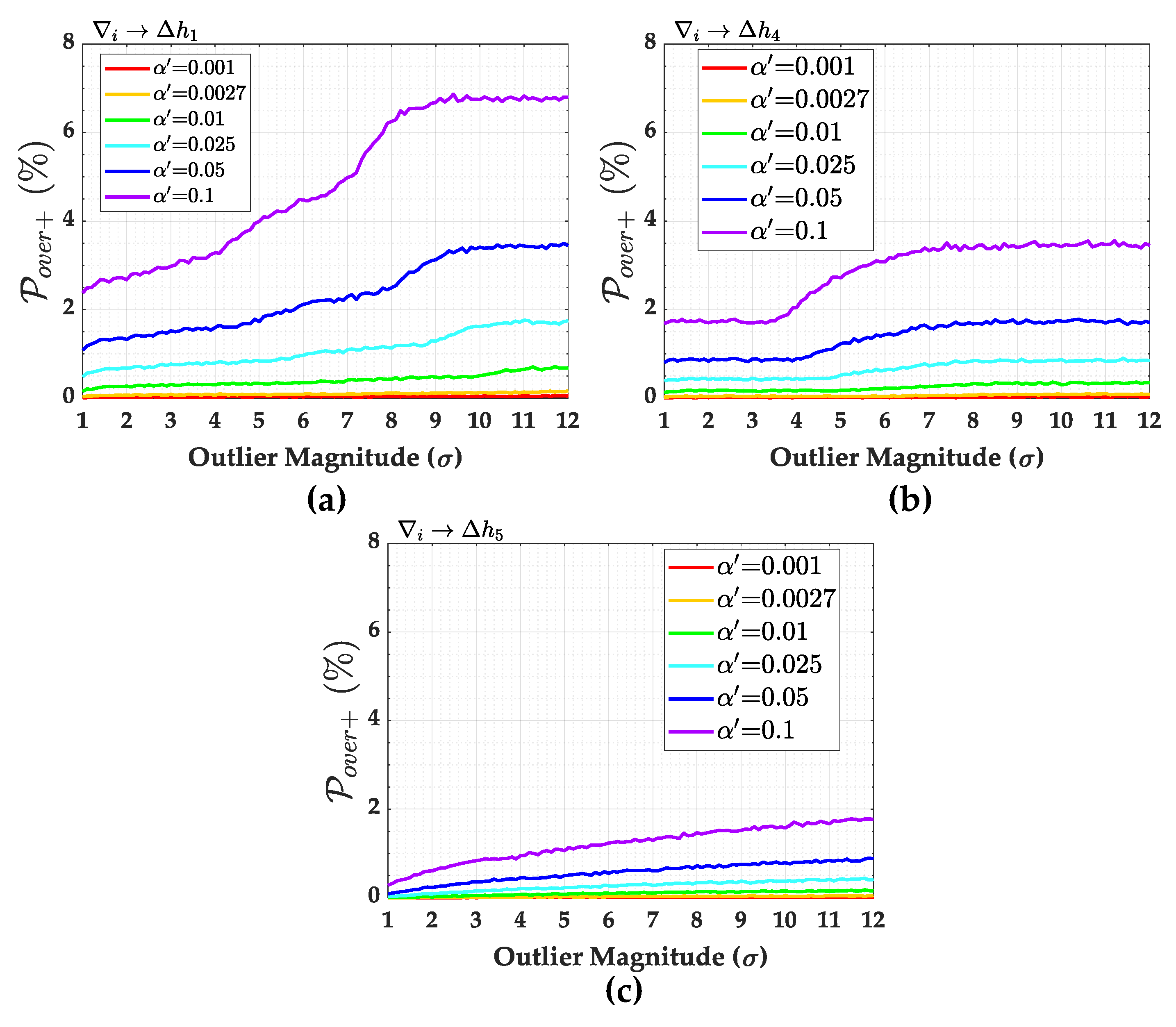
The over-identification cases
and
are presented in
Figure 14. In general, the larger the Type I decision error
, the larger the over-identification cases for that network. The larger the magnitude of the outlier, the larger the
and smaller the
. For small
, we observe that
and
are practically null (see, e.g., for
and
). In general, the larger the correlation coefficient
, the smaller the
and the larger the
. Moreover, we also observe that the larger the redundancy number
, the larger the
and the smaller the
.
The probability of statistical overlap is practically null for this network. This is because each point of network (a) has at least four connections. This means that even with an exclusion, there are still three measurement levels per point (i.e., three connections per point), which guarantees the minimum redundancy necessary for the second round of IDS. The very low residual correlation of this network also contributes to the non-occurrence of statistical overlap.
The results presented so far are valid for the case of a system with high redundancy and low residual correlation. In the next section, we present the results for a system with low redundancy and high residual correlation.
6.2.2. Geodetic Network with High Correlation Between Residuals
Now, the correlation between residuals is very high. This is the case for network (
b) detailed in
Figure 2. Since the measurements are correlated for network (
b), instead of redundancy numbers, reliability numbers
should be given as an internal reliability measure, as follows [
43]:
The reliability numbers
in Equation (
61) are equivalent to redundancy numbers when it is assumed that the measurements are uncorrelated.
Table 7 gives the reliability numbers
, the standard deviation of each measurement
and the standard deviation of each estimated outlier
for network (
b).
The probabilities of correct identification (
) for this network are displayed in
Figure 15. The critical values
for network (
b) are those given in
Table 4. The probability levels of correct detection (
) are provided in
Figure 16.
In contrast to network (a), the probability of correct identification () for network (b) is different for each measurement. It is also found that the larger the Type I decision error , the higher the probability of correct identification (). However, it is only true up to a certain level of outlier magnitude. After this magnitude level, the larger the Type I decision error , the lower the probability of correct identification ().
The user-defined Type I error has indeed become less significant at a certain outlier magnitude. Note, for example, that the probability of correct identification for measurement for is higher than that for when the outlier magnitude is between and . For a magnitude greater than , we note that the larger the Type I decision error , the lower the probability of correct identification . The choice of Type I error , however, has no significant effect on the probability of correct identification for an outlier magnitude greater than . This analysis can also be done with , and .
There is no probability of identification for both measurements
and
. This is because the residual correlation of these measurements is equal to exactly one (i.e.,
). Furthermore, the reliability numbers
in
Table 7 for those measurements are close to zero. However, if one of those measurements were affected by a single outlier, then
IDS would have the ability to detect it. In other words, there is reliability in terms of outlier detection for
and
.
We observe that the higher the reliability numbers in
Table 3, the higher the power of detection
and identification
. In general, the larger the Type I decision error
, the lower the probability of missed detection
and, therefore, the higher the probability of correct detection
.
The sensitivity indicators MDB and MIB for
,
,
and
are shown in
Table 8,
Table 9,
Table 10 and
Table 11, respectively. Both MIBs and MDBs were computed for each
and for a success rate of 0.8 (80%) for both outlier detection and identification, i.e.,
. The non-centrality parameters for outlier detection and identification were computed according to Equations (
45) and (
46), respectively. In general, the larger the Type I decision error
, the larger the MIB and the smaller the MDB. In other words, the larger the Type I decision error
, the greater the chances of outlier detection but the lower the chances of outlier identification. In that case, the larger the Type I Error
, the larger the MIB/MDB ratio. Therefore, an outlier with a size of the MDB should be enlarged in order to identify it [
1,
2,
12,
46].
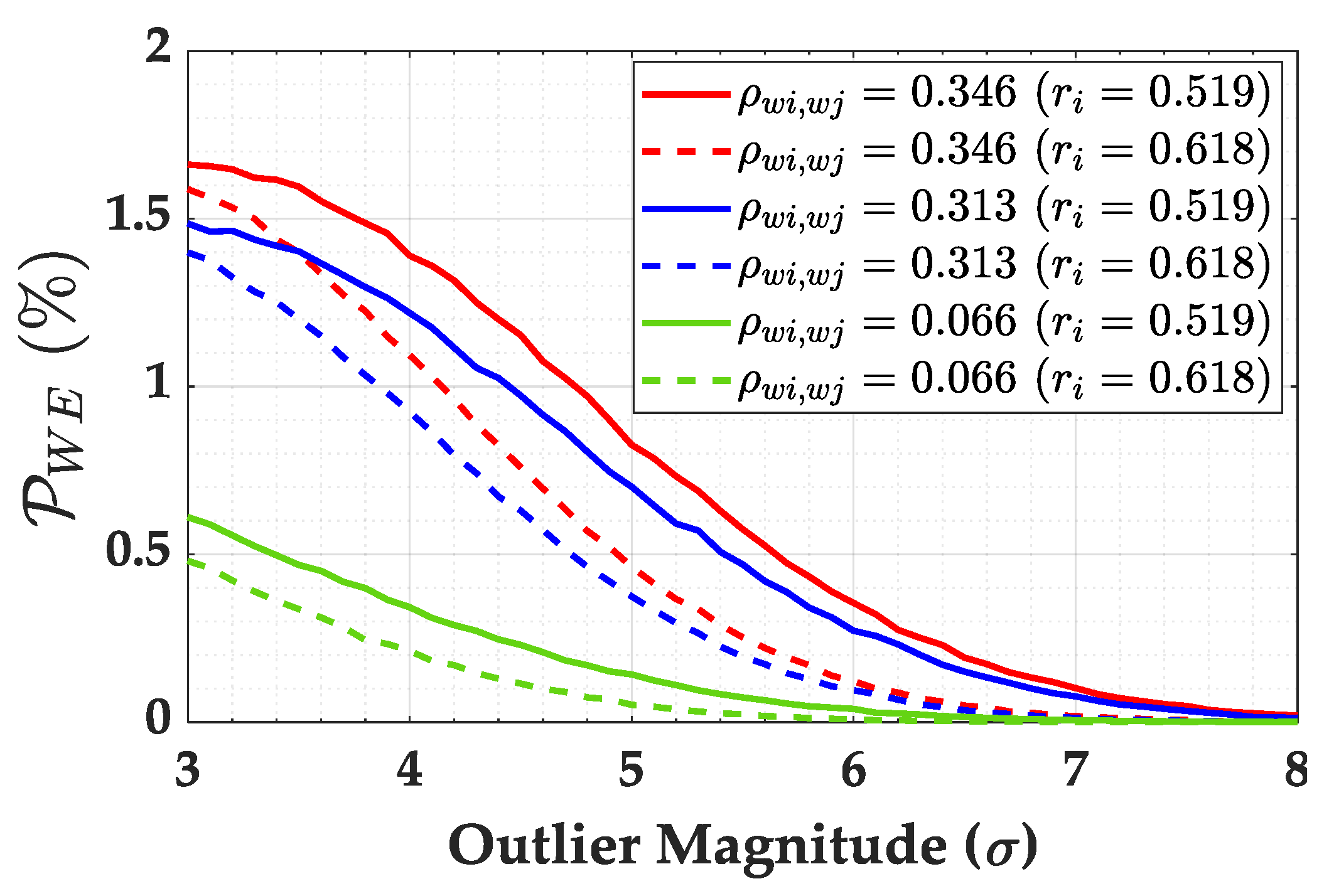
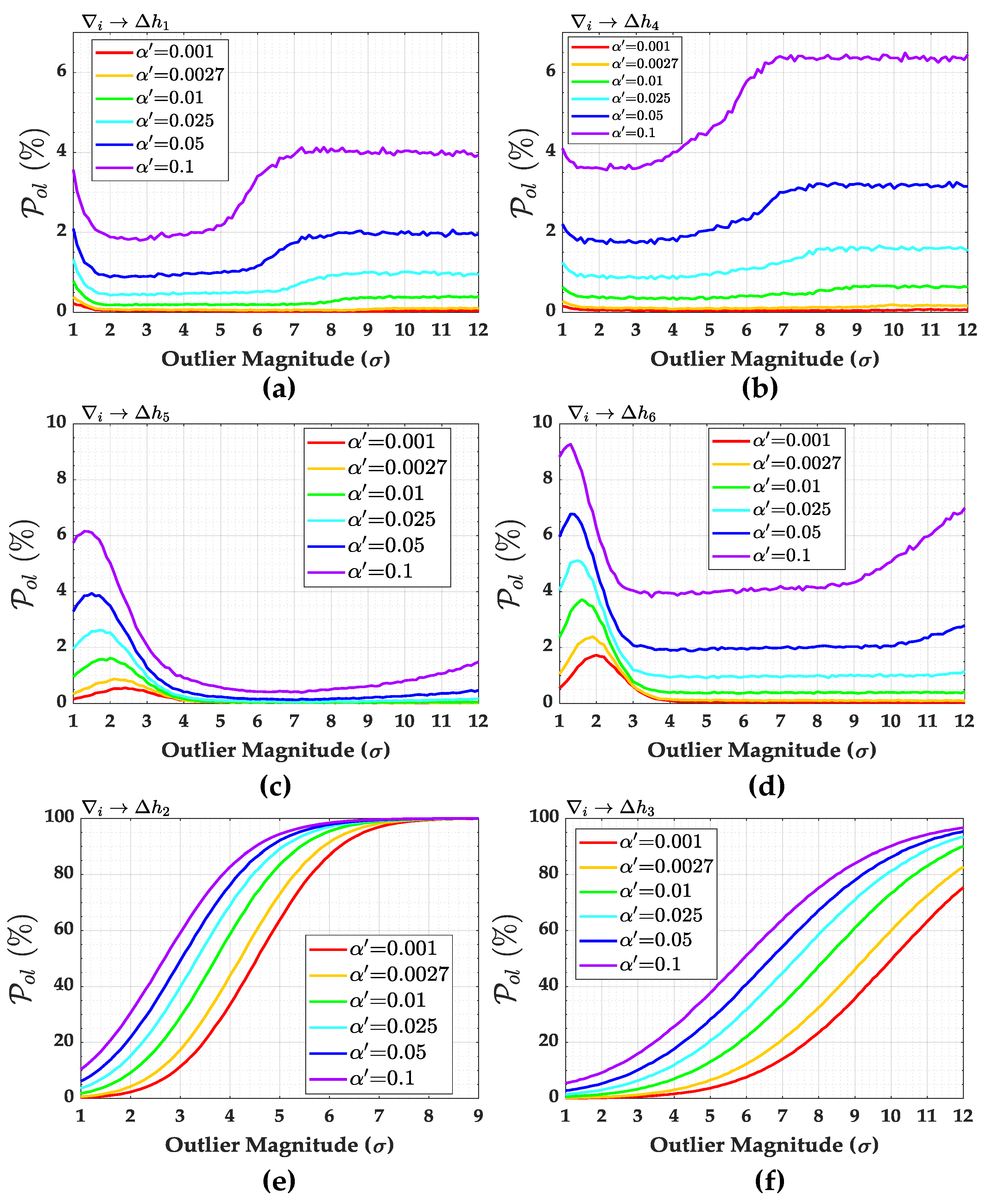
The overall probabilities of wrong exclusion (
) for network (
b) are provided in
Figure 17. In general, we observe that the wrong exclusion rate (
) increases up to a certain outlier magnitude and, from this point on, the wrong exclusion rate (
) starts to decline, and the effect of the user-defined Type 1 decision error (
) on
becomes neutral in practical terms. This effect is due to the residuals’ correlation. To see this effect more clearly, we also computed the individual contribution of each measurement to the overall wrong exclusion
and their corresponding weighting factors given by Equations (
40) and (
41), respectively.
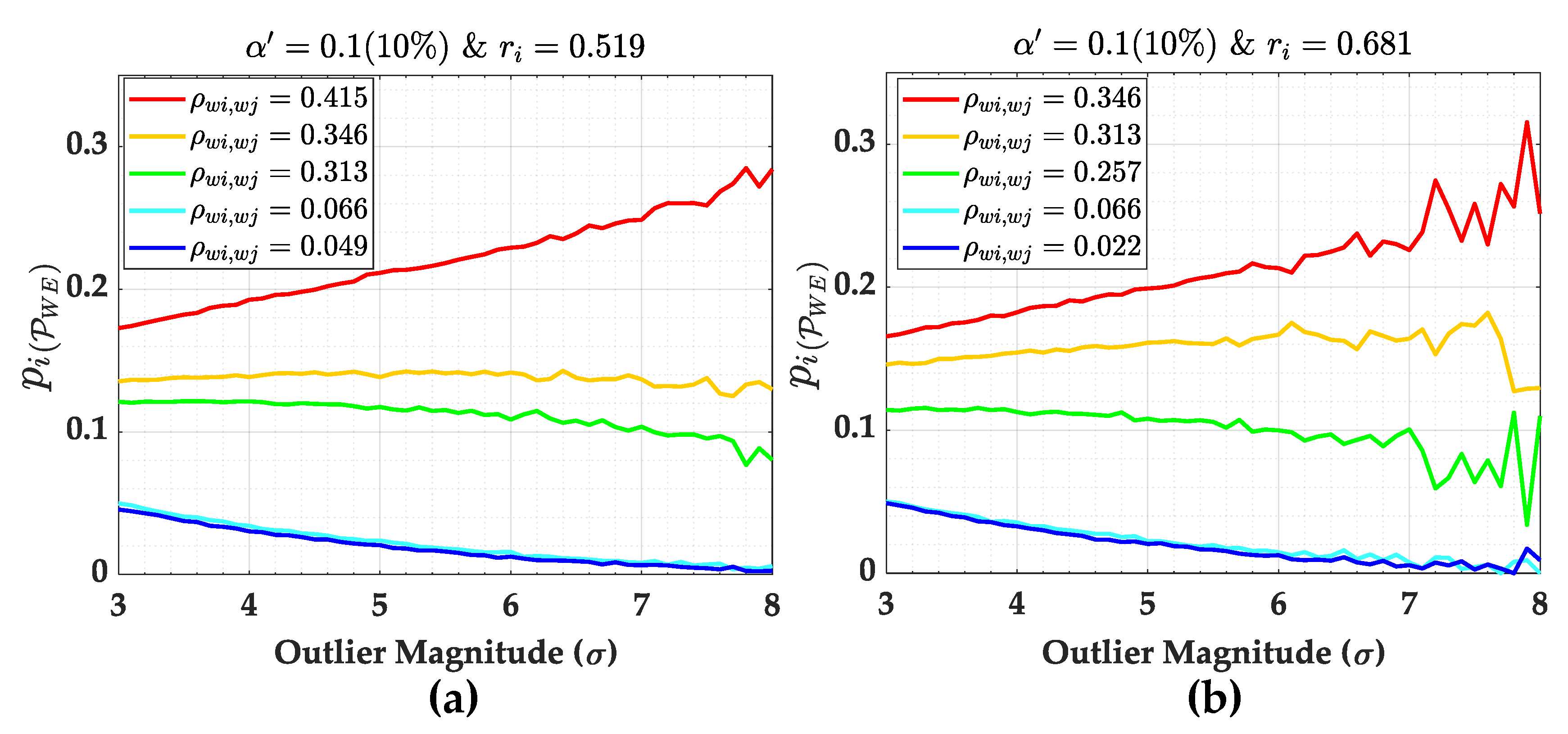
The individual contributions to the overall
and their weighting factors for
are displayed in
Figure 18 and
Figure 19, respectively. It is important to mention that the behaviour shown in
Figure 18 and
Figure 19 is similar to that for other
values. We observe that the correlation coefficient (
) only has a direct relationship with
for a certain outlier magnitude. Let us consider the case in which
is set up as an outlier. In that case, the larger the correlation coefficient (
), the higher the individual contribution to
. Of course, this only holds true if the outlier magnitude is larger than
. This is also evident from the results of the weighting factors in
Figure 19.
An important highlight is the association between the MIB and the contribution of each measurement to the probability of wrong exclusion
in
Figure 18.
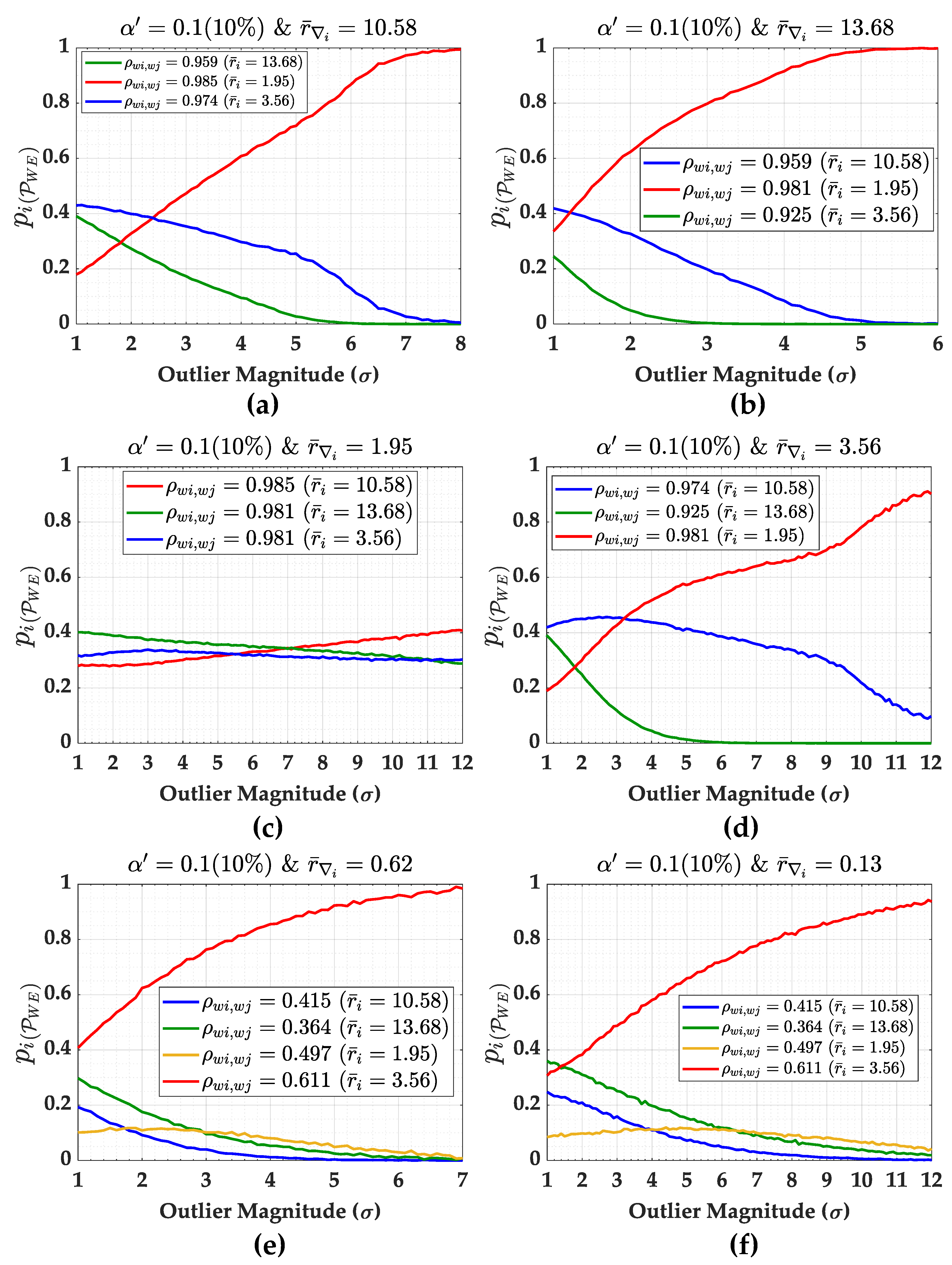
We observe that it is possible to find the value of the MIB at high success rates when the individual contributions to the overall wrong exclusion of a given outlier start to decrease simultaneously. It is important to mention that this simultaneous decay occurs when there is a direct relationship between the correlation coefficient () and the wrong exclusion rate . In that case, the identifiability of a given outlier can be verified for a given significance level and probability of correct identification .
Figure 20 illustrates an example for measurements
and
. The black dashed line corresponds to the probability of correct identification
and the respective MIB for
. Note that when the effect of all measurements on
decreases, it is possible to find an outlier magnitude that can be identified. In other words, the effect of the correlation between residuals (
) becomes insignificant at a certain outlier magnitude, which increases the probability of identification.
The probabilities of wrong exclusion for both
and
are smaller than those for the other cases. This is because of the correlation between residuals (
). In fact, we also note that although there is no reliability in terms of outlier identification for cases in which the correlation is
(i.e., 100%), there is reliability for outlier detection. In this case, outlier detection is caused by overlapping
w-test statistics. The result for statistical overlap (
) is displayed in
Figure 21. In general, the larger the Type 1 decision error
, the larger the statistical overlap (
).
The over-identification cases (
and
) are displayed in
Figure 22 and
Figure 23, respectively. We observe that the larger the Type I decision error (
), the larger the over-identification cases. It should be noted that
is always larger than
. Over-identification
is practically null. The over-identification cases
for
,
and
and
for
are exactly null. The over-identifications
for
and
are less than 0.2% and are therefore not shown here.

 ,
, 
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}