1. Introduction
With the development of imaging sensor technology, the imaging quality of remote sensing images is constantly improving, which makes obtaining high-resolution remote sensing images more convenient. High-resolution remote sensing images play an important role in many aspects, not only in marine, agricultural, and ecological protection but also in urban planning [
1,
2,
3,
4]. With the increasing amount of remote sensing images, automatic and accurate extraction of useful information from images has become valuable topic. Among them, the automatic extraction of buildings from high-resolution images is of great significance in the establishment and updating of urban geographic information databases and urban planning. However, the phenomenon of “synonyms spectrum” or “foreign objects with the same spectrum” often appear in the remote sensing images, such as inconsistent hues and textures of the same building and similar spectra of the building and the bare land, which brings great challenges to the automatic extraction of buildings. The improvement of the spatial resolution of remote sensing images makes the information of ground features more abundant, but it also brings greater challenges to the extraction of buildings [
5,
6,
7,
8]. For example, the difference in hues and textures of the same building increases, which aggravates the problem of incomplete building extraction, and the footprints of buildings on high-resolution images are more complicated, which makes accurate extraction of them difficult for a neural network-based method. Many researchers are working on the automatic extraction of buildings from remote sensing images, and have proposed some effective building extraction methods. These methods can roughly be classified into two categories: one is based on artificially designed features and the other is based on deep learning.
The artificial features-based methods mainly make use of geometric, spectra, and contextual information design features of buildings in remote sensing images for building extraction. Lin and Nevatia [
9] used the edge detection algorithm for the first time to extract buildings by detecting roof, walls, and shadows of buildings. After the edge detection, geometric constraint processing for line segment detection, or the combination of region segmentation, region growing, and region merging can contribute to the accurate extraction of buildings [
10]. Katartzis et al. [
11] combined the edge detection with the Markov model and used the onboard image to extract the buildings. However, the method of edge detection is vulnerable to many objects close to the building such as roads, so that the result of the extraction contains a large number of non-building areas. In addition to the use of edge or corner detection methods, researchers also use image segmentation methods for building extraction. Baatz [
12] presented a fractal network algorithm to segment the image in multiple scales, and combined the image features, texture, and other features to extract the building. In the study of image feature extraction, image segmentation by a certain threshold of the index is often used for extracting features. Zhang et al. [
13] proposed a pixel shape index, which extracts the buildings by clustering homogeneous pixels with similar shape and contour information. Shao et al. [
14] proposed a new index to extract built-up areas from high-resolution remote sensing images by visual attention model. Liu et al. [
15] used the texture, shape, spectrum, and structural features of the extracted image to construct the feature vector; introduced the machine learning method to take feature vector as input; and classified each pixel to distinguish the building. Although the traditional image segmentation methods for high-resolution images used to extract buildings have made some achievements, the extraction accuracy is not high at present. The main reason is that the spatial resolution of remote sensing images is improved, which makes the information of ground features more abundant. Overall, methods based on artificial design features often only make use of the shallow features of ground targets rather than deep features being able to effectively distinguish different ground features, leading to the low extraction accuracy. Additionally, they also require various rules to predefine features, which is thus laborious.
With the rapid development of deep learning, especially the convolutional neural network (CNN), deep learning methods have deserved great breakthrough in tasks such as natural image classification, object detection, and semantic segmentation. At present, commonly used convolutional neural networks mainly include AlexNet [
16], VGGNet [
17], GoogleNet [
18], and ResNet [
19]. Convolutional neural networks mainly consist of convolutional layers, non-linear activation functions, and pooling layers. Convolutional layers use a large number of convolution kernels to extract local features of the input image. The introduction of non-linear activation functions improves the network’s extraction of non-linear features of the input image. The pooling layers can further improve the receptive field to extract more global features. Compared with the traditional artificial design feature methods, the convolutional neural network can automatically extract the features of the input image, which has gradually replaced the traditional artificial feature methods due to its powerful feature representation ability. As convolutional neural networks show strong advantages in the field of natural images, more and more researchers have tried to apply convolutional neural networks to the field of remote sensing images, with some progress made in the segmentation and recognition of remote sensing images. Lv et al. classified remote sensing images with SEEDS-CNN and scale effectiveness analysis [
20]. Chen et al. applied multi-scale CNN and scale parameter estimation in land cover classification [
21]. Zhou et al. proposed So-CNN for urban functional zone fine division with VHR remote sensing images [
22]. Lv et al. proposed a new method for region-based majority voting CNNs for very high-resolution image classification [
23]. As an important issue of ground feature extraction, automatic building extraction has also obtained many results in the application of convolutional neural networks. Minh first applied the convolutional neural network to the building extraction of remote sensing images and proposed a building block extraction method based on image blocks. This method can directly obtain the building extraction results in the middle region of the input image [
24]. To further improve the accuracy, Minh proposed using CRF or post-processing to refine the extraction results of the network. However, because these methods can only obtain the results of the middle region of the input image rather than the entire image, there are still discontinuous image blocks in the results.
In 2015, the Fully Convolutional Neural Network (FCN) was proposed to achieve pixel-level dense prediction of images [
25]. FCN restores the size of the input image by using an upsampling operation and finally obtains the prediction result of each pixel of the input image. Most of the methods proposed later for image semantic segmentation were improved based on FCN, mainly including SegNet [
26], DeconvNet [
27], U-Net [
28], and DeepLab [
29]. Many researchers have also applied FCN-based methods to the automatic extraction of buildings from remote sensing images. Huang et al. proposed an improved DeconvNet, adding upsampling and dense connection operations to the deconvolution layer to get the results of building extraction [
30]. Based on FCN, Maggiori et al. proposed a two-stage network that comprehensively considers the problems of identification and precise positioning [
31]. Wu et al. used multi-constraint FCN to automatically extract buildings from aerial images [
32]. Aiming at the problem that the use of the pooling layer will lose the information of the original image [
33], Shariah et al. used FCN without the pooling layer to make the network retain as much important and useful information of the original image as possible [
34]. Xu et al. combined the fully convolutional neural network and guided filtering to further optimize the extraction results of buildings [
35]. Although FCN-based methods has achieved many results on the building extraction of remote sensing images, there are still some problems when applying them to the automatic extraction of buildings with high-resolution remote sensing images. On the one hand, due to the different hues and textures of the same building on the image, the extraction is incomplete or the extracted buildings are partially missed. On the other hand, these methods are not accurate enough for the building footprint extraction of buildings with complex shapes.
To better address the problems of incomplete building extraction and inaccurate building footprint extraction of complex buildings in high-resolution remote sensing images, this paper proposes a new network named Building Residual Refine Network (BRRNet). BRRNet is composed of a prediction module and a residual refinement module. The prediction module outputs the preliminary building extraction results of the input image and then the residual refinement module takes the output of the prediction module as an input. By correcting the residual between the result of the prediction module and the real result, it finally further improves the accuracy of building extraction. In the task of building extraction from high-resolution images, there is a problem of data imbalances due to the large difference in the total number of pixels between the building and the background, which affects the accuracy of building extraction. Therefore, we adopt Dice loss as the loss function during training, which effectively solves the problem of data imbalance and further improves the accuracy of building extraction.
The contributions of this paper mainly include the following three aspects.
(1) This paper proposes a new network named Building Residual Refine Network (BRRNet) composed of the prediction module and the residual refinement module for accurate and complete building extraction in remote sensing images. The extensive experimental results on Massachusetts Building Dataset [
24] show that our method outperforms other five state-of-the-art methods in terms of the integrity of buildings and the accuracy of complex building footprints.
(2) It was verified on Massachusetts Building Dataset that using Dice loss as the loss function during training is more conducive to alleviating the problem of data imbalance in building extraction tasks than BCE (Binary Cross Entropy) loss and thus boosts the accuracy of building extraction.
(3) This paper proposes a new residual refinement module named RRM_Bu equipped with deeper layers and atrous convolution and confirms that it can be readily migrated to other fully convolutional neural networks and improve the performance of the basic network.
The following sections present the proposed method and the experiments performed.
Section 2 elaborates on the proposed network BRRNet.
Section 3 gives the experiments and analysis, which explains in detail our comparative experiments and analysis of experimental results. In
Section 4, we discuss the total parameters of different networks and the generalization ability of BRRNet. Finally,
Section 5 concludes the paper.
2. Methodology
This section describes the method proposed in this paper. In particular,
Section 2.1 introduces the atrous convolution.
Section 2.2 presents the overall architecture of BRRNet.
Section 2.3 details the network’s prediction module.
Section 2.4 details the network’s residual refinement module.
Section 2.5 describes the loss function used in the training process.
2.1. Atrous Convolution
Convolutional neural networks usually use pooling layers to expand the receptive field during feature extraction to extract more global information. Moreover, the use of pooling layers reduces the size of feature maps, which can reduce network parameters. However, because of the use of pooling layers, the resolution of the obtained feature maps are reduced so that the information of the input image is lost, which finally affects the positioning accuracy in image semantic segmentation. To further expand the receptive field during feature extraction without serious loss of input image information, researchers introduce atrous convolution into convolutional neural networks [
29,
36]. The atrous convolution kernel is obtained by performing a certain amount of zero paddings between the adjacent weight values of the ordinary convolution kernel. The distance between adjacent weights is called dilation rate. Compared with ordinary convolution, atrous convolution can expand the receptive field of feature extraction without increasing parameters to extract more global features.
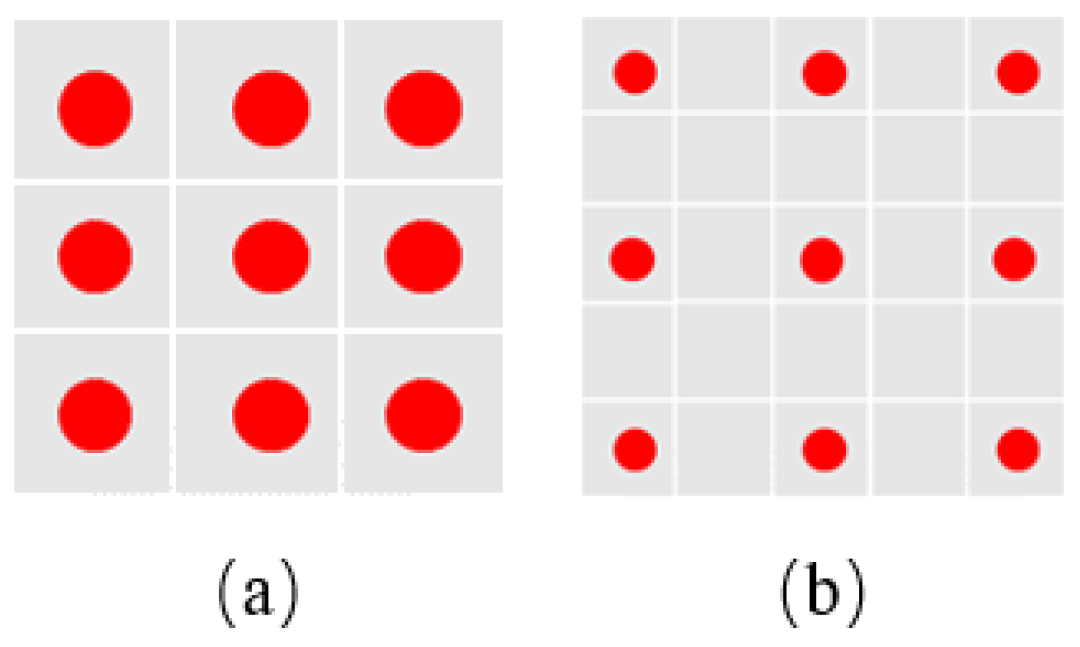
Figure 1a shows a single 3 × 3 ordinary convolution, whose number of parameters is 9.
Figure 1b shows an atrous convolution with the size of 3 × 3 and the dilation rate of 2. Since the atrous convolution is obtained by filling zeros between the adjacent weights of the ordinary convolution, the atrous convolution keeps same with the number of parameters of the corresponding ordinary convolution, but the receptive field of the atrous convolution becomes larger so that it can extract more global features. We incorporate atrous convolution into the proposed network which will be explained in detail below.
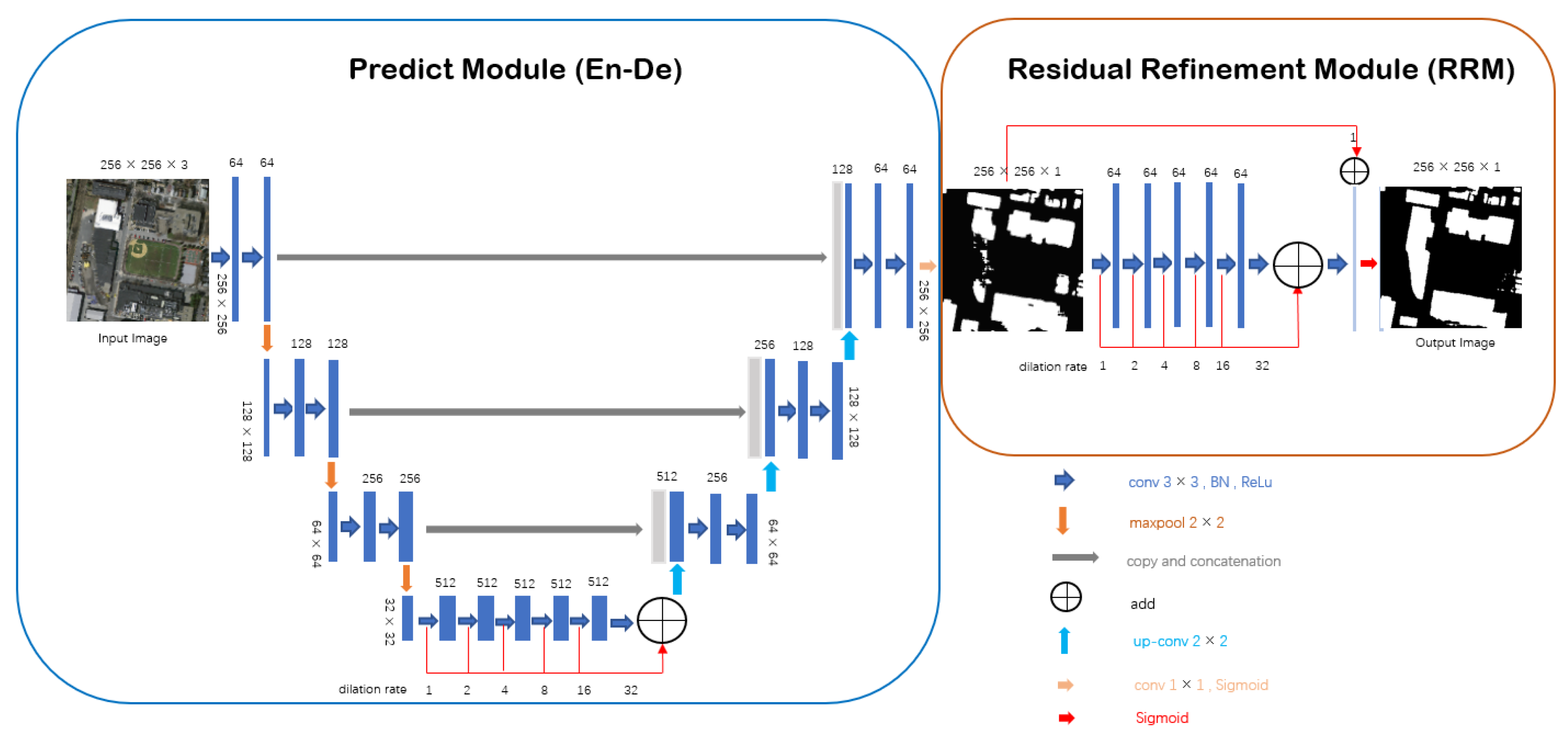
2.2. BRRNet
To better address the problems of incomplete building extraction and inaccurate building footprint extraction of complex buildings in high-resolution remote sensing images, we propose a new deep learning network Building Residual Refine Network (BRRNet). The network consists of two parts: the prediction module and the residual refinement module. The prediction module is based in an encoder–decoder structure, which gradually increases the receptive field during feature extraction by introducing atrous convolution with different dilation rate to extract more global features. The prediction module finally outputs the preliminary building extraction results of the input image. The residual refinement module takes the output of the prediction module as an input. By correcting the residual between the result of the prediction module and the real result, it finally further improves the accuracy of building extraction. The network’s structure is shown in
Figure 2.
2.3. Prediction Module
The design of the prediction module is inspired by U-Net and the atrous convolution structure. It consists of five parts: input, encoder, bridge connection, decoder, and output. The inputs in our experiments are remote sensing image tiles. The encoder uses the first three blocks of U-Net’s encoder, where each block is a two-layer convolution and a max-pooling layer with a window size of and a step size of 2. After the convolution operation, Batch Normalization and ReLu activation functions are performed. The convolution kernel size used in these blocks is , and the number of the kernel is 64, 128, and 256, respectively. The encoder of our prediction module removes the fourth block in the U-Net’s encoder because the fourth block has a large number of parameters. The previous deep learning methods applied to building extraction from high-resolution images generally have problems of incomplete building extraction and inaccurate building footprint extraction. An important reason for these problems is that, to avoid serious loss of input image’s information, which affects the final positioning accuracy, the previous networks only use a small number of pooling operations. For remote sensing images, the number of pixels occupied by buildings will increase relatively rapidly as the resolution increases. We call buildings with more pixels in the image as large buildings, and many large buildings have inconsistent hue and texture or complicated shape in high-resolution remote sensing images. The use of only a small number of pooling layers causes the receptive is insufficient to cover the entire building and the surrounding background. Therefore, it is not possible to extract the global features of the entire building, which causes problems such as incomplete building extraction and inaccurate building footprint extraction in the obtained results. To further increase the receptive field to extract more global information, and at the same time to avoid losing the information of the image as much as possible, we use a dilated convolutional series structure by successively increasing dilation rate in the bridge connection part of the prediction module. The size of the convolution kernel is and the number of convolution kernels is 512. The dilation rate is set to 1, 2, 4, 8, 16, and 32 in turn. These hyper parameters are tuned on the validation set in experiments. After each convolution operation, Batch Normalization and ReLu activation function are used. To produce more rich information, we fuse different scales of feature maps from various dilated convolution outputs. The decoder part corresponding to the encoder part has three blocks to restore the size of the original image. Each block includes a deconvolution layer and two convolution layers. The function of the deconvolution operation is to upsample the feature maps obtained in the previous stage by two times, and then the upsampled feature maps and the corresponding encoder maps are concatenated. Then, two convolution layers are followed to extract features. Each convolution layer is followed by the Batch Normalization and ReLu activation function. Following the decoder, we use a convolution kernel of size to convert the number of channels of the feature maps to 1, and then the Sigmoid activation function is used to finally obtain the prediction probability map of the prediction module. To further correct the residual between the result of the prediction module and the real result, the prediction probability map is inputed to the residual refinement module.
2.4. Residual Refinement Module
At present, most of the methods for automatic building extraction of remote sensing images based on deep learning generate the building extraction results in one step without further correcting the obtained results in the model. For example, when using networks such as encoder–decoder for building extraction, the input remote sensing image is first subjected to feature extraction by the encoder, and then the size of the original image is restored by the upsampling operation of the decoder. Finally, the building extraction results can be obtained. However, the building extraction results obtained in this way may be significantly different from the real results. To further correct the residuals between the results obtained from the prediction module and the real results, we propose a new residual refinement module RRM_Bu. It takes the single-channel probability map output by the prediction module as the input, and automatically learns the residual between the input image and the corresponding real result during the training process to further refine the input image, producing more accurate building extraction results.
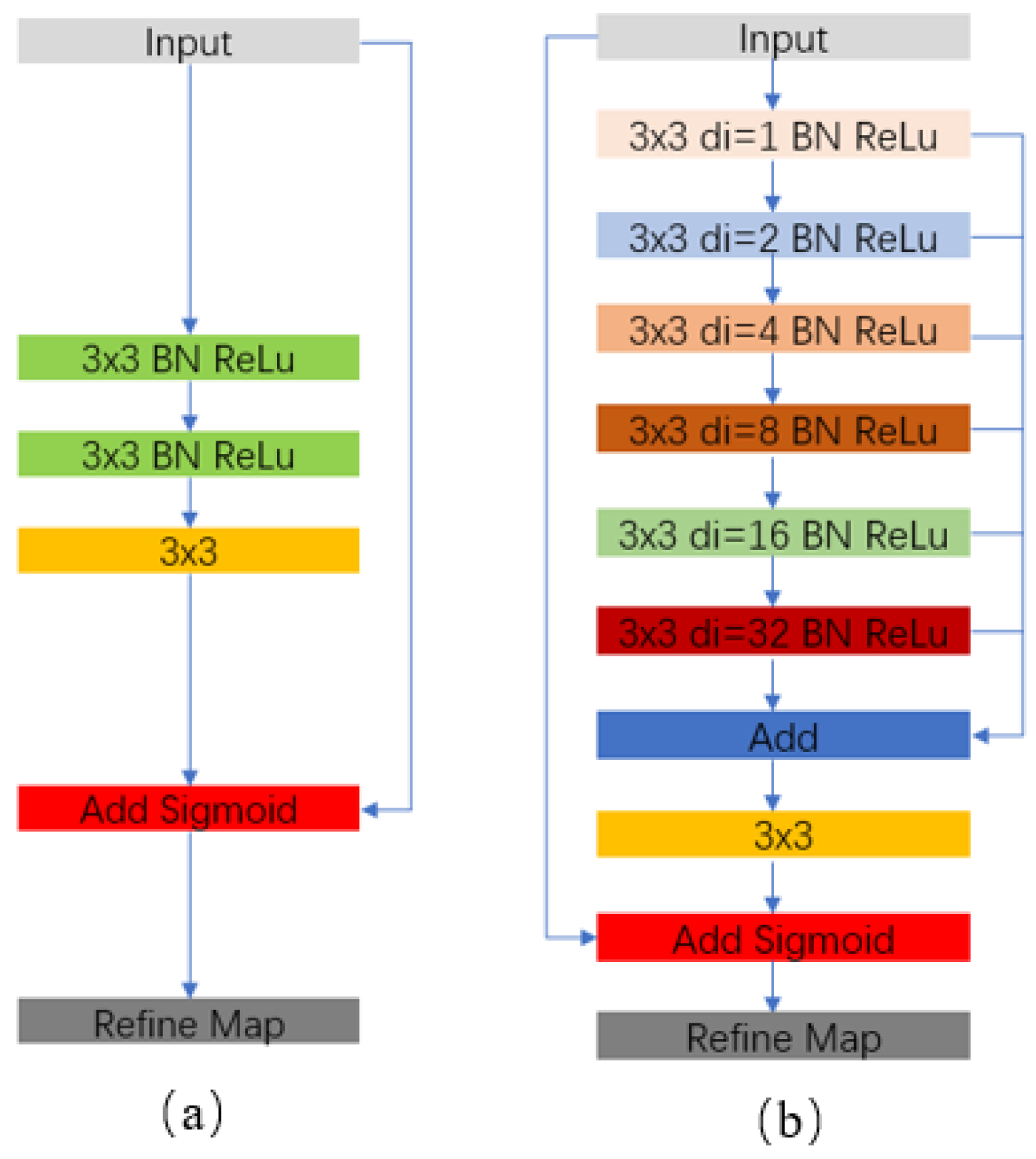
The residual refinement module RRM_Lc based on local context information was originally proposed by Peng et al. [
37], and is used to further refine the boundary. This structure is shown in
Figure 3a. Although RRM_Lc can improve the accuracy of the boundary to a certain extent, due to the small number of network layers, it is impossible to extract deeper features of the input image. On the other hand, this structure does not increase the receptive field during feature extraction so that it cannot extract more global features. In high-resolution remote sensing images, there are a large number of large buildings with inconsistent tone and textures or complex shapes. When using RRM_Lc to extract features from the input image, the receptive field is not enough to contain the entire building and the surrounding background. Consequently, it is impossible to extract sufficient global features, which fails to handle the problems of incomplete building extraction and inaccurate building footprint extraction. Therefore, we propose a new residual refinement module RRM_Bu which has more layers and larger receptive field when extracting features.
The structure of RRM_Bu is shown in
Figure 3b. It is similar to the structure of the bridge connection part in the prediction module, which uses six atrous convolutions with a dilation rate of 1, 2, 4, 8, 16, and 32 to extract features and then fuses feature maps of different scales in an additive manner. After each convolution operation, the Batch Normalization and ReLu activation function are used. The number of kernels of the atrous convolution is 64. Then, a convolution kernel of size
and a step size of 1 is used to convert the number of channels of feature map to 1. Since the input image of RRM_Bu contains the preliminary information of the prediction module, we fuse the input image with the feature map obtained at this stage in an additive manner and then input the fused result into the Sigmoid function to obtain the final probability map. Compared with RRM_Lc, the residual refinement module proposed in this paper has deeper layers, which can further extract the deep features of the input image. In addition, the use of atrous convolution gradually extracts more global information and fuse multi-scale information, which is not only beneficial to improving the building footprint extraction accuracy of the building but also beneficial to obtaining more complete building extraction results. The experiments presented in
Section 3 demonstrate that our residual refinement module performs better than RRM_Lc.
2.5. Loss Function
The loss function adopted in the training process of the network is Dice loss, which is calculated as:
where
represents Dice loss and
is Dice coefficient.
Dice coefficient, first proposed in [
38], demonstrates that maximizing the Dice coefficient in training networks can solve the problem of data imbalance in medical image segmentation. Since minimizing Dice loss when training a network is essentially consistent with maximizing the goal of Dice coefficient, we use the Dice loss as the loss function. The calculation of Dice coefficient is shown in Equation (
2):
where
is the predicted probability value of the ith pixel of the image,
is the true value of the ith pixel of the image, and
N is the total number of pixels of the image.
In the two-class image segmentation task, the Binary Cross Entropy loss (BCE loss) [
39] is the most commonly used loss function, which is shown in Equation (
3).
where
is BCE loss,
is the predicted probability value of the ith pixel of the image,
is the true value of the ith pixel of the image, and
N is the total number of pixels of the image.
We compare BCE loss and Dice loss in
Section 3 to determine the loss function of BRRNet.
3. Experiments and Analysis
This section presents the experimental evaluation of the effectiveness of BRRNet proposed in this paper on the automatic building extraction of high-resolution remote sensing image, by comparing BRRNet with five other state-of-the-art methods.
Section 3.1 describes the dataset used in the experiments.
Section 3.2 presents the evaluation metrics of the experiments.
Section 3.3 illustrates the details of the experiments.
Section 3.4 shows the comparative experimental results along with analysis.
3.1. Dataset
The dataset used in the experiments is the Massachusetts Building Dataset [
24]. This dataset contains 151 aerial images of the Boston area. The size of each image is
pixels and the resolution is 1 m. This dataset is already divided into three parts. The training set has 137 images, the validation set has 4 images, and the testing set has 10 images. The buildings in this dataset are mainly villas and commercial center buildings. There are many buildings with different tones and textures or complex shapes. Two types of buildings are shown in
Figure 4.
3.2. Evaluation Metrics
We adopted two evaluation metrics to measure the effectiveness of our method: Intersection over Union (IoU) and F1-Score.
Mostly four indicators are used to evaluate the effectiveness in image pixel-level prediction tasks: true positive case (TP), false positive case (FP), true negative case (TN) and false negative case (FN). TP refers to the positive sample that is predicted to be a positive example. FP refers to the negative sample that is predicted to be a positive example. TN refers to the negative sample that is predicted to be a negative example. FN is the positive sample that is predicted to be a negative example. The evaluation metrics used to measure the effectiveness of our method are calculated based on these four indicators.
IoU is a common evaluation metric in image semantic segmentation. The degree of similarity between the predicted result and the ground truth is measured by calculating the IoU of them. The larger is the IoU value, the higher is the similarity between predicted results and ground truths. The calculation of IoU is shown in Equation (
4).
F1-Score is also a commonly used evaluation metric and is the harmonic mean of precision and recall. Precision means the proportion of positive cases that are predicted to be true among all predicted positive cases. The calculation of precision is shown in Equation (
5). Recall means the proportion of positive examples that are predicted to be true among all positive examples. The calculation of recall is given by Equation (
6). These evaluation metrics relate to the effectiveness of the model from different aspects. To balance the results of precision and recall, we used F1-Score as another measure, as expressed in Equation (
7).
3.3. Implementation Details
Due to memory limitations, remote sensing images needed to be cropped into tiles and then input into the network for training. We used a sliding window with a size of pixels and set the step size in both the horizontal and vertical directions to 64 for image cropping. Therefore, the size of image tiles was pixels. The same parameter initialization method and optimizer were used in the training process in all experiments. We used the glorot_uniform to initialize the parameters of the convolution operation. The batch size was set to 8. We used Adam as the optimizer and initialize the learning rate to . We calculated the loss of validation set after each epoch. If the loss of validation set did not decrease after three epochs, the previous learning rate was multiplied by the attenuation coefficient of 0.1, and used as the new learning rate. We used a GPU to train our model and the entire training process took about 20 h.
The implementation of our model was based on TensorFlow v1.14. The experimental environment was Ubuntu16.04. The CPU model was Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00GHz and the GPU model is TITAN XP.
3.4. Comparisons and Analysis
To evaluate the effectiveness of BRRNet proposed in this paper, several sets of comparative experiments were carried out on the Massachusetts Building Dataset. Firstly, we compared different network structures and different loss functions to determine the structure and loss function of BRRNet, then compared BRRNet with five state-of-the-art methods, and finally performed migration experiments of RRM_Bu.
Comparative experiments of different network structures. We took U-Net as the baseline. Firstly, we compared our prediction module with U-Net to evaluate its effectiveness, and then we applied our residual refinement module RRM_Bu to U-Net for validation. Then, we combined the prediction module and the residual refinement module RRM_Bu to form our network BRRNet and compared it with the network combining the prediction module and the residual refinement module RRM_Lc. To ensure fairness, we used BCE loss in all comparative experiments of the network structure.
Table 1 shows the results of the comparative experiment. As shown in
Table 1, our prediction module for building extraction is significantly better than U-Net, with IoU/F1-Score increased by 0.0271/0.019. Applying our residual refinement module RRM_Bu to U-Net also significantly improve the result, with IoU/F1-Score increased by 0.0358/0.025. Therefore, the prediction module and the residual refinement module proposed in this paper are effective. Moreover, the combination of our prediction module and the residual refinement module RRM_Bu is better than the combination of our prediction module and RRM_Lc and obtained the highest scores in IoU and F1-Score in the comparative experiment of network structure. To further evaluate the effectiveness of our method, we analyzed the building extraction results of different methods from a qualitative perspective.
Figure 5 shows the building extraction results of the baseline U-Net and the combination of our prediction module and residual refinement module RRM_Bu. Rows 1 and 2 of
Figure 5 show that, for the buildings with inconsistency of tone and textures, there is an obvious problem of missing part of the building in the building extraction results obtained using U-Net. In contrast, the buildings of this type extracted by our method are more complete. As shown in Row 3 of
Figure 5, for the buildings with complex shape, the building footprints obtained by U-Net differ greatly from the ground truth, but the building footprints obtained by our method are very similar to the ground truth, which demonstrates that our method can obtain much more accurate building footprints.
Comparative experiments of different loss functions. The number of pixels in background is usually much larger than that in the buildings in the remote sensing images, which leads to a serious data imbalance problem in the building extraction task. This problem causes the extraction results to be more biased towards the background, which causes problems with missing building parts in the results. The Dice loss proposed by Milletari et al. [
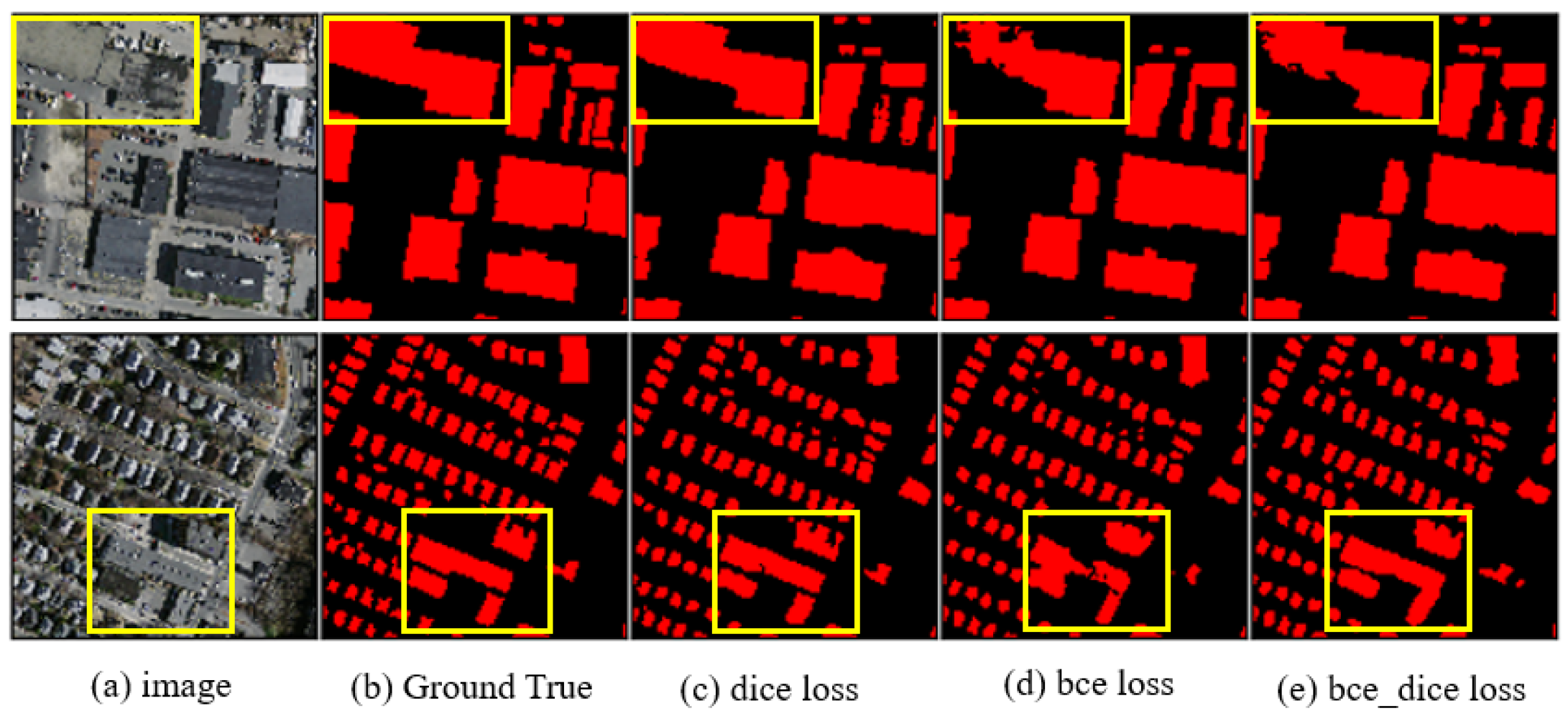
38] can effectively solve the problem of data imbalance in medical image segmentation tasks. Therefore, we attempted to use Dice loss as the loss function in training to solve the data imbalance problem in the task of building extraction from remote sensing images. To validate the effectiveness of Dice loss, we used different loss functions including BCE loss, Dice loss, and the sum of BCE loss and Dice loss to train our network BRRNet. As shown in
Table 2, when we used BCE loss as the loss function, the result is not so good. The result obtained by using the sum of BCE loss and Dice loss as the loss function is slightly better. Moreover, the result obtained by using Dice loss as the loss function achieves the highest score on both IoU and F1-Score. On the other hand, from a qualitative perspective,
Figure 6 shows that the integrity of building extraction in the results obtained by using Dice loss is better than that of the others. Therefore, we used Dice loss as the loss function of our network BRRNet.
When BCE loss was used as the loss function in training, the penalty weights for the pixels in buildings and background are the same. However, because the number of pixels in background is much larger than that in buildings, it is easy to fall into the local optimum instead of the global optimum in training, which causes the extraction result to be biased to the background, so that the extraction result of buildings may be partially missing. The difference from BCE loss is that the essence of Dice loss is to make the intersection over union of the predicted result and the real result continuously increase during the training process, which is conducive to approaching the global optimal. Therefore, Dice loss can better solve the problem of data imbalance and improve the integrity of building extraction.
Comparative experiments with state-of-the-art methods. To further evaluate the effectiveness of our method, we compared BRRNet with five state-of-the-art methods including SegNet [
26], Bayesian-SegNet [
26], RefineNet [
40], PSPNet [
41], and DeepLabv3+ [
42].
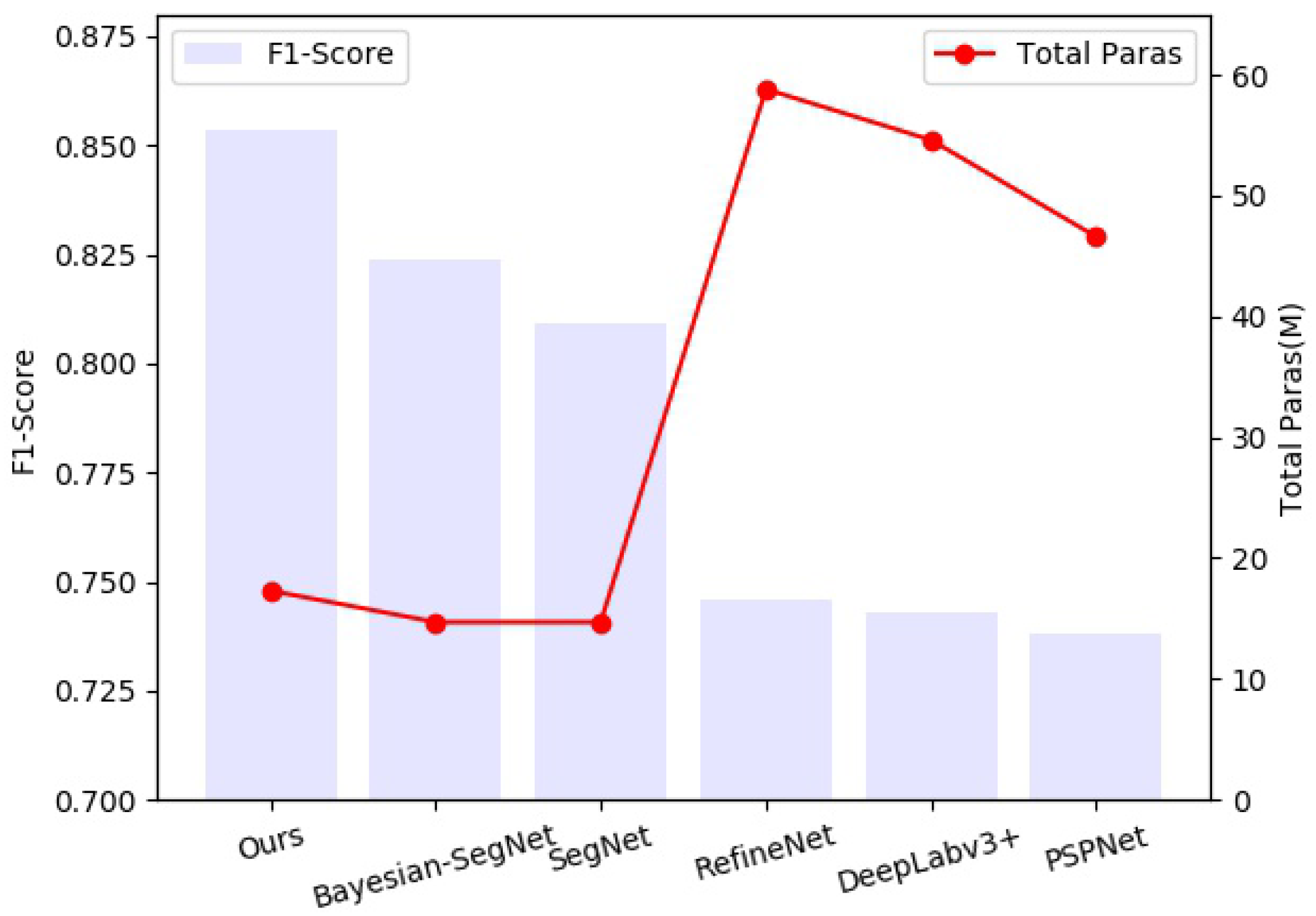
Table 3 shows the experimental results. It can be seen that our method gets higher scores than other methods in both IoU and F1-Score.
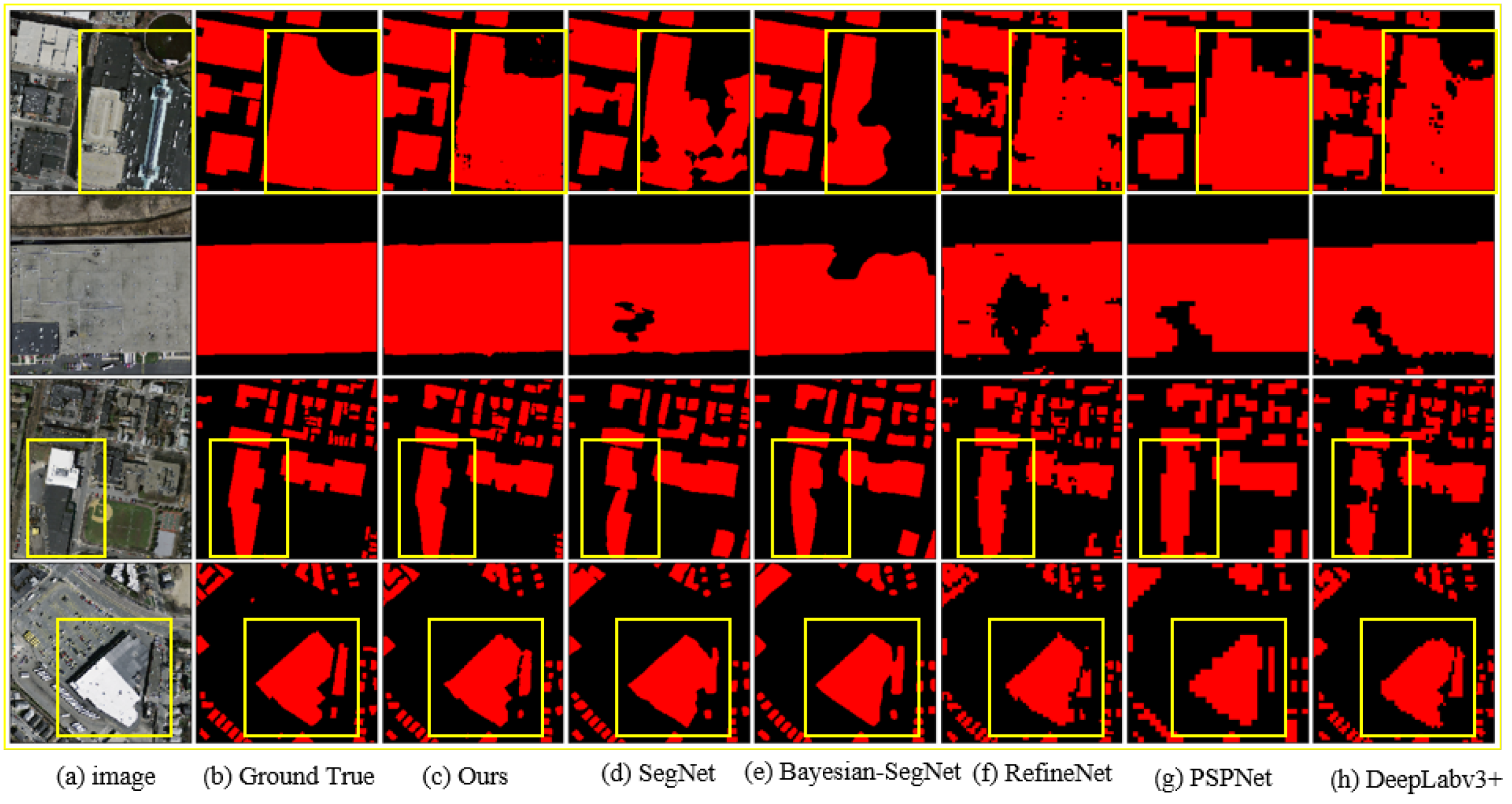
Figure 7 shows the results of some typical buildings. The buildings in Rows 1 and 2 of
Figure 7 are large buildings with inconsistent hue and texture. The results of the other five methods generally have the problem of incomplete building extraction. However, our method obtains much more complete results when extracting such buildings. The buildings in Rows 3 and 4 of
Figure 7 have complex shape. In the results of the other five methods, the building footprints are generally different from the real results, and the details are not prominent. However, the results of our method show higher accuracy in terms of the building footprints, and the details are similar to the real results. Therefore, our method can effectively solve the problems of incomplete building extraction and inaccurate building footprint extraction of the buildings with complex shapes.
We analyzed the reasons for the above results in detail. Most of the previous fully convolutional neural networks use pooling layers to increase the receptive field during feature extraction to extract more global information. The introduction of the pooling layers reduces the size of the feature maps and causes the loss of information of the original image, which eventually affects the positioning accuracy. To avoid serious loss of input image information, these models do not use too many pooling layers, and the number of pooling layers is generally less than 5. However, there are many large buildings with inconsistent tones and textures and complex shapes in high-resolution remote sensing images. This type of building occupies many pixels; thus, the methods using a small number of pooling layers to expand the receptive field cannot contain the whole building and the surrounding background. These methods can only extract local features of this type of building, which leads to incomplete extraction of such buildings and inaccurate building footprint extraction for buildings with complex shapes. Besides, because these networks are based on encoder–decoder single-stage structures, it is not possible to further refine the results.
The BRRNet proposed in this paper has two stages: preliminary prediction and residual refinement. We use our prediction module to output the preliminary results of input image. The prediction module first uses three pooling layers to expand the receptive field during feature extraction. To avoid the loss of image information due to the continued reduction in the size of the feature maps, we use an atrous convolution series structure with a gradually increasing dilation rate to further increase the receptive field, so that it can contain as much as possible the whole building and the surrounding background to extract more global information. Then, it fuses the multi-scale feature maps of different atrous convolutions to obtain richer information, which better solves the problem of incomplete extraction of such buildings. Furthermore, we use the output of the prediction module as the input of our residual refinement module RRM_Bu, so that our network can further learn the residuals between the output of the prediction module and the real results. Particularly, when the difference between the preliminary result and the real label becomes large, our network will further refine the residuals to produce more complete buildings and accurate building footprints. In addition, we use Dice loss as the loss function in training to handle the data imbalance that biases the extraction results to the background, which also improves the accuracy of buildings.
Migration experiments of RRM_Bu. The prediction module and the residual refinement module proposed in this paper are two separate parts of our network BRRNet. We use the residual refinement module to further refine the residuals between the output of the prediction module and the ground truth so as to obtain more accurate building extraction results. To confirm that our residual refinement module can be readily migrated to other networks and improve the performance of the basic networks, we migrated it to three different networks: FCN-32s [
25], SegNet [
26], and Bayesian-SegNet [
26]. The experimental results are shown in
Table 4. As shown in the table, migrating our residual refinement module to these networks significantly improves the effectiveness of the corresponding counterparts, especially in the case of poor results given by the basic network. For example, the result of FCN-32s has been greatly improved after migrating RRM_Bu to it.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}