1. Introduction
With the rapid development of imaging technology in the field of remote sensing, high-resolution (HR) remote sensing images are provided by many airborne and spaceborne sensors, for instance, RADARSAT-2, Gaofen-3, TerraSAR-X, Sentinel-1, Ziyuan-3, Gaofen-2 and unmanned aerial vehicles (UAV). Nowadays, these HR images have been applied to the national economy and the military fields, such as urban monitoring, ocean monitoring, maritime management, and traffic planning [
1,
2,
3]. In particular, territories such as military precision strike and maritime transport safety tend to take full advantage of the HR remote sensing images for object detection and segmentation [
3,
4,
5].
Traditional object detection methods in remote sensing (RS) imagery mainly pay attention to the detection results with the bounding boxes and the rotational bounding boxes, as shown in
Figure 1b,c. Cheng et al. [
6] proposed an approach to improve the performance of target detection by learning the rotation-invariant CNN (RICNN) model. Ma et al. [
7] applied the You Only Look Once (YOLOv3) approach to locate collapsed buildings from remote sensing images after the earthquake. Gong et al. [
8] put forward a context-aware convolutional neural network (CA-CNN) method to improve the performance of object detection. Liu et al. [
9] proposed a multi-layer abstraction saliency model for airport detection in synthetic aperture radar (SAR) images. Wei et al. [
10] came up with a HR ship detection network (HR-SDNet) to perform precise and robust ship detection in SAR images. Deng et al. [
11] devised a method to detect multiscale artificial targets in remote sensing images. An et al. [
12] came up with a DRBox-v2 with rotatable boxes to boost the precision and recall rates of detection for object detection in HR SAR images. Xiao et al. [
13] came up with a novel anchor generation algorithm to eliminate the deficiencies in the previous anchor-based detectors. However, these detection results with the bounding boxes and the rotational bounding boxes do not reflect the pixel-level contours of the original targets.
Traditional semantic segmentation methods in remote sensing imagery mainly focus on pixel-level segmentation results. Shahzad et al. [
14] used Fully Convolution Neural Networks to automatically detect man-made structures, especially buildings in very HR SAR Images. Chen et al. [
15], based on a fully convolutional network (FCN), proposed a symmetrical dense-shortcut FCN (SDFCN) and a symmetrical normal-shortcut FCN (SNFCN) for the semantic segmentation of very HR remote sensing images. Yu et al. [
16] came up with an end-to-end semantic segmentation framework that can simultaneously segment multiple ground objects from HR images. Peng et al. [
17] came up with dense connection and FCN (DFCN) to automatically acquire fine-grained feature maps of semantic segmentation for HR remote-sensing images. Nogueira et al. [
18] came up with a novel method based on ConvNets to accomplish semantic segmentation in HR remote sensing images. However, these segmentation results cannot distinguish different instances in each category. Therefore, instance segmentation is introduced into the field of remote sensing.
Instance segmentation in remote sensing (RS) images is a complicated problem and one of the most challenging tasks [
3,
19]. It aims to predict both the location and the semantic mask of each instance in an image, as shown in
Figure 1d. This task is much harder than object detection and semantic segmentation. However, there are rare methods currently suitable for instance segmentation in RS images. Meanwhile, it is more difficult to implement instance segmentation on HR RS images due to the complex background of remote sensing images. Therefore, this paper focuses on a high-quality instance segmentation method for remote sensing images, especially for high-resolution artificial targets.
Nowadays, many instance segmentation methods have emerged in the area of computer vision, which uses FPN structures as the backbone network, such as Mask R-CNN [
19], Cascade Mask R-CNN [
20,
21], Mask Scoring R-CNN [
22]. In the remote sensing field, Mou et al. [
2] came up with a novel method to perform vehicle instance segmentation of aerial images and videos obtained by UAV. Su et al. [
3] introduced the precise regions of interest (RoI) pooling into the Mask R-CNN to solve the problem of loss of accuracy due to the coordinate quantization in optical remote sensing images. However, these methods mostly utilize low-resolution representations or restore high-resolution representations for instance segmentation. Therefore, these methods are not appropriate for instance segmentation at the pixel-level in the HR RS images due to the huge loss of spatial resolution. Furthermore, in Cascade Mask R-CNN [
20,
21], the lack of interactive information flow between the mask branches will lead to the loss of the ability to gradually adjust and enhance between stages. In this article, a novel instance segmentation approach of HR remote sensing imagery based on Cascade Mask R-CNN [
20,
21] is proposed to address these problems, which we call the high-quality instance segmentation network (HQ-ISNet).
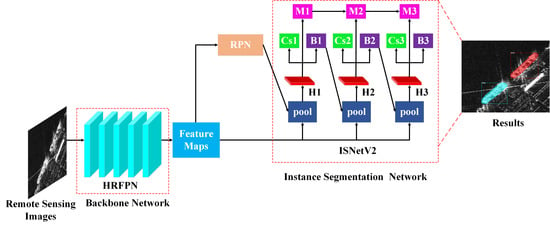
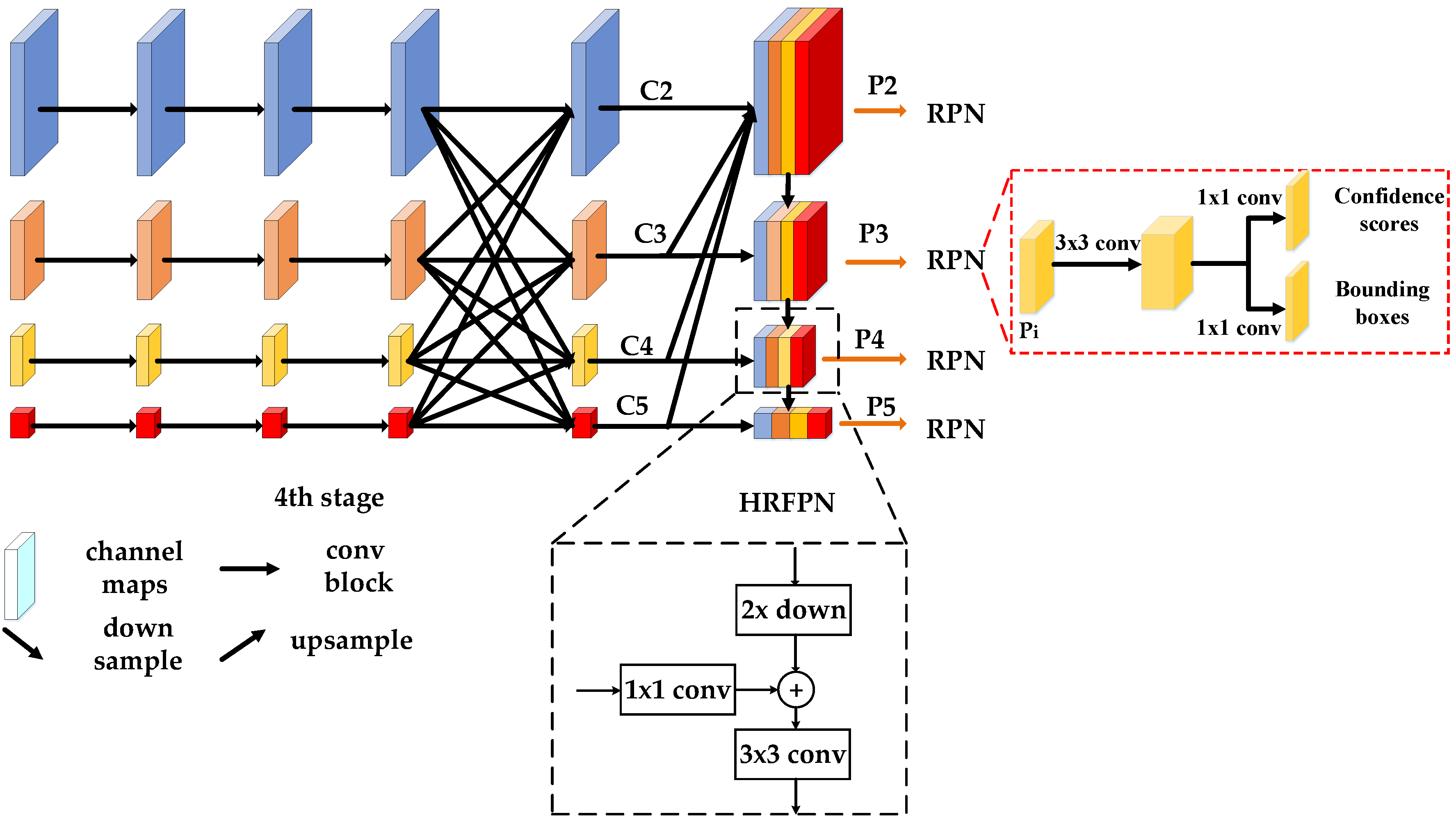
First, the HR feature pyramid network (HRFPN) is introduced into pixel-level instance segmentation in remote sensing images to fully utilize multi-level feature maps and maintain HR feature maps. Next, to refine mask information flow between mask branches, the instance segmentation network version 2 (ISNetV2) is proposed to promote further improvements in mask prediction accuracy. Then, we construct a new, more challenging dataset based on the synthetic aperture radar (SAR), ship detection dataset (SSDD) and the Northwestern Polytechnical University very-high-resolution 10-class geospatial object detection dataset (NWPU VHR-10) for remote sensing images’ instance segmentation, which can be used as a benchmark for evaluating instance segmentation algorithms in the HR remote sensing images. Finally, the proposed HQ-ISNet is optimized in an end-to-end manner. Extensive experimental analyses and comparisons on the SSDD dataset [
23] and the NWPU VHR-10 dataset [
3,
6] prove that the proposed framework is more efficient than the existing instance segmentation algorithms in the HR remote sensing images.
The main contributions of this article are shown below:
We introduce HRFPN into remote sensing image instance segmentation to fully utilize multi-level feature maps and maintain HR feature maps, so as to solve the problem of spatial resolution loss in FPN;
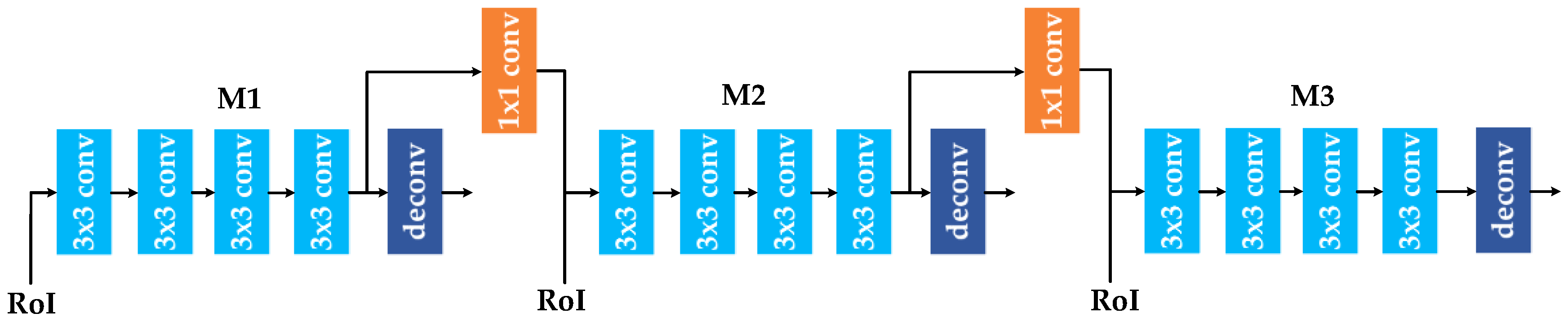
We design an ISNetV2 to refine mask information flow between mask branches, thereby promoting the improvement in mask prediction accuracy;
We construct a new, more challenging dataset based on the SSDD and the NWPU VHR-10 dataset for remote sensing images instance segmentation, and it can be used as a benchmark for evaluating instance segmentation algorithms in the HR remote sensing images. In addition, we provide a study baseline for instance segmentation in remote sensing images;
Most importantly, we are the first to perform instance segmentation in SAR images.
The organization of this paper is as follows.
Section 2 is related to object detection and instance segmentation.
Section 3 presents our instance segmentation approach.
Section 4 describes the experiments, including the dataset description, evaluation metrics, experimental analysis, and experimental results.
Section 5 discusses the impact of the dataset.
Section 6 comes up with a conclusion.
4. Experiments
In this section, the instance segmentation approaches will be evaluated in high-resolution remote sensing imagery.
4.1. Dataset Description
4.1.1. The SSDD Dataset
The SSDD datasets [
23] include 1160 SAR images with resolutions ranging from 1 to 15 m. Besides this, the SSDD has a total of 2540 ships. We further mark the instance masks directly on the SSDD dataset. In this paper, we use the LabelMe [
42] open source project on GitHub to annotate these SAR images. Then, LabelMe converts the annotation message into the COCO JSON format. The SAR images annotation process is shown in
Figure 7. In all experiment, the datasets are randomly split into a train dataset 70% (812 images) and a test dataset 30% (348 images).
4.1.2. The NWPU VHR-10 Dataset
The experiment also uses the NWPU VHR-10 datasets [
3,
6], which is a challenging ten-class geospatial object detection dataset. The positive image set in the datasets contains a total of 650 high-resolution optical remote sensing images with a resolution ranging from 0.08 to 2 m. These images were acquired from Google Earth and Vaihingen data. Su et al. [
3] manually used the instance masks to annotate ten-class objects in these optical remote sensing images. Then, LabelMe converts the annotation message into the COCO JSON format. Some examples of images and the corresponding annotated instance masks are shown in
Figure 8. In all experiment, the datasets are randomly split into a train dataset 70% (455 images) and a test dataset 30% (195 images).
4.2. Evaluation Metrics
For the instance segmentation of remote sensing imagery, the intersection over union (IoU) is the overlap rate between the ground-truth and the predicted mask. The calculation formulas of IoU is as follows
where
represents the predicted mask and
denotes the ground-truth mask.
The performance of the instance segmentation methods in remote sensing images is quantitatively and comprehensively evaluated by the standard COCO [
43] metrics. These metrics include average precision (AP), AP
50, AP
75, AP
S, AP
M, AP
L [
43]. The average precision (AP) is averaged across all 10 IoU thresholds (0.50: 0.05: 0.95) and all categories. Averaging over IoUs rewards detectors with better localization. The larger AP value indicates that the more accurate the predicted instance masks, the better the instance segmentation performance. AP
50 represents the calculation under the IoU threshold of 0.50; AP
75 is a stricter metric and represents the calculation under the IoU threshold of 0.75. Therefore, AP
75 performs better than AP
50 in the instance of mask accuracy evaluation. The greater AP
75 value indicates more accurate instance masks. AP
L is set for large targets (area > 96
2); AP
M is set for medium targets (32
2 < area < 96
2); AP
S is set for small targets (area < 32
2).
4.3. Implementation Details
All the experiments are implemented on pytorch and mmdetection [
44]. The operating system is Ubuntu 16.04. A single GTX-1080Ti GPU is used to train and test the detectors.
In our experiments, the HQ-ISNet uses HRFPN-W18, HRFPN-W32, and HRFPN-W40 for feature extraction, in which 18, 32, and 40 indicate the widths of the HR subnetworks, respectively. Regarding HRFPN-W18, HRFPN-W32, and HRFPN-W40, the dimensions of the HR representation are reduced to 144, 256, and 320, respectively, by a convolution. For HRFPN-W18, the output channels of the four-resolution feature maps are 18, 36, 72, and 144. For HRFPN- W32, they are 32, 64, 128, and 256. For HRFPN-W40, they are 40, 80, 160, and 320. In addition, the IoU thresholds of the three detection heads were set to 0.5, 0.6, and 0.7, respectively.
The comparative experiments are performed using advanced object detection and instance segmentation approaches: Faster R-CNN [
33], Mask R-CNN [
19], Cascade R-CNN [
35], Cascade Mask R-CNN [
20,
21], Mask Scoring R-CNN [
22], and Hybrid Task Cascade [
20]. They all use ResNet-FPN [
45,
46] as backbone networks.
For HQ-ISNet, Hybrid Task Cascade, and Cascade Mask R-CNN, we use a single GPU to train the model for 20 epochs [
20,
21,
41,
44]. The initial learning rate (LR) is set as 0.0025 for these methods. Then, the LR will gradually reduce by 0.1 after 16 and 19 epochs, respectively. The batch size is set to two images. We train Faster R-CNN, Mask R-CNN, Cascade R-CNN, and Mask Scoring R-CNN with batch size of 2 for 12 epochs [
20,
21,
41,
44]. The initial learning rate is set as 0.0025 for these methods. Then, the learning rate will gradually reduce by 0.1 after eight and 11 epochs, respectively. Besides, SGD is used to optimize the entire model. We use a momentum of 0.9 and a weight decay of 0.0001. The input images are adjusted to 1000 px along the long axis and 600 px along the short axis by the bilinear interpolation. Additionally, the overall framework is optimized in an end-to-end manner. All other hyper-parameters follow the literature [
10,
19,
20,
21,
22,
33,
35,
44] in this paper.
4.4. Results and Analysis of HQ-ISNet
4.4.1. Results of the HQ-ISNet
The instance segmentation outcomes of the proposed approach in SAR images and remote sensing optical images are shown in
Figure 9. a and c are ground-truth mask; b and d are the predicted instance outcomes. As can be seen in
Figure 9, HQ-ISNet is suitable for our instance segmentation task in HR remote sensing images. HQ-ISNet has almost no missed detections and false alarms, which guarantees that our mask branch performs instance segmentation. Finally, these artificial targets are correctly detected and segmented. Moreover, the segmentation results of HQ-ISNet are very close to the ground truth. HQ-ISNet successfully completed the instance segmentation task in HR remote sensing images.
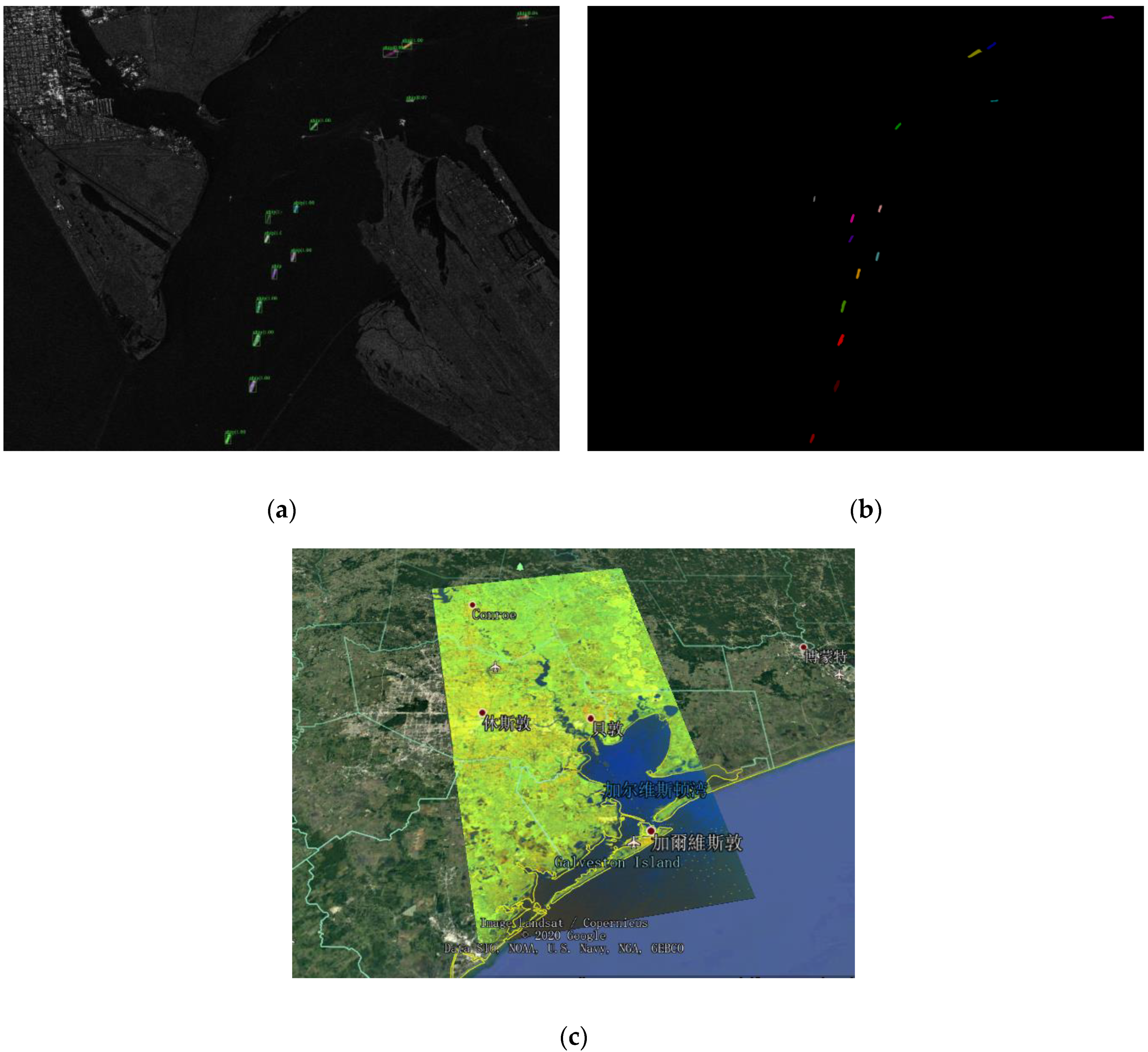
To further test our network, we performed test experiments on the SAR image from the port of Houston. SAR images were obtained with a Sentinel-1B [
47] sensor. The following is the parameter information: the resolution is 3m, the polarization method is HH, and the imaging mode is S3-StripMap. In addition, we have annotated according to the labeling methods and principles in
Section 4.1.1. As can be seen from
Figure 10, HQ-ISNet successfully completed the instance segmentation task in the SAR image. Our results have almost no missed ships and false alarms, and the segmentation results also are very close to the ground truth.
From
Table 1 and
Table 2, we can see that the HQ-ISNet, based on the ISNetV2 module and HRFPN backbone, has the best instance segmentation performance. It achieves 67.4% and 67.2% AP on the SSDD dataset and NWPU VHR-10 dataset, respectively. More specifically, with the help of the HRFPN, our network achieves a 2.1% and 5.3% performance improvement on the SSDD dataset and NWPU VHR-10 dataset in terms of AP. With the help of the ISNetV2, our network achieves 1.3% and 4.8% performance improvement on the SSDD dataset and NWPU VHR-10 dataset in terms of AP. Moreover, for AP
75 score, our network achieves a gain of 1% and 1.6% on the SSDD dataset with ISNetV2 and HRFPN, respectively. For the AP
75 value, our network achieves a gain of 5.4% and 6.1% on the NWPU VHR-10 dataset with ISNetV2 and HRFPN, respectively. In the SSDD and NWPU VHR-10 dataset, the AP
50 has also been increased. Besides this, AP
S value, AP
M value, and AP
L value have also been improved in the SSDD and NWPU VHR-10 dataset. Among them, the AP
L in SSDD has a decline rate under the influence of HRFPN. We will discuss this in
Section 5. The HRFPN can maintain a high resolution and solve the problem of spatial resolution loss in FPN, and the ISNetV2 refines the mask information flow between mask branches. Accordingly, the final feature maps are semantically richer and spatially more accurate. The final predicted instance mask is also more accurate. In addition, there are only ships in SSDD, and ten target categories in NWPU VHR-10 involve ship, harbor, ground track field, basketball court, etc. The NWPU VHR-10 dataset with many complex targets needs this rich semantic and spatial information, so its improvement is the most obvious. The results reveal that the HRFPN and ISNetV2 modules can effectively improve instance segmentation performance in remote sensing images.
4.4.2. Effect of HRFPN
The comparison of the outcomes of HRFPN and FPN in SAR images and remote sensing optical images is displayed in
Figure 11. Mask R-CNN is used as a powerful baseline to accomplish our approach and comparison approach. Compared with FPN, the segmentation results of HRFPN are closer to the ground truth mask, and the instance masks of HRFPN are more accurate. It is worth noting that the instance segmentation performance of the HRPFN is better than the original FPN for the high-resolution remote sensing imagery.
From
Table 3 and
Table 4, we can see that the HRFPN is more efficient than FPN in the Mask R-CNN framework for instance segmentation, with less computational complexity and smaller parameters. The AP value is 66.0% on the SSDD dataset, which can achieve a performance improvement of nearly 1.5% compared to FPN. In addition, the AP value is 60.7% on the NWPU VHR-10 dataset, which can achieve a performance improvement of nearly 3.3% compared to FPN. It has been suggested that our approach acquires more accurate instance masks and improves the instance segmentation performance. The AP
50 and AP
75 scores are 96.2% and 85.0% on the SSDD dataset, which achieves a 0.5% and 2.4% performance improvement over the FPN, respectively. Moreover, the AP
50 and AP
75 scores are 92.7% and 65.5% on the NWPU VHR-10 dataset, which achieves a 1% and 2.7% performance improvement over the FPN, respectively. We find that AP
75 improves significantly compared to AP
50 on both datasets. With looser metrics, AP
50, our method may approach the best performance in the two datasets, so the improvement is not significant. However, under more stringent indicators AP
75, our method has been greatly improved. Therefore, the predicted instance masks are more accurate. Besides, the performance improvement is obtained for small ships (AP
S) on the SSDD dataset, and AP
M maintains the original performance. We disucss AP
L in
Section 5. Importantly, the AP
S score, AP
M score, and AP
L score have been greatly increased on the NWPU VHR-10 dataset. In particular, the performance improvement of small targets is most obvious, and small targets achieve nearly 6.2% performance gains.
Furthermore, we find that HRFPN improves the NWPU VHR-10 dataset more significantly than the SSDD dataset. There are only ships in SSDD, and ten target categories in NWPU VHR-10 involve ship, harbor, ground track field, basketball court, etc. Our HRFPN can maintain a high resolution and solve the problem of spatial resolution loss in FPN. Hence, the final feature maps are semantically richer and spatially more accurate compared with FPN. The NWPU VHR-10 dataset with many complex targets needs this rich semantic and spatial information, so its improvement is the most obvious, especially for small targets. In short, HRFPN can effectively improve instance segmentation performance in remote sensing images, with less computational complexity and smaller parameters.
In the HRFPN structure, the HRFPN-W40 achieves a 66.0% AP score on the SSDD dataset and a 60.7% AP score on the NWPU VHR-10 dataset, which is improved compared with HRFPN-W18 and HRFPN-W32, but it also increases computational complexity and the parameters.
In conclusion, the HRFPN, which fully utilizes multi-level feature maps and can maintain HR feature maps, can make the predicted instance masks more accurate and effectively improve the instance segmentation performance for the HR remote sensing images.
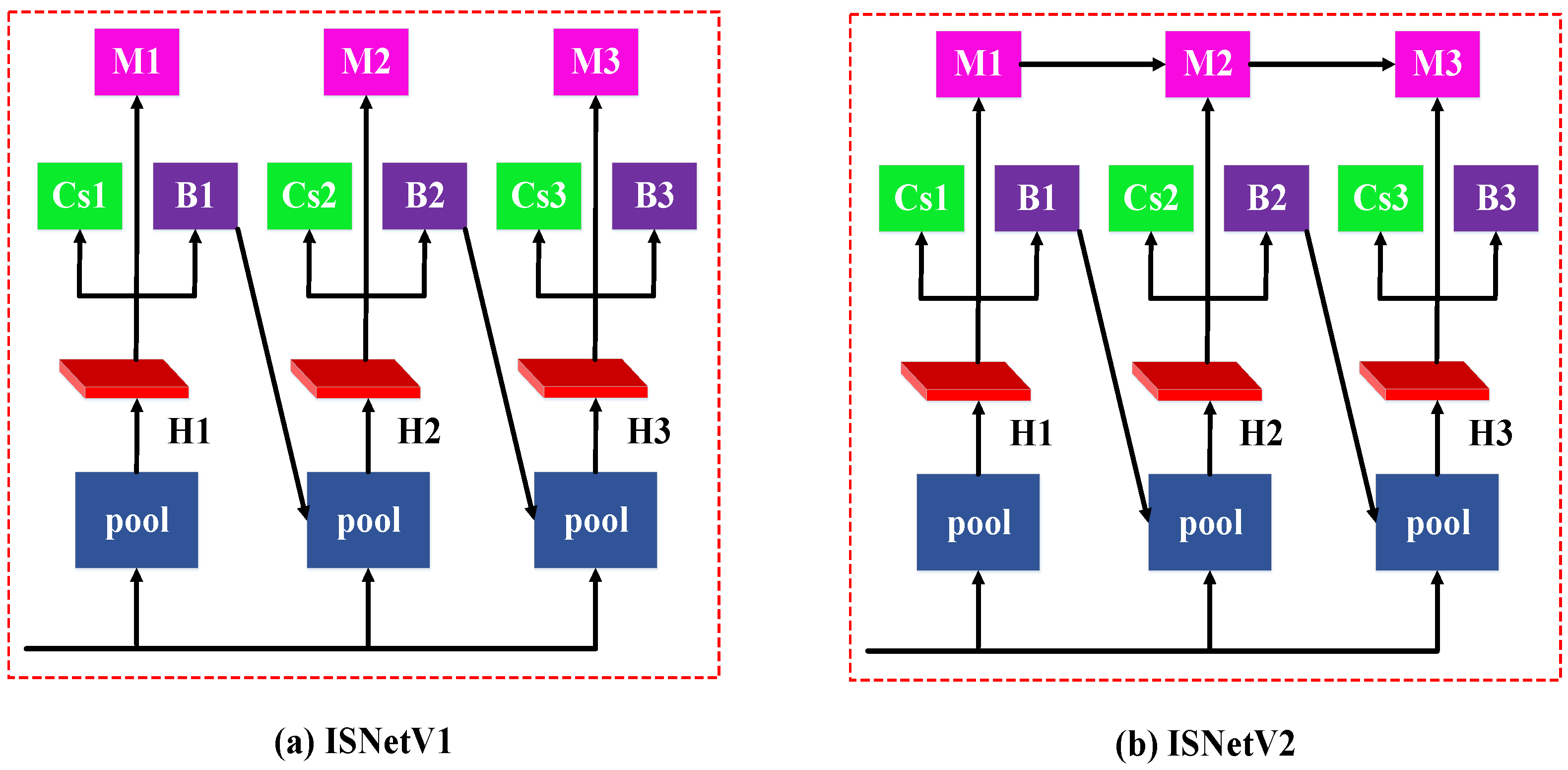
4.4.3. Effect of ISNetV2
The comparison results of ISNetV1 and ISNetV2 in SAR images and remote sensing optical images are displayed in
Figure 12. Cascade Mask R-CNN is used as a powerful baseline to accomplish our approach and comparison approach. Compared with ISNetV1, the segmentation result of ISNetV2 is closer to the ground truth mask. The ISNetV2 is more accurate than ISNetV1 in the mask segmentation. There is no doubt that that the instance segmentation performance of the ISNetV2 is better than the original ISNetV1 for the high-resolution remote sensing imagery, especially for high-resolution artificial targets.
From
Table 5 and
Table 6, we can see that the ISNetV2 is more efficient than ISNetV1 in the Cascade Mask R-CNN framework for instance segmentation, with similar parameters and computational cost. With the ISNetV2, Cascade Mask R-CNN performs better on the SSDD dataset, which can achieve a performance improvement of nearly 1.4% in terms of AP. In addition, the AP value on the NWPU VHR-10 dataset achieves nearly 4.8% performance gains over ISNetV1. It has been suggested that ISNetV2 refines the mask information flow between the mask branches, which promotes further improvements in mask prediction accuracy. The AP
50 and AP
75 scores on the SSDD dataset, compared to ISNetV1, achieve a gain of 1.3% and 1%, respectively. Moreover, the AP
50 and AP
75 scores on the NWPU VHR-10 dataset, compared to ISNetV1, achieve a gain of 2.2% and 5.8%, respectively. The results reveal that the predicted instance mask is more accurate. Importantly, a large performance improvement is obtained for medium ships (AP
M) and large ships (AP
L) on the SSDD dataset, and AP
S also improved. Besides these, the AP
S score, AP
M score, and AP
L score have been greatly increased on the NWPU VHR-10 dataset. As a result, the instance segmentation performance is remarkably enhanced for small, medium and large targets. Furthermore, we find that ISNetV2 improves the NWPU VHR-10 dataset more significantly than SSDD dataset. There are only ships in SSDD, and ten target categories in NWPU VHR-10 involve ship, harbor, ground track field, basketball court, etc. When calculating the IoU, we know that the larger the target, the more pixels it takes, and the inaccurate prediction has a great impact on the quantitative result. Therefore, small changes have a big impact on results. Our ISNetV2 improves the mask information flow and makes the predicted results more accurate. Therefore, the NWPU VHR-10 dataset with a larger target size has the most significant improvement.
In summary, the information flow between the mask branches is refined, which promotes further improvements in mask prediction accuracy. Therefore, ISNetV2 can effectively improve instance segmentation performance in the HR remote sensing imagery.
4.5. Comparison with Other Approaches
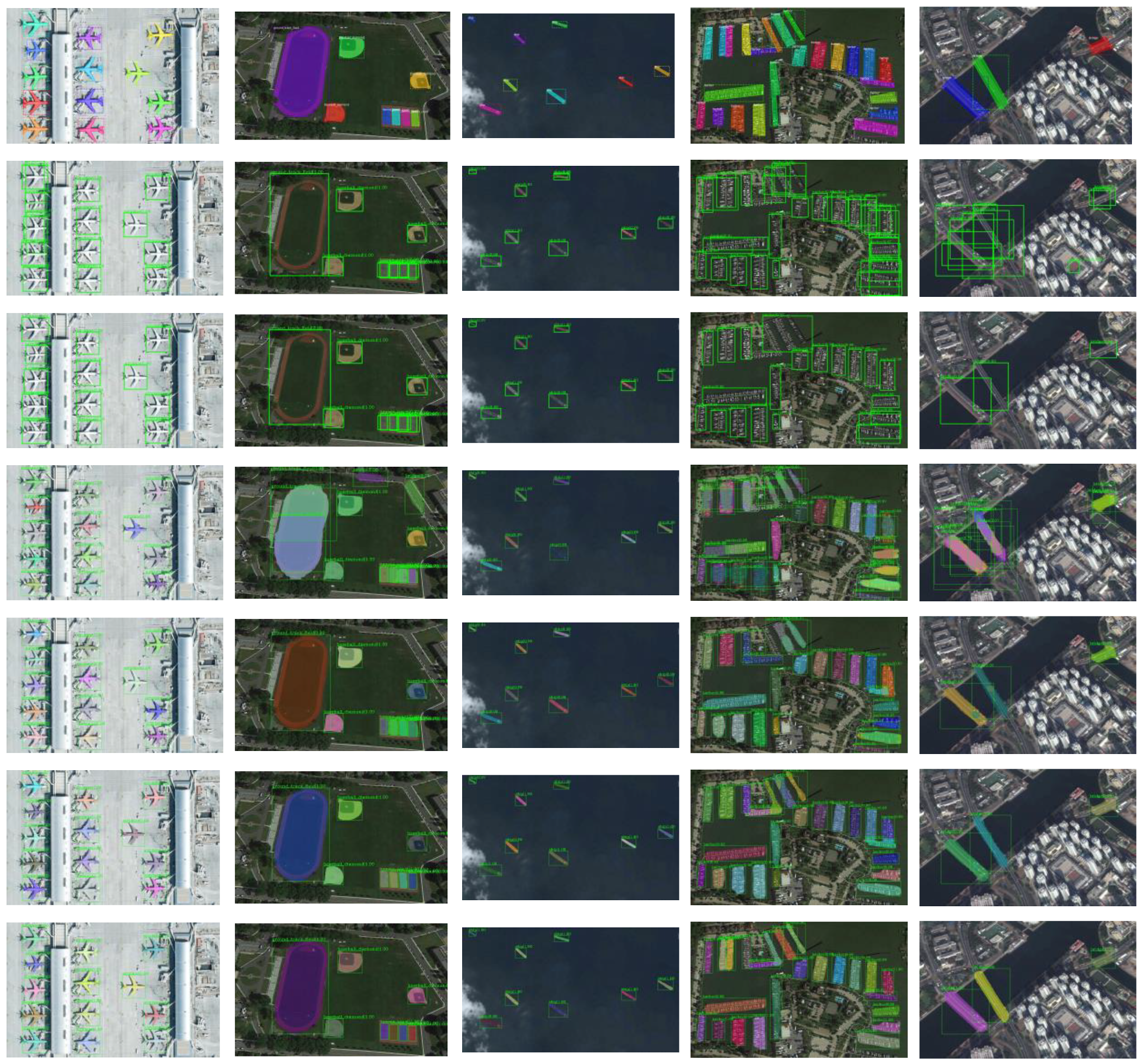
The qualitative outcomes between the HQ-ISNet and the comparison method on the SSDD dataset and NWPU VHR-10 dataset are displayed in
Figure 13 and
Figure 14 to further validate the instance segmentation performance. Row 1 is ground-truth mask; Row 2-4 are the outcomes of Faster R-CNN, Cascade R-CNN, and Mask R-CNN, respectively; Row 5-7 are the outcomes of Cascade Mask R-CNN, Hybrid Task Cascade (HTC), and HQ-ISNet, respectively.
As shown in
Figure 13 and
Figure 14, compared with other instance segmentation methods, our approach can accurately detect and segment artificial targets in multiple remote sensing scenes. Specifically, these artificial targets are accurately covered by the predicted instance masks. HQ-ISNet has almost no missed detections and false alarms, which ensures that our mask branch performs better instance segmentation. Compared with bounding box detection, such as Faster R-CNN and Cascade R-CNN, the results of instance segmentation are closer to the silhouette of the original targets. The instance segmentation can also distinguish between different instances in the same category. The ships in
Figure 13 are distinguished by different colors. The targets, such as airplanes, in
Figure 14 are also distinguished by different colors. Furthermore, compared with other instance segmentation methods, our approach not only has almost no missed targets and false alarms but also has better mask segmentation results. The results of the SSDD dataset and the NWPU VHR-10 dataset imply that our method is suitable for instance segmentation task in HR remote sensing images and has a better mask segmentation performance than the other instance segmentation algorithms.
In
Table 7 and
Table 8, we compare the HQ-ISNet based on ISNetV2 and HRFPN with other advanced approaches on the SSDD dataset and the NWPU VHR-10 dataset to quantitatively evaluate the instance segmentation performance. These methods include Mask R-CNN [
19], Mask Scoring R-CNN [
22], Cascade Mask R-CNN [
21] and Hybrid Task Cascade (HTC) [
20] based on ResNet-FPN [
45,
46].
As can be observed from
Table 7, the HQ-ISNet achieves the highest AP of 67.4%. Compared with Mask R-CNN and Mask Scoring R-CNN, the HQ-ISNet achieves 2.9% and 2.6% improvements, respectively. Besides, the HQ-ISNet achieves gains of 2.3% over Cascade Mask R-CNN. In short, compared with other instance segmentation algorithms on the SSDD dataset, our approach has a better instance segmentation performance and more accurate predicted instance masks. Moreover, the AP
50 score of HQ-ISNet is 96.4%, which has 0.7% improvements over Mask R-CNN, 1.4% gains over Mask Scoring R-CNN, and 1.6% improvements over Cascade Mask R-CNN. The HQ-ISNet attains an 85.8% AP
75, which achieves a gain of 3.2% over Mask R-CNN, 3.4% over Mask Scoring R-CNN, and 2.4% over Cascade Mask R-CNN. It has been established that the mask segmentation will be better and more precise than the other advanced approaches for instance segmentation on the SSDD dataset. The performance of small, medium, and large targets has also been improved on the SSDD dataset according to AP
S, AP
M, and AP
L. Under various AP indicators, we can obtain the same performance as HTC on the SSDD dataset, and some indicators exceed it, such as AP.
As can be observed from
Table 8, the HQ-ISNet attains a 67.2% AP, which achieves a gain of 9.8% over Mask R-CNN, 8.4% over Mask Scoring R-CNN, and 6.9% over Cascade Mask R-CNN. In short, contrasted with other instance segmentation methods on the NWPU VHR-10 dataset, our approach has a better instance segmentation performance and more accurate predicted instance masks. Moreover, the AP
50 score of HQ-ISNet is 94.6%, which has 2.9% improvements over Mask R-CNN, 3.3% gains over Mask Scoring R-CNN, and 2.3% improvements over Cascade Mask R-CNN. The HQ-ISNet attains a 74.2% AP
75, which achieves a gain of 11.4% over Mask R-CNN, 9.3% over Mask Scoring R-CNN, and 7.6% over Cascade Mask R-CNN. It has been established that the mask segmentation will be better and more precise than the other advanced approaches for instance segmentation on the NWPU VHR-10 dataset. The performance of small, medium, and large targets has also been greatly improved on the NWPU VHR-10 dataset according to AP
S, AP
M, and AP
L scores. Under various AP indicators, we can obtain the same performance as HTC on the NWPU VHR-10 dataset, and some indicators exceed it, such as AP.
Furthermore, the performance gain on the NWPU VHR-10 dataset is greater than the SSDD dataset. Just as for the analysis of HRFPN and ISNetV2 in
Section 4.4.2 and
Section 4.4.3, the performance of NWPU VHR-10 is better due to the influence of target type, target size distribution, etc. In conclusion, our HRFPN can maintain a high resolution and solve the problem of spatial resolution loss in FPN, and our ISNetV2 improves the mask information flow. The final feature maps are semantically richer and spatially more accurate. The final predicted instance mask is also more accurate. Consequently, it can be extrapolated that the HRFPN and ISNetV2 modules can effectively improve instance segmentation performance in remote sensing images.
It can be observed from
Table 7 and
Table 8 that the entire performance of HQ-ISNet performs the best with a lighter computation cost and fewer parameters. Besides, our models have a better performance than Mask R-CNN and Mask Scoring R-CNN with a similar model size and computational complexity. Compared with Cascade Mask R-CNN, our models have a better performance with less computational cost and smaller model size. Additionally, the HQ-ISNet has a similar performance compared to the Hybrid Task Cascade under the same model size, but with less runtime. Therefore, our network is more efficient and practical than other advanced approaches in terms of model size and computation complexity.
In [
20], HTC introduced semantic segmentation into the instance segmentation framework to obtain a better spatial context. Because semantic segmentation requires fine pixel-level classification of the whole image, it is characterized by strong spatial position information and strong discrimination ability for the foreground and background. By reusing the semantic information of this branch into the box and mask branches, the performance of these two branches can be greatly improved. However, to achieve this function, HTC needs a separate semantic segmentation label to supervise the training of semantic segmentation branches, which is difficult to implement without annotations. Therefore, under the same model size, we achieve a similar performance compared to HTC, but our method runs for a shorter time and is easier to implement.
In summary, compared with other advanced approaches, our network acquires more accurate instance masks and improves the instance segmentation performance in HR remote sensing imagery. There are two main reasons for this. One is that HRFPN fully utilizes multi-level feature maps and can maintain HR feature maps. The other is that ISNetV2 refines the mask information flow between the mask branches.
5. Discussion
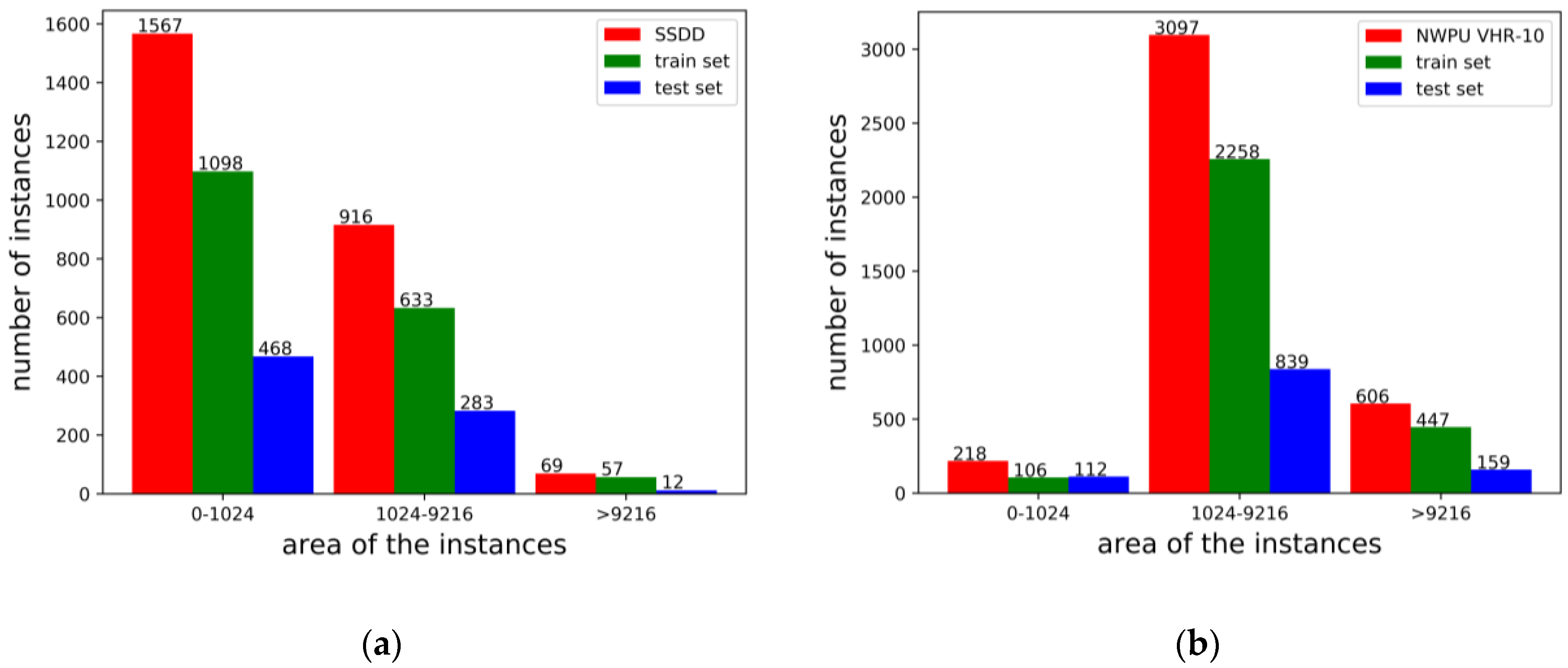
We found that the AP
L metrics in the SSDD dataset fluctuated greatly, so we calculated the number of target instances in SSDD according to the definition of large (area > 96
2), medium (32
2 < area < 96
2) and small (area < 32
2) targets in
Section 4.2. As can be observed in
Figure 15, ship instances are mainly concentrated in small and medium target areas and AP
L fluctuates greatly due to too few large ships in SSDD. According to the AP calculation formula [
10], a small amount of missed detections and false alarms will cause huge changes in the AP
L value. Because our instance segmentation method relies on detection performance, in NWPU VHR-10, the target instances are mainly concentrated in large and medium target areas, but the number of small targets is significantly larger than the number of large targets in SSDD.
In addition, we calculate the variance to discuss the uncertainty estimate of the quality metric. We train and test our model five times to calculate the variance. As can be observed from
Table 9, AP
L has the largest variance fluctuation in SSDD. It is known from
Figure 15 that it is caused by too few large targets. In short, the variance of other indicators is relatively stable. Thus, our results are effective.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}