A Two-stage Deep Domain Adaptation Method for Hyperspectral Image Classification



Abstract
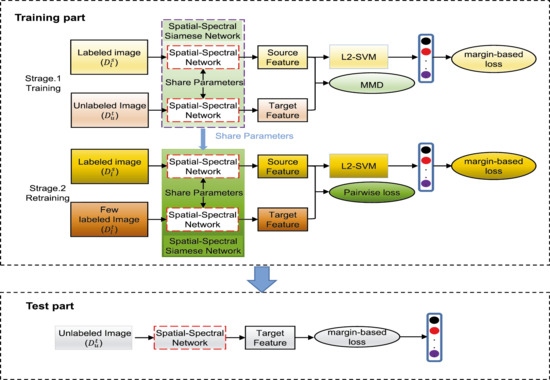
1. Introduction
2. Proposed Method
2.1. A Two-Stage Deep Domain Adaptation Framework
2.2. The Spatial–Spectral Network
2.3. The First Stage of TDDA
2.4. The Second Stage of TDDA
3. Experiments
3.1. Data Sets Description
3.2. Experimental Settings
3.3. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liang, L.; Di, L.; Zhang, L.; Deng, M.; Qin, Z.; Zhao, S.; Lin, H. Estimation of crop LAI using hyperspectral vegetation indices and a hybrid inversion method. Remote Sens. Environ. 2015, 165, 123–134. [Google Scholar] [CrossRef]
- Laurin, G.V.; Chan, J.C.W.; Chen, Q.; Lindsell, J.A.; Coomes, D.A.; Guerriero, L.; Del Frate, F.; Miglietta, F.; Valentini, R. Biodiversity mapping in a tropical West African forest with airborne hyperspectral data. PLoS ONE 2014, 9, e97910. [Google Scholar]
- Yokoya, N.; Chan, J.C.W.; Segl, K. Potential of Resolution-Enhanced Hyperspectral Data for Mineral Mapping Using Simulated EnMAP and Sentinel-2 Images. Remote Sens. 2016, 8, 172. [Google Scholar] [CrossRef]
- Lu, X.; Li, X.; Mou, L. Semi-Supervised Multitask Learning for Scene Recognition. IEEE Trans. Cybern. 2015, 45, 1967–1976. [Google Scholar] [PubMed]
- Yuen, P.W.T.; Richardson, M. An introduction to hyperspectral imaging and its application for security, surveillance and target acquisition. Imaging Sci. J. 2010, 58, 241–253. [Google Scholar] [CrossRef]
- Li, W.; Wu, G.; Zhang, F.; Du, Q. Hyperspectral image classification using deep pixel-pair features. IEEE Trans. Geosci. Remote Sens. 2017, 55, 844–853. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Li, Z.; Huang, L.; He, J. A Multiscale Deep Middle-level Feature Fusion Network for Hyperspectral Classification. Remote Sens. 2019, 11, 695. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral-Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Learning multiscale and deep representations for classifying remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2016, 113, 155–165. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Marsheva, T.V.B.; Zhou, D. Semi-supervised graph-based hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3044–3054. [Google Scholar] [CrossRef]
- Zhou, X.; Prasad, S. Active and semisupervised learning with morphological component analysis for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1348–1352. [Google Scholar] [CrossRef]
- Ye, M.C.; Qian, Y.T.; Zhou, J.; Tang, Y.Y. Dictionary learning-based feature-level domain adaptation for cross-scene hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1544–1562. [Google Scholar] [CrossRef]
- Jiao, L.; Liang, M.; Chen, H.; Yang, S.; Liu, H.; Cao, X. Deep Fully Convolutional Network-Based Spatial Distribution Prediction for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5585–5599. [Google Scholar] [CrossRef]
- Mei, S.; Ji, J.; Hou, J.; Li, X.; Du, Q. Learning Sensor-Specific Spatial-Spectral Features of Hyperspectral Images via Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4520–4533. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.Q.; Chan, J.C.W. Learning and Transferring Deep Joint Spectral–Spatial Features for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4729–4742. [Google Scholar] [CrossRef]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain adaptation for the classification of remote sensing data: An overview of recent advances. IEEE Geosci. Remote Sens. Mag. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep Transfer Learning with Joint Adaptation Networks. In Proceedings of the 2017 International Conference on Machine Learning (ICML), Sydney, NSW, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Yan, H.; Ding, Y.; Li, P.; Wang, Q.; Xu, Y.; Zuo, W. Mind the Class Weight Bias: Weighted Maximum Mean Discrepancy for Unsupervised Domain Adaptation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 945–954. [Google Scholar]
- Sun, Z.; Wang, C.; Wang, H.; Li, J. Learn multiple-kernel SVMs for domain adaptation in hyperspectral data. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1224–1228. [Google Scholar]
- Deng, C.; Liu, X.; Li, C.; Tao, D. Active multi-kernel domain adaptation for hyperspectral image classification. Pattern Recognit. 2018, 77, 306–315. [Google Scholar] [CrossRef]
- Yang, H.; Crawford, M. Domain adaptation with preservation of manifold geometry for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 9, 543–555. [Google Scholar] [CrossRef]
- Othman, E.; Bazi, Y.; Melgani, F.; Alhichri, H.; Alajlan, N.; Zuair, M. Domain adaptation network for cross-scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4441–4456. [Google Scholar] [CrossRef]
- Wang, Z.; Du, B.; Shi, Q.; Tu, W. Domain Adaptation with Discriminative Distribution and Manifold Embedding for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1155–1159. [Google Scholar] [CrossRef]
- Motiian, S.; Piccirilli, M.; Adjeroh, D.A.; Doretto, G. Unified Deep Supervised Domain Adaptation and Generalization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 5716–5726. [Google Scholar]
- Yichuan, T. Deep learning using linear support vector machines. arXiv 2015, arXiv:1306.0239, 2015. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a Similarity Metric Discriminatively, with Application to Face Verification. In Proceedings of the 2005 IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 539–546. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 2015 International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Liao, W.; Mura, M.D.; Chanussot, J.; Pižurica, A. Fusion of spectral and spatial information for classification of hyperspectral remote-sensed imagery by local graph. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 2016, 9, 583–594. [Google Scholar] [CrossRef]
- Li, Z.; Huang, L.; Zhang, D.; Liu, C.; Wang, Y.; Shi, X. A deep network based on multiscale spectral-spatial fusion for Hyperspectral Classification. In Proceedings of the 2018 International Conference on Knowledge Science, Engineering and Management (KSEM), Jilin, China, 17–19 August 2018; pp. 283–290. [Google Scholar]
- Guo, X.; Huang, X.; Zhang, L.; Zhang, L.; Plaza, A.; Benediktsson, J.A. Support tensor machines for classification of hyperspectral remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3248–3264. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.D.; Doulamis, N.D. Deep Supervised Learning for Hyperspectral Data Classification Through Convolutional Neural Networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Kingma, D.P.; Ba, J.A. A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meanings |
|---|---|
| labeled samples in source domain | |
| labeled samples in source domain | |
| unlabeled samples in target domain | |
| be pixels in , and with chn-bands | |
| , be the corresponding labels with | |
| is the number of classes |
| Class | Number of Samples | ||
|---|---|---|---|
| No. | Name | Pavia University | Pavia Center |
| 1 | Trees | 3064 | 7598 |
| 2 | Asphalt | 6631 | 3090 |
| 3 | Bricks | 3682 | 2685 |
| 4 | Bitumen | 1330 | 6584 |
| 5 | Shadows | 947 | 7287 |
| 6 | Meadows | 18,649 | 42,816 |
| 7 | Bare Soil | 5029 | 2863 |
| Total | 39,332 | 72,923 | |
| Class | Number of Samples | ||
|---|---|---|---|
| No. | Name | Shanghai | Hangzhou |
| 1 | Water | 123,123 | 18,043 |
| 2 | Ground/Building | 161,689 | 77,450 |
| 3 | Plants | 83,188 | 40,207 |
| Total | 368,000 | 135,700 | |
| Spectral Branch | Spatial Branch | |
|---|---|---|
| Number of conv. layers | 2 | 2 |
| Number of filters | 16,32 | 32,128 |
| Filters size of conv. layer | 1 × 1 × 16 | 3 × 3 |
| Number of pooling layers | 1 | 1 |
| Filters size of pooling layer | 1 × 1 × 5 | 3 × 3 |
| Dropout | 0.25 | |
| Fully Connected layer1 | 1000 | |
| Fully Connected layer2 | 100 | |
| Output | L | |
| α | Overall Accuracy (OA) | Average Accuracy (AA) |
|---|---|---|
| 0.25 | 94.19 ± 0.64 | 93.96 ± 0.27 |
| 0. 5 | 90.53 ± 0.67 | 92.35 ± 0.26 |
| 0.75 | 92.64 ± 0.70 | 93.03 ± 0.29 |
| Class | Mei et al. | Yang et al. | Wang et al. +FT | First-Stage + FT | TDDA |
|---|---|---|---|---|---|
| Trees | 71.49 | 80.41 | 88.20 | 84.46 | 92.81 |
| Asphalt | 95.23 | 70.26 | 94.34 | 84.21 | 93.56 |
| Bricks | 89.22 | 55.25 | 69.99 | 91.56 | 98.56 |
| Bitumen | 68.30 | 78.81 | 80.52 | 73.51 | 88.27 |
| Shadows | 88.88 | 77.88 | 88.28 | 89.49 | 89.18 |
| Meadows | 97.36 | 73.90 | 97.99 | 98.08 | 95.59 |
| Bare soil | 99.97 | 73.90 | 99.58 | 99.70 | 99.90 |
| OA | 90.91 ±0.97 | 75.51 ±1.56 | 93.10 ±0.61 | 92.83 ±0.79 | 94.19 ±0.64 |
| AA | 87.20 ±0.90 | 76.28 ±1.00 | 88.42 ±0. 86 | 88.11 ±0.78 | 93.96 ±0.27 |
| Kappa | 85.59 ±1.47 | 64.63 ±1.82 | 89.21 ±1.16 | 88.19 ±0.97 | 90.89 ±0.95 |
| Class | Mei et al. | Yang et al. | Wang et al. +FT | First-Stage + FT | TDDA |
|---|---|---|---|---|---|
| Trees | 94.40 | 94.72 | 97.47 | 94.45 | 98.33 |
| Asphalt | 74.06 | 87.77 | 63.58 | 57.93 | 84.49 |
| Bricks | 88.74 | 73.39 | 96.92 | 81.65 | 95.07 |
| Bitumen | 77.24 | 23.05 | 96.75 | 95.14 | 94.87 |
| Shadows | 99.68 | 99.47 | 99.42 | 98.63 | 99.98 |
| Meadows | 63.33 | 59.91 | 81.33 | 73.51 | 86.74 |
| Bare soil | 50.16 | 22.65 | 39.10 | 73.53 | 27.27 |
| OA | 69.54 ±1.50 | 63.59 ±1.37 | 76.61 ±1.39 | 75.22 ±1.41 | 81.03 ±0.77 |
| AA | 78.24 ±1.98 | 65.85 ±0.86 | 82.08 ±0.89 | 82.13 ±1.16 | 83.82 ±0.78 |
| Kappa | 60.12 ±1.83 | 52.60 ±1.42 | 67.74 ±1.82 | 67.17 ±1.71 | 73.26 ±1.05 |
| Class | Mei et al. | Yang et al. | Wang et al. +FT | First-Stage + FT | TDDA |
|---|---|---|---|---|---|
| Water | 89.80 | 99.40 | 93.56 | 92.56 | 99.59 |
| Ground/Building | 92.68 | 87.10 | 83.80 | 83.87 | 95.13 |
| Plant | 95.86 | 54.92 | 96.33 | 85.07 | 95.04 |
| OA | 93.24 ±0.91 | 79.20 ±1.26 | 88.81 ±1.55 | 85.66 ±1.04 | 95.65 ±0.24 |
| AA | 92.78 ±0.59 | 80.48 ±0.92 | 91.23 ±0.60 | 87.86 ±1.36 | 96.52 ±0.27 |
| Kappa | 88.17 ±1.52 | 62.98 ±2.04 | 81.02 ±2.38 | 75.34 ±1.17 | 92.42 ±0.41 |
| Class | Mei et al. | Yang et al. | Wang et al. +FT | First-Stage + FT | TDDA |
|---|---|---|---|---|---|
| Water | 98.08 | 92.99 | 98.76 | 95.30 | 95.27 |
| Ground/Building | 98.65 | 87.17 | 84.43 | 88.29 | 93.76 |
| Plant | 80.90 | 99.98 | 99.56 | 94.36 | 99.78 |
| OA | 94.45 ±0.42 | 92.02 ±0.35 | 92.64 ±0.89 | 92.23 ±1.17 | 95.62 ±0.25 |
| AA | 92.54 ±0.32 | 93.38 ±0.27 | 94.25 ±0.63 | 93.00 ±0.48 | 96.27 ±0.20 |
| Kappa | 91.46 ±0.56 | 87.79 ±0.52 | 88.79 ±1.32 | 88.09 ±1.69 | 93.25 ±0.38 |
| Mei et al. | Yang et al. | Wang et al. + FT | First-Stage + FT | TDDA | ||
|---|---|---|---|---|---|---|
| Pavia university → Pavia center | Train (s) | 83.82 | 91.42 | 108.10 | 76.08 | 883.69 |
| Test (s) | 1.47 | 3.61 | 13.91 | 11.76 | 15.04 | |
| Pavia center → Pavia university | Train (s) | 74.30 | 75.98 | 102.97 | 71.39 | 889.25 |
| Test (s) | 0.85 | 1.80 | 6.02 | 5.54 | 7.32 | |
| Shanghai → Hangzhou | Train (s) | 37.26 | 39.00 | 78.92 | 48.05 | 526.90 |
| Test (s) | 2.55 | 5.98 | 33.06 | 21.36 | 42.97 | |
| Hangzhou → Shanghai | Train (s) | 38.64 | 43.88 | 106.65 | 54.65 | 516.87 |
| Test (s) | 3.69 | 15.77 | 69.66 | 44.52 | 127.64 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Tang, X.; Li, W.; Wang, C.; Liu, C.; He, J. A Two-stage Deep Domain Adaptation Method for Hyperspectral Image Classification. Remote Sens. 2020, 12, 1054. https://doi.org/10.3390/rs12071054
Li Z, Tang X, Li W, Wang C, Liu C, He J. A Two-stage Deep Domain Adaptation Method for Hyperspectral Image Classification. Remote Sensing. 2020; 12(7):1054. https://doi.org/10.3390/rs12071054
Chicago/Turabian StyleLi, Zhaokui, Xiangyi Tang, Wei Li, Chuanyun Wang, Cuiwei Liu, and Jinrong He. 2020. "A Two-stage Deep Domain Adaptation Method for Hyperspectral Image Classification" Remote Sensing 12, no. 7: 1054. https://doi.org/10.3390/rs12071054
APA StyleLi, Z., Tang, X., Li, W., Wang, C., Liu, C., & He, J. (2020). A Two-stage Deep Domain Adaptation Method for Hyperspectral Image Classification. Remote Sensing, 12(7), 1054. https://doi.org/10.3390/rs12071054