1. Introduction
Land cover mapping, as a basic process to categorize and describe the surface on Earth, provides fundamental data for various management and research applications, such as food production forecast, urban planning, flood control, disaster prevention, biodiversity protection, climate change research, and other Earth system studies [
1]. With the demand of detailed land resource surveys and spatial planning for optimizing the development and protection of national land space, high-resolution land cover data is significant and widely used in many sustainability-related applications [
2]. Its uses include modeling un-authorized land use sprawl, monitoring urban changes and surveying the coastline [
3]. The potential of 1–3 m resolution land cover data opens the door to many new applications that require high geometric precision and roof-top/small-farm level spatial details. Therefore, timely and higher resolution land cover products are urgently needed [
4].
In the past few decades, thanks to the advancement in satellite remote sensing and data processing technologies, more and more higher resolution land cover products have been produced at the global and continental scales [
2,
4]. At the global scale, 1-km spatial resolution land cover products have been developed using Advanced Very High Resolution Radiometer (AVHRR) data [
5,
6]. Annual 500-m resolution global land cover products were developed for several generations [
7,
8]. In 2008, ESA delivered the first 300-m resolution global land cover maps for 2005 [
9]. Then in 2011, ESA and the Université catholique de Louvain (UCL) delivered a set of GlobCover 2009 products [
10]. The CCI-LC team produced and released its 3-epoch series of global land cover maps at a 300-m spatial resolution, where each epoch covers a 5-year period (2008–2012, 2003–2007, 1998–2002) [
11]. In 2013, the first 30-m resolution global land cover maps were produced using Landsat Thematic Mapper (TM) and Enhanced Thematic Mapper Plus (ETM+) data [
1]. In 2019, the latest global land cover product, Finer Resolution Observation and Monitoring of Global Land Cover (FROM-GLC10), developed with 10-m resolution Sentinel-2 data for 2017, was published [
4]. Over the recent decades, these public land cover datasets have already made significant contributions to the global research community. Taking the FROM-GLC series of datasets as an example, the 30-m and 10-m results have already been accessed by over 50,000 users from 183 different countries, with over 30 million file clicks and downloads (
http://data.ess.tsinghua.edu.cn/).
In recent years, with the increased availability of high-resolution remotely sensed data, the maturing of machine learning techniques (especially deep learning based methods), and the readiness of computing capabilities, land cover mapping efforts have been further extended to a resolution of three meters or even one meter [
12,
13]. However, under the current paradigm of deep neural networks, one major constraint that stops many researchers from achieving improved results is the lack of well-labelled training data [
14].
If we look at the recent boom in deep learning technologies in the domain of computer vision, a critical base is the availability of many well-labeled datasets like ImageNet [
15]. However, remote sensing images are more diverse and more difficult to interpret than daily images. Because the interpretation and labelling of remotely sensed images requires huge human efforts and a high level of expertise, it is costly and time-consuming to obtain high-resolution land cover maps on a large scale. Although many efforts have been devoted to developing land cover datasets on a large scale [
1,
16], they suffer from a number of limitations, such as point-based or patch-based annotation, diversity or simplification of the samples and the scenes, variation in the spatial resolution, and hardly accessible or unpublished datasets. For example, it took 10 months and
$1.3 million to label about 160,000 square kilometers in the Chesapeake Bay watershed in the northeastern United States that included only four cover types (Water, Forest, Field, and Impervious) [
17]. Even with those high-cost and numerous interpretation datasets, the limited number of land cover types and the specific coverage make it difficult to use for other land cover studies [
2]. Gong et al. [
4] transformed a 30-m resolution sample set, which is a point-based annotation at the global scale, to mapping, at a 10-m resolution, global land cover with more spatial detail yet found no accuracy improvement. The reason is that the spatial resolution and point-based annotation of the 30-m land cover dataset presents a strong limitation to higher resolution land cover mapping.
To deal with the above-mentioned issues, many recent studies have focused on training data collection from readily available land cover products. For instances, Zhang et al. used the random forest classification method to transfer a 500-m resolution MODIS (the Moderate Resolution Imaging Spectroradiometer) land cover product to produce 30-m land cover classification results in North America [
18]. Lee et al. applied an improved Bayesian Updating of Land Cover algorithm to sharpen the results from a 300-m to a 30-m classification [
19]. Zhang et al. combined the MODIS and GlobCover2009 land cover product to produce a 30-m resolution land cover map of China [
20]. Although they have demonstrated that refined 30-m resolution land cover maps can be produced from lower resolution land cover products, the feasibility of transferring the knowledge to a very high resolution (e.g., 3-m) has never been assessed. Schmitt et al. integrated 10-m resolution images (Sentinel-1 and Sentinel-2) with low-resolution MODIS land cover (with 250-m to 1000-m resolution) to produce the higher resolution SEN12MS dataset [
21]. This problem was defined as weakly supervised learning for land cover prediction due to the huge difference in resolution between the MODIS land cover products and satellite data [
22]. However, in this work, we explore the possibility of transferring a 10-m product to produce 3-m results, in which satellite images and land cover products are both in higher resolutions and have relatively small resolution gaps. The situation and corresponding methodology are quite different from the above studies, because of the characteristics of different resolution satellite imagery and the accuracy of different land cover products.
Open Street Map (OSM) or other open data sources were also used in updating and improving land cover and land use products [
23,
24]. Kaiser et al. indicated that the use of large-scale imperfect labeled training data could replace 85% of high-quality manually labeled data in high-resolution building and road extraction [
23]. An impressive performance in the imperfect label situation has been achieved, which only drops by 6% in accuracy when the proportion of imperfect labels increases up to 50% [
25]. These studies show that in specific scenarios or cases, even though training on imperfect data, it may still achieve reasonable results [
26]. Based on the existing efforts mentioned above, we propose a deep learning based approach that can intelligently and efficiently “grow” the current 10-m resolution FROM-GLC land cover product to an improved 3-m resolution land cover product.
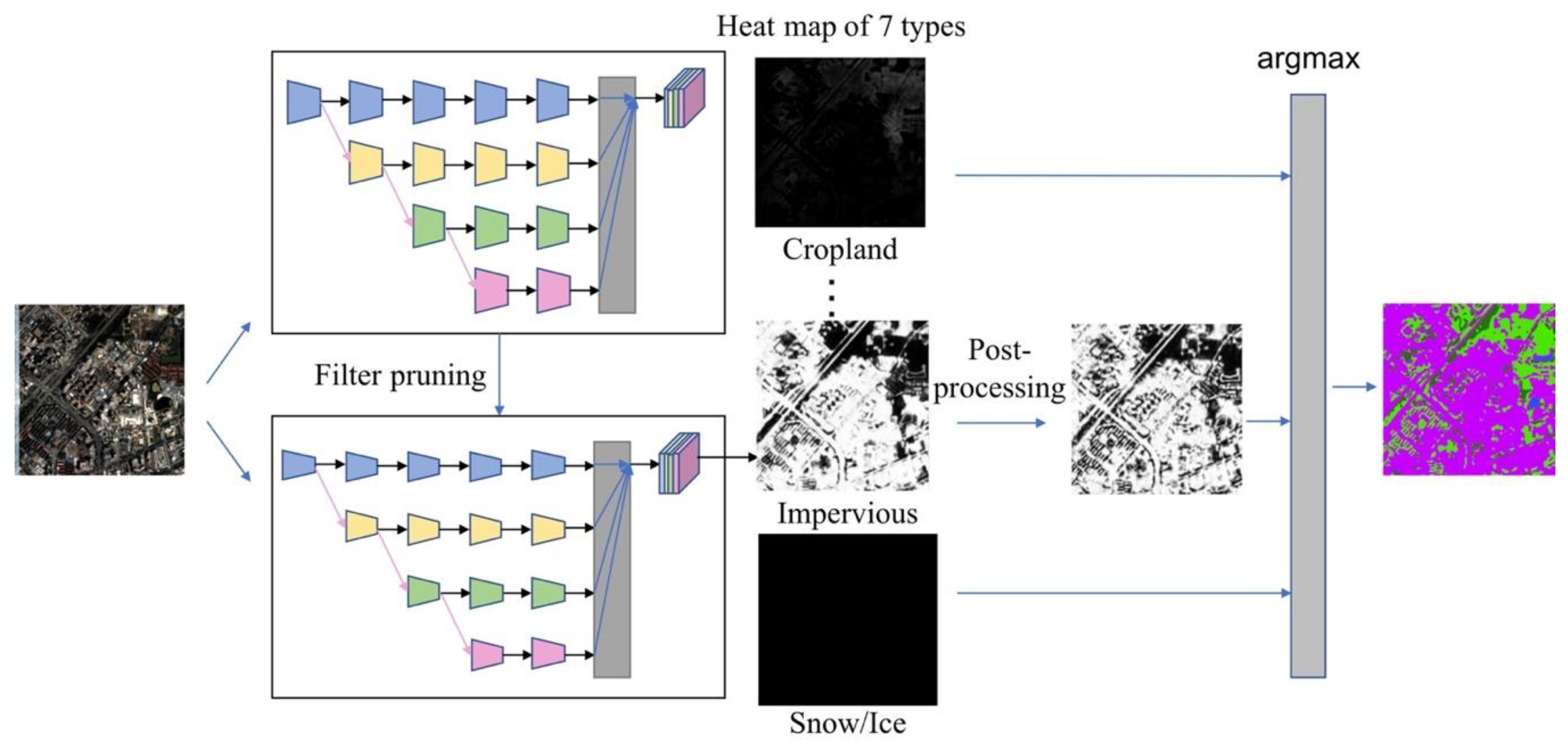
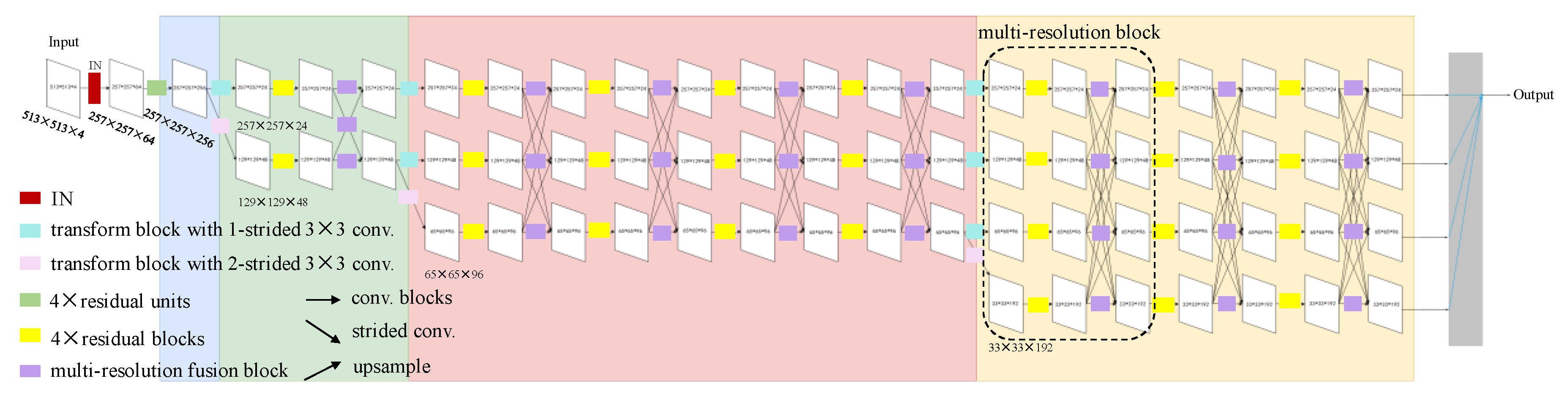
The first part of this research focuses on designing a robust and generalized learning method that can take advantage of the imperfect 10-m resolution product as the training input, and transfer the knowledge into a network that can produce refined 3-m resolution land cover maps. In recent years, deep learning-based approaches for high-resolution land cover mapping have been considered as the state-of-the-art methods [
2,
12]. High-resolution satellite imagery contains more spatial information (e.g., texture, contexture, and shape). A deep learning-based semantic segmentation method can effectively extract the necessary spatial information from the neighborhoods surrounding each pixel. It enables effective end-to-end segmentation, obtaining superior results to traditional machine learning methods and the patch-based Convolutional Neural Network (CNN) classification method [
27]. For example, on the ISPRS Vaihingen benchmark (including six types, i.e., impervious surface, building, low vegetation, tree, car, and background), Audebert et al. [
28] achieved an overall accuracy of 89.8%, which is over 3.9% higher than that with traditional machine learning methods, such as Random Forest (RF) with a fully connected conditional random field (CRF). Liu et al. [
29] proposed a self-cascaded network based on PSPNet [
30] and RefineNet [
31], which further improved the overall accuracy to 91.1% for the ISPRS Vaihingen challenge online test dataset in 2017. The latest national-scale 1-m resolution land cover maps (using aerial imagery from the USDA National Agriculture Imagery Program) of the US in 2019 applied the U-Net Large model and achieved substantially improved results (with an overall accuracy increased by 2%–41% in different test regions) compared with a traditional machine learning method (i.e., RF) [
2]. As a result, we apply a deep learning-based semantic segmentation method for this research.
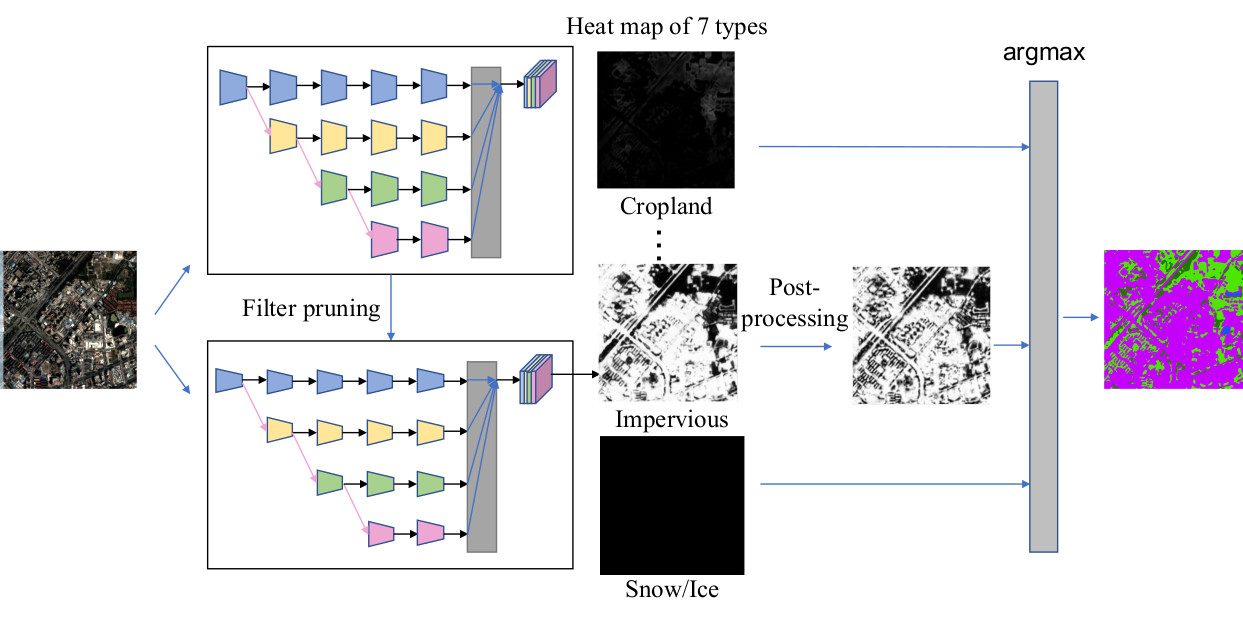
The second part of this research focuses on improving the computational efficiency of the proposed method. Recent studies on model compression and acceleration include Quantization [
32], Fast convolution [
33], Low rank approximation [
34], and Filter pruning [
35]. In this study, we apply filter pruning due to its usability and expansibility. Aiming at producing a continental or even global land cover product, we carefully prune the resulting segmentation model so that we can process an area as big as China within a few days rather than a few months. The basic idea of our pruning method is to remove the redundant or insignificant filters in the network that make little or no contribution to the final output [
29,
36]. For example, He et al. proposed the Soft Filter Pruning (SFP) method, which reduced FLOPs by more than 40.8% on ResNet-110 and even produced a 0.18% accuracy improvement on CIFAR-10 [
37]. Filter Pruning via Geometric Median (FPGM) [
3] was proposed in 2019, and further reduced FLOPS by more than 52% on ResNet-110 and even produced a 2.69% relative accuracy improvement on the same dataset. In our work, we explored the pruning of a rather complex architecture (i.e., high-resolution network [
38]) compared with ResNet, implemented on a more complicated dataset compared to CIFAR-10. We apply FPGM for network compression and acceleration with almost no loss of accuracy. This makes it possible to map large areas.
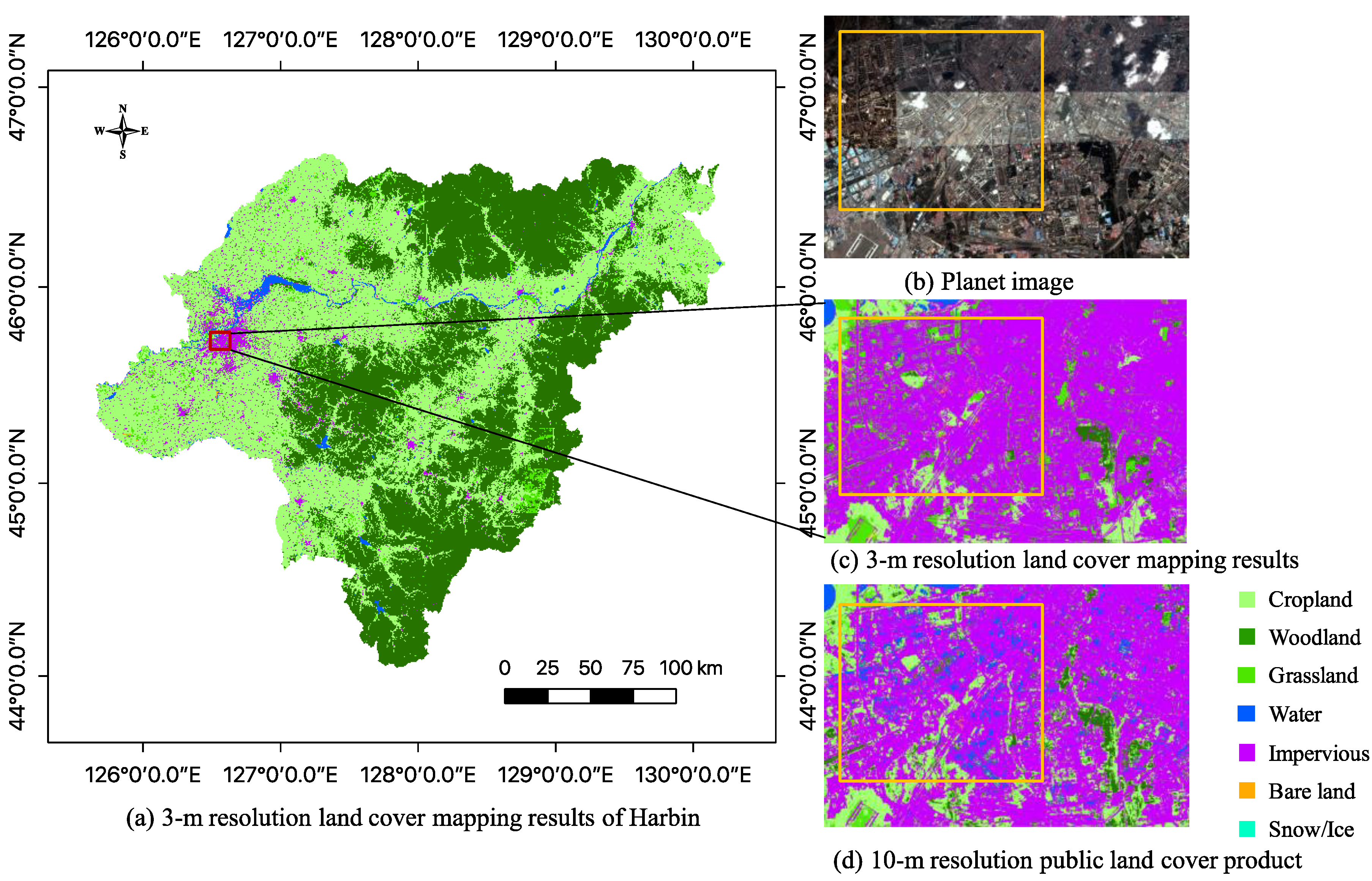
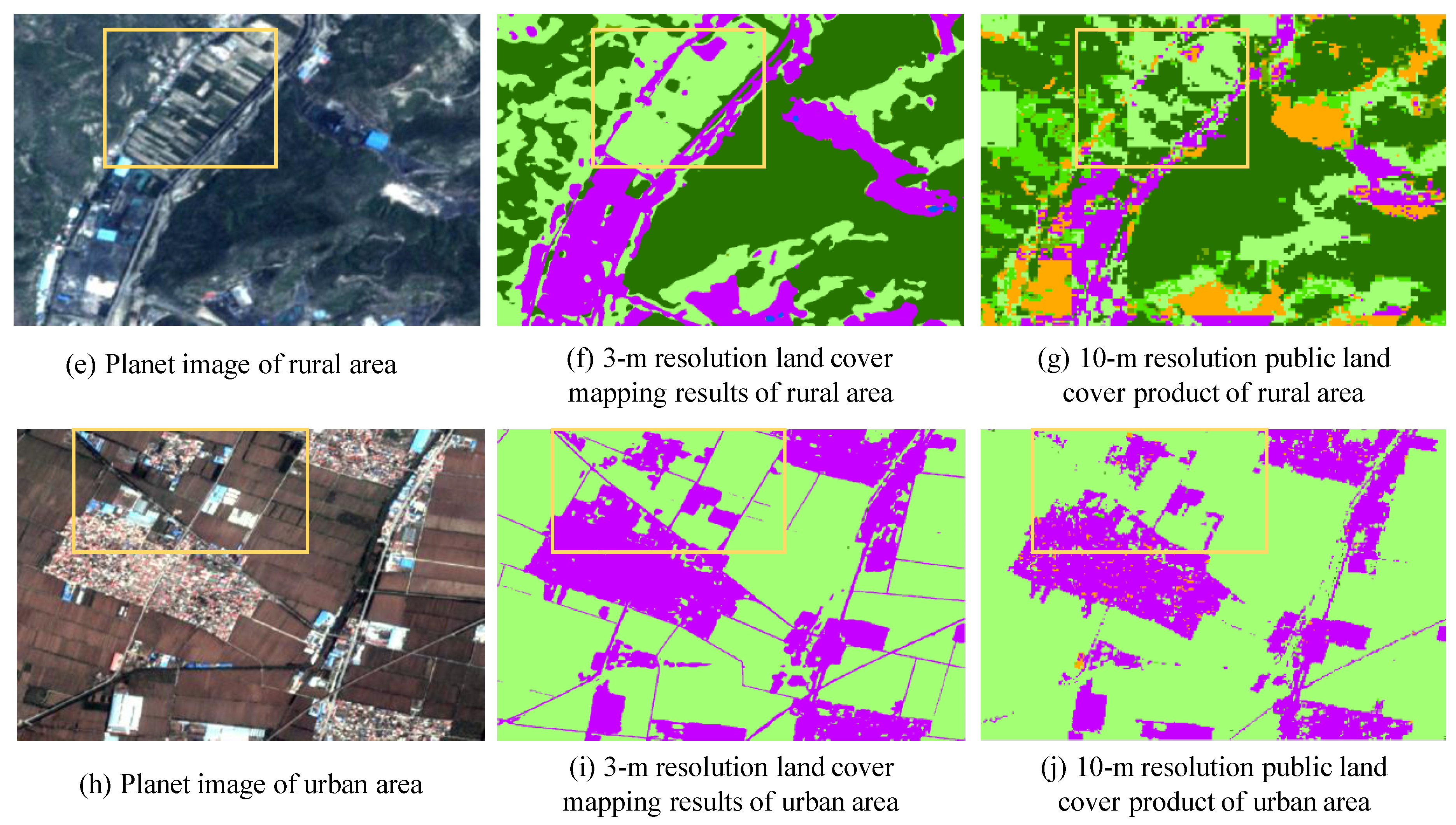
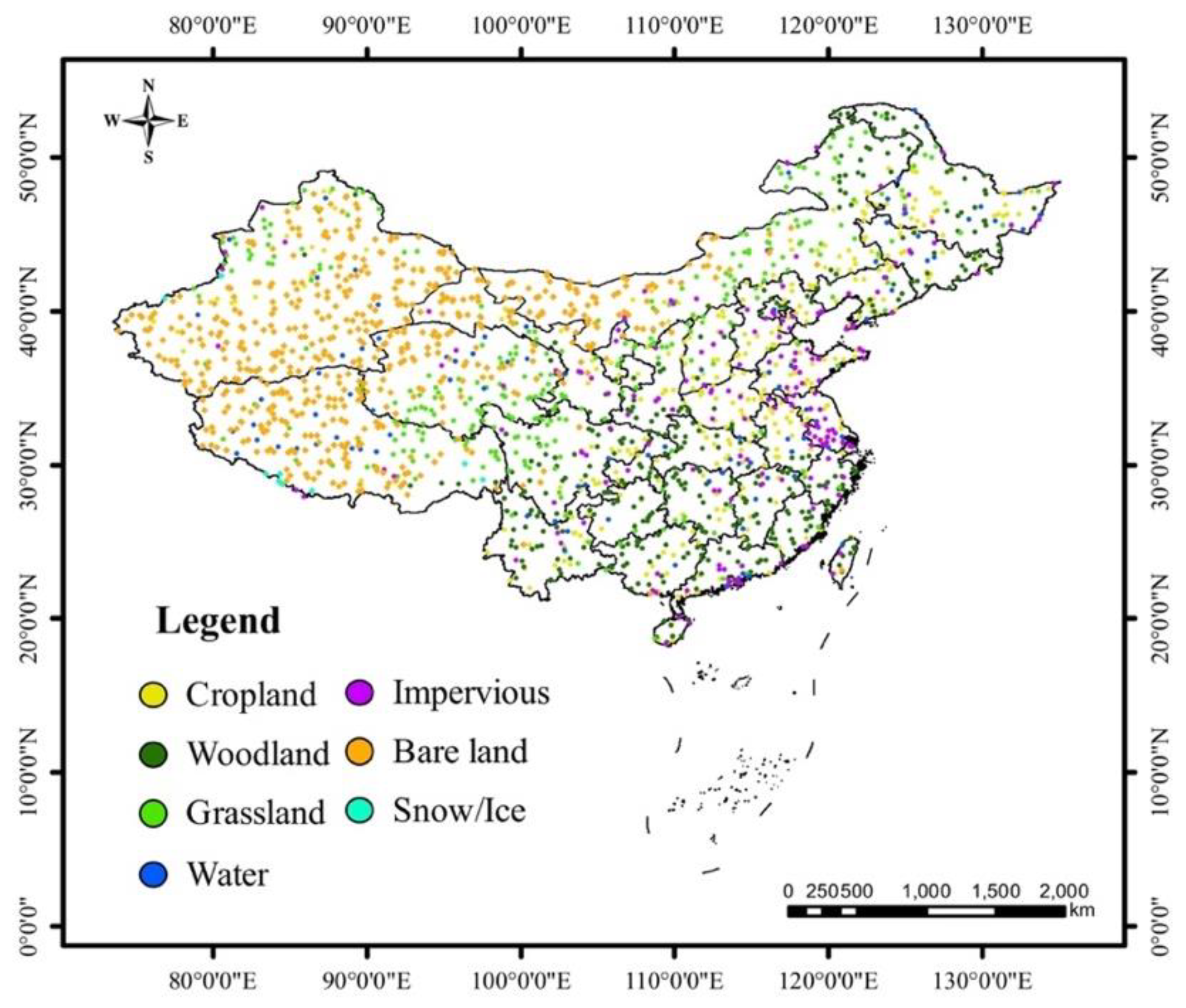
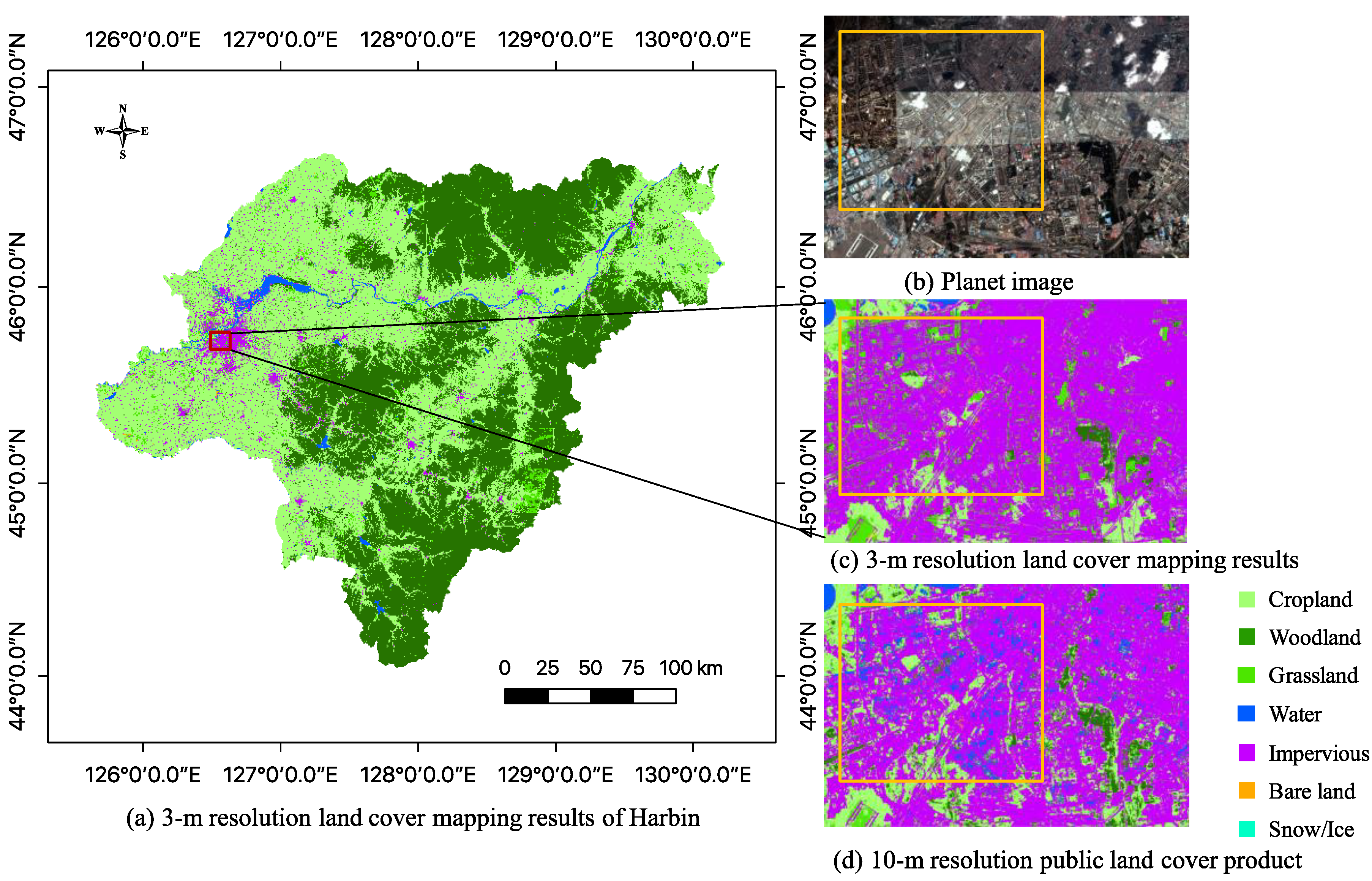
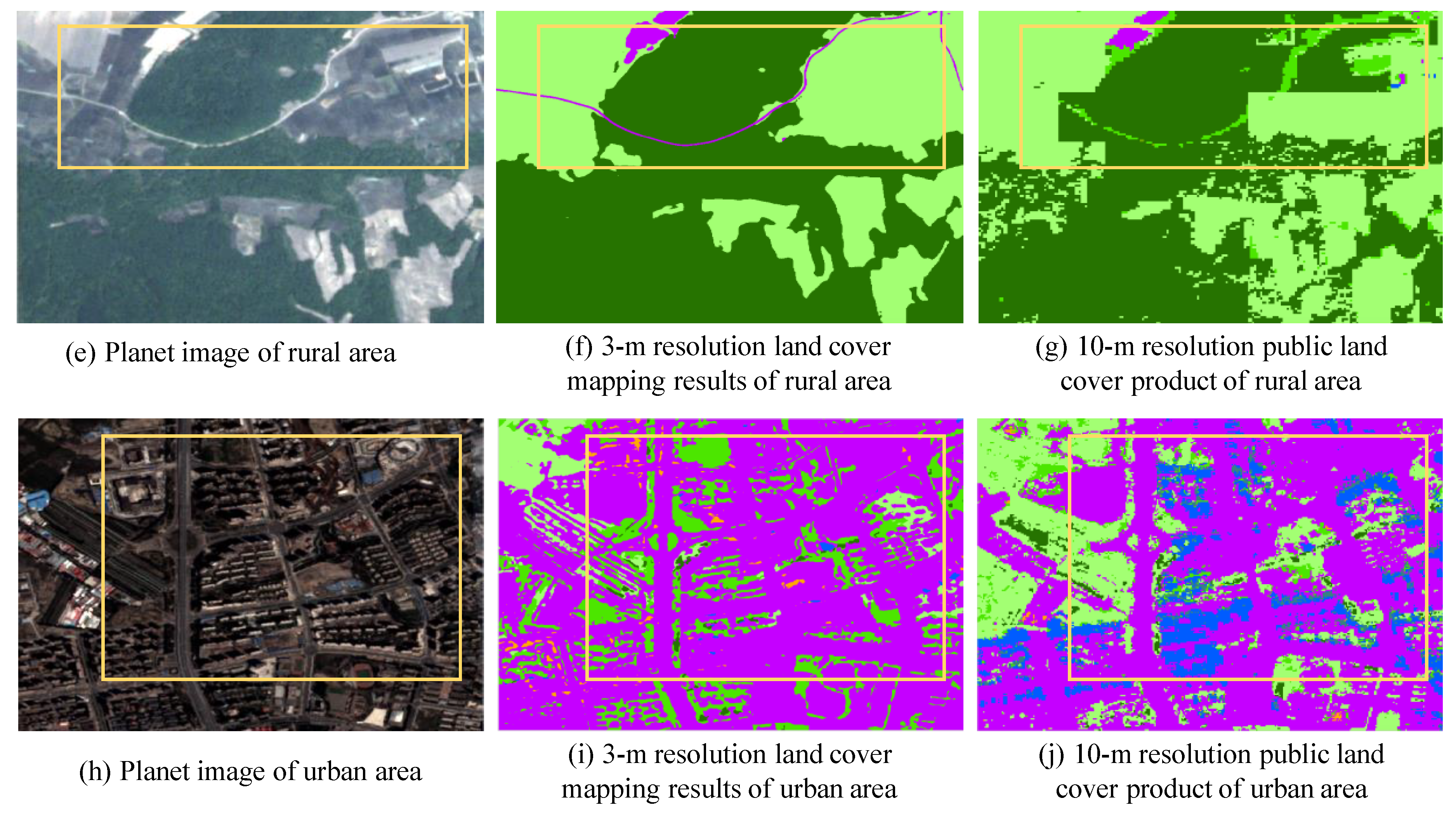
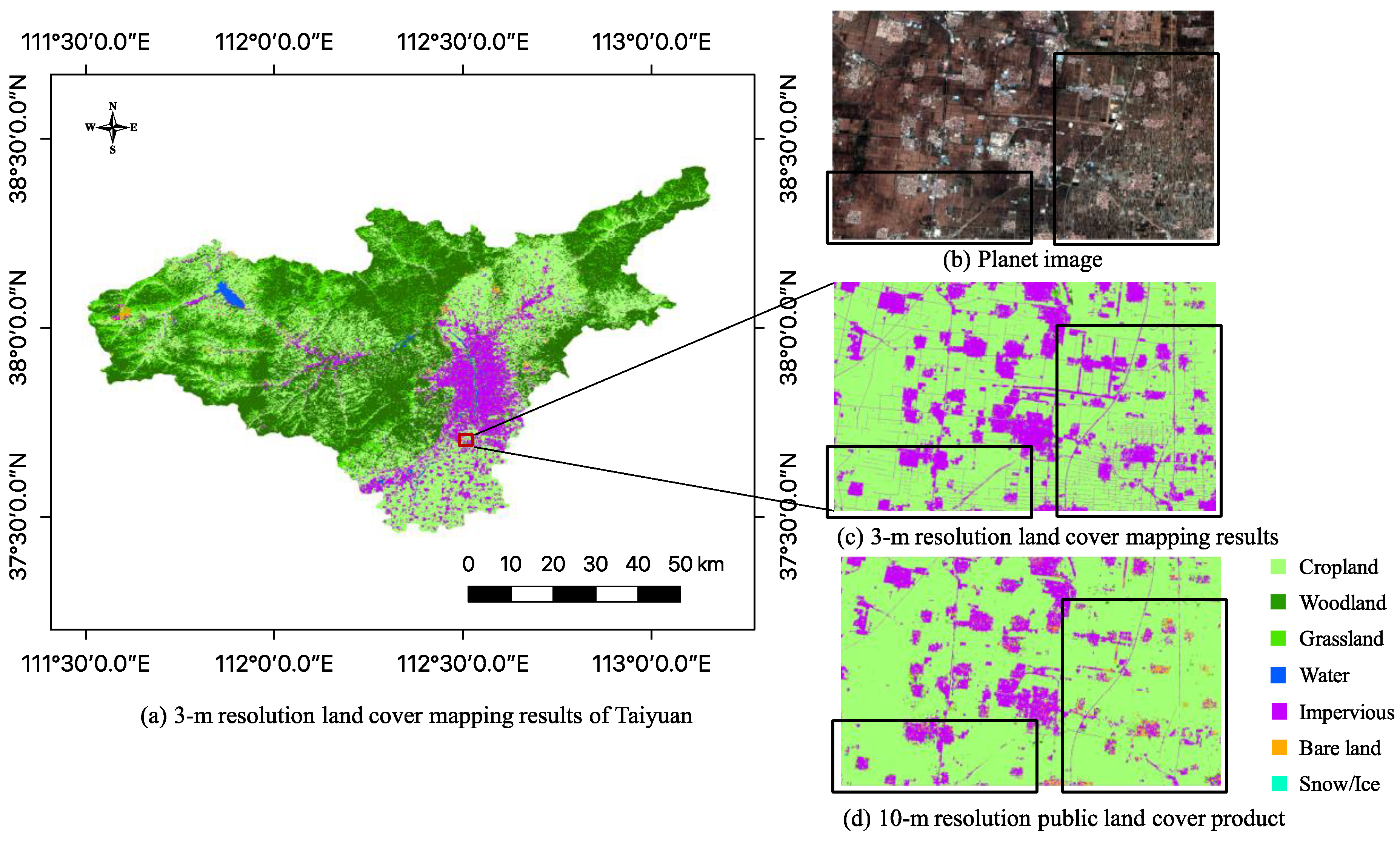
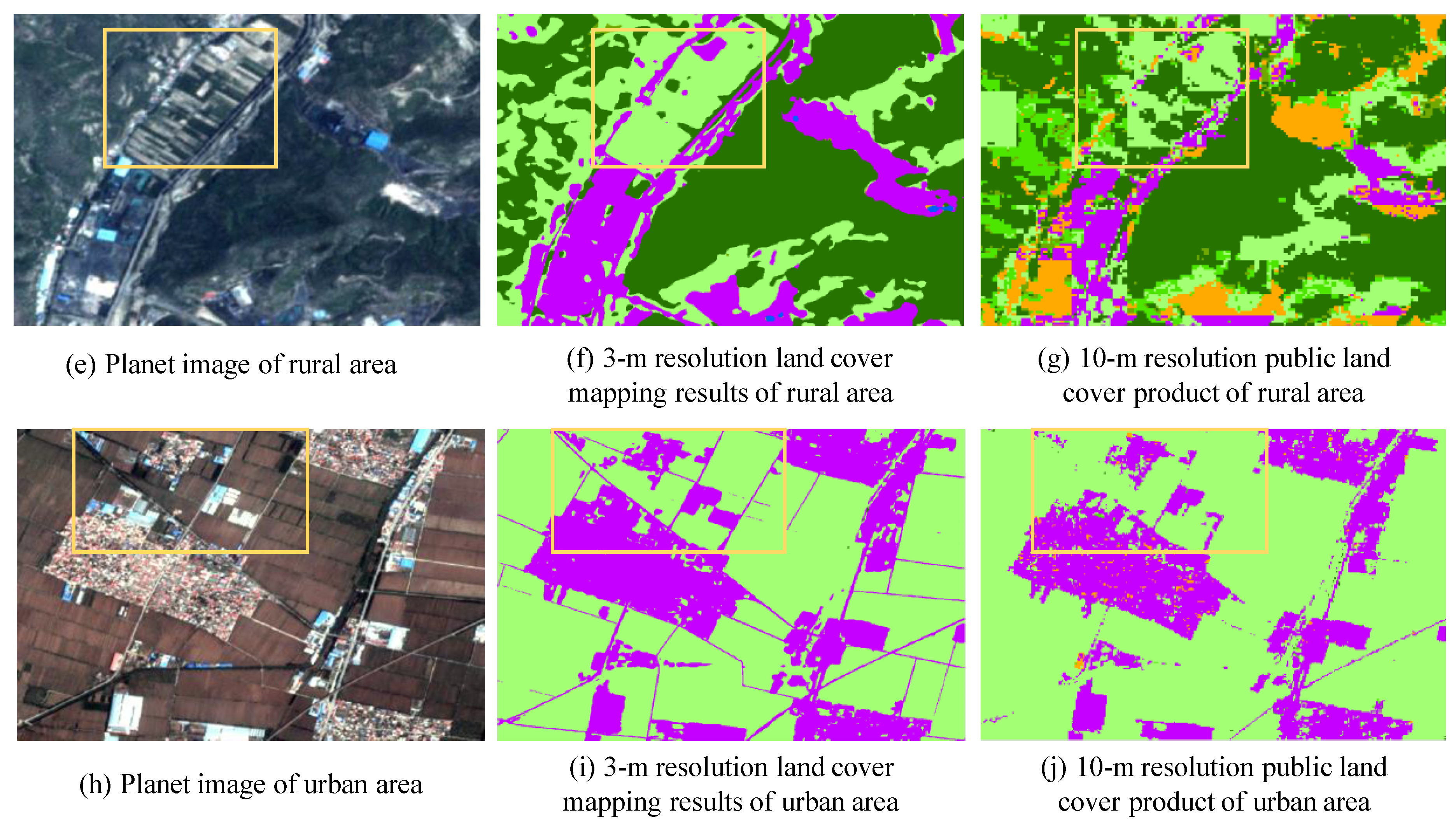
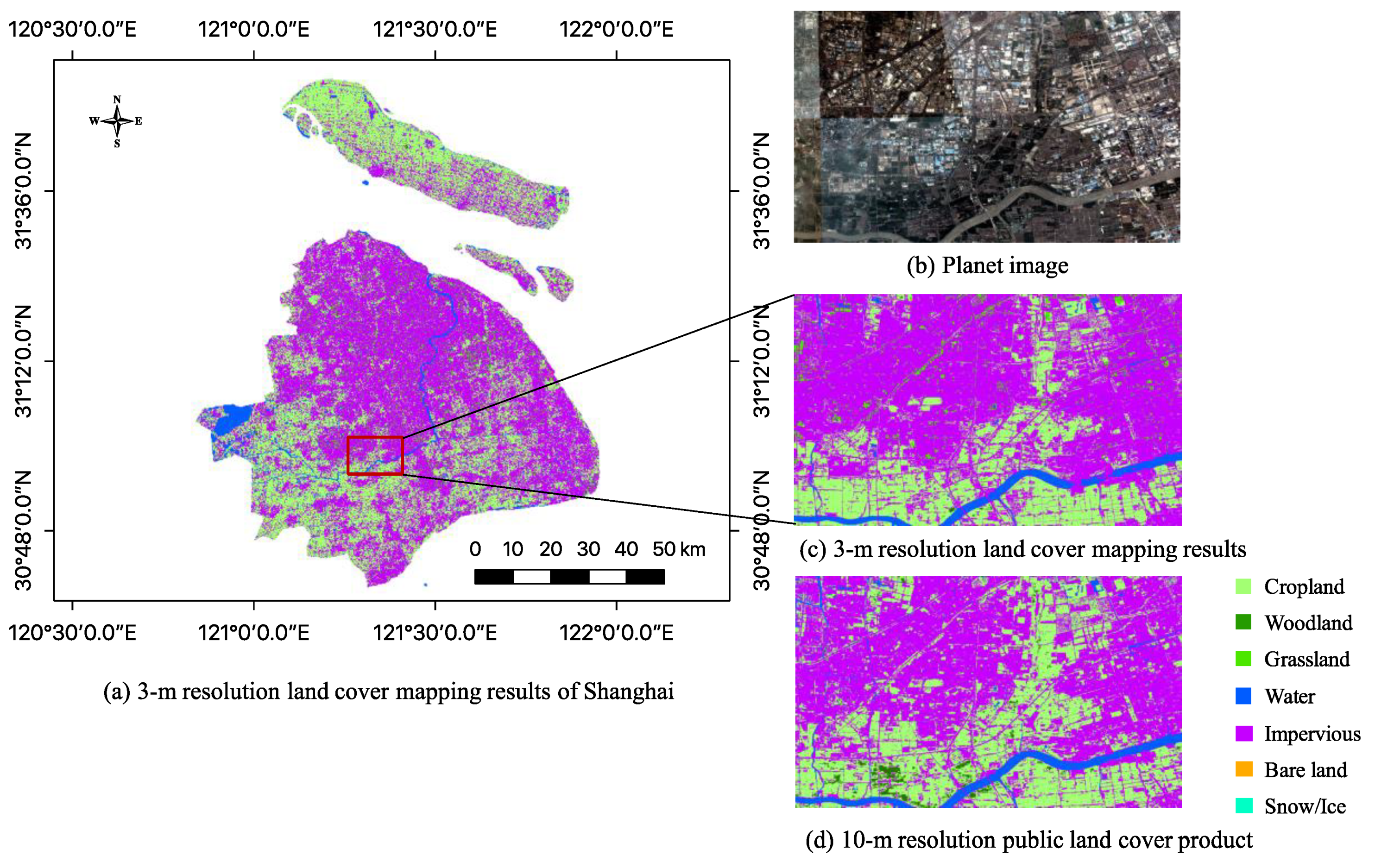
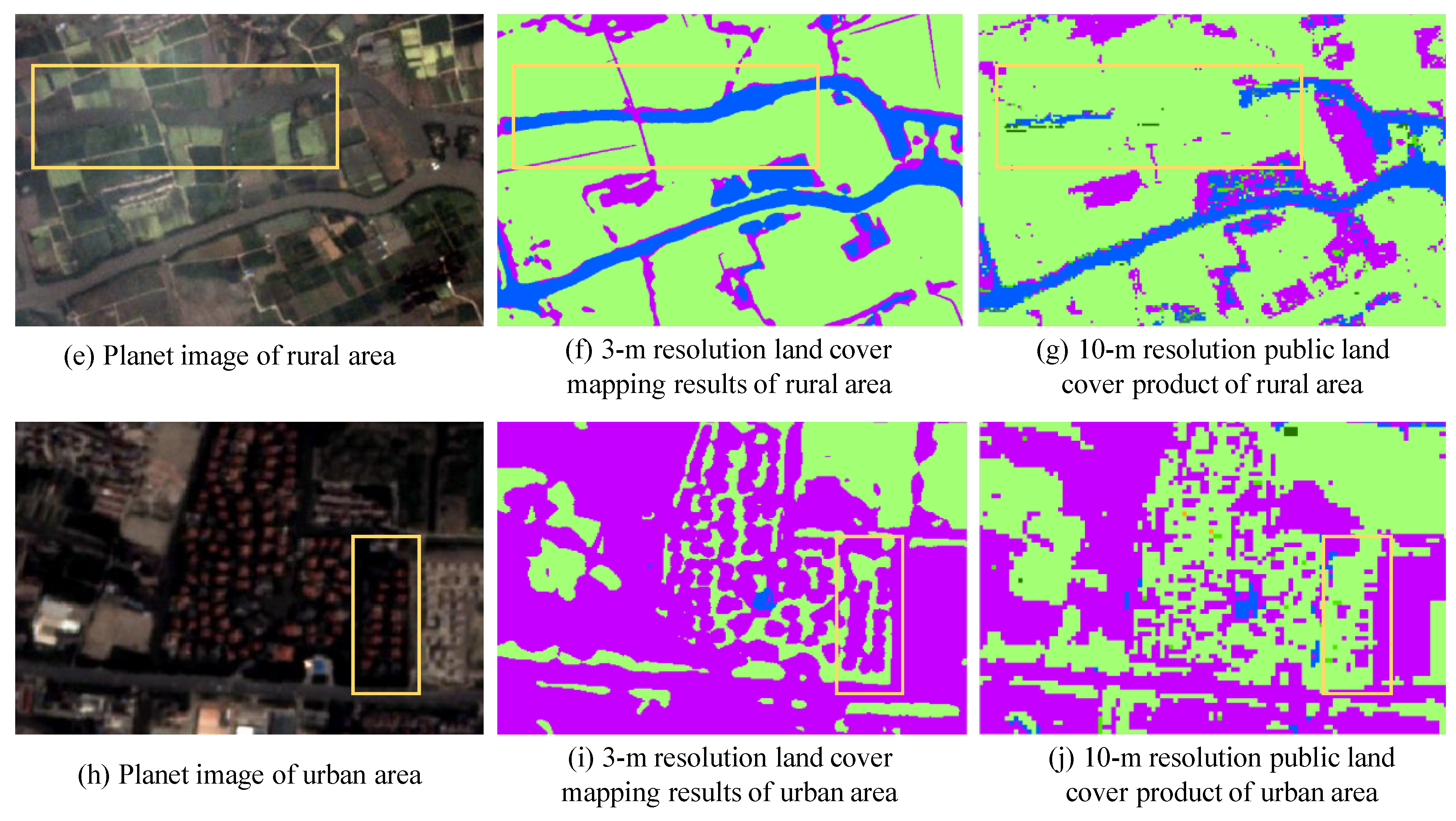
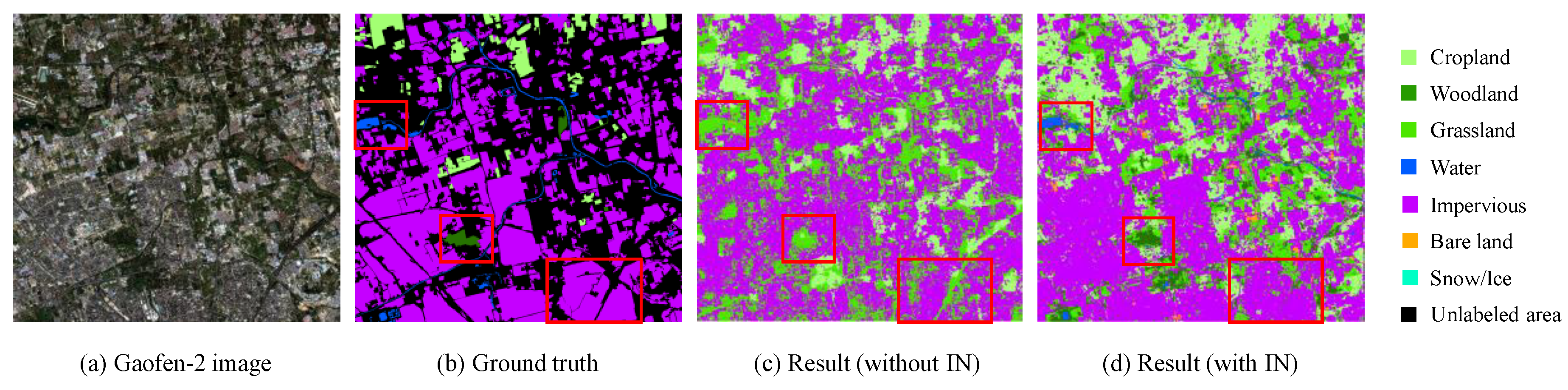
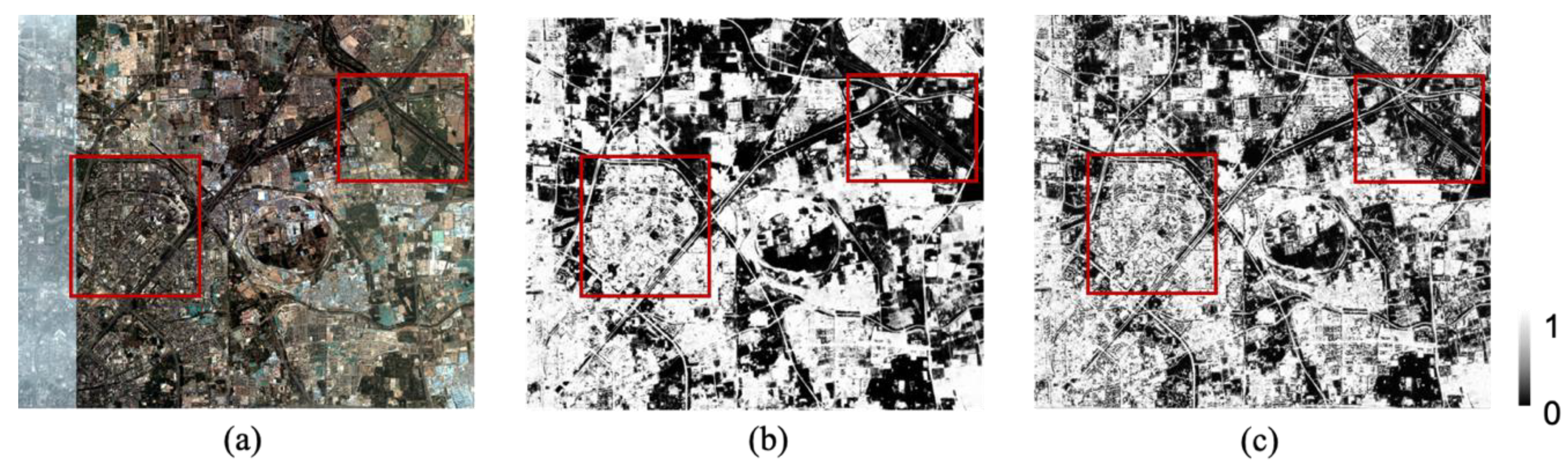
In summary, we aim to produce a novel 3-m resolution land cover map through efficient learning from imperfect 10-m resolution maps without any human interpretation. We propose a complete workflow and a deep learning-based network for this task, which is beneficial to reduce the research thresholds in this community and serves as an example to similar studies. Furthermore, we exhibit the 3-m resolution land cover mapping results over three cities in China as examples (i.e., Harbin, Taiyuan, and Shanghai) to demonstrate the effectiveness of our proposed approach for 3-m resolution large-area land cover mapping.


 and
and 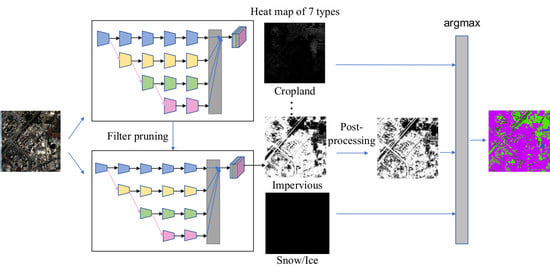











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}