1. Introduction
Aerial images, taken from the air and space, provide sufficient detail about the earth’s surface, such as its landforms, vegetation, landscapes, buildings, and other various resources. Such abundant information is a significant data source for earth observation [
1], which opens the door to a broad range of essential applications spanning urban planning [
2], land-use and land-cover (LULC) determination [
3,
4], mapping [
5], environmental monitoring [
6] and climate modeling. As a fundamental problem in the remote sensing community, aerial scene classification is crucial for these research fields. Xia et al. [
7] defined the aerial scene classification as automatically assigning a specific semantic label to each image according to its content.
Over the past few decades, aerial scene classification enjoys much attention from researchers, and many methods have been proposed. According to the the literature [
7], the existing approaches to aerial scene classification have mostly fallen into three categories—methods adopting low-level feature descriptors [
8,
9,
10,
11], methods using middle-level visual representations [
12,
13,
14,
15] and methods relying on deep learning networks [
7,
16,
17,
18,
19].
Methods adopting low-level feature descriptors. Most early researches [
8,
9,
10] on aerial image classification fall into this category. These methods use hand-crafted, low-level visual features such as color, spectrum, texture, structure, or their combination to distinguish aerial scene images. Among the hand-crafted features, the most representative feature descriptors include color histograms [
8], texture features [
9], and SIFT [
10]. While this type of method performs well in certain aerial scenes with uniform structures and spatial arrangements, it has limited performance for aerial images containing complex semantic information.
Methods using middle-level visual representations. In order to overwhelm the insufficiency of low-level methods, many middle-level methods have been explored for aerial scene classification. Such methods mainly aim at combining the local visual attributes extracted by low-level feature methods into high-order statistical patterns to build a holistic scene representation for aerial scenes. Bag of Visual Words (BOVW) [
12] and many of its variants have been widely used. Besides the BOVW model, typical middle-level methods include, but not limited to, Spatial Pyramid Matching (SPM) [
13], Vector of Locally Aggregated Descriptors (VLAD [
14], Locality-constrained Linear Coding (LLC) [
20], Probabilistic Latent Semantic Analysis (pLSA) [
15] and Latent Dirichlet Allocation (LDA) [
21]. Compared with low-level methods, the scene classification methods using middle-level visual representations have obtained higher accuracy. However, middle-level methods will only go so far; they require hand design features and lack adaptability; their generalization is poor for complex scenes or massive data.
Methods relying on deep learning. Fortunately, with the emergence of deep learning, especially convolutional neural networks [
22,
23], image classification approaches have seen great success in both accuracy and efficiency, also in remote sensing fields. The methods relying on deep neural networks automatically learn global features from the input data and cast the aerial scene classification task as an end-to-end problem. More recently, while the deep CNNs methods have become the new state-of-the-art solutions [
16,
18,
24,
25] for the aerial scene classification area, yet, there are clear limitations. Specifically, the most notorious drawback of deep learning methods is that they typically require vast quantities of labeled data and suffer from poor sample efficiency, which excludes many applications where data is intrinsically rare or expensive [
26]. In contrast, humans possess a remarkable ability to learn new abstract concepts from only a few examples and quickly generalize to new circumstances. For instance, Marcus, G.F. [
27] pointed out that even a 7-month-old baby can learn abstract language-like rules from a handful of unlabeled examples, in just two minutes.
Why do we need few-shot learning? In a world with unlimited data and computational resources, we might hardly need any other technique rather than deep learning. However, we live in a real-world where data are never infinite, especially in the remote sensing community, due to the high cost of collecting. Still, almost all existing aerial scene datasets have several notable limitations.
On the one hand, the classification accuracy is saturated; to be more specific, the state-of-the-art methods can achieve nearly 100% accuracy on the most popular UC Merced dataset [
12] and the WHU-RS19 [
28] dataset. Yet, we argue, such a limited number of categories in the two datasets are critically insufficient for the real world. On the other hand, the scale of the scene categories and the image number per class are limited, and the images lack scene variation and diversity. An intuitive way to tackle this issue is to construct a large-scale dataset for aerial scene classification, and several more challenging datasets, including the AID dataset [
7], the PatternNet dataset [
29], the NWPU-RESISC45 dataset [
18], and the RSD46-WHU dataset [
30,
31], have been proposed. See
Table A1 (
Appendix A) for a detailed description of these common datasets.
Although the aerial scene datasets increase in scale, most of them are still considered small from the perspective of deep learning. For similar situations in the machine learning community, few-shot learning [
32] offers an alternative way to address the data-hungry issue from a different standpoint. Instead of expanding the dataset scale, few-shot learning aims to learn a model that can quickly generalize to new tasks from very few labeled examples. Arguably, few-shot learning is a human-like way of learning. It assumes a more realistic situation where not rely on thousands or millions of supervised training data. Namely, few-shot learning can help to relieve the burden of collecting data, especially in some specific domains in which collecting labeled examples is usually time-consuming and laborious, such as aerial scene field or drug discovery.
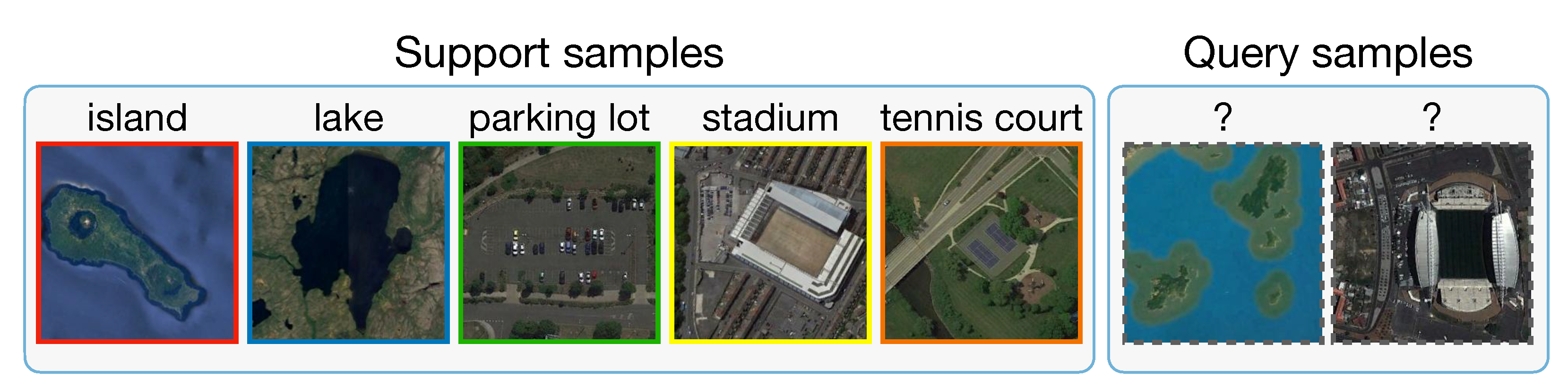
Figure 1 demonstrates a specific 1-shot scenario that it is possible to learn much information about a new category from just one image.
By seeing the potential that few-shot learning can alleviate the data-gathering effort, improve computing efficiency, and bridge the gap between Artificial Intelligence and human-like learning, we introduce the few-shot paradigm to the aerial scene classification problem. The goal of this work is to classify aerial scene images with only 1 or 5 labeled samples. More specifically, we adopt a meta-learning framework to address this problem. To the best of our knowledge, only a few efforts have focused on the few-shot classification problem in the aerial/remote scene regime. A deep few-shot learning method is proposed in work [
26] to tackle the small sample size problem of hyperspectral image classification. The very recent work [
33] developed a few-shot learning method based on Prototypical networks [
32] for the classification of RS scene. By far, we are the first to provide a testbed for few-shot classification of aerial scene images. We re-implement several state-of-the-art few-shot learning approaches (i.e., Prototypical Networks [
32], MAML [
34] and Relation Network [
35]) with a deeper backbone Resnet-12 for a fair comparison. In addition, we re-implement a typical machine learning classification method D-CNN [
16], to evaluate its performance in the few-shot scenario.
The main contributions of this article are summarized as follows.
This is the first work to provide a unified testbed for fair comparison with several state-of-the-art few-shot learning approaches in the aerial scene field. Our experimental evaluation reveals that it is possible to learn much information for a new category from just a few labeled images, which is a great potential for the remote sensing community.
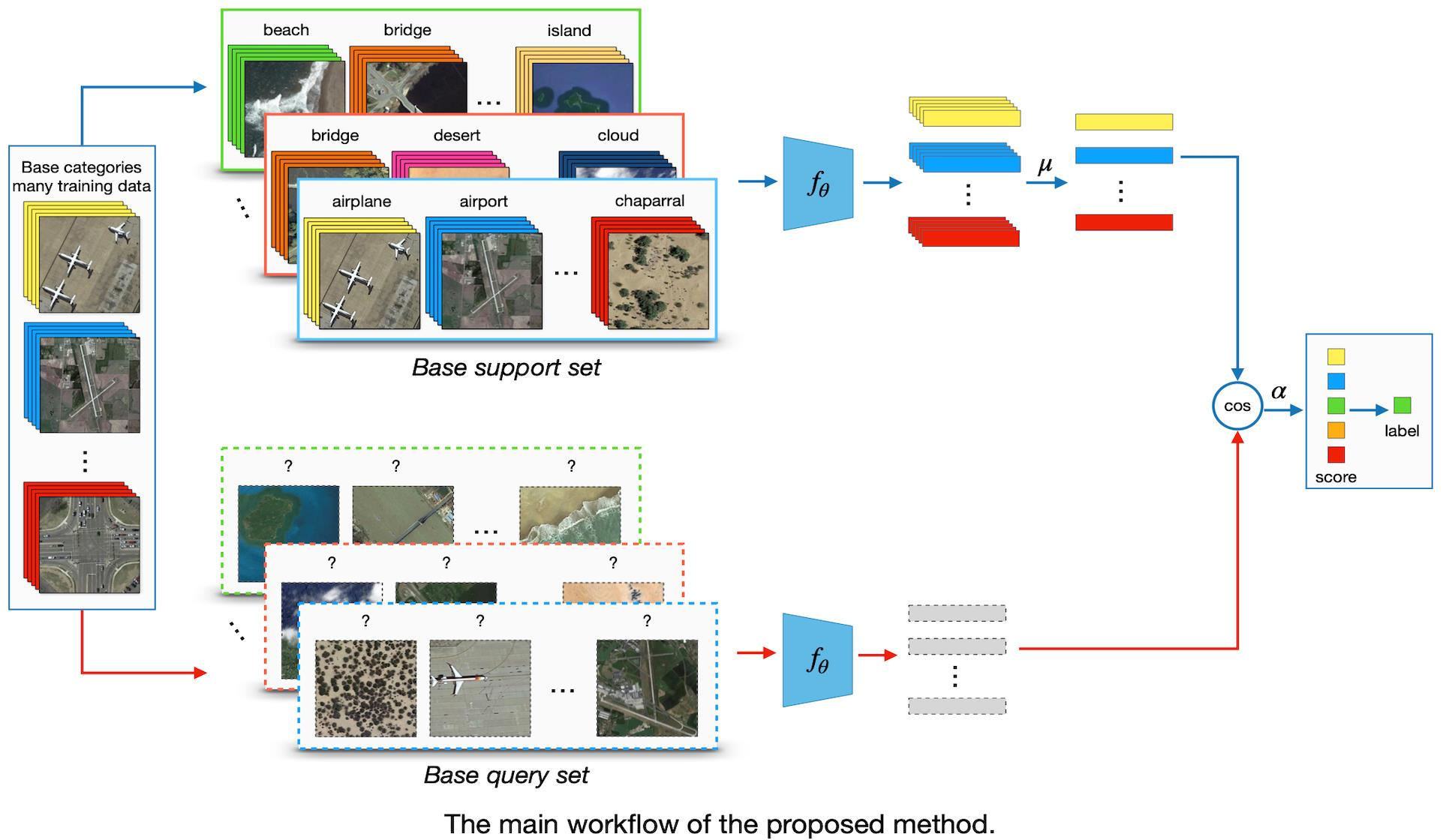
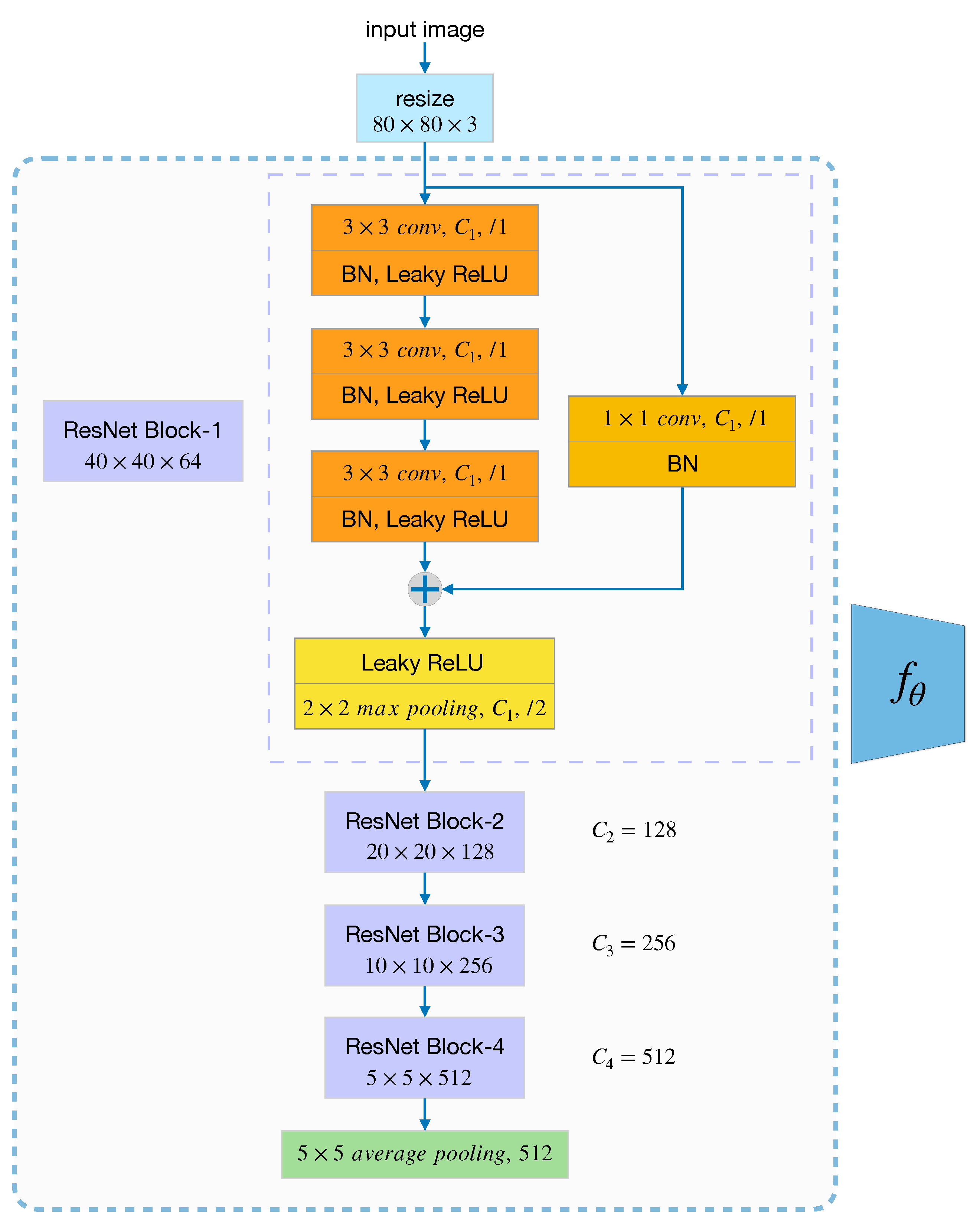
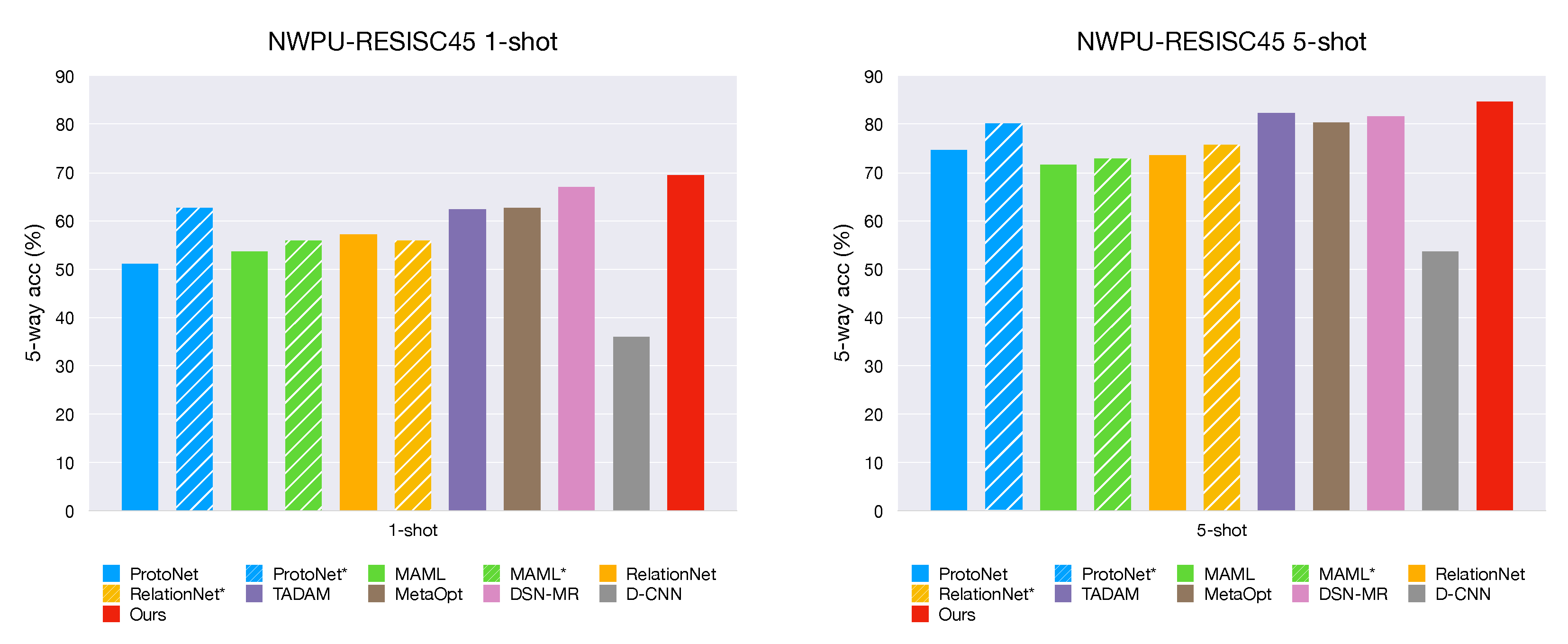
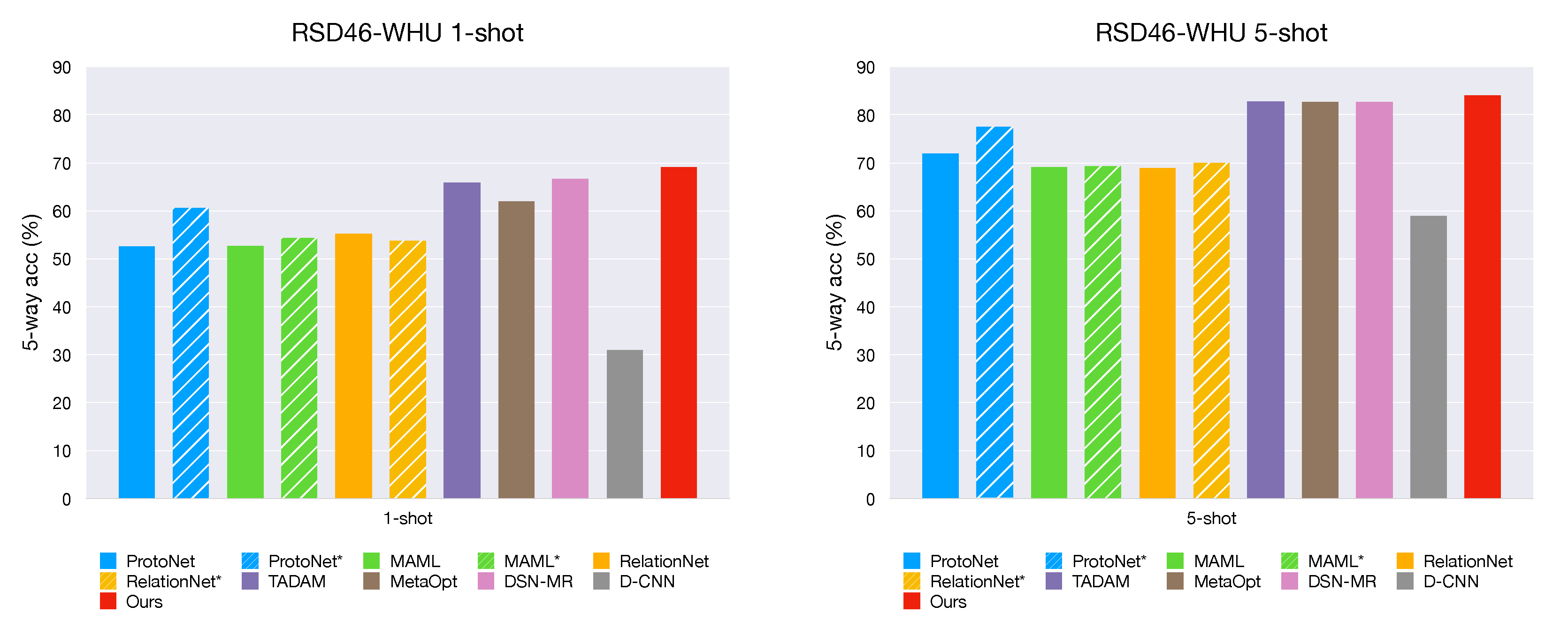
The proposed method including a feature extraction module and a meta-learning module. First, ResNet-12 is used as a backbone to learn a representation of input on base set. Then, in the meta-training stage, we optimize the classifier by cosine distance with a learnable scale parameter in the feature space, neither fix nor introduce any additional parameters. Our method is simple yet effective, achieves state-of-the-art performance on two challenging datasets: NWPU-RESISC45 and RSD46-WHU.
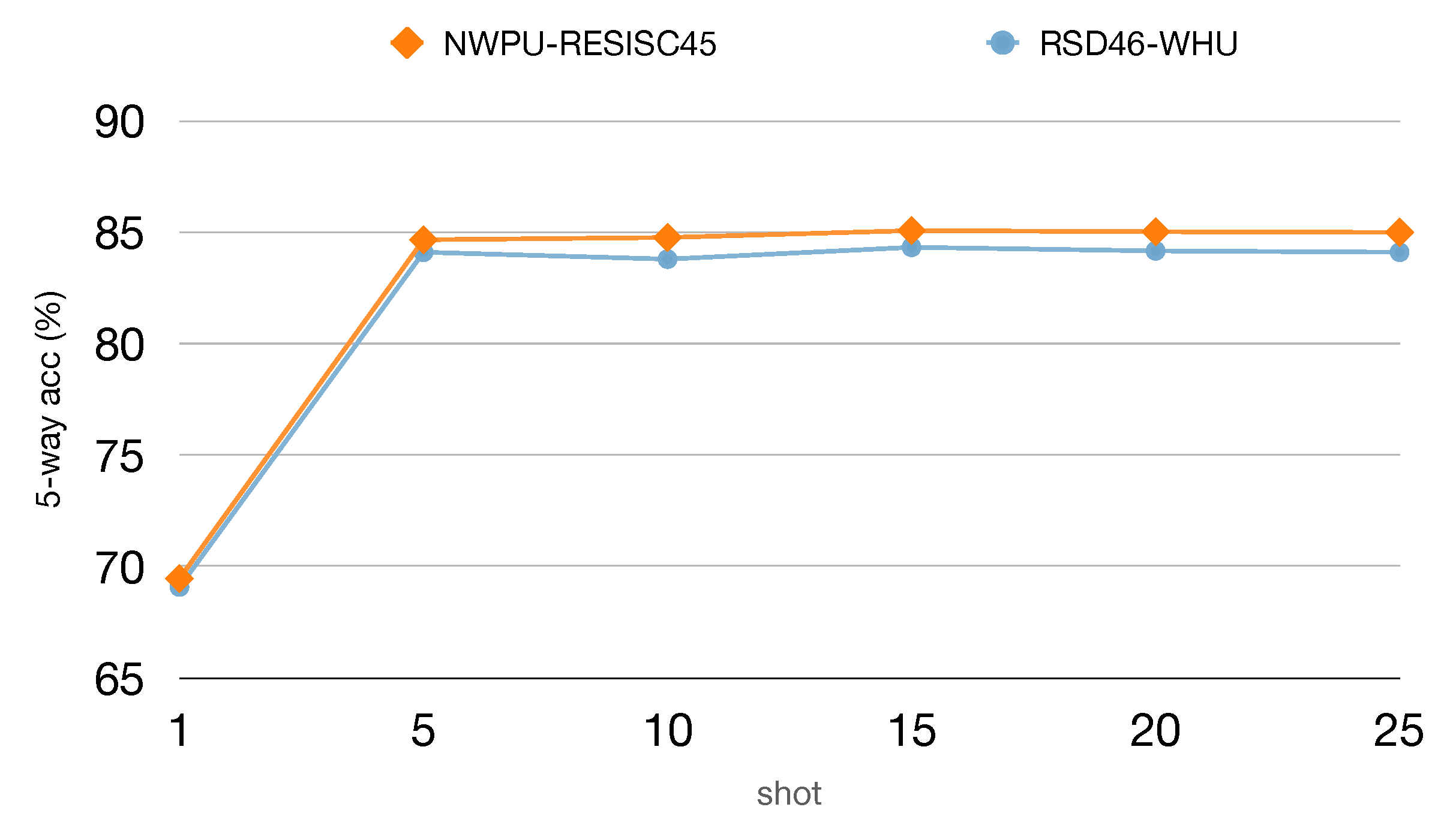
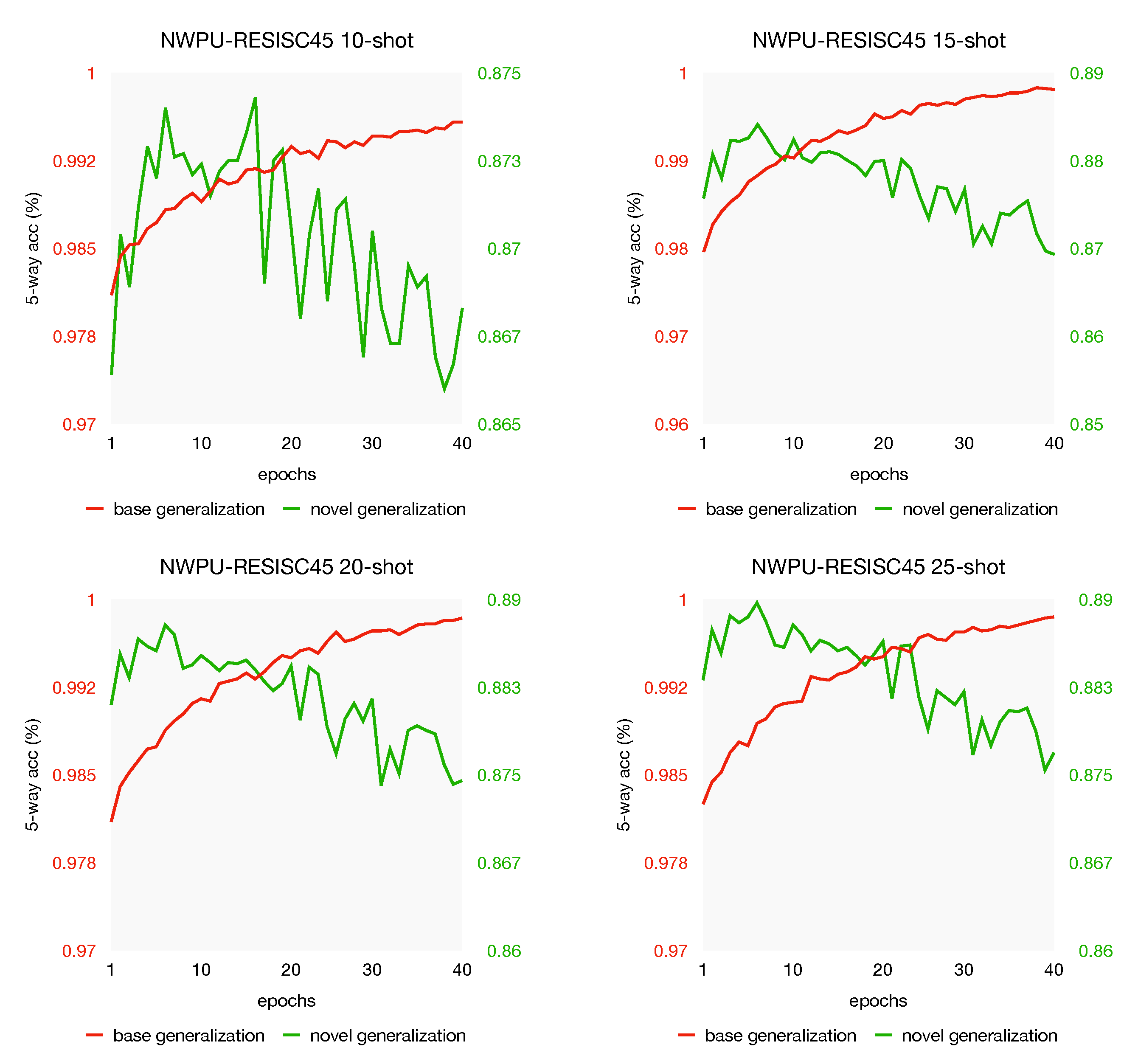
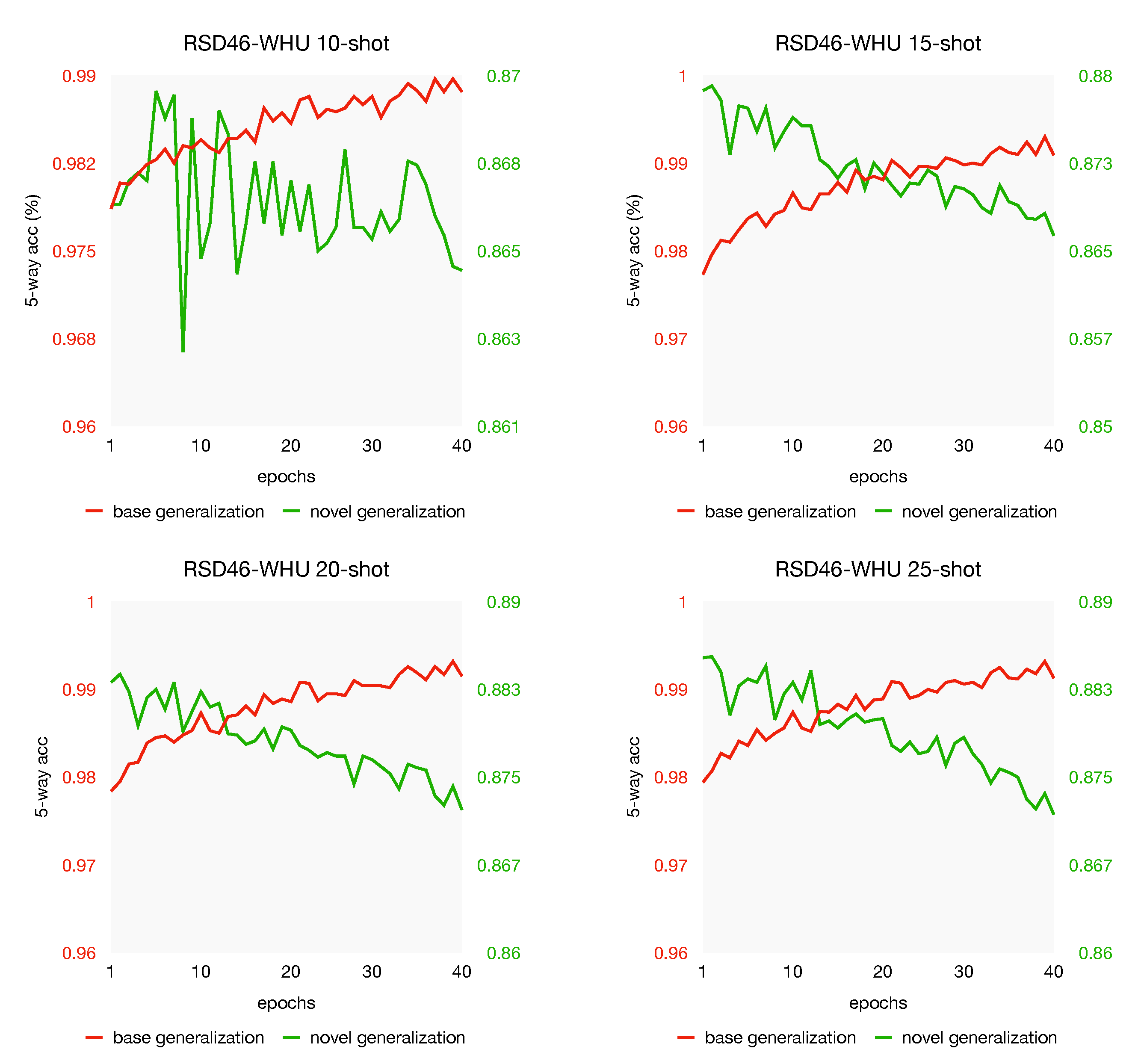
We conduct extensive experiments and build a mini dataset from the RSD46-WHU to further investigate what factors aspect the performance, including the effect of dataset scale, the impact of different metrics and number of support shots. The experiment results demonstrate that our model is specifically effective in few-shot settings.
The remainder of this paper is organized as follows. In
Section 2, we discuss the related work on CNN-based methods of aerial scene classification and various state-of-the-art few-shot classification approaches that developed recently. In
Section 3, we introduce some preliminary of the few-shot classification as it may be new to some readers. The proposed meta-learning method is described in
Section 4. We illustrate the datasets and discuss the experiment results in
Section 5. Moreover, finally,
Section 6 concludes the paper with a summary and an outlook.
3. Preliminary
Before introducing our overall framework in detail, we first look at some preliminary of the few-shot classification as it may be new to some readers.
In standard supervised classification, we are dealing with a dataset . The training set takes labeled pairs as inputs, denoted as , , where N is the number of training samples, is the number of categories in . We are interested in learning a model , parameterized by on , to predict the label for an unlabeled sample on the test set .
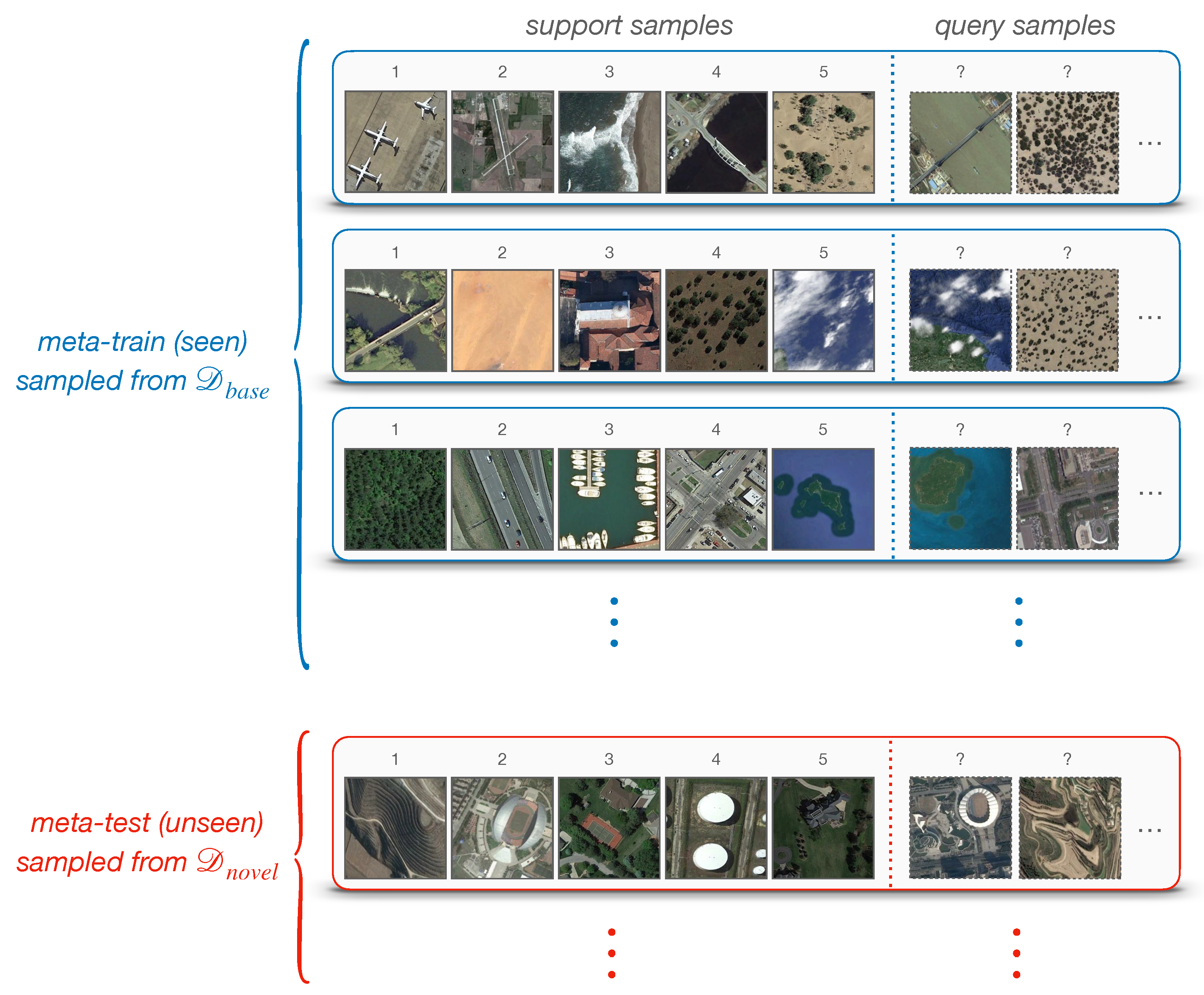
In few-shot classification, we instead consider a meta-set and are chosen to be mutually disjoint, where represents the category. The vision is to learn a model on that can quickly adapt to unseen categories in with only a few support samples, usually 1 or 5. is held-out for choosing the hyperparameters and select the best model.
Following the standard FSL protocol [
45,
52], a model is often evaluated on a set of
N-way
K-shot classification
tasks, denoted as
, also known as
episodes. To be specific, each
episode has a split of support-set
and query-set
. The support-set
contains
N unique categories with
K labeled samples in each, meaning that
consists of
samples for training. The query-set
holds the same
N categories, each with
Q unlabeled samples being to classify. An
episode is often constructed in the same way in training and testing. In other words, if we are supposed to perform 5-way 1-shot classification at test-time, then training
episodes could be comprised of
N = 5,
K = 1.
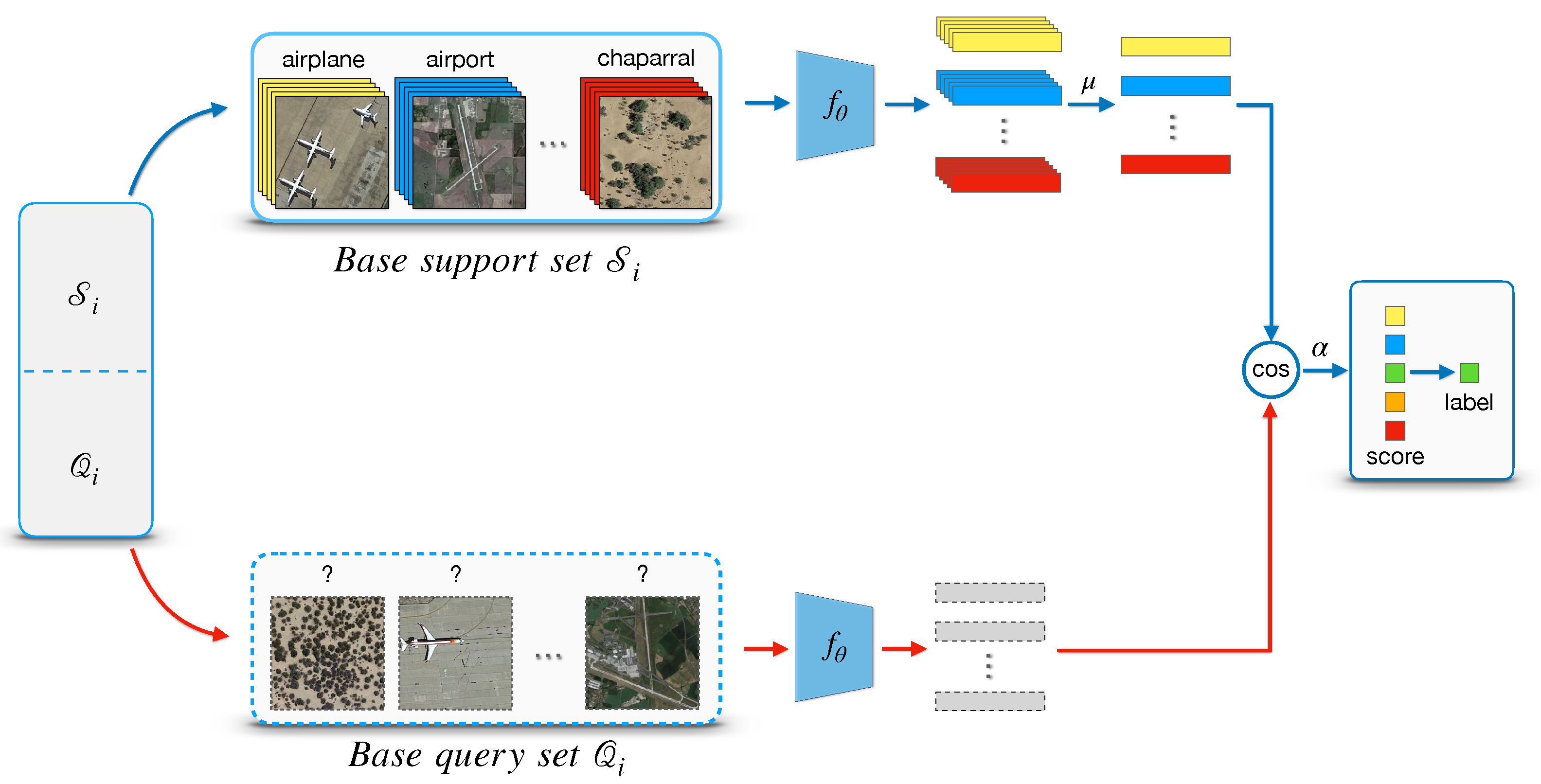
Figure 2 shows a visualization of 5-way 1-shot
episodes. Note that, an entire
task/episode in FSL is treated as a training instance in conventional machine learning.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










