1. Introduction
The Sentinel-2 mission consists of two polar-orbiting satellites, Sentinel-2A and Sentinel-2B, providing a five day revisit time at the equator. The swath width of a Sentinel-2 scene is 290 km and data is acquired in 13 bands with spatial resolutions of 10 m, 20 m, and 60 m [
1] (see
Table 1). Sentinel-2 images are open access data, offer high quality radiometric measurements and include a dedicated cirrus detection band. The free data access, frequent coverage of territories, wide swath and many spectral bands are reasons for the wide-spread use of this kind of data in many applications. Satellite imagery is frequently contaminated by low and medium altitude water clouds as well as by high-altitude cirrus clouds in the upper troposphere and in the stratosphere. Many operations require clear sky pixels as input, such as agriculture related products [
2,
3], the retrieval of surface reflectance within atmospheric correction [
4,
5] and the coregistration with other images [
6,
7].
Atmospheric correction and land cover classification depend on an accurate cloud map [
8,
9,
10]. In addition, maps of water and snow/ice are also indispensable in many applications, i.e., mapping of glaciers [
11] and water bodies [
12].
Cloud screening is applied to the data in order to retrieve accurate atmospheric and surface parameters as input for further processing steps, either the Atmospheric Correction (AC) itself or higher-level processing such as compositing, time-series analysis or estimation of biogeophysical parameters.
However, a fully automatic detection of these classes is not an easy task, due to the high reflectance variability of earth surfaces. For instance, bright desert surfaces or urban structures can be misclassified as one or the other or as cloud and shadow surfaces as water. A class assignment for mixed pixels (e.g., semitransparent cloud over snow) can be problematic because they do not have a spectral signature, which clearly belongs to a class. These together will decrease the classification accuracy and shows the need for a performance assessment of classification algorithms.
The
Cloud Masking Intercomparison Exercise (CMIX) [
13] was a recent state-of-the art intercomparison of a set of cloud detection algorithms for Sentinel-2 and Landsat-8 representative for sensors in the 10–30 m range. However, CMIX was limited to differentiate only cloudy and cloudless pixels. Reference [
14] is limited to valid and invalid pixels too. Valid pixels in reference [
14] are cloudless pixels like land, water and snow and invalid are clouds and cloud shadows. Cloud masks from the
MACCS ATCOR Joint Atmospheric Correction (MAJA) algorithm using multi-temporal information are compared with monotemporal classification by Sen2Cor and Fmask [
15]. The comparison in reference [
14] is done twice: Once for cloud masks of all three processors dilated around clouds and second for all processors with nondilated cloud masks. This means that there is no comparison on original processor outputs. Overall accuracies for all three algorithms are nearby at 90–93% in case of nondilated cloud mask. Monotemporal Fmask gave equivalent classification performance as multitemporal MAJA for dilated masks and Sen2Cor was on average 6% worse on these. However, dilation of Sen2Cor cloud mask is not recommended with the used processor version because it is a known issue that it misclassifies many bright objects as clouds in urban area, which leads to commission of clouds and even more if dilation is applied. On the contrary, original masking outputs are evaluated in this paper and not only for valid and invalid pixels, but in more detail for six consolidated classes given below. This gives more insight into strengths and weaknesses of the masking algorithms.
As opposed to radiometric validation, the validation of masking is limited due to the lack of suitable reference datasets. Imaged-based reference data are required, which can only be generated through image interpretation or semiautomated methods as done in [
14] CMIX is based on four classification reference data bases for Sentinel-2 data. These existing reference data are either not publicly available or do not fulfill the requirements for this study, e.g., 20 m resolution and a distinction of all defined classes.
In this study we evaluate the performance of three widely used monotemporal masking codes on Sentinel-2 imagery.
Our first masking code is
Function of mask (Fmask) [
16]. It was originally designed for Landsat imagery but later extended for Sentinel-2 data [
15]. Here, we use the Fmask version as implemented in FORCE ([
17]), which is able to separate clouds from bright surfaces exploiting parallax effects. In FORCE, the cloud masking is integrated into a processing workflow, which also includes coregistration [
18], radiometric correction [
19], resolution merging [
20] and datacube generation [
21]. The individual detectors of MSI-sensor have slightly different viewing directions alternating from forward view to backward view between adjacent detectors. The second code is the latest version of ATCOR (v 9.3.0), which contains a masking algorithm [
22] as a necessary preprocessing part before starting the atmospheric correction. Masking in ATCOR 9.3.0 was improved relative to previous versions. The third is the scene classification of Sen2Cor (version 2.8.0). Sen2Cor is an atmospheric correction processor for Sentinel-2 (S2) data provided by the
European Space Agency (ESA), which contains a preprocessing scene classification step preceding atmospheric correction [
23]. Whereas the atmospheric correction module of Sen2Cor was developed in heritage of ATCOR, the scene classification is completely independent. Scene classification of Sen2Cor makes use of some external auxiliary data from Climate Change Initiative [
24]. It is still to mention that Fmask uses a 300 m dilation buffer for cloud, and 60 m for cloud shadow, while ATCOR uses 100 m and 220 m, respectively, and Sen2Cor (version 2.8.0) uses no dilation buffers. Fmask applies also a 1 pixel buffer for snow. The reader is referred to the given references for a detailed description of the three methods and the different threshold values used, because it is outside the scope of this paper.
This paper is organized as follows:
Section 2 presents an overview over the S2 scenes used for the exercise.
Section 3 describes the approach to define the reference (“truth”) mask (validation procedure).
Section 4 presents the classification results in terms of user’s, producer’s and overall accuracy [
25], and
Section 5 provides a discussion of the critical issues. The conclusion and possible further improvements are given at the end of the paper.
2. Methods (Processors) and Data
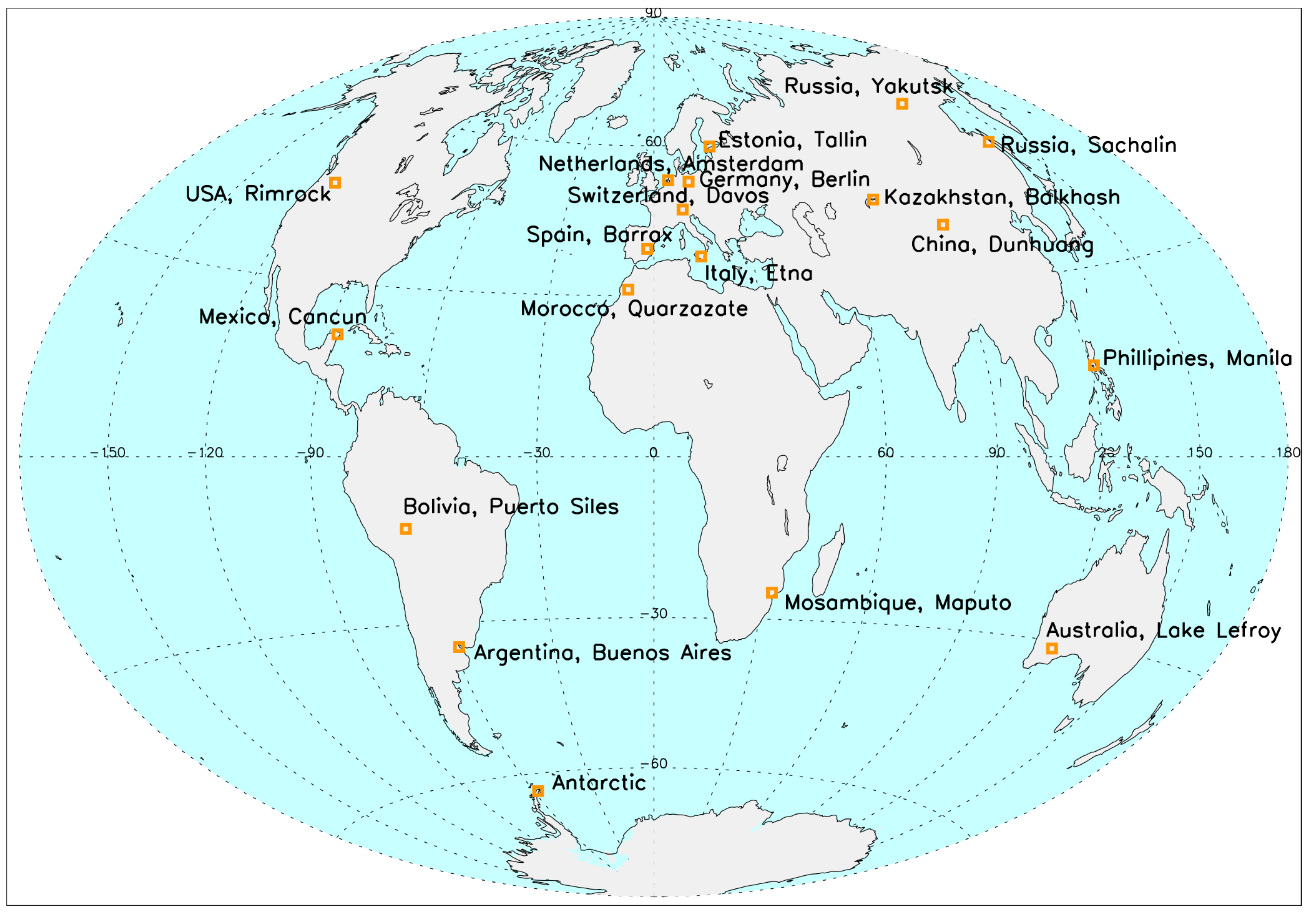
Twenty S2 scenes are processed with the three codes. A list of the investigated Sentinel-2 scenes is given in
Table 2. The scenes were selected to cover all continents, different climates, seasons, weather conditions, and land cover classes (
Figure 1). They represent flat and mountainous sites with cloud cover from 1% to 62% and include the presence of cumulus, thin and thick cirrus clouds and snow cover. Additionally, the scenes represent different land cover types such as desert, urban, cropland, grass, forest, wetlands, sand, coastal areas and glaciers. The range of solar zenith angles is from 18
to
. For the scene classification validation, all S2 bands with 10 m and 60 m are resampled to a common 20 m pixel size. All processors used
Digital Elevation Models (DEMs) usually from SRTM (90 m) (downloaded from the USGS website (
https://earthexplorer.usgs.gov/)) except for the scenes number 1, 6 and 16, which used Planet DEM [
26].
The classification of ATCOR provides a map with 22 classes which is used in the subsequent atmospheric correction module [
22]. For this investigation, a compact map with seven classes (clear, semitransparent cloud, cloud, cloud shadow, water, snow/ice, topographic shadow) is derived from the detailed map at 20 m spatial resolution. A potential shadow mask is defined as reference shadow and the cloud height of the cloud mask is iterated until the projected cloud mask for the given solar geometry matches the shadow mask. Topographic shadow is calculated with a ray tracing algorithm using the DEM and the solar geometry. The classes “cloud shadow” and “water” are often difficult to distinguish and in case of cloud shadow over water the class assignment is arbitrary. Therefore, misclassifications can happen, because only one label can be assigned in this method. Semitransparent cloud can be thin cirrus or another cloud type of low optical thickness.
The SCL algorithm of Sen2Cor aims to detect clouds with their shadows and to generate a scene classification map. The latter raster map consists of 12 classes, including 2 classes for cloud probabilities (medium, and high), thin cirrus, cloud shadows, vegetated pixels, nonvegetated pixels, water, snow, dark feature pixels, unclassified, saturated or defective pixels and no data. This map is used internally in Sen2Cor in the atmospheric correction module to distinguish between cloudy pixels, clear land pixels and water pixels, and it does not constitute a land cover classification map in a strict sense [
27]. The scene classification map is delivered at 60 m and 20 m spatial resolution, with associated
Quality Indicators (QI) for cloud and snow probabilities. The QIs provide the probability measure (0–100%) that the Earth surface is obstructed either by clouds or by snow. Class dark area pixels can contain dark features like burned area, topographic shadows or cast shadows but also very dark water bodies and vegetation. Thin cirrus may also be other transparent cloud and the transition from medium to high probability cloud is impossible to validate. Pixels assigned to unclassified are mostly pixels with low probability of clouds or mixed pixels, which do not fit into any of the other classes.
3. Validation Procedure
Validation of masks comprises verification of the mask classification accuracy to clarify uncertainties of masking products for their applications. Comparison of different mask classification algorithms requires first to map all the individual masking outputs to a common set of labels.
Table 3 shows the seven classes used as a common set for Fmask, ATCOR and Sen2Cor.
Semitransparent cloud is defined as optically thin cirrus cloud, thin lower altitude cloud, haze or smoke. To detect thin cirrus clouds, the reference mask generation use the TOA reflectance in the cirrus band 10, lying below 0.04 but above 0.01. The lower threshold is used to avoid classifying all pixels as semitransparent. The label cloud comprises optically thick (opaque) water cloud and also cirrus cloud with (TOA, band 10) > 0.04.
The focus of the present paper is not only validation of the scene classification provided by the three processors but its comparison. This comparison is done by generating two reference maps which complement each other—one for the “difference area” and another for the “same area”. The difference area is the part of the classification images where the classification maps provided by the three processors disagree. Validation statistics over the difference area enable a relative comparison between processors pointing on strengths and weaknesses much sharper than interpreting statistics over an entire image, which are often fairly similar. The same area is the remaining part of the images where all three classifications give the same result. Combination of the validation statistics over the same area and disagreement area enables to assess the absolute classification performance of the processors. This requires that the ratio of labeled pixels in the difference area to the labeled pixels in the same area is the same as the ratio of the size of disagreement area to size of agreement area. The challenge for validation of SCL is generation of high quality reference maps which gives the "truth". Generation of the reference maps for the performed comparison of Fmask, ATCOR and Sen2Cor outputs relies on visual inspection, supplemented by meteorological data, if available. The following procedure was repeated for each image of the validation dataset.
First, stratified random sampling [
25] is applied to the difference mask between three processors to get the sample points for visual labeling. Stratification serves to get the sample size balanced between all classes present in the image, thus to guarantee statistical consistency and to avoid exclusion of spatially limited classes from the validation. Our aim is an amount of 1000 randomly selected samples per image with the minimum number of 50 samples for the smallest class (for reference please see following authors: [
28,
29,
30,
31]). Visual inspection by human interpreter results in labeling of either one pixel only or alternatively labeling a polygon drawn around an adjacent area of pixels of the same class to assign the correct class and create the reference (“truth”) map. All labeled pixels are used to create the reference classification image typically resulting in an average number of 5000 pixels per scene.
Figure 2 presents an overview on the generation of the classification reference mask. It begins (left part) with selected L1C channel combinations (4-3-2; 8A-6-5; 10; spectral TOA reflectance profiles, etc.), continues with the consolidation, stratified random sampling and visual labeling to create the reference image. This image (right part) is masked and compared to the consolidated images to obtain the corresponding pixels of the classification images and perform the accuracy assessment.
Visual inspection by the expert human interpreter was supported by:
Visual checks of the TOA true color image (bands 4, 3, 2), TOA near infrared false color (bands 8A, 6, 5), and TOA short-wave infrared false color (bands 12, 11, 8A).
Check of L1C cirrus (band 10) concerning semitransparent cirrus regions.
Check of BOA reflectance spectral profiles from Level-2 Sen2Cor products.
Comparison with imagery archive from GoogleEarth .
The created reference classification map is finally compared to the consolidated classification maps from Fmask, ATCOR and Sen2Cor and a confusion matrix is obtained for each classification. Finally, classification accuracy statistics are computed from confusion matrices. After completing analysis for disagreement area, the same procedure is repeated for the same area to allow computation of absolute classification accuracy statistics of the three classifications.
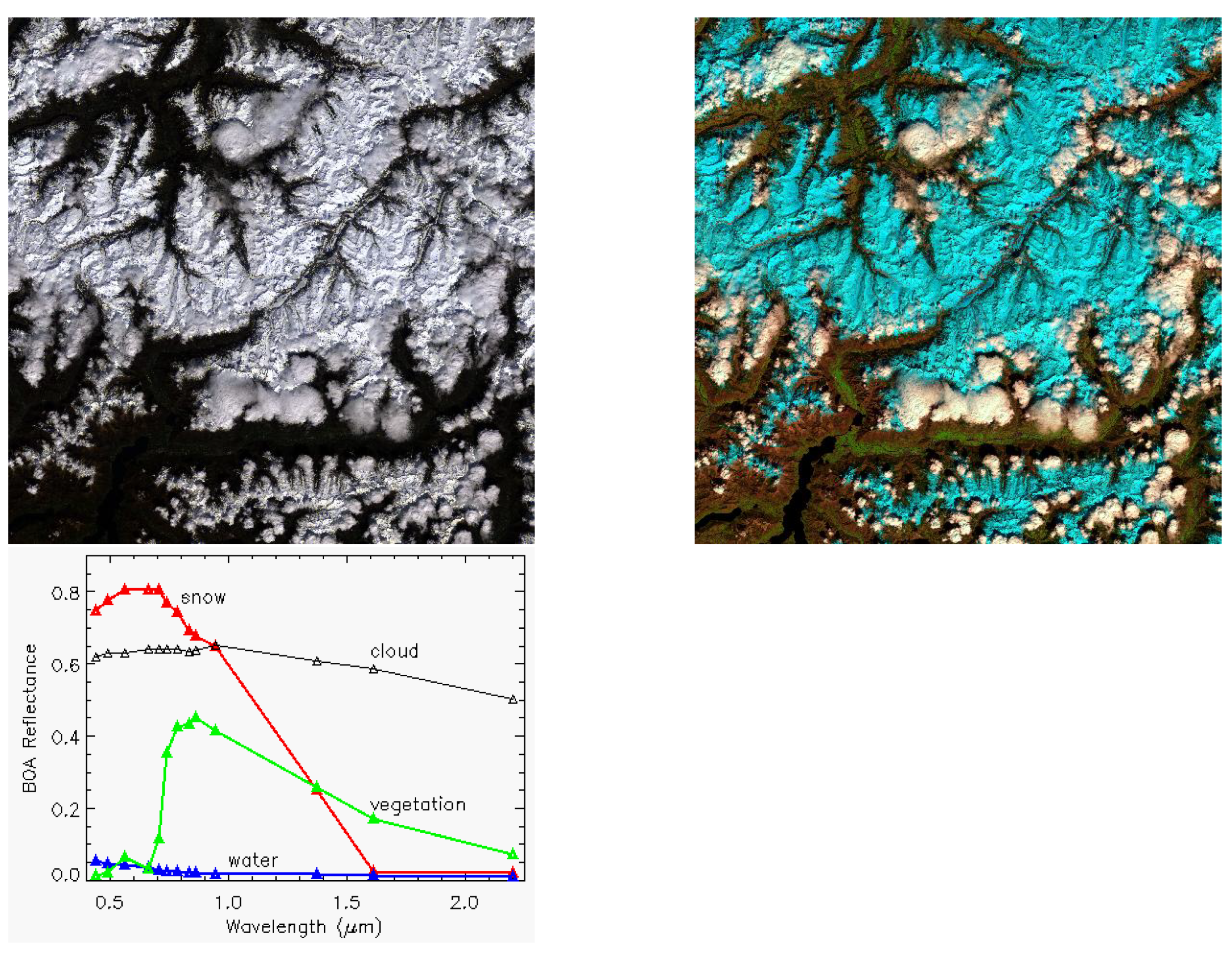
Figure 3 shows an example of a true color (RGB = Red, Green, Blue = bands 4, 3, 1) composite of scene 19 (Davos) of
Table 2, a false color composite using RGB (SWIR1, NIR, red) and some typical BOA reflectance spectra of snow, clouds, clear (vegetation) and water. Obviously, snow/ice and clouds cannot easily be discerned in the true color image. Therefore, the human interpreter also uses other band combinations, in this case with band 11 (SWIR1), where snow/ice (colored blue) is clearly recognized. In addition, BOA reflectance spectra are evaluated for a polygon if a class assignment is not obvious.
The procedure applied for generation of our reference classification map is similar to the way used to create the references for the Hollstein and PixBox datasets [
10]. The new point is that we split the validation into creating a reference for the difference area and another for the same area for comparison of classification tools. Please note that obtained reference maps are not perfect. The manual labeling includes some amount of subjectivity. Most of all visual interpretation and labeling of transparent clouds is challenging. Subjectivity of the method was tested with four people, creating a reference map for the same two products. The test revealed quite stable results with 5–6% differences in
overall accuracy (OA) using the reference maps for computation of classification accuracy statistics. Another limitation of our classification reference maps comes from the stratified random sampling. The stratification between classes has to be oriented itself on one classification, which was Sen2Cor in our case. If the Sen2Cor classification fails, then the reference map becomes imbalanced. Even if this is not the case, then the reference maps are not perfectly balanced for the other classifications. The potential bias could be investigated by creating another stratified random sampling based on a different set, but such a sensitivity study is outside the scope of this paper.
Classification accuracy statistics is represented by three parameters calculated from the error confusion matrix [
25,
29,
30]. If the number of classes is
n, then the confusion matrix
C is a
matrix, and the
user’s accuracy of class
i (percentage of the area mapped as class
i that has reference class
i) is defined as
The second parameter is the
producer’s accuracy of class
i (percentage of the area of reference class
i that is mapped as class
i)
The last is the
overall accuracy:
The OA can be calculated for the total area of an image, i.e., the absolute OA but also for the difference and same area of each scene and masking code.
Besides the OA, UA and PA measures, a detailed visual inspection supported the analysis of the confusion within and between classes per processor. Comparison was performed per processor and class over difference area, including recognition rates, misclassification rates of particular class as well as its confusion potential with other classes (the proportion of one mistaken by other class).
4. Results
Validation results consist of confusion matrix with the number of correctly classified pixels in the validation set. Confusion matrix is the basis for computation of UA and PA and OA of classification.
Table 4 provides results for difference area and shows a summary of the UA and PA per class, i.e., the average over all 20 scenes.
Table 5 provides results for absolute validation of classifications comparable to results present in the literature and contains the OA per scene. Boldface numbers indicate the method with the best performance, but if the values differ less than about 1% then two methods are marked correspondingly.
For space reasons, we cannot present detailed results for each scene. The example of scene 4 (Bolivia, Puerto Siles) in
Figure 4 serves as an example to demonstrate the difference mask validation. The image contains no clouds but water with different color and sediment, bright soil and burned area. This image is the example with the smallest difference area rather than the one with the largest agreement between Fmask, ATCOR and Sen2Cor classifications. This is also underlined with high absolute OA over complete image of 99%, 98% and 99%. There is only a small difference between classifications in PA over complete image for class clear land with 100%, 98% and 99% representing what is visible in
Figure 4—a different amount of burned area is classified as water. User accuracy of class water for the total image is 99% for all masking codes, hiding differences clearly to see in the figure. Statistics over difference area gives a much more detailed insight into classification performance. OA over difference area is 90%, 22% and 58% for Fmask, ATCOR and Sen2Cor. Differences in PA for class clear land are now more highlighted with values 97%, 18% and 57%. User accuracy of class water for the difference image now is different between Fmask and Sen2Cor with 74% resp. 80%. Whereas Fmask identifies 97% of clear pixels in the difference area as clear, ATCOR and Sen2Cor do it for less than 60% of pixels. ATCOR largely misclassifies burned area as water. The problem shown for Sen2Cor with misclassification of clear land as topographic shadow has its origin in the transformation of Sen2Cor classification outputs to the consolidated mask. Consolidated class topographic shadow corresponds to Sen2Cor class dark area, which can contain dark features like burned area, topographic shadows or cast shadows but also very dark water bodies and vegetation. A planned update of class definition of Sen2Cor class dark area to only topographic or cast shadow will solve this confusion.
To furthermore compare the classification performance of Fmask, ATCOR and Sen2Cor, details are given for three selected cases: the best and worst case scenarios and an average case.
Figure 5 shows the best case (highest absolute overall accuracy) scenario of all analyzed scenes from
Table 5. It is scene number 18 from Spain (Barrax) taken on 19 March 2017 with a zenith angle of 22.0
and a azimuth angle of 143.2
. In
Figure 6 subset of scene ID 18 can be found. It nicely illustrates the differences between Fmask, ATCOR and Sen2Cor. The cloud percentage is overestimated in Fmask due to mask dilation, while ATCOR and Sen2Cor classifications are very similar and close to the reference.
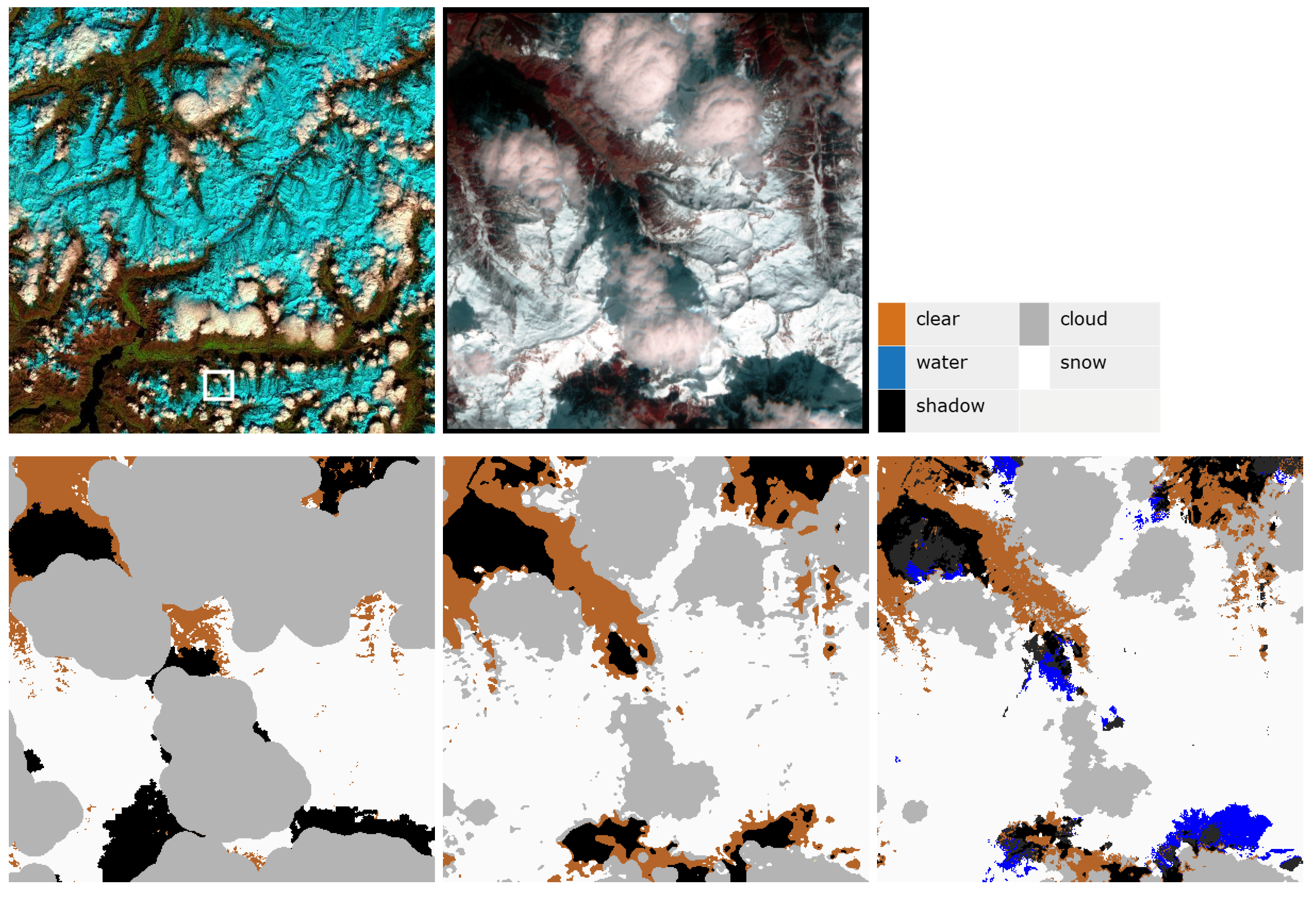
The overall worst case scenario (lowest absolute OA) of the 20 scenes analyzed is illustrated in
Figure 7. This scene from Switzerland (Davos) was acquired on 4 April 2019 at a zenith and azimuth angle of 37.7
and 158.5
, respectively. This scene is difficult to classify correctly for all the processors due to the high reflectivity of the snow and complex topography. The snow is often misclassified as cloud. The lower overall accuracy in Fmask compared to ATCOR and Sen2Cor is again connected with the cloud dilation.
Figure 7 shows a subset of scene ID 19. As in the previous case (scene ID 18 from Spain) Fmask overestimates the percentage of cloud coverage at the expense of snow cover, which may or may not be problematic depending on the application. ATCOR and Sen2Cor show a more accurate cloud mask. An inspection of a zoom area (see
Figure 8) reveals that Sen2Cor sometimes falsely classifies cloud shadows as water.
A scene showing an average case scenario (i.e., no complex topography, small percentage of cloud cover and bright objects) for all classification methods is the one from the USA (Rimrock). It was taken on 12 May 2018 at a zenith angle of 30.4
and an azimuth angle of 153.5
.
Figure 9 shows the entire area of the scene with the three different classification maps, whereas
Figure 10 only illustrates a subset of scene ID 20. Most of the scene is clear with some clouds and snow/ice in the southern part. Additionally, the river is accurately mapped by all processors.
The subset (
Figure 10) demonstrates the difficulties Sen2Cor faces when distinguishing between urban areas or bright ground objects and clouds. ATCOR on the other hand misinterprets dark water for shadow. However, if both classes have about the same probability, then ATCOR’s preference is shadow.
As can be deduced from
Table 4 for the difference area, up to 75.5% of clear pixels were correctly classified by Sen2Cor, whereas Fmask and ATCOR recognize 56.2% and 64.6% correctly. The highest share of clear pixel misclassification was found by clouds for Fmask and Sen2Cor and semitransparent clouds for ATCOR. Semitransparent clouds were recognized up to 30.4% and 28.2% for ATCOR and Sen2Cor, respectively, while the omitted pixels were mainly distributed between classes clear and clouds by ATCOR and clear and snow by Sen2Cor. Fmask only classifies 1.8% of semitransparent cloud pixels correctly and mostly missclassifies the omitted pixels as clouds. Fmask performs best for the classification of cloud pixels (84.5%), while ATCOR and Sen2Cor have a recognition rate of 62.7% and 65.7%, respectively. The highest share of the cloud omission was found by class clear for Fmask and Sen2Cor and by class cloud shadows for ATCOR. Cloud shadows have low recognition rate (27.7%) and high confusion with class clear in the case of Sen2Cor. Fmask and ATCOR have lowest recognition for the class topographic shadows with a rate of 2.2% and 4.1%, respectively. Sen2Cor performs slightly better with 53.0%. Their omission is distributed mainly between classes clear and cloud shadows. The highest recognition rates (and lowest confusion to other classes) were found for clouds (84.5%) and water (68.1%), clear (64.6%) and snow (75.7%) and water (80.3%) and snow pixels (85.7%), for Fmask, ATCOR and Sen2Cor, respectively. Surprisingly, the proportion of snow pixels being mistaken toward clouds was low for ATCOR and Sen2Cor (12% and 8%, respectively), whereas Fmask misclassifies 47%, which is because of the cloud buffer, as well as the compilation of FORCE quality bits into the scene classification as employed in this study. In original FORCE output, multiple flags can be set for one pixel, i.e., the snow and cloud flags can both be set. During the reclassification process, clouds were given highest priority, thus snow detections were overruled by buffered cloud detections.
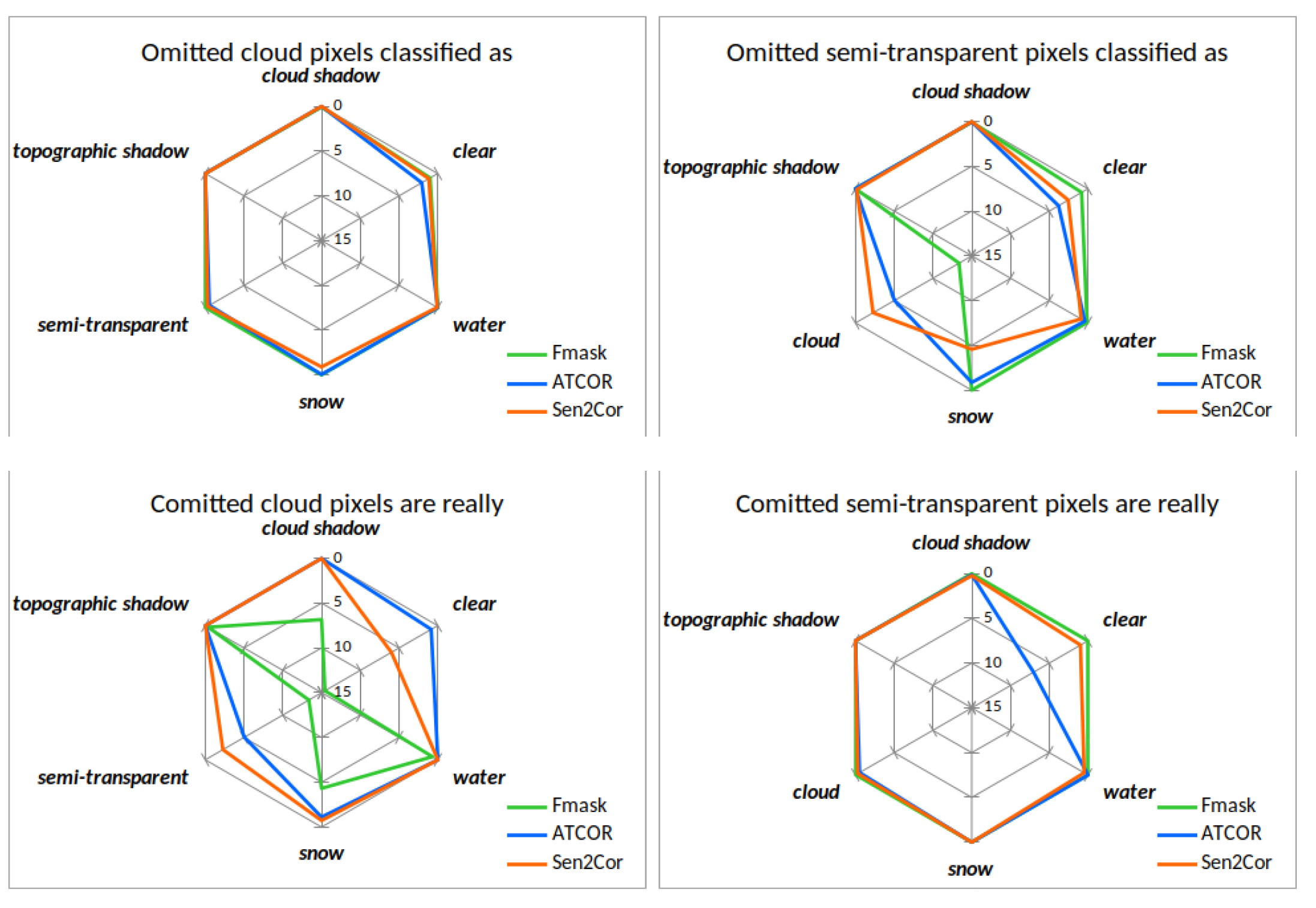
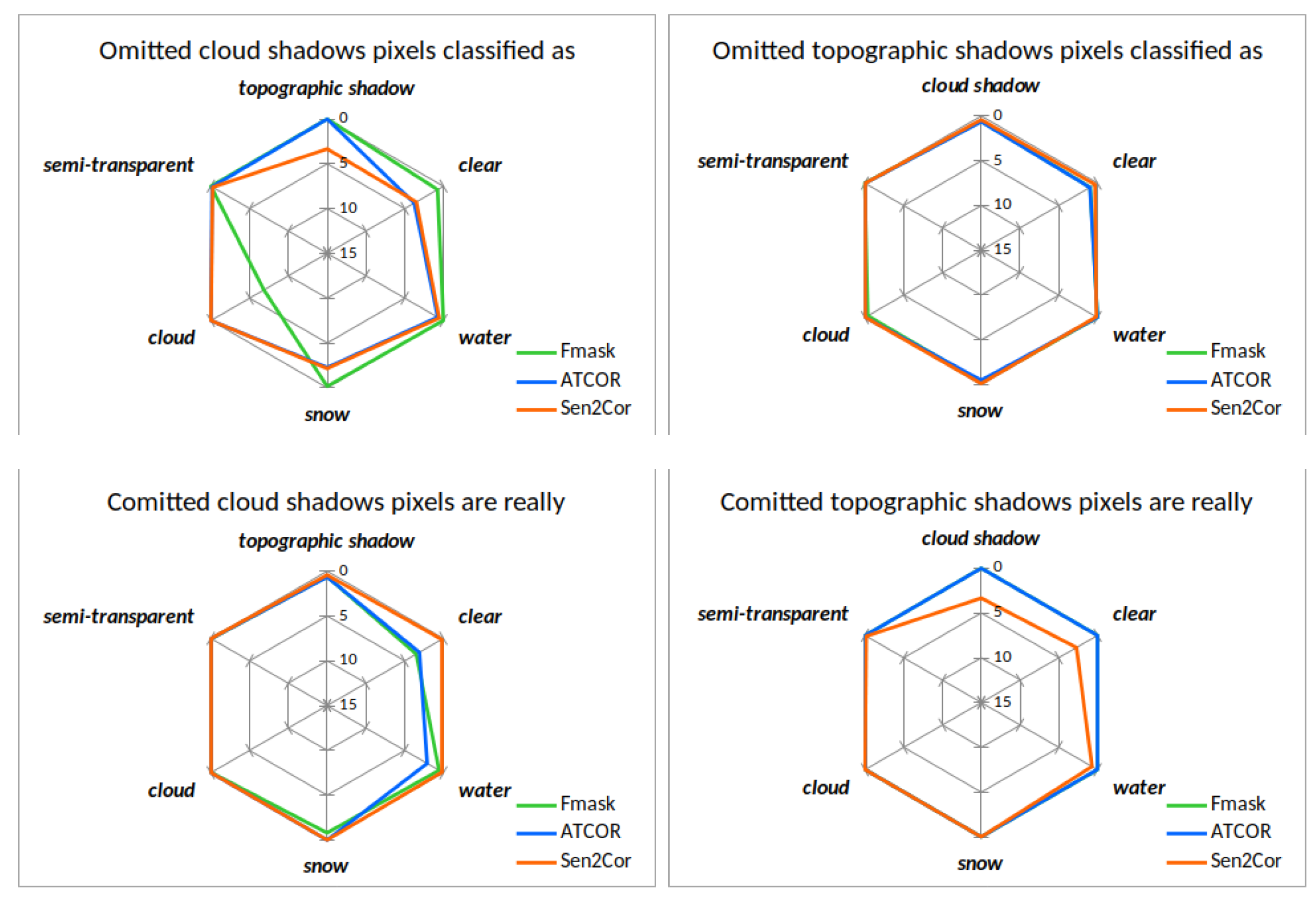
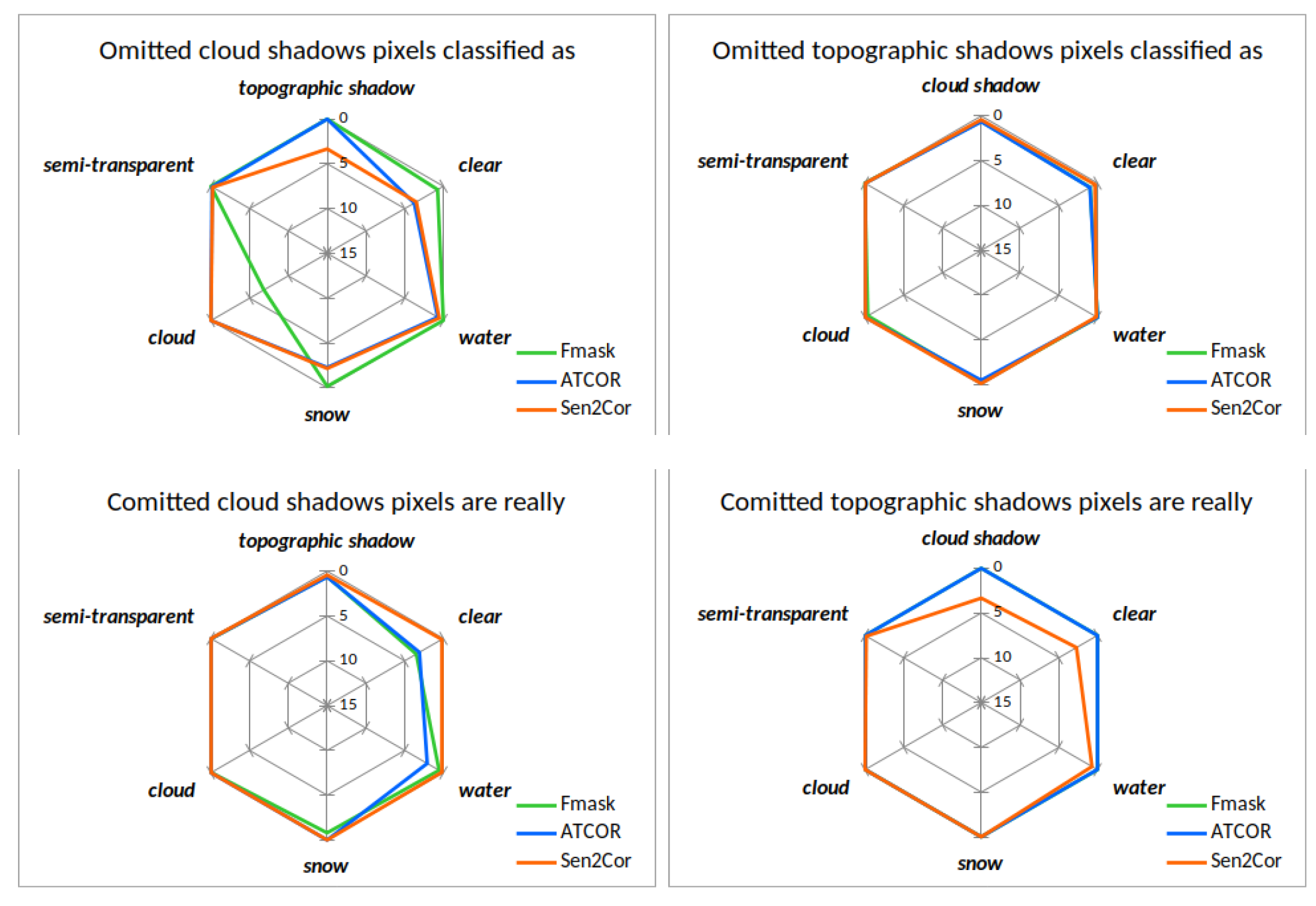
The confusion within and between classes can be additionally illustrated using the proportion of the individual class omissions for the difference area (
Figure 11,
Figure 12 and
Figure 13).
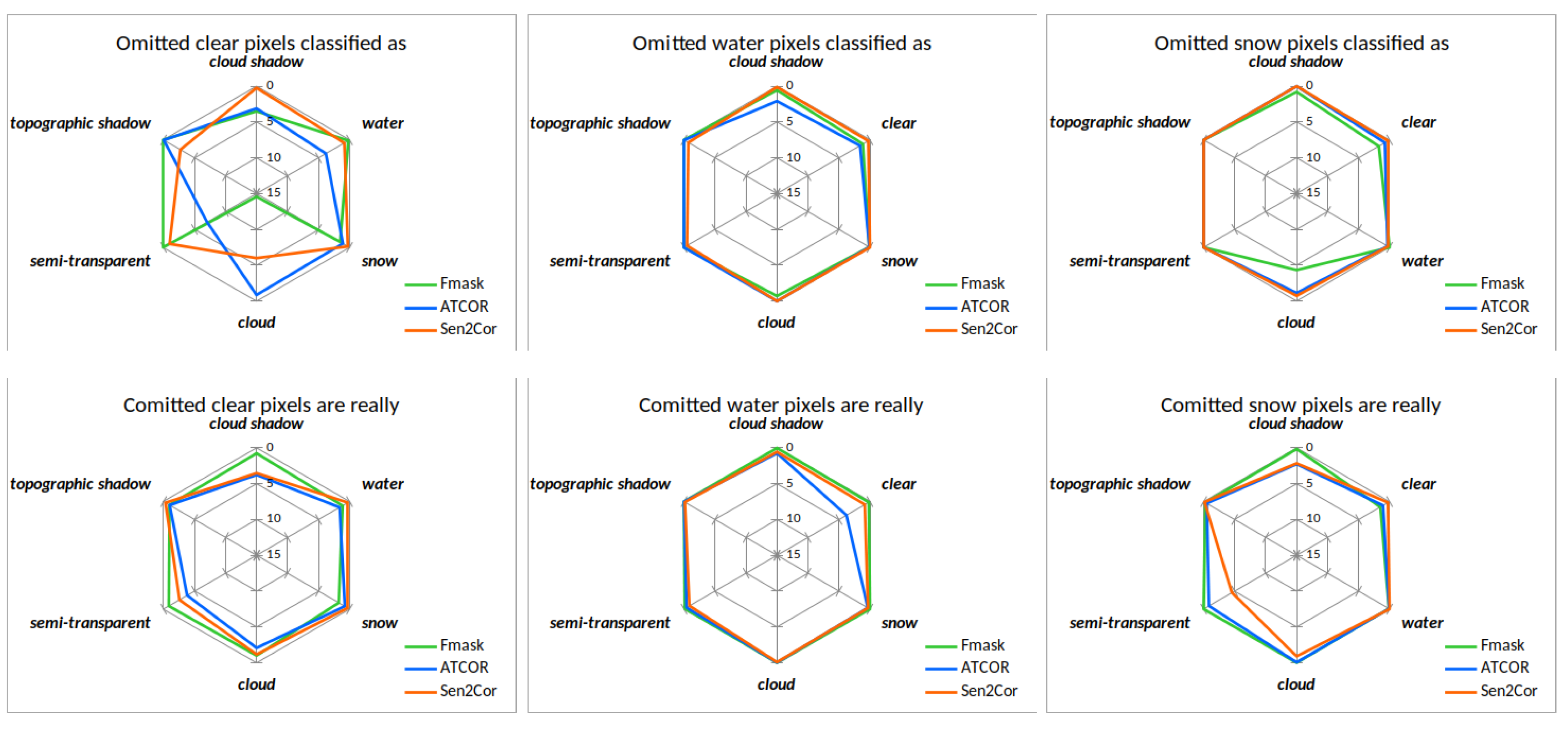
Figure 11 illustrates spider diagrams for the omission and commission of the classes clear land, water and snow representing valid, cloudless pixels. Fmask, ATCOR and Sen2Cor are represented by the colors green, blue and orange. Looking at the left upper plot of
Figure 11, it can be noted that Fmask has a large omission of clear land towards clouds. This can be clearly attributed to cloud dilation. ATCOR has a omission of clear land to water, which is uncritical for pure cloud masking. Sen2Cor confuses most clear land pixels with topographic shadows due to the unfavorable class definition of class dark feature, which is mapped to topographic shadows. In the central lower plot of
Figure 11 we see that ATCOR confuses most water pixels as clear land. All three masking codes show commission of water pixels towards the same direction of clear land but with different amounts. The commission of snow shows that Fmask and ATCOR classifies some clear as snow, which is uncritical for clear/cloud mask. Sen2Cor classifies some semitransparent clouds as snow.
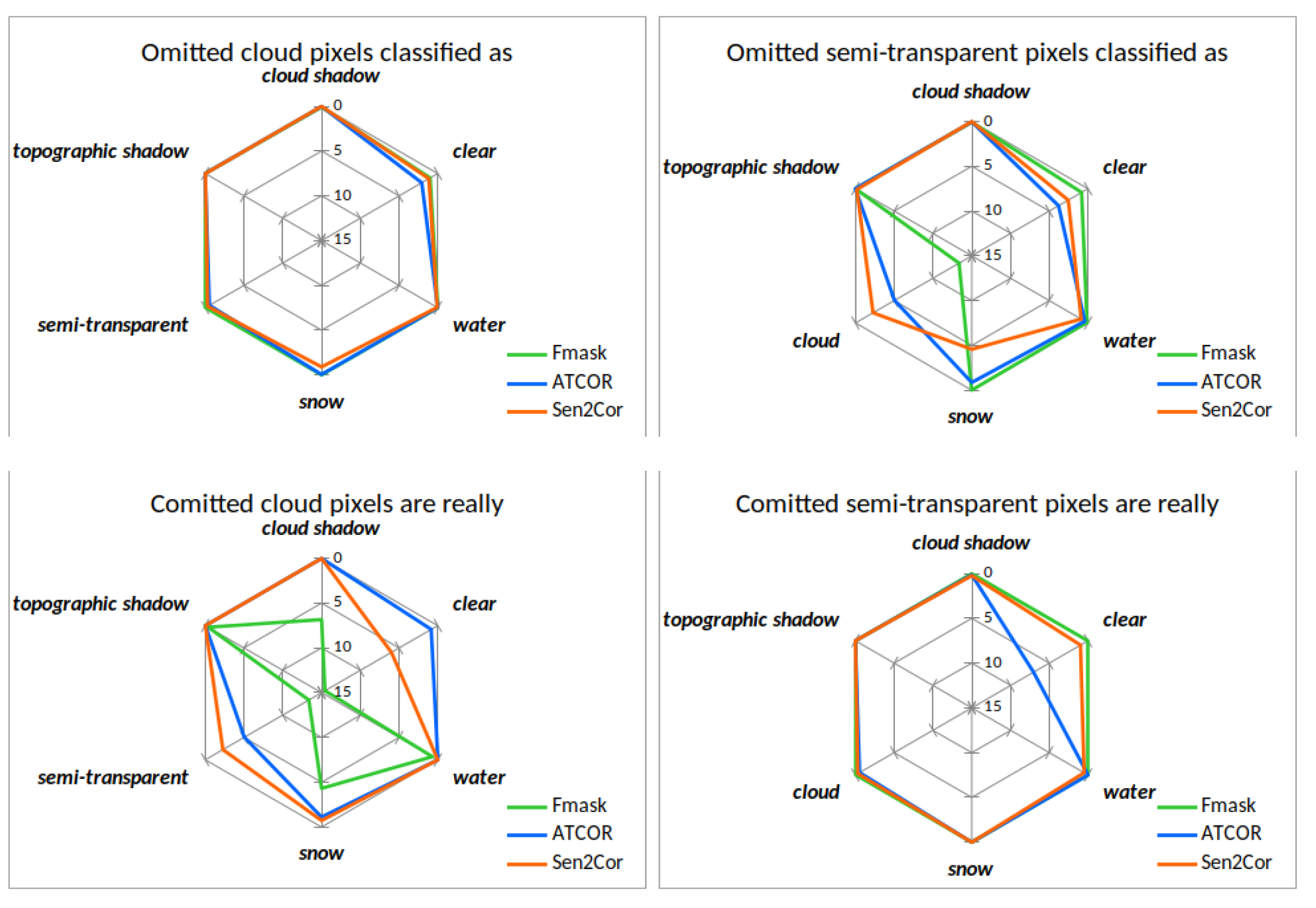
Figure 12 illustrates spider diagrams for the omission and commission of the classes cloud and semitransparent cloud for difference area. The upper left image shows that ATCOR and Sen2Cor have omission of cloud pixels towards the class clear. The commission of cloud is on the other hand different for all three masking codes. Fmask shows the largest commission of cloud pixels towards clear, semitransparent cloud and cloud shadow. Sen2Cor classifies some clear and semitransparent pixels as cloud and ATCOR shows a slight commission of semitransparent pixels towards cloud. For the class semitransparent cloud, the largest omission comes from Fmask, which confuses most semitransparent clouds as cloud. This perfectly corresponds to commission of cloudy pixels towards semitransparent clouds. ATCOR and Sen2Cor show a commission of semitransparent pixels towards the class clear.
Figure 13 illustrates spider diagrams for the omission and commission for difference area of the shadow classes cloud shadows and topographic shadows. From the left upper image of
Figure 13 it can be noted that Fmask has the largest omission of cloud shadow towards the class cloud. ATCOR and Sen2Cor confuse cloud shadows mostly with clear pixels. All three masking codes show a similar direction of commission of cloud shadows towards clear pixels. Except for the class definition problem of Sen2Cor for topographic shadows, the upper and lower right images show good agreement between the processors and almost perfect performance. Sen2Cor shows a large commission of topographic shadow pixels towards the class clear, water and cloud shadow due to its definition of dark pixels.
5. Discussion
Since the reference and classified maps are based on the same dataset, i.e., a perfect match of geometry and acquisition time, the main uncertainty of the reference map classification is the use of a human interpreter [
29]. Experiences with similar experiments using several human analysts report an average interpretation variability of ∼5–7% [
16,
32] for cloud masks. In order to reduce the influence of the interpreter, a reference polygon should have homogeneous BOA reflectance properties per class, i.e., heterogeneous areas with mixed pixels are excluded [
30]. The area homogeneity can be checked visually per band and it also shows if pixel spectra of a polygon have a large dispersion, e.g., for cloud border regions or snow areas below semitransparent cloud. Although the variability within a polygon should be small, large differences can exist between different polygons of the same class, e.g., in the case of different cloud types or fresh and polluted snow.
Table 4 presents the class-specific
user’s accuracy (UA) and
producer’s accuracy (PA) for the three methods averaged over the 20 scenes valid for difference area. High PA values (>80%) are only achieved for the classes cloud (Fmask) and snow/ice (Sen2Cor) indicating how difficult a classification is for all other classes. The low values for semitransparent cloud are most likely caused by the interpreter and his visual assessment, which does not agree with the selected physical criterion (0.01 <
(TOA, 1.38
m) < 0.04) of the three methods. Another known classification problem concerns the distinction of water and cloud shadow if no external maps are included. Both classes can be spectrally very similar. Additionally, there can be cloud shadow over water, but since a pixel can only belong to one class in our evaluation, the setting of the preference rule adds another uncertainty.
Nevertheless, a comparison with S2 classification results obtained by the standard Fmask [
15] (applied to seven scenes) demonstrates that, in our investigation, all three methods yield better overall accuracies than presented in reference [
15] (
Figure 6). This is even more remarkable because our approach uses six classes instead of four, and an increase of the number of classes usually tends to decrease the overall accuracy. One has to consider that the spatial resolution of Sentinel-2 data is 20 m, while it is 30 m for the Landsat data of reference [
15]. A better classification agreement might, at least partly, be achieved by the enhanced Sentinel-2 resolution. However, while a higher spatial resolution can help to achieve a better classification, this is mainly related to mixed pixels, and in our study heterogeneous areas with mixed pixels are excluded.
Table 5 allows a selection of the best method depending on location and cloud cover:
Fmask can best be applied for scenes in moderate climate, excluding arid and desert regions as well as areas with a large snow/ice coverage.
ATCOR can best be applied for urban (bright surfaces), arid and desert scenes.
Sen2Cor can best be applied for rural scenes in moderate climate and also in scenes with snow and cloud.
Again, a reminder is needed: the Fmask results shown here pertain to the Fmask parallax version [
17] not the available standard version [
15]. Furthermore, Sen2Cor uses an additional external ESACCI-LC data package, which improves the classification accuracy over water, urban and bare areas and enables a better handling of false detection of snow pixels [
33]. Therefore, Sen2Cor benefits from a certain advantage compared to Fmask and ATCOR. During this investigation we also found out that the performance of Fmask (parallax version) can be improved if the current cloud buffer size of 300 m is reduced to 100 m. In the meantime, the size of the cloud buffer has become a user-defined parameter. The performance of Sen2Cor (version 2.8.0) can be slightly improved with an additional cloud buffer of 100 m (instead of no buffer), whereas an additional 100 m cloud buffer is almost of no influence on the ATCOR performance.
To sum up, we can say that the overall accuracy is very high for all three masking codes and nearly the same (89%, 91% and 92% for Fmask, ATCOR and Sen2Cor, respectively) and the balanced OA (OA for same area) is equal (97%). ATCOR finds most valid pixels, has the highest PA and lowest UA for valid pixels. Sen2Cor finds less valid pixels due to its class definition of dark area. Fmask finds least valid pixels due to dilation of cloud masks, thus not a randomly occurring commission. In contrast, Fmask has the lowest cloud omission and clear commission at the expense of higher cloud commission and clear omission. Depending on application, losing a higher rate of cloud-adjacent pixels may be far less severe than missing cloud pixels.
6. Conclusions
The performance of three classification methods (Fmask, parallax version), ATCOR and Sen2Cor was evaluated on a set of 20 Sentinel-2 scenes covering all continents, different climates, seasons and environments. The reference maps with seven classes (clear, semitransparent cloud, cloud, cloud shadow, water, snow/ice and topographic shadows) were created by an experienced human interpreter. The average overall accuracy for the absolute area is 89%, 91%, and 92% for Fmask, ATCOR, and Sen2Cor, respectively. High values of producer’s accuracy of the difference area (>80%) were achieved for cloud and snow/ice, and lower values for the other classes typically range between 30% and 70%. This study can serve as a guide to learn more about possible pitfalls and achieve more accurate algorithms. Future improvements for the classification algorithms could involve texture measures and convolutional neural networks.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}