Figure 1.
Multi-Pedestrian tracking results of AerialMPTNet on the frame 18 of the “Munich02” (left) and frame 10 of the “Bauma3” (right) sequences of the AerialMPT dataset. Different pedestrians are depicted in different colors with the corresponding trajectories.
Figure 1.
Multi-Pedestrian tracking results of AerialMPTNet on the frame 18 of the “Munich02” (left) and frame 10 of the “Bauma3” (right) sequences of the AerialMPT dataset. Different pedestrians are depicted in different colors with the corresponding trajectories.
Figure 2.
Illustrations of some challenges in aerial MOT datasets. The examples are from the KIT AIS pedestrian (a), AerialMPT (b), and KIT AIS vehicle datasets (c,d). Multiple pedestrians which are hard to distinguish due to their similar appearance features and low image contrast (a). Multiple pedestrians at a trade fair walking closely together with occlusions, shadows, and strong background colors (b). Multiple vehicles at a stop light where the shadow on the right hand side can be problematic (c). Multiple vehicles with some of them occluded by trees (d).
Figure 2.
Illustrations of some challenges in aerial MOT datasets. The examples are from the KIT AIS pedestrian (a), AerialMPT (b), and KIT AIS vehicle datasets (c,d). Multiple pedestrians which are hard to distinguish due to their similar appearance features and low image contrast (a). Multiple pedestrians at a trade fair walking closely together with occlusions, shadows, and strong background colors (b). Multiple vehicles at a stop light where the shadow on the right hand side can be problematic (c). Multiple vehicles with some of them occluded by trees (d).
Figure 3.
Sample images from the KIT AIS vehicle dataset acquired at different locations in Munich and Stuttgart, Germany.
Figure 3.
Sample images from the KIT AIS vehicle dataset acquired at different locations in Munich and Stuttgart, Germany.
Figure 4.
Sample images from the AerialMPT and KIT AIS datasets. “Bauma3”, “Witt”, “Pasing1” are from AerialMPT. “Entrance_01”, “Walking_02”, and “Munich02” are from KIT AIS.
Figure 4.
Sample images from the AerialMPT and KIT AIS datasets. “Bauma3”, “Witt”, “Pasing1” are from AerialMPT. “Entrance_01”, “Walking_02”, and “Munich02” are from KIT AIS.
Figure 5.
Example images of the DLR-ACD dataset. The images are from an open-air (a) festival (b) and music concert.
Figure 5.
Example images of the DLR-ACD dataset. The images are from an open-air (a) festival (b) and music concert.
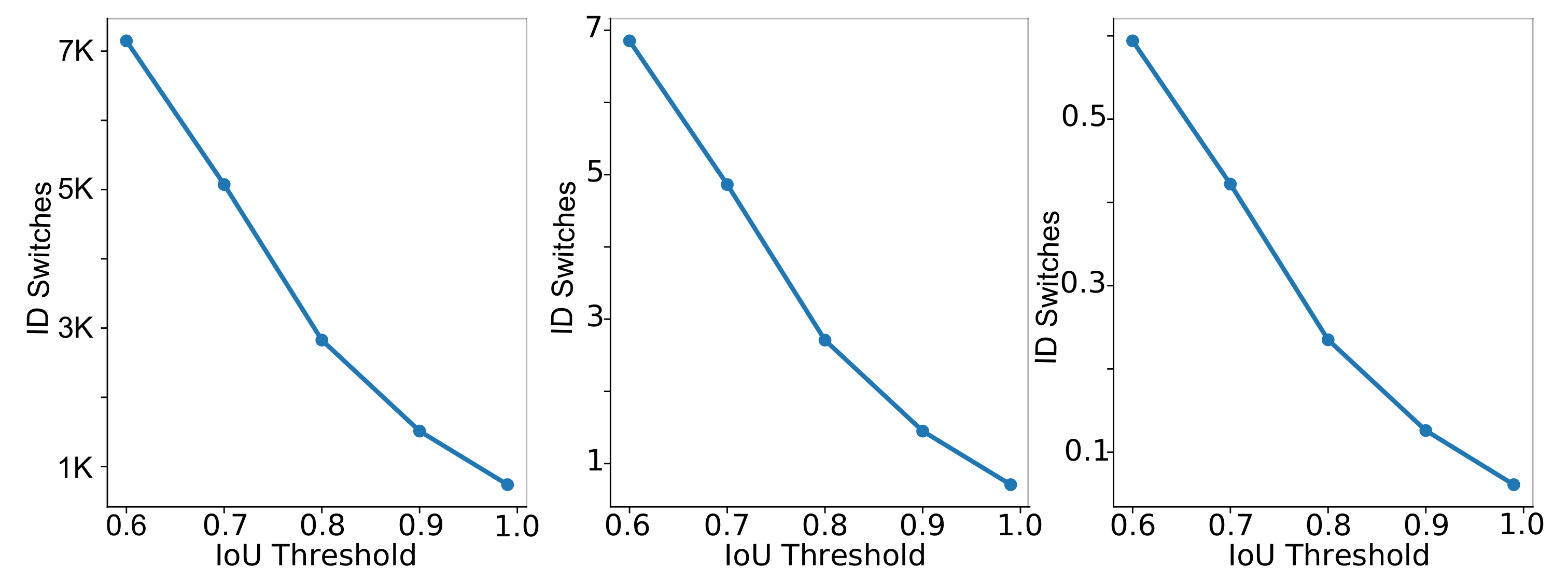
Figure 6.
ID Switches versus IoU thresholds in DeepSORT. From left to right: total, average per person, and average per detection ID Switches.
Figure 6.
ID Switches versus IoU thresholds in DeepSORT. From left to right: total, average per person, and average per detection ID Switches.
Figure 7.
A success case processed by Stacked-DCFNet on the sequence “Munich02”. The tracking results and ground truth are depicted in green and black, respectively.
Figure 7.
A success case processed by Stacked-DCFNet on the sequence “Munich02”. The tracking results and ground truth are depicted in green and black, respectively.
Figure 8.
A failure case by Stacked-DCFNet on the sequence “AA_Walking_02”. The tracking results and ground truth are depicted in green and black, respectively.
Figure 8.
A failure case by Stacked-DCFNet on the sequence “AA_Walking_02”. The tracking results and ground truth are depicted in green and black, respectively.
Figure 9.
A success case by Stacked-DCFNet on the sequence “AA_Crossing_02”. The tracking results and ground truth are depicted in green and black, respectively.
Figure 9.
A success case by Stacked-DCFNet on the sequence “AA_Crossing_02”. The tracking results and ground truth are depicted in green and black, respectively.
Figure 10.
A failure case by Stacked-DCFNet on the test sequence “RaR_Snack_Zone_04”. The tracking results and the ground truth are depicted in green and black, respectively.
Figure 10.
A failure case by Stacked-DCFNet on the test sequence “RaR_Snack_Zone_04”. The tracking results and the ground truth are depicted in green and black, respectively.
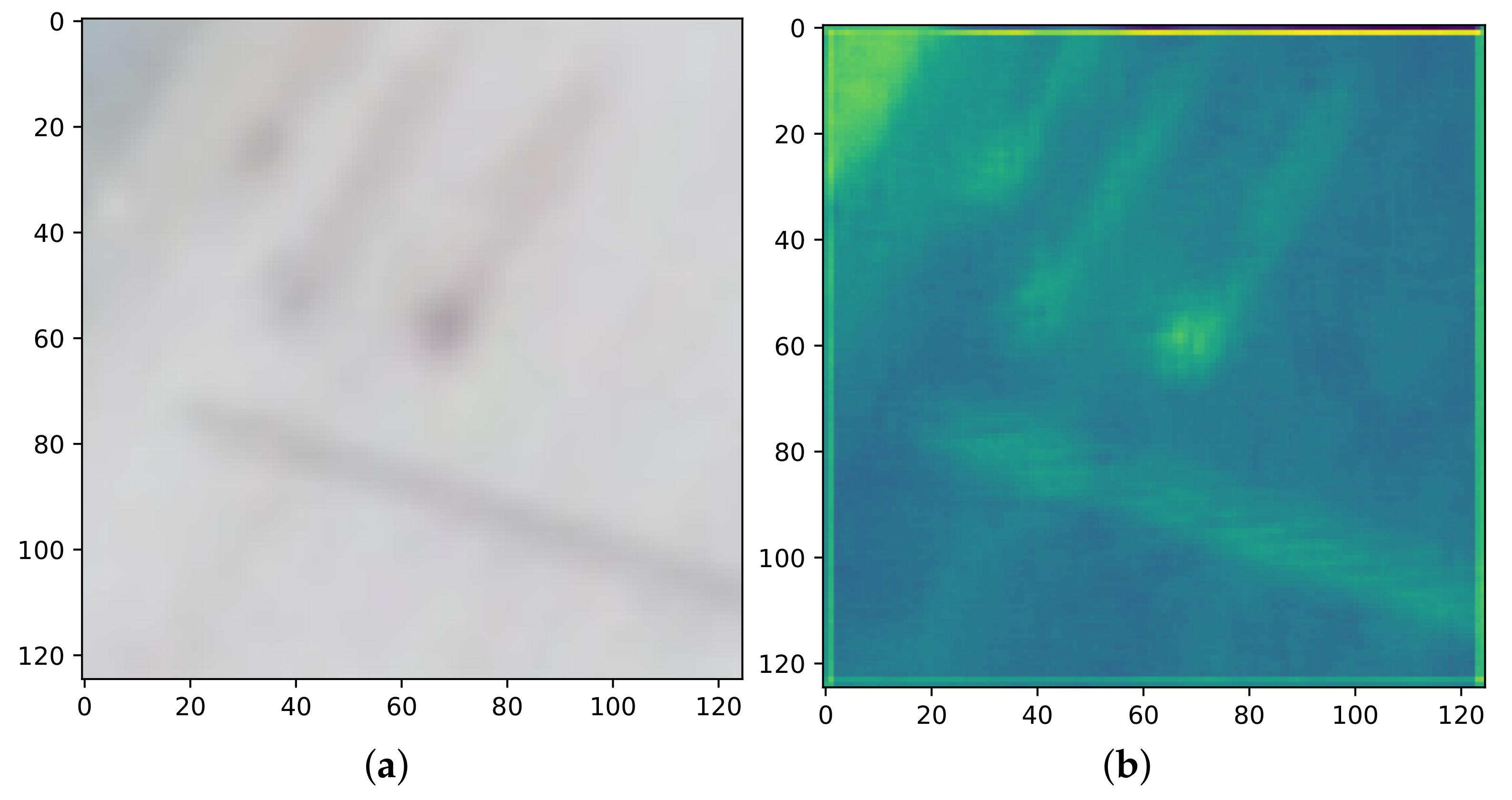
Figure 11.
(a) An input image patch to the last convolutional layer of Stacked-DCFNetand and (b) its corresponding activation map.
Figure 11.
(a) An input image patch to the last convolutional layer of Stacked-DCFNetand and (b) its corresponding activation map.
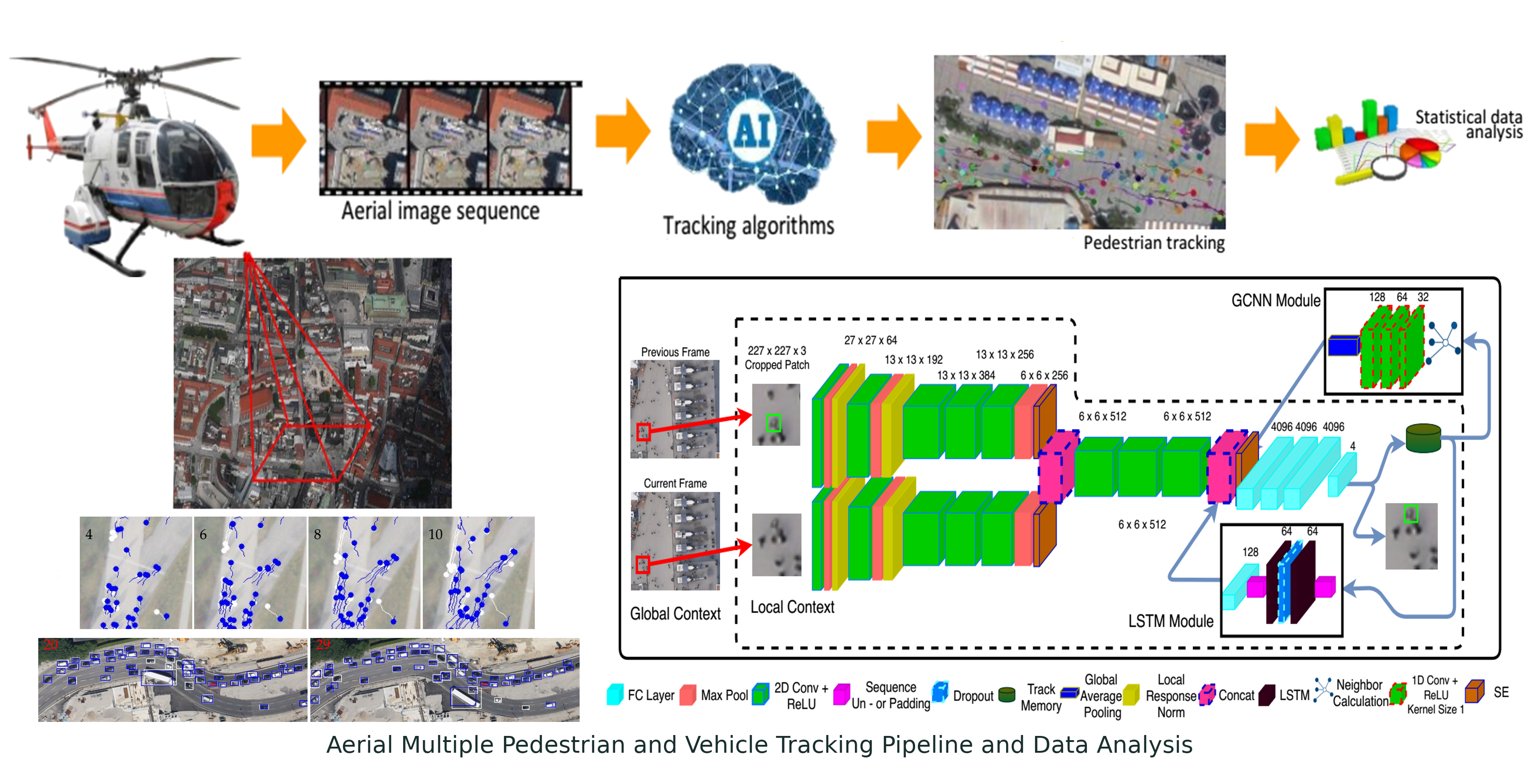
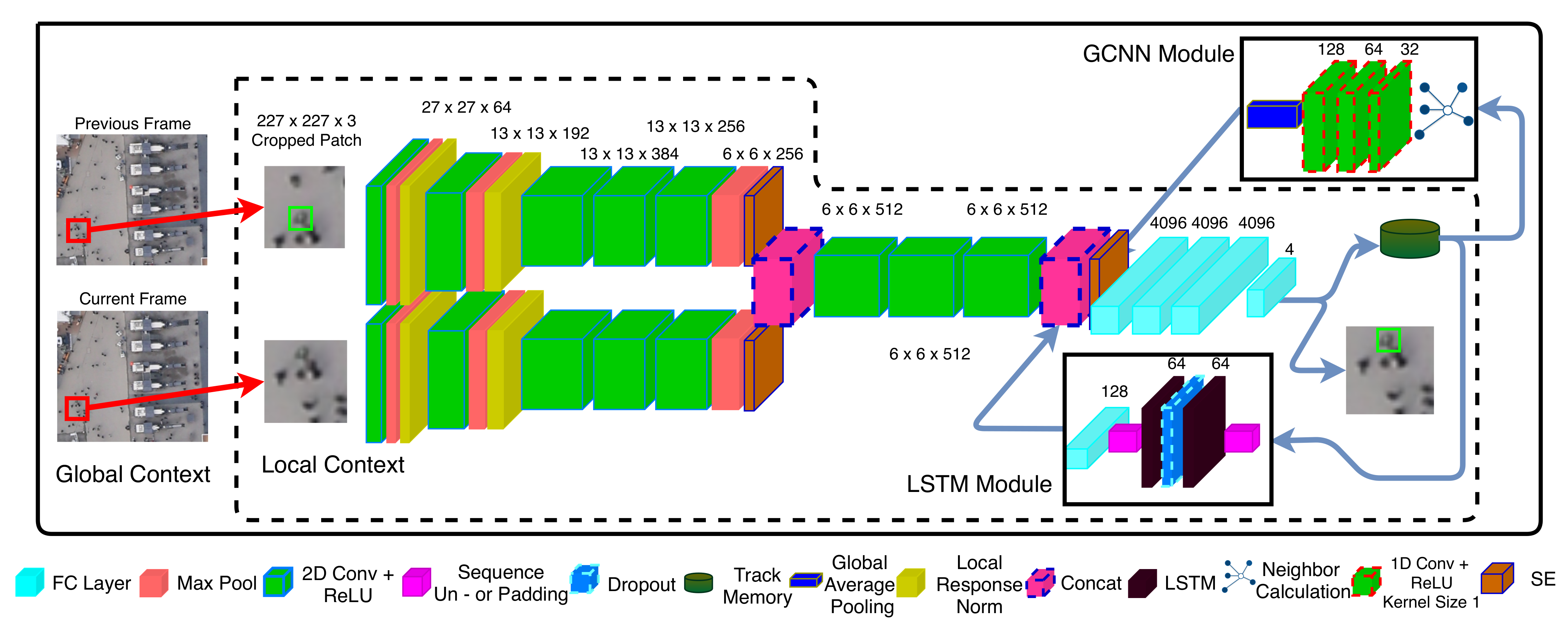
Figure 12.
Overview of the network’s architecture composing a SNN, a LSTM and a GraphCNN module. The inputs are two consecutive images cropped and centered to a target object, while the output is the object location in search crop coordinates.Overview of AerialMPTNet’s architecture.
Figure 12.
Overview of the network’s architecture composing a SNN, a LSTM and a GraphCNN module. The inputs are two consecutive images cropped and centered to a target object, while the output is the object location in search crop coordinates.Overview of AerialMPTNet’s architecture.
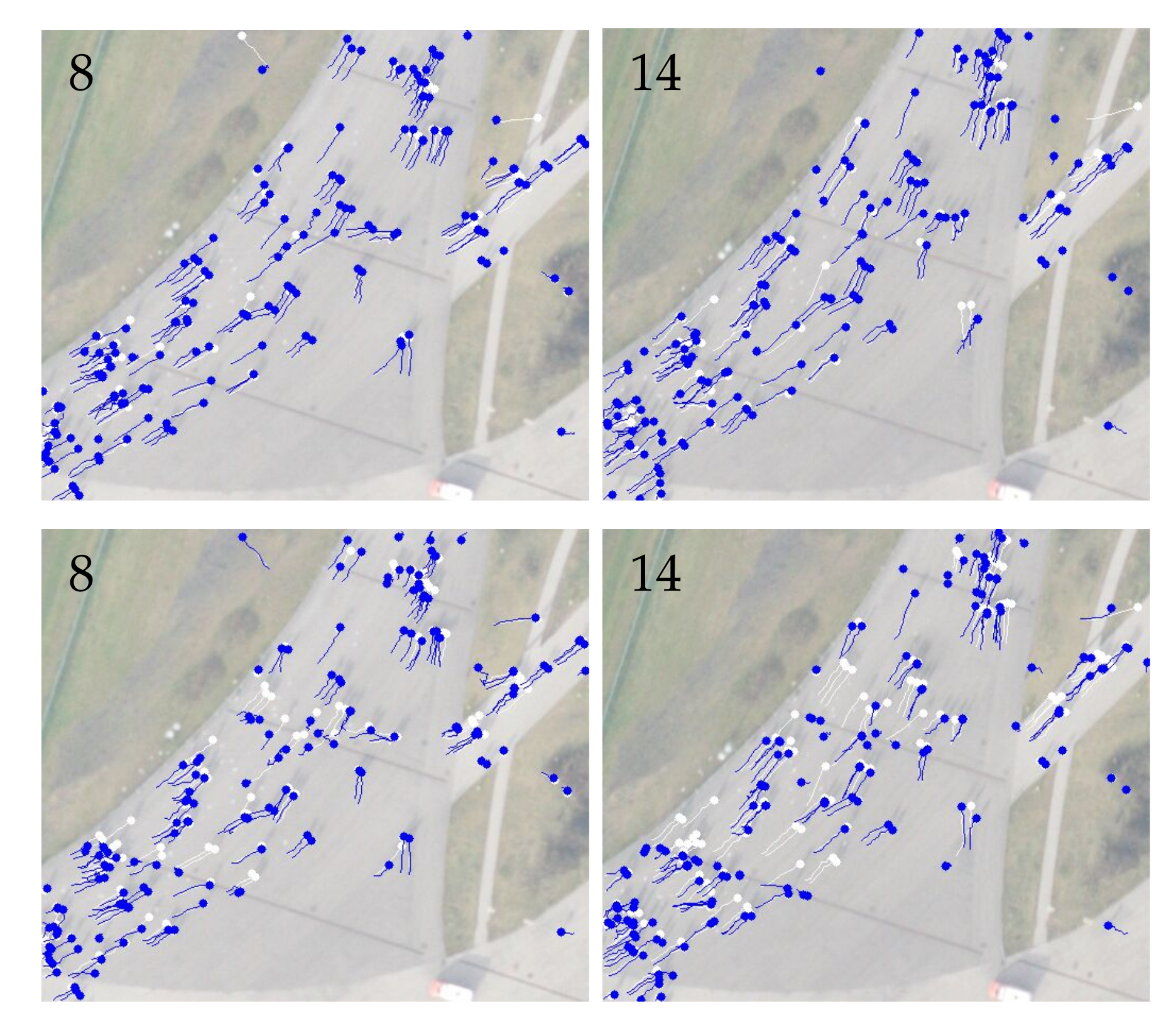
Figure 13.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 8 and 14 of the “AA_Walking_ 02” sequence of the KIT AIS pedestrian dataset. The predictions and ground truth are depicted in blue and white, respectively.
Figure 13.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 8 and 14 of the “AA_Walking_ 02” sequence of the KIT AIS pedestrian dataset. The predictions and ground truth are depicted in blue and white, respectively.
Figure 14.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 4, 6, 8, and 10 of the “AA_Crossing_02” sequence of the KIT AIS pedestrian dataset. The predictions and ground truth are depicted in blue and white, respectively.
Figure 14.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 4, 6, 8, and 10 of the “AA_Crossing_02” sequence of the KIT AIS pedestrian dataset. The predictions and ground truth are depicted in blue and white, respectively.
Figure 15.
Tracking results by the AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 11, 13, 15, and 17 of the “Pasing8” sequence of the AerialMPT dataset. The predictions and ground truth are depicted in blue and white, respectively.
Figure 15.
Tracking results by the AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 11, 13, 15, and 17 of the “Pasing8” sequence of the AerialMPT dataset. The predictions and ground truth are depicted in blue and white, respectively.
Figure 16.
Tracking results by the AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 21, 23, 25, and 27 of the “Karlsplatz” sequence of the AerialMPT dataset. The predictions and ground truth are depicted in blue and white, respectively.
Figure 16.
Tracking results by the AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 21, 23, 25, and 27 of the “Karlsplatz” sequence of the AerialMPT dataset. The predictions and ground truth are depicted in blue and white, respectively.
Figure 17.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 3 and 6 of the “Witt” sequence of the AerialMPT dataset. The predictions and ground truth are depicted in blue and white, respectively.
Figure 17.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 3 and 6 of the “Witt” sequence of the AerialMPT dataset. The predictions and ground truth are depicted in blue and white, respectively.
Figure 18.
Tracking results by AerialMPTNet on the frames 4 and 31 of the “MunichCrossroad02” sequence of the KIT AIS vehicle dataset. The predictions and ground truth bounding boxes are depicted in blue and white, respectively. Several hindrances such as changing viewing angle, shadows, and occlusions (e.g., by trees) are visible.
Figure 18.
Tracking results by AerialMPTNet on the frames 4 and 31 of the “MunichCrossroad02” sequence of the KIT AIS vehicle dataset. The predictions and ground truth bounding boxes are depicted in blue and white, respectively. Several hindrances such as changing viewing angle, shadows, and occlusions (e.g., by trees) are visible.
Figure 19.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 2 and 8 of the “MunichCrossroad02” sequence of the KIT AIS vehicle dataset. The predictions and ground truth bounding boxes are depicted in blue and white, respectively.
Figure 19.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 2 and 8 of the “MunichCrossroad02” sequence of the KIT AIS vehicle dataset. The predictions and ground truth bounding boxes are depicted in blue and white, respectively.
Figure 20.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 20 and 29 of the “MunichStreet04” sequence of the KIT AIS vehicle dataset. The predictions and ground truth bounding boxes are depicted in blue and white, respectively.
Figure 20.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 20 and 29 of the “MunichStreet04” sequence of the KIT AIS vehicle dataset. The predictions and ground truth bounding boxes are depicted in blue and white, respectively.
Figure 21.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 1 and 7 of the “MunichStreet02” sequence of the KIT AIS vehicle dataset. The predictions and ground truth bounding boxes are depicted in blue and white, respectively.
Figure 21.
Tracking results by AerialMPTNet (top row) and SMSOT-CNN (bottom row) on the frames 1 and 7 of the “MunichStreet02” sequence of the KIT AIS vehicle dataset. The predictions and ground truth bounding boxes are depicted in blue and white, respectively.
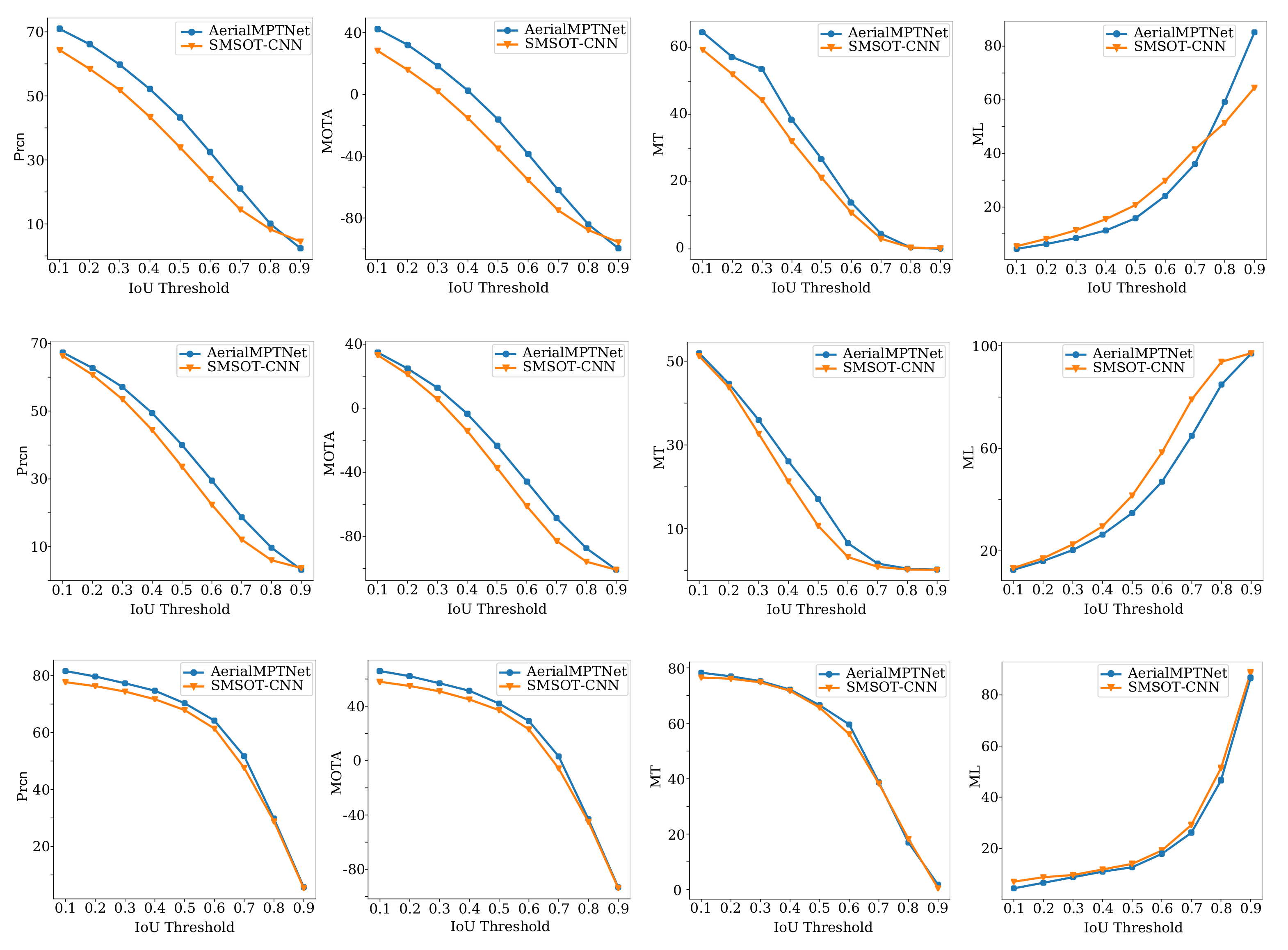
Figure 22.
Comparing the Prcn, MOTA, MT, and ML of the AerialMPTNet and SMSOT-CNN on the KIT AIS pedestrian (first row), AerialMPT (second row), and KIT AIS vehicle (third row) datasets by changing the IoU thresholds of the evaluation metrics.
Figure 22.
Comparing the Prcn, MOTA, MT, and ML of the AerialMPTNet and SMSOT-CNN on the KIT AIS pedestrian (first row), AerialMPT (second row), and KIT AIS vehicle (third row) datasets by changing the IoU thresholds of the evaluation metrics.
Figure 23.
Ranking the tracking methods based on their MOTA and MOTP values on the (a) KIT AIS pedestrian, (b) AerialMPT, and (c) KIT AIS vehicle datasets.
Figure 23.
Ranking the tracking methods based on their MOTA and MOTP values on the (a) KIT AIS pedestrian, (b) AerialMPT, and (c) KIT AIS vehicle datasets.
Table 1.
Statistics of the KIT AIS pedestrian dataset.
Table 1.
Statistics of the KIT AIS pedestrian dataset.
| Train |
|---|
| Seq. | Image Size | #Fr. | #Pedest. | #Anno. | #Anno./Fr. | GSD |
| AA_Crossing_01 | 309 × 487 | 18 | 164 | 2618 | 145.4 | 15.0 |
| AA_Easy_01 | 161 × 168 | 14 | 8 | 112 | 8.0 | 15.0 |
| AA_Easy_02 | 338 × 507 | 12 | 16 | 185 | 15.4 | 15.0 |
| AA_Easy_Entrance | 165 × 125 | 19 | 83 | 1105 | 58.3 | 15.0 |
| AA_Walking_01 | 227 × 297 | 13 | 40 | 445 | 34.2 | 15.0 |
| Munich01 | 509 × 579 | 24 | 100 | 1308 | 54.5 | 12.0 |
| RaR_Snack_Zone_01 | 443 × 535 | 4 | 237 | 930 | 232.5 | 15.0 |
| Total | 104 | 633 | 6703 | 64.4 | |
| Test |
| AA_Crossing_02 | 322 × 537 | 13 | 94 | 1135 | 87.3 | 15.0 |
| AA_Entrance_01 | 835 × 798 | 16 | 973 | 14,031 | 876.9 | 15.0 |
| AA_Walking_02 | 516 × 445 | 17 | 188 | 2671 | 157.1 | 15.0 |
| Munich02 | 702 × 790 | 31 | 230 | 6125 | 197.6 | 12.0 |
| RaR_Snack_Zone_02 | 509 × 474 | 4 | 220 | 865 | 216.2 | 15.0 |
| RaR_Snack_Zone_04 | 669 × 542 | 4 | 311 | 1230 | 307.5 | 15.0 |
| Total | 85 | 2016 | 26,057 | 306.5 | |
Table 2.
Statistics of the KIT AIS vehicle dataset.
Table 2.
Statistics of the KIT AIS vehicle dataset.
| Train |
|---|
|
Seq.
| Image Size | #Fr.
| #Vehic.
| #Anno.
| #Anno./Fr.
| GSD
|
| MunichAutobahn1 | 633 × 988 | 16 | 16 | 161 | 10.1 | 15.0 |
| MunichCrossroad1 | 684 × 547 | 20 | 30 | 509 | 25.5 | 12.0 |
| MunichStreet1 | 1764 × 430 | 25 | 57 | 1338 | 53.5 | 12.0 |
| MunichStreet3 | 1771 × 422 | 47 | 88 | 3071 | 65.3 | 12.0 |
| StuttgartAutobahn1 | 767 × 669 | 23 | 43 | 764 | 33.2 | 17.0 |
| Total | 131 | 234 | 5843 | 44.6 | |
| Test |
| MunichCrossroad2 | 895 × 1036 | 45 | 66 | 2155 | 47.9 | 12.0 |
| MunichStreet2 | 1284 × 377 | 20 | 47 | 746 | 37.3 | 12.0 |
| MunichStreet4 | 1284 × 388 | 29 | 68 | 1519 | 52.4 | 12.0 |
| StuttgartCrossroad1 | 724 × 708 | 14 | 49 | 554 | 39.6 | 17.0 |
| Total | 108 | 230 | 4974 | 46.1 | |
Table 3.
Statistics of the AerialMPT dataset.
Table 3.
Statistics of the AerialMPT dataset.
| Train |
|---|
| Seq.
| Image Size
| #Fr.
| #Pedest.
| #Anno.
| #Anno./Fr.
| GSD
|
| Bauma1 | 462 × 306 | 19 | 270 | 4448 | 234.1 | 11.5 |
| Bauma2 | 310 × 249 | 29 | 148 | 3627 | 125.1 | 11.5 |
| Bauma4 | 281 × 243 | 22 | 127 | 2399 | 109.1 | 11.5 |
| Bauma5 | 281 × 243 | 17 | 94 | 1410 | 82.9 | 11.5 |
| Marienplatz | 316 × 355 | 30 | 215 | 5158 | 171.9 | 10.5 |
| Pasing1L | 614 × 366 | 28 | 100 | 2327 | 83.1 | 10.5 |
| Pasing1R | 667 × 220 | 16 | 86 | 1196 | 74.7 | 10.5 |
| OAC | 186 × 163 | 18 | 92 | 1287 | 71.5 | 8.0 |
| Total | 179 | 1132 | 21,852 | 122.1 | |
| Test |
| Bauma3 | 611 × 552 | 16 | 609 | 8788 | 549.2 | 11.5 |
| Bauma6 | 310 × 249 | 26 | 270 | 5314 | 204.4 | 11.5 |
| Karlsplatz | 283 × 275 | 27 | 146 | 3374 | 125.0 | 10.0 |
| Pasing7 | 667 × 220 | 24 | 103 | 2064 | 86.0 | 10.5 |
| Pasing8 | 614 × 366 | 27 | 83 | 1932 | 71.6 | 10.5 |
| Witt | 353 × 1202 | 8 | 185 | 1416 | 177.0 | 13.0 |
| Total | 128 | 1396 | 22,888 | 178.8 | |
Table 4.
Description of the metrics used for quantitative evaluations.
Table 4.
Description of the metrics used for quantitative evaluations.
| Metric | | Description |
|---|
| IDF1 | ↑ | ID F1-Score |
| IDP | ↑ | ID Global Min-Cost Precision |
| IDR | ↑ | ID Global Min-Cost Recall |
| Rcll | ↑ | Recall |
| Prcn | ↑ | Precision |
| FAR | ↓ | False Acceptance Rate |
| MT | ↑ | Ratio of Mostly Tracked Objects |
| PT | ↑ | Ratio of Partially Tracked Objects |
| ML | ↓ | Ratio of Mostly Lost Objects |
| FP | ↓ | False Positives |
| FN | ↓ | False Negatives |
| IDS | ↓ | Number of Identity Switches |
| FM | ↓ | Number of Fragmented Tracks |
| MOTA | ↑ | Multiple Object Tracker Accuracy |
| MOTP | ↑ | Multiple Object Tracker Precision |
| MOTAL | ↑ | Multiple Object Tracker Accuracy Log |
Table 5.
Results of KCF, MOSSE, CSRT, Median Flow, and Stacked-DCFNet on the KIT AIS pedestrian dataset. The first and second best values are highlighted.
Table 5.
Results of KCF, MOSSE, CSRT, Median Flow, and Stacked-DCFNet on the KIT AIS pedestrian dataset. The first and second best values are highlighted.
| Methods | IDF1↑ | IDP↑ | IDR↑ | Rcll↑ | Prcn↑ | FAR↓ | MT%↑ | PT%↑ | ML%↓ | FP↓ | FN↓ | IDS↓ | FM↓ | MOTA↑ | MOTP↑ | MOTAL↑ |
|---|
| KCF | 9.0 | 8.8 | 9.3 | 10.3 | 9.8 | 165.6 | 1.1 | 53.8 | 45.1 | 11,426 | 10,782 | 32 | 116 | −84.9 | 87.2 | −84.7 |
| MOSSE | 9.1 | 8.9 | 9.3 | 10.5 | 10.0 | 163.8 | 0.8 | 54.0 | 45.2 | 11,303 | 10,765 | 31 | 133 | −85.8 | 86.7 | −83.5 |
| CSRT | 16.0 | 16.9 | 15.2 | 17.5 | 19.4 | 126.5 | 9.6 | 51.0 | 39.4 | 8732 | 9924 | 91 | 254 | −55.9 | 78.4 | −55.1 |
| Median Flow | 18.5 | 18.3 | 18.8 | 19.5 | 19.0 | 144.7 | 7.7 | 55.8 | 36.5 | 9986 | 9678 | 30 | 161 | −63.8 | 77.7 | −63.5 |
| Stacked-DCFNet | 30.0 | 30.2 | 30.9 | 33.1 | 32.3 | 120.5 | 13.8 | 62.6 | 23.6 | 8316 | 8051 | 139 | 651 | −37.3 | 71.6 | −36.1 |
Table 6.
Results of KCF, MOSSE, CSRT, Median Flow, and Stacked-DCFNet on different sequences of KIT AIS pedestrian dataset. The first and second best values of each method on the sequences are highlighted.
Table 6.
Results of KCF, MOSSE, CSRT, Median Flow, and Stacked-DCFNet on different sequences of KIT AIS pedestrian dataset. The first and second best values of each method on the sequences are highlighted.
| Sequences | # Imgs | GT | IDF1↑ | IDP↑ | IDR↑ | Rcll↑ | Prcn↑ | FAR↓ | MT%↑ | PT%↑ | ML%↓ | FP↓ | FN↓ | IDS↓ | FM↓ | MOTA↑ | MOTP↑ | MOTAL↑ |
|---|
| KCF |
| AA_Crossing_02 | 13 | 94 | 8.1 | 8.1 | 8.0 | 9.1 | 9.2 | 78.1 | 1.1 | 6.4 | 92.5 | 1015 | 1032 | 0 | 8 | −80.4 | 97.3 | −80.4 |
| AA_Walking_02 | 17 | 188 | 6.5 | 6.3 | 6.7 | 7.8 | 7.3 | 154.9 | 1.6 | 10.6 | 87.8 | 2633 | 2463 | 3 | 14 | −90.9 | 96.9 | −90.8 |
| Munich02 | 31 | 230 | 4.3 | 4.1 | 4.4 | 5.6 | 5.2 | 201.7 | 0.9 | 3.9 | 95.2 | 6254 | 5781 | 29 | 75 | −97.0 | 62.2 | −96.5 |
| RaR_Snack_Zone_02 | 4 | 220 | 29.3 | 29.1 | 29.5 | 29.8 | 29.5 | 154.5 | 1.8 | 98.2 | 0.0 | 618 | 607 | 0 | 8 | −41.6 | 95.1 | −41.6 |
| RaR_Snack_Zone_04 | 4 | 311 | 25.8 | 25.7 | 25.9 | 26.9 | 26.8 | 226.5 | 0.3 | 99.7 | 0.0 | 906 | 899 | 0 | 11 | −46.7 | 97.9 | −46.7 |
| MOSSE |
| AA_Crossing_02 | 13 | 94 | 8.0 | 8.1 | 7.9 | 9.1 | 9.2 | 78.1 | 1.1 | 5.3 | 93.6 | 1015 | 1032 | 0 | 9 | −80.4 | 96.9 | -80.4 |
| AA_Walking_02 | 17 | 188 | 6.6 | 6.4 | 6.7 | 8.0 | 7.6 | 151.8 | 1.6 | 10.1 | 88.3 | 2580 | 2458 | 2 | 20 | −88.7 | 95.7 | −88.6 |
| Munich02 | 31 | 230 | 4.3 | 4.2 | 4.5 | 5.7 | 5.4 | 199.7 | 0.9 | 4.3 | 94.8 | 6190 | 5775 | 29 | 78 | −95.8 | 61.9 | −95.4 |
| RaR_Snack_Zone_02 | 4 | 220 | 29.4 | 29.2 | 29.6 | 30.4 | 30.0 | 153.2 | 0.5 | 99.5 | 0.0 | 613 | 602 | 0 | 14 | −40.5 | 94.9 | −40.5 |
| RaR_Snack_Zone_04 | 4 | 311 | 25.8 | 25.7 | 25.9 | 27.0 | 26.8 | 226.2 | 0.3 | 99.7 | 0.0 | 905 | 898 | 0 | 12 | −46.6 | 97.5 | −46.6 |
| CSRT |
| AA_Crossing_02 | 13 | 94 | 12.9 | 13.2 | 12.5 | 15.1 | 15.9 | 69.5 | 1.1 | 30.9 | 68.0 | 904 | 964 | 10 | 29 | −65.5 | 84.6 | −64.7 |
| AA_Walking_02 | 17 | 188 | 9.2 | 10.0 | 8.5 | 11 | 12.9 | 116.9 | 2.7 | 15.4 | 81.9 | 187 | 2378 | 12 | 41 | −63.9 | 88.0 | −63.5 |
| Munich02 | 31 | 230 | 9.2 | 9.9 | 8.7 | 10.9 | 12.5 | 151.4 | 1.8 | 14.3 | 83.9 | 4696 | 5455 | 66 | 137 | −66.8 | 61.2 | −65.8 |
| RaR_Snack_Zone_02 | 4 | 220 | 43.2 | 42.0 | 42.5 | 43.8 | 43.3 | 124.2 | 17.3 | 82.7 | 0.0 | 497 | 486 | 0 | 16 | −13.6 | 87.9 | −13.6 |
| RaR_Snack_Zone_04 | 4 | 311 | 45.6 | 45.5 | 45.0 | 47.9 | 47.6 | 162.0 | 16.7 | 83.3 | 0.0 | 648 | 641 | 3 | 31 | −5.0 | 85.2 | −4.8 |
| Median Flow |
| AA_Crossing_02 | 13 | 94 | 27.3 | 27.3 | 27.4 | 28.5 | 28.3 | 62.8 | 1.1 | 68.1 | 30.8 | 817 | 812 | 4 | 49 | −43.9 | 74.9 | −43.6 |
| AA_Walking_02 | 17 | 188 | 10.0 | 9.9 | 10.0 | 11.1 | 11.0 | 141.1 | 1.6 | 21.3 | 77.1 | 2398 | 2374 | 8 | 16 | −79.0 | 86.3 | −78.7 |
| Munich02 | 31 | 230 | 9.2 | 9.0 | 9.4 | 9.9 | 9.5 | 186.4 | 1.3 | 8.7 | 90.0 | 5778 | 5517 | 10 | 53 | −84.6 | 64.7 | −84.4 |
| RaR_Snack_Zone_02 | 4 | 220 | 51.7 | 51.4 | 52.0 | 52.8 | 52.2 | 104.7 | 8.6 | 91.4 | 0.0 | 419 | 408 | 2 | 14 | 4.2 | 83.7 | 4.3 |
| RaR_Snack_Zone_04 | 4 | 311 | 53.1 | 53.0 | 53.3 | 53.9 | 53.6 | 143.5 | 17.4 | 82.6 | 0.0 | 574 | 567 | 6 | 29 | 6.7 | 83.0 | 7.2 |
| Stacked-DCFNet |
| AA_Crossing_02 | 13 | 94 | 41.9 | 42.4 | 41.3 | 42.7 | 43.9 | 47.8 | 12.8 | 58.5 | 28.7 | 621 | 650 | 15 | 71 | −13.3 | 74.7 | -12.1 |
| AA_Walking_02 | 17 | 188 | 31.4 | 31.6 | 31.2 | 32.3 | 32.7 | 104.3 | 5.9 | 45.7 | 48.4 | 1773 | 1809 | 23 | 184 | −35.0 | 74.1 | −34.2 |
| Munich02 | 31 | 230 | 21.2 | 20.6 | 21.9 | 25.0 | 23.6 | 160.4 | 1.7 | 50.0 | 48.3 | 4974 | 4591 | 97 | 322 | −57.7 | 60.5 | −56.2 |
| RaR_Snack_Zone_02 | 4 | 220 | 51.8 | 52.3 | 51.3 | 52.4 | 53.4 | 99.0 | 22.3 | 74.5 | 3.2 | 396 | 412 | 4 | 35 | 6.1 | 84.0 | 6.5 |
| RaR_Snack_Zone_04 | 4 | 311 | 51.8 | 52.6 | 51.0 | 52.1 | 53.7 | 138.0 | 21.9 | 74.9 | 3.2 | 552 | 589 | 0 | 39 | 7.2 | 83.6 | 7.2 |
Table 7.
Results of DeepSORT, SORT, Tracktor++, and SMSOT-CNN on the KIT AIS pedestrian dataset. The first and second best values are highlighted.
Table 7.
Results of DeepSORT, SORT, Tracktor++, and SMSOT-CNN on the KIT AIS pedestrian dataset. The first and second best values are highlighted.
| Methods | IDF1↑ | IDP↑ | IDR↑ | Rcll↑ | Prcn↑ | FAR↓ | MT%↑ | PT%↑ | ML%↓ | FP↓ | FN↓ | IDS↓ | FM↓ | MOTA↑ | MOTP↑ | MOTAL↑ |
|---|
| DeepSORT | 10.0 | 9.8 | 10.2 | 100.0 | 95.8 | 7.6 | 100.0 | 0.0 | 0.0 | 523 | 0 | 8627 | 9 | 23.9 | 81.1 | 98.6 |
| DeepSORT-BBX | 38.4 | 36.9 | 39.9 | 100.0 | 92.6 | 13.9 | 100.0 | 0.0 | 0.0 | 958 | 0 | 5073 | 9 | 49.9 | 78.7 | 92.0 |
| DeepSORT-IoU | 43.3 | 40.8 | 44.0 | 98.3 | 91.1 | 16.7 | 99.8 | 0.2 | 0.0 | 1152 | 205 | 4009 | 189 | 55.4 | 73.7 | 88.7 |
| DeepSORT-BBX-IoU | 82.1 | 80.7 | 83.6 | 99.4 | 96.0 | 7.3 | 99.8 | 0.2 | 0.0 | 502 | 75 | 738 | 70 | 89.1 | 74.7 | 95.2 |
| DeepSORT-BBX-IoU-FT | 82.4 | 81.0 | 83.8 | 99.4 | 96.0 | 7.1 | 99.8 | 0.2 | 0.0 | 493 | 71 | 734 | 68 | 89.2 | 74.7 | 95.3 |
| SORT-IoU | 42.9 | 41.8 | 44.2 | 98.7 | 93.4 | 12.2 | 99.8 | 0.2 | 0.0 | 840 | 151 | 3805 | 141 | 60.1 | 73.6 | 91.7 |
| SORT-BBX-IoU | 86.5 | 85.5 | 87.2 | 99.6 | 98.1 | 3.3 | 99.8 | 0.2 | 0.0 | 231 | 46 | 438 | 48 | 94.1 | 74.7 | 97.7 |
| Tracktor++ | 13.7 | 27.3 | 9.2 | 28.5 | 85.0 | – | 13.2 | 44.2 | 42.6 | 604 | 8593 | 2188 | 725 | 5.3 | 0.1 | – |
| SMSOT-CNN | 34.0 | 33.2 | 34.9 | 38.2 | 36.4 | 116.4 | 25.0 | 52.5 | 22.5 | 8028 | 7427 | 157 | 614 | −29.8 | 71.0 | −28.5 |
| EOT-D | 85.2 | 84.9 | 85.5 | 86.5 | 86.0 | 24.5 | 80.2 | 19.6 | 0.2 | 1692 | 1619 | 37 | 1074 | 72.2 | 69.3 | 72.5 |
Table 8.
Results of DeepSORT, SORT, Tracktor++, and SMSOT-CNN on the KIT AIS pedestrian dataset. The first and second best values of each method on the sequences are highlighted.
Table 8.
Results of DeepSORT, SORT, Tracktor++, and SMSOT-CNN on the KIT AIS pedestrian dataset. The first and second best values of each method on the sequences are highlighted.
| Sequences | # Imgs | GT | IDF1↑ | IDP↑ | IDR↑ | Rcll↑ | Prcn↑ | FAR↓ | MT%↑ | PT%↑ | ML%↓ | FP↓ | FN↓ | IDS↓ | FM↓ | MOTA↑ | MOTP↑ | MOTAL↑ |
|---|
| DeepSORT |
| AA_Crossing_02 | 13 | 94 | 3.1 | 3.1 | 3.1 | 100.0 | 100.0 | 0.0 | 100.0 | 0.0 | 0.0 | 0 | 0 | 940 | 1 | 17.2 | 99.7 | 99.7 |
| AA_Walking_02 | 17 | 188 | 7.7 | 7.7 | 7.8 | 100.0 | 98.9 | 1.7 | 100.0 | 0.0 | 0.0 | 29 | 0 | 2145 | 5 | 18.6 | 99.0 | 98.8 |
| Munich02 | 31 | 230 | 9.1 | 8.8 | 9.4 | 100.0 | 92.8 | 15.4 | 100.0 | 0.0 | 0.0 | 478 | 0 | 4681 | 1 | 15.8 | 64.0 | 92.1 |
| RaR_Snack_Zone_02 | 4 | 220 | 21.0 | 20.9 | 21.2 | 100.0 | 98.7 | 2.7 | 100.0 | 0.0 | 0.0 | 11 | 0 | 351 | 2 | 58.2 | 98.1 | 98.4 |
| RaR_Snack_Zone_04 | 4 | 311 | 17.9 | 17.9 | 18.0 | 100.0 | 99.6 | 1.2 | 100.0 | 0.0 | 0.0 | 5 | 0 | 510 | 0 | 58.1 | 98.6 | 99.4 |
| DeepSORT-BBX |
| AA_Crossing_02 | 13 | 94 | 34.8 | 34.5 | 35.1 | 100.0 | 98.4 | 1.4 | 100.0 | 0.0 | 0.0 | 18 | 0 | 566 | 1 | 48.5 | 94.3 | 98.2 |
| AA_Walking_02 | 17 | 188 | 46.6 | 46.0 | 47.1 | 100.0 | 98.8 | 3.6 | 100.0 | 0.0 | 0.0 | 61 | 0 | 1073 | 5 | 57.5 | 93.1 | 97.6 |
| Munich02 | 31 | 230 | 29.5 | 27.6 | 31.5 | 100.0 | 87.7 | 27.7 | 100.0 | 0.0 | 0.0 | 859 | 0 | 2989 | 1 | 37.2 | 63.9 | 85.9 |
| RaR_Snack_Zone_02 | 4 | 220 | 52.2 | 51.9 | 52.5 | 100.0 | 98.9 | 2.5 | 100.0 | 0.0 | 0.0 | 10 | 0 | 203 | 2 | 75.4 | 95.7 | 98.6 |
| RaR_Snack_Zone_04 | 4 | 311 | 61.2 | 61.0 | 61.5 | 100.0 | 99.2 | 2.5 | 100.0 | 0.0 | 0.0 | 10 | 0 | 242 | 0 | 79.5 | 94.4 | 99.0 |
| DeepSORT-IoU |
| AA_Crossing_02 | 13 | 94 | 55.0 | 54.4 | 55.6 | 99.0 | 96.9 | 2.8 | 100.0 | 0.0 | 0.0 | 36 | 11 | 347 | 10 | 65.3 | 83.6 | 95.6 |
| AA_Walking_02 | 17 | 188 | 63.4 | 62.5 | 64.3 | 99.1 | 96.3 | 6.1 | 100.0 | 0.0 | 0.0 | 103 | 23 | 557 | 25 | 74.4 | 82.0 | 95.2 |
| Munich02 | 31 | 230 | 24.2 | 22.8 | 25.8 | 97.2 | 85.8 | 31.8 | 99.6 | 0.4 | 0.0 | 985 | 170 | 2737 | 151 | 36.5 | 62.9 | 81.1 |
| RaR_Snack_Zone_02 | 4 | 220 | 57.7 | 57.3 | 58.2 | 100.0 | 98.5 | 3.2 | 100.0 | 0.0 | 0.0 | 13 | 0 | 177 | 2 | 78.0 | 90.4 | 98.2 |
| RaR_Snack_Zone_04 | 4 | 311 | 69.1 | 68.7 | 69.5 | 99.9 | 98.8 | 3.7 | 99.7 | 0.3 | 0.0 | 15 | 1 | 191 | 1 | 83.2 | 87.2 | 98.5 |
| DeepSORT-BBX-IoU |
| AA_Crossing_02 | 13 | 94 | 93.8 | 92.5 | 95.2 | 99.8 | 96.9 | 2.8 | 100.0 | 0.0 | 0.0 | 36 | 2 | 45 | 2 | 93.8 | 85.0 | 96.5 |
| AA_Walking_02 | 17 | 188 | 88.7 | 84.4 | 93.4 | 99.7 | 90.0 | 17.3 | 100.0 | 0.0 | 0.0 | 295 | 8 | 42 | 12 | 87.0 | 86.4 | 88.6 |
| Munich02 | 31 | 230 | 73.1 | 70.9 | 75.3 | 98.9 | 93.2 | 14.2 | 100.0 | 0.0 | 0.0 | 441 | 67 | 565 | 56 | 82.5 | 62.9 | 91.7 |
| RaR_Snack_Zone_02 | 4 | 220 | 90.1 | 89.9 | 90.4 | 99.8 | 99.2 | 1.7 | 99.1 | 0.9 | 0.0 | 7 | 2 | 37 | 4 | 94.7 | 87.9 | 98.8 |
| RaR_Snack_Zone_04 | 4 | 311 | 90.2 | 90.1 | 90.3 | 100.0 | 99.8 | 0.7 | 100.0 | 0.0 | 0.0 | 3 | 0 | 49 | 0 | 95.8 | 88.4 | 99.6 |
| DeepSORT-BBX-IoU-FT |
| AA_Crossing_02 | 13 | 94 | 93.1 | 92.7 | 93.4 | 100.0 | 99.3 | 0.6 | 100.0 | 0.0 | 0.0 | 8 | 0 | 43 | 1 | 95.5 | 85.1 | 99.2 |
| AA_Walking_02 | 17 | 188 | 93.1 | 92.4 | 93.7 | 99.8 | 98.4 | 2.5 | 100.0 | 0.0 | 0.0 | 43 | 6 | 42 | 9 | 96.6 | 86.5 | 98.1 |
| Munich02 | 31 | 230 | 73.3 | 71.2 | 75.5 | 99.0 | 93.3 | 13.9 | 100.0 | 0.0 | 0.0 | 432 | 63 | 563 | 54 | 82.7 | 62.9 | 91.9 |
| RaR_Snack_Zone_02 | 4 | 220 | 90.1 | 89.9 | 90.4 | 99.8 | 99.2 | 1.7 | 99.1 | 0.9 | 0.0 | 7 | 2 | 37 | 4 | 94.7 | 87.9 | 98.8 |
| RaR_Snack_Zone_04 | 4 | 311 | 90.2 | 90.1 | 90.3 | 100.0 | 99.8 | 0.7 | 100.0 | 0.0 | 0.0 | 3 | 0 | 49 | 0 | 95.8 | 88.4 | 99.6 |
| SORT-IoU |
| AA_Crossing_02 | 13 | 94 | 55.9 | 55.4 | 56.5 | 99.1 | 97.2 | 5.5 | 100.0 | 0.0 | 0.0 | 33 | 10 | 343 | 9 | 66.0 | 83.5 | 96.0 |
| AA_Walking_02 | 17 | 188 | 64.0 | 63.2 | 64.9 | 99.3 | 96.7 | 5.3 | 100.0 | 0.0 | 0.0 | 90 | 19 | 550 | 21 | 75.3 | 82.0 | 95.8 |
| Munich02 | 31 | 230 | 24.6 | 23.6 | 25.8 | 98.0 | 89.7 | 22.2 | 99.6 | 0.4 | 0.0 | 689 | 122 | 2544 | 108 | 45.2 | 62.8 | 86.7 |
| RaR_Snack_Zone_02 | 4 | 220 | 57.7 | 57.3 | 58.2 | 100.0 | 98.5 | 3.2 | 100.0 | 0.0 | 0.0 | 13 | 0 | 177 | 2 | 78.0 | 90.4 | 98.2 |
| RaR_Snack_Zone_04 | 4 | 311 | 69.1 | 68.7 | 69.5 | 99.9 | 98.8 | 3.7 | 99.7 | 0.3 | 0.0 | 15 | 1 | 191 | 1 | 83.2 | 87.2 | 98.5 |
| SORT-BBX-IoU |
| AA_Crossing_02 | 13 | 94 | 93.1 | 92.7 | 93.4 | 100.0 | 99.3 | 0.6 | 100.0 | 0.0 | 0.0 | 8 | 0 | 45 | 1 | 95.3 | 85.0 | 99.1 |
| AA_Walking_02 | 17 | 188 | 94.5 | 93.9 | 95.1 | 99.3 | 98.6 | 2.2 | 100.0 | 0.0 | 0.0 | 37 | 2 | 30 | 6 | 97.4 | 86.5 | 98.5 |
| Munich02 | 31 | 230 | 80.4 | 79.6 | 81.3 | 99.3 | 97.2 | 5.7 | 100.0 | 0.0 | 0.0 | 176 | 42 | 284 | 37 | 91.8 | 63.0 | 96.4 |
| RaR_Snack_Zone_02 | 4 | 220 | 90.5 | 90.2 | 90.8 | 99.8 | 99.2 | 1.7 | 99.1 | 0.9 | 0.0 | 7 | 2 | 34 | 4 | 95.0 | 87.9 | 98.8 |
| RaR_Snack_Zone_04 | 4 | 311 | 90.5 | 90.4 | 90.7 | 100.0 | 99.8 | 0.7 | 100.0 | 0.0 | 0.0 | 3 | 0 | 45 | 0 | 96.1 | 88.4 | 99.6 |
| Tracktor++ |
| AA_Crossing_02 | 13 | 94 | 12.7 | 19.6 | 9.4 | 48.2 | 100.0 | – | 20.1 | 51.1 | 28.8 | 0 | 588 | 432 | 107 | 10.1 | 0.13 | – |
| AA_Walking_02 | 17 | 188 | 10.7 | 27.5 | 6.7 | 23.2 | 95.8 | – | 3.2 | 43.1 | 53.7 | 27 | 2050 | 426 | 154 | 6.3 | 0.13 | – |
| Munich02 | 31 | 230 | 7.8 | 16.7 | 5.1 | 22.7 | 74.5 | – | 2.2 | 41.3 | 56.6 | 746 | 4736 | 965 | 412 | −0.8 | 0.08 | – |
| RaR_Snack_Zone_02 | 4 | 220 | 33.8 | 54.5 | 24.5 | 40.2 | 89.5 | – | 17.7 | 45.5 | 36.8 | 41 | 517 | 134 | 27 | 20.0 | 0.09 | – |
| RaR_Snack_Zone_04 | 4 | 311 | 32.5 | 50.2 | 24.0 | 42.9 | 89.8 | – | 22.2 | 44.1 | 33.7 | 60 | 702 | 231 | 25 | 19.3 | 0.06 | – |
| SMSOT-CNN |
| AA_Crossing_02 | 13 | 94 | 49.9 | 49.7 | 50.1 | 52.1 | 51.6 | 42.6 | 24.5 | 52.1 | 23.4 | 554 | 544 | 11 | 71 | 2.3 | 68.8 | 3.2 |
| AA_Walking_02 | 17 | 188 | 30.7 | 30.2 | 31.3 | 33.8 | 32.7 | 109.6 | 15.5 | 38.9 | 45.6 | 1864 | 1767 | 34 | 140 | −32.7 | 68.0 | −36.0 |
| Munich02 | 31 | 230 | 23.6 | 22.7 | 24.5 | 28.8 | 26.7 | 156.3 | 8.6 | 38.3 | 53.1 | 4846 | 4363 | 105 | 316 | −52.1 | 68.4 | −50.4 |
| RaR_Snack_Zone_02 | 4 | 220 | 61.6 | 61.4 | 61.8 | 64.4 | 63.9 | 78.5 | 37.3 | 62.3 | 0.4 | 314 | 308 | 2 | 39 | 27.9 | 77.9 | 28.0 |
| RaR_Snack_Zone_04 | 4 | 311 | 61.2 | 61.1 | 61.3 | 63.8 | 63.6 | 112.5 | 34.4 | 64.6 | 1.0 | 450 | 445 | 5 | 48 | 26.8 | 76.7 | 27.2 |
| EOT-D |
| AA_Crossing_02 | 13 | 94 | 94.4 | 94.4 | 94.4 | 95.3 | 95.2 | 4.1 | 91.5 | 8.5 | 0.0 | 54 | 53 | 4 | 34 | 90.2 | 73.8 | 90.5 |
| AA_Walking_02 | 17 | 188 | 94.6 | 94.0 | 95.1 | 96.9 | 95.8 | 6.7 | 96.8 | 2.7 | 0.5 | 114 | 82 | 10 | 63 | 92.3 | 76.6 | 92.6 |
| Munich02 | 31 | 230 | 76.0 | 75.8 | 76.2 | 77.0 | 76.5 | 46.6 | 44.3 | 54.8 | 0.9 | 1446 | 1409 | 15 | 930 | 53.1 | 60.4 | 53.4 |
| RaR_Snack_Zone_02 | 4 | 220 | 95.0 | 94.9 | 95.1 | 96.5 | 96.3 | 8.0 | 87.7 | 12.3 | 0.0 | 32 | 30 | 3 | 16 | 92.5 | 77.6 | 92.8 |
| RaR_Snack_Zone_04 | 4 | 311 | 95.2 | 95.1 | 95.2 | 96.3 | 96.3 | 11.5 | 76.2 | 23.8 | 0.0 | 46 | 45 | 5 | 31 | 92.2 | 78.6 | 92.5 |
Table 9.
Different network configurations.
Table 9.
Different network configurations.
| Name | SNN | LSTM | GCNN | SE Layers | OHEM |
|---|
| SMSOT-CNN | 🗸 | × | × | × | × |
| AerialMPTNet | 🗸 | 🗸 | × | × | × |
| AerialMPTNet | 🗸 | × | 🗸 | × | × |
| AerialMPTNet | 🗸 | 🗸 | 🗸 | × | × |
| AerialMPTNet | 🗸 | 🗸 | 🗸 | 🗸 | × |
| AerialMPTNet | 🗸 | 🗸 | 🗸 | × | 🗸 |
Table 10.
SMSOT-CNN on the KIT AIS and AerialMPT datasets.
Table 10.
SMSOT-CNN on the KIT AIS and AerialMPT datasets.
| Sequences | # Imgs | GT | IDF1↑ | IDP↑ | IDR↑ | Rcll↑ | Prcn↑ | FAR↓ | MT%↑ | PT%↑ | ML%↓ | FP↓ | FN↓ | IDS↓ | FM↓ | MOTA↑ | MOTP↑ | MOTAL↑ |
|---|
| KIT AIS Pedestrian Dataset |
| AA_Crossing_02 | 13 | 94 | 49.4 | 49.2 | 49.6 | 51.7 | 51.3 | 42.92 | 22.4 | 60.6 | 17.0 | 558 | 548 | 15 | 88 | 1.2 | 66.8 | 2.4 |
| AA_Walking_02 | 17 | 188 | 29.6 | 29.0 | 30.2 | 31.9 | 30.6 | 113.76 | 9.1 | 45.7 | 45.2 | 1934 | 1820 | 25 | 139 | −41.5 | 65.7 | −40.6 |
| Munich02 | 31 | 20.7 | 230 | 19.9 | 21.5 | 24.5 | 22.6 | 165.45 | 3.5 | 44.3 | 52.2 | 5129 | 4625 | 91 | 271 | −60.7 | 67.1 | −59.3 |
| RaR_Snack_Zone_02 | 4 | 220 | 63.1 | 62.9 | 63.4 | 64.2 | 63.7 | 79.0 | 35.0 | 63.6 | 1.4 | 316 | 310 | 1 | 39 | 27.5 | 78.2 | 27.6 |
| RaR_Snack_Zone_04 | 4 | 311 | 63.5 | 63.3 | 63.7 | 65.3 | 64.9 | 108.5 | 35.0 | 64.0 | 1.0 | 434 | 427 | 3 | 48 | 29.8 | 76.7 | 30.0 |
| Overall | 69 | 1043 | 32.5 | 31.7 | 33.4 | 35.7 | 33.9 | 121.32 | 22.2 | 56.0 | 21.8 | 8371 | 7730 | 135 | 585 | −35.0 | 70.0 | −33.9 |
| AerialMPT Dataset |
| Bauma3 | 16 | 609 | 29.3 | 28.6 | 30.0 | 34.6 | 33.0 | 385.69 | 9.9 | 47.1 | 43.0 | 6171 | 5748 | 200 | 458 | −37.9 | 69.1 | −35.7 |
| Bauma6 | 26 | 270 | 30.8 | 28.6 | 33.3 | 37.7 | 32.3 | 161.23 | 12.2 | 57.4 | 30.4 | 4192 | 3311 | 115 | 302 | −43.4 | 67.7 | −41.2 |
| Karlsplatz | 27 | 146 | 30.7 | 29.4 | 32.2 | 33.8 | 30.8 | 94.93 | 6.9 | 58.2 | 34.9 | 2563 | 2233 | 26 | 95 | −42.9 | 67.9 | −42.2 |
| Pasing7 | 24 | 103 | 57.7 | 54.5 | 61.3 | 61.9 | 55.1 | 43.42 | 35.9 | 54.4 | 9.7 | 1042 | 786 | 7 | 136 | 11.1 | 67.6 | 11.4 |
| Pasing8 | 27 | 83 | 33.5 | 32.6 | 34.4 | 35.1 | 33.3 | 50.30 | 8.4 | 54.2 | 37.4 | 1358 | 1253 | 10 | 82 | −35.7 | 67.0 | −35.2 |
| Witt | 8 | 185 | 15.8 | 15.7 | 15.9 | 16.4 | 16.2 | 150.38 | 1.1 | 20.5 | 78.4 | 1203 | 1184 | 1 | 9 | −68.6 | 61.5 | −68.6 |
| Overall | 128 | 1396 | 32.0 | 30.7 | 33.4 | 36.6 | 33.6 | 129.13 | 10.7 | 47.7 | 41.6 | 16,529 | 14,515 | 359 | 1082 | −37.2 | 68.0 | −35.6 |
| KIT AIS Vehicle Dataset |
| MunichStreet02 | 20 | 47 | 87.4 | 85.0 | 90.1 | 90.5 | 85.3 | 5.80 | 87.2 | 8.5 | 4.3 | 116 | 71 | 1 | 7 | 74.8 | 80.6 | 74.9 |
| StuttgartCrossroad01 | 14 | 49 | 67.3 | 63.6 | 71.5 | 74.9 | 66.6 | 14.86 | 57.1 | 30.6 | 12.3 | 208 | 139 | 3 | 17 | 36.8 | 75.3 | 37.3 |
| MunichCrossroad02 | 45 | 66 | 50.6 | 49.5 | 51.7 | 53.5 | 51.3 | 24.38 | 45.5 | 27.3 | 27.2 | 1097 | 1001 | 17 | 41 | 1.9 | 69.4 | 2.6 |
| MunichStreet04 | 29 | 68 | 83.5 | 82.4 | 84.7 | 85.8 | 83.6 | 8.83 | 76.5 | 14.7 | 8.8 | 256 | 215 | 6 | 15 | 68.6 | 79.7 | 68.9 |
| Overall | 108 | 230 | 68.0 | 66.4 | 69.7 | 71.3 | 67.9 | 15.53 | 65.7 | 20.4 | 13.9 | 1677 | 1426 | 27 | 80 | 37.1 | 75.8 | 37.6 |
Table 11.
AerialMPTNet on the KIT AIS and AerialMPT datasets. The best overall values of the two configurations on the KIT AIS pedestrian dataset are highlighted.
Table 11.
AerialMPTNet on the KIT AIS and AerialMPT datasets. The best overall values of the two configurations on the KIT AIS pedestrian dataset are highlighted.
| Sequences | # Imgs | GT | IDF1↑ | IDP↑ | IDR↑ | Rcll↑ | Prcn↑ | FAR↓ | MT%↑ | PT%↑ | ML%↓ | FP↓ | FN↓ | IDS↓ | FM↓ | MOTA↑ | MOTP↑ | MOTAL↑ |
|---|
| KIT AIS Pedestrian Dataset—Frozen Weights |
| AA_Crossing_02 | 13 | 94 | 42.0 | 41.8 | 42.2 | 44.8 | 44.5 | 48.92 | 13.8 | 59.6 | 26.6 | 636 | 626 | 13 | 99 | −12.3 | 68.4 | −11.3 |
| AA_Walking_02 | 17 | 188 | 34.7 | 34.0 | 35.4 | 37.2 | 35.8 | 104.94 | 8.0 | 55.3 | 36.7 | 1784 | 1678 | 22 | 227 | −30.4 | 67.4 | −29.7 |
| Munich02 | 31 | 230 | 26.0 | 25.1 | 26.9 | 33.1 | 30.8 | 146.81 | 6.1 | 57.8 | 36.1 | 4551 | 4098 | 191 | 463 | −44.3 | 67.8 | −41.2 |
| RaR_Snack_Zone_02 | 4 | 220 | 57.1 | 56.9 | 57.3 | 59.0 | 58.6 | 90.25 | 29.1 | 69.5 | 1.4 | 361 | 355 | 1 | 42 | 17.1 | 72.9 | 17.2 |
| RaR_Snack_Zone_04 | 4 | 311 | 64.7 | 64.4 | 64.9 | 66.3 | 65.9 | 105.25 | 39.6 | 58.8 | 1.6 | 421 | 415 | 4 | 52 | 31.7 | 73.8 | 32.0 |
| Overall | 69 | 1043 | 35.5 | 34.6 | 36.3 | 40.4 | 38.5 | 112.36 | 22.0 | 60.3 | 17.7 | 7753 | 7172 | 231 | 883 | −26.0 | 69.3 | −24.1 |
| KIT AIS Pedestrian Dataset—Trainable Weights |
| AA_Crossing_02 | 13 | 94 | 47.1 | 49.9 | 47.3 | 49.6 | 49.2 | 44.77 | 23.4 | 48.9 | 27.7 | 582 | 572 | 11 | 91 | −2.6 | 68.2 | −1.8 |
| AA_Walking_02 | 17 | 188 | 39.8 | 39.2 | 40.5 | 41.9 | 40.5 | 96.47 | 18.6 | 46.8 | 34.6 | 1640 | 1553 | 31 | 215 | −20.7 | 67.2 | −19.6 |
| Munich02 | 31 | 230 | 29.6 | 28.6 | 30.8 | 37.1 | 34.5 | 139.10 | 8.3 | 59.6 | 32.1 | 4312 | 3852 | 221 | 506 | −36.9 | 67.1 | −33.3 |
| RaR_Snack_Zone_02 | 4 | 220 | 63.0 | 62.8 | 63.2 | 64.9 | 64.4 | 77.50 | 37.3 | 60.0 | 2.7 | 310 | 304 | 4 | 31 | 28.6 | 72.2 | 28.9 |
| RaR_Snack_Zone_04 | 4 | 311 | 67.6 | 67.5 | 67.8 | 69.1 | 68.8 | 96.50 | 46.0 | 50.8 | 3.2 | 386 | 380 | 3 | 43 | 37.5 | 73.3 | 37.7 |
| Overall | 69 | 1043 | 39.7 | 38.8 | 40.6 | 44.6 | 42.6 | 104.78 | 28.9 | 53.8 | 17.3 | 7230 | 6661 | 270 | 886 | −17.8 | 68.8 | −15.5 |
| AerialMPT Dataset |
| Bauma3 | 16 | 609 | 28.3 | 27.7 | 29.0 | 34.6 | 33.0 | 386.00 | 8.4 | 51.2 | 40.4 | 6176 | 5745 | 246 | 608 | −38.5 | 71.0 | −35.7 |
| Bauma6 | 26 | 270 | 33.2 | 31.2 | 35.5 | 39.3 | 34.5 | 152.35 | 13.0 | 58.5 | 28.5 | 3961 | 3225 | 135 | 387 | −37.8 | 70.1 | −35.3 |
| Karlsplatz | 27 | 146 | 48.4 | 47.0 | 50.0 | 51.4 | 48.2 | 68.89 | 24.7 | 55.5 | 19.8 | 1860 | 1641 | 16 | 140 | −4.2 | 69.7 | −3.8 |
| Pasing7 | 24 | 103 | 61.0 | 58.5 | 63.6 | 64.3 | 59.2 | 38.08 | 35.9 | 56.3 | 7.8 | 914 | 737 | 5 | 127 | 19.8 | 70.5 | 20.0 |
| Pasing8 | 27 | 83 | 41.3 | 40.6 | 42.1 | 42.7 | 41.4 | 43.78 | 18.1 | 50.6 | 31.3 | 1182 | 1108 | 4 | 90 | −18.7 | 69.4 | −18.6 |
| Witt | 8 | 185 | 15.6 | 15.5 | 15.7 | 17.3 | 17.1 | 148.75 | 2.7 | 23.8 | 73.5 | 1190 | 1171 | 3 | 24 | −66.9 | 61.1 | −66.8 |
| Overall | 128 | 1396 | 35.7 | 34.5 | 37.0 | 40.5 | 37.7 | 119.40 | 12.8 | 49.8 | 37.4 | 15,283 | 13,627 | 409 | 1376 | −28.1 | 70.1 | −26.3 |
| KIT AIS Vehicle Dataset |
| MunichStreet02 | 20 | 47 | 81.9 | 79.9 | 84.0 | 84.9 | 80.6 | 7.60 | 74.5 | 10.6 | 14.9 | 152 | 113 | 4 | 3 | 63.9 | 79.6 | 64.4 |
| StuttgartCrossroad01 | 14 | 49 | 65.9 | 62.4 | 69.9 | 72.7 | 65.0 | 15.50 | 59.2 | 26.5 | 14.3 | 217 | 151 | 2 | 11 | 33.2 | 76.2 | 33.5 |
| MunichCrossroad02 | 45 | 66 | 57.7 | 56.0 | 59.5 | 60.6 | 56.9 | 21.93 | 48.5 | 33.3 | 18.2 | 987 | 850 | 22 | 43 | 13.7 | 69.4 | 14.7 |
| MunichStreet04 | 29 | 68 | 88.7 | 88.3 | 89.1 | 89.9 | 89.0 | 5.79 | 86.8 | 7.4 | 5.8 | 168 | 153 | 2 | 3 | 78.7 | 79.8 | 78.8 |
| Overall | 108 | 230 | 71.6 | 69.8 | 73.4 | 74.5 | 70.9 | 14.11 | 67.4 | 19.6 | 13.0 | 1524 | 1267 | 30 | 60 | 43.3 | 75.7 | 43.9 |
Table 12.
Overall Performances of Different Tracking Methods on the KIT AIS and AerialMPT Datasets. The first and second best values on each dataset are highlighted.
Table 12.
Overall Performances of Different Tracking Methods on the KIT AIS and AerialMPT Datasets. The first and second best values on each dataset are highlighted.
| Methods | IDF1↑ | IDP↑ | IDR↑ | Rcll↑ | Prcn↑ | FAR↓ | MT%↑ | PT%↑ | ML%↓ | FP↓ | FN↓ | IDS↓ | FM↓ | MOTA↑ | MOTP↑ | MOTAL↑ |
|---|
| KIT AIS Pedestrian Dataset |
| KCF | 9.0 | 8.8 | 9.3 | 10.3 | 9.8 | 165.6 | 1.1 | 53.8 | 45.1 | 11,426 | 10,782 | 32 | 116 | −84.9 | 87.2 | −84.7 |
| Median Flow | 18.5 | 18.3 | 18.8 | 19.5 | 19.0 | 144.7 | 7.7 | 55.8 | 36.5 | 9986 | 9678 | 30 | 161 | −63.8 | 77.7 | −63.5 |
| CSRT | 16.0 | 16.9 | 15.2 | 17.5 | 19.4 | 126.5 | 9.6 | 51.0 | 39.4 | 8732 | 9924 | 91 | 254 | −55.9 | 78.4 | −55.1 |
| MOSSE | 9.1 | 8.9 | 9.3 | 10.5 | 10.0 | 163.8 | 0.8 | 54.0 | 45.2 | 11,303 | 10,765 | 31 | 133 | −85.8 | 86.7 | −83.5 |
| Tracktor++ | 6.6 | 9.0 | 5.2 | 10.8 | 18.7 | 81.7 | 1.1 | 28.4 | 70.5 | 5648 | 10,723 | 648 | 367 | −41.5 | 40.5 | – |
| Stacked-DCFNet | 30.0 | 30.2 | 30.9 | 33.1 | 32.3 | 120.5 | 13.8 | 62.6 | 23.6 | 8316 | 8051 | 139 | 651 | −37.3 | 71.6 | −36.1 |
| SMSOT-CNN | 32.5 | 31.7 | 33.4 | 35.7 | 33.9 | 121.3 | 22.2 | 56.0 | 21.8 | 8371 | 7730 | 135 | 585 | −35.0 | 70.0 | −33.9 |
| AerialMPTNet (Ours) | 39.7 | 38.8 | 40.6 | 44.6 | 42.6 | 104.8 | 28.9 | 53.8 | 17.3 | 7230 | 6661 | 270 | 886 | −17.8 | 68.8 | −15.5 |
| AerialMPTNet (Ours) | 37.5 | 36.7 | 38.4 | 42.0 | 40.0 | 109.5 | 25.3 | 55.3 | 19.4 | 7555 | 6980 | 259 | 814 | −23.0 | 69.6 | −20.9 |
| AerialMPTNet (Ours) | 40.6 | 39.7 | 41.5 | 45.1 | 43.2 | 103.4 | 28.1 | 55.3 | 16.6 | 7138 | 6597 | 236 | 897 | −16.2 | 69.6 | −14.2 |
| AerialMPTNet (Ours) | 38.3 | 37.5 | 39.1 | 42.8 | 41.1 | 107.2 | 27.4 | 54.5 | 18.1 | 7395 | 6876 | 250 | 818 | −20.7 | 69.9 | −18.7 |
| AerialMPTNet (Ours) | 38.6 | 37.7 | 39.4 | 42.7 | 40.9 | 107.7 | 26.1 | 55.8 | 18.1 | 7435 | 6889 | 254 | 854 | −21.2 | 69.5 | −19.1 |
| AerialMPT Dataset |
| KCF | 11.9 | 11.5 | 12.3 | 13.4 | 12.5 | 167.2 | 3.7 | 17.0 | 79.3 | 21,407 | 19,820 | 86 | 212 | −80.5 | 77.2 | −80.1 |
| Median Flow | 12.2 | 12.0 | 12.4 | 13.1 | 12.7 | 162.0 | 1.7 | 20.2 | 78.1 | 20,732 | 19,883 | 46 | 144 | −77.7 | 77.8 | −77.5 |
| CSRT | 16.9 | 16.6 | 17.1 | 20.3 | 19.7 | 148.5 | 2.9 | 37.8 | 59.3 | 19,011 | 18,235 | 426 | 668 | −64.6 | 74.6 | −62.7 |
| MOSSE | 12.1 | 11.7 | 12.4 | 13.7 | 12.9 | 165.7 | 3.8 | 17.9 | 78.3 | 21,204 | 19,749 | 85 | 194 | −79.3 | 80.0 | −78.9 |
| Tracktor++ | 4.0 | 8.8 | 3.1 | 5.0 | 8.7 | 93.0 | 0.1 | 7.6 | 92.3 | 11,907 | 21,752 | 399 | 345 | −48.8 | 40.3 | – |
| Stacked-DCFNet | 28.0 | 27.6 | 28.5 | 31.4 | 30.4 | 128.3 | 9.4 | 44.2 | 46.4 | 16,422 | 15,712 | 322 | 944 | −41.8 | 72.3 | −40.4 |
| SMSOT-CNN | 32.0 | 30.7 | 33.4 | 36.6 | 33.6 | 129.1 | 10.7 | 47.7 | 41.6 | 16,529 | 14,515 | 359 | 1082 | −37.2 | 68.0 | −35.6 |
| AerialMPTNet (Ours) | 35.7 | 34.5 | 37.0 | 40.5 | 37.7 | 119.4 | 12.8 | 49.8 | 37.4 | 15,283 | 13,627 | 409 | 1376 | −28.1 | 70.1 | −26.3 |
| AerialMPTNet(Ours) | 37.0 | 35.7 | 38.3 | 42.0 | 39.1 | 117.0 | 15.6 | 46.0 | 38.4 | 14,983 | 13,279 | 433 | 1229 | −25.4 | 69.7 | −23.5 |
| AerialMPTNet (Ours) | 37.8 | 36.5 | 39.3 | 43.1 | 40.0 | 115.5 | 15.3 | 49.9 | 34.8 | 14,782 | 13,022 | 436 | 1269 | −23.4 | 69.7 | −21.5 |
| AerialMPTNet (Ours) | 38.9 | 37.5 | 40.4 | 44.1 | 40.9 | 113.8 | 17.0 | 48.1 | 34.9 | 14,568 | 12,799 | 430 | 1212 | −21.4 | 69.8 | −19.6 |
| AerialMPTNet (Ours) | 37.2 | 35.8 | 38.7 | 42.4 | 39.3 | 117.3 | 16.0 | 46.8 | 37.2 | 15,016 | 13,181 | 430 | 1284 | −25.1 | 69.8 | −23.2 |
| KIT AIS Vehicle Dataset |
| KCF | 41.3 | 39.0 | 43.9 | 45.6 | 40.4 | 30.9 | 27.0 | 33.5 | 39.5 | 3339 | 2708 | 53 | 96 | −22.6 | 72.3 | −21.6 |
| Median Flow | 42.0 | 39.5 | 44.9 | 46.3 | 40.8 | 31.0 | 32.2 | 40.0 | 27.8 | 3348 | 2669 | 23 | 47 | −21.4 | 82.0 | −21.0 |
| CSRT | 76.7 | 72.1 | 81.9 | 83.1 | 73.1 | 14.1 | 72.6 | 21.7 | 5.7 | 1520 | 841 | 21 | 46 | 52.1 | 80.7 | 52.5 |
| MOSSE | 29.0 | 27.4 | 30.8 | 32.4 | 28.8 | 36.8 | 19.6 | 30.0 | 50.4 | 3977 | 3364 | 56 | 81 | −48.7 | 75.0 | −47.6 |
| Tracktor++ | 55.3 | 66.6 | 47.2 | 57.3 | 80.7 | 6.3 | 30.0 | 47.4 | 22.6 | 681 | 2125 | 323 | 204 | 37.1 | 77.4 | – |
| Stacked-DCFNet | 73.8 | 71.2 | 76.6 | 77.2 | 71.8 | 14.0 | 69.1 | 15.2 | 15.7 | 1512 | 1133 | 9 | 39 | 46.6 | 82.0 | 46.8 |
| SMSOT-CNN | 68.0 | 66.4 | 69.7 | 71.3 | 67.9 | 15.5 | 65.7 | 20.4 | 13.9 | 1677 | 1426 | 27 | 80 | 37.1 | 75.8 | 37.6 |
| AerialMPTNet (Ours) | 71.6 | 69.8 | 73.4 | 74.5 | 70.9 | 14.1 | 67.4 | 19.6 | 13.0 | 1524 | 1267 | 30 | 60 | 43.3 | 75.7 | 43.9 |
| AerialMPTNet (Ours) | 71.1 | 69.4 | 72.9 | 74.1 | 70.6 | 14.2 | 67.0 | 18.7 | 14.3 | 1536 | 1289 | 22 | 58 | 42.8 | 75.9 | 43.2 |
| AerialMPTNet (Ours) | 70.0 | 68.3 | 71.8 | 73.9 | 70.3 | 14.4 | 66.5 | 20.9 | 12.6 | 1556 | 1299 | 29 | 67 | 42.0 | 76.3 | 42.6 |
| AerialMPTNet (Ours) | 70.0 | 68.4 | 71.7 | 73.2 | 69.8 | 14.6 | 63.5 | 24.8 | 11.7 | 1574 | 1334 | 23 | 84 | 41.1 | 75.6 | 41.5 |
| AerialMPTNet (Ours) | 71.7 | 70.0 | 73.4 | 74.6 | 71.2 | 13.9 | 67.0 | 19.6 | 13.4 | 1505 | 1262 | 27 | 66 | 43.8 | 75.5 | 44.3 |
Table 13.
AerialMPTNet on the KIT AIS and AerialMPT datasets.
Table 13.
AerialMPTNet on the KIT AIS and AerialMPT datasets.
| Sequences | # Imgs | GT | IDF1↑ | IDP↑ | IDR↑ | Rcll↑ | Prcn↑ | FAR↓ | MT%↑ | PT%↑ | ML%↓ | FP↓ | FN↓ | IDS↓ | FM↓ | MOTA↑ | MOTP↑ | MOTAL↑ |
|---|
| KIT AIS Pedestrian Dataset |
| AA_Crossing_02 | 13 | 94 | 43.5 | 43.3 | 43.7 | 45.5 | 45.1 | 48.4 | 18.1 | 51.1 | 30.8 | 629 | 619 | 11 | 90 | −10.9 | 68.5 | −10.1 |
| AA_Walking_02 | 17 | 188 | 35.8 | 35.3 | 36.2 | 38.2 | 37.2 | 101.3 | 14.9 | 47.9 | 37.2 | 1723 | 1650 | 35 | 204 | −27.6 | 68.1 | −26.3 |
| Munich02 | 31 | 230 | 29.1 | 28 | 30.2 | 35.5 | 32.9 | 142.9 | 8.3 | 53.9 | 37.8 | 4431 | 3951 | 204 | 434 | −40.2 | 68.1 | −36.9 |
| RaR_Snack_Zone_02 | 4 | 220 | 55.2 | 55.0 | 55.4 | 56.9 | 56.5 | 94.7 | 28.2 | 69.5 | 2.3 | 379 | 373 | 3 | 41 | 12.7 | 73.3 | 13.0 |
| RaR_Snack_Zone_04 | 4 | 311 | 67.2 | 67 | 67.3 | 68.5 | 68.2 | 98.2 | 44.4 | 52.1 | 3.5 | 393 | 387 | 6 | 45 | 36.1 | 73.9 | 36.5 |
| Overall | 69 | 1043 | 37.5 | 36.7 | 38.4 | 42.0 | 40.0 | 109.5 | 25.3 | 55.3 | 19.4 | 7555 | 6980 | 259 | 814 | −23.0 | 69.6 | −20.9 |
| AerialMPT Dataset |
| Bauma3 | 16 | 609 | 29.6 | 28.9 | 30.4 | 36.5 | 34.7 | 376.7 | 11.3 | 48.3 | 40.4 | 6028 | 5581 | 276 | 550 | −35.2 | 70.0 | −32.1 |
| Bauma6 | 26 | 270 | 36.7 | 34.4 | 39.3 | 43.7 | 38.2 | 144.2 | 20.4 | 50.4 | 29.2 | 3750 | 2994 | 126 | 329 | −29.3 | 70.6 | −26.9 |
| Karlsplatz | 27 | 146 | 43.7 | 72.3 | 45.2 | 46.4 | 43.4 | 75.6 | 15.8 | 63.0 | 21.2 | 2042 | 1809 | 25 | 145 | −14.9 | 68.5 | −14.2 |
| Pasing7 | 24 | 103 | 68.6 | 66.0 | 71.4 | 71.6 | 66.1 | 31.5 | 51.5 | 39.8 | 8.7 | 756 | 857 | 4 | 96 | 34.7 | 71.0 | 34.9 |
| Pasing8 | 27 | 83 | 41.2 | 40.4 | 42.1 | 42.7 | 41.0 | 44.0 | 18.1 | 51.8 | 30.1 | 1188 | 1108 | 2 | 94 | −18.9 | 68.2 | −18.9 |
| Witt | 8 | 185 | 14.1 | 14.0 | 14.2 | 15.3 | 15.1 | 152.4 | 1.6 | 19.5 | 78.9 | 1219 | 1200 | 0 | 15 | −70.8 | 60.8 | −70.8 |
| Overall | 128 | 1396 | 37.0 | 35.7 | 38.3 | 42.0 | 39.1 | 117.1 | 15.6 | 46.0 | 38.4 | 14,983 | 13,279 | 433 | 1229 | −25.4 | 69.7 | −23.5 |
| KIT AIS Vehicle Dataset |
| MunichStreet02 | 20 | 47 | 82.6 | 80.5 | 84.7 | 85.4 | 81.1 | 7.4 | 76.6 | 6.4 | 17.0 | 148 | 109 | 4 | 3 | 65.0 | 79.5 | 65.5 |
| StuttgartCrossroad01 | 14 | 49 | 70.0 | 66.5 | 73.8 | 76.7 | 69.1 | 13.6 | 65.3 | 22.4 | 12.3 | 190 | 129 | 2 | 11 | 42.1 | 75.7 | 42.3 |
| MunichCrossroad02 | 45 | 66 | 56.3 | 54.7 | 58.0 | 59.4 | 56.0 | 22.3 | 44.0 | 34.8 | 21.2 | 1005 | 876 | 14 | 41 | 12.1 | 70.0 | 12.7 |
| MunichStreet04 | 29 | 68 | 87.3 | 86.8 | 87.8 | 88.5 | 87.4 | 6.7 | 83.8 | 8.8 | 7.4 | 193 | 175 | 2 | 3 | 75.6 | 79.7 | 75.7 |
| Overall | 108 | 230 | 71.1 | 69.4 | 72.9 | 74.1 | 70.6 | 14.2 | 67.0 | 18.7 | 14.3 | 1536 | 1289 | 22 | 58 | 42.8 | 75.9 | 43.2 |
Table 14.
AerialMPTNet on the KIT AIS and AerialMPT datasets.
Table 14.
AerialMPTNet on the KIT AIS and AerialMPT datasets.
| Sequences | # Imgs | GT | IDF1↑ | IDP↑ | IDR↑ | Rcll↑ | Prcn↑ | FAR↓ | MT%↑ | PT%↑ | ML%↓ | FP↓ | FN↓ | IDS↓ | FM↓ | MOTA↑ | MOTP↑ | MOTAL↑ |
|---|
| KIT AIS Pedestrian Dataset |
| AA_Crossing_02 | 13 | 94 | 46.7 | 45.6 | 46.9 | 49.3 | 48.8 | 45.1 | 23.4 | 51.1 | 25.5 | 586 | 576 | 12 | 92 | −3.4 | 69.7 | −2.5 |
| AA_Walking_02 | 17 | 188 | 41.4 | 40.8 | 42.1 | 43.7 | 42.3 | 93.6 | 17.0 | 51.6 | 31.4 | 1591 | 1504 | 25 | 231 | −16.8 | 68.5 | −15.9 |
| Munich02 | 31 | 230 | 31.2 | 30.2 | 32.3 | 37.8 | 35.3 | 136.8 | 10.4 | 55.7 | 33.9 | 4240 | 3808 | 192 | 498 | −34.5 | 67.6 | −31.4 |
| RaR_Snack_Zone_02 | 4 | 220 | 59.0 | 58.8 | 59.2 | 60.9 | 60.5 | 86.0 | 33.2 | 65.0 | 1.8 | 344 | 3338 | 4 | 34 | 20.7 | 73.4 | 21.1 |
| RaR_Snack_Zone_04 | 4 | 311 | 68.5 | 68.3 | 68.6 | 69.8 | 69.5 | 94.2 | 45.7 | 51.8 | 2.5 | 377 | 371 | 3 | 42 | 38.9 | 74.2 | 39.1 |
| Overall | 69 | 1043 | 40.6 | 39.7 | 41.5 | 45.1 | 43.2 | 103.4 | 28.1 | 55.3 | 16.6 | 7138 | 6597 | 236 | 897 | −16.2 | 69.6 | −14.2 |
| AerialMPT Dataset |
| Bauma3 | 16 | 606 | 31.2 | 30.4 | 32.0 | 38.2 | 36.3 | 368.1 | 11.6 | 51.7 | 36.7 | 5890 | 5435 | 277 | 582 | −32.0 | 70.8 | −28.9 |
| Bauma6 | 26 | 270 | 37.2 | 34.8 | 39.9 | 44.2 | 38.6 | 143.7 | 17.0 | 58.1 | 24.9 | 3736 | 2964 | 123 | 333 | −28.4 | 70.2 | −26.1 |
| Karlsplatz | 27 | 146 | 45.6 | 44.2 | 47.1 | 48.6 | 45.6 | 72.4 | 19.9 | 61.6 | 18.5 | 1954 | 1733 | 25 | 153 | −10.0 | 67.4 | −9.3 |
| Pasing7 | 24 | 103 | 67.6 | 64.8 | 70.7 | 71.3 | 65.3 | 32.6 | 49.5 | 43.7 | 6.8 | 782 | 593 | 5 | 93 | 33.1 | 70.7 | 33.3 |
| Pasing8 | 27 | 83 | 39.7 | 38.7 | 40.8 | 41.3 | 39.2 | 45.8 | 15.7 | 55.4 | 28.9 | 1238 | 1134 | 2 | 83 | −22.9 | 68.9 | −22.8 |
| Witt | 8 | 185 | 16.0 | 15.9 | 16.1 | 17.9 | 17.6 | 147.7 | 2.7 | 24.3 | 73.0 | 1182 | 1163 | 4 | 25 | −65.9 | 60.1 | −65.7 |
| Overall | 128 | 1396 | 37.8 | 36.5 | 39.3 | 43.1 | 40.0 | 115.5 | 15.3 | 49.9 | 34.8 | 14,782 | 13,022 | 436 | 1269 | −23.4 | 69.7 | −21.5 |
| KIT AIS Vehicle Dataset |
| MunichStreet02 | 20 | 47 | 83.2 | 81.1 | 85.4 | 86.3 | 82.0 | 07.1 | 76.6 | 10.6 | 12.7 | 141 | 102 | 4 | 3 | 66.9 | 80.1 | 67.3 |
| StuttgartCrossroad01 | 14 | 49 | 68.4 | 65.0 | 72.2 | 75.3 | 67.8 | 14.14 | 61.2 | 26.5 | 12.3 | 198 | 137 | 1 | 16 | 39.4 | 76.3 | 39.5 |
| MunichCrossroad02 | 45 | 66 | 54.5 | 52.9 | 56.3 | 58.5 | 54.9 | 22.9 | 43.9 | 37.9 | 18.2 | 1033 | 895 | 20 | 45 | 9.6 | 70.1 | 10.5 |
| MunichStreet04 | 29 | 68 | 86.5 | 86.0 | 87.0 | 89.1 | 88.0 | 6.3 | 85.3 | 7.4 | 7.3 | 184 | 165 | 4 | 3 | 76.8 | 80.2 | 77.0 |
| Overall | 108 | 230 | 70.0 | 68.3 | 71.8 | 73.9 | 70.3 | 14.4 | 66.5 | 20.9 | 12.6 | 1556 | 1299 | 29 | 67 | 42.0 | 76.3 | 42.6 |
Table 15.
Comparison of AerialMPTNet trained with the and Huber Losses.
Table 15.
Comparison of AerialMPTNet trained with the and Huber Losses.
| Loss | IDF1↑ | IDP↑ | IDR↑ | Rcll↑ | Prcn↑ | FAR↓ | GT | MT%↑ | PT%↑ | ML%↓ | FP↓ | FN↓ | IDS↓ | FM↓ | MOTA↑ | MOTP↑ | MOTAL↑ |
|---|
| KIT AIS Pedestrian Dataset |
| L1 | 40.6 | 39.7 | 41.5 | 45.1 | 43.2 | 103.45 | 1043 | 28.1 | 55.3 | 16.6 | 7138 | 6597 | 236 | 897 | −16.2 | 69.6 | −14.2 |
| Huber | 38.8 | 37.9 | 39.7 | 43.1 | 41.1 | 107.42 | 1043 | 25.0 | 56.5 | 18.5 | 7412 | 6845 | 212 | 866 | −20.3 | 69.4 | −18.6 |
| AerialMPT Dataset |
| L1 | 37.8 | 36.5 | 39.3 | 43.1 | 40.0 | 115.48 | 1396 | 15.3 | 49.9 | 34.8 | 14,782 | 13,022 | 436 | 1269 | −23.4 | 69.7 | −21.5 |
| Huber | 38.0 | 36.7 | 39.5 | 43.0 | 39.9 | 115.70 | 1396 | 15.6 | 48.4 | 36.0 | 14,809 | 13,051 | 415 | 1196 | −23.5 | 69.9 | −21.7 |
| KIT AIS Vehicle Dataset |
| L1 | 70.0 | 68.3 | 71.8 | 73.9 | 70.3 | 14.41 | 230 | 66.5 | 20.9 | 12.6 | 1556 | 1299 | 29 | 67 | 42.0 | 76.3 | 42.6 |
| Huber | 67.2 | 65.5 | 69.0 | 70.6 | 67.1 | 15.98 | 230 | 67.0 | 17.4 | 15.6 | 1726 | 1461 | 34 | 65 | 35.2 | 76.1 | 35.9 |




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}