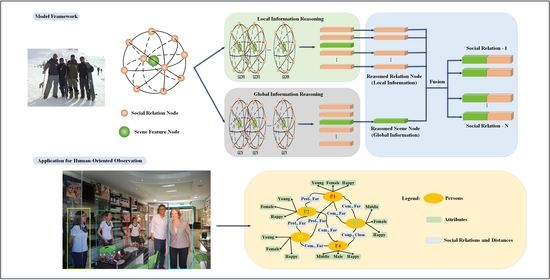
In this section, we introduce our experimental implementation and analyze the experimental results. First, a brief introduction of the two datasets and the implementation details are presented. Then, we compare our proposed model with the state-of-the-art methods. Next, a group of ablation experiments are described, which verify the importance of the global information. We also analyze whether the global information contributes equally to different social relations in the scene. Finally, we analyze the computational complexity via running-time experiments.
4.1. Datasets
To validate the effectiveness of our proposed SRR-LGR model, extensive experiments were conducted on the PISC dataset and the PIPA dataset. Here, a brief introduction of the two datasets is presented.
The PISC dataset and PIPA dataset were collected from a broad range of data sources, including social media (i.e., Flickr, Instagram, Twitter, Google and Bing) and the other specific datasets (i.e., Visual Genome [
54], MS-COCO [
55] and YFCC100M [
56]). In spite of the images from the other datasets, they are also related to human activities and similar to those images in social media. Li et al. [
2] and Sun et al. [
3] annotated various social relations in still images following different social psychological theories (i.e., the relational model theory [
10] and social domain theory [
9]), respectively.
For social relation division, each dataset contains two recognition tasks at the coarse and fine levels, which means that there are four types of relation definitions: (1) PISC-Coarse tasks, including intimate, nonintimate and no relation; (2) PISC-Fine tasks, including friends, families, couples, professional pairs, commercial pairs and no relation; (3) PIPA-Coarse tasks, including attachment, reciprocity, mating, hierarchical power and coalitional groups; (4) PIPA-Fine tasks, including 16 classes such as father–child, friends, lovers/spouses, presenter-audience and band members. We evaluated our method on the PISC-Coarse task, PISC-Fine task and PIPA-Fine task (“PIPA” task defaults to "PIPA-Fine" task in the following part). Accordingly, per-class recall and mean average precision (mAP) for the PISC task and top-1 accuracy for the PIPA task were used to evaluate the performance of our model.
For the split of training set, validation set and testing set, the details are shown in
Table 1 according to the specific recognition tasks.
4.2. Training Strategy and Parameter Setting
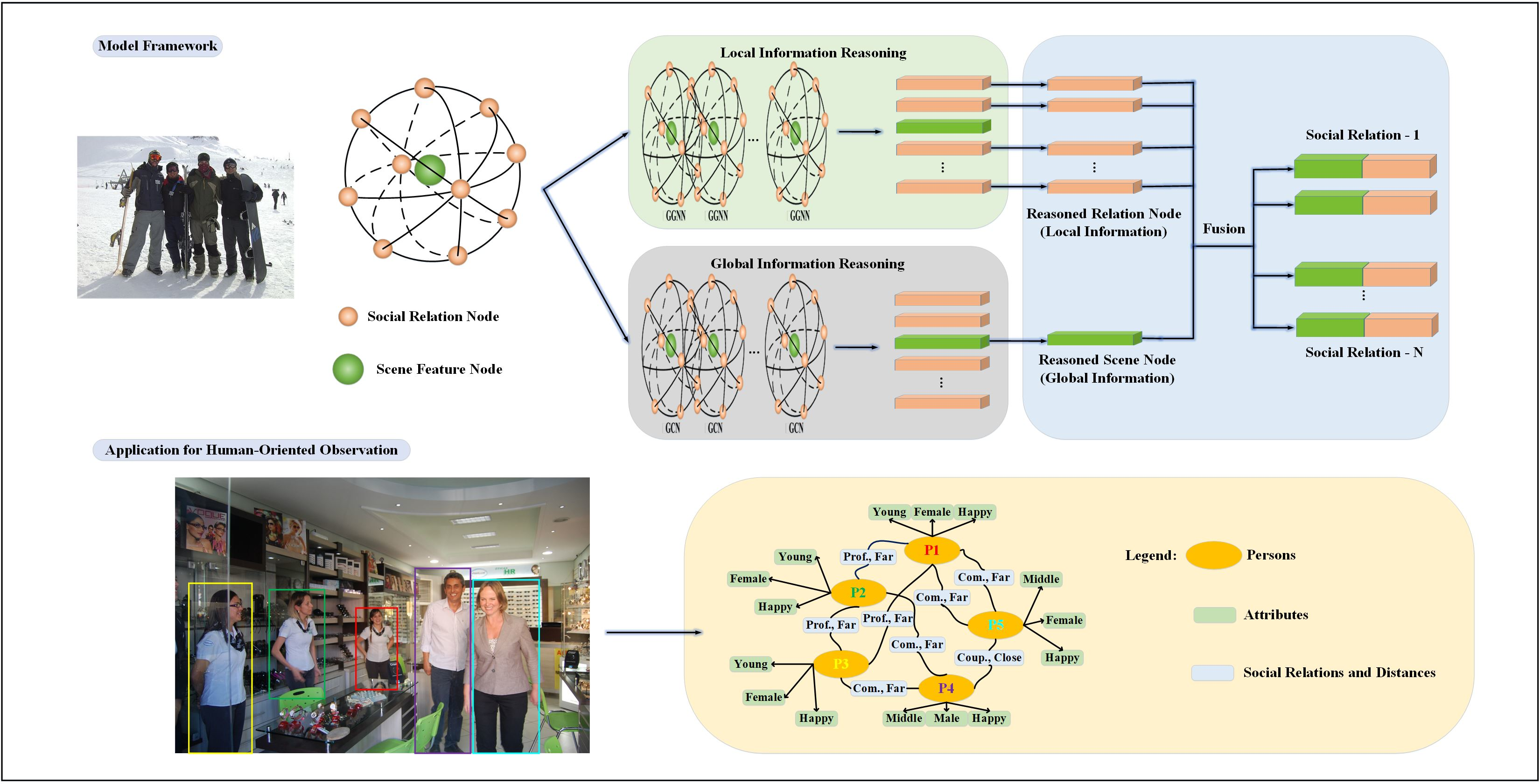
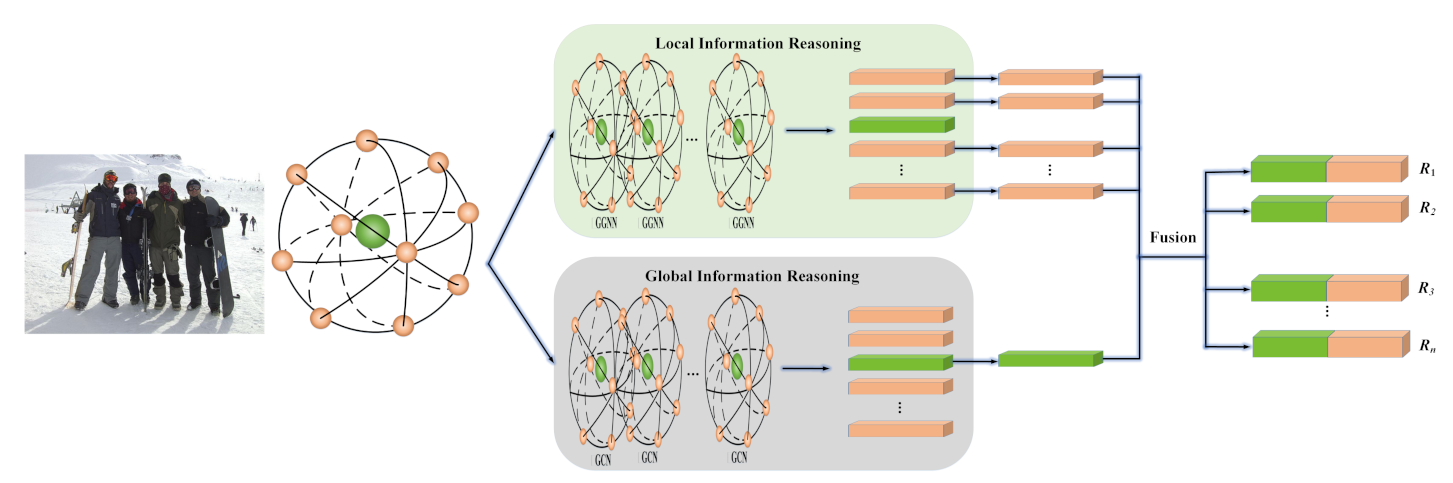
To decrease the difficulty of training and remove the limitation of computational source, we trained our model part by part based on transfer learning. Specifically, we first trained the node generation module and then optimized the local information reasoning module while freezing the parameters of node generation module. With the same transfer learning method, the global information reasoning module was trained and optimized.
In the process of training, we optimized our model on one Nvidia GeForce RTX 2080 Ti using Adam [
57] optimizer under the deep learning framework named Pytorch. Batch size, learning rate, learning attenuation and number of epochs were set to 24,
,
and 200 respectively. Additionally, the learning decay reduced to 10% per 10 epochs. For the numbers of layers of GGNN and GCN, they were set to 3 and 1, respectively.
It is worth noting that two methods of data augmentation were adopted, which were suggested by the collector of the PISC [
2] dataset. One reverses the people of the person pair, and the other horizontally flips the full image. Both methods can obtain more minority samples.
4.3. Comparison with State-Of-The-Art Methods
To demonstrate the performance of our proposed method, we compare it here with the state-of-the-art ones. First though, we provide a brief introduction for each method.
Dual-glance [
2]. This model is the baseline method of PISC dataset, which extracts features using two channels named glances in the paper. The first glance extracts the features of a person pair similarly to our model, while the second glance extracts the features of regions of interest detected by Faster RCNN [
58]. Then attention mechanism is used to weight each region, and finally the outputs of the two glances are concatenated for social relation prediction.
DSFS [
7]. This paper proposed a deep supervised feature selection framework which aims to reduce the feature redundancy from multi-source data and select the discriminative features for SRR. Specifically, the framework fuses deep learning algorithm with
-
to learn effective features from two views (i.e., group feature selection and dimensional feature selection).
GRM [
4]. This model constructs a graph which treats the features of persons and the contextual objects in the scene as nodes. Next, GGNN is introduced to reason through the constructed graph, and the weights for two types of nodes are calculated using an attention mechanism. Finally, the vector representations of person nodes concatenate the weighted ones of object nodes for SRR.
MGR [
6]. Multi-granularity features are exploited using different methods, including features between persons and objects contained in the person-object graph, correlations of pose between two persons contained in the person-pose graph and the scene information from the full image. In this model, GCN reasons the constructed graphs and pretrained ResNet-101 on ImageNet [
50] extracts the scene information. At last, these multi-granularity features jointly predict the social relations.
SRG-GN [
5]. The framework first extracts the features of person pair attributions (i.e., age, gender and clothing) from the single-body image and the information of relation attributions (i.e., scene and activity). Then the two kinds of attribution information are inferred using GRUs and a message passing scheme, and the final output of reasoning is used to classify the social relations.
GRN [
8]. To exploit the interactions among social relations in an image, a novel graph relational reasoning network was designed to model the logical constraints among different types of social relations contained in the constructed virtual relation graphs. In the graph, the node representation comes from the person patches in the feature map obtained by a convolutional neural network.
As shown in
Table 2, our proposed model achieved superiority over the existing state-of-the-art methods in the PISC-Coarse task, PISC-Fine task and PIPA task. Specifically, the proposed SRR-LGR model achieved 84.8%, a 1.7% improvement compared with the GR
N, in the PISC-Coarse task; and 73.0%, a 0.3% improvement compared with the GR
N, in the PISC-Fine task, which constitute the best results on PISC tasks. In the PIPA task, the top-1 accuracy was up to 66.1%, a 1.7% improvement over the previous best MGR.
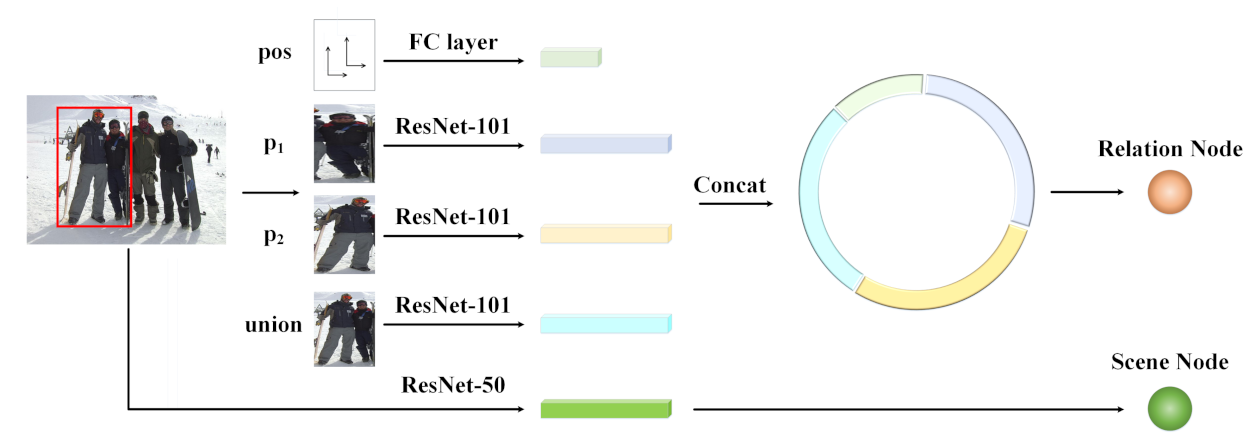
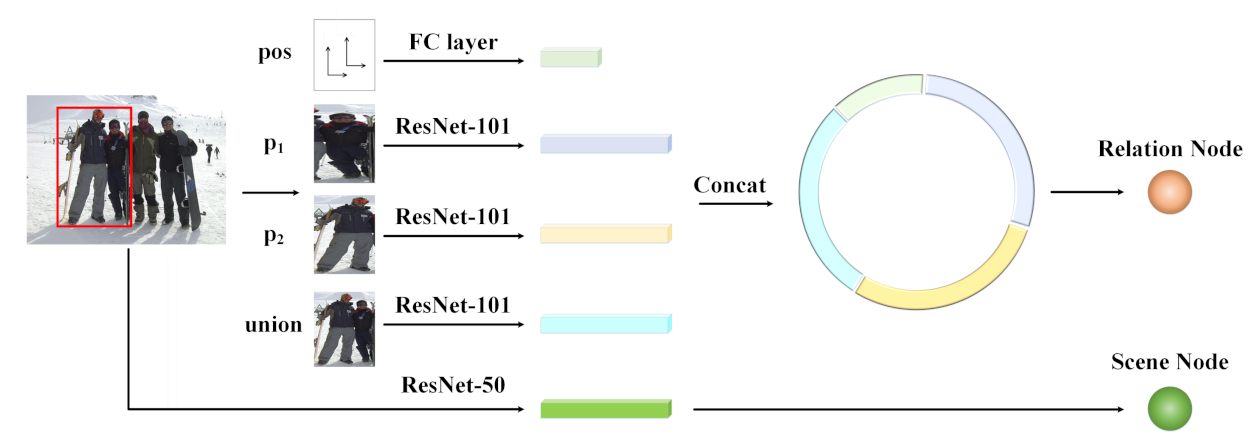
Like the baseline method, i.e., dual-glance, our model also extracts the features of the relative position, the two bounding boxes of the person pair and their union. For the scene features, dual-glance detects the objects of interest in the scene as the scene features. However, our model made great improvements of 5.1% in the PISC-Coarse task, 9.8% in the PISC-Fine task and 6.5% in the PIPA task, which demonstrates the effectiveness of our constructed graph and the reasoned local–global information. On the other hand, GRN, it also considers the local information while the global information is ignored; hence, our model increased the accuracy by 1.7% in the PISC-Coarse task, 0.3% in the PISC-Fine task and 1.8% in the PIPA task. This comparison demonstrates that it is important to take the global information into account.
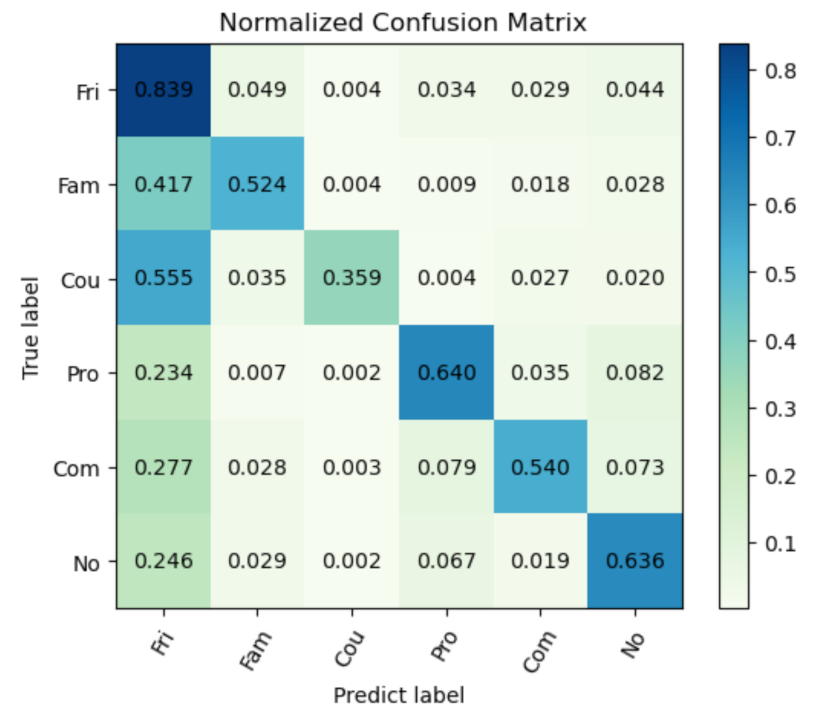
Next, we analyze the per-class recall in the PISC task to elaborate this characteristic of this model. In the PISC-Coarse task, our model outperformed the GR
N in both the mAP and the per-class recall. It can be noticed from
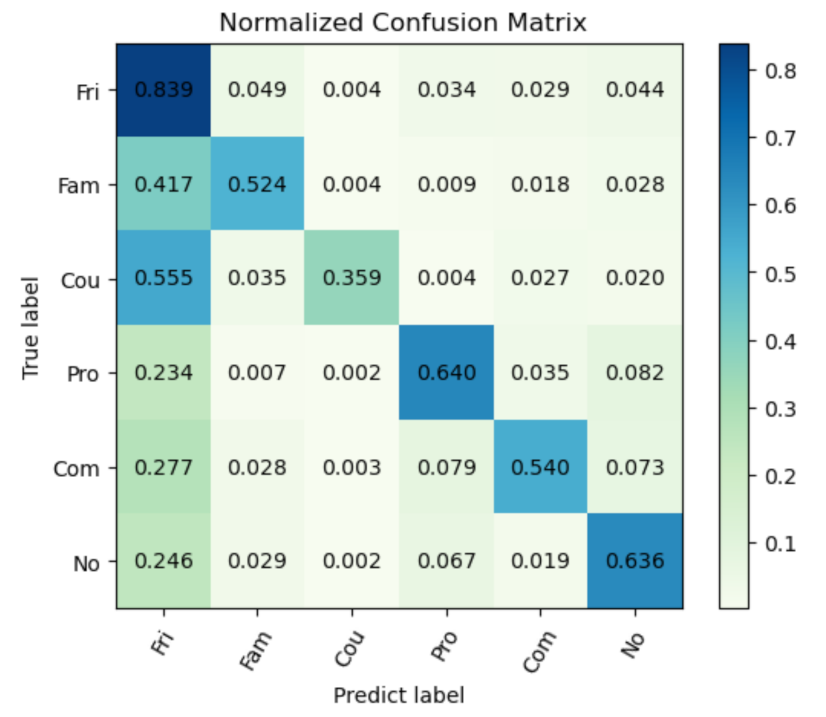
Table 2 that our proposed work cannot always outperform the existing work in terms of per-class recall. In order to better understand this point, the confusion matrix in the PISC-Fine task is given in
Figure 3.
As shown in
Figure 3, the model performed well in recognizing friends, professionals and no relation; for friends in particular, the per-class recall was up to 83.9%. However, differently from the good performance in the PISC-Coarse task, there were some minor problems in detail in the PISC-Fine task. It can be observed that many samples were misclassified into the social relation friend, especially the families and couples.
All these three social groups (i.e., friends, families and couples) have intimate relations, which may be the cause of the difficulty when discriminating the features of them. In
Figure 4, we present some true positive (TP) samples of the relation friend (row 1), couple samples misclassified to friends (row 2), and family samples misclassified to friends (row 3). These samples (i.e., friend, family, and couple) share similar features visually, but there still exist some distinguishing features. For the couples, the two individuals are always one male and one female. In addition, they are likely to be closer than the friends, especially in sample (d). For family, their ages may be different (e.g., take a father and a daughter). Besides the gender and age differences, activity is another factor with which to discriminate the different social relations. For example, the couples in sample (e) were dating and the family members in the sample (h) were having a family dinner.
In addition, although data augmentation was adopted to alleviate the data imbalance, the samples of the class friend were still too many compared with family and couple samples—one of the reasons for the misclassifications. As listed in
Table 3, the number of the friend pairs was greater than those of family and the couple. The number of couples was only about one tenth of the number of friends.
Nevertheless, our proposed SRR-LGR model outperforms the state-of-the-art methods in terms of the overall metric (i.e., mAP), which demonstrates the effectiveness of our model.
4.4. Ablation Study
To evaluate the performance of our designed SRR-LGR model, a group of ablation experiments were conducted.
(1) Concatenation. This is the baseline method, which simply concatenates all extracted features from person pair and scene and directly predicts the social relation.
(2) Local information. On top of the baseline method, the local information reasoning channel is added and then the output of this channel is used to recognize social relations.
(3) Local–global information. In addition to the local information reasoning channel, the global contextual information reasoning channel is also added to jointly classify social relations.
The results of this group of ablation experiments are listed in
Table 4. To begin with, we implemented the paradigm shift by using GGNN to reason through the local information in our constructed graph. By this means, the performance of recognizing social relations obtained great improvements, 4.9%, in the PISC-Coarse task, 6.5% in the PISC-Fine task and 2.9% in the PIPA task, respectively. This proves that the local information is of vital importance for SRR. After the addition of the global information, we can see the overall improvements in the PISC-Coarse task and the PISC-Fine task but a worsening in the PIPA task. This indicates, in our opinion, that the contribution of global information varies for different social relations. Furthermore, since the classification tasks went from coarse to fine (i.e., numbers of categories were 3, 6 and 16), it became more difficult to distinguish the subtle differences. For the PISC-Coarse task with only three categories, the local information could reason through the logical constraints among social relations and achieve great performance. This is due to the simplicity of the triple classification; the global information has barely any impact on it. So after fusing the global information, the mAP improved by a slight 0.1% in the PISC-Coarse task. However, for the PISC-Fine task and the PIPA task with more label categories, local information alone was not adequate to discriminate the different social relations; hence, the global information has a greater impact on improving the discriminative ability, which facilitates the increase of the accuracy for an SRR. Therefore, the mAP went up by 1.8% in the PISC-Fine task. In the PIPA task, the top-1 accuracy slightly decreased by 0.6%, which was possibly because the global information in this task is more difficult and cannot correspond to the each class of the 16 social relations. Even so, the top-1 accuracy was still superior compared to the other state-of-the-art methods.
4.5. The Contribution of the Global Information for Different Social Relations
As discussed in
Section 4.4, the global information contributes to the social relations in the scene. In order to further find out if the global information contributes equally to different social relations, we introduced the attention mechanism to exploit this point, motivated by [
2,
4,
7]. Li et al. [
2] and Wang et al. [
4] introduced the attention mechanism to weigh the contributions of different objects in a scene. Wang et al. [
7] also proposed a deep supervised feature selection (DSFS) framework to reduce the redundancy of the multi-source features. Experiments have demonstrated that the attention mechanism does not make sense for global information, and the global information is little redundant. Here, we give the implementation process of the attention mechanism and present the possible reasoning.
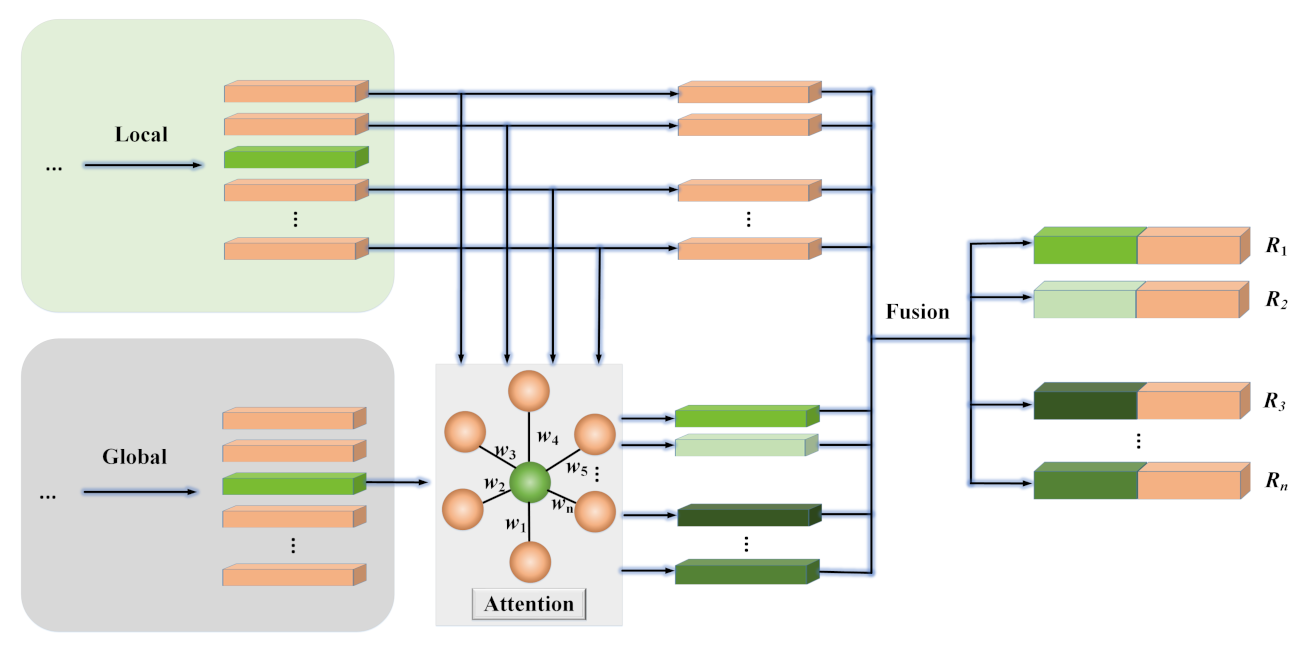
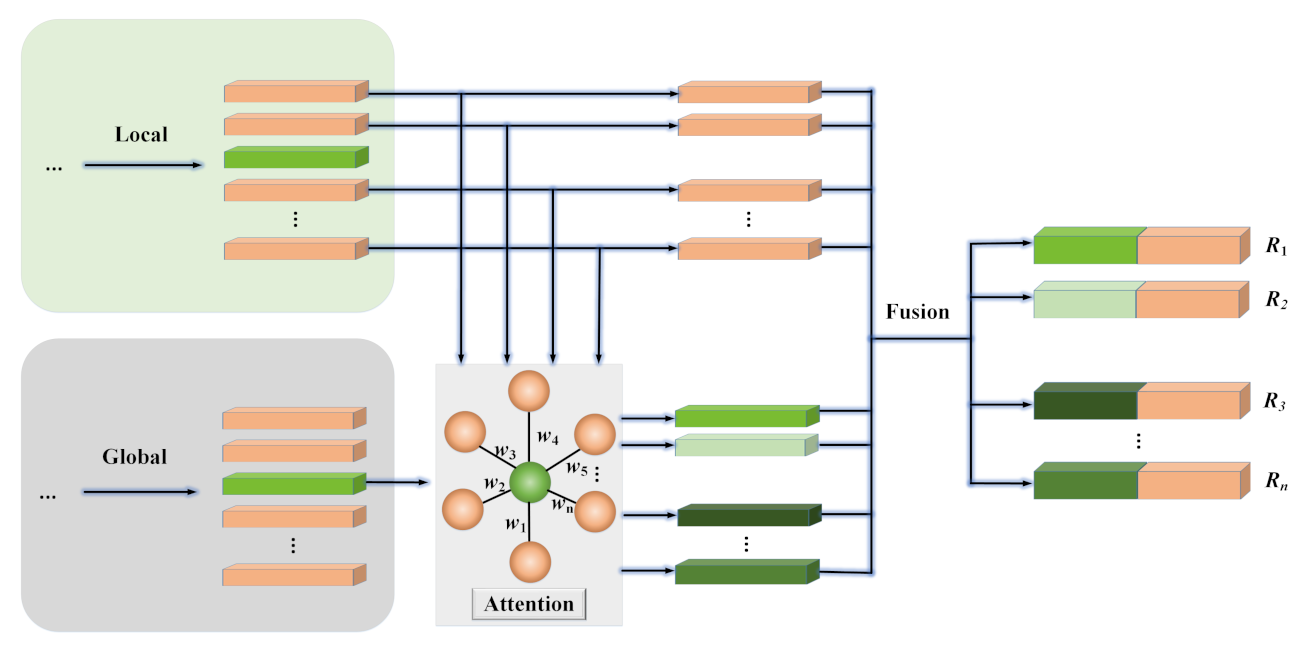
As shown in
Figure 5, we introduced an extra attention mechanism to weigh the contributions of the global information to different social relations in the same scene.
In order to weigh the contribution of the global information
for each social relation node
, an attention mechanism is introduced to capture the global information weighted by the local information. We first compute the hidden state
inspired by low-rank linear pooling method [
59] as follows:
where ⊙ denotes the Hadamard product,
and
are the trainable weights and Relu denotes the ReLU activation function.
Then we can compute the attention weight and use the sigmoid function to normalize the weight:
where
and bias are also the trainable weight and bias and
is a scaling factor, denoting the length of
.
Thus, the corresponding weighed global information
of each social relation can be expressed as follows:
Finally, we concatenate and to classify social relations.
The above is the implementation process of the attention mechanism, and the models achieved the same effectiveness no matter whether the attention mechanism was added or not. We visualized the weights of the attention mechanism
in
Figure 5 and found that they are the same. All of these facts demonstrate that the global information makes the same contribution to different social relations in the same scene.
Li et al. [
2] and Wang et al. [
4] have proved that the objects in a scene made different contributions to social relations. However, the global information contains not only the overall information of the scene but also the social relations in the same scene, and even the classified social relation also exists in the global information. In the same scene, people always interact each other, which means each social relation is related to the other ones. This may be the reason why the global information always makes equal contributions when we classify some of all the social relations in the scene. Nevertheless, the global information makes the model improvement over the state-of-the-art methods. We will also make the code and the two models (i.e., without the attention mechanism and with it) available for this discussion.
4.6. Running Time Analysis
Our method takes the local information (i.e., the logical constraints among social relations) into account, so we can recognize all the social relations in an image at the same time. This leads to the higher efficiency of our method compared to most pair-based methods, which classify the social relations pair by pair. We followed Li et al. [
8] and implemented running-time experiments with different batch sizes on the PIPA dataset using a Nvidia GeForce RTX 1080 Ti GPU. We firstly introduce the three representative methods and ours as follows:
GRM [
4]. One of the pair-based methods—that is, it recognizes the social relations in an image pair by pair. Dual-glance [
2], DSFS [
7], MGR [
6] and SRG-GN [
5] also belong to this type.
SRR-LGR (Ours). Our method, the image-based method, can classify all the social relations in an image.
Pair CNN [
8]. It is the baseline method that recognizes the social relations using two bounding boxes for the person pair. Additionally, it is also a pair-based method. To be fair, we conducted the experiments using the Pair CNN provided by [
8].
GRN [
8]. It is also an image-based method.
The comparative results are listed in
Table 5, and the “-” in the table represents the memory overflow.
Compared with the pair-based method (i.e., GRM [
4]), our method is much faster and achieves
∼
speed-ups, which shows the benefits of the image-based method (i.e., recognizing all the social relations in an image simultaneously). Considering the Pair CNN [
8] method, its efficiency is slightly higher than that of our method because our model extracts more comprehensive features and utilizes a more effective method to achieve better performance. It can be observed that our model was 19.7% more accurate in the PISC-Coarse task, 24.8% in the PISC-Fine task and 8.1% in the PIPA task over the Pair CNN method. In addition, since there were on average
bounding boxes per image on the testing set of the PIPA dataset, we could achieve higher speed when more individuals exist in an image. Compared with the image-based GR
N method, it is faster about two times than our method because its input is one patch, whereas our inputs are four patches and one vector. However, our method considers the extra and effective global information and improved performance by 1.7% in the PISC-Coarse task, 0.3% in the PISC-Fine task and 1.8% in the PIPA task. Generally speaking, our method achieves a good balance between the efficiency and the accuracy.
In order to further demonstrate the efficiency and computational complexity, we calculated the numbers of float-point operations (Flops), the numbers of parameters and the memory requirements (i.e., size of parameters) of different modules of our model, and the results are given in
Table 6. It can be observed that the key local–global information reasoned module expends little in the way of computational resources; that is, this module is effective and low-cost. As for the dynamics of the number of the social relations in an image, the number of the nodes in the constructed graph is also dynamic so that the three values are approximate. In addition, we set the number of social relation classes as six (i.e., the number of output classes in the PISC-Fine task) to calculate these values.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}