
A Spatio-Temporal Local Association Query Algorithm for Multi-Source Remote Sensing Big Data

Abstract
:1. Introduction
1.1. Research Background
1.2. Contributions
- In view of the general problems in remote sensing big data management and retrieval, we design a general and efficient spatio-temporal local association query algorithm for remote sensing data, the STLAQ, on the basis of mining and constructing the relationships of remote sensing data from different perspectives.
- The STLAQ solves the association problem of high-dimensional remote sensing data, relying on a data model and correlation network, especially when global features degenerate into local features on a unified multi-scale organization model.
- The STLAQ weakens the barriers between remote sensing data and expands their sharing mode, and has strong versatility and practical value in the field of remote sensing data application.
1.3. Paper Organization
2. Related Work
3. Materials and Methods
3.1. Local Association Query Algorithm for Remote Sensing Data
3.1.1. Spatio-Temporal Data Model
- Space-time Reference. Space-time reference is the basis for describing and measuring remote sensing data, including two parts; time reference and space reference. The origin and measurement scale of the datum need to be clarified in each reference. The space reference system includes several parts, such as plane coordinate system, map projection, and height datum, used in representing the spatial feature of remote sensing data and describing the spatial relationship between them. The time reference system is the basis for time information exchange and calculation. Remote sensing data can be expressed as a moment or a period in the time reference system. In [30], the Gregorian calendar, 24:00, local time or coordinated universal time are designated as the basic time reference system for information exchange.
- Structure Description. The structure description of remote sensing data is a description of the underlying remote sensing data organization scheme, including multi-scale model, storage structure and index structure. The multi-scale model is a multi-level-of-detail model, established by way of breaking up different types of data according to uniform rules and dividing the data into different resolution levels. In the multi-scale model, spatio-temporal data units at different resolutions can be correlated based on features, and be stored and indexed uniformly. The storage structure defines the storage form of remote sensing data, to organize data and its characteristics in a certain structure. In order to solve the efficiency problem of massive remote sensing data in joint retrieval, it is necessary to build indexes on the basis of storage structure. The index structure describes the composition of the spatio-temporal index, including retrieval conditions, retrieval values, and keys of the remote sensing data in storage structure.
- Feature Description. Feature description is the low-level features exacted from remote sensing data. The relationship between remote sensing data is essentially to calculate the similarity between the various features and then to aggregate the results. Therefore, the extraction of data features and the calculation of the correlation degree are critical parts of the construction of data correlation. This paper divides the features of remote sensing data into three categories: time feature, spatial feature, and data feature. In this case, time feature can be expressed as the production time or the life cycle of remote sensing data; spatial features include two parts, spatial position (such as latitude and longitude) and spatial form (such as points, lines, surfaces). Spatial and time features of the data can be obtained from the data itself, as well as through data analysis. Data features refer to the low-level features extracted from remote sensing data. For example, color features, texture features and shape features of remote sensing image data can be extracted, such as gray-level mean, gray-level standard deviation, direction gradient, principal component features, etc. Different remote sensing data often differ in the types and values of data features.
- In the part of space-time reference, the spatial reference is WGS84/EGM96, and the time reference is UTC/GMT+08:00 zone.
- In the part of structure description, the multi-scale model of the sample data is a tile pyramid model. The key of the storage table is composed of data location, data type, and data acquisition time. There are 2 column families in the storage table, where data is used to store tile data, meta is used to store the meta information. The index structure includes a multi-dimensional feature index and an association index.
- In the part of feature description, the time feature is the data acquisition time expressed in the format of “yyyy-mm-dd hh:mm:ss”. The spatial feature is the geographic region of the sample data, and the data feature is the low-level features, such as the maximum, minimum, mean, standard deviation and other statistical features.
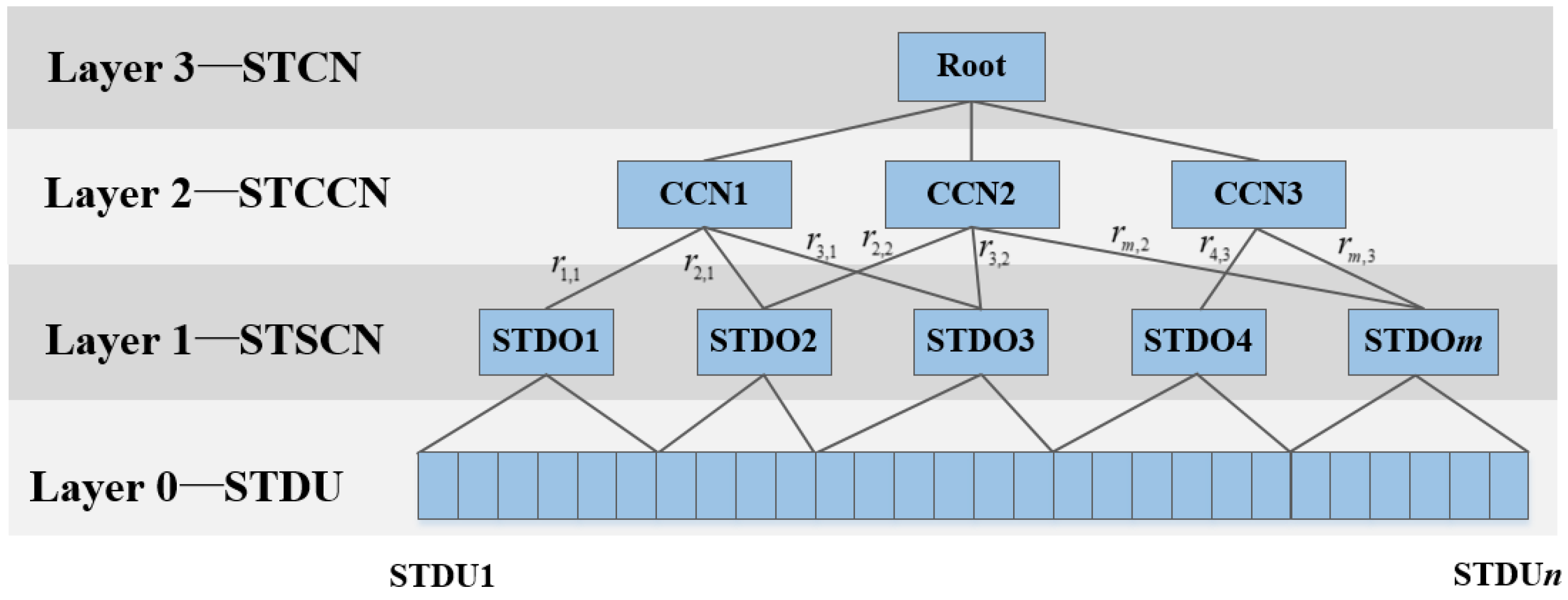
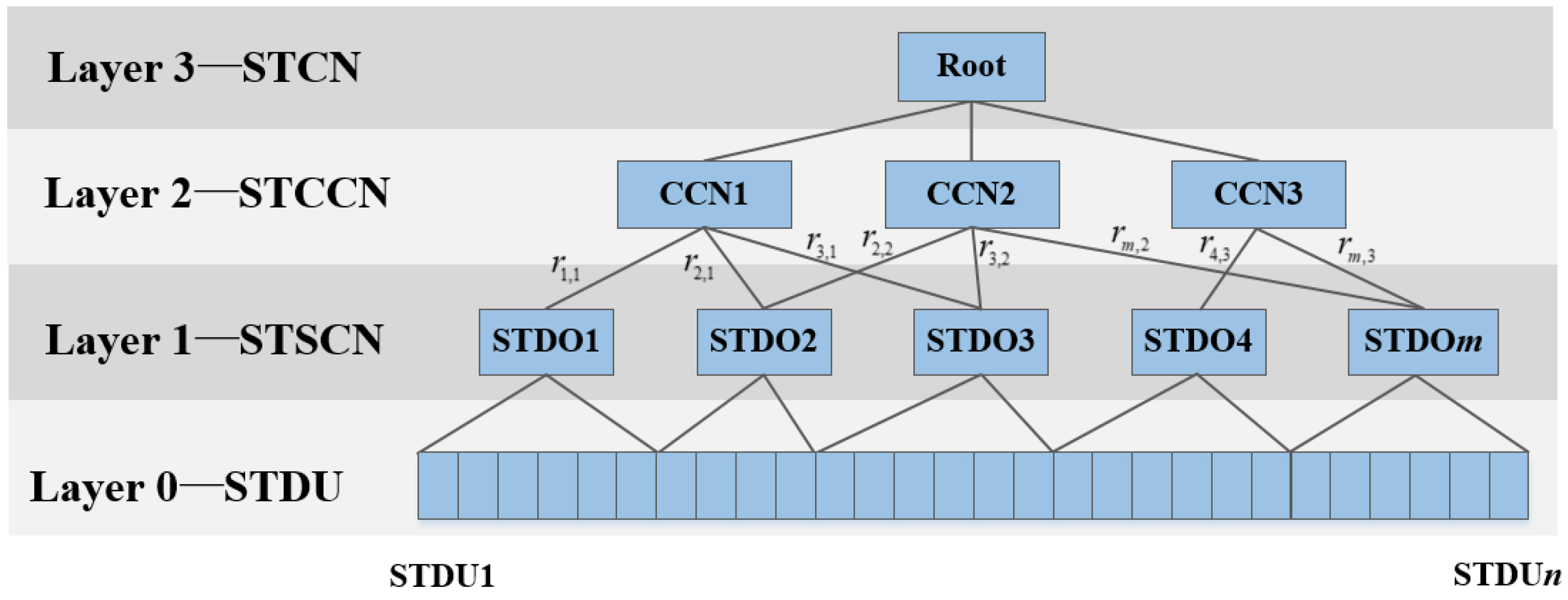
3.1.2. Spatio-Temporal Correlation Network
3.1.3. Preliminaries
- Hypergraph Model [33]. The graph model is a typical model that can effectively represent entities and their relationships. A graph can be expressed as , its vertex set is , and the edge set is . In the graph, each edge is a point pair , where . There are two kinds of graphs: directed graph and undirected graph [33]. If the is ordered, G is a directed graph, otherwise is an undirected graph. Hypergraph is a generalization of ordinary graphs and can be used to express complex relationships. For a hypergraph , the set of hyperedges is , and each hyperedge is a subset of the set of vertices , which can connect two or more vertices and meet the regulation . A weighted hypergraph is to assign a weight as to each hyperedge, indicating the degree to which the vertices within belong to the hyperedge . Adjacency matrix and incidence matrix are always used to describe structure of graph . The adjacency matrix of graph is a matrix of size , denoted as . If there is an edge between the vertex and , the value of is 1, otherwise is 0. The incidence matrix of graph is a matrix of size , denoted as . If the vertex is an endpoint of the edge , the value of is 1, otherwise it is 0.
- Spectral Cluster [34]. Spectral clustering turns the clustering problem into the graph partitioning problem. To solve the graph cut objective function, the properties of the Rayleigh quotient are usually utilized to map the original data points into a lower dimensional eigen-space by calculating the eigenvectors of Laplacian matrix and then conducting the clustering in the new space [34]. In spectral clustering, all data can be treated as vertices connected by edges. The edge weight value between two points farther apart is lower, and the edge weight value between two points closer together is higher. The purposes of clustering are to make the weight of the edges between the different subgraphs as low as possible, and to make the weight of the edges in the subgraphs as high as possible. The method of spectral clustering used in this paper is normalized cut. According to the implementation of spectral clustering given in [35,36], the application of spectral clustering in STCN construction can be found in Section 3.3.2.
3.2. Multi-Source Remote Sensing Data Association
3.2.1. Spatio-Temporal Data Model Encapsulation
- Associate spatio-temporal information on the basis of the pyramidal grid, and establish the correspondence between remote sensing data and grid models according to the spatial resolution and geographic scope of the remote sensing data.
- In the global remote sensing data grid, the size of the grid cell is fixed (such as 256 × 256), and the spatial resolution of grid cells at different levels can be obtained viawhere and represent the maximum and minimum value of the longitude range of the current coordinate system, respectively, represents the level of current grid, represents the resolution, and represents the size of current grid.
- Copy the remote sensing data to the relevant position in the grid based on the correspondence to obtain a grid generated from the remote sensing data.
- Use resampling algorithm (such as bilinear interpolation algorithm) to down-sample remote sensing data step-by-step, to obtain grid data at lower resolution levels, obtaining a complete remote sensing data pyramid.
- Multi-source remote sensing data is sampled and processed on a unified remote sensing data pyramid hierarchy to obtain global spatio-temporal data units with multiple levels of detail.
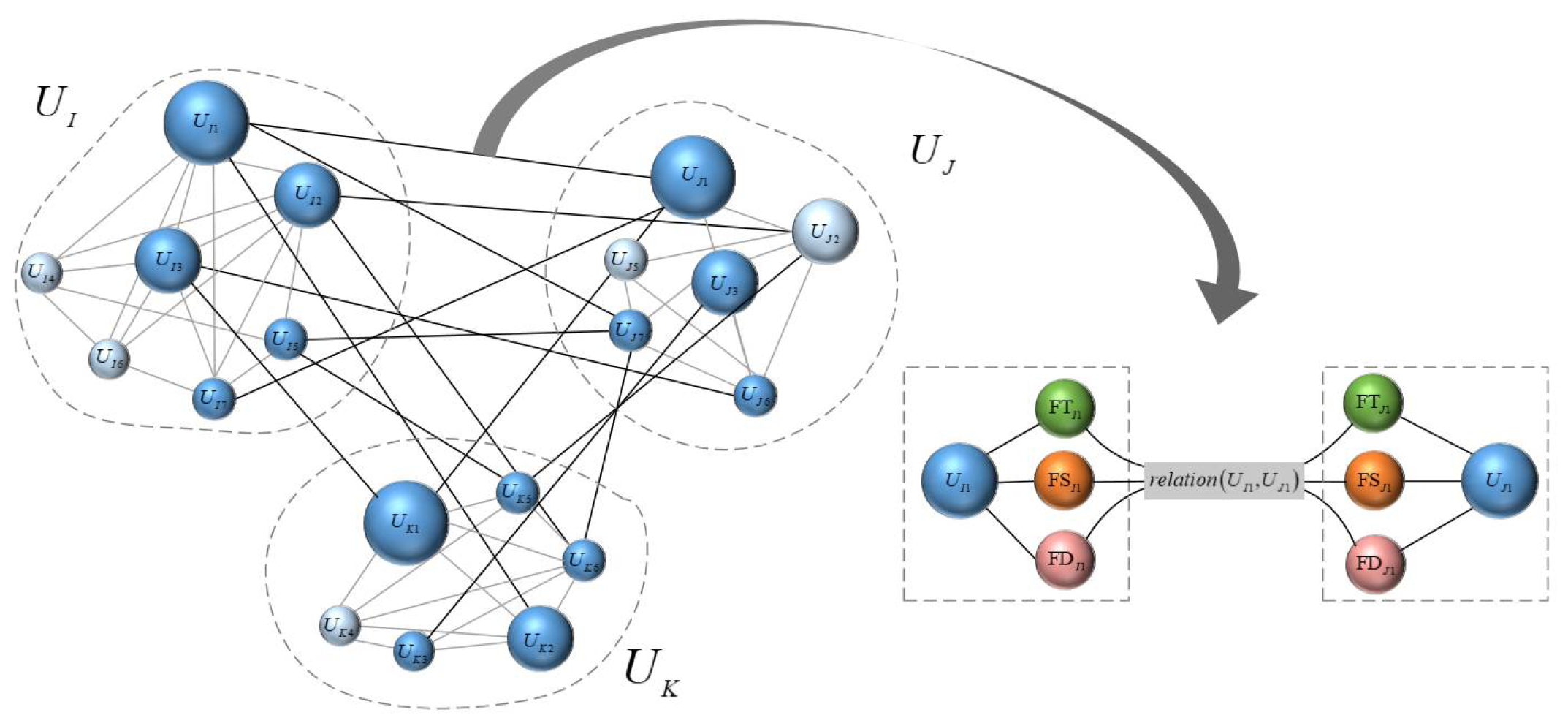
3.2.2. Spatio-Temporal Correlation Network Construction
The Construction of the Self-Correlation Network
- Similarity in Data Features
- Similarity in Time Features
- Similarity in Spatial Features
- Joint similarity
- Correlation degree
| Algorithm 1. The algorithm implementation of the multi-source remote sensing data correlation method. |
| STSCN Construction Algorithm |
| Input: Output:, |
|
1. ; 2. ; 3. Use optimized FCM algorithm for clustering to get ; 4. for 5. 6. for 7. Calculate , , ; 8. Calculate , ; 9. Calculate , ; 10. if 11. ; 12. ; 13. ; 14. ; 15. end if 16. end for 17 end for 18. return . |
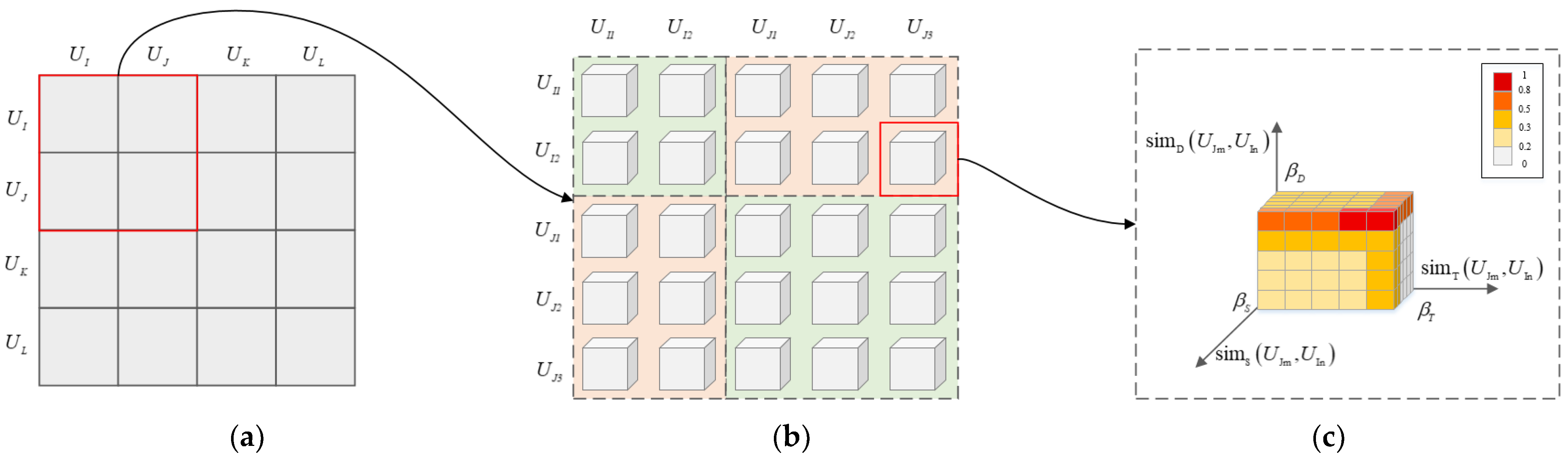
The Construction of the Cross-Correlation Network
- Establish similarity matrix, adjacency matrix and degree matrix for the correlation among STDOs. The adjacency tensor of STCCN can be degenerated into an adjacency matrix , letAs for in STCCN, the degree is defined as the sum of the weights of all edges connected to it, that isThe Laplacian matrix of STCCN can be calculated from the degree matrix and the adjacency matrix as .
- Calculate and standardize the Laplacian matrix of the correlation graph of STDOs;
- Calculate the smallest eigenvalue and its corresponding eigenvector on the standardized matrix;
- Standardize obtained eigenvectors by rows to form a characteristic matrix of size ;
- Regard matrix as -dimensional samples, perform FCM clustering, and divide the complete set of spatio-temporal data objects into c clusters, , corresponding to STCCNs.
- Take a remote sensing data cross-correlation network from ;
- Take a remote sensing data object from , and calculate the correlation degree of to the element in aswhere is the complement of , that is, the union of other cross-correlation networks in except ;
- If obtained in step 2 is greater than the threshold , it is considered that belongs to , let ;
- Execute step 2 to step 4 cyclically, until all the STDOs in have verified the correlation of each subnet;
- Execute step 1 to step 4 cyclically, until all the spatio-temporal cross-correlation networks in have completed the completion operation.
| Algorithm 2. The algorithm implementation of the multi-source remote sensing data correlation method. |
| STCCN Construction Algorithm |
| Input: Spatio-temporal data objects Output: |
|
1. 2. for 3. ; 4. ; 5. ; 6. ; 7. end for 8. Calculate ; 9. Standardize ; 10. Get the smallest eigenvalues and eigenvectors of ; 11. Standardize the eigenvectors by rows to obtain an eigenmatrix of size ; 12. Consider as k-dimensional samples, and use FCM for clustering to obtain the divided cluster set ; 13. for 14. if 15. Calculate ; 16. IF 17. ; 18. end if 19. end if 20. end for 21. for 22. for 23. Calculate ; 24. ; 25. ; 26. end for 27. end for 28. return, |
3.2.3. Spatio-Temporal Correlation Network Update
- Encapsulate the features of the remote sensing data object into query conditions to query eligible candidate remote sensing datasets ;
- Query the correlation network set , corresponding to all spatio-temporal data objects in ;
- Take an element from and calculate the correlation degree between and ;
- Determine whether there is relationship based on the correlation threshold. If there is a correlation, update the structure of the correlation network accordingly, that is, update the adjacency matrix and the correlation matrix stored;
- Repeat steps 3 and 4 until all elements are traversed.
| Algorithm 3. The algorithm implementation of the multi-source remote sensing data correlation method. |
| STCN Update Algorithm Input: remote sensing data object Output: |
|
1. Transform features of into query conditions; 2. Traverse data table to get a set of STDOs as ; 3. for 4. Get a set of STCCNs which belongs to as ; 5. 6. end for 7. for 8. Calculate ; 9. IF 10. ; 11. 12. end for 13. Update and ; 14. return , |
3.2.4. Algorithm Implementation
| Algorithm 4. The algorithm implementation of the multi-source remote sensing data association method. |
| Multi-Source Remote Sensing Data Association Method Algorithm |
| Input: remote sensing data Output: |
|
1. ; 2. switch (OperateType) 3. { 4. case CONSTRUCTION: 5. Extract data, spatial and time features to construct ; 6. Analyze the data structure to construct ; 7. Encapsulate , where , ; 8. Get through STSCN Construction Algorithm 9. for 10. ; 11. for 12. ; 13. end for 14. 15. end for 16. ; 17. Get through STSCN Construction Algorithm; 18. break 19. case UPDATE: 20. Extract data, spatial and time features to construct ; 21. Analyze the data structure to construct ; 22. Encapsulate , where , ; 23. Get through STSCN Construction Algorithm; 24. for 25. ; 26. for 27. ; 28. Update through STSCN Update Algorithm 29. end for 30. 31. end for 32. break 33. } 34. return |
3.3. Local Association Query Based on Correlation Network
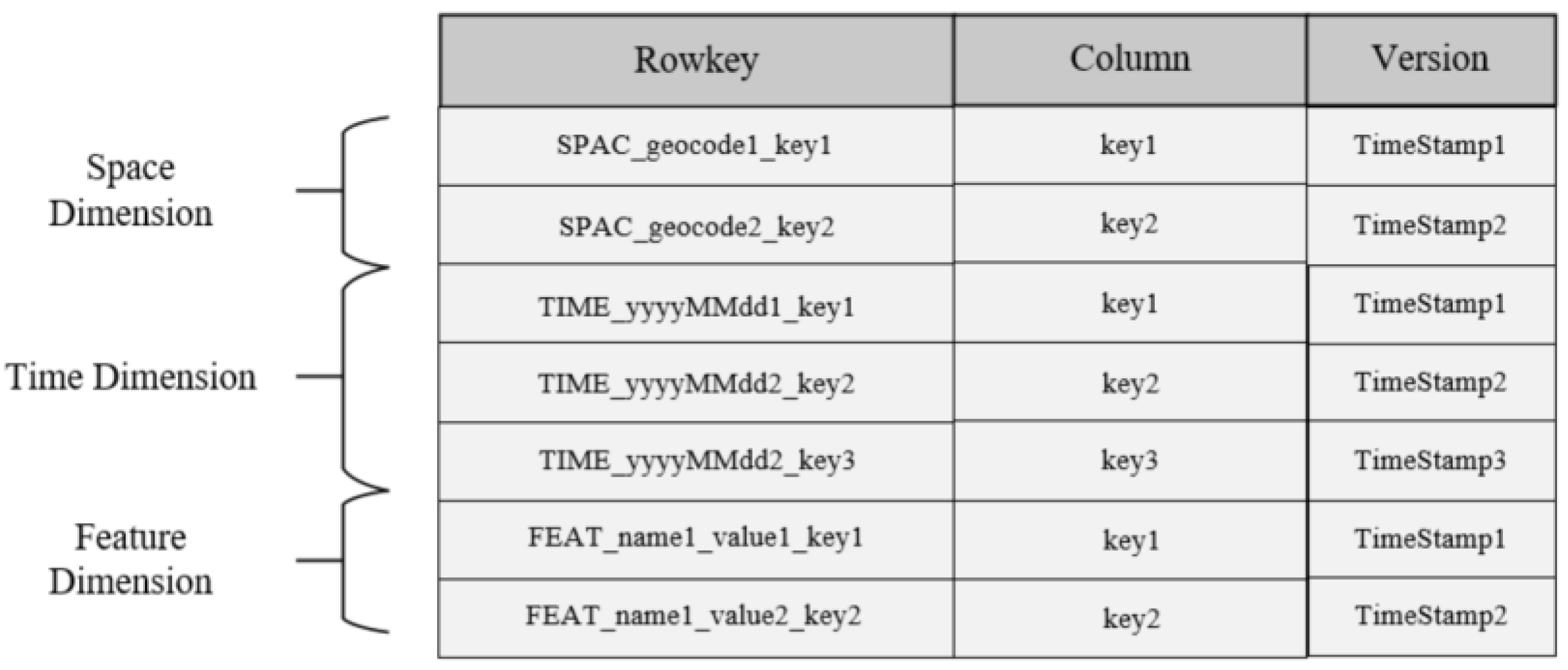
3.3.1. Spatio-Temporal Index
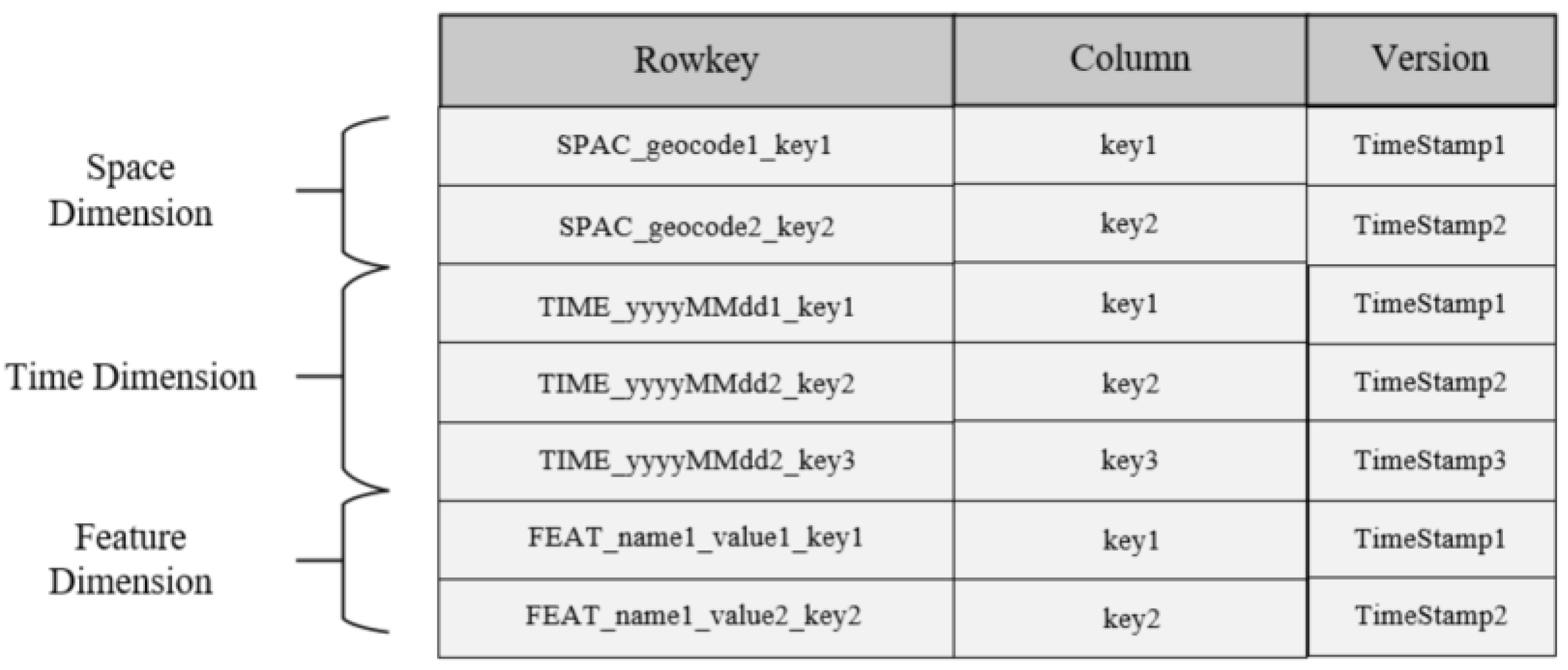
- Multi-dimensional feature index
- “SPAC_geocode1_key1” means that the value of the key corresponding to the grid whose spatial feature coding value is “geocode1” is key1;
- “TIME_yyyyMMdd1_key1” means that the value of the key corresponding to the grid whose time attribute value is “yyyyMMdd1” is key1;
- “FEAT_name1_value1_key1” means that the value of the data feature name1 is the grid data of value1, and the value of the key stored in the data table is key1;
- “SPAC”, ”TIME” and “FEAT” are used to distinguish spatial, time and data features.
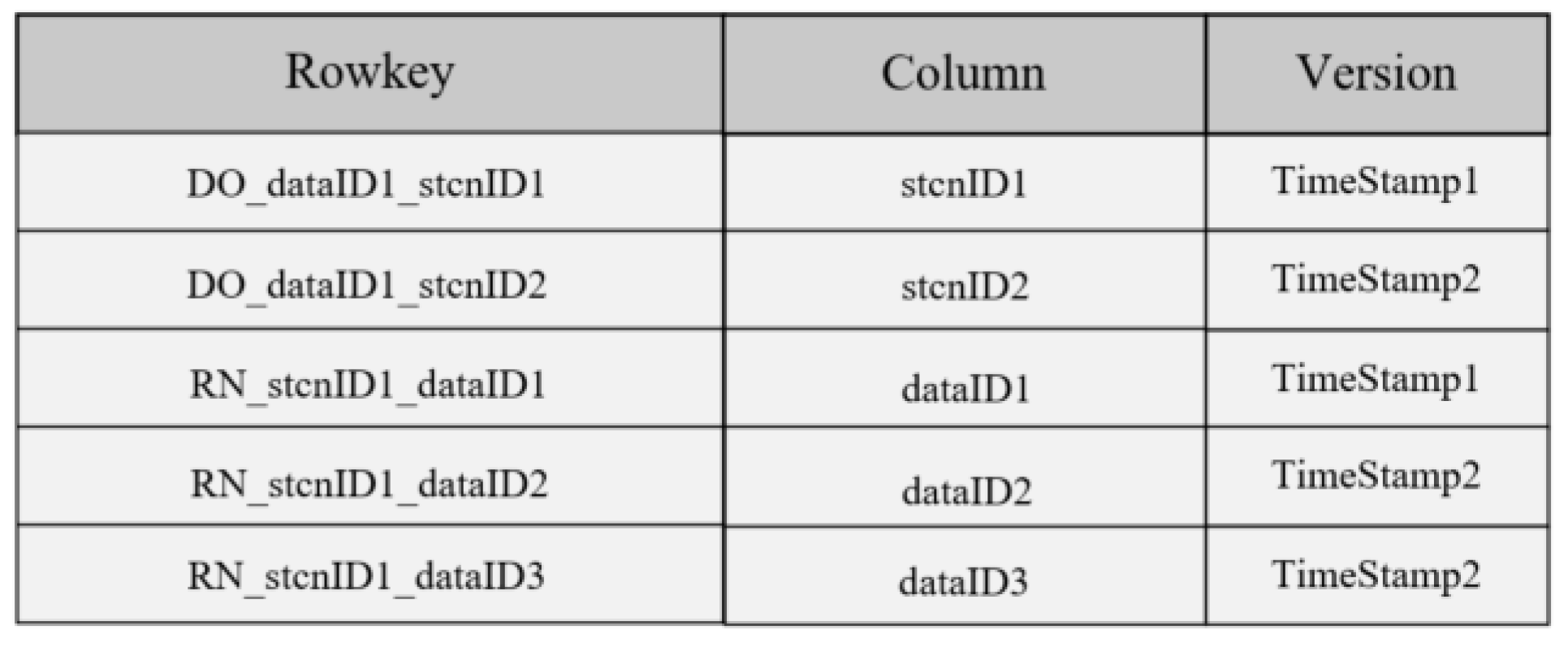
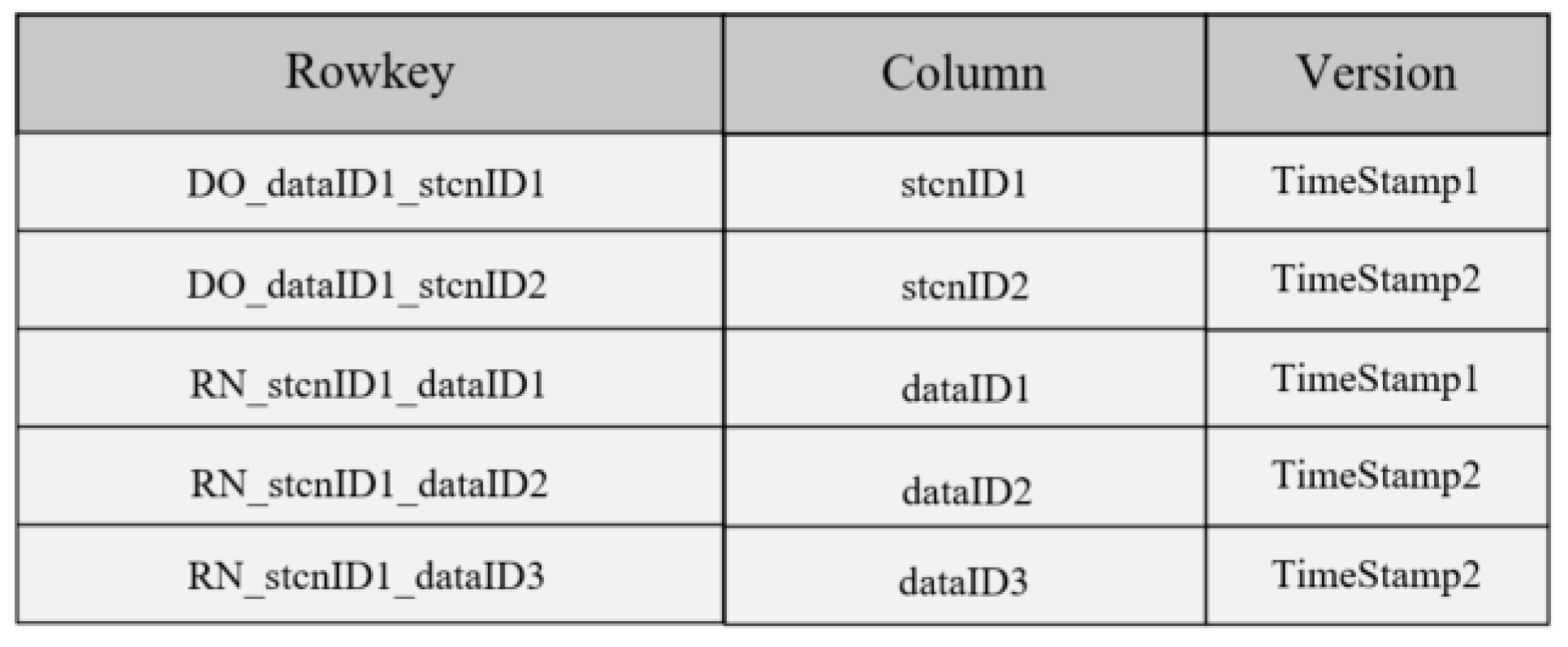
- Association index
- “DO_dataID1_stcnID1” indicates that the remote sensing data dataID1 belongs to the spatio-temporal correlation network stcnID1;
- “CN_stcnID1_dataID1” means that the spatio-temporal correlation network stcnID1 contains the remote sensing data dataID1.
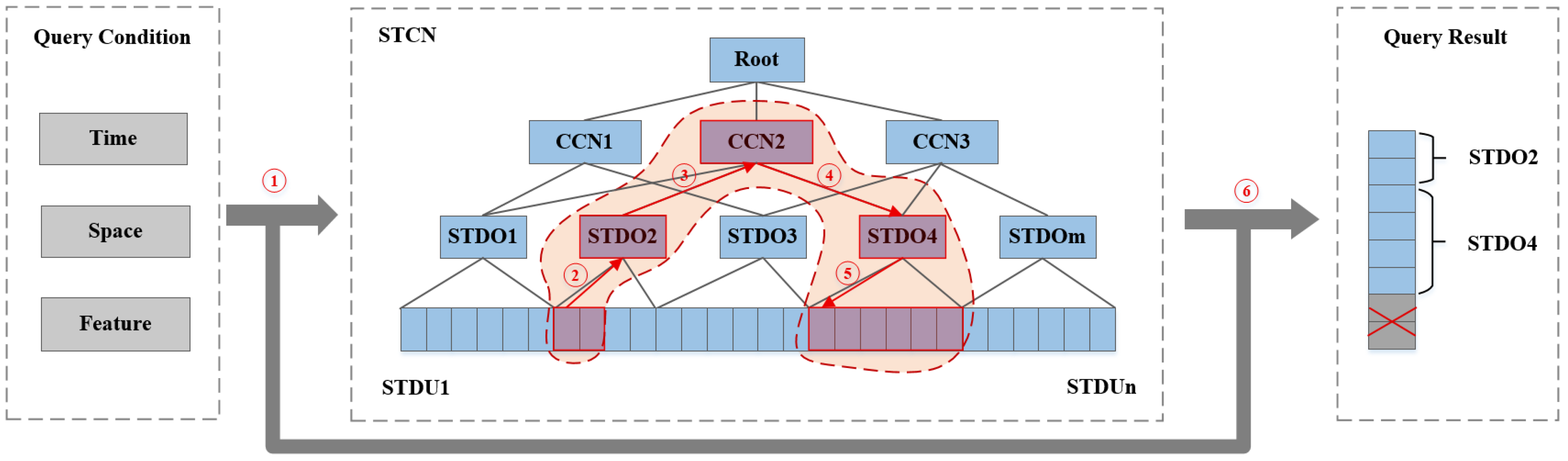
3.3.2. Local Association Query
- Extract the eligible candidate remote sensing dataset from the database according to query conditions;
- Query that the correlation network set consists of all the correlation network spatio-temporal data objects in belongs to;
- Encapsulate the query conditions as virtual spatio-temporal data objects ;
- Calculate the correlation degree between and the element in set , in turn;
- Put the spatio-temporal data objects in into the set of spatio-temporal data objects .
- Remove the remote sensing data in whose correlation degrees are less than , meaning that they do not meet the requirement, and sort spatio-temporal data objects by correlation degree.
| Algorithm 5. Local association query for remote sensing data. |
| Local Association Query for Remote Sensing Data |
| Input: Query conditions, threshold |
| Output: |
|
1. ; 2. Traverse data table to get a set of STDOs as ; 3. for 4. Get a set of STCCNs which belonging to as ; 5. 6. end for 7. Convert query conditions to a set of virtual STDOs as ; 8. for 9. Calculate ; 10. if 11. for 12. 13. if 14. ; 15. ; 16. end if 17. end for 18. end for 19. Sort the elements in by correlation degree; 20. return ;. |
4. Experiments
4.1. Experimental Materials
- Remote sensing satellite image data
- Three-dimensional terrain data
- Street view image data
- Lake distribution data of the Qinghai-Tibet Plateau
4.2. The STCN Construction Results
4.3. Local Association Query Results
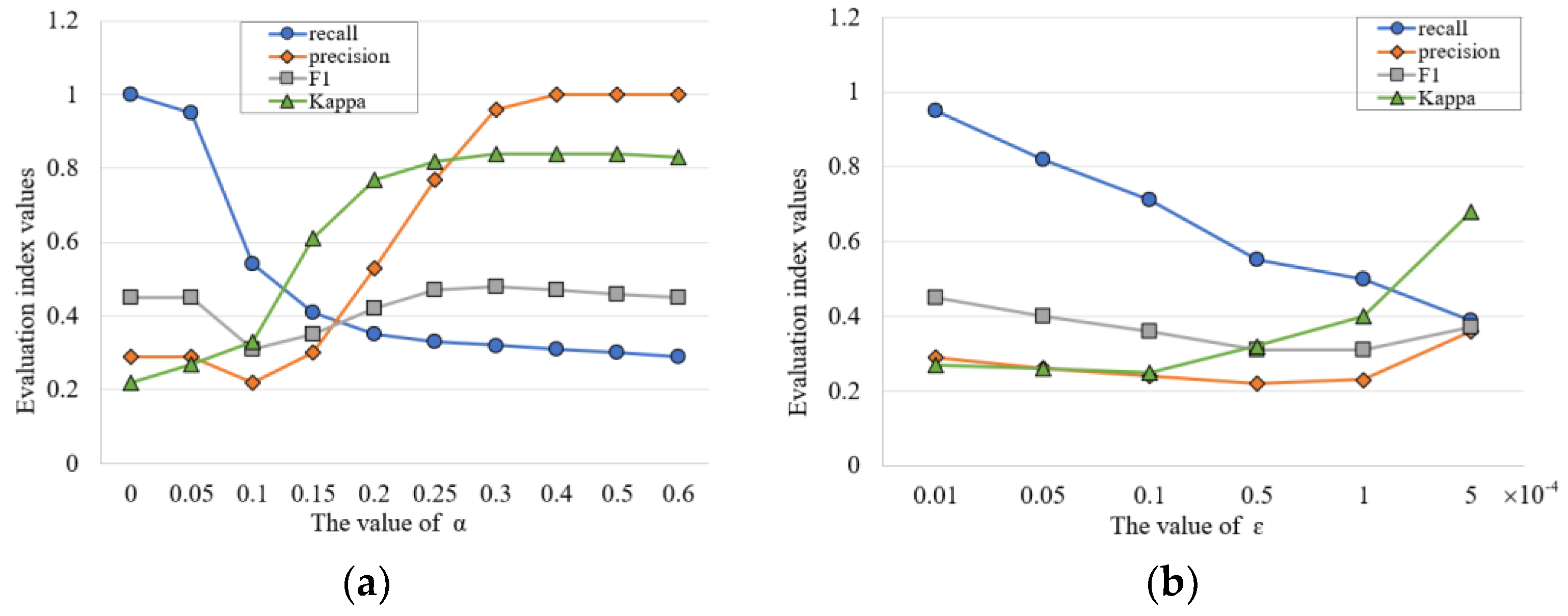
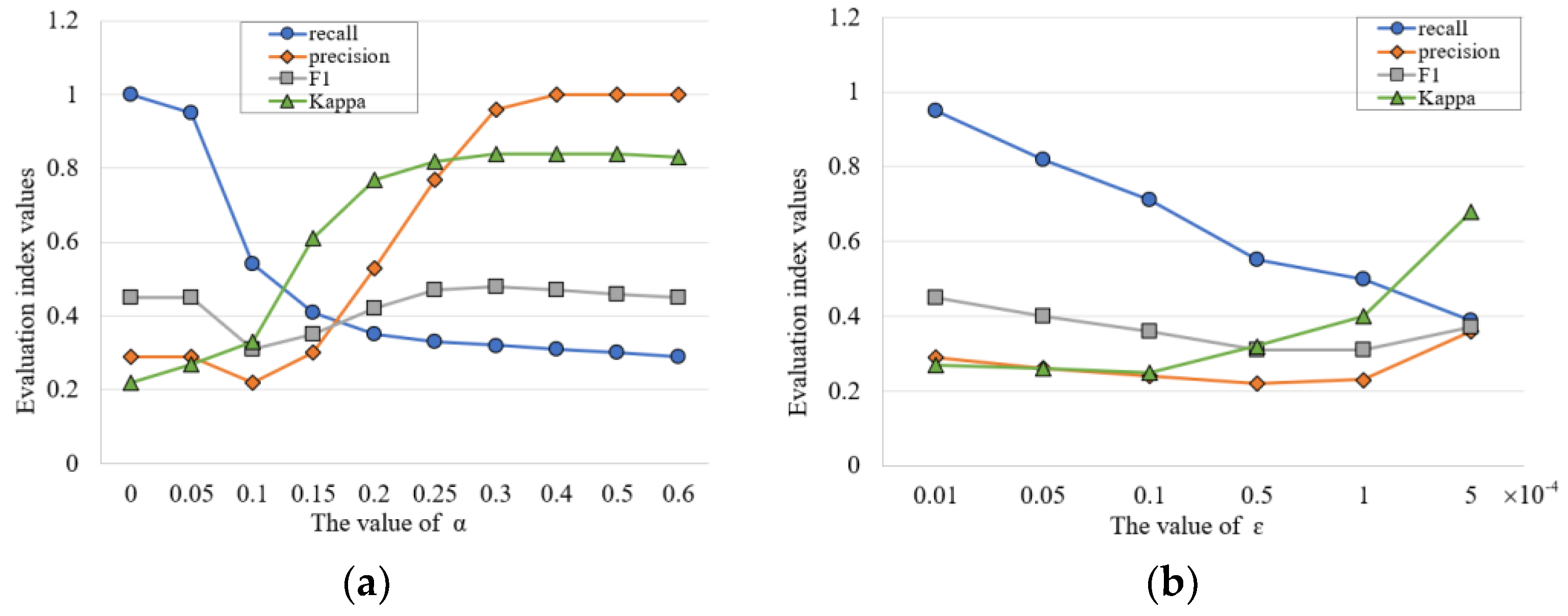
4.3.1. Association Query Evaluation
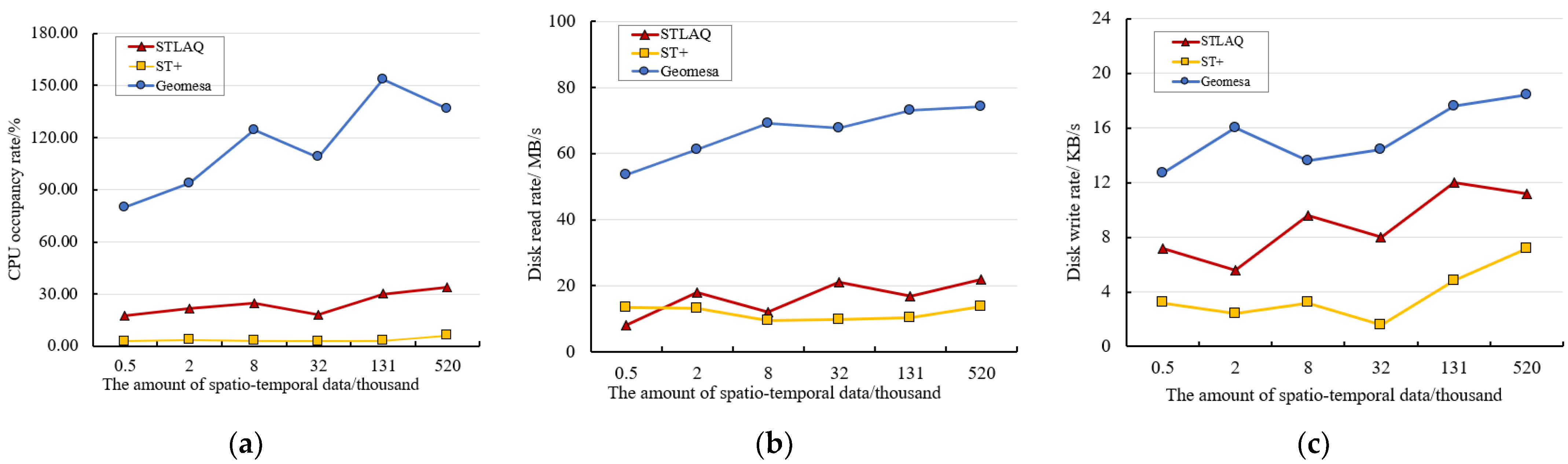
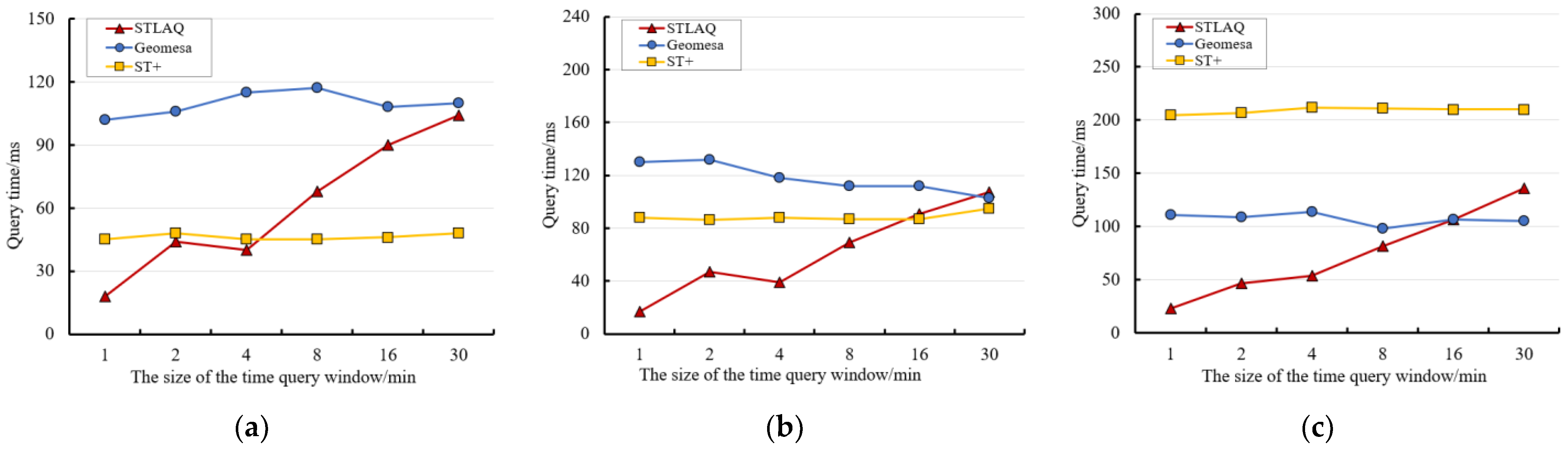
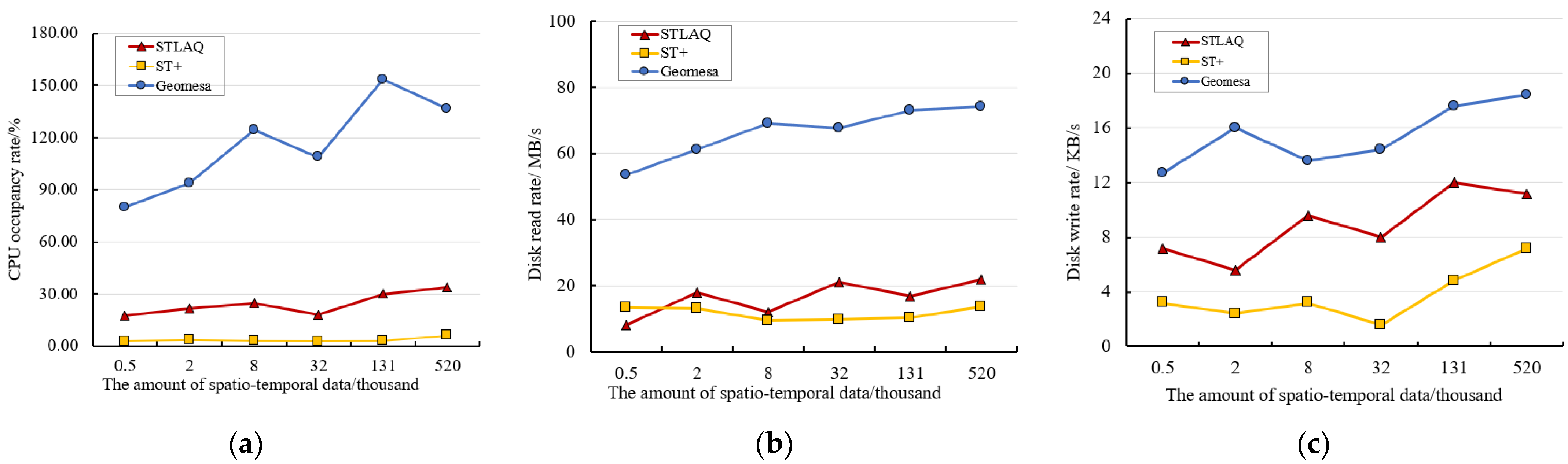
4.3.2. Association Query Performance
- Perform remote sensing data retrieval based on the STLAQ proposed in this article;
- Perform remote sensing data retrieval based on Geomesa, a distributed architecture for spatio-temporal fusion, proposed in [18]. We built indexes on the remote sensing data in time and event dimensions.
- Perform remote sensing data retrieval based on a customizable multi-dimensional index structure named ST+, proposed in [22].
- We perform spatial retrieval, time retrieval, and feature retrieval on tables that store different amounts of data, respectively.
- Then, we use query windows of different sizes to carry out retrieval in multiple dimensions such as space, time, and feature, on the table with the largest amount of stored data.
- Finally, we adopt two ways to query the combination of two dimensions, space-time and space-feature, to test the efficiency of STLAQ in multi-dimensional combination query.
- STLAQ has established indexes on both the features and association, and maps multi-dimensional features to a one-dimensional space. It avoids the drawbacks of a sharp increase in the scanning range during data retrieval as the data dimension increases;
- When constructing indexes on the time and feature dimensions, the sequential coding method ensures the locality of the data. This also brings about the insufficient matching accuracy when the scope of the query on these two dimensions expands, resulting in a decrease in retrieval performance.
- Firstly, under the premise of ensuring the continuity of time and attributing characteristics, we should optimize the structure of the index, improve the process of feature encoding, and achieve a more accurate match between the query range and the feature index;
- Secondly, we should introduce a parallel retrieval mechanism to improve data at the system level search efficiency.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, D.R.; Ma, J.; Shao, Z.F. Discussion on spatio-temporal big data and its application. Satell. Appl. 2015, 9, 7–11. [Google Scholar]
- Yang, C.; Huang, Q.; Li, Z.; Liu, K.; Hu, F. Big data and cloud computing: Innovation opportunities and challenges. Int. J. Digit. Earth 2017, 10, 13–53. [Google Scholar] [CrossRef] [Green Version]
- Wang, J. Spatio-temporal big data and its application in smart cities. Satell. Appl. 2017, 5, 10–17. [Google Scholar]
- Li, D. The intelligent processing and service of spatio-temporal big data. J. Geo-Inf. Sci. 2019, 21, 1825–1831. [Google Scholar]
- Li, D. Towards geo-spatial information science in big data era. Acta Geod. Cartogr. Sin. 2016, 45, 379–384. [Google Scholar]
- Zhang, Y. Research on the Theory and Key Technology of Global Spatial Information Muti-Grid with China’s Geographic Characteristics Considered; Huazhong University of Science & Technology: Hangzhou, China, 2014. [Google Scholar]
- Wang, S.; Zhong, Y.; Wang, E. An integrated GIS platform architecture for spatio-temporal big data. Future Gener. Comput. Syst. 2019, 94, 160–172. [Google Scholar] [CrossRef]
- Chen, X.; Wu, J.; Yuan, G. Research on the construction of spatio-temporal information cloud platform for big data. Geomat. Spat. Inf. Technol. 2020, 43, 138–140. [Google Scholar]
- Hua, Y.; Zhou, C. Description frame of data model of multi-granularity spatio-temporal object for pan-spatial information system. J. Geo-Inf. Sci. 2017, 19, 1142–1149. [Google Scholar]
- Huang, X. Research on Spatio-Temporal raster Data Modeling Based on Grid Mode; Zhejiang University: Hangzhou, China, 2015. [Google Scholar]
- Yuan, F. A New Strategy of Storage & Retrieval for Massive Tile Data of Remote Sensing Images; University of Electronic Science and Technology of China: Chengdu, China, 2013. [Google Scholar]
- Bentley, R.A.F.J.L. Quad trees a data structure for retrieval on composite keys. Acta Inform. 1974, 4, 1–9. [Google Scholar]
- Robinson, J.T. The K-D-B-tree: A search structure for large multidimensional dynamic indexes. In Proceedings of the 1981 ACM SIGMOD International Conference on Management of Data; ACM: New York, NY, USA, 1981; pp. 10–18. [Google Scholar]
- Guttman, A. R-Trees: A Dynamic Index Structure for Spatial Searching; ACM: New York, NY, USA, 1984; pp. 47–57. [Google Scholar]
- Zhao, N. A hybrid structure of spatial multilevel index based on grids and R-tree. Comput. Technol. Dev. 2009, 19, 91–94. [Google Scholar]
- Kamel, I.; Falout, S.; Hilbert, C. Hilbert R-tree: An improved R-tree using fractals. In Proceedings of the 20th Very Large Databases, Santiago, Chile, 12–15 September 1994; pp. 500–509. [Google Scholar]
- Yang, Y. Tile quadtree and filling curve realizing massive terrain dataset management. Comput. Eng. Appl. 2016, 52, 192–196. [Google Scholar]
- Hughes, J.N.; Annex, A.; Eichelberger, C.N.; Fox, A.; Hulbert, A.; Ronquest, M. GeoMesa: A distributed architecture for spatio-temporal fusion. In Geospatial Informatics, Fusion, and Motion Video Analytics V; International Society for Optics and Photonics: Baltimore, MD, USA, 20 April 2015. [Google Scholar]
- Zhao, X.Y.; Huang, X.D.; Qiao, J.L. A spatio-temporal index based on skew spatial coding and r-tree. J. Comput. Res. Dev. 2019, 56, 666–676. [Google Scholar]
- Xu, J.F.; Tan, Y.L. Optimization of multidimensional index query mechanism based on HBase. J. Comput. Appl. 2020, 40, 571–577. [Google Scholar]
- Qian, B.Z. Research on Linked Spatial Index Based on LSM-Tree; Zhejiang University: Hangzhou, China, 2020. [Google Scholar]
- Zhao, Y.H.; Lü, L.; Xu, Q. A multidimensional retrieval strategy for massive spatio-temporal data. Sci. Surv. Mapp. 2020, 45, 203–208. [Google Scholar]
- Wu, Y.H.; Cao, X.F. Hilbert code index method for spatiotemporal data of virtual battlefield environment. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 1403–1411. [Google Scholar]
- Tang, N.; Zhu, Z.H.; Li, J.J. Temporal-spatial phase point moving object data indexing: PM-Tree. Chin. J. Comput. 2021, 44, 579–593. [Google Scholar]
- Wu, Y.; Chen, L.; Xiong, W.; Zhong, Z.N.; Jing, N. Multi-source geospatial data correlation model for efficient retrieval. Chin. J. Comput. 2014, 9, 1999–2010. [Google Scholar]
- Liu, P.F.; Cui, T.J. Research progress in geographic data association. J. Tianjin Norm. Univ. (Nat. Sci. Ed.) 2019, 39, 10–15. [Google Scholar]
- Wu, Y. Research on Key Techniques of Entity Relationship Association Analysis Based on Graph; National Defense University: Changsha, China, 2014. [Google Scholar]
- Xu, Y.J.; Tan, C.G. Research on the organization and application of spatio-temporal data. Surv. Mapp. Bull. 2017, 2, 98–101. [Google Scholar]
- Li, P.Y.; Pan, H.W.; Li, Q. Top-k query method of medical image based on relational graph model. Comput. Technol. Dev. 2009, 19, 91–94. [Google Scholar]
- Shi, Y.; Zhan, M.; Yin, L. Research on associated organization and analysis of target-oriented multi-source heterogeneous data. Bull. Surv. Mapp. 2015, 1, 102–104. [Google Scholar]
- Lü, X.; Cheng, C.; Gong, J.; Guan, L. Review of data storage and management technologies for massive remote sensing data. Sci. China Technol. Sci. 2011, 41, 1561–1573. [Google Scholar] [CrossRef]
- Zheng, W.U.; Chengming, L.I.; Pengda, W.U.; Jianming, S.H.E.N.; Wei, S.U.N. Integerated storage and management of vector and raster data based on Oracle database. Acta Geod. Cartogr. Sin. 2017, 46, 639–648. [Google Scholar]
- Wootton, C. ISO 8601 Date Format Output. Dev. Qual. Metadata 2007, 419–420. [Google Scholar]
- Douglas, B.W.; West, J.L. Introduction to Graph Theory; Machinery Industry Press: Beijing, China, 2006. [Google Scholar]
- Shao, S.; Lou, W.; Yan, L. Optimization of Algorithm of Similarity Measurement in High-Demensional Data. Comput. Technol. Dev. 2011, 2, 7–10. [Google Scholar]
- Wang, T. High-Dimensional Data Clustering Based on Hypergraph Partition; Lanzhou University: Lanzhou, China, 2016. [Google Scholar]
- Jia, H.J.; Ding, S.F.; Shi, Z.Z. Approximate weighted kernel k-means for large-scale spectral clustering. J. Softw. 2015, 26, 2836–2846. [Google Scholar]
- Yan, W. Research on Image Feature Extraction Method; Northwestern Polytechnical University: Xian, China, 2007. [Google Scholar]
- Wang, C. Study on Nondestructive Detection Method of Potato Grading Based on Multi-Source Information Fusion; Huazhong Agricultural University: Wuhan, China, 2014. [Google Scholar]
- Qing, Y.; Song, W. Remote sensing image feature extraction and selection and its application in image classification. Sci. Serveying Mapp. 2008, 33, 176–199. [Google Scholar]
- Chen, P. Research on Principal Component Analysis and Its Application in Feature Extraction; Shanxi Normal University: Linfen, China, 2014. [Google Scholar]
- Cao, M. Research on Intelligent Recognition and Extraction of Feature Elements Based on Remote Sensing Images; Changan University: Xian, China, 2015. [Google Scholar]
- Xu, D. Research on the Key Techniques of Multi-Source Remote Sensing Big Data Management under the Cloud Computing Environment; University of Chinese Academy of Sciences: Beijing, China, 2018. [Google Scholar]
- Zhang, M.; Yu, J. Fuzzy partitional clustering algorithms. J. Softw. 2004, 15, 858–869. [Google Scholar]
- Zhou, K. Theoretical and Applied Research on Fuzzy c-Mean Clustering and Its Cluster Validation; Hefei University of Technology: Hefei, China, 2014. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spatio-temporal Data Model | |
|---|---|
| Space-time Reference | |
| Space reference | WGS84/EGM96 |
| Time reference | UTC+8:00 |
| Structure Description | |
| Multi-scale Model | tile pyramid model |
| Storage Structure | key: hilbertcode_type_time data column: tile storage; meta column: property storage, feature storage |
| Index Structure | multi-dimensional feature index association index |
| Feature Description | |
| Time Feature | 2011:03:15 19:00:04 |
| Spatial Feature | [22.9998611, 23.9998611, 24.0001389, 25.0001389] |
| Data Feature | Minimum = 229.000, Maximum = 656.000, Mean = 412.612, StdDev = 32.007, … |
| Target | Lake Data in a Certain Geographic Area | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Query conditions | Spatial region | |||||||||
| Time region | Unlimited | |||||||||
| Feature query condition | Grayscale mean, standard deviation, grayscale histogram entropy, energy, direction gradient histogram, etc. | |||||||||
| Query result | Satellite image data |  |  |  |  |  |  |  |  |  |
| 3D terrain data |  |  |  |  |  |  |  |  |  | |
| Streetview image data |  |  |  |  |  |  |  | |||
| Lake distribution vector data |  |  |  |  |  |  |  |  |  | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, L.; Su, X.; Hu, Y.; Tai, X.; Fu, K. A Spatio-Temporal Local Association Query Algorithm for Multi-Source Remote Sensing Big Data. Remote Sens. 2021, 13, 2333. https://doi.org/10.3390/rs13122333
Zhu L, Su X, Hu Y, Tai X, Fu K. A Spatio-Temporal Local Association Query Algorithm for Multi-Source Remote Sensing Big Data. Remote Sensing. 2021; 13(12):2333. https://doi.org/10.3390/rs13122333
Chicago/Turabian StyleZhu, Lilu, Xiaolu Su, Yanfeng Hu, Xianqing Tai, and Kun Fu. 2021. "A Spatio-Temporal Local Association Query Algorithm for Multi-Source Remote Sensing Big Data" Remote Sensing 13, no. 12: 2333. https://doi.org/10.3390/rs13122333
APA StyleZhu, L., Su, X., Hu, Y., Tai, X., & Fu, K. (2021). A Spatio-Temporal Local Association Query Algorithm for Multi-Source Remote Sensing Big Data. Remote Sensing, 13(12), 2333. https://doi.org/10.3390/rs13122333