2.1. Morphological and Geometrical Feature-Based
For morphological and geometrical feature-based methods, the morphological and geometrical features are used as the criteria for building extraction. The morphological and geometrical features usually contain shapes, lines, length and width, etc. As morphological and geometrical features are simple and easy to be modeled for buildings in visual, morphological and geometrical features have been widely used and achieved large amounts of research success. A novel adaptive morphological attribute profile based on object boundary constraint was proposed in [
29] for building extraction from high-resolution remote-sensing images. Their model was tested on groups of images from different sensors and showed good results. A building extraction approach was proposed in [
30], which is based on morphological attributes’ relationships among different morphological features (e.g. shape, size). They assessed their method on three VHR datasets and demonstrated good results. A method that combined CNN and morphological filters was presented in [
40] for building extraction from VHR images. In their method, the morphological features were used for final extraction filtering after the extraction of CNN. The experiments proved that their method is effective. The morphological features and support vector machine (SVM) were used in [
31] for building extraction from VHR images. They tested their method on WorldView-2 and Sentinal-2 images and demonstrated good F1-scores.
Although morphological and geometrical features are simple and easy for using, these kinds of features usually suffer from the problems of the rigid model and the sensitivity to image resolution, occlusions’ interference, etc.
2.2. Manually Designed Feature-Based
For manually designed feature-based methods, the researchers usually use transformations to extract features and then combine the extracted features with classifiers for the final building extraction task. The typical classifiers include SVM, Hough Forest, TensorVoting, Random Forest, etc. Since the manually designed features have shown superiority to morphological features in robustness to occlusions, brightness changing, resolution changing and imaging perspective changing, etc., the manually designed feature-based methods became popular in the past 20 years. A building extraction approach from high-resolution optical satellite images was proposed in [
34] and achieved quite good and impressive results. In their method, the SVM, Hough transformation and perceptual grouping were combined. The Hough transformation was used for delineating circular-shape buildings, while the perceptual grouping strategy was used for constructing the building boundaries through integrating the detected lines. A hybrid approach to building extraction was proposed in [
35], which used a template matching strategy for automatically computing the relative height of buildings. After estimating the relative height of buildings, the SVM-based classifier was employed to recognize the buildings and non-buildings, thus extracting the buildings. They tested on images of WorldView-2 and achieved high building-detection accuracy.
The manually designed feature-based methods usually can extract the classical features of the buildings, and the buildings can be extracted with quite high accuracy through combining the classifiers. However, the models’ extendibility is still weak due to the brightness variations, occlusions, etc. The main reason may be that the manually designed features cannot cover all the building appearance situations in the images, resulting in incomplete considerations for special situations.
2.3. Deep Learning-Based
Recently, deep learning-based building extraction methods have made great breakthroughs. The classical models usually extract the buildings with an end-to-end strategy, i.e., input a target image and output a building extraction result image. The benefits of the deep learning models lay in the great powers of automatic feature learning and representing. In addition, the deep learning-based methods also can obtain results with fast processing speed through using GPUs. The processing time of deep learning-based building extraction methods is usually only several seconds to produce the final results (sometimes even within only 1 second), while the unsupervised and manually designed methods usually take dozens of minutes (or even several hours) for processing one image.
A single path-based CNN model was proposed in [
41] for simultaneously extracting roads and buildings from remote-sensing images. After the extraction of the CNN model, the low-level features of roads and buildings were also combined to improve performance. They tested their model on two challenging datasets and demonstrated good extraction results. A Building-A-Nets for building extraction was proposed in [
42,
43], in which the adversarial network architecture was applied and they jointly trained their model of generator and discriminator. They tested on open available datasets and achieved good results. A building extraction model of fully convolutional network (FCN) was proposed in [
43]. To further improve the final results, the Conditional Random Fields were employed. They obtained high F1-scores and the intersection of union (IoU) scores in their experiments. A new deep learning model based on ResNet was proposed in [
44], which used the specially designed guided filters to improve their results and remove the salt-and-pepper noise. The method illustrated good performance in the tests. A deep CNN model was proposed in [
45], which integrated activation from multiple layers and introduced a signed distance function for representing building boundary outputs. They demonstrated superior performance on test datasets. A deep learning model was proposed in [
46], which aimed to conquer the problems of sensitivity to unavoidable noise and interference, and the insufficient use of structure information. They showed good results on the test datasets. A Siamese fully convolutional network was proposed in [
27] for building extraction and provided an open dataset called WHU that contained multiple data sources.
Now the WHU dataset is quite famous in open available building extraction datasets and has been used in much building extraction research. An EU-Net for building extraction was proposed in [
47] that designed a dense spatial pyramid pooling module. They achieved quite good results in the test datasets. In [
48], a DE-Net that consisted of four modules (the inception-style down-sampling module, the encoding module, the compressing module and the densely up-sampling module). They tested the model on an open available dataset and a self-built dataset called Suzhou. The test results showed good performance of their model. Liu et al. proposed a building extraction model that used a spatial residual inception module to obtain multiscale contexts [
49]. In addition, they used depthwise separable convolutions and convolution factorization to further improve the computational efficiency. In [
13], a JointNet was proposed to extract both large and small targets using a wide receptive field, and it used focal loss function to further improve the road extraction performance. In [
50], an FCN was proposed to use multiscale aggregation of feature pyramids to enhance the scale robustness. After the segmentation results were obtained, a polygon regularization approach was further used for vectorizing and polygonizing the segmentation results. In [
40], a multifeature CNN was proposed to extract building outlines. To improve the boundary regularity, they also combined morphological filtering in the post-processing. They achieved good results in the experiments. In [
51], a CNN model was proposed that used an improved boundary-aware perceptual loss for building extraction, and their experimental results were very promising. The DR-Net, a dense residual network presented in [
1] showed promising results in the test datasets. The attention-gate-based encoder-decoder network was used in [
5] for building extraction, and illustrated good performance in both an open available dataset and the dataset built by themselves.
Except for the methods specially designed for building extraction from remote-sensing images, the segmentation methods for natural scenes are also suitable for building extraction from remote-sensing images. Thus, we also give a brief introduction about segmentation methods for natural scenes. The classical segmentation methods based on deep learning include FCN [
52], PSPNet [
20], U-Net [
53,
54] , DANet [
55] and Residual U-Net [
53] etc. In addition to the classical segmentation methods, many recent semantic segmentation methods have been proposed. Chen et al. proposed a DeepLab for semantic segmentation, and they achieved good experimental results [
56]. Zhong et al. proposed a Squeeze-and-Attention Network for semantic segmentation. They achieved good results on two challenging public datasets. Zhang et al. used an encoding part that extracts multiscale contextual features for semantic segmentation, and they showed good results in the experiments [
57]. Yu et al. proposed a CPNet (Context Prior Network) for learning robust context features in semantic segmentation tasks, and they showed good results in the experiments [
58].
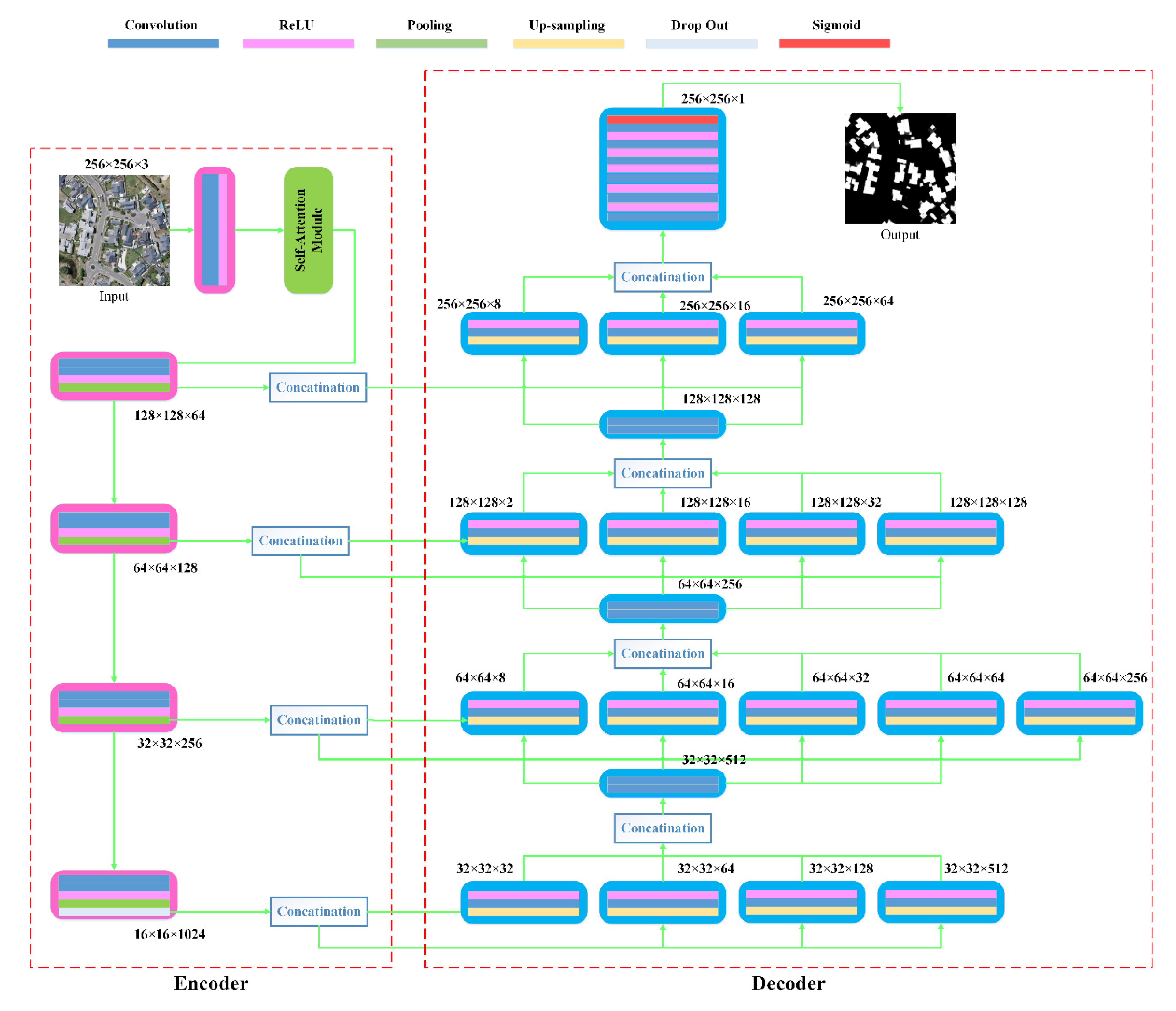
In general, the deep learning-based methods have achieved great progress in building extraction from remote-sensing images. However, their main shortcoming is the requirement of a large amount of labelling work. On the other hand, the research about a more powerful decoding part of the designed models is still insufficient in our reviews.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}