
Intelligent Recognition Method of Low-Altitude Squint Optical Ship Target Fused with Simulation Samples



Abstract
:1. Introduction
- (1)
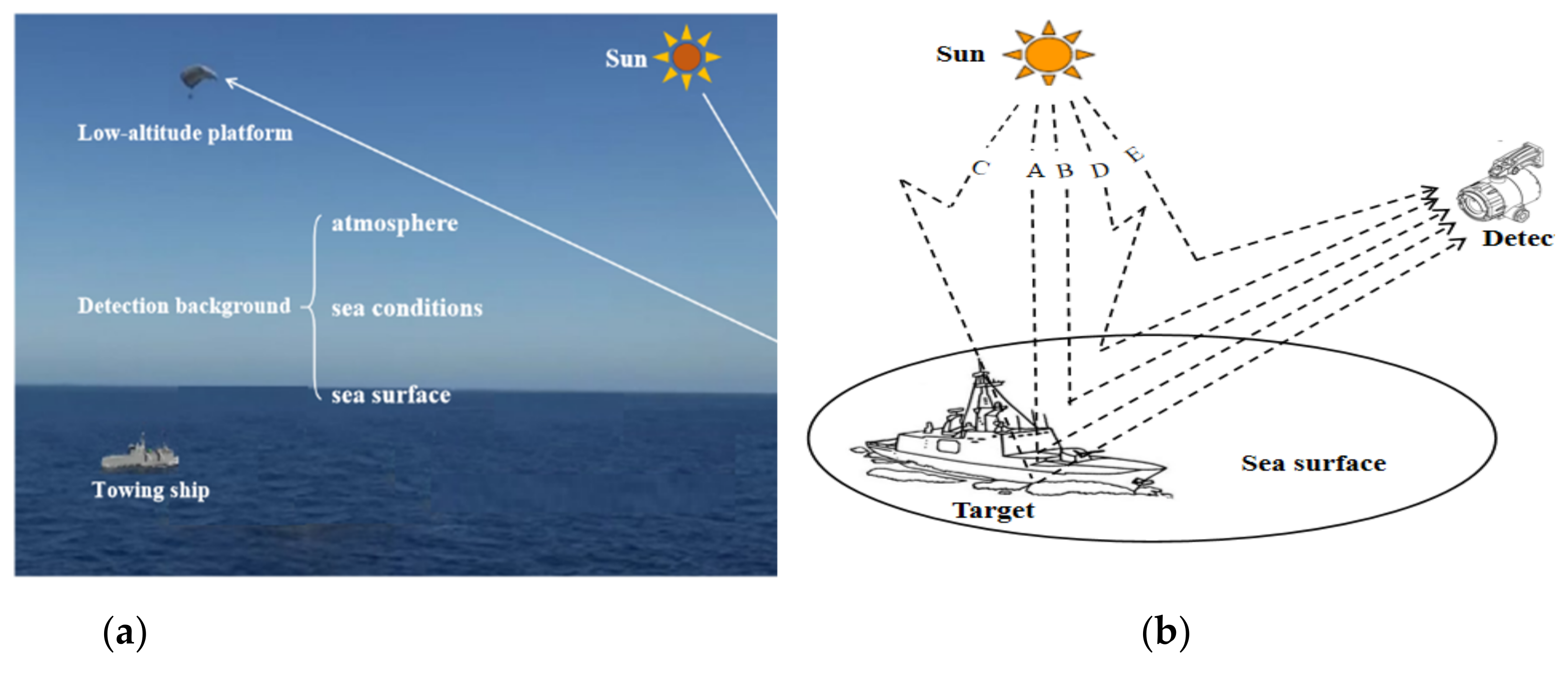
- For the imaging simulation of low-altitude squint visible light ship targets, we considered their geometric and spectral characteristics, the ocean background, and the atmospheric transmission link to complete their optical imaging simulation modeling.
- (2)
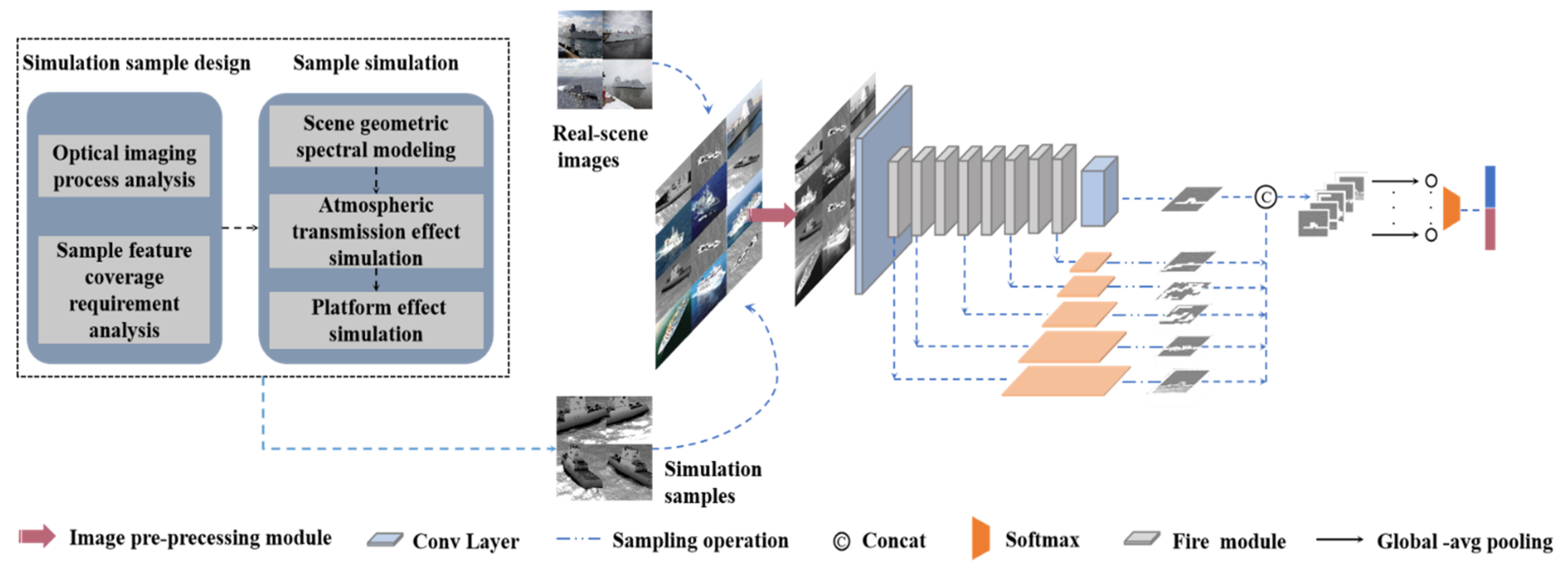
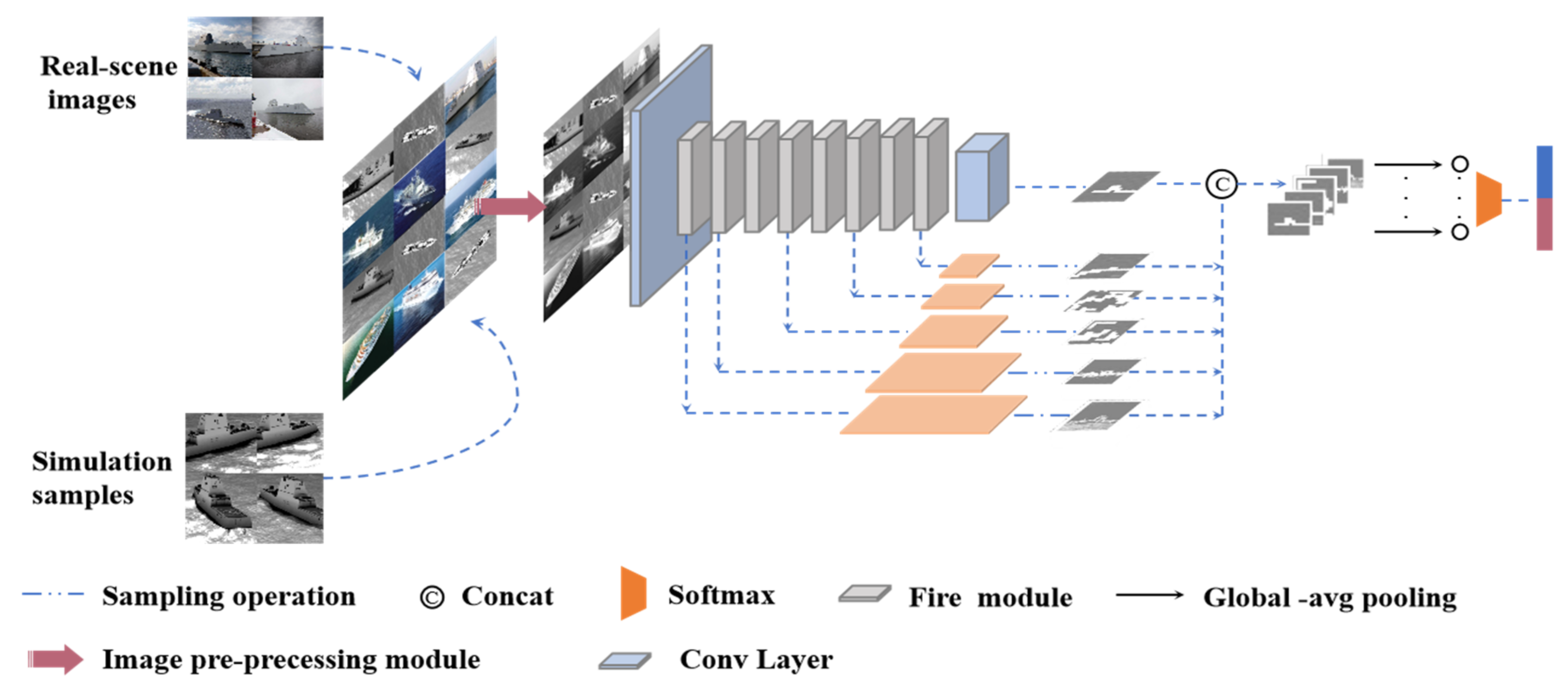
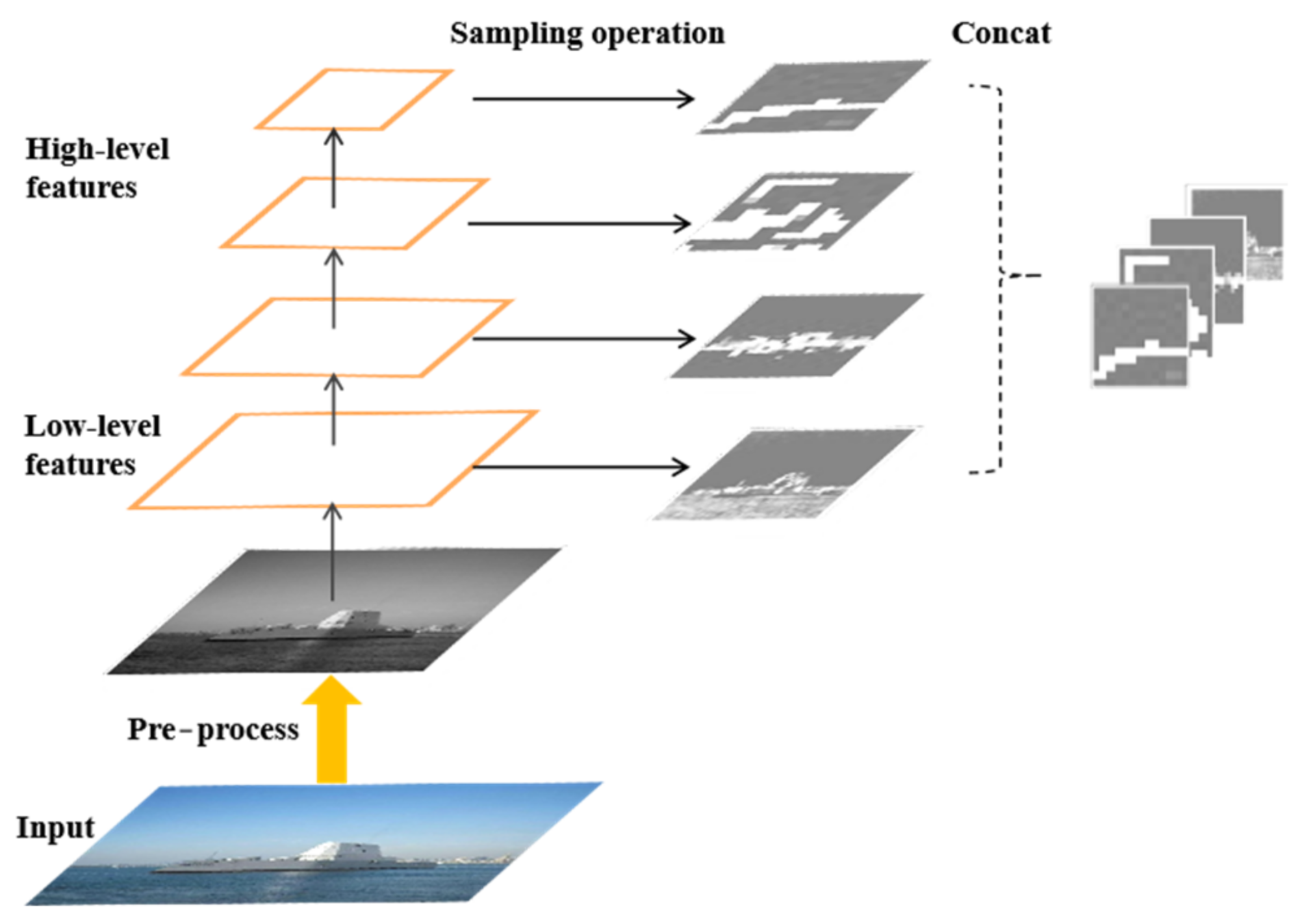
- We present a new deep neural network to accomplish low-altitude squint optical ship target classification based on SqueezeNet. We modified SqueezeNet with feature fusion (FF-SqueezeNet), using the complementary output of the shallow layer and the deep layer features as the final output to enrich the feature content. The overall framework is illustrated in Figure 1.
- (3)
- For specific ship target type recognition, we used a mixed-scene dataset expanded by simulation samples during training. The classification accuracy of our proposed FF-SqueezeNet was 91.85%, which demonstrates the effectiveness of the proposed method.
2. Materials and Methods
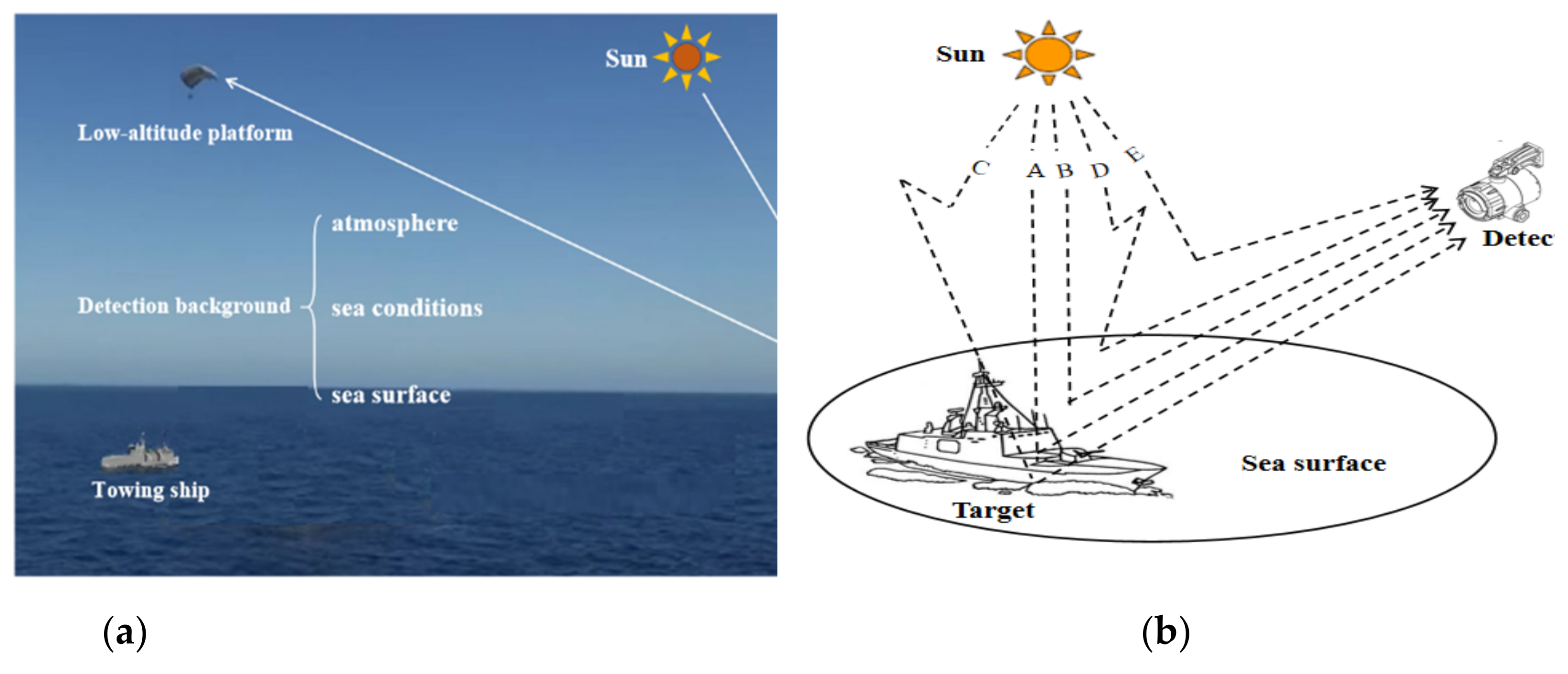
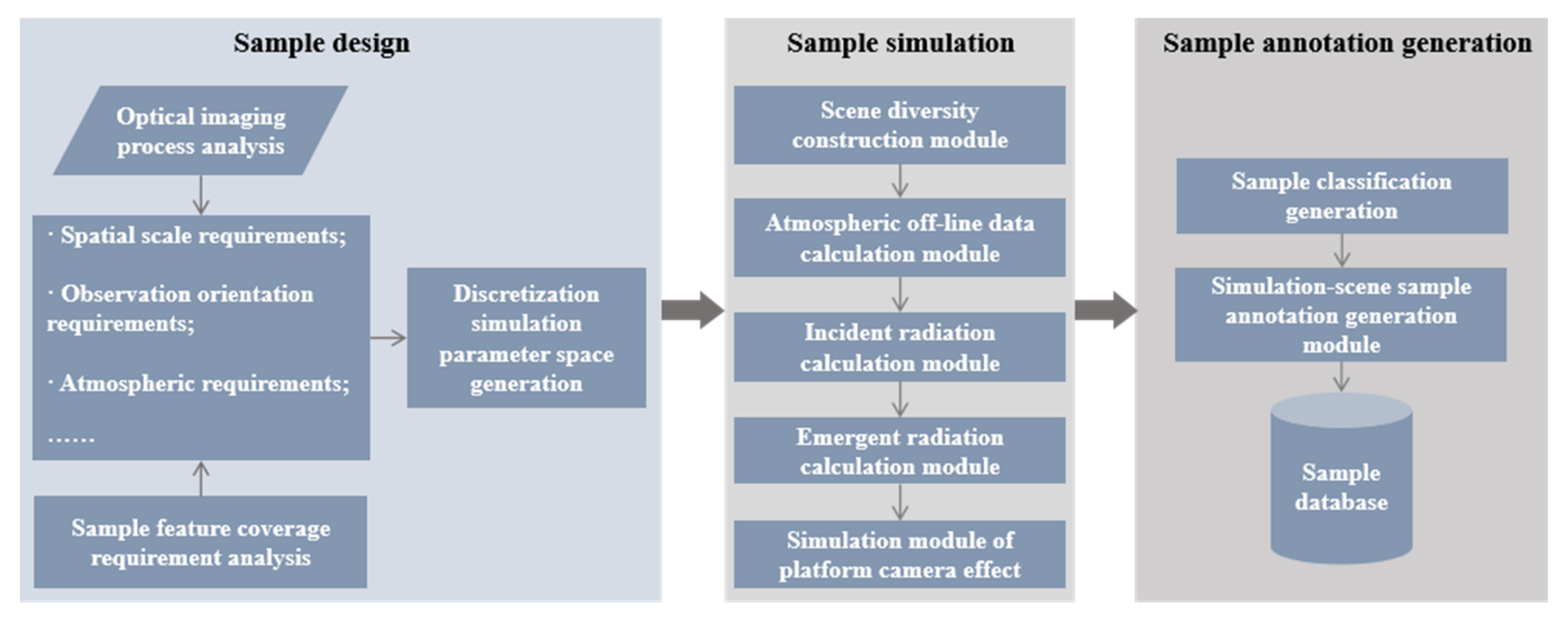
2.1. Optical Imaging Simulation of Low-Altitude Squint Multi-Angle Ship Target
2.1.1. Simulation Principle of Visible Light Imaging for Low-Altitude Squint Ship Targets
2.1.2. Simulation Image Generation of Ship Target in Visible Light Band with Low-Altitude Squint
2.2. Modified Design of SqueezeNet Classification Network Structure Based on Simulation Images
3. Experimental Details and Data Exploitation
3.1. Experimental Environment and Index Design
3.2. Dataset
3.2.1. Real-Scene Ship Dataset
3.2.2. Mixed-Scene Ship Dataset
4. Results and Discussion
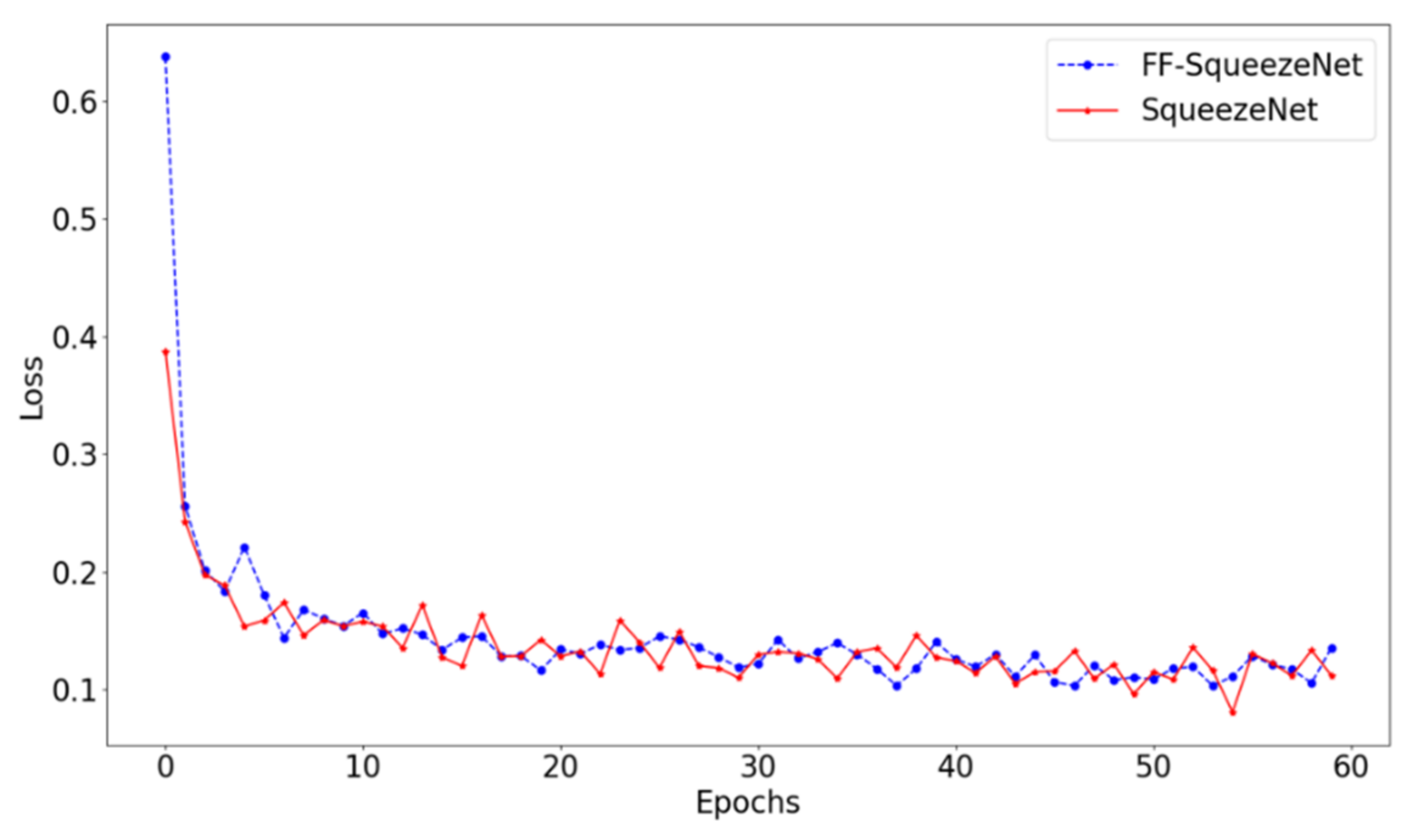
4.1. Performance of FF-SqueezeNet
4.2. Improving the Performance of FF-SqueezeNet with Simulation-Scene Images
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Velotto, D.; Soccorsi, M.; Lehner, S. Azimuth ambiguities removal for ship detection using full polarimetric X-band SAR data. IEEE Trans. Geosci. Remote Sens. 2013, 52, 76–88. [Google Scholar] [CrossRef]
- Xi, Y.; Lang, H.; Tao, Y.; Huang, L.; Pei, Z. Four-component model-based decomposition for ship targets using PolSAR data. Remote Sens. 2017, 9, 621. [Google Scholar] [CrossRef] [Green Version]
- Farhadi, A.; Redmon, J. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. NIPS 2012, 1, 1097–1105. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer Press: Zurich, Switzerland, 2014. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. Comput. Sci. 2014, 48, 135–148. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.X.; Li, H.L.; Zhang, G.Q.; Zhu, W.P.; Liu, L.Y.; Liu, J.; Wu, N.J. CCNet: A high-speed cascaded convolutional neural network for ship detection with multispectral images. Infrared. Millim. Waves 2019, 38, 290–295. [Google Scholar]
- Lei, F.; Wang, W.; Zhang, W. Ship extraction using post CNN from high resolution optical remotely sensed images. In IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference; IEEE Press: Chengdu, China, 2019. [Google Scholar] [CrossRef]
- Liu, W.; Ma, L.; Chen, H. Arbitrary-oriented ship detection framework in optical remote-sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 937–941. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget, A.J.; Mirza, M.; Xu, B.; Warde, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 3, 2672–2680. [Google Scholar]
- Adam, A.G.; Scott, D.B. DIRSIG5: Next-Generation Remote Sensing Data and Image Simulation Framework. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 4818–4833. [Google Scholar] [CrossRef]
- Tian, Y.L.; Li, X.; Wang, K.F.; Wang, F.Y. Training and Testing Object Detectors with Virtual Images. IEEE CAA J. Autom. Sin. 2018, 5, 539–546. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.B. Feasibility Study on Application of Simulated Images in Deep Learning. J. Biomech. 2019, 99, 109544. [Google Scholar] [CrossRef]
- Li, X.; Wang, K.F.; Tian, Y.L.; Yan, L.; Wang, F.Y. The ParallelEye Dataset: Constructing Large-Scale Artificial Scenes for Traffic Vision Research. In Proceedings of the International Conference on Intelligent Transportation Systems, Yokahama, Japan, 30 August 2018; pp. 2072–2084. [Google Scholar] [CrossRef]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 852–863. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Sun, J. Mobile-nets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:physics/1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.Y.; Zhou, X.Y.; Lin, M.X.; Sun, J. Shuffle-net: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding. ICLR 2015, 56, 3–7. [Google Scholar] [CrossRef]
- Ren, D.Q.; Du, J.T.; Hua, F.; Yang, Y.; Han, L. Analysis of different atmospheric physical parameterizations in COAWST modeling system for the Tropical Storm Nock-ten application. Nat. Hazards 2016, 82, 903–920. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, J.L. Real-Time Synthesis and Rendering of Ocean. Water. ATI Research Technical Report Marlboro; Citeseerx: Princeton, NJ, USA, 2005; pp. 121–126. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. ECCV 2014, 8689, 818–833. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In International Conference on Computer Vision; IEEE Press: Barcelona, Spain, 2011; pp. 2018–2025. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.L.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. IJCV Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Cui, Z.; Zhang, M.; Cao, Z.; Cao, C. Image data augmentation for SAR sensor via generative adversarial nets. IEEE Access 2019, 7, 42255–42268. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference Learning Representations (ICLR), San Diego, CA, USA, 5–8 May 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutakever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. JMLR 2014, 15, 1929–1958. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Image Type | Number of Training Set Images | Number of Test Set Images |
|---|---|---|---|
| Warship | Real-scene image | 430 | 256 |
| Simulation-scene image | 0 | 0 | |
| Civilian ships | Real-scene image | 430 | 755 |
| Simulation-scene image | 0 | 0 | |
| Total | 860 | 1011 | |
| Class | Image Type | Number of Training Set Images | Number of Test Set Images |
|---|---|---|---|
| Specific target | Real-scene image | 25 | 15 |
| Simulation-scene image | 150 | 0 | |
| Non-specific target | Real-scene image | 25 | 15 |
| Simulation-scene image | 150 | 0 | |
| Total | 350 | 30 | |
| Algorithm Model | Accuracy |
|---|---|
| Original SqueezeNet | 84.31% |
| FF-SqueezeNet | 88.54% |
| Algorithm | Dataset | Accuracy |
|---|---|---|
| Traditional algorithm (KNN) | Real sub-dataset of mixed-scene ship dataset | 61.54% |
| Mixed-scene ship dataset | 78.41% | |
| Original SqueezeNet | Real sub-dataset of mixed-scene ship dataset | 76.24% |
| Mixed-scene ship dataset | 87.96% | |
| FF-SqueezeNet | Real sub-dataset of mixed-scene ship dataset | 83.63% |
| Mixed-scene ship dataset | 91.85% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Xiao, Q.; Zhang, Y.; Ni, W.; Yang, Z.; Li, L. Intelligent Recognition Method of Low-Altitude Squint Optical Ship Target Fused with Simulation Samples. Remote Sens. 2021, 13, 2697. https://doi.org/10.3390/rs13142697
Liu B, Xiao Q, Zhang Y, Ni W, Yang Z, Li L. Intelligent Recognition Method of Low-Altitude Squint Optical Ship Target Fused with Simulation Samples. Remote Sensing. 2021; 13(14):2697. https://doi.org/10.3390/rs13142697
Chicago/Turabian StyleLiu, Bo, Qi Xiao, Yuhao Zhang, Wei Ni, Zhen Yang, and Ligang Li. 2021. "Intelligent Recognition Method of Low-Altitude Squint Optical Ship Target Fused with Simulation Samples" Remote Sensing 13, no. 14: 2697. https://doi.org/10.3390/rs13142697
APA StyleLiu, B., Xiao, Q., Zhang, Y., Ni, W., Yang, Z., & Li, L. (2021). Intelligent Recognition Method of Low-Altitude Squint Optical Ship Target Fused with Simulation Samples. Remote Sensing, 13(14), 2697. https://doi.org/10.3390/rs13142697