Meta-FSEO: A Meta-Learning Fast Adaptation with Self-Supervised Embedding Optimization for Few-Shot Remote Sensing Scene Classification



Abstract
:
1. Introduction
- (1)
- We proposed a meta-learning algorithm called Meta-FSEO to improve the generalization performance of classification models in multiple urban conditions under a few-shot scenario. The proposed Meta-FSEO allows quick generalization to the data from unknown cities by training on the data of known cities according to task-level samples.
- (2)
- We designed a self-supervised comparison module that effectively balances the requirements for feature classification tasks between multiple images collected at different times and places.
- (3)
- We designed a loss function that combines the contrast loss and the cross-entropy loss weighting, aiming to achieve high-accuracy generalization capabilities.
2. Materials and Methods
2.1. Transfer Learning
2.2. Self-Supervised Transformers
2.3. Meta-Learning Background Knowledge
2.4. The Proposed Method
| Algorithm 1: Meta-FSEO Algorithm. |
| Input: |
| Base model function and initialisation parameters , Self-supervised Embedding Optimization fuction and parameters , step size hyperparameters , , |
| 1: Randomly initialize |
| 2: while not done do |
| 3: Sample batch of tasks |
| 4: for all do |
| 5: for in rang() do |
| 6: Sample datapoints from |
| 7: Evaluate using and in Equation (1) |
| 8: Inner loop optimization in support sets: |
| 9: end for |
| 10: Sample datapoints and from |
| 11: Compute with transformer net |
| 12: |
| 13: Update using and in Equation (4) |
| 14: end for |
| 15: end while |
3. Results
3.1. Datasets and Preprocessing
3.2. Hyperparameters Details
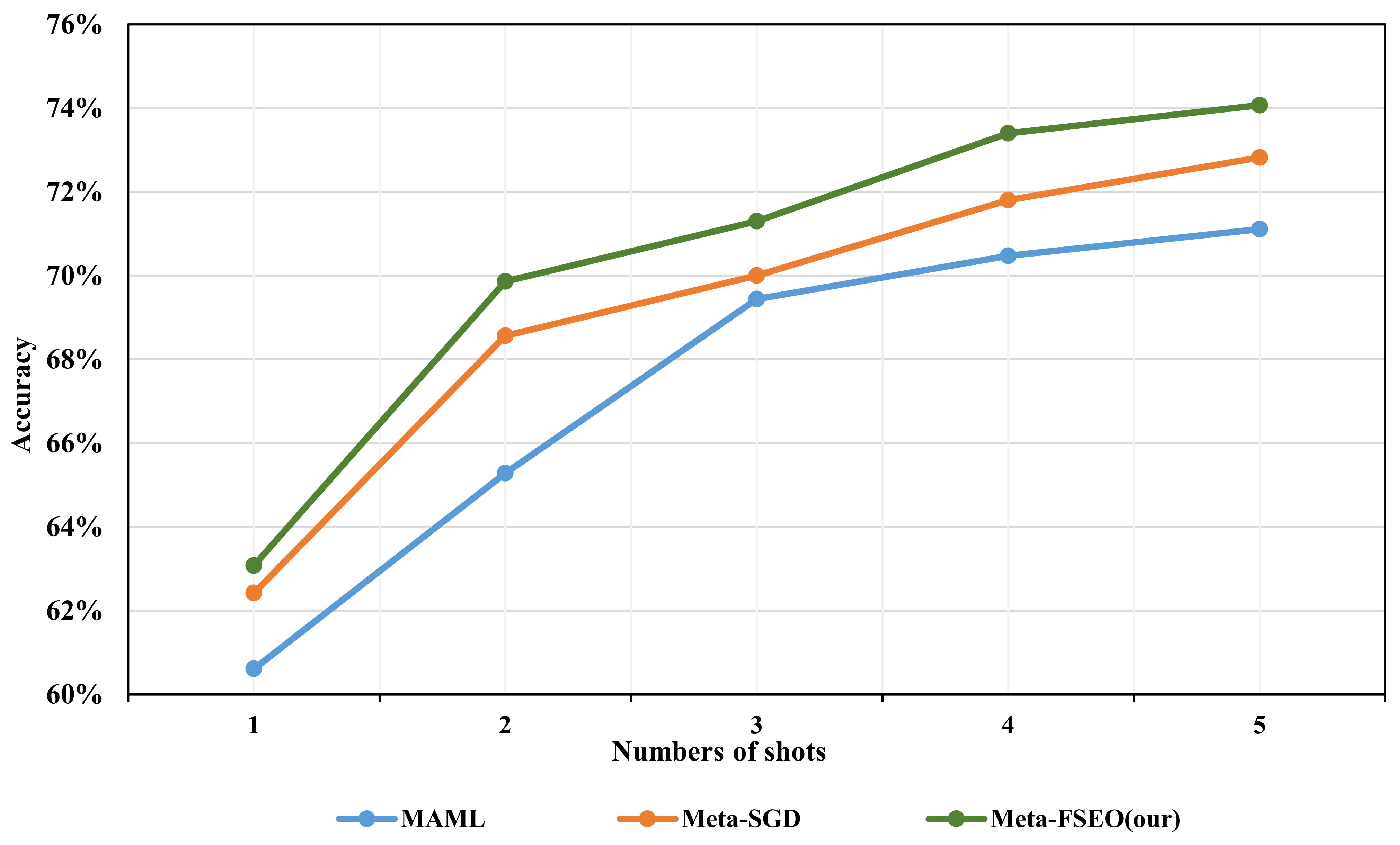
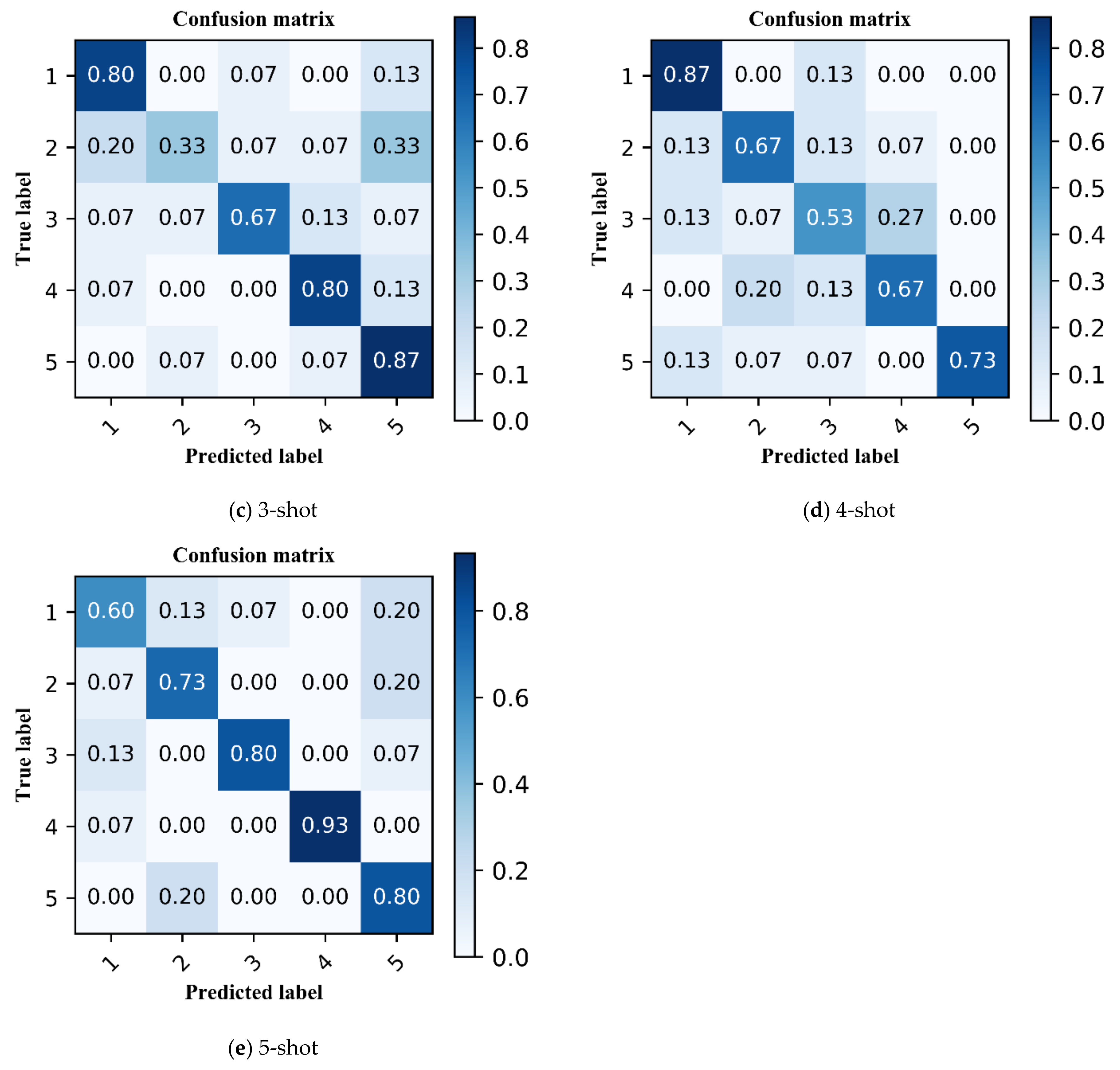
3.3. Classification Accuracy
4. Discussion
4.1. The Effect of the Transformers in Network Architecture
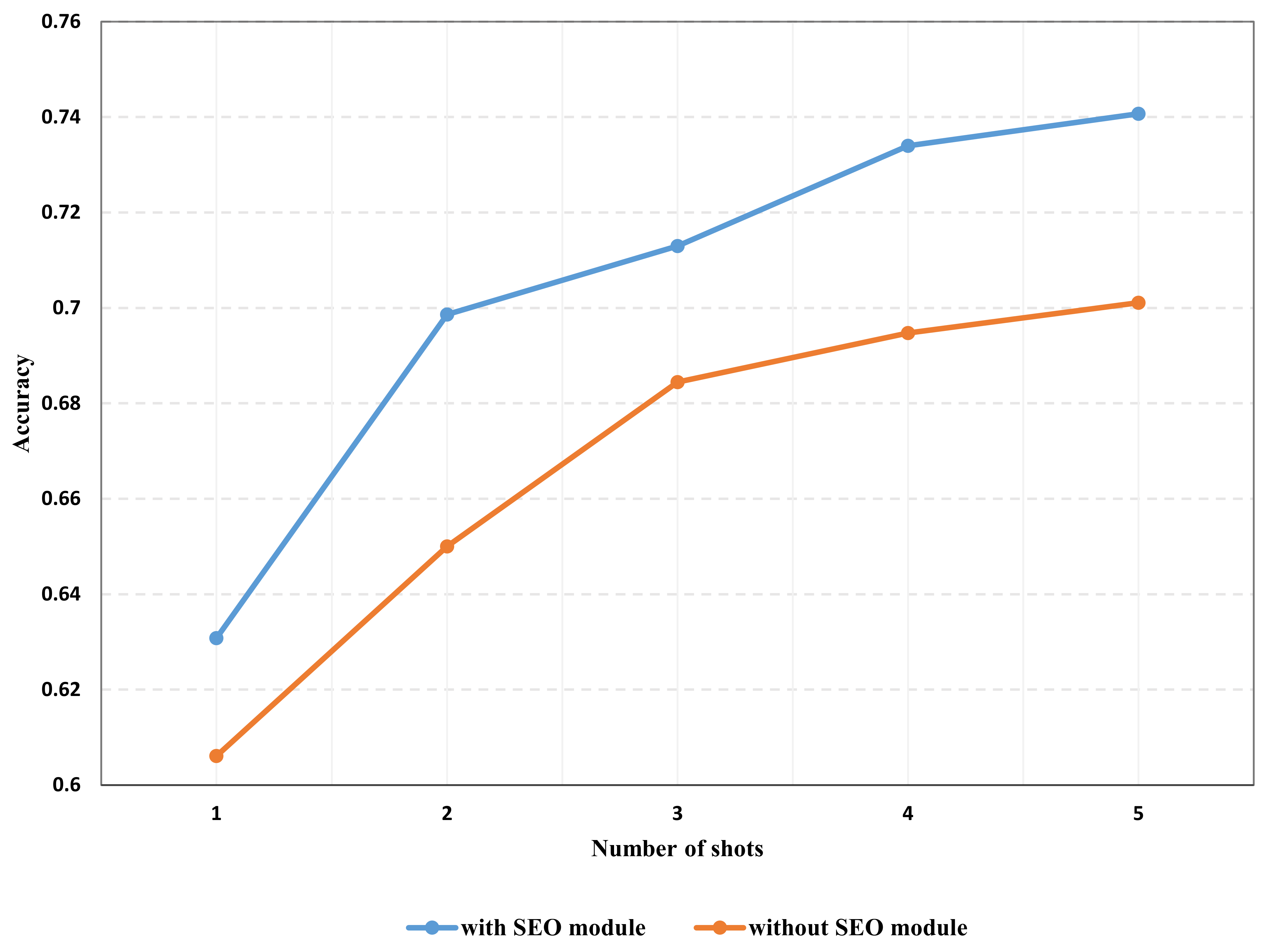
4.2. Ablation Analysis
4.3. Loss Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Shao, Z.; Cai, J.; Fu, P.; Hu, L.; Liu, T. Deep Learning-Based Fusion of Landsat-8 and Sentinel-2 Images for a Harmonized Surface Reflectance Product. Remote Sens. Environ. 2019, 235, 111425. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Zhang, R.; Shao, Z.; Huang, X.; Wang, J.; Li, D. Object Detection in UAV Images via Global Density Fused Convolutional Network. Remote Sens. 2020, 12, 3140. [Google Scholar] [CrossRef]
- Yao, H.; Liu, Y.; Wei, Y.; Tang, X.; Li, Z. Learning from Multiple Cities: A Meta-Learning Approach for Spatial-Temporal Prediction. In Proceedings of the The World Wide Web Conference on-WWW ’19; ACM Press: San Francisco, CA, USA, 2019; pp. 2181–2191. [Google Scholar]
- Li, W.; Wang, Z.; Wang, Y.; Wu, J.; Wang, J.; Jia, Y.; Gui, G. Classification of High-Spatial-Resolution Remote Sensing Scenes Method Using Transfer Learning and Deep Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1986–1995. [Google Scholar] [CrossRef]
- Huang, Z.; Dumitru, C.O.; Pan, Z.; Lei, B.; Datcu, M. Classification of Large-Scale High-Resolution SAR Images With Deep Transfer Learning. IEEE Geosci. Remote Sens. Lett. 2021, 18, 107–111. [Google Scholar] [CrossRef] [Green Version]
- Pires de Lima, R.; Marfurt, K. Convolutional Neural Network for Remote-Sensing Scene Classification: Transfer Learning Analysis. Remote Sens. 2020, 12, 86. [Google Scholar] [CrossRef] [Green Version]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning; Precup, D., Teh, Y.W., Eds.; PMLR: Sydney, NSW, Australia, 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Chen, W.-Y.; Liu, Y.-C.; Kira, Z.; Wang, Y.-C.; Huang, J.-B. A Closer Look at Few-Shot Classification. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-Shot Learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. arXiv 2020, arXiv:2004.05439. [Google Scholar]
- Raghu, A.; Raghu, M.; Bengio, S.; Vinyals, O. Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Hochreiter, S.; Younger, A.S.; Conwell, P.R. Learning to Learn Using Gradient Descent. In Artificial Neural Networks—ICANN 2001; Dorffner, G., Bischof, H., Hornik, K., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2130, pp. 87–94. ISBN 978-3-540-42486-4. [Google Scholar]
- Li, H.; Cui, Z.; Zhu, Z.; Chen, L.; Zhu, J.; Huang, H.; Tao, C. RS-MetaNet: Deep Metametric Learning for Few-Shot Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2020, 1–12. [Google Scholar] [CrossRef]
- Ruswurm, M.; Wang, S.; Korner, M.; Lobell, D. Meta-Learning for Few-Shot Land Cover Classification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–16 June 2020; IEEE: Piscataway Township, NJ, USA; pp. 788–796. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Erhan, D.; Courville, A.; Bengio, Y.; Vincent, P. Why Does Unsupervised Pre-Training Help Deep Learning? In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics; Teh, Y.W., Titterington, M., Eds.; PMLR: Sardinia, Italy, 2010; Volume 9, pp. 201–208. [Google Scholar]
- Saikia, T.; Brox, T.; Schmid, C. Optimized Generic Feature Learning for Few-Shot Classification across Domains. arXiv 2020, arXiv:2001.07926. [Google Scholar]
- Chen, Z.; Zhang, T.; Ouyang, C. End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images. Remote Sens. 2018, 10, 139. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Zhang, L.; Du, B.; Zhang, L.; Shi, Q. Iterative Reweighting Heterogeneous Transfer Learning Framework for Supervised Remote Sensing Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2022–2035. [Google Scholar] [CrossRef]
- Chen, X.; Xie, S.; He, K. An Empirical Study of Training Self-Supervised Visual Transformers. arXiv 2021, arXiv:2104.02057. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Srinivas, A.; Lin, T.-Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 16519–16529. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; p. 11. [Google Scholar]
- Ren, M.; Triantafillou, E.; Ravi, S.; Snell, J.; Swersky, K.; Tenenbaum, J.B.; Larochelle, H.; Zemel, R.S. Meta-Learning for Semi-Supervised Few-Shot Classification. arXiv 2018, arXiv:1803.00676. [Google Scholar]
- Dhillon, G.S.; Chaudhari, P.; Ravichandran, A.; Soatto, S. A Baseline for Few-Shot Image Classification. arXiv 2020, arXiv:1909.02729. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-Learning with Memory-Augmented Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning; Balcan, M.F., Weinberger, K.Q., Eds.; PMLR: New York, NY, USA, 2016; Volume 48, pp. 1842–1850. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-shot Learning. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 4077–4087. [Google Scholar]
- Antoniou, A.; Storkey, A.J. Learning to Learn by Self-Critique. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., dAlché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-Learning with Latent Embedding Optimization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-SGD: Learning to Learn Quickly for Few-Shot Learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Keskar, N.S.; Socher, R. Improving Generalization Performance by Switching from Adam to SGD. arXiv 2017, arXiv:1712.07628. [Google Scholar]
- Metz, L.; Maheswaranathan, N.; Cheung, B.; Sohl-Dickstein, J. Meta-Learning Update Rules for Unsupervised Representation Learning. arXiv 2019, arXiv:1804.00222. [Google Scholar]
- Schmitt, M.; Hughes, L.H.; Qiu, C.; Zhu, X.X. SEN12MS—A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion. arXiv 2019, arXiv:1906.07789. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Parameter |
|---|---|
| inner meta size a | 0.01 |
| meta step size | 0.01 |
| learning rate | 0.001 |
| weight decay | 0.0001 |
| balance parameter | 0.7 |
| iterations | 75,000 |
| epoch | 150 |
| Model | Backbone | 5-Way Accuracy | |
|---|---|---|---|
| 1-Shot | 5-Shot | ||
| Transfer Learning (fine-tuning) | 4-layer CNN | 35.20 0.603 | 53.90 0.720 |
| 4-layer CNN + Transformers | 35.86 0.554 | 54.79 0.690 | |
| MAML | 4-layer CNN | 60.02 0.495 | 69.44 0.460 |
| 4-layer CNN + Transformers | 60.61 0.488 | 70.00 0.488 | |
| Meta-SGD | 4-layer CNN | 61.22 0.486 | 71.11 0.486 |
| 4-layer CNN + Transformers | 61.72 0.486 | 72.48 0.446 | |
| Meta-FSEO (ours) | 4-layer CNN | 62.42 0.484 | 72.82 0.445 |
| 4-layer CNN + Transformers | 63.08 0.480 | 74.29 0.437 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Shao, Z.; Huang, X.; Cai, B.; Peng, S. Meta-FSEO: A Meta-Learning Fast Adaptation with Self-Supervised Embedding Optimization for Few-Shot Remote Sensing Scene Classification. Remote Sens. 2021, 13, 2776. https://doi.org/10.3390/rs13142776
Li Y, Shao Z, Huang X, Cai B, Peng S. Meta-FSEO: A Meta-Learning Fast Adaptation with Self-Supervised Embedding Optimization for Few-Shot Remote Sensing Scene Classification. Remote Sensing. 2021; 13(14):2776. https://doi.org/10.3390/rs13142776
Chicago/Turabian StyleLi, Yong, Zhenfeng Shao, Xiao Huang, Bowen Cai, and Song Peng. 2021. "Meta-FSEO: A Meta-Learning Fast Adaptation with Self-Supervised Embedding Optimization for Few-Shot Remote Sensing Scene Classification" Remote Sensing 13, no. 14: 2776. https://doi.org/10.3390/rs13142776
APA StyleLi, Y., Shao, Z., Huang, X., Cai, B., & Peng, S. (2021). Meta-FSEO: A Meta-Learning Fast Adaptation with Self-Supervised Embedding Optimization for Few-Shot Remote Sensing Scene Classification. Remote Sensing, 13(14), 2776. https://doi.org/10.3390/rs13142776