
A Novel Modeling Strategy of Weighted Mean Temperature in China Using RNN and LSTM


Abstract
:1. Introduction
2. Methods
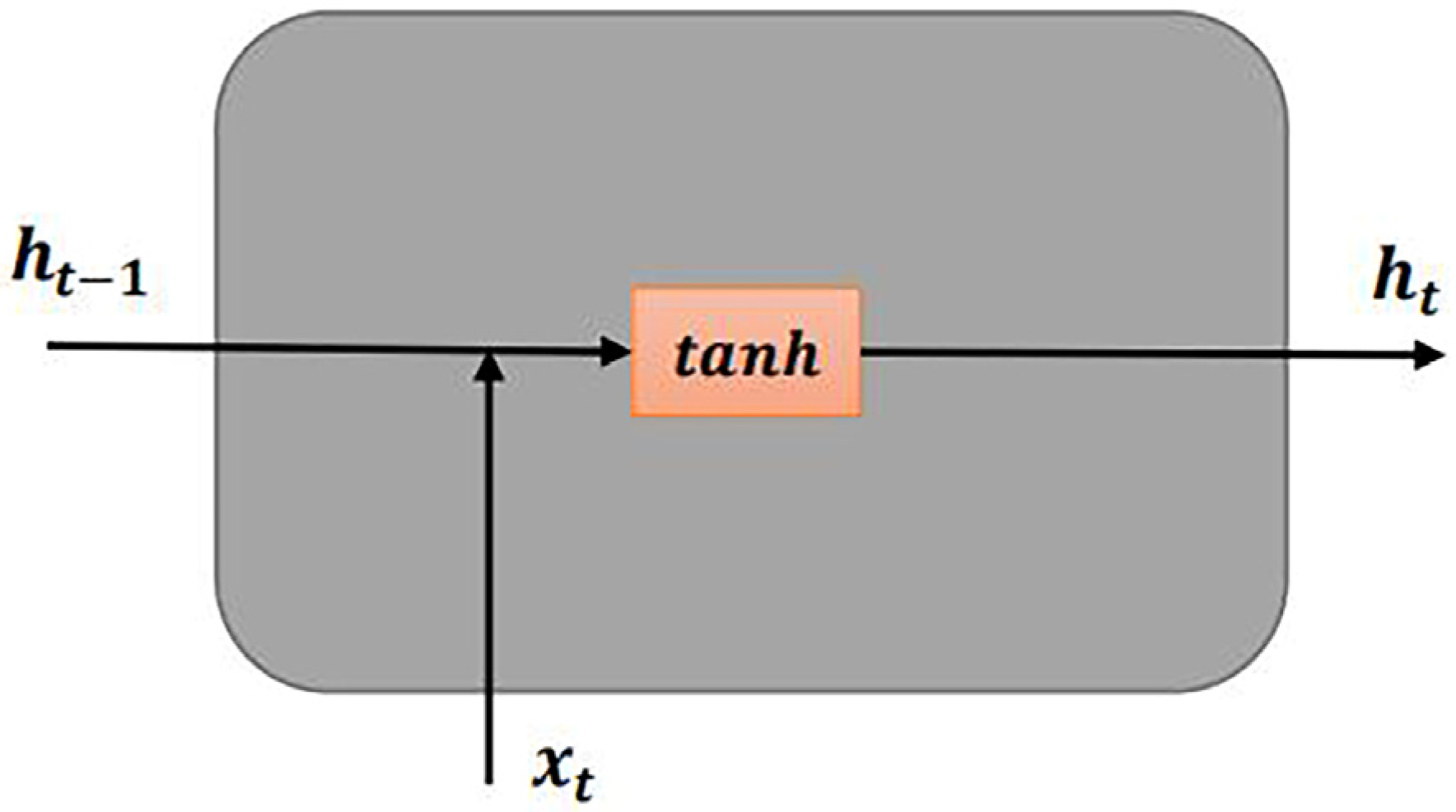
2.1. Recurrent Neural Network (RNN)
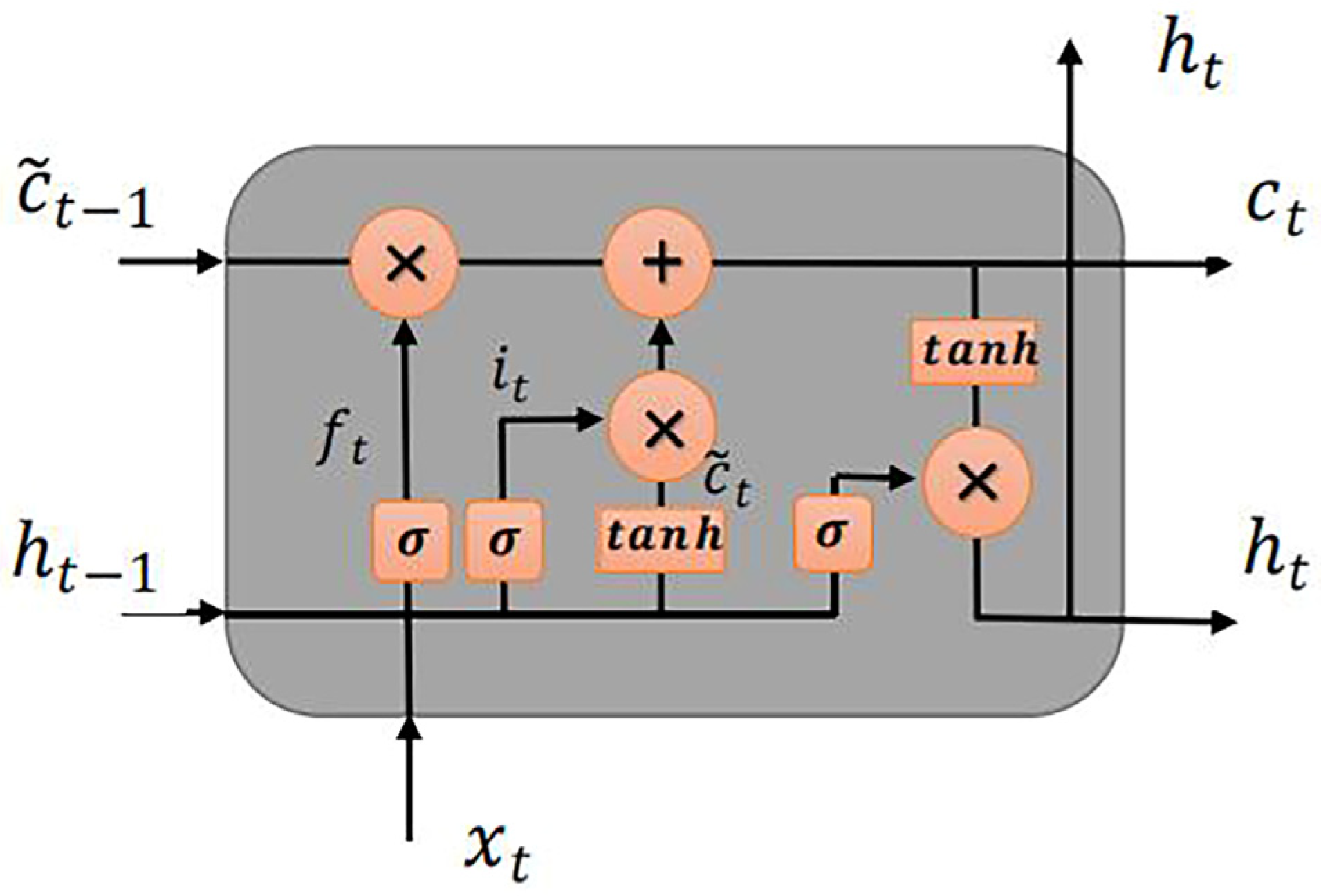
2.2. Long Short-Term Memory (LSTM)
3. Model Establishment
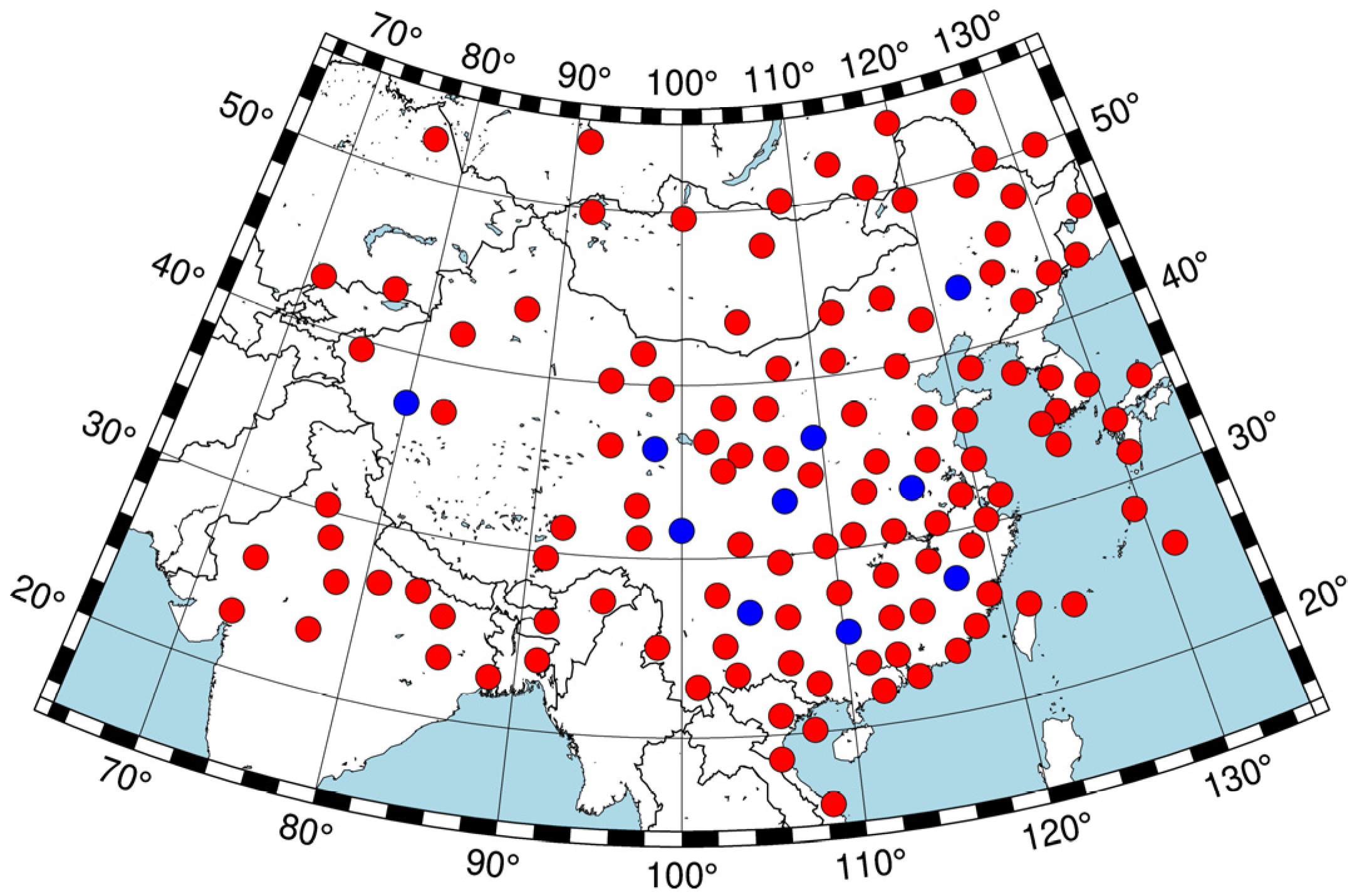
3.1. Data Preparation
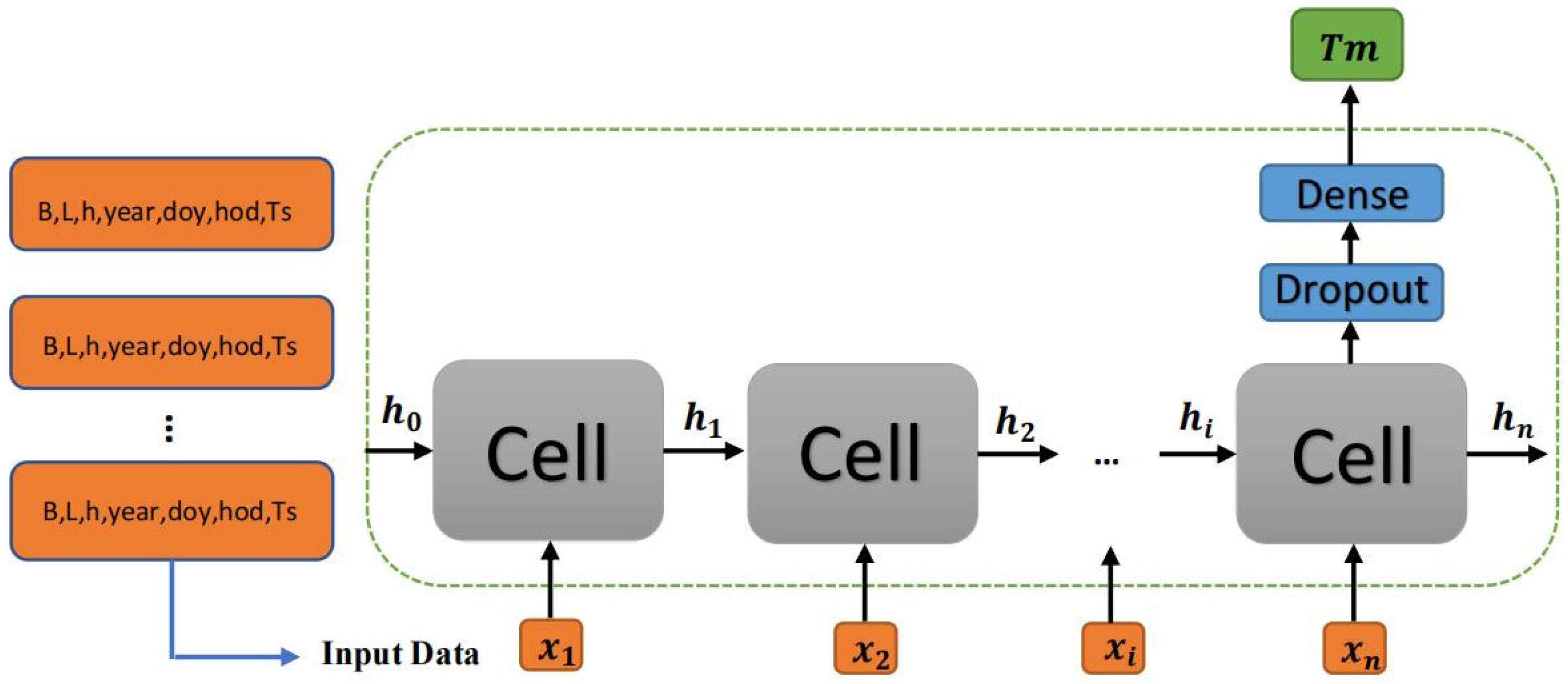
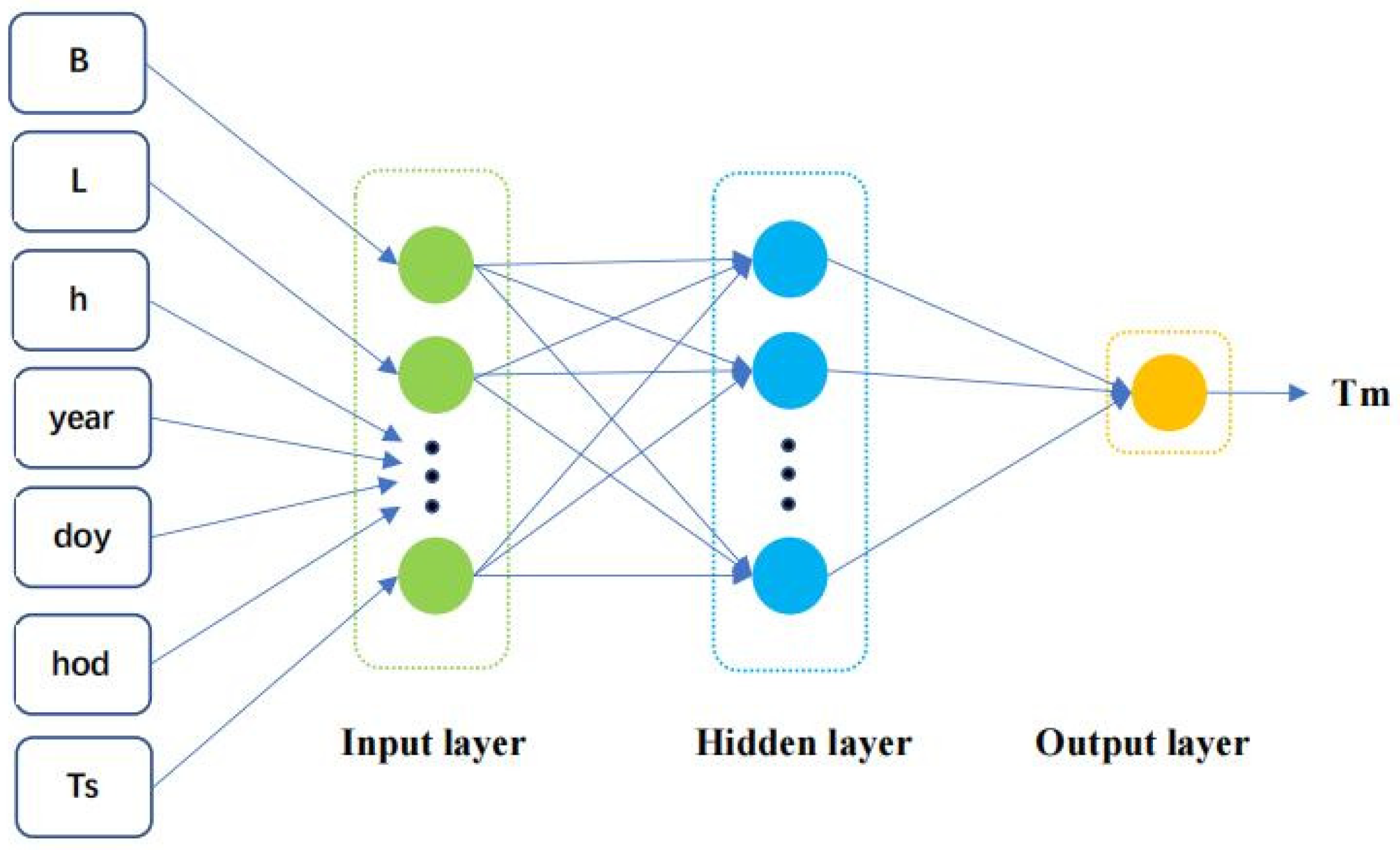
3.2. Input and Output of the Model
3.3. Data Normalization
3.4. Determination of Model Hyperparameters
4. Model Evaluation
4.1. Model for Comparison
4.1.1. BTm Model
4.1.2. GPT3 Model
4.1.3. BPNN Model
4.2. Model Evaluation Index
4.3. Computational Performance of the Model
5. Results
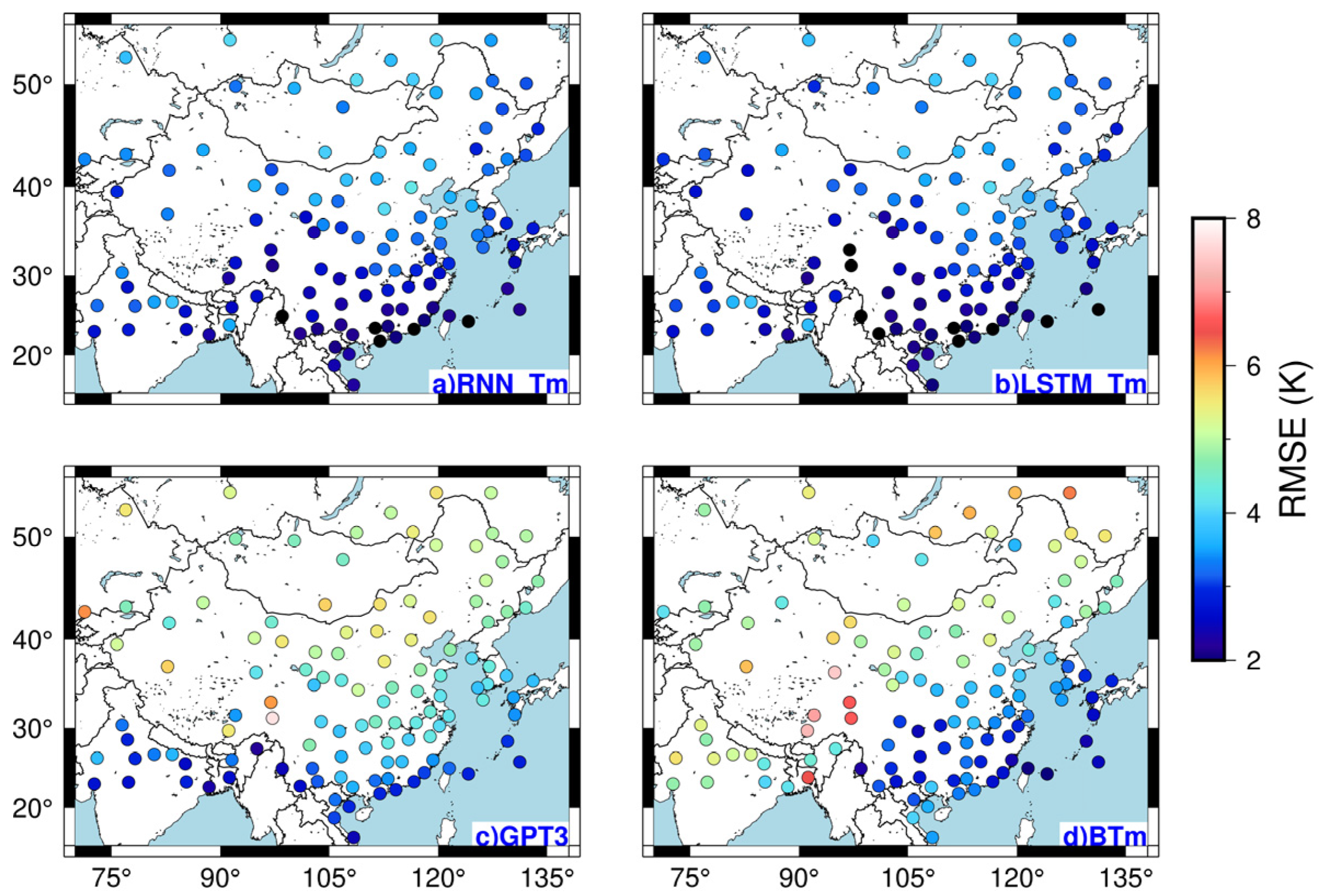
5.1. Predictive Performance of the Model at Modeling Stations
5.2. Predictive Performance of Model at Non-Modeling Stations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Davis, J.L.; Herring, T.A.; Shapiro, I.I.; Rogers, A.E.E.; Elgered, G. Geodesy by radio interferometry: Effects of atmospheric modeling errors on estimates of baseline length. Radio Sci. 1985, 20, 1593–1607. [Google Scholar] [CrossRef]
- Bevis, M.; Businger, S.; Herring, T.A.; Rocken, C.; Anthes, R.A.; Ware, R.H. GPS meteorology: Remote sensing of atmospheric water vapor using the global positioning system. J. Geophys. Res. Atmos. 1992, 97, 15787–15801. [Google Scholar] [CrossRef]
- Bevis, M.; Businger, S.; Chiswell, S.; Herring, T.A.; Ware, R.H. GPS Meteorology: Mapping Zenith Wet Delays onto Precipitable Water. J. Appl. Meteorol. 1994, 33, 379–386. [Google Scholar] [CrossRef]
- Yao, Y.; Zhang, B.; Xu, C.; Chen, J. Analysis of the global Tm–Ts correlation and establishment of the latitude-related linear model. Chin. Sci. Bull. 2014, 59, 2340–2347. [Google Scholar] [CrossRef]
- Baldysz, Z.; Nykiel, G. Improved Empirical Coefficients for Estimating Water Vapor Weighted Mean Temperature over Europe for GNSS Applications. Remote Sens. 2019, 11, 1995. [Google Scholar] [CrossRef] [Green Version]
- Yao, Y.; Zhu, S.; Yue, S. A globally applicable, season-specific model for estimating the weighted mean temperature of the atmosphere. J. Geod. 2012, 86, 1125–1135. [Google Scholar] [CrossRef]
- Yao, Y.; Zhang, B.; Yue, S.; Chao, Q.; Wen, F. Global empirical model for mapping zenith wet delays onto precipitable water. J. Geod. 2013, 87, 439–448. [Google Scholar] [CrossRef]
- Yao, Y.; Xu, C.; Zhang, B.; Cao, N. GTm-III: A new global empirical model for mapping zenith wet delays onto precipitable water vapour. Geophys. J. Int. 2018, 197, 202–212. [Google Scholar] [CrossRef] [Green Version]
- Bhm, J.; Mller, G.; Schindelegger, M.; Pain, G.; Weber, R. Development of an improved empirical model for slant delays in the troposphere (GPT2w). GPS Solut. 2015, 19, 433–441. [Google Scholar] [CrossRef] [Green Version]
- Landskron, D.; Boehm, J. VMF3/GPT3: Refined discrete and empirical troposphere mapping functions. J. Geod. 2018, 92, 349–360. [Google Scholar] [CrossRef]
- Sun, Z.; Zhang, B.; Yao, Y. A Global Model for Estimating Tropospheric Delay and Weighted Mean Temperature Developed with Atmospheric Reanalysis Data from 1979 to 2017. Remote Sens. 2019, 11, 1893. [Google Scholar] [CrossRef] [Green Version]
- Chen, P.; Yao, W.; Zhu, X. Realization of global empirical model for mapping zenith wet delays onto precipitable water using NCEP re-analysis data. Geophys. J. Int. 2014, 198, 1748–1757. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Yuan, Y.; Li, W.; Ou, J.; Li, Y.; Zhang, B. GPS PPP-derived precipitable water vapor retrieval based on Tm/Ps from multiple sources of meteorological data sets in China. J. Geophys. Res. 2017, 122, 4165–4183. [Google Scholar] [CrossRef]
- Balidakis, K.; Nilsson, T.; Zus, F.; Glaser, S.; Heinkelmann, R.; Deng, Z.; Schuh, H. Estimating Integrated Water Vapor Trends From VLBI, GPS, and Numerical Weather Models: Sensitivity to Tropospheric Parameterization. J. Geophys. Res. Atmos. 2018, 123, 6356–6372. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Chen, P.; Sun, L.; Ma, X. A global weighted mean temperature model based on empirical orthogonal function analysis. Adv. Space Res. 2018, 61, 1398–1411. [Google Scholar] [CrossRef]
- Huang, L.; Jiang, W.; Liu, L.; Chen, H.; Ye, S. A new global grid model for the determination of atmospheric weighted mean temperature in GPS precipitable water vapor. J. Geod. 2019, 93, 159–176. [Google Scholar] [CrossRef]
- Huang, L.; Liu, L.; Chen, H.; Jiang, W. An improved atmospheric weighted mean temperature model and its impact on GNSS precipitable water vapor estimates for China. GPS Solut. 2019, 23, 51. [Google Scholar] [CrossRef]
- Li, Q.; Yuan, L.; Chen, P.; Jiang, Z. Global grid-based Tm model with vertical adjustment for GNSS precipitable water retrieval. GPS Solut. 2020, 24, 73. [Google Scholar] [CrossRef]
- Ding, M. A neural network model for predicting weighted mean temperature. J. Geod. 2018, 92, 1187–1198. [Google Scholar] [CrossRef]
- Ding, M. A second generation of the neural network model for predicting weighted mean temperature. GPS Solut. 2020, 24, 61. [Google Scholar] [CrossRef]
- Yang, L.; Chang, G.; Qian, N.; Gao, J. Improved atmospheric weighted mean temperature modeling using sparse kernel learning. GPS Solut. 2021, 25, 28. [Google Scholar] [CrossRef]
- Sun, Z.; Zhang, B.; Yao, Y. Improving the Estimation of Weighted Mean Temperature in China Using Machine Learning Methods. Remote Sens. 2021, 13, 1016. [Google Scholar] [CrossRef]
- Gill, M.K.; Asefa, T.; Kemblowski, M.W.; Mckee, M. Soil moisture prediction using support vector machines. JAWRA J. Am. Water Resour. Assoc. 2006, 42, 1033–1046. [Google Scholar] [CrossRef]
- Lv, H.; Chen, G. Research on Wind Speed Vertical Extrapolation Based on Extreme Learning Machine; Springer: Singapore, 2017; pp. 3–11. [Google Scholar] [CrossRef]
- Bhuiyan, A.E.; Yang, F.; Biswas, N.K.; Rahat, S.H.; Neelam, T.J. Machine Learning-Based Error Modeling to Improve GPM IMERG Precipitation Product over the Brahmaputra River Basin. Forecasting 2020, 2, 248–266. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Sulaiman, S.O.; Deo, R.C.; Chau, K.W. An enhanced extreme learning machine model for river flow forecasting: State-of-the-art, practical applications in water resource engineering area and future research direction. J. Hydrol. 2019, 569, 387–408. [Google Scholar] [CrossRef]
- Ahn, K.H.; Palmer, R. Regional flood frequency analysis using spatial proximity and basin characteristics: Quantile regression vs. parameter regression technique. J. Hydrol. 2016, 540, 515–526. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.; Burnetas, A.; Langousis, A. Hydrological post-processing using stacked generalization of quantile regression algorithms: Large-scale application over CONUS. J. Hydrol. 2019, 577, 123957. [Google Scholar] [CrossRef]
- Asanjan, A.A.; Yang, T.T.; Hsu, K.L.; Sorooshian, S.; Lin, J.Q.; Peng, Q.D. Short-Term Precipitation Forecast Based on the PERSIANN System and LSTM Recurrent Neural NetworksN. J. Geophys. Res. Atmos. 2018, 123, 12543–12563. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, H.; Dong, J.Y.; Zhong, G.Q.; Sun, X. Prediction of Sea Surface Temperature Using Long Short-Term Memory. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1745–1749. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Dousa, J.; Elias, M. An improved model for calculating tropospheric wet delay. Geophys. Res. Lett. 2014, 41, 4389–4397. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, K.; Wu, S.; Fan, S.; Cheng, Y. Water vapor-weighted mean temperature and its impact on the determination of precipitable water vapor and its linear trend. J. Geophys. Res. Atmos. 2016, 121, 833–852. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Memory Unit Number | Learning Rate | Dropout | Epochs |
|---|---|---|---|---|
| RNN_Tm | 30 | 0.001 | 0.2 | 43 |
| LSTM_Tm | 75 | 0.005 | 0.2 | 27 |
| Model | Training Time | Prediction Time | Parameter Numbers |
|---|---|---|---|
| RNN_Tm | 11′54″ | 0′02″ | 1171 |
| LSTM_Tm | 15′35” | 0′04″ | 24,976 |
| BPNN | 25″49 | 0′02″ | 135 |
| GPT3 | - | 0′03″ | 324,000 |
| Model | RMSE | Bias | MAE | R | KGE |
|---|---|---|---|---|---|
| BTm | 4.34 | 0.57 | 3.35 | 0.935 | 0.806 |
| GPT3 | 4.37 | −0.88 | 3.38 | 0.932 | 0.892 |
| BPNN | 3.48 | 0.34 | 2.57 | 0.921 | 0.924 |
| RNN_Tm | 3.01 | −0.13 | 2.33 | 0.967 | 0.942 |
| LSTM_Tm | 2.89 | 0.14 | 2.23 | 0.970 | 0.954 |
| Latitude | BTm | GPT3 | RNN_Tm | LSTM_Tm |
|---|---|---|---|---|
| 15° N–20° N | 3.74 | 2.75 | 2.33 | 2.13 |
| 20° N–25° N | 3.47 | 2.96 | 2.23 | 2.21 |
| 25° N–30° N | 3.71 | 3.56 | 2.60 | 2.53 |
| 30° N–35° N | 3.97 | 4.37 | 2.91 | 2.79 |
| 35° N–40° N | 4.45 | 4.67 | 3.28 | 3.11 |
| 40° N–45° N | 4.80 | 5.09 | 3.45 | 3.25 |
| 45° N–50° N | 4.61 | 4.85 | 3.31 | 3.20 |
| 50° N–55° N | 5.61 | 5.20 | 3.71 | 3.59 |
| Station | Latitude(°) | Longitude(°) | H(m) | BTm | GPT3 | RNN_Tm | LSTM_Tm |
|---|---|---|---|---|---|---|---|
| 57957 | 25.33 | 110.30 | 166 | 2.79 | 3.50 | 2.30 | 2.45 |
| 56691 | 26.87 | 104.28 | 2236 | 2.51 | 4.02 | 2.58 | 2.97 |
| 58725 | 27.33 | 117.47 | 219 | 3.06 | 3.49 | 2.47 | 2.28 |
| 56146 | 31.62 | 100.00 | 3394 | 6.02 | 4.05 | 2.29 | 2.29 |
| 58203 | 32.87 | 115.73 | 33 | 3.59 | 4.36 | 3.25 | 3.25 |
| 57127 | 33.07 | 107.03 | 509 | 3.10 | 5.47 | 2.93 | 2.72 |
| 52836 | 36.30 | 98.10 | 3190 | 7.75 | 3.79 | 2.67 | 2.64 |
| 53845 | 36.57 | 109.45 | 959 | 4.52 | 4.39 | 3.67 | 3.23 |
| 51828 | 37.14 | 79.93 | 1375 | 6.17 | 4.27 | 3.10 | 2.86 |
| 54135 | 43.60 | 122.27 | 180 | 5.34 | 5.36 | 3.80 | 3.71 |
| Mean | - | - | - | 4.49 | 4.27 | 2.91 | 2.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, W.; Gao, J.; Yang, L.; Wang, M.; Yao, W. A Novel Modeling Strategy of Weighted Mean Temperature in China Using RNN and LSTM. Remote Sens. 2021, 13, 3004. https://doi.org/10.3390/rs13153004
Gao W, Gao J, Yang L, Wang M, Yao W. A Novel Modeling Strategy of Weighted Mean Temperature in China Using RNN and LSTM. Remote Sensing. 2021; 13(15):3004. https://doi.org/10.3390/rs13153004
Chicago/Turabian StyleGao, Wenliang, Jingxiang Gao, Liu Yang, Mingjun Wang, and Wenhao Yao. 2021. "A Novel Modeling Strategy of Weighted Mean Temperature in China Using RNN and LSTM" Remote Sensing 13, no. 15: 3004. https://doi.org/10.3390/rs13153004
APA StyleGao, W., Gao, J., Yang, L., Wang, M., & Yao, W. (2021). A Novel Modeling Strategy of Weighted Mean Temperature in China Using RNN and LSTM. Remote Sensing, 13(15), 3004. https://doi.org/10.3390/rs13153004