
A No-Reference CNN-Based Super-Resolution Method for KOMPSAT-3 Using Adaptive Image Quality Modification


Abstract
:1. Introduction
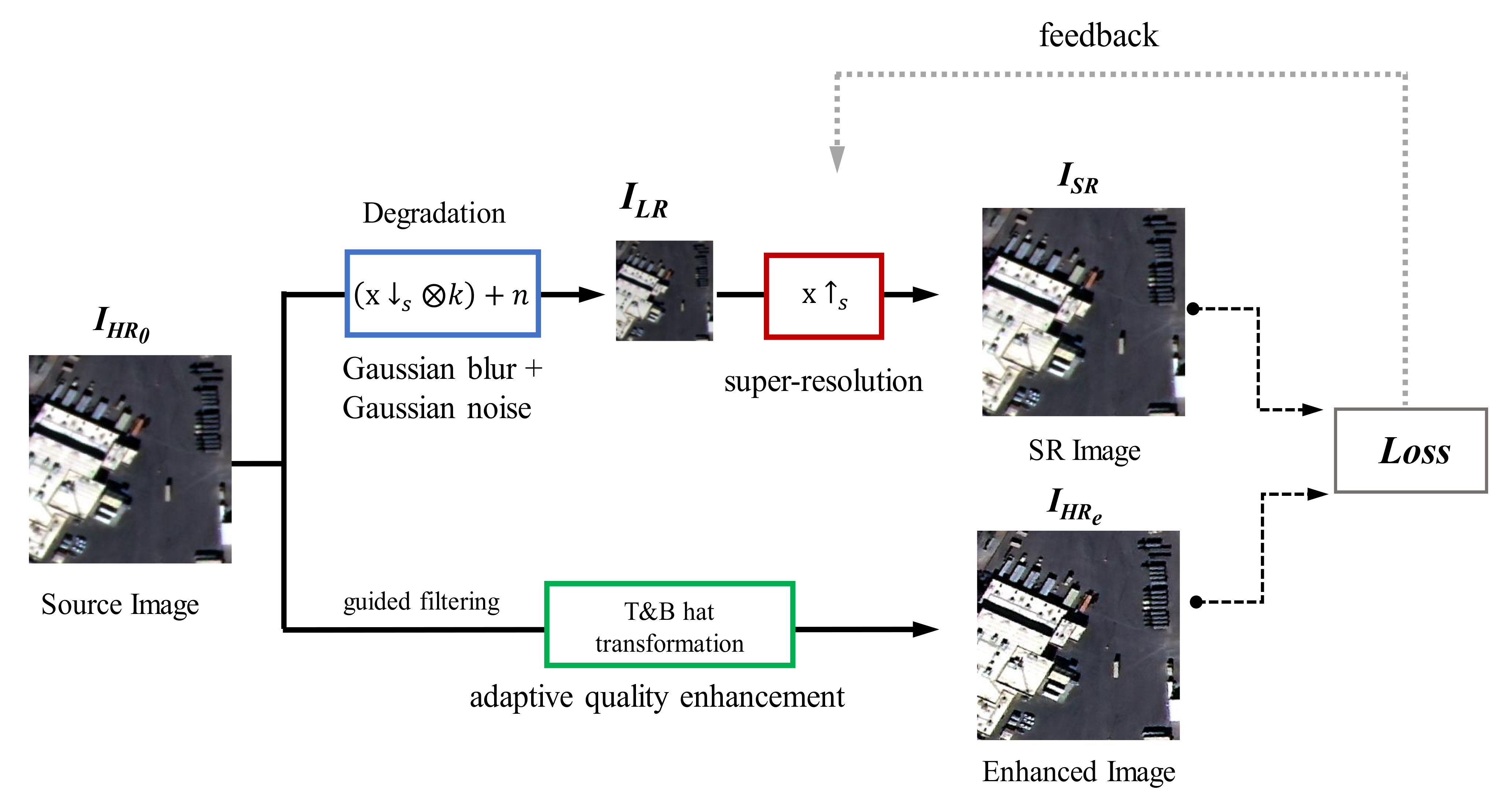
- In this study, we propose a new degradation model for generating LR images required for training to obtain high-quality SR images from KOMPSAT-3 imaging data. This degradation model generates various input images by adding Gaussian noise and blur kernel to the training LR input images. Using the proposed degradation model, we were able to obtain clear and sharpened SR images with noise removed.
- In addition, we propose an adaptive image quality modification technique that applies top-hat and bottom-hat transformation and guided filter to HR images to generate the sharpened edge and reduced the noise on SR images compared to the original images.
- In comparison with other SR methods, the effect of improving edge sharpness and reducing noise was verified through various experiments. Three diverse types of analysis methods were introduced to verify the SR performance. First, the reconstruction performance was evaluated with visual comparison and reference quantitative indices, PSNR and structural similarity index (SSIM). In addition, we performed the no-reference quantitative evaluation index with proposed SR method and other SR methods. Second, to evaluate improvement performance, we extracted edges from the super-resolved panchromatic (PAN) images and compared them with the reference target specification. Finally, the effect of the SR images on the object detection performance was analyzed by applying the object detection algorithm to the obtained SR image.
2. Methodology
2.1. Degradation Model for Training LR Images
2.2. Image Quality Enhancement for HR Images
2.3. Proposed CNN-Based SR Network
3. Experiment
4. Results and Discussion
4.1. Quantitative and Qualitative Analysis
4.2. Edge Detection Performance by Target Site
4.3. Object Detection Performance Test
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Sajjadi, M.S.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 4491–4500. [Google Scholar]
- Tan, W.; Yan, B.; Bare, B. Feature super-resolution: Make machine see more clearly. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3994–4002. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lucas, A.; Lopez-Tapia, S.; Molina, R.; Katsaggelos, A.K. Self-supervised Fine-tuning for Correcting Super-Resolution Convolutional Neural Networks. arXiv 2019, arXiv:1912.12879. [Google Scholar]
- Efrat, N.; Glasner, D.; Apartsin, A.; Nadler, B.; Levin, A. Accurate blur models vs. image priors in single image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2832–2839. [Google Scholar]
- Michaeli, T.; Irani, M. Nonparametric Blind Super-resolution. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 945–952. [Google Scholar] [CrossRef]
- Sroubek, F.; Cristobal, G.; Flusser, J. Simultaneous super-resolution and blind deconvolution. J. Phys. Conf. Ser. 2008, 124, 012048. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. Deep plug-and-play super-resolution for arbitrary blur kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1671–1681. [Google Scholar]
- Zhang, K.; Van Gool, L.; Timofte, R. Deep Unfolding Network for Image Super-Resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 3214–3223. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Y.; Dong, X.; Xu, Q.; Yang, J.; An, W.; Guo, Y. Unsupervised Degradation Representation Learning for Blind Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 10581–10590. [Google Scholar]
- Kim, S.Y.; Sim, H.; Kim, M. KOALAnet: Blind Super-Resolution Using Kernel-Oriented Adaptive Local Adjustment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 10611–10620. [Google Scholar]
- Liu, H.; Fu, Z.; Han, J.; Shao, L.; Liu, H. Single satellite imagery simultaneous super-resolution and colorization using multi-task deep neural networks. J. Vis. Commun. Image Represent. 2018, 53, 20–30. [Google Scholar] [CrossRef] [Green Version]
- Jiang, K.; Wang, Z.; Yi, P.; Jiang, J.; Xiao, J.; Yao, Y. Deep Distillation Recursive Network for Remote Sensing Imagery Super-Resolution. Remote Sens. 2018, 10, 1700. [Google Scholar] [CrossRef] [Green Version]
- Kwan, C. Remote Sensing Performance Enhancement in Hyperspectral Images. Sensors 2018, 18, 3598. [Google Scholar] [CrossRef] [Green Version]
- Burdziakowski, P. Increasing the Geometrical and Interpretation Quality of Unmanned Aerial Vehicle Photogrammetry Products using Super-Resolution Algorithms. Remote Sens. 2020, 12, 810. [Google Scholar] [CrossRef] [Green Version]
- Haris, M.; Watanabe, T.; Fan, L.; Widyanto, M.R.; Nobuhara, H. Superresolution for UAV Images via Adaptive Multiple Sparse Representation and Its Application to 3-D Reconstruction. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4047–4058. [Google Scholar] [CrossRef]
- Kang, W.; Yu, S.; Ko, S.; Paik, J. Multisensor Super Resolution Using Directionally-Adaptive Regularization for UAV Images. Sensors 2015, 15, 12053–12079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Jiang, K.; Yi, P.; Han, Z.; He, Z. Ultra-dense GAN for satellite imagery super-resolution. Neurocomputing 2020, 398, 328–337. [Google Scholar] [CrossRef]
- Bosch, M.; Gifford, C.M.; Rodriguez, P.A. Super-resolution for overhead imagery using densenets and adversarial learning. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1414–1422. [Google Scholar]
- Liebel, L.; Körner, M. Single-image super resolution for multispectral remote sensing data using convolutional neural networks. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 883–890. [Google Scholar] [CrossRef] [Green Version]
- Shermeyer, J.; Van Etten, A. The effects of super-resolution on object detection performance in satellite imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Rabbi, J.; Ray, N.; Schubert, M.; Chowdhury, S.; Chao, D. Small-object detection in remote sensing images with end-to-end edge-enhanced GAN and object detector network. Remote Sens. 2020, 12, 1432. [Google Scholar] [CrossRef]
- Zhou, R.; Susstrunk, S. Kernel modeling super-resolution on real low-resolution images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 2433–2443. [Google Scholar]
- Donoho, D.L.; Johnstone, J.M. Ideal spatial adaptation by wavelet shrinkage. Biometrika 1994, 81, 425–455. [Google Scholar] [CrossRef]
- Hassanpour, H.; Samadiani, N.; Salehi, S.M. Using morphological transforms to enhance the contrast of medical images. Egypt. J. Radiol. Nucl. Med. 2015, 46, 481–489. [Google Scholar] [CrossRef]
- Haralick, R.M.; Sternberg, S.R.; Zhuang, X. Image analysis using mathematical morphology. IEEE Trans. Pattern Anal. Mach. Intell. 1987, PAMI-9, 532–550. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Bai, X.; Zhou, F.; Xue, B. Image enhancement using multi scale image features extracted by top-hat transform. Opt. Laser Technol. 2012, 44, 328–336. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- USGS Remote Sensing Technologies Test Sites. Available online: https://calval.cr.usgs.gov/apps/test_sites_catalog (accessed on 10 June 2021).
- Li, C.; Tang, L.; Ma, L.; Zhou, Y.; Gao, C.; Wang, N.; Li, X.; Wang, X.; Zhu, X. Comprehensive calibration and validation site for information remote sensing. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 1233. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 1–11. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| KOMPSAT-3 | KOMPSAT-3A | |||
|---|---|---|---|---|
| Ground Sampling Distance | PAN: 0.7 m MS: 2.8 m | PAN: 0.54 m MS: 2.16 m | ||
| Spectral Bands | PAN: 450∼900 nm Blue: 450∼520 nm Green: 520∼600 nm Red: 630∼690 nm | PAN: 450∼900 nm Blue: 450∼520 nm Green: 520∼600 nm Red: 630∼690 nm | ||
| View Angle | Roll: −30∼30 deg Pitch: −30∼30 deg | Roll: −30∼30 deg Pitch: −30∼30 deg | ||
| Data Quantization | 14 bits/pixel | 14 bits/pixel | ||
| PSNR (dB) | SSIM | NIQE | |
|---|---|---|---|
| Nearest Neighbor | 40.56 | 0.8096 | 22.94 |
| Bicubic | 42.74 | 0.8672 | 22.98 |
| SRResNet [9] | 47.63 | 0.9224 | 22.79 |
| RRDB [12] | 47.78 | 0.9234 | 22.80 |
| RCAN [8] | 47.65 | 0.9226 | 22.76 |
| DPSR [17] | 47.34 | 0.9182 | 22.76 |
| USRNET [18] | 47.69 | 0.9229 | 22.53 |
| Proposed | 47.39 | 0.9158 | 22.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, Y.; Han, S.; Kim, Y. A No-Reference CNN-Based Super-Resolution Method for KOMPSAT-3 Using Adaptive Image Quality Modification. Remote Sens. 2021, 13, 3301. https://doi.org/10.3390/rs13163301
Choi Y, Han S, Kim Y. A No-Reference CNN-Based Super-Resolution Method for KOMPSAT-3 Using Adaptive Image Quality Modification. Remote Sensing. 2021; 13(16):3301. https://doi.org/10.3390/rs13163301
Chicago/Turabian StyleChoi, Yeonju, Sanghyuck Han, and Yongwoo Kim. 2021. "A No-Reference CNN-Based Super-Resolution Method for KOMPSAT-3 Using Adaptive Image Quality Modification" Remote Sensing 13, no. 16: 3301. https://doi.org/10.3390/rs13163301
APA StyleChoi, Y., Han, S., & Kim, Y. (2021). A No-Reference CNN-Based Super-Resolution Method for KOMPSAT-3 Using Adaptive Image Quality Modification. Remote Sensing, 13(16), 3301. https://doi.org/10.3390/rs13163301